大数据技术发展史
文章目录
- Google论文
- Hadoop
- Hive
- 大数据生态
Google论文
今天我们常说的大数据技术,其实起源于Google在2004年前后发表的三篇论文,也就是我们经常听到的“三驾马车”,分别是分布式文件系统GFS、大数据分布式计算框架MapReduce和NoSQL数据库系统BigTable。
你知道,搜索引擎主要就做两件事情,一个是网页抓取,一个是索引构建,而在这个过程中,有大量的数据需要存储和计算。这“三驾马车”其实就是用来解决这个问题的,你从介绍中也能看出来,一个文件系统、一个计算框架、一个数据库系统。
现在你听到分布式、大数据之类的词,肯定一点儿也不陌生。但你要知道,在2004年那会儿,整个互联网还处于懵懂时代,Google发布的论文实在是让业界为之一振,大家恍然大悟,原来还可以这么玩。
因为那个时间段,大多数公司的关注点其实还是聚焦在单机上,在思考如何提升单机的性能,寻找更贵更好的服务器。而Google的思路是部署一个大规模的服务器集群,通过分布式的方式将海量数据存储在这个集群上,然后利用集群上的所有机器进行数据计算。 这样,Google其实不需要买很多很贵的服务器,它只要把这些普通的机器组织到一起,就非常厉害了。
当时的天才程序员,也是Lucene开源项目的创始人Doug Cutting正在开发开源搜索引擎Nutch,阅读了Google的论文后,他非常兴奋,紧接着就根据论文原理初步实现了类似GFS和MapReduce的功能。
Hadoop
两年后的2006年,Doug Cutting将这些大数据相关的功能从Nutch中分离了出来,然后启动了一个独立的项目专门开发维护大数据技术,这就是后来赫赫有名的Hadoop,主要包括Hadoop分布式文件系统HDFS和大数据计算引擎MapReduce。
当我们回顾软件开发的历史,包括我们自己开发的软件,你会发现,有的软件在开发出来以后无人问津或者寥寥数人使用,这样的软件其实在所有开发出来的软件中占大多数。而有的软件则可能会开创一个行业,每年创造数百亿美元的价值,创造百万计的就业岗位,这些软件曾经是Windows、Linux、Java,而现在这个名单要加上Hadoop的名字。
如果有时间,你可以简单浏览下Hadoop的代码,这个纯用Java编写的软件其实并没有什么高深的技术难点,使用的也都是一些最基础的编程技巧,也没有什么出奇之处,但是它却给社会带来巨大的影响,甚至带动一场深刻的科技革命,推动了人工智能的发展与进步。
我觉得,我们在做软件开发的时候,也可以多思考一下,我们所开发软件的价值点在哪里?真正需要使用软件实现价值的地方在哪里?你应该关注业务、理解业务,有价值导向,用自己的技术为公司创造真正的价值,进而实现自己的人生价值。而不是整天埋头在需求说明文档里,做一个没有思考的代码机器人。
Hadoop发布之后,Yahoo很快就用了起来。大概又过了一年到了2007年,百度和阿里巴巴也开始使用Hadoop进行大数据存储与计算。
2008年,Hadoop正式成为Apache的顶级项目,后来Doug Cutting本人也成为了Apache基金会的主席。自此,Hadoop作为软件开发领域的一颗明星冉冉升起。
同年,专门运营Hadoop的商业公司Cloudera成立,Hadoop得到进一步的商业支持。
Hive
这个时候,Yahoo的一些人觉得用MapReduce进行大数据编程太麻烦了,于是便开发了Pig。Pig是一种脚本语言,使用类SQL的语法,开发者可以用Pig脚本描述要对大数据集上进行的操作,Pig经过编译后会生成MapReduce程序,然后在Hadoop上运行。
编写Pig脚本虽然比直接MapReduce编程容易,但是依然需要学习新的脚本语法。于是Facebook又发布了Hive。Hive支持使用SQL语法来进行大数据计算,比如说你可以写个Select语句进行数据查询,然后Hive会把SQL语句转化成MapReduce的计算程序。
这样,熟悉数据库的数据分析师和工程师便可以无门槛地使用大数据进行数据分析和处理了。Hive出现后极大程度地降低了Hadoop的使用难度,迅速得到开发者和企业的追捧。据说,2011年的时候,Facebook大数据平台上运行的作业90%都来源于Hive。
大数据生态
随后,众多Hadoop周边产品开始出现,大数据生态体系逐渐形成,其中包括:专门将关系数据库中的数据导入导出到Hadoop平台的Sqoop;针对大规模日志进行分布式收集、聚合和传输的Flume;MapReduce工作流调度引擎Oozie等。
在Hadoop早期,MapReduce既是一个执行引擎,又是一个资源调度框架,服务器集群的资源调度管理由MapReduce自己完成。但是这样不利于资源复用,也使得MapReduce非常臃肿。于是一个新项目启动了,将MapReduce执行引擎和资源调度分离开来,这就是Yarn。
2012年,Yarn成为一个独立的项目开始运营,随后被各类大数据产品支持,成为大数据平台上最主流的资源调度系统。
同样是在2012年,UC伯克利AMP实验室(Algorithms、Machine和People的缩写)开发的Spark开始崭露头角。当时AMP实验室的马铁博士发现使用MapReduce进行机器学习计算的时候性能非常差,因为机器学习算法通常需要进行很多次的迭代计算,而MapReduce每执行一次Map和Reduce计算都需要重新启动一次作业,带来大量的无谓消耗。还有一点就是MapReduce主要使用磁盘作为存储介质,而2012年的时候,内存已经突破容量和成本限制,成为数据运行过程中主要的存储介质。Spark一经推出,立即受到业界的追捧,并逐步替代MapReduce在企业应用中的地位。
一般说来,像MapReduce、Spark这类计算框架处理的业务场景都被称作批处理计算,因为它们通常针对以“天”为单位产生的数据进行一次计算,然后得到需要的结果,这中间计算需要花费的时间大概是几十分钟甚至更长的时间。因为计算的数据是非在线得到的实时数据,而是历史数据,所以这类计算也被称为大数据离线计算。
而在大数据领域,还有另外一类应用场景,它们需要对实时产生的大量数据进行即时计算,比如对于遍布城市的监控摄像头进行人脸识别和嫌犯追踪。这类计算称为大数据流计算,相应地,有Storm、Flink、Spark Streaming等流计算框架来满足此类大数据应用的场景。 流式计算要处理的数据是实时在线产生的数据,所以这类计算也被称为大数据实时计算。
在典型的大数据的业务场景下,数据业务最通用的做法是,采用批处理的技术处理历史全量数据,采用流式计算处理实时新增数据。而像Flink这样的计算引擎,可以同时支持流式计算和批处理计算。
除了大数据批处理和流处理,NoSQL系统处理的主要也是大规模海量数据的存储与访问,所以也被归为大数据技术。 NoSQL曾经在2011年左右非常火爆,涌现出HBase、Cassandra等许多优秀的产品,其中HBase是从Hadoop中分离出来的、基于HDFS的NoSQL系统。
我们回顾软件发展的历史会发现,差不多类似功能的软件,它们出现的时间都非常接近,比如Linux和Windows都是在90年代初出现,Java开发中的各类MVC框架也基本都是同期出现,Android和iOS也是前脚后脚问世。2011年前后,各种NoSQL数据库也是层出不穷,我也是在那个时候参与开发了阿里巴巴自己的NoSQL系统。
事物发展有自己的潮流和规律,当你身处潮流之中的时候,要紧紧抓住潮流的机会,想办法脱颖而出,即使没有成功,也会更加洞悉时代的脉搏,收获珍贵的知识和经验。而如果潮流已经退去,这个时候再去往这个方向上努力,只会收获迷茫与压抑,对时代、对自己都没有什么帮助。
但是时代的浪潮犹如海滩上的浪花,总是一浪接着一浪,只要你站在海边,身处这个行业之中,下一个浪潮很快又会到来。你需要敏感而又深刻地去观察,略去那些浮躁的泡沫,抓住真正潮流的机会,奋力一搏,不管成败,都不会遗憾。
正所谓在历史前进的逻辑中前进,在时代发展的潮流中发展。通俗地说,就是要在风口中飞翔。
上面我讲的这些基本上都可以归类为大数据引擎或者大数据框架。而大数据处理的主要应用场景包括数据分析、数据挖掘与机器学习。数据分析主要使用Hive、Spark SQL等SQL引擎完成;数据挖掘与机器学习则有专门的机器学习框架TensorFlow、Mahout以及MLlib等,内置了主要的机器学习和数据挖掘算法。
此外,大数据要存入分布式文件系统(HDFS),要有序调度MapReduce和Spark作业执行,并能把执行结果写入到各个应用系统的数据库中,还需要有一个大数据平台整合所有这些大数据组件和企业应用系统。

图中的所有这些框架、平台以及相关的算法共同构成了大数据的技术体系,我将会在专栏后面逐个分析,帮你能够对大数据技术原理和应用算法构建起完整的知识体系,进可以专职从事大数据开发,退可以在自己的应用开发中更好地和大数据集成,掌控自己的项目。
结语:
从我的角度而言,不管是学习某门技术,还是讨论某个事情,最好的方式一定不是一头扎到具体细节里,而是应该从时空的角度先了解它的来龙去脉,以及它为什么会演进成为现在的状态。当你深刻理解了这些前因后果之后,再去看现状,就会明朗很多,也能更直接地看到现状背后的本质。说实话,这对于我们理解技术、学习技术而言,同等重要。
相关文章:
大数据技术发展史
文章目录 Google论文HadoopHive大数据生态 Google论文 今天我们常说的大数据技术,其实起源于Google在2004年前后发表的三篇论文,也就是我们经常听到的“三驾马车”,分别是分布式文件系统GFS、大数据分布式计算框架MapReduce和NoSQL数据库系统…...

linux常见基础指令
入门常见基础指令 ls、stat、 pwd 、cd、tree、 whoami、 touch、 mkdir、 rm 、 man、 cp、mv、cat、tac、echo、>、 >>、 < 、more、 less、 head、 tail、date、 cal、 find、 which、alias、whereis、grep、zip与unzip、 tar、bc、uname、xargs... 热键Tab、…...

“人家赚那么多”系列01:如何练习?练什么?
01 如何练习?练习什么? 今年计划重点围绕「在不骗自己的前提下,如何才能把事儿彻底做好,并做得有声有色?」为主题来写点儿东西,聊聊我是怎么做的,如何通过一些有效的方法来不断优化自己的。 想把…...

【Android】使用android studio查看内置数据库信息
要使用Android Studio查看内置数据库信息,可以按照以下步骤进行操作: 打开Android Studio并打开你的项目。 在左侧的Project窗口中,找到并展开你的app模块。 找到并展开"app" > "src" > "main"文件夹。…...

PHP开发日志 ━━ 基于PHP和JS的AES相互加密解密方法详解(CryptoJS) 适合CryptoJS4.0和PHP8.0
最近客户在做安全等保,需要后台登录密码采用加密方式,原来用个base64变形一下就算了,现在不行,一定要加密加key加盐~~ 前端使用Cypto-JS加密,传输给后端使用PHP解密,当然,前端虽然有key有盐&…...

2021-01-03 excel实现列递增,行保持不变
需求:excel文档数据操作的时候发现自动递增只能实现列不变行号递增 我这里里需要的是列递增行不变 解决方式:通过一些函数的组合使用 INDIRECT("驻场明细!"&CHAR(ROW()62)&ROW(驻场明细!A$28)) INDIRECT()函数的使用: INDI…...

[Python]两个杯子取水问题
利用两个杯子巧取三升水: 今天的这个趣味数学小游戏是利用两个没有刻度的水杯,巧妙地取出三升水来。 题目的条件是:一个总容量为6升的杯子和一个总容量为5升的杯子,同时面前有无限容量的水供你使用。不借助其它任何的容器…...

C++汇编语言学习计划
前几天买了某游戏的外挂,感觉外挂在我计算机上进行了不少操作,我想一探究竟,可是只有exe,没办法,翻译成汇编我也看不懂,索性来简单学习下。访问Chatgpt4,给了如下学习计划。 要从零开始学习C生成…...
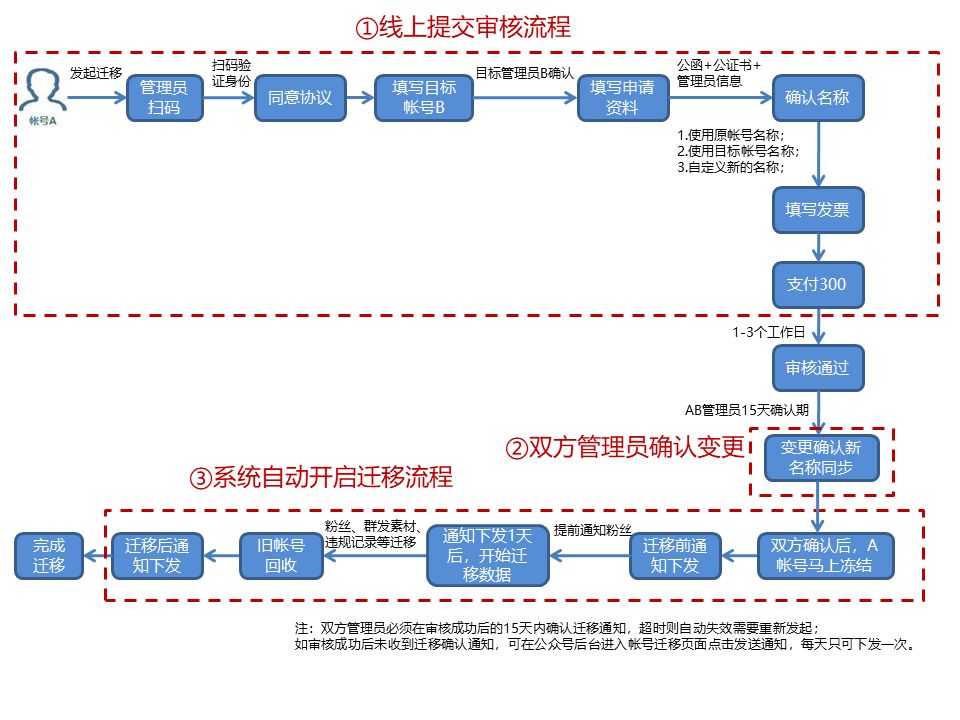
微信服务号升级订阅号条件
服务号和订阅号有什么区别?服务号转为订阅号有哪些作用?首先我们要看一下服务号和订阅号的主要区别。1、服务号推送的消息没有折叠,消息出现在聊天列表中,会像收到消息一样有提醒。而订阅号推送的消息是折叠的,“订阅号…...
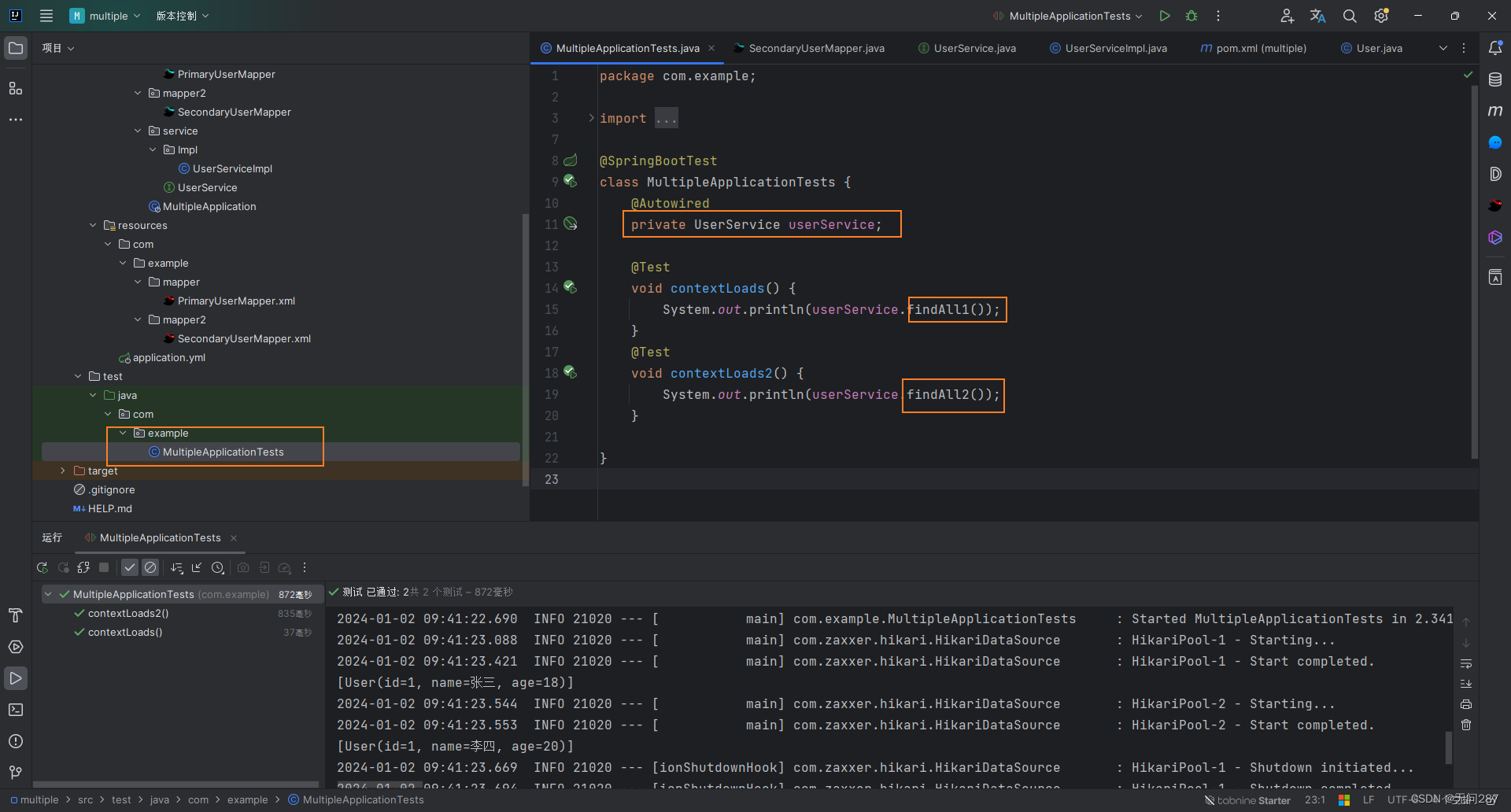
SpringBoot整合mybatis多数据源
废话不多说先上结果 对应数据库 首先导入所需的mybatis、mysql和lombok依赖 <dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.2.2</version></dependen…...
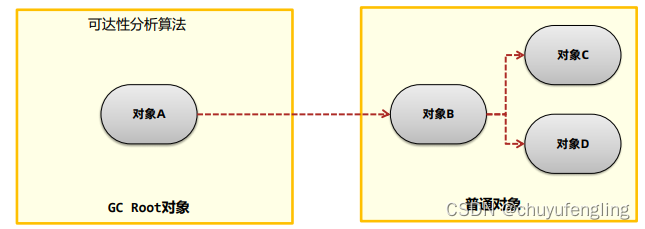
垃圾收集器与内存分配策略
内存分配和回收原则 对象优先在Eden区分配 大对象直接进入老年代 长期存活的对象进入老年代 什么是内存泄漏 不再使用的对象在系统中未被回收,内存泄漏的积累可能会导致内存溢出 自动垃圾回收与手动垃圾回收 自动垃圾回收:由虚拟机来自动回收对象…...

Python计算三角形的面积
Python 计算三角形的面积 以下实例为通过用户输入三角形三边长度,并计算三角形的面积: # 三角形第一边长 a 3 # 三角形第二边长 b 4 c float( input("输入三角形第三边长: ") ) # 计算半周长 s (a b c) / 2 # 计算…...
】万能字符单词拼写(JavaPythonC++JS实现))
198.【2023年华为OD机试真题(C卷)】万能字符单词拼写(JavaPythonC++JS实现)
🚀点击这里可直接跳转到本专栏,可查阅顶置最新的华为OD机试宝典~ 本专栏所有题目均包含优质解题思路,高质量解题代码(Java&Python&C++&JS分别实现),详细代码讲解,助你深入学习,深度掌握! 文章目录 一. 题目-万能字符单词拼写二.解题思路三.题解代码Pytho…...

Tomcat服务为什么起不来?
转载说明:如果您喜欢这篇文章并打算转载它,请私信作者取得授权。感谢您喜爱本文,请文明转载,谢谢。 服务跑在Tomcat下面,有时候会遇到Tomcat起不来的情况。目前为止常遇到的情况有如下几种: 1. Tomcat服务…...
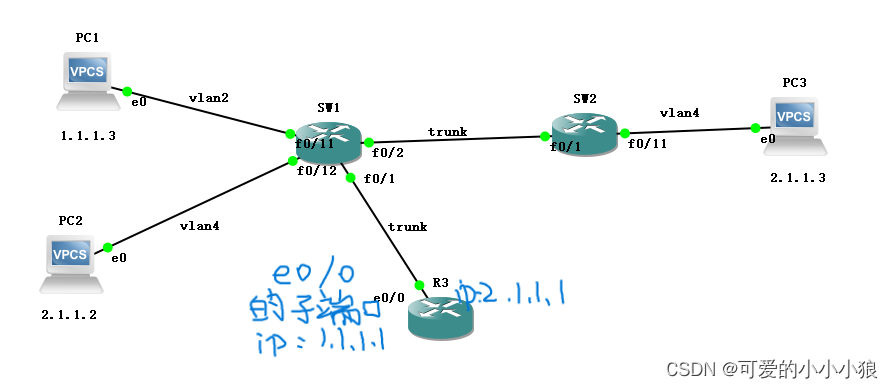
计算机网络 VLAN
路由器将多个局域网连接起来,而交换机将一个局域网里的设备连接起来。 路由器的端口分配局域网的网段(子网网段),局域网的内部设备的ip都在这个网段里,再由交换机将数据派发到目的设备,交换机是按照MAC地址…...
docker搭建Dinky —— 筑梦之路
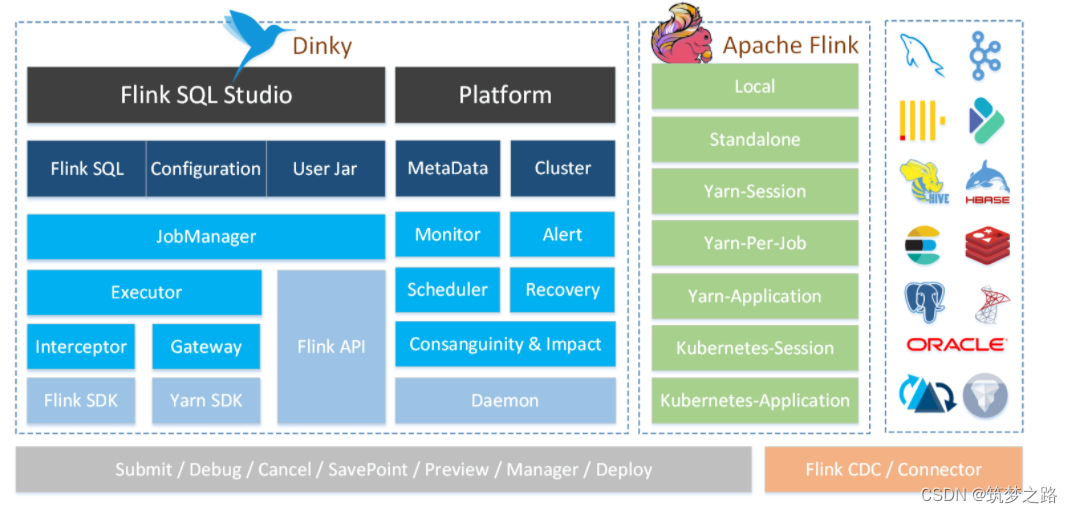
简介 Dinky 是一个 开箱即用 、易扩展 ,以 Apache Flink 为基础,连接 OLAP 和 数据湖 等众多框架的 一站式 实时计算平台,致力于 流批一体 和 湖仓一体 的探索与实践。 主要功能 其主要功能如下: 沉浸式 FlinkSQL 数据开发&#x…...
)
Python基础(十四、数据容器之集合Set)
文章目录 一、集合语法二、集合的基本操作添加元素删除元素随机删除元素,可获得删除的值清空取出2个集合的差集消除2个集合的差集合并2个集合集合元素个数查询元素是否存在 遍历集合集合的遍历 什么是数据容器? 数据容器是Python中用于存储和操作数据的对…...
OpenHarmony之HDF驱动框架
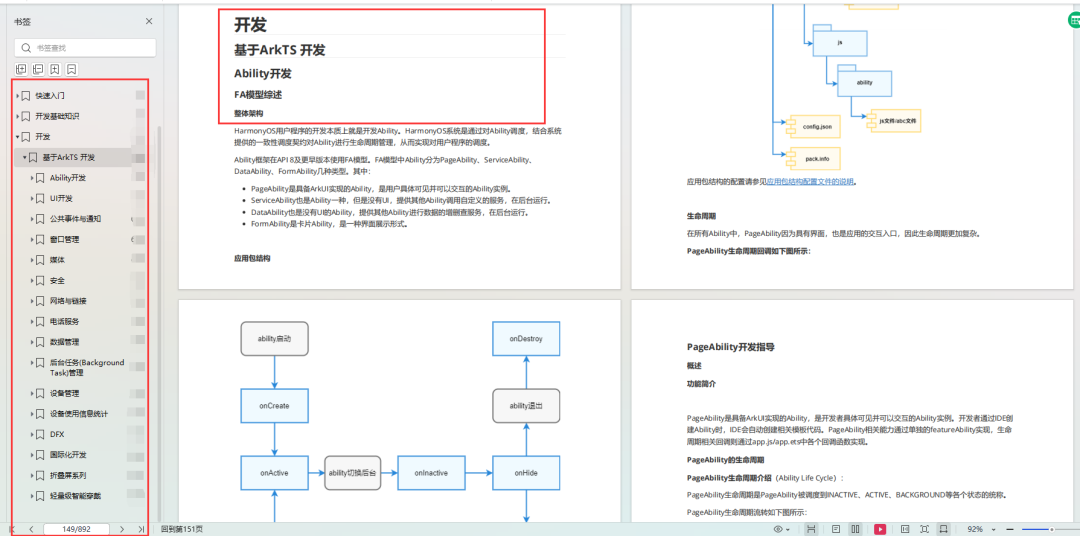
概述 HDF(Hardware Driver Foundation)驱动框架,为驱动开发者提供驱动框架能力,包括驱动加载、驱动服务管理、驱动消息机制和配置管理。并以组件化驱动模型作为核心设计思路,让驱动开发和部署更加规范,旨在…...

深入浅出理解TensorFlow的padding填充算法
一、参考资料 notes_on_padding_2 二、TensorFlow的padding算法 本文以TensorFlow v2.14.0版本为例,介绍TensorFlow的padding算法。 tf.nn.conv2d # https://github.com/tensorflow/tensorflow/blob/v2.14.0/tensorflow/python/ops/nn_ops.py#L2257-L2361paddi…...
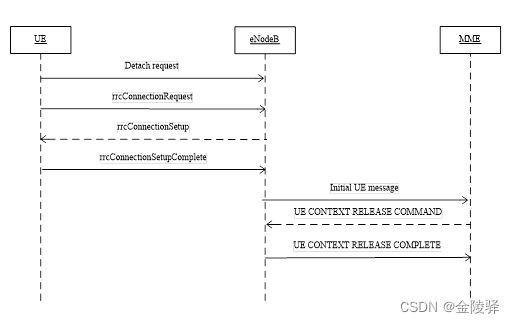
TDD-LTE 附着流程和去附着流程
目录 1. 附着流程 1.1. 正常附着流程 2. 异常附着流程 2.1 RRC建立失败 2.2 核心网拒绝 2.3 eNodeB未收到初始化上下文建立请求 2.4 RRC重配置请求丢失 2. 去附着流程 2.1 非关机去附着流程 2.1.1 连接态非关机去附着 2.1.2 空闲态非关机去附着 2.2 关机去附着流程 …...

为什么需要做GEO优化?AI新时代的商业规则探索
2026年,一个加速蔓延的商业现象正在发生:消费者不再打开搜索引擎、翻阅列表、逐条点击蓝色链接——他们直接打开DeepSeek、豆包、Kimi等AI助手,用一句完整的话发起提问:“这个价位哪个品牌最值得买?”“敏感肌用什么护…...

如何让PT下载像点外卖一样简单?3个场景教你玩转PT-Plugin-Plus
如何让PT下载像点外卖一样简单?3个场景教你玩转PT-Plugin-Plus 【免费下载链接】PT-Plugin-Plus PT 助手 Plus,为 Microsoft Edge、Google Chrome、Firefox 浏览器插件(Web Extensions),主要用于辅助下载 PT 站的种子。…...

图片重复检测革命:AntiDupl.NET如何智能清理你的数字相册
图片重复检测革命:AntiDupl.NET如何智能清理你的数字相册 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 在数字摄影普及的今天,我们每个人的硬…...

电子围栏系统设计:基于基站定位的防疫隔离技术方案解析
1. 项目概述:电子围栏系统的核心逻辑与设计初衷在2020年初那场席卷全球的公共卫生事件中,如何有效管理居家隔离人员,防止疫情在社区内扩散,成了各国政府面临的共同难题。当时,我作为技术顾问,深度参与了一些…...

1.8.1 掌握Scala类与对象 - Scala类
本次实战通过两组对比鲜明的案例,带你快速入门Scala面向对象编程的核心。首先,通过创建User类,我们掌握了Scala普通类的定义方式,了解了如何使用private修饰符封装成员变量,以及如何通过new关键字实例化对象并调用其公…...

Windows系统美化终极指南:如何快速实现个性化定制与性能优化 [特殊字符]
Windows系统美化终极指南:如何快速实现个性化定制与性能优化 🚀 【免费下载链接】Atlas 🚀 An open and lightweight modification to Windows, designed to optimize performance, privacy and usability. 项目地址: https://gitcode.com/…...

别再死记硬背公式了!用“预测-更新”的贝叶斯视角,5分钟看懂卡尔曼滤波核心
卡尔曼滤波:用贝叶斯思维解决自动驾驶中的不确定性追踪问题 想象一下你正驾驶一辆特斯拉行驶在高速公路上,车载雷达显示前方100米处有一辆卡车。但下一秒雷达数据突然跳变到105米,而摄像头却显示距离是98米。作为人类司机,你会本能…...

Nexus Machine架构:边缘计算中稀疏矩阵处理的革新
1. 项目概述:Nexus Machine架构的创新价值在边缘计算和AI推理领域,稀疏矩阵计算(如SpMSpM、SpMV)和图形处理(如BFS、PageRank)等不规则工作负载正面临严峻的性能瓶颈。传统CGRA(Coarse-Grained …...

3步解锁Cursor AI编程助手完整功能:多账户管理与设备重置终极方案
3步解锁Cursor AI编程助手完整功能:多账户管理与设备重置终极方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reach…...

PyCharm专业版SSH远程开发环境一站式部署指南
1. PyCharm专业版安装与激活 作为数据科学和算法开发的主力工具,PyCharm专业版提供了完整的远程开发支持。首先需要从JetBrains官网下载对应操作系统的安装包。这里有个小技巧:如果你使用的是Windows系统但需要连接Linux服务器开发,建议选择W…...