后台管理项目的多数据源方案
引言
在互联网开发公司中,往往伴随着业务的快速迭代,程序员可能没有过多的时间去思考技术扩展的相关问题,长久下来导致技术过于单一。为此最近在学习互联网思维,从相对简单的功能开始做总结,比如非常常见的基础数据的后台管理,那么涉及到多数据源的情况又会有哪些问题呢?
思考1:在业务中如何更加灵活方便的切换数据源呢?
思考2:多数据源之间的事务如何保证呢?
思考3:这种多数据源的分布式事务实现思路有哪些?
本篇文章的重点,也就是多数据源问题总结为以下三种方式:
使用Spring提供的AbstractRoutingDataSource
准备工作:
首先AbstractRoutingDataSource是jdbc包提供的,需要引入依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>自定义一个类继承AbstractRoutingDataSource,重写关键方法:
@Component
@Primary
public class DynamicDatasource extends AbstractRoutingDataSource
{public static ThreadLocal<String> dataSourceName = new ThreadLocal<>();@AutowiredDataSource dataSource1;@AutowiredDataSource dataSource2;@Overrideprotected Object determineCurrentLookupKey(){return dataSourceName.get();}@Overridepublic void afterPropertiesSet(){Map<Object, Object> targetDataSources = new HashMap<>();targetDataSources.put("W", dataSource1); //写数据库,主库targetDataSources.put("R", dataSource2); //读数据库,从库super.setTargetDataSources(targetDataSources);super.setDefaultTargetDataSource(dataSource1);super.afterPropertiesSet();}
}配置多个数据源:
@Configuration
public class DataSourceConfig
{@Bean@ConfigurationProperties(prefix = "spring.datasource.datasource1")public DataSource dataSource1(){return DruidDataSourceBuilder.create().build();}@Bean@ConfigurationProperties(prefix = "spring.datasource.datasource2")public DataSource dataSource2(){return DruidDataSourceBuilder.create().build();}@Beanpublic DataSourceTransactionManager transactionManager1(DynamicDatasource dataSource){DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();dataSourceTransactionManager.setDataSource(dataSource);return dataSourceTransactionManager;}@Beanpublic DataSourceTransactionManager transactionManager2(DynamicDatasource dataSource){DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();dataSourceTransactionManager.setDataSource(dataSource);return dataSourceTransactionManager;}
}application.yml参考配置:
spring:datasource:type: com.alibaba.druid.pool.DruidDataSourcedatasource1:url: jdbc:mysql://127.0.0.1:3306/datasource1?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF8&useSSL=falseusername: rootpassword: 123666initial-size: 1min-idle: 1max-active: 20test-on-borrow: truedriver-class-name: com.mysql.cj.jdbc.Driverdatasource2:url: jdbc:mysql://127.0.0.1:3306/datasource2?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF8&useSSL=falseusername: rootpassword: 123666initial-size: 1min-idle: 1max-active: 20test-on-borrow: truedriver-class-name: com.mysql.cj.jdbc.Drivermin-idle,最小空闲连接,不会被销毁的数据库连接。注意:如果设置的太小,当客户端连接多的情况下,就需要新创建数据库连接,是一个比较耗时的操作,可能导致客户端连接超时。设置太大会占用系统资源
max-active:最大活跃数,官网建议配置:正在使用的数据库连接数 / 配置的这个值 = 85%
test-on-borrow:每次连接时都进行检查,生产上配置为true会影响性能,建议false,默认也是false
test-on-return:每次归还连接时进行检查,同样影响性能同上
生产上建议上面两个参数设置false,testWhileIdle设置为true,间隔一段时间检查连接是否可用:
空闲时间大于timeBetweenEvictionRunsMillis(默认1分钟)检查一次,检查发现连接失效也不会马上删除,而是空闲时间超过minEvictableIdleTimeMillis(最小空闲时间,默认30分钟)自动删除
maxEvictableIdleTimeMillis:最大空闲时间,默认7小时。空闲连接时间过长,数据库就会自动把连接关闭,Druid为了防止从连接池中拿到被数据库关闭的连接,设置了这个参数,超过时间强行关闭连接
使用测试:
方案一,直接在方法中设置数据源标识,简单实现功能,缺点也很明显
@Service
public class FriendServiceImpl implements FriendService
{@AutowiredFriendMapper friendMapper;@Overridepublic List<Friend> list(){DynamicDatasource.dataSourceName.set("R");return friendMapper.list();}@Overridepublic void save(Friend friend){DynamicDatasource.dataSourceName.set("W");friendMapper.save(friend);}
}方案二,使用自定义注解+AOP实现,适合不同业务的多数据源场景
// 1、自定义注解:
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface WR
{String value() default "W";
}// 2、切面配置类
@Component
@Aspect
public class DynamicDataSourceAspect
{@Before("within(com.example.dynamicdatasource.service.impl.*) && @annotation(wr)")public void before(JoinPoint joinPoint, WR wr){String value = wr.value();DynamicDatasource.dataSourceName.set(value);System.out.println(value);}
}// 3、使用注解测试
@Service
public class FriendServiceImpl implements FriendService
{@AutowiredFriendMapper friendMapper;@WR("R")@Overridepublic List<Friend> list(){
// DynamicDatasource.dataSourceName.set("R");return friendMapper.list();}@WR("W")@Overridepublic void save(Friend friend){
// DynamicDatasource.dataSourceName.set("W");friendMapper.save(friend);}
}方案三,使用MyBatis插件,适合相同业务读写分离的业务场景
import com.example.dynamicdatasource.DynamicDatasource;
import org.apache.ibatis.executor.Executor;
import org.apache.ibatis.mapping.MappedStatement;
import org.apache.ibatis.mapping.SqlCommandType;
import org.apache.ibatis.plugin.*;
import org.apache.ibatis.session.ResultHandler;
import org.apache.ibatis.session.RowBounds;
import org.springframework.stereotype.Component;import java.util.Properties;@Component
@Intercepts({@Signature(type = Executor.class, method = "update", args = {MappedStatement.class, Object.class}),@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class,ResultHandler.class})})
public class DynamicDataSourcePlugin implements Interceptor
{@Overridepublic Object intercept(Invocation invocation)throws Throwable{Object[] objects = invocation.getArgs();MappedStatement ms = (MappedStatement)objects[0];if (ms.getSqlCommandType().equals(SqlCommandType.SELECT)){DynamicDatasource.dataSourceName.set("R");}else{DynamicDatasource.dataSourceName.set("W");}return invocation.proceed();}@Overridepublic Object plugin(Object target){if (target instanceof Executor){return Plugin.wrap(target, this);}else{return target;}}@Overridepublic void setProperties(Properties properties){}
}使用MyBatis注册多个sqlSessionFactory
实现思路:Spring集成多个MyBatis框架,指定不同的扫描包、不同的数据源
准备工作:
读库和写库分别添加配置类,扫描不同的包路径:
@Configuration
@MapperScan(basePackages = "com.example.dynamicmybatis.mapper.r", sqlSessionFactoryRef = "rSqlSessionFactory")
public class RMyBatisConfig
{@Bean@ConfigurationProperties(prefix = "spring.datasource.datasource2")public DataSource dataSource2(){return DruidDataSourceBuilder.create().build();}@Beanpublic DataSourceTransactionManager rTransactionManager(){DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();dataSourceTransactionManager.setDataSource(dataSource2());return dataSourceTransactionManager;}@Beanpublic SqlSessionFactory rSqlSessionFactory()throws Exception{final SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();sqlSessionFactoryBean.setDataSource(dataSource2());return sqlSessionFactoryBean.getObject();}@Beanpublic TransactionTemplate rTransactionTemplate(){return new TransactionTemplate(rTransactionManager());}
}@Configuration
@MapperScan(basePackages = "com.example.dynamicmybatis.mapper.w", sqlSessionFactoryRef = "wSqlSessionFactory")
public class WMyBatisConfig
{@Bean@ConfigurationProperties(prefix = "spring.datasource.datasource1")public DataSource dataSource1(){return DruidDataSourceBuilder.create().build();}@Beanpublic DataSourceTransactionManager wTransactionManager(){DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();dataSourceTransactionManager.setDataSource(dataSource1());return dataSourceTransactionManager;}@Beanpublic SqlSessionFactory wSqlSessionFactory()throws Exception{final SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();sqlSessionFactoryBean.setDataSource(dataSource1());return sqlSessionFactoryBean.getObject();}@Beanpublic TransactionTemplate wTransactionTemplate(){return new TransactionTemplate(wTransactionManager());}
}写库和读库使用两个Mapper类,在不同的包下:
public interface RFriendMapper
{@Select("select * from friend")List<Friend> list();@Insert("insert into friend(name) values(#{name})")void save(Friend friend);
}public interface WFriendMapper
{@Select("select * from friend")List<Friend> list();@Insert("insert into friend(name) values(#{name})")void save(Friend friend);
}使用测试:
@Service
public class FriendServiceImpl implements FriendService
{@AutowiredRFriendMapper rFriendMapper;@AutowiredWFriendMapper wFriendMapper;@Overridepublic List<Friend> list(){return rFriendMapper.list();}@Overridepublic void save(Friend friend){wFriendMapper.save(friend);}
}思考:多数据源的事务问题
public void saveW(Friend friend)
{friend.setName("gaoW");wFriendMapper.save(friend);
}public void saveR(Friend friend)
{friend.setName("gaoR");rFriendMapper.save(friend);
}@Transactional
// @Transactional(transactionManager = "wTransactionManager")
@Override
public void saveAll(Friend friend)
{saveW(friend);saveR(friend);int a = 1 / 0;
}存在多个事务管理器的情况直接使用@Transactional注解是不行的,Spring不知道使用哪个事务管理器会报错。但是指定了事务管理器后,仅当前事务管理器负责的部分支持回滚,还是存在问题。
在特定场景下,直接指定事务管理器名称的方式可以生效(保证数据一致的意思):
@Transactional(transactionManager = "wTransactionManager")
@Override
public void saveAll(Friend friend)
{saveW(friend);saveR(friend);int a = 1 / 0;
}1、saveW方法内部异常,saveW发生异常事务不提交,数据一致
2、saveR方法内部异常,事务管理器回滚saveW的更新,saveR异常未提交,数据一致
3、saveW和saveR方法中间的业务发生异常,事务管理器回滚saveW的更新,saveR未提交,数据一致
4、saveW和saveR方法后面的业务发生异常,事务管理器回滚saveW的更新,saveR已提交,数据不一致
Spring提供的编程式事务解决方案:
@Service
public class FriendServiceImpl implements FriendService
{@AutowiredRFriendMapper rFriendMapper;@AutowiredWFriendMapper wFriendMapper;@AutowiredTransactionTemplate rTransactionTemplate;@AutowiredTransactionTemplate wTransactionTemplate;public void saveW(Friend friend){friend.setName("gaoW");wFriendMapper.save(friend);}public void saveR(Friend friend){friend.setName("gaoR");rFriendMapper.save(friend);}@Overridepublic void saveAll2(Friend friend){wTransactionTemplate.execute(wstatus -> {rTransactionTemplate.execute(rstatus -> {try{saveW(friend);saveR(friend);
// int a = 1 / 0;}catch (Exception e){e.printStackTrace();wstatus.setRollbackOnly();rstatus.setRollbackOnly();return false;}return true;});return true;});}
}Spring支持的声明式事务解决方案(分布式事务变种实现):
@Service
public class FriendServiceImpl implements FriendService
{@AutowiredRFriendMapper rFriendMapper;@AutowiredWFriendMapper wFriendMapper;@AutowiredTransactionTemplate rTransactionTemplate;@AutowiredTransactionTemplate wTransactionTemplate;@Overridepublic List<Friend> list(){return rFriendMapper.list();}@Overridepublic void save(Friend friend){wFriendMapper.save(friend);}public void saveW(Friend friend){friend.setName("gaoW");wFriendMapper.save(friend);}public void saveR(Friend friend){friend.setName("gaoR");rFriendMapper.save(friend);}@Transactional(transactionManager = "wTransactionManager")@Overridepublic void saveAll1(Friend friend){FriendService friendService = (FriendService)AopContext.currentProxy();friendService.saveAllR(friend);}@Transactional(transactionManager = "rTransactionManager")@Overridepublic void saveAllR(Friend friend){saveW(friend);saveR(friend);
// int a = 1 / 0;}
}@EnableAspectJAutoProxy(exposeProxy = true) //暴露代理对象
public class DynamicMybatisApplication {注意:调用saveAllR方式时,需要使用代理对象,直接调用本类的其他方法事务不会生效
@Autowired自动注入自己获取代理对象,这种方式在springboot2.6以后有循环依赖报错,需要改配置,按照错误提示添加配置,设置参数为true即可
上面这两种事务的解决方式适用场景:
只涉及到两三个数据源,并且多数据源事务的场景不多,同时公司又不希望引入其他组件(安全性问题考虑),那么就可以使用这种方式实现分布式事务。当然分布式事务最好的解决方案肯定是通过第三方组件比如Seata
使用dynamic-datasource框架
dynamic-datasource是属于苞米豆生态圈的
基于Springboot的多数据源组件,功能强悍,支持Seata事务
-
支持数据源分组,适用多库、读写分离、一主多从(实现了负载均衡,轮询/随机)等场景
-
提供自定义数据源方案,比如从数据库加载
-
提供项目启动后动态增加和删除数据源方案,可以添加管理后台页面灵活调整
-
提供MyBatis环境下的纯读写分离方案
-
提供本地多数据源事务方案
-
提供基于Seata的分布式事务方案,注意不能和原生spring事务混用
-
等等
多数据源实现方式:就是通过继承AbstractRoutingDataSource的这种方式
数据源切换:通过AOP+自定义注解实现的
使用示例:
@Service
public class FriendServiceImpl implements FriendService
{@AutowiredFriendMapper friendMapper;@Override@DS("slave")public List<Friend> list(){return friendMapper.list();}@Override@DS("master")@DSTransactionalpublic void save(Friend friend){friendMapper.save(friend);}@DS("master")@DSTransactionalpublic void saveAll(){// 执行多数据源的操作}
}application.yml参考配置:
spring:datasource:dynamic:#设置默认的数据源或者数据源组,默认值即为masterprimary: master#严格匹配数据源,默认false. true未匹配到指定数据源时抛异常,false使用默认数据源strict: falsedatasource:master:url: jdbc:mysql://127.0.0.1:3306/datasource1?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF8&useSSL=falseusername: rootpassword: 123666initial-size: 1min-idle: 1max-active: 20test-on-borrow: truedriver-class-name: com.mysql.cj.jdbc.Driverslave_1:url: jdbc:mysql://127.0.0.1:3306/datasource2?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF8&useSSL=falseusername: rootpassword: 123666initial-size: 1min-idle: 1max-active: 20test-on-borrow: truedriver-class-name: com.mysql.cj.jdbc.Driver相关文章:

后台管理项目的多数据源方案
引言 在互联网开发公司中,往往伴随着业务的快速迭代,程序员可能没有过多的时间去思考技术扩展的相关问题,长久下来导致技术过于单一。为此最近在学习互联网思维,从相对简单的功能开始做总结,比如非常常见的基础数据的…...

视频美颜SDK趋势畅想:未来发展方向与应用场景
当下,视频美颜SDK正不断演进,本文将深入探讨视频美颜SDK的发展趋势,探讨未来可能的方向和广泛的应用场景。 1.深度学习与视频美颜的融合 未来,我们可以期待看到更多基于深度学习算法的视频美颜SDK,为用户提供更高质量…...

C++ const 限定符的全面介绍
C const 限定符的全面介绍 1. const 修饰基本数据类型 定义 const 修饰的基本数据类型变量,值不可改变。 语法 const type variable value;特点 不可变性,增加代码可读性。 作用 定义不可修改的常量。 使用场景 全局常量、配置项。 注意事项…...

Vue 中的 ref 与 reactive:让你的应用更具响应性(上)
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...
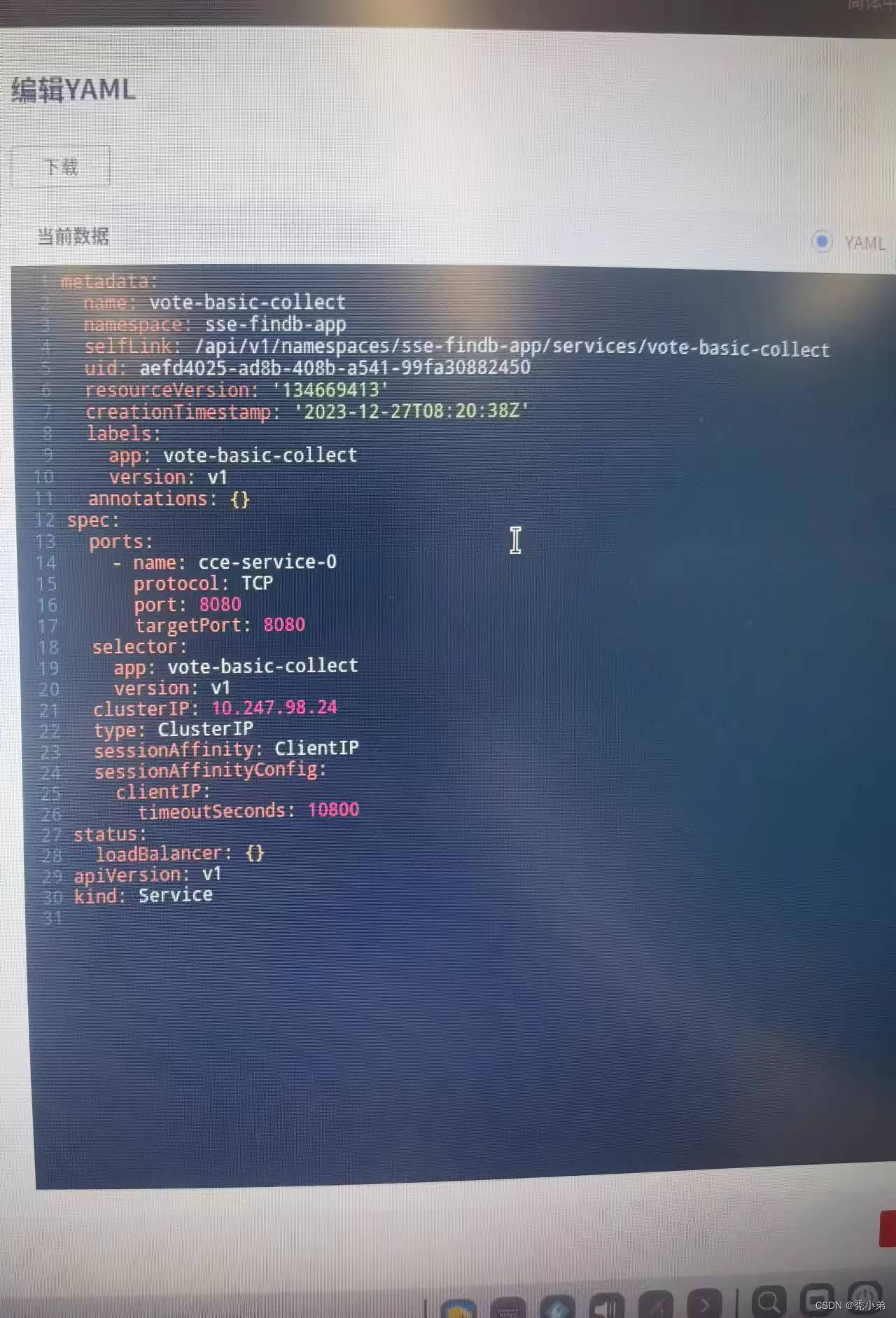
华为云CCE-集群内访问-根据ip访问同个pod
华为云CCE-集群内访问-根据ip访问同个pod 问题描述:架构如下:解决方法: 问题描述: 使用service集群内访问时,由于启用了两个pod,导致请求轮询在两个pod之间,无法返回正确的结果。 架构如下&am…...
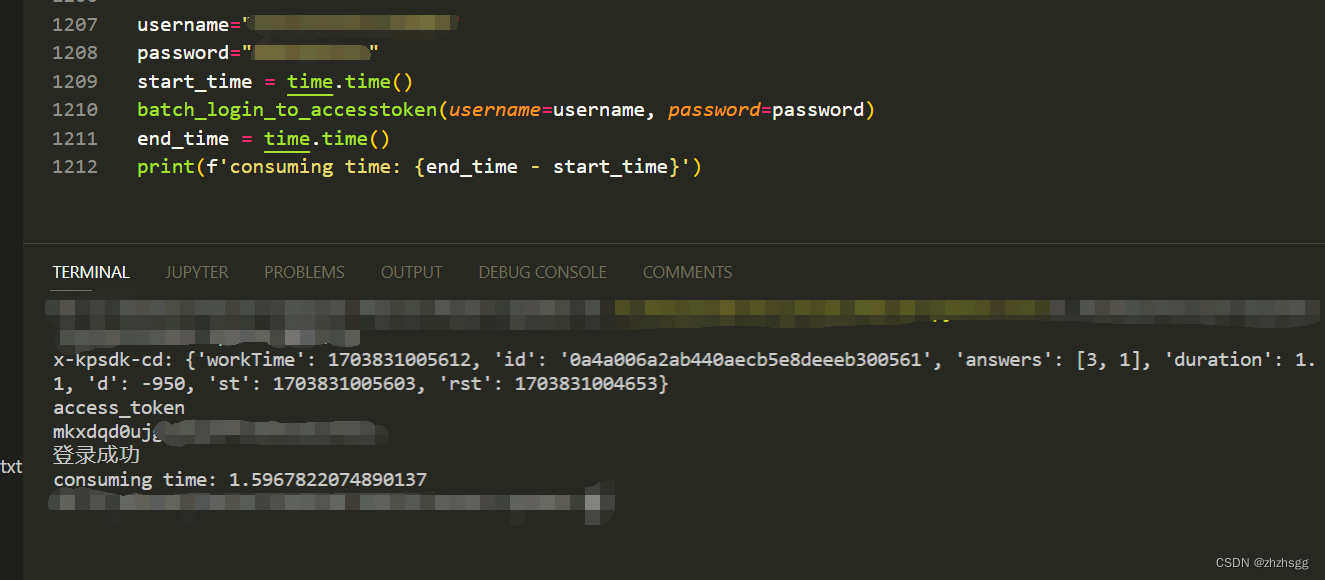
Kasada p.js (x-kpsdk-cd、x-kpsdk-ct、integrity)
提供x-kpsdk-cd的API服务 详细请私信~ 可试用~ V:zhzhsgg 一、简述 integrity是通过身份验证Kasada检测机器人流量后获得的一个检测结果(数据完整性) x-kpsdk-cd 是经过编码计算等等获得。当你得到正确的解决验证码值之后,解码会看到如下图…...

Thinkphp 5框架学习
TP框架主要是通过URL实现操作 http://servername/index.php/模块/控制器/操作/参数/值.. index.php 为入口文件,在 public 目录内的 index.php 文件; 模块在 application 目录下默认有一个 index 目录,这就是一个模块; 而在 index 目录下有一个 contro…...

麒麟云增加计算节点
一、安装基座系统并配置好各项设置 追加的计算节点服务器,安装好系统,把主机名、网络网线(网线要和其他网线插的位置一样)、hosts这些配置好,在所有节点的/etc/hosts里面添加信息 在控制节点添加/kylincloud/multinod…...

使用Redis进行搜索
文章目录 构建反向索引 构建反向索引 在Begin-End区域编写 tokenize(content) 函数,实现文本标记化的功能,具体参数与要求如下: 方法参数 content 为待标记化的文本; 文本标记的实现:使用正则表达式提取全小写化后的…...

Oracle修改用户密码
文章目录 Oracle修改用户密码Oracle用户锁定常见的两种状态Oracle用户锁定和解锁 Oracle修改用户密码 使用sys或system使用sysdba权限登录,然后执行以下命令修改密码: alter user 用户名 identified by 密码;密码过期导致的锁定,也通过修改…...

LeetCode解法汇总1276. 不浪费原料的汉堡制作方案
目录链接: 力扣编程题-解法汇总_分享记录-CSDN博客 GitHub同步刷题项目: https://github.com/September26/java-algorithms 原题链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 描述: 圣诞活动预…...

Vue解决跨域问错误:has been blocked by CORS policy 后端跨域配置
解决跨域问题后端跨域配置代码: /*** 作者 hua* 描述 跨域配置*/ Configuration public class WebConfiguration implements WebMvcConfigurer {/*** 跨域配置对象* return CorsConfiguration对象*/private CorsConfiguration corsConfig() {CorsConfiguration cor…...
【谷歌云】注册谷歌云 创建Compute Engine
文章目录 一、Google Cloud注册1.1 账号信息1.2 付款信息验证1.3 验证成功 二、Compute Engine创建2.1 启动Compute Engine API2.2 创建实例2.3 新建虚拟机实例2.4 等待实例创建完成2.5 查看虚拟机配置信息2.6 创建防火墙规则2.7 SSH远程连接虚拟机 三、参考链接 一、Google Cl…...

面试数据库八股文五问五答第四期
面试数据库八股文五问五答第四期 作者:程序员小白条,个人博客 相信看了本文后,对你的面试是有一定帮助的! ⭐点赞⭐收藏⭐不迷路!⭐ 1)什么情况下 mysql 会索引失效? 不使用索引列进行查询&a…...

2023 年中国金融级分布式数据库市场报告:TiDB 位列领导者梯队,创新能力与增长指数表现突出
近日,沙利文联合头豹研究院发布了中国数据库系列报告之《2023 年中国金融级分布式数据库市场报告》。 报告认为,金融行业对于分布式数据库信任度与认可度正在逐步提高,中国金融级分布式数据库市场正处于成熟落地的高增长阶段,行业…...

基于ExoPlayer的缓存方案实现
音视频APP 的一个必备功能就是在播放的时候会持续缓存完整个音频,同时进度条会更新缓存进度。但是目前Google推出的播放器ExoPlayer本身并没有提供什么方便的接口去实现这个功能,因此大多数的开发者可能会使用AndroidVideoCache 开源库来实现缓存。 AndroidVideoCache 的原理…...
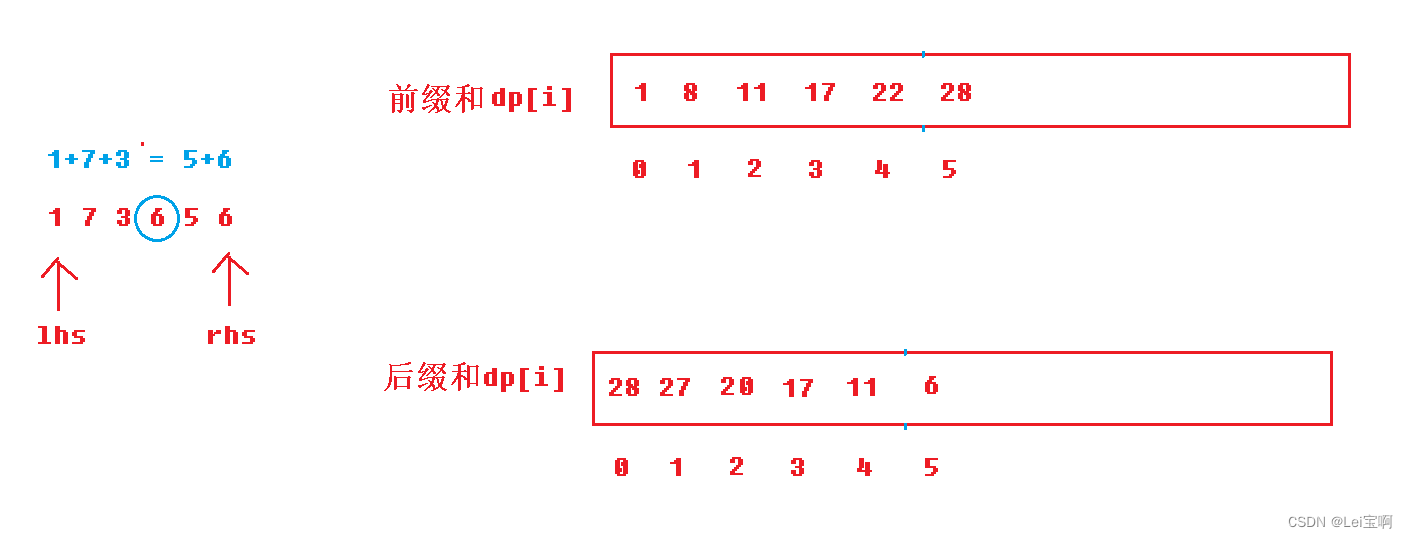
前缀和算法 -- 寻找数组的中心坐标
个人主页:Lei宝啊 愿所有美好如期而遇 本题链接 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 输入描述 给定一个数组,接口为int pivotIndex(vector<int>& nums) 输出描述 我们以示例1为例画图解释…...
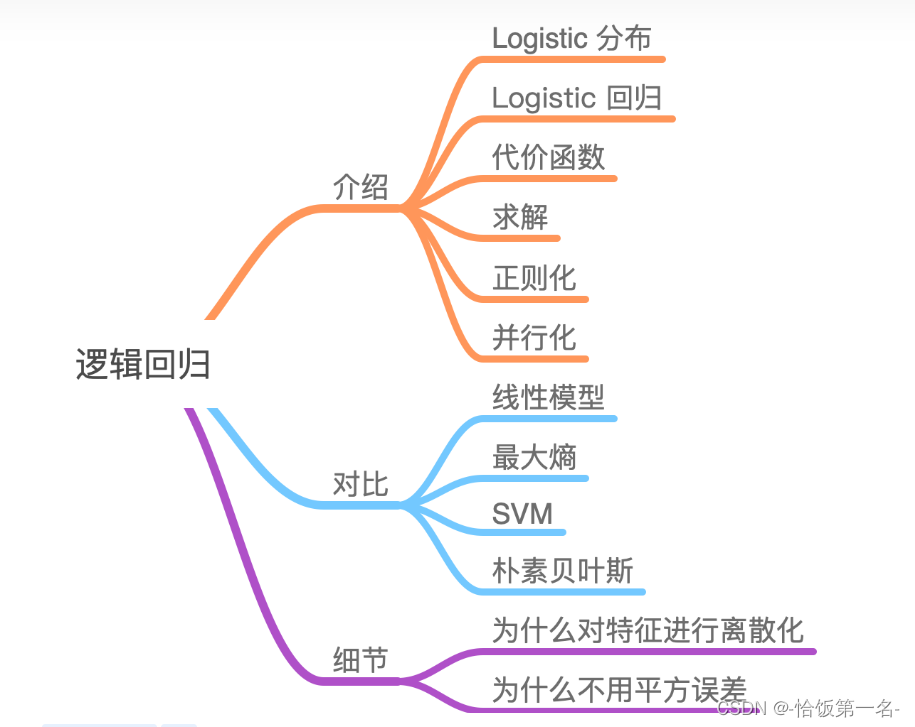
autograd与逻辑回归
一、autograd—自动求导系统 torch.autograd.backward() torch.autograd.backward()是PyTorch中用于计算梯度的函数。以下是对该函数的参数的解释: 功能:自动求取梯度 • tensors: 用于求导的张量,如 loss • retain_graph : 保存计算图 •…...

Xshell 从github克隆项目:使用ssh方式。
接上文: https://blog.csdn.net/liu834189447/article/details/135247868 是能克隆项目了,但是速度太磕碜了,磕碜到难以直视。 找到另外一种办法,使用SSH克隆项目 速度嘎嘎猛。 首先得能进得去github网站,不能点上边…...

C++:通过erase删除map的键值对
map是经常使用的数据结构,erase可以删除map中的键值对。 可以通过以下几种方式使用erase 1.通过迭代器进行删除 #include <iostream> #include <map> #include <string> using namespace std;void pMap(const string& w, const auto& m) {cout&l…...

深度解析:libiec61850开源库如何解决电力系统通信的三大核心挑战
深度解析:libiec61850开源库如何解决电力系统通信的三大核心挑战 【免费下载链接】libiec61850 Official repository for libIEC61850, the open-source library for the IEC 61850 protocols 项目地址: https://gitcode.com/gh_mirrors/li/libiec61850 在电…...

产品兼容性实战:硬件与软件设计的平衡艺术与工程策略
1. 产品兼容性:一个永恒的工程与商业困境在硬件开发,尤其是数据采集、测试测量这类领域里,产品经理和工程师们几乎每天都在面对一个看似无解的难题:新产品的功能要向前狂奔,但老用户的兼容性需求却像一根锚,…...

终极指南:轻松突破Cursor Pro限制,实现永久免费使用
终极指南:轻松突破Cursor Pro限制,实现永久免费使用 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached…...

机器视觉在人工智能领域的应用
机器视觉在人工智能领域的应用 目录机器视觉在人工智能领域的应用一、图像处理与机器视觉的概念阐述1. 图像处理(Image Processing)2. 机器视觉(Machine Vision / Computer Vision)二、图像处理与机器视觉的区别与共同点区别共同点…...

学术人必抢的实时检索红利,Perplexity这4个隐藏功能90%研究者至今未启用,错过再等半年!
更多请点击: https://intelliparadigm.com 第一章:Perplexity实时学术搜索怎么用 Perplexity 是一款面向研究者与开发者设计的实时学术搜索引擎,其核心优势在于直接对接 arXiv、PubMed、ACL Anthology、Semantic Scholar 等权威学术数据库&a…...

智能图像去重引擎:解放数字存储空间的完整解决方案
智能图像去重引擎:解放数字存储空间的完整解决方案 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 在数字内容爆炸的时代,重复图片问题已成为技…...

LeagueAkari游戏数据分析工具:从新手到高手的完整进阶攻略
LeagueAkari游戏数据分析工具:从新手到高手的完整进阶攻略 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否曾在英雄联盟游戏…...

收藏!小白程序员必看:AI时代如何从执行者变身价值创造者?
本文指出,85%的知识工作者使用AI,但仅16%真正获得突破性价值。这些"前沿专业人士"并非更会使用工具,而是懂得重新定义工作。他们通过保持核心技能敏锐度、判断AI输出质量、构建人机协作系统等方式,创造80%的新价值。文章…...

AI小白必看:手把手教你开发大模型智能体,附收藏指南!
本文深入解析AI Agent(智能体)的核心概念与技术架构,通过实战案例展示如何使用LangChain等工具开发智能客服Agent。文章涵盖自主任务拆解、工具调用、多轮交互等关键点,并分享避免“模型幻觉”的实践技巧及性能优化方法。适合程序…...

私有云时代来临:AI NAS如何重塑你的数字生活?
超越传统存储,打造你的私人云端 在信息爆炸的时代,随着个人存储需求的激增和变化,以及个体对数据隐私和安全性的日益重视,外加AI的技术加持,一种大家也许并不熟知的存储解决方案——NAS迎来了发展机遇。 NAS是Network …...