大数据 - Hadoop系列《三》- HDFS(分布式文件系统)概述
🐶5.1 hdfs的概念
HDFS分布式文件系统,全称为:Hadoop Distributed File System。
它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。
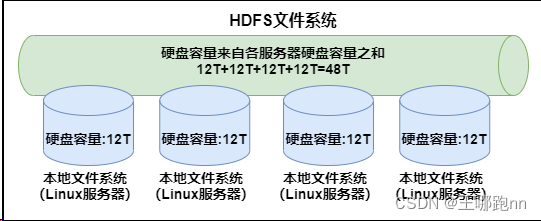
我一共三台linux服务器,每台机器内存60G,所以HDFS文件系统之和为180G
🐶5.2 为什么要用hdfs:
因为随着数据量越来越大,一台机器已经不能满足当前数据的存储,如果使用多台计算机进行存储,虽然解决了数据的存储问题,但是后期的管理和维护成本比较高,因为我们不能精准的知道哪台机器上存储了什么样的数据,所以我们迫切的需要一个能够帮助我们管理多台机器上的文件的一套管理系统,这就是分布式文件系统的作用,而hdfs就是这样的一套管理系统,而且他也只是其中的一种.
🐶5.3 hdfs的优缺点
5.3.1 优点:
🥙1. 高容错性:
数据自动保存多个副本。它通过增加副本的形式,提高容错性。

某一个副本丢失以后,它可以自动恢复。

🥙2. 高扩展性:
当HDFS系统的存储空间不够时,我们只需要添加一台新的机器到当前集群中即可完成扩容,这就是我们所说的横向扩容,而集群的存储能力,是按照整个集群中的所有的机器的存储能力来计算的,这也就是我们所说的高扩容性
🥙3. 适合处理大数据:
-
数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据。
-
文件规模:能够处理百万规模以上的文件数量,数量相当之大。
5.3.2 缺点:
🥙1. 不适合低延时数据访问;
-
比如毫秒级的来存储数据,这是不行的,它做不到。
-
它适合高吞吐率的场景,就是在某一时间内写入大量的数据。但是它在低延时的情况 下是不行的,比如毫秒级以内读取数据,这样它是很难做到的。
🥙2. 无法高效的对大量小文件进行存储
-
存储大量小文件的话,它会占用NameNode大量的内存来存储文件、目录和块信息。这样是不可取的,因为NameNode的内存总是有限的。
-
小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
🥙3. 不支持并发写入、文件随机修改
-
一个文件只能有一个写,不允许多个线程同时写。

-
仅支持数据 append(追加),不支持文件的随机修改。
🐶5.4 HDFS架构
HDFS是一个主/从(Master/Slave)体系结构,架构中有三个角色:一个叫NameNode,一个叫DataNode,还有一个叫secondaryNameNode
主从架构示例图:
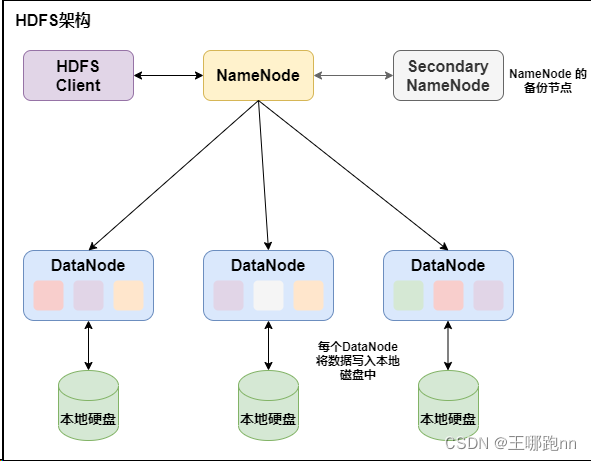
所以我们在搭建hdfs架构时,需要一台NameNode,三台DataNode,一台SecondaryNameNode.
1. NameNode
主要负责存储文件的元数据,比如集群id,文件存储所在的目录名称,文件的副本数,以及每个文件被切割成块以后的块列表和块列表所在的DataNode。
1)管理HDFS的名称空间。
2)配置副本策略
3)管理数据块(Block)映射信息。
2. DataNode
负责管理用户的文件数据块,每一个数据块都可以在多个 DataNode 上存储多个副本,默认为3个。
1)存储实际的数据块
2)执行数据块的读/写操作

| NameNode | DataNode |
| 存储元数据 | 存储文件内容 |
| 元数据保存在内存中 | 文件内容保存在磁盘 |
| 保存文件、block、DataNode之间的映射关系 | 维护了block id到DataNode本地文件的映射关系 |
3. SecondaryNameNode
并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
1)辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode;
2) 在紧急情况下,可辅助恢复NameNode.
4. Client:就是客户端
1)文件切分。文件上传HDFS的时候,client将文件切分成一个一个的block,然后进行上传。
2)与namenode交互,获取文件的位置信息
3)与datanode交互,读取或者写入数据。
4)Client提供一些命令来管理HDFS,比如NameNode格式化
5)Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作。
🐶5.5 HDFS文件块大小(面试题)
HDFS中的文件在物理上是分块存储(Block), 块的大小可以通过配置参数(dfs blocksize)来规定,默认大小在Hadoop2x/3x版本中是128M,1x版本中是64M.
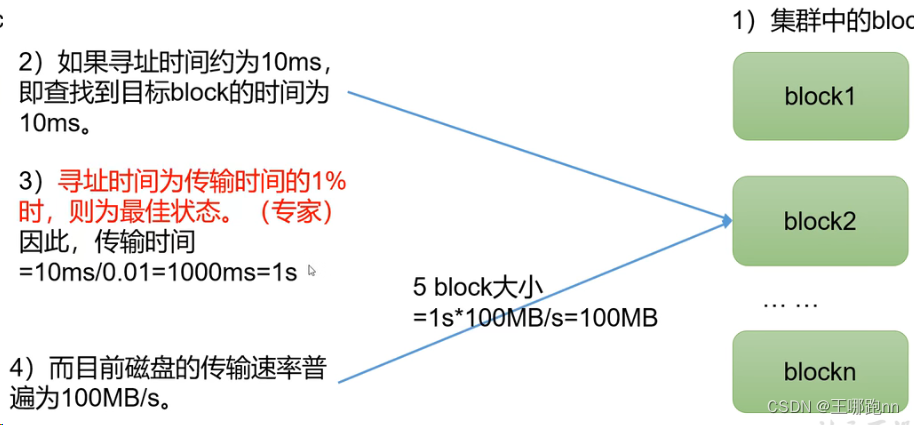
问题:能不能将块设置的小一些? 理论上是可以的,但是如果设置的块大小过小,会占用大量的namenode的元数据空间,而且在读写操作时,加大了寻址时间,所以不建议设置的过小 问题:不能过小,那能不能过大? 不建议,因为设置的过大,传输时间会远远大于寻址时间,增加了网络资源的消耗,而且如果在读写的过程中出现故障,恢复起来也很麻烦,所以不建议
总结:HDFS块的大小设置主要取决于磁盘传输速率。
相关文章:
大数据 - Hadoop系列《三》- HDFS(分布式文件系统)概述
🐶5.1 hdfs的概念 HDFS分布式文件系统,全称为:Hadoop Distributed File System。 它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集…...

Golang标准库sync的使用
Go语言作为现代编程语言,其并发编程的优势是有目共睹的。在实际编程中,我们常常需要保证多个goroutine之间的同步,这就需要使用到Go语言的sync标准库。sync库提供了基本的同步原语,例如互斥锁(Mutex)和等待…...

判断两张图片是否完全一致
判断两张图片是否为完全相同的图片 批量判断尺寸 大小 图像展示内容体是否完全一致的图片 import os import hashlib from PIL import Imagedef check_img_repeat(directory):"""批量对图片进行重复性校验是检查一组图像中是否有相同或几乎相同的图像副本。一…...

2024洗地机哪家强?口碑洗地机推荐
现如今,智能家电在人们生活中变得越来越受欢迎,例如智能洗地机的出现,不仅省时省力,还实现了家务清洁的自由。在家庭中,地面清洁一直是一个令人头疼的问题,各种智能家居品牌通过开发各种智能家电产品来解决…...
k8s的资源管理
命令行: kubectl命令行工具优点: 90%以上的场景都可以满足 对资源的增,删,查比较方便,对改不是很友好缺点:命令比较冗长,复杂难记 声明方式:k8s当中的yaml文件实现资源管理----声明式GUI:图形化工具的管理。 查看k8s的…...
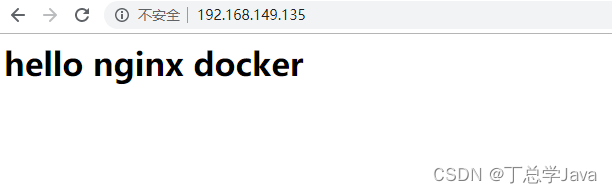
docker应用部署(部署MySql,部署Tomcat,部署Nginx,部署Redis)
Docker 应用部署 一、部署MySQL 搜索mysql镜像 docker search mysql拉取mysql镜像 docker pull mysql:5.6创建容器,设置端口映射、目录映射 # 在/root目录下创建mysql目录用于存储mysql数据信息 mkdir ~/mysql cd ~/mysqldocker run -id \ -p 3307:3306 \ --na…...

非常好用的ocr图片文字识别技术,识别图片中的文字
目录 一.配置环境 二.应用 2.1常见图片识别 2.2排版简单的印刷体截图图片识别 2.3竖排文字识别 2.4英文识别 2.5繁体中文识别 2.6单行文字的图片识别 三.参考 一.配置环境 pip3 install cnocr -i https://pypi.tuna.tsinghua.edu.cn/simple pip3 install onnxruntime…...

20231227在Firefly的AIO-3399J开发板的Android11的挖掘机的DTS配置单后摄像头ov13850
20231227在Firefly的AIO-3399J开发板的Android11的挖掘机的DTS配置单后摄像头ov13850 2023/12/27 18:40 1、简略步骤: rootrootrootroot-X99-Turbo:~/3TB$ cat Android11.0.tar.bz2.a* > Android11.0.tar.bz2 rootrootrootroot-X99-Turbo:~/3TB$ tar jxvf Androi…...
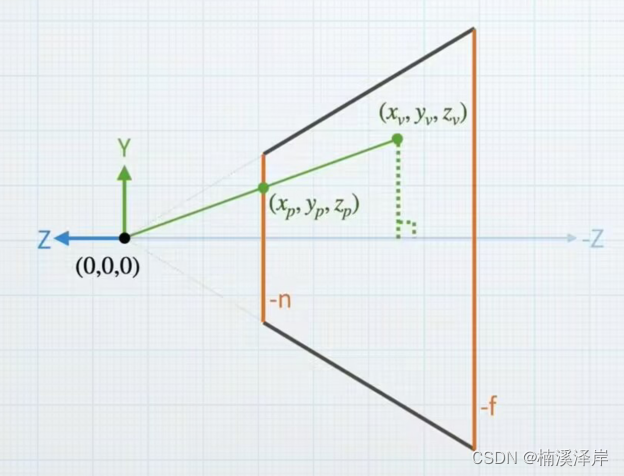
Unity中Shader裁剪空间推导(透视相机到裁剪空间的转化矩阵)
文章目录 前言一、简单看一下 观察空间—>裁剪空间—>屏幕空间 的转化1、观察空间(右手坐标系、透视相机)2、裁剪空间(左手坐标系、且转化为了齐次坐标)3、屏幕空间(把裁剪坐标归一化设置)4、从观察空…...

企业签名分发对移动应用开发者有什么影响
企业签名分发是移动应用开发者在应用程序发布前测试、内部分发和特定的受众群体分发等方面比较常用的一种工具。那对于应用商城分发有啥区别,下面简单的探讨一下。 独立分发能力 通过企业签名分发开发者可以自己决定应用程序的发布时间和方式,不用受应用…...
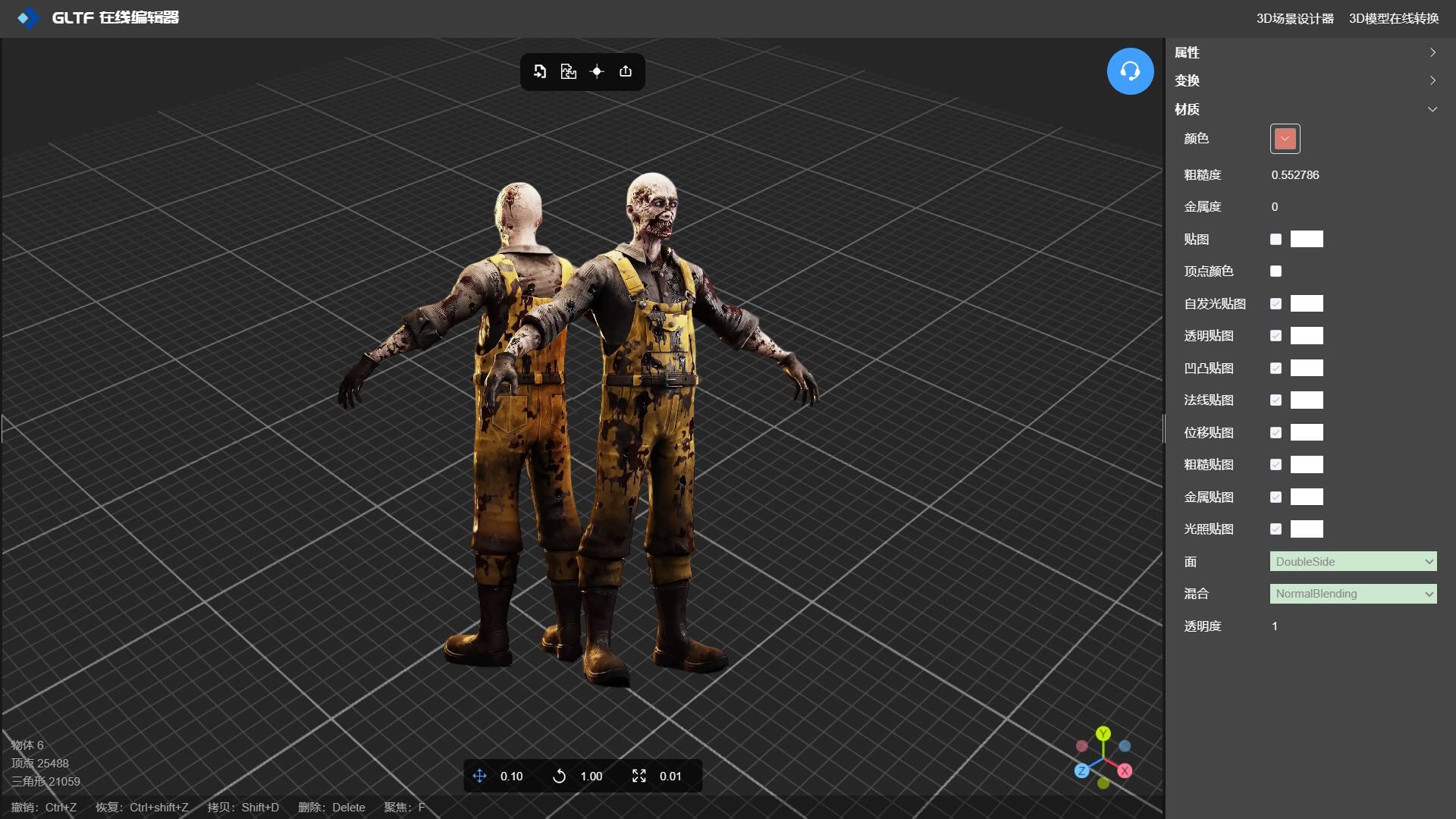
3D游戏角色建模纹理贴图处理
在线工具推荐: 3D数字孪生场景编辑器 - GLTF/GLB材质纹理编辑器 - 3D模型在线转换 - Three.js AI自动纹理开发包 - YOLO 虚幻合成数据生成器 - 三维模型预览图生成器 - 3D模型语义搜索引擎 在本文中,我们将介绍 3D 纹理的基础知识,并讨…...

【C++ 单例模式】
正确的析构 静态实例和回收类 SingletonMode.cpp #include <iostream> #include <pthread.h>class Singleton {private:Singleton(){std::cout << "构造" << std::endl;};~Singleton(){std::cout << "析构" << std::…...

React16源码: ConcurrentMode的使用及源码实现
ConcurrentMode 1 ) 概述 ConcurrentMode 是 React 16 出来的一个最令人振奋的功能在2018年年初是 Async Mode,在发布了16.6之后,名字进行了更新然后改成了 ConcurrentMode,中间的API有一个过渡的版本,后续会提到它其实是 React…...

SQL性能优化-索引
1.性能下降sql慢执行时间长等待时间长常见原因 1)索引失效 索引分为单索、复合索引。 四种创建索引方式 create index index_name on user (name); create index index_name_2 on user(id,name,email); 2)查询语句较烂 3)关联查询太多join&a…...

Ubuntu本地快速搭建web小游戏网站,公网用户远程访问
🔥博客主页: 小羊失眠啦. 🎥系列专栏:《C语言》 《数据结构》 《Linux》《Cpolar》 ❤️感谢大家点赞👍收藏⭐评论✍️ 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,…...
easyrecovery 2024最新免费密钥分享 实用数据恢复软件分享
在日常使用电脑时,我们经常会遇到误删文件的情况,若文件还未被彻底删除,我们还可以通过电脑中的回收站将其恢复,但若是回收站都被清空的话,想要恢复文件就变得比较困难了,而EasyRecovery可以很好的帮助我们…...

2.4信道复用技术
目录 2.4信道复用技术2.4.1频分复用、时分复用和统计时分复用频分复用FDM(Frequency Division Multiplexing)时分复用TDM(Time Division Multiplexing)统计时分复用STDM(Statistic TDM) 2.4.2波分复用2.4.3…...

JVM篇:JVM的简介
JVM简介 JVM全称为Java Virtual Machine,翻译过来就是java虚拟机,Java程序(Java二进制字节码)的运行环境 JVM的优点: Java最大的一个优点是,一次编写,到处运行。之所以能够实现这个功能就是依…...
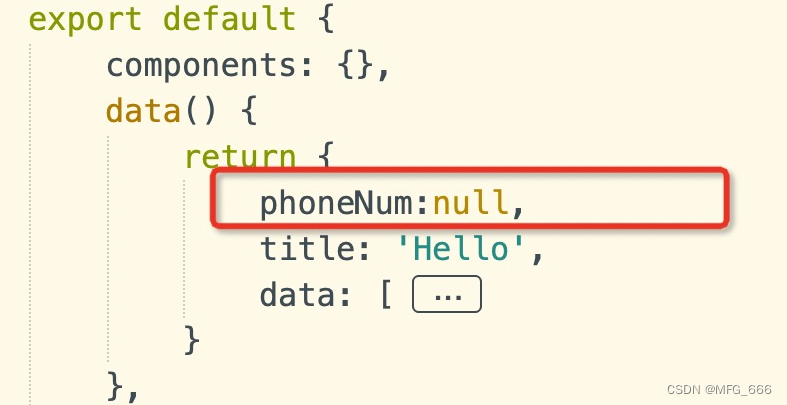
uniapp 输入手机号并且正则校验
1.<input input“onInput” :value“phoneNum” type“number” maxlength“11”/> 3. method里面写 onInput(e){ this.phoneNum e.detail.value }, 4.调用接口时候校验正则 if (!/^1[3456789]\d{9}$/.test(this.phoneNum)) {uni.showToast({title: 请输入正确的手机号…...

经典目标检测YOLO系列(一)复现YOLOV1(3)正样本的匹配及损失函数的实现
经典目标检测YOLO系列(一)复现YOLOV1(3)正样本的匹配及损失函数的实现 之前,我们依据《YOLO目标检测》(ISBN:9787115627094)一书,提出了新的YOLOV1架构,并解决前向推理过程中的两个问题,继续按照此书进行YOLOV1的复现。 经典目标…...

量子生成分类技术:原理、优势与应用解析
1. 量子生成分类技术概述量子生成分类(Quantum Generative Classification, QGC)是一种基于量子计算原理的新型机器学习范式,它从根本上改变了传统分类任务的实现方式。与常见的判别式学习方法不同,QGC采用生成式学习策略…...

ARM异常处理机制与ESR寄存器详解
1. ARM异常处理机制概述在ARMv8/v9架构中,异常处理是处理器响应硬件或软件事件的核心机制。当发生异常时,处理器会暂停当前程序执行,跳转到预定义的异常向量表入口,同时将异常相关信息记录在异常综合征寄存器(ESR)中。异常可能由多…...

用Python复现数学建模国赛B题‘穿越沙漠’:手把手教你写最优路径规划算法
用Python复现数学建模国赛B题‘穿越沙漠’:手把手教你写最优路径规划算法 当数学建模问题遇上Python编程,会产生怎样的化学反应?本文将以2020年高教杯数学建模国赛B题"穿越沙漠"为例,带你从零开始构建一个完整的路径规划…...

【深度解析】从 Gemini 3.2、Claude 限额变化到 AI Agent:大模型工程化选型与实战评估
摘要 本文基于近期 AI 模型与 Agent 生态变化,解析 Gemini 3.2、Claude 快速模式、第三方 Agent 成本变化等技术趋势,并给出一套可落地的大模型 API 调用与评估示例,帮助开发者构建更稳定、可扩展的 AI 应用架构。背景介绍 近期 AI 领域出现了…...
)
客户要求改iServer访问路径?别慌,手把手教你修改Tomcat配置+Nginx代理(附避坑点)
深度解析iServer访问路径修改:从Tomcat配置到Nginx代理的全链路实践 当客户提出"需要将iServer访问地址调整为特定路径格式"的需求时,许多运维工程师的第一反应可能是简单修改Nginx配置。但实际操作中会发现,仅靠代理层调整会导致…...

掌握CRC32校验码:从基础计算到高级逆向操作的完整指南
掌握CRC32校验码:从基础计算到高级逆向操作的完整指南 【免费下载链接】crc32 CRC32 tools: reverse, undo/rewind, and calculate hashes 项目地址: https://gitcode.com/gh_mirrors/cr/crc32 你是否曾遇到过需要验证文件完整性,却不知道如何下手…...

嘎嘎降AI和笔灵AI哪个更适合毕业论文:2026年达标率改写质量售后完整测评对比报告
嘎嘎降AI和笔灵AI哪个更适合毕业论文:2026年达标率改写质量售后完整测评对比报告 帮几个不同专业的同学处理过论文AI率,用过的工具加起来也有六七款了。 综合看,嘎嘎降AI(www.aigcleaner.com)是最稳的选择࿰…...

实测Taotoken在低功耗arm7设备上的API调用延迟与稳定性表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 实测Taotoken在低功耗arm7设备上的API调用延迟与稳定性表现 1. 测试背景与目的 在边缘计算或资源受限的嵌入式场景中,…...
)
Zynq MPSoC实战:从官方Base TRD里,只抠出HDMI输入+DP显示这一个功能(Vivado 2020.1 + Petalinux)
Zynq MPSoC实战:精准剥离HDMI输入与DP显示功能的工程精简指南 面对Xilinx官方提供的Base TRD参考设计,许多开发者都会被其庞大的规模所震撼——12000行代码、数十个功能模块交织在一起,就像一个功能齐全但臃肿不堪的"瑞士军刀"。本…...

终极分子绘图工具Ketcher:免费在线化学结构编辑器完整指南
终极分子绘图工具Ketcher:免费在线化学结构编辑器完整指南 【免费下载链接】ketcher Web-based molecule sketcher 项目地址: https://gitcode.com/gh_mirrors/ke/ketcher 还在为复杂的化学结构绘图而烦恼吗?传统绘图工具操作繁琐、格式兼容性差、…...