Transformer梳理与总结
其实transformer的成功也是源于对注意力机制的应用,其本质上还是可以归因于注意力机制,首先我们先来了解一下什么是注意力机制。在注意力机制的背景下,自主性提示被称为查询(query),给定任何查询,注意力机制通过注意力汇聚(attention pooling) 将选择引导至感官输入(sensory inputs,例如中间特征表示)

通过给定的查询,与键值进行计算,得到不同的注意力权重,这里注意力汇聚操作是得到由查询和键值计算出的权重先进行加权 然后再求和 ,得到加权平均值,根据加权方式的不同又可以分为非参注意力汇聚和带参注意力汇聚
非参数注意力汇聚(Nadaraya-Watson kernel regression)
x是查询, ( x i , y i ) (x_i,y_i) (xi,yi)是键值对,将查询x和键值对建模为注意力权重(attention weight),那么注意力汇聚操作就是对 y i y_i yi的加权平均
α ( x , x i ) = = > f ( x ) = ∑ i = 1 n K ( x − x i ) ∑ j = 1 n K ( x − x j ) y i , \alpha(x,x_i) ==>f(x)=\sum_{i=1}^n\frac{K(x-x_i)}{\sum_{j=1}^nK(x-x_j)}y_i, α(x,xi)==>f(x)=i=1∑n∑j=1nK(x−xj)K(x−xi)yi,
f ( x ) = ∑ i = 1 n α ( x , x i ) y i , f(x)=\sum_{i=1}^n\alpha(x,x_i)y_i, f(x)=i=1∑nα(x,xi)yi,
为了便于理解,可以借鉴这个高斯核的例子

带参数注意力汇聚
从上述高斯核的例子出发,在计算查询x和键值x_i之间的距离时,加入权重参数
f ( x ) = ∑ i = 1 n α ( x , x i ) y i = ∑ i = 1 n exp ( − 1 2 ( ( x − x i ) w ) 2 ) ∑ j = 1 n exp ( − 1 2 ( ( x − x j ) w ) 2 ) y i = ∑ i = 1 n softmax ( − 1 2 ( ( x − x i ) w ) 2 ) y i . \begin{aligned} f(x)& =\sum_{i=1}^n\alpha(x,x_i)y_i \\ &=\sum_{i=1}^n\frac{\exp\left(-\frac12((x-x_i)w)^2\right)}{\sum_{j=1}^n\exp\left(-\frac12((x-x_j)w)^2\right)}y_i \\ &=\sum_{i=1}^n\text{softmax}\left(-\frac12((x-x_i)w)^2\right)y_i. \end{aligned} f(x)=i=1∑nα(x,xi)yi=i=1∑n∑j=1nexp(−21((x−xj)w)2)exp(−21((x−xi)w)2)yi=i=1∑nsoftmax(−21((x−xi)w)2)yi.
注意力评分函数
其实刚才讲的是两种注意力汇聚的方式,也就是说算一下查询值和键值之间的相似性,然后加权到y上。这里讲注意力汇聚的计算又进行了细化,通过softmax得到概率值之后再加权到值上,最终得到输出。注意力评分函数也就是研究怎么评判键值和查询值之间的相关性

加性注意力(additive attention)
当查询和键是不同长度的矢量时(masked-softmax),可以使用加性注意力作为评分函数
a ( q , k ) = w v ⊤ t a n h ( W q q + W k k ) ∈ R , a(\mathbf{q},\mathbf{k})=\mathbf{w}_v^\top\mathrm{tanh}(\mathbf{W}_q\mathbf{q}+\mathbf{W}_k\mathbf{k})\in\mathbb{R}, a(q,k)=wv⊤tanh(Wqq+Wkk)∈R,
将查询和键连结起来后输入到一个多层感知机(MLP)中, 感知机包含一个隐藏层,其隐藏单元数是一个超参数h,通过使用tanh作为激活函数,并且禁用偏置项
缩放点积注意力(scaled dot-product attention)
点积操作要求查询和键具有相同的长度,假设查询和键的所有元素都是独立的随机变量, 并且都满足零均值和单位方差,其评价函数为
a ( q , k ) = q ⊤ k / d . a(\mathbf{q},\mathbf{k})=\mathbf{q}^\top\mathbf{k}/\sqrt d. a(q,k)=q⊤k/d.
多头注意力
多头也就是说,独立学习多组注意力结果,然后再汇聚起来,相当于说,增加多样性,从多个角度看问题

h i = f ( W i ( q ) q , W i ( k ) k , W i ( v ) v ) ∈ R p v , \mathbf{h}_i=f(\mathbf{W}_i^{(q)}\mathbf{q},\mathbf{W}_i^{(k)}\mathbf{k},\mathbf{W}_i^{(v)}\mathbf{v})\in\mathbb{R}^{p_v}, hi=f(Wi(q)q,Wi(k)k,Wi(v)v)∈Rpv,
W o [ h 1 ⋮ h h ] ∈ R p o . \mathbf{W}_o\begin{bmatrix}\mathbf{h}_1\\\vdots\\\mathbf{h}_h\end{bmatrix}\in\mathbb{R}^{p_o}. Wo h1⋮hh ∈Rpo.
如上式所示,给定一组qkv 就可以得到一个注意力结果h,且每个qkv都由权重w来决定,最后在汇聚时,也要乘以权重w,这些权重都是可学习参数
自注意力和位置编码
我觉得这事其实很简单,自注意力也就是说,q k v 均有x乘以权重得到,然后使用上述的注意力汇聚机制进行计算

Transformer
Transformer其实就是在完全基于注意力机制的基础上,构建了一个编码器-解码器架构

每层都使用了残差连接,这里使用的layer normalization(关于为什么不适用batch normalizetion(13分钟)),之后添加了一个FFN层,等价于两层核窗口为1的一维卷积层。之后编码器的输出作为解码器种多头注意力的V(值)和K(键),而q呢,则是通过mask-attention逐个输入进来,mask机制让其只考虑要预测位置之前所有位置的特征值
VIT
VIT证明了模型越大效果越好,成为了transformer在CV领域应用的里程碑著作,当拥有足够多的数据进行预训练的时候,ViT的表现就会超过CNN
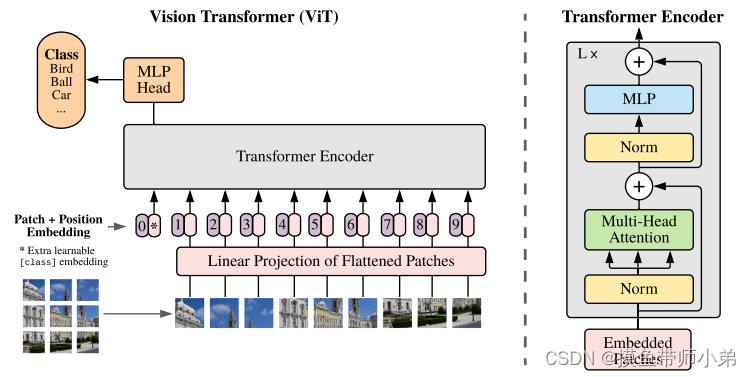
从上图可以看出,这个网络只有编码模块,并没有解码模块,通过多层编码之后,接一个MLP用于分类任务,作者只在论文中,证明了VIT可以在分类任务上,有很好的效果,对于分割、检测等其他任务,作者没有验证。
DETR
将transformers运用到了object detection领域,并且取代了非极大值抑制、anchor generation

作者首先通过CNN作为backbone 进行image embeding,然后再通过一个transformer 的encoder-decoder结构,之后通过FFN层预测目标位置,作者提出一张图中预测100个框,由于不做nms,作者采用的是匈牙利算法,进行最优匹配,每个true anchor都从这个100个预测结果中匹配到一个最优的预测,然后再进行后续损失的计算
MoCo
这篇文章是基于对比学习机制,首先介绍一下对比学习

x i x_i xi属于正样本,其余的都属于负样本,上面画的 x i x_i xi通过 T 1 T_1 T1进行特征提取得到的是正样本,称为anchor,这里也作为q,通过 T 2 T_2 T2进行特征提取的作为 x i x_i xi的一个正样本,因为正样本和负样本都是相对于anchor来说的,因此其余的负样本也应该经过 T 2 T_2 T2进行特征提取,作为k
字典里面的K值都应该由相同或者相似的编码器得到,这里作者就提出了动量对比学习的概念。同时为了避免字典过大,作者讲数据结构中队列的思想应用进来,新的batch数据进来时,之前的数据就丢出去
作者选用个体判别的方法作为代理任务去训练整个网络,然后再将其迁移到分类任务中
待梳理
Transformer从数学中解读 https://www.bilibili.com/video/BV1ea4y197dH/?spm_id_from=333.1007.tianma.1-1-1.click&vd_source=aabedda8f33d60215e3856e026901625
零基础多图详解图神经网络 https://www.bilibili.com/video/BV1iT4y1d7zP/?spm_id_from=333.999.0.0&vd_source=aabedda8f33d60215e3856e026901625
SWIN Transformer https://www.bilibili.com/video/BV13L4y1475U/?spm_id_from=333.999.0.0&vd_source=aabedda8f33d60215e3856e026901625
迁移学习 https://www.bilibili.com/video/BV1X8411f7q1/?spm_id_from=333.999.0.0&vd_source=aabedda8f33d60215e3856e026901625
RT-Detr https://www.bilibili.com/video/BV1Nb4y1F7k9/?spm_id_from=333.1007.tianma.1-1-1.click&vd_source=aabedda8f33d60215e3856e026901625
MAP评价函数
RESnest 分散注意力网络
Mamba
大核CNN
参考资料
- 动手深度学习 https://zh-v2.d2l.ai/chapter_attention-mechanisms/attention-cues.html
相关文章:
Transformer梳理与总结
其实transformer的成功也是源于对注意力机制的应用,其本质上还是可以归因于注意力机制,首先我们先来了解一下什么是注意力机制。在注意力机制的背景下,自主性提示被称为查询(query),给定任何查询,注意力机制…...

php之 校验多个时间段是否重复
参考网址 https://www.kancloud.cn/xiaobaoxuetp/mywork/3069416 https://segmentfault.com/a/1190000020487996 PHP判断多个时间段是否存在跨天或重复叠加的场景 /*** PHP计算两个时间段是否有交集(边界重叠不算)** param string $beginTime1 开始时间…...
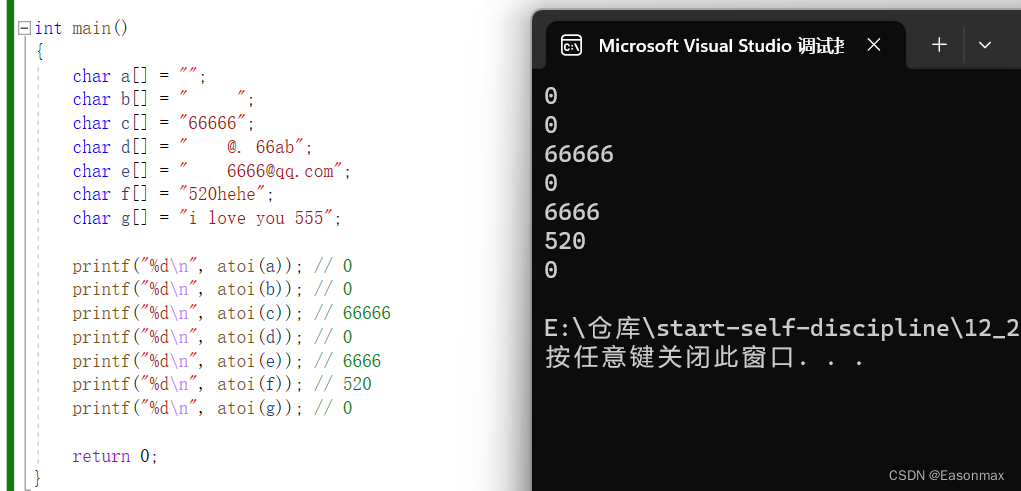
atoi函数的模拟实现
这里强力推荐一篇文章 http://t.csdnimg.cn/kWuAm 详细解析了atoi函数以及其模拟实现,我这里就不说了。 这里作者先把自己模拟的代码给大家看一下。 int add(char* arr) {char* arr2 arr;while (*arr!-48){arr;}arr--;int sum 0;int n 0;while (arr ! (arr2-…...

编程笔记 html5cssjs 009 HTML链接
编程笔记 html5&css&js 009 HTML链接 一、HTML 链接二、文本链接三、图片链接四、HTML 链接- id 属性五、锚点链接六、HTML 链接 - target 属性七、属性downloadhrefpingreferrerpolicyreltargettype 八、操作小结 网页有了链接,就可根据需要进行跳转。纸质…...

Vue实现导出Excel表格,提示“文件已损坏,无法打开”的解决方法
一、vue实现导出excel 1、前端实现 xlsx是一个用于读取、解析和写入Excel文件的JavaScript库。它提供了一系列的API来处理Excel文件。使用该库,你可以将数据转换为Excel文件并下载到本地。这种方法适用于在前端直接生成Excel文件的场景。 安装xlsx依赖 npm inst…...

分发糖果,Java经典算法编程实战。
🏆作者简介,普修罗双战士,一直追求不断学习和成长,在技术的道路上持续探索和实践。 🏆多年互联网行业从业经验,历任核心研发工程师,项目技术负责人。 🎉欢迎 👍点赞✍评论…...
鸿蒙原生应用再添新丁!中国移动 入局鸿蒙
鸿蒙原生应用再添新丁!中国移动 入局鸿蒙 来自 HarmonyOS 微博1月2日消息,#中国移动APP启动鸿蒙原生应用开发#,拥有超3亿用户的中国移动APP宣布,正式基于HarmonyOS NEXT启动#鸿蒙原生应用#及元服务开发。#HarmonyOS#系统的分布式…...

一个人能不能快速搭建一套微服务环境
一、背景 大型软件系统的开发现在往往需要多人的协助,特别是前后端分离的情况下下,分工越来越细,那么一个人是否也能快速搭建一套微服务系统呢? 答案是能的。看我是怎么操作的吧。 二、搭建过程 1、首先需要一套逆向代码生成工…...
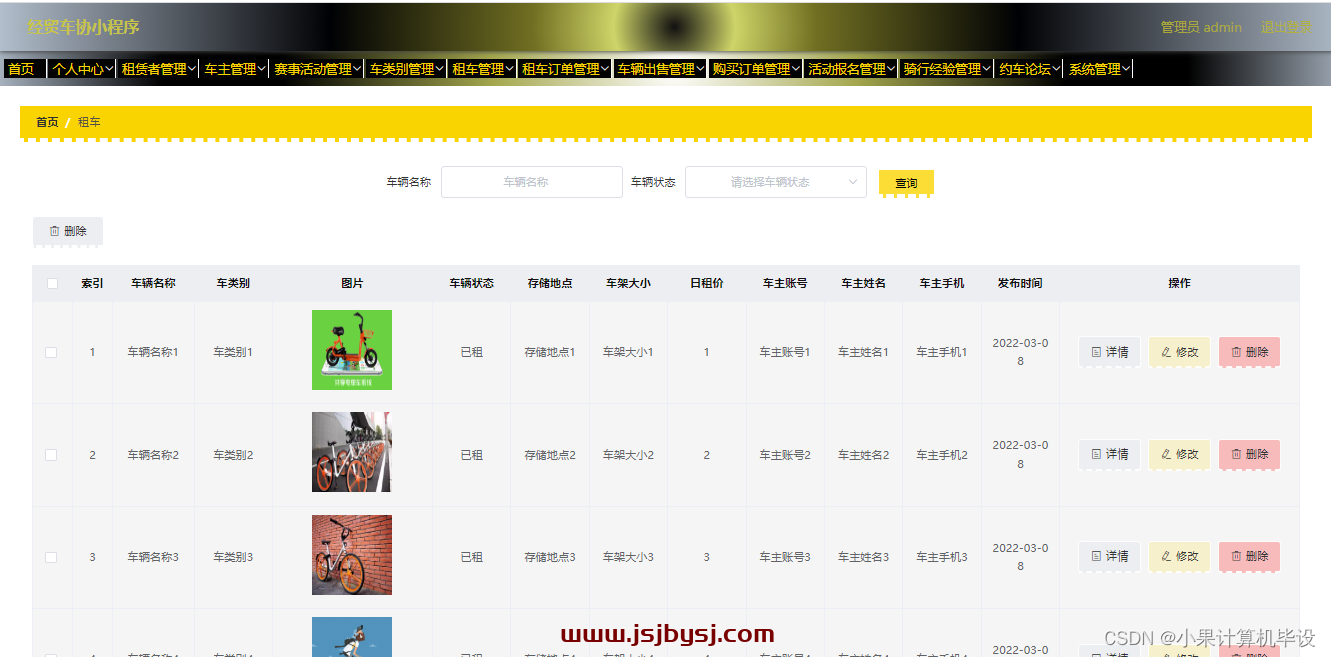
计算机毕业设计------经贸车协小程序
项目介绍 本项目分为三种用户类型,分别是租赁者,车主,管理员用户; 管理员用户包含以下功能: 管理员登录,个人中心,租赁者管理,车主管理,赛事活动管理,车类别管理,租车管理,租车订单管理,车辆出售管理,购买订单管理,…...

数据结构OJ实验11-拓扑排序与最短路径
A. DS图—图的最短路径(无框架) 题目描述 给出一个图的邻接矩阵,输入顶点v,用迪杰斯特拉算法求顶点v到其它顶点的最短路径。 输入 第一行输入t,表示有t个测试实例 第二行输入顶点数n和n个顶点信息 第三行起&…...

你的第一个JavaScript程序
JavaScript,即JS,JavaScript是一种具有函数优先的轻量级,解释型或即时编译型的编程语言。虽然它是作为开发Web页面的脚本语言而出名,但是它也被用到了很多非浏览器环境中,JavaScript基于原型编程、多范式的动态脚本语言…...
)
CMake入门教程【基础篇】列表操作(list)
文章目录 1. 定义列表2. 获取列表长度3. 获取列表元素4. 追加元素到列表末尾5. 插入元素到指定位置6. 移除指定位置的元素7. 移除指定值的元素8. 替换指定位置的元素9. 迭代列表元素 #mermaid-svg-IAjFPWI6IXEGYmuU {font-family:"trebuchet ms",verdana,arial,sans-…...

普中STM32-PZ6806L开发板(HAL库函数实现-读取内部温度)
简介 主芯片STM32F103ZET6,读取内部温度其他知识 内部温度所在ADC通道 温度计算公式 V25跟Avg_Slope值 参考文档 stm32f103ze.pdf 电压计算公式 Vout Vref * (D / 2^n) 其中Vref代表参考电压, n为ADC的位数, D为ADC输入的数字信号。 实现…...
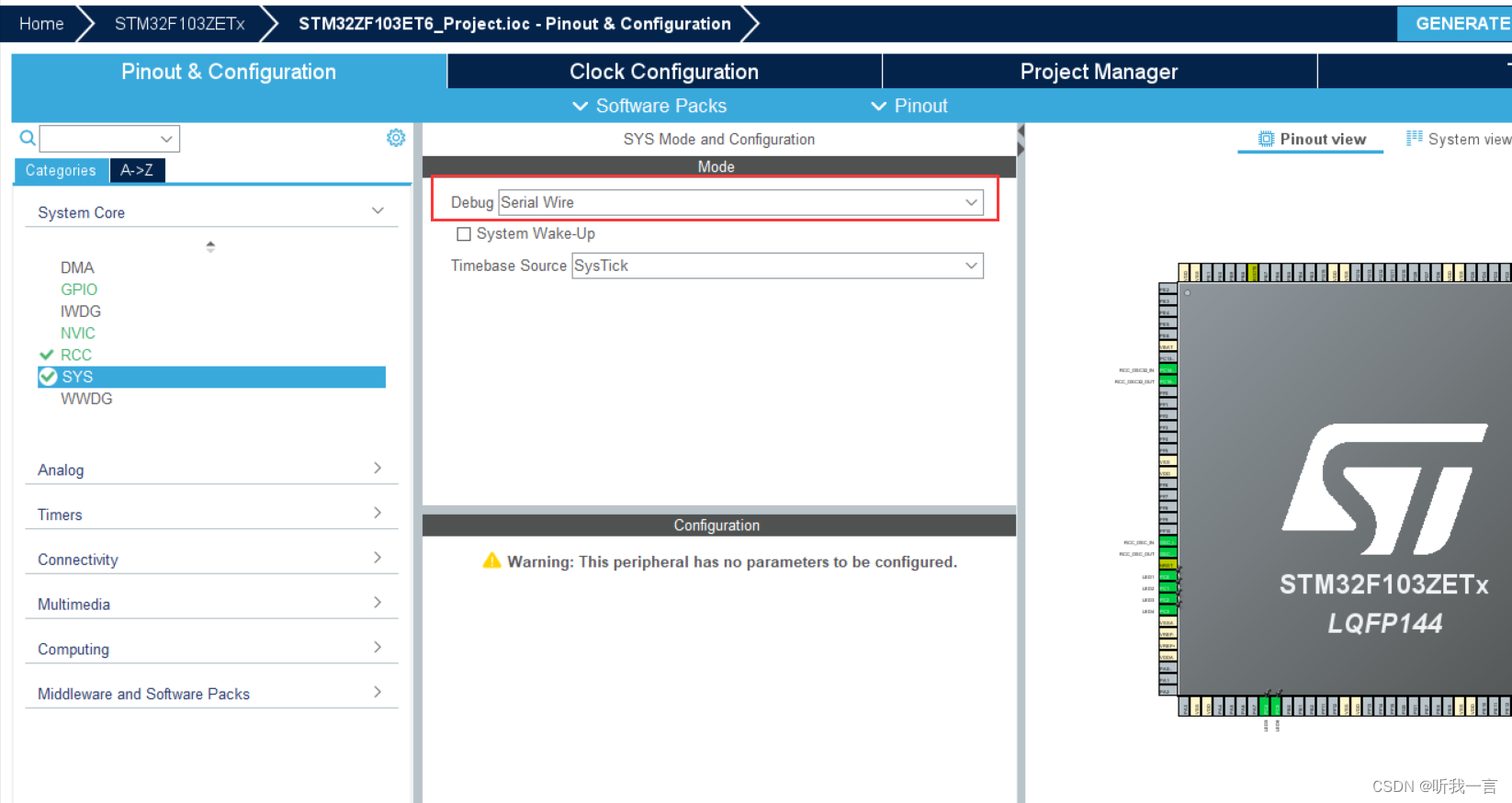
普中STM32-PZ6806L开发板(使用过程中的问题收集)
Keil使用ST-Link 报错 Internal command error 描述: 在某一次使用过程中,前面都是正常使用, Keil在烧录时报错Internal command error, 试了网上的诸多方式, 例如 升级固件;ST-Link Utility 清除;Keil升级到最新版本;甚至笔者板子的Micro头也换了,因为坏…...
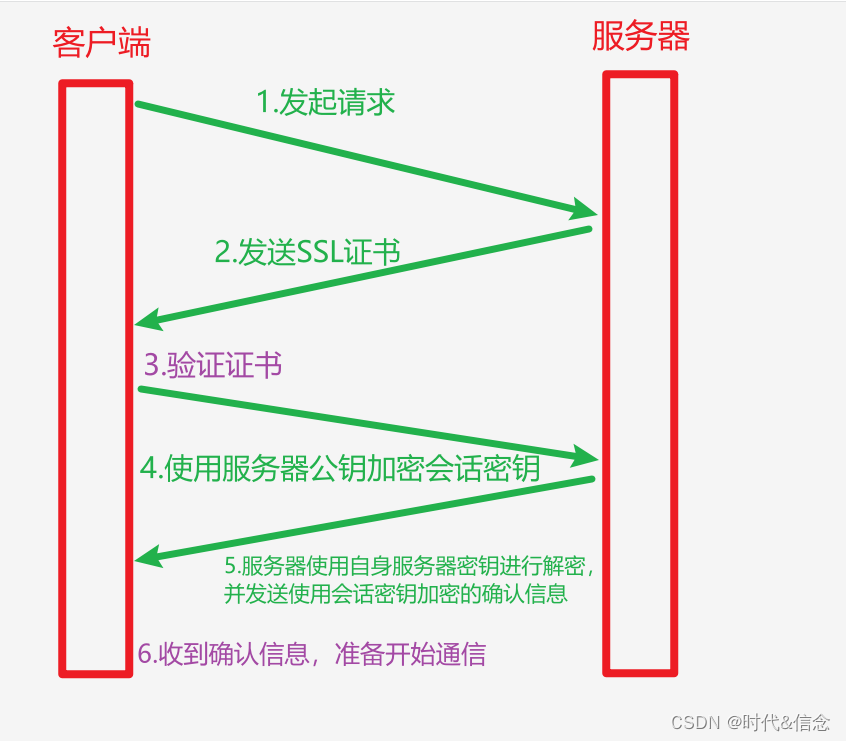
八股文打卡day12——计算机网络(12)
面试题:HTTPS的工作原理?HTTPS是怎么建立连接的? 我的回答: 1.客户端向服务器发起请求,请求建立连接。 2.服务器收到请求之后,向客户端发送其SSL证书,这个证书包含服务器的公钥和一些其他信息…...
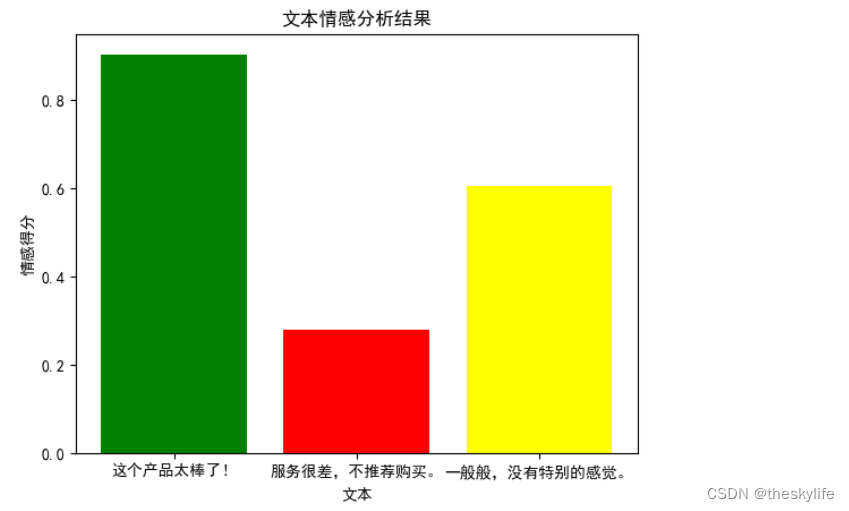
自然语言处理2——轻松入门情感分析 - Python实战指南
目录 写在开头1.了解情感分析的概念及其在实际应用中的重要性1.1 情感分析的核心概念1.1.1 情感极性1.1.2 词汇和上下文1.1.3 情感强度1.2 实际应用中的重要性 2. 使用情感分析库进行简单的情感分析2.1 TextBlob库的基本使用和优势2.1.1 安装TextBlob库2.1.2 文本情感分析示例2…...
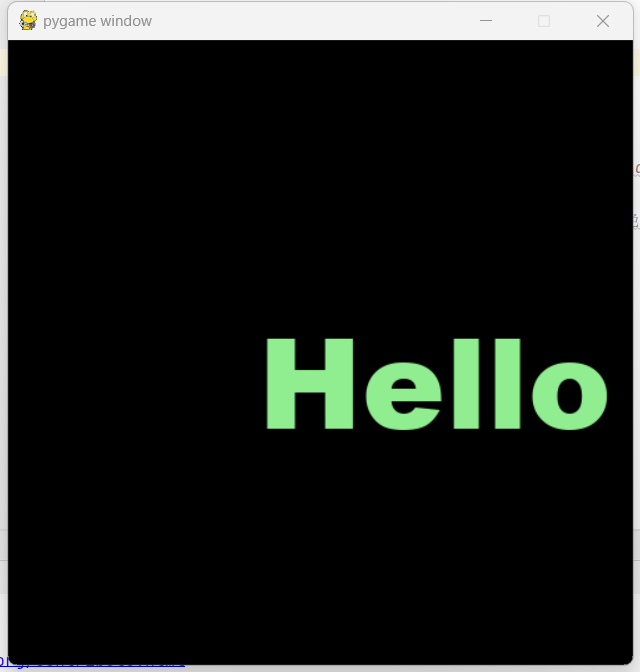
pygame学习(一)——pygame库的导包、初始化、窗口的设置、打印文字
导语 pygame是一个跨平台Python库(pygame news),专门用来开发游戏。pygame主要为开发、设计2D电子游戏而生,提供图像模块(image)、声音模块(mixer)、输入/输出(鼠标、键盘、显示屏)…...

前端面试
1. 什么是MVVM,MVC,MVP模型? 软件架构模式: MVC: M: 模型,拉取数据的类。 V: 视图,展现给用户的视觉效果。 C: 控制器,通知M拉取数据,并且给V。 > MV…...
Spring Boot快速搭建一个简易商城项目【完成登录功能且优化】
完成登录且优化: 未优化做简单的判断: 全部异常抓捕 优化:返回的是json的格式 BusinessException:所有的错误放到这个容器中,全局异常从这个类中调用 BusinessException: package com.lya.lyaspshop.exce…...
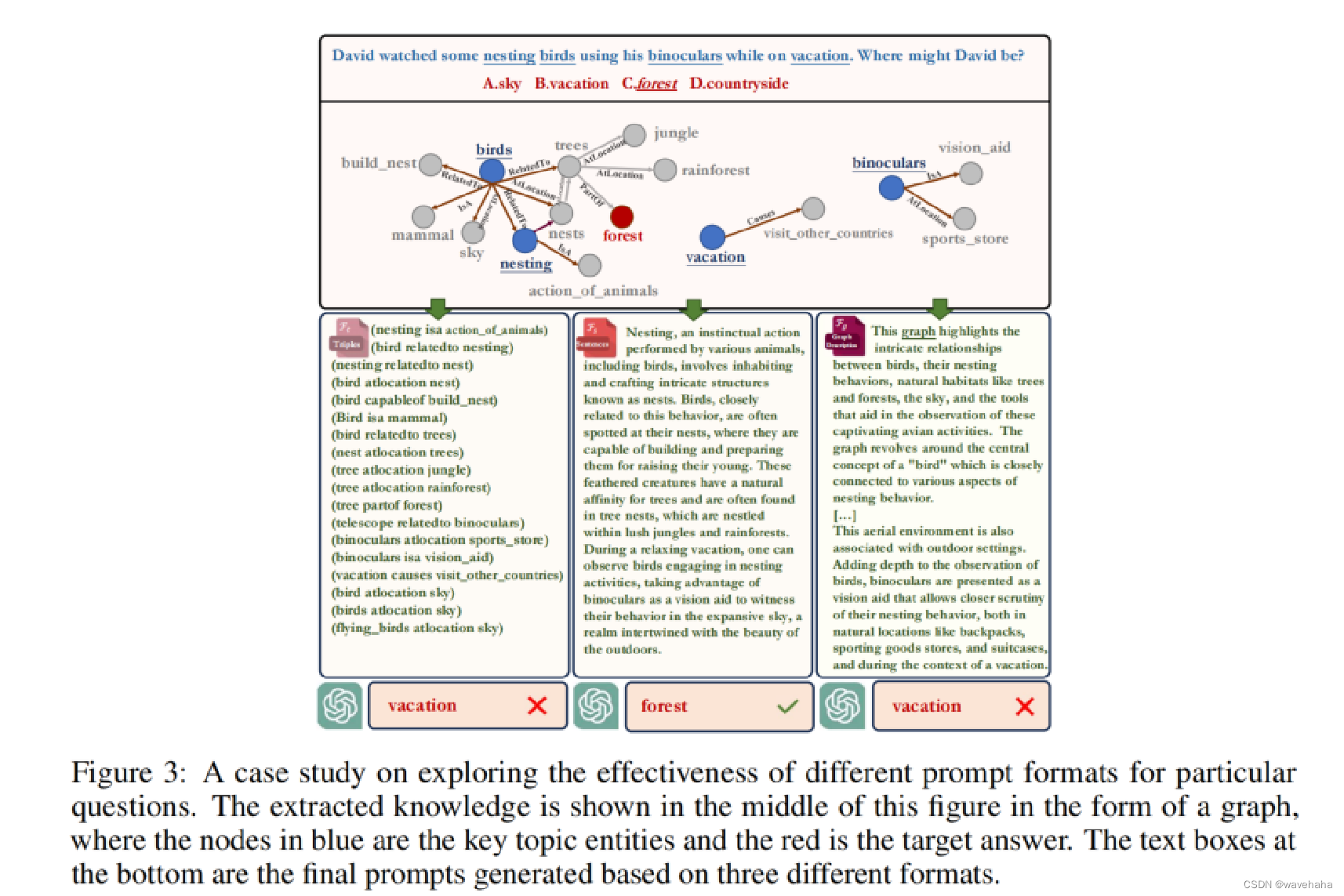
KG+LLM(一)KnowGPT: Black-Box Knowledge Injection for Large Language Models
论文链接:2023.12-https://arxiv.org/pdf/2312.06185.pdf 1.Background & Motivation 目前生成式的语言模型,如ChatGPT等在通用领域获得了巨大的成功,但在专业领域,由于缺乏相关事实性知识,LLM往往会产生不准确的…...

Markdown基础功能
原文:Markdown基础语法介绍 | Colin Gretzky的博客 本文介绍 Markdown 笔记格式的基础功能,涵盖核心语法和使用要点,适合初学者快速上手。 Markdown 简介 Markdown 是一种轻量级的标记语言,由 John Gruber 于 2004 年设计。它的核…...
)
Perplexity学术模式尚未开放的4个隐藏功能(仅限IEEE Fellow级用户测试通道泄露)
更多请点击: https://intelliparadigm.com 第一章:Perplexity学术模式尚未开放的4个隐藏功能(仅限IEEE Fellow级用户测试通道泄露) 离线语义缓存预热接口 Perplexity 内部测试版暴露了 /v2/academic/cache/warmup 端点ÿ…...
)
NOI Linux 2.0不只是竞赛工具:我用它搭建了一个轻量级C++/Python学习环境(含GUIDE、VS Code配置)
NOI Linux 2.0:从竞赛平台到全能编程学习环境的蜕变指南 当大多数人提起NOI Linux 2.0时,第一反应往往是"信息学奥赛专用系统"。但作为一个深度使用过各类Linux发行版的开发者,我发现这个官方定制系统其实是被严重低估的理想编程学…...

6.1 图表选择指南
本章学习目标: 理解数据可视化的核心目的:探索 vs 解释掌握不同分析场景对应的图表类型了解每种图表的优势和局限学会根据数据特征和分析目标选择图表核心能力:不只会画图,更知道为什么画这张图一、为什么要做数据可视化ÿ…...

收藏!小白也能入行:AI训练师是什么?值不值?怎么学?
AI冲击重复性岗位,但AI训练师需求激增347%。本文解读AI训练师(非程序员)的工作内容(数据标注、Prompt设计等)、市场数据(薪资60k、缺口百万)、适合人群(内容创作者、白领、应届生&am…...

Adobe-GenP 3.0:Adobe CC通用补丁工具终极完整指南
Adobe-GenP 3.0:Adobe CC通用补丁工具终极完整指南 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP 3.0是一款功能强大的Adobe CC通用补丁工具…...
)
别只盯着YOLOv5了!从R-CNN到DETR:手把手带你看懂目标检测算法演进史(附论文精读笔记)
从R-CNN到DETR:目标检测算法的范式革命与技术演进 当计算机视觉领域的研究者翻开2023年的顶会论文时,会发现目标检测任务已经呈现出与五年前截然不同的技术图景。这个看似"古老"的计算机视觉基础任务,正在经历着从传统卷积到Transf…...

Illustrator智能脚本终极指南:如何让设计效率提升300%
Illustrator智能脚本终极指南:如何让设计效率提升300% 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 还在为Adobe Illustrator中重复繁琐的操作而烦恼吗?想…...

基于插件化架构的OBS实时音乐信息集成系统技术解析
基于插件化架构的OBS实时音乐信息集成系统技术解析 【免费下载链接】tuna Song information plugin for obs-studio 项目地址: https://gitcode.com/gh_mirrors/tuna1/tuna Tuna是一款面向OBS Studio的高性能插件化实时音乐信息集成系统,采用模块化架构设计&…...

从零上手CircuitJS1:开源电路仿真工具的核心功能与实战演练
1. 初识CircuitJS1:浏览器里的电子实验室 第一次打开CircuitJS1时,我仿佛回到了大学电子实验室——只不过这次所有仪器都装进了浏览器窗口。这个完全开源的工具用JavaScript重构了经典的Falstad电路模拟器,不需要安装任何插件就能在Chrome或…...