使用python快速开发与PDF文档对话的Gemini聊天机器人

检索增强生成(Retrieval-augmented generation,RAG)使得我们可以让大型语言模型(LLMs)访问外部知识库数据(如pdf,word、text等),从而让人们可以更加方便的通过LLM来学习外部数据的知识。今天我们将利用之前学习到的RAG方法,谷歌Gemini模型和langchain框架来快速开发一个能够和pdf文件对话的机器人,之所以要选择Gemini模型是因为它的API目前是免费调用的,而OpenAI的API则是要收费的,而我没有那么多银子,所以只能选择免费的。
一、什么是检索增强生成 (Retrieval-augmented generation,RAG)?
检索增强生成 (RAG) 是一种使用来自私有或专有数据源的信息来辅助文本生成的技术。 它将检索模型(设计用于搜索大型数据集或知识库)和生成模型(例如 大型语言模型 (LLM) ,此类模型会使用检索到的信息生成可供阅读的文本回复)结合在一起。一个基本的RAG检索过程主要包含以下这些步骤:
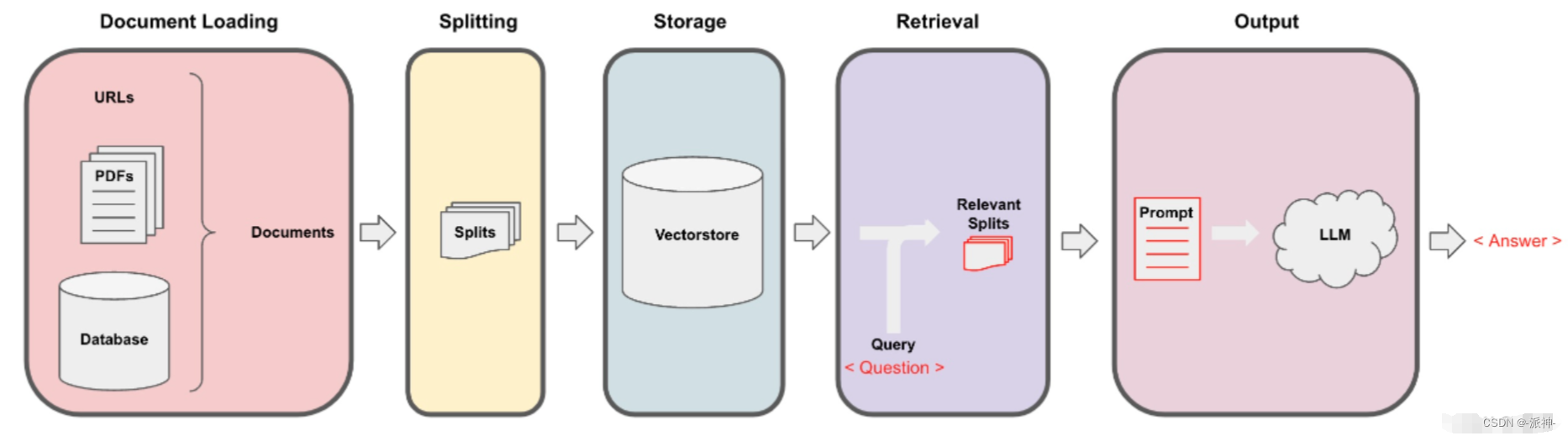
一个典型的RAG系统一般包含两个主要的部件:
- 检索器组件:根据用户问题从外部数据源(如pdf,word,text等)检索相关信息并提供给LLM 以便回答用户问题。
- 生成器组件:LLM根据检索到的相关信息,生成正确的、完整的对用户友好的答案。
我之前写过一系列的关于使用langchain与文档对话的博客,如果想详细了解RAG的基本过程可以先看一下我写的这些博客。
在本次的与PDF文档对话的系统中我们使用的检索器组件是基于Langchain框架的父文档检索器,如果对它还不熟悉朋友可以先看一下我之前写的父文档检索器这篇博客,至于生成器组件,我们使用的是基于谷歌的Gemini大模型。对于如何开发一个基于web页面的聊天机器人程序还不熟悉的朋友可以查看我之前写的使用python快速开发各种聊天机器人应用这篇博客,以便可以快速上手开发机器人应用程序。对谷歌gemini模型还不熟悉的朋友可以查看我之前写的谷歌Gemini API 应用(一):基础应用这篇博客,以便可以快速了解Gemini API的使用方法。
在本文的最后我会给大家分享完整的代码,大家可以在此基础上不断的完善代码开发出符合你们自己需求的机器人。
一,环境配置
这里我们主要使用的是panel和langchain这两个python包:
pip install google-generativeai
pip install panel
pip install langchain
pip install chroma如果在安装过程中报错,请根据报错信息安装其他必要的python包。
二、组件介绍
这里我们会使用谷歌Gemini模型组件,以及基于langchain的检索器组件,其中包括:文档分割器组件、父文档检索器组件、向量数据库组件、另外我们还需要使用python的web框架组件panel等。下面我们导入这些组件的python包:
import tempfile
import panel as pn
import param
from langchain.document_loaders import PyPDFLoader
from langchain.embeddings import HuggingFaceBgeEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.retrievers import ParentDocumentRetriever
from langchain.storage import InMemoryStore
from langchain.vectorstores import Chroma
from panel_chat_examples import EnvironmentWidgetBase
import google.generativeai as genai这里需要说明的是我们使用的LLM是谷歌原生的Gemini模型组件,而非由langchain非封装的gemini组件,之所以使用谷歌原生组件是因为我发现langchain的gemini组件存在一些bug, 它不能设置谷歌模型的安全策略,导致机器人在回答问题的时候经常会报用户问题存在安全性问题的异常,这可能是由于目前这个langchain的gemini组件还是早期版本,估计后面会完善这些问题。
三、功能模块介绍
31. Embedding模型的选择
如果对Embedding模型还不太熟悉的朋友可以查看我之前写的Embedding模型的选择这篇博客,因为本次实验使用的是中文内容的文档,所以我还是选择了BAAI的"bge-small-zh-v1.5", 如果大家使用的是英文的pdf文档则可以将Embedding模型切换为了BAAI的"bge-small-en-v1.5":
#支持中文的BAAI embedding模型
bge_embeddings = HuggingFaceBgeEmbeddings(model_name="BAAI/bge-small-zh-v1.5",cache_folder="D:\\models")这里的cache_folder指的是存放Embedding模型的文件夹,当首次执行机器人程序的时候系统会自动从HuggingFace的网站下载Embedding模型并将它存放到默认的cache_folder文件夹下(C盘),所以这里我们可以指定cache_folder文件夹的路径把Embedding模型存储在C盘以外的地方。
3.2 Gemini模型的安全策略
Gemini模型在回答用户问题的时候有一套严格的关于内容的安全审查机制,以防止出现违反道德伦理,色情暴力等内容。由于本次实验我使用的PDF文档是:"阿凡提故事大全.pdf"它是一个中文文档,当机器人在回答问题的时候不知为何经常出现内容违规的提示,这可能是由于gemini模型的默认安全审查策略的阈值设置的太高引起的,因此当我把安全审查策略的阈值调到"无"以后就不再出现违规提示了:
generation_config = {"temperature": 0.0,"top_p": 1,"top_k": 1,"max_output_tokens": 2048,
}safety_settings = [{"category": "HARM_CATEGORY_HARASSMENT","threshold": "BLOCK_NONE"},{"category": "HARM_CATEGORY_HATE_SPEECH","threshold": "BLOCK_NONE"},{"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT","threshold": "BLOCK_NONE"},{"category": "HARM_CATEGORY_DANGEROUS_CONTENT","threshold": "BLOCK_NONE"}]这里我们设置了模型参数generation_config 和安全策略参数safety_settings ,在模型参数中我们设置了temperature为0,该参数的取值范围为0-1,参数值越低,llm给出的答案越精准,参数值越高给出的答案变化性越大,因此为了让llm不要产生多样化的结果,我们应尽量调低temperature的值,设置为0或0.1都可以。另外我们将所有安全策略的阈值都设置为"BLOCK_NONE"即不做安全性审查。
3.3父文档检索器
如果对langchain的父文档检索器策略还不熟悉的朋友可以先看一下我之前写的父文档检索器这篇博客,下面是我们在panel中定义父文档检索器的一些组件:
#加载文档
@pn.cache(ttl=TTL)
def _get_docs(pdf):# load documentswith tempfile.NamedTemporaryFile("wb", delete=False) as f:f.write(pdf)file_name = f.nameloader = PyPDFLoader(file_name)docs = loader.load()return docs#创建父文档切割器
@pn.cache(ttl=TTL)
def _get_parent_splitter():return RecursiveCharacterTextSplitter(chunk_size=1000)
#创建子文档切割器
@pn.cache(ttl=TTL)
def _get_child_splitter():return RecursiveCharacterTextSplitter(chunk_size=400)
#创建内存存储组件
@pn.cache(ttl=TTL)
def _get_MemoryStore():return InMemoryStore()
#创建向量数据库
@pn.cache(ttl=TTL)
def _get_vector_db(): vectorstore = Chroma(collection_name="split_parents", embedding_function = bge_embeddings)return vectorstore
#创建父文档检索器
@pn.cache(ttl=TTL)
def _get_retriever(pdf, number_of_chunks: int):docs=_get_docs(pdf)vectorstore= _get_vector_db()store=_get_MemoryStore()child_splitter=_get_child_splitter()parent_splitter=_get_parent_splitter()#创建父文档检索器retriever = ParentDocumentRetriever(vectorstore=vectorstore,docstore=store,child_splitter=child_splitter,parent_splitter=parent_splitter,search_kwargs={"k": number_of_chunks})#添加文档集retriever.add_documents(docs)return retriever3.4创建gemini模型对象
下面是在panel中定义gemini模型对象和模型生成内容的方法:
#创建gemini模型对象
@pn.cache(ttl=TTL)
def _get_model():#创建gemini modelmodel = genai.GenerativeModel(model_name="gemini-pro",generation_config=generation_config,safety_settings=safety_settings)return modeldef _get_response(contents):retriever=_get_retriever(state.pdf, state.number_of_chunks)model=_get_model()relevant_docs=retriever.get_relevant_documents(contents)contexts='\n\n'.join([w.page_content for w in relevant_docs])#prompt模板template = f"""请根据下面给出的上下文来回答下面的问题,并给出完整的答案:
上下文:{contexts}问题: {contents}
"""response = model.generate_content(template)chunks = []for chunk in relevant_docs:name = f"Chunk {chunk.metadata['page']}"content = chunk.page_contentchunks.insert(0, (name, content))return response.text, chunks3.5创建panel页面组件
这里我们还需要创建panel的页面组件和设置环境变量等全局变量以便设置谷歌的api_key和callback函数,这里我们我们仍然使用的是panel的chat_interface作为我们的页面聊天组件,对应panel还不熟悉的朋友可以查看我之前写的使用python快速开发各种聊天机器人应用以及panel的官方文档:
# 定义应用程序全局变量
class EnvironmentWidget(EnvironmentWidgetBase):GOOGLE_API_KEY: str = param.String()class State(param.Parameterized):pdf: bytes = param.Bytes()number_of_chunks: int = param.Integer(default=2, bounds=(1, 5), step=1)environ = EnvironmentWidget()
state = State()# 定义页面组件
pdf_input = pn.widgets.FileInput.from_param(state.param.pdf, accept=".pdf", height=50)
text_input = pn.widgets.TextInput(placeholder="First, upload a PDF!")# 定义和配置 panel ChatInterface
def _get_validation_message():pdf = state.pdfgoogle_api_key = environ.GOOGLE_API_KEYif not pdf and not google_api_key:return "请在左侧侧边栏中输入谷歌api key 然后上传PDF文件!"if not pdf:return "请先上传pdf 文件"if not google_api_key:return "请先输入谷歌api key"genai.configure(api_key=google_api_key,transport='rest')return ""def _send_not_ready_message(chat_interface) -> bool:message = _get_validation_message()if message:chat_interface.send({"user": "System", "object": message}, respond=False)return bool(message)async def respond(contents, user, chat_interface):if _send_not_ready_message(chat_interface):returnif chat_interface.active == 0:chat_interface.active = 1chat_interface.active_widget.placeholder = "在这里输入您的问题!"yield {"user": "Gemini", "object": "现在可以开始和pdf对话了!"}returnresponse, documents = _get_response(contents)pages_layout = pn.Accordion(*documents, sizing_mode="stretch_width", max_width=800)answers = pn.Column(response, pages_layout)yield {"user": "Gemini", "object": answers}chat_interface = pn.chat.ChatInterface(callback=respond,sizing_mode="stretch_width",widgets=[pdf_input, text_input],disabled=True,
)@pn.depends(state.param.pdf, environ.param.GOOGLE_API_KEY, watch=True)
def _enable_chat_interface(pdf, google_api_key):if pdf and google_api_key:chat_interface.disabled = Falseelse:chat_interface.disabled = True_send_not_ready_message(chat_interface)## Wrap the app in a nice templatetemplate = pn.template.BootstrapTemplate(title="PDF文档对话机器人",sidebar=[environ,state.param.number_of_chunks],main=[chat_interface],
)
template.servable()四、机器人使用方法介绍
我们需要在命令行窗口中执行机器人的源代码程序:
panel serve gemini_pdf_bot.py
在浏览器中打开访问机器人的链接:
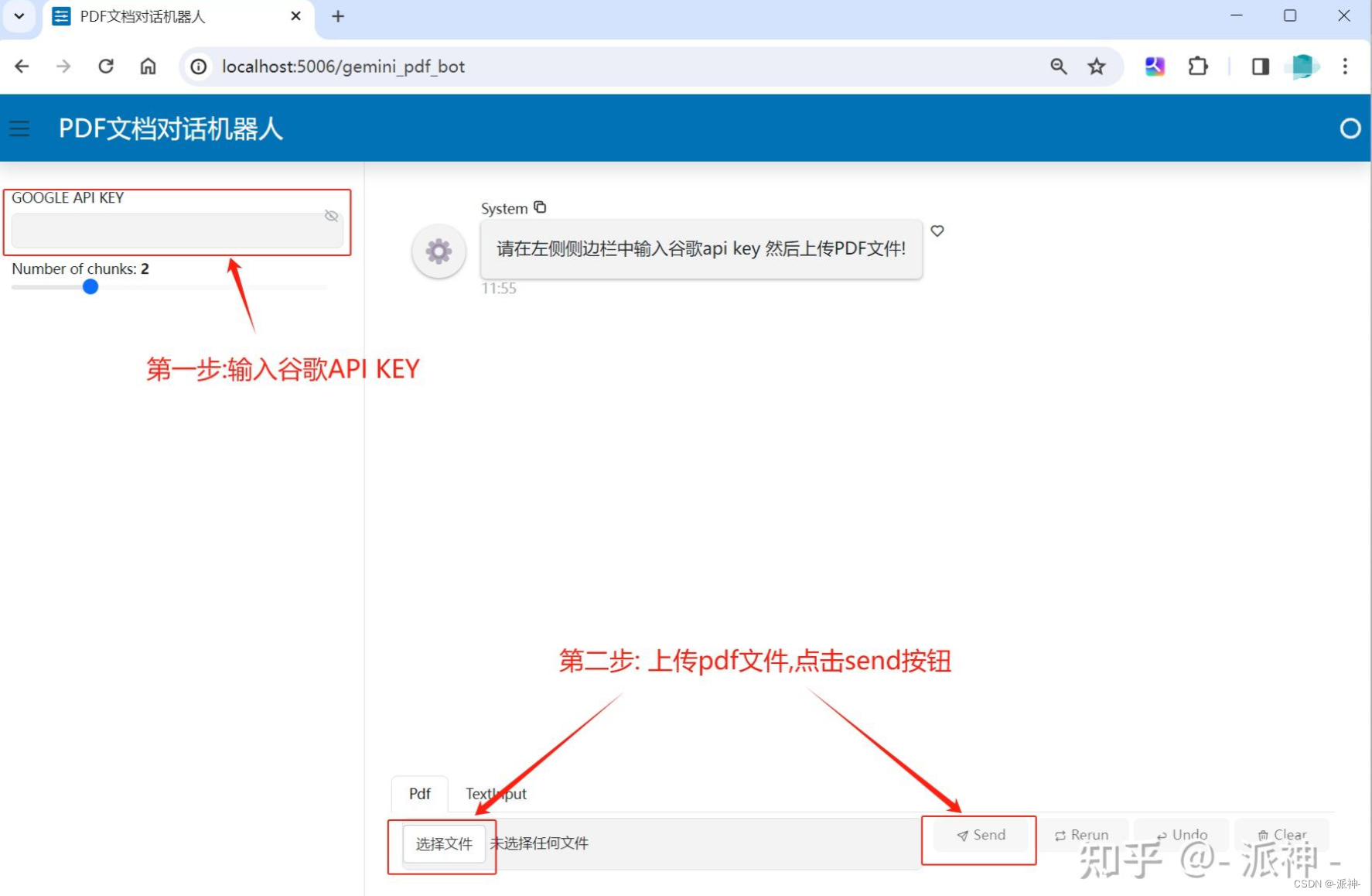
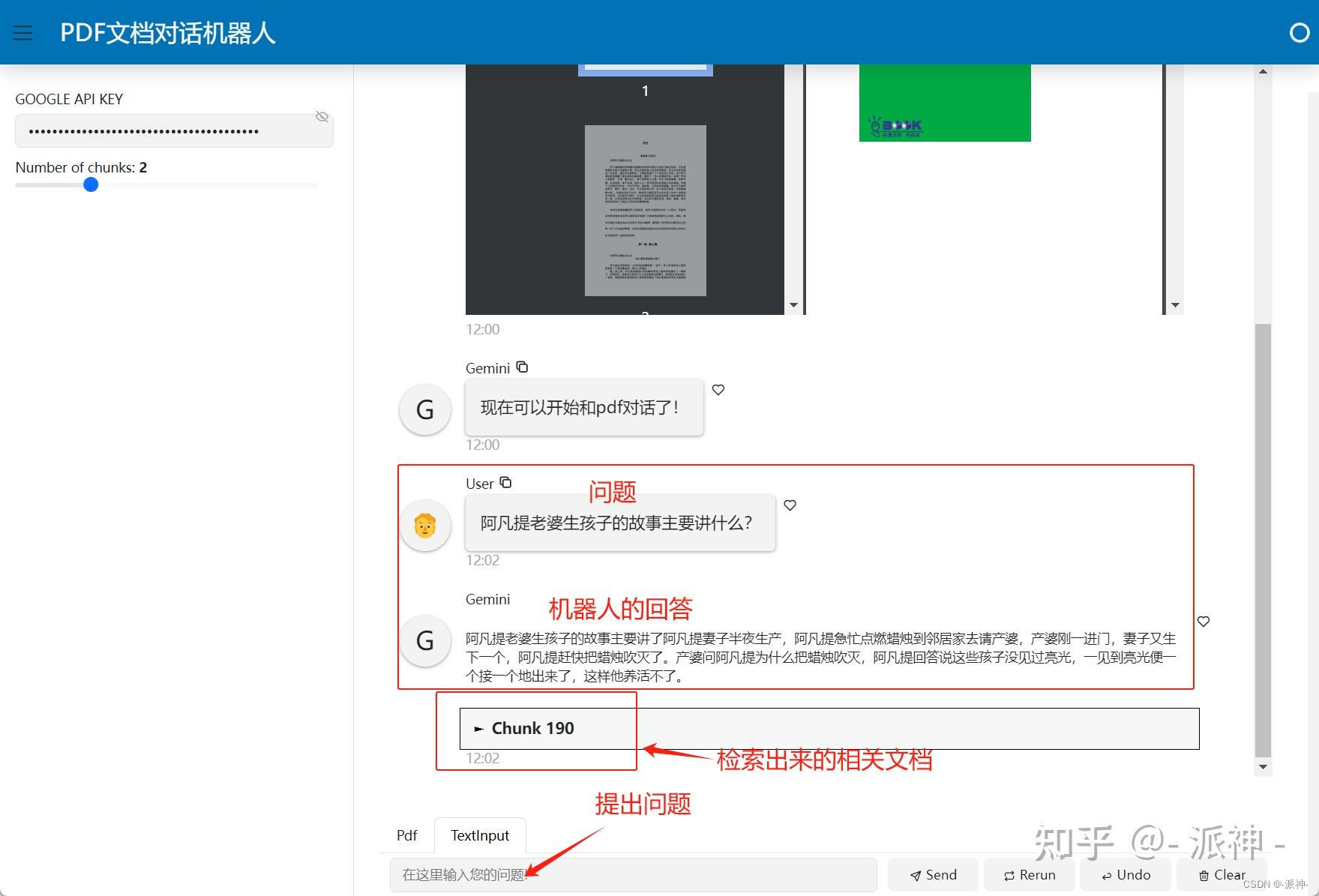
完成输入谷歌api key和上传pdf文件以后,就可以开始和机器人聊天了:
五、总结
今天我们主要介绍了如何开发一个简单的RAG系统:基于pdf文档问答的机器人应用,其中我们应用了langchain的父文档检索策略,panel的页面聊天组件chat_interface以及谷歌的Gemini大模型。希望今天的内容对大家学习RAG和聊天机器人程序有所帮助。
六、完整代码
链接:https://pan.baidu.com/s/1w6MzGDflLF7N3-NlENKj8w 提取码:tllt
相关文章:
使用python快速开发与PDF文档对话的Gemini聊天机器人
检索增强生成(Retrieval-augmented generation,RAG)使得我们可以让大型语言模型(LLMs)访问外部知识库数据(如pdf,word、text等),从而让人们可以更加方便的通过LLM来学习外部数据的知识。今天我们将利用之前学习到的RAG方法,谷歌Gemini模型和l…...
Spring Cloud Gateway集成Knife4j
1、前提 网关路由能够正常工作。 案例 基于 Spring Cloud Gateway Nacos 实现动态路由拓展的参考地址:Spring Cloud Gateway Nacos 实现动态路由 详细官网案例:https://doc.xiaominfo.com/docs/middleware-sources/spring-cloud-gateway/spring-gatewa…...

Hive10_窗口函数
窗口函数(开窗函数) 1 相关函数说明 普通的聚合函数聚合的行集是组,开窗函数聚合的行集是窗口。因此,普通的聚合函数每组(Group by)只返回一个值,而开窗函数则可为窗口中的每行都返回一个值。简单理解,就是对查询的结果多出一列…...

ipvsadm命令详解
ipvsadm命令详解 大家好,我是免费搭建查券返利机器人赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将深入探讨一个在Linux系统网络管理中极具威力的命令——ipvsadm,通过详细解析…...
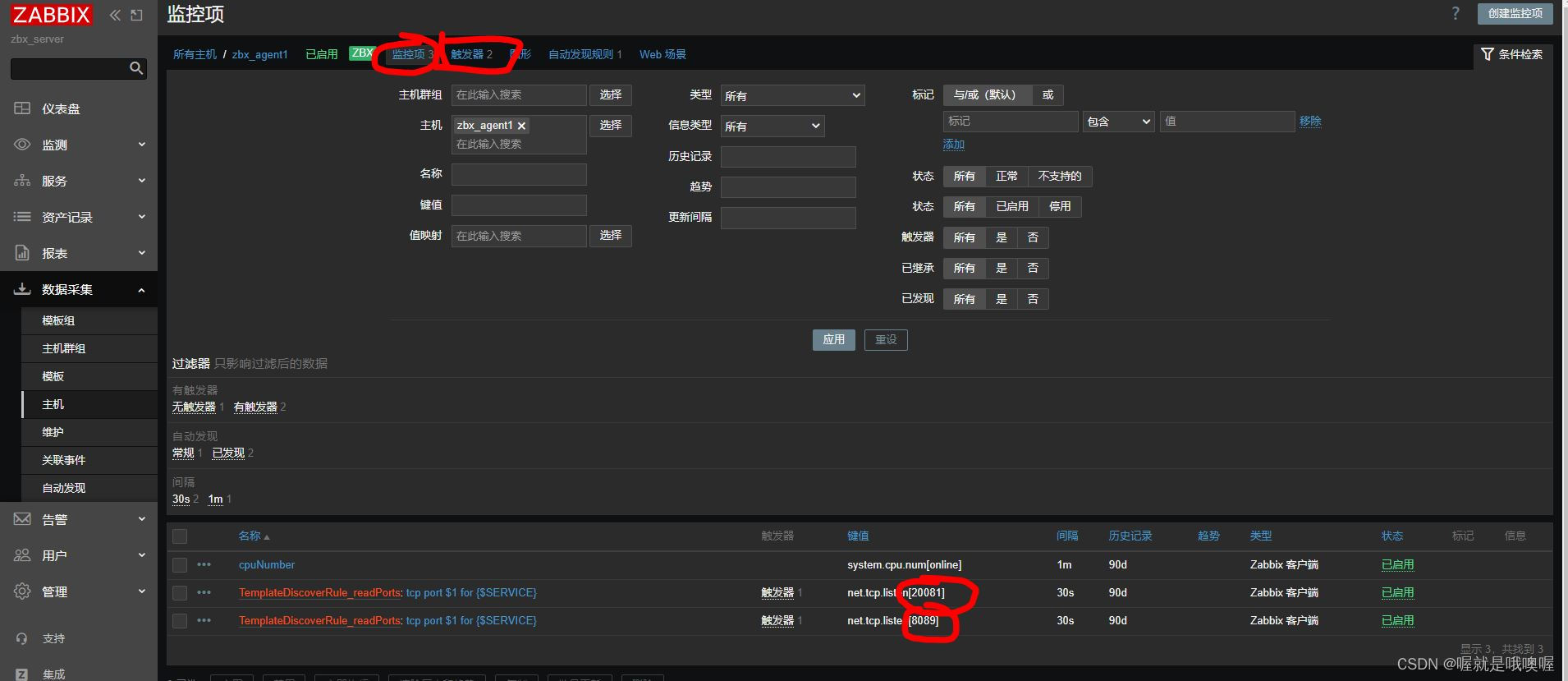
zabbix通过自动发现-配置监控项、触发器(小白教程)
自动发现配置参考链接(不小白,不友好) zabbix-get介绍 1配置 zabbix server:版本7(不影响),IP地址:192.168.0.60zabbix agent:版本agent1(不影响)ÿ…...

Dockerfile文件介绍
0 Preface/Foreword 0.1 Docker docker用来自制镜像。 1 Introduction 1.1 Dockerfile Dockerfile是用于定义Docker镜像的构建过程,它包含一系列的指令用于安装 软件包、配置环境等操作。 Dockerfile文件的格式如下: FROM base_image RUN apt-get up…...
使用场景)
【PHP】函数array_reduce()使用场景
目录 1.计算数组中所有元素的和 2.计算数组中所有元素的乘积 3.将多个字符串连接在一起 4.对数组中的元素进行逻辑计算 5.取出第一个满足条件的数组,筛选有用数组 6.array_reduce()函数的基本语法: array_reduce 函数通常用于对数组中的元素进行累…...

软件测试基础理论学习-软件测试方法论
软件测试方法论 软件测试的方法应该建立在不同的软件测试类型上,不同的测试类型会存在不同的方法。本文以软件测试中常见的黑盒测试为例,简述常见软件测试方法。 黑盒测试用例设计方法包括等价类划分法、边界值分析法、因果图法、判定表驱动法、正交试…...

Unity 关于点击不同物品移动并触发不同事件
关于点击不同物品触发不同事件 可以实现在界面中点击不同的物体,移动到物品附近位置,然后触发对应的事件。 首先建立一个公共管理的类: public class InteractionObject : MonoBehaviour {private NavMeshAgent PlayerAgent;private bool …...

c++IO库详细介绍
文章目录 前言c IO 类简介1. iostream库iostream 类标准IO对象 2. fstream库fstream 类 3. stringstream库stringstream 类 格式化和控制错误处理 IO对象无拷贝或赋值IO条件状态主要的状态标志检查流状态控制流状态示例 管理输出缓冲主要操作示例 文件输入输出使用文件流对象示…...

海外静态IP和动态IP有什么区别?推荐哪种?
什么是静态ip、动态ip,二者有什么区别?哪种好?关于这个问题,不难发现,在知道、知乎上面的解释有很多,但据小编的发现,这些回答都是关于静态ip和动态ip的专业术语解释,普通非专业人事…...

OpenHarmony从入门到放弃(一)
OpenHarmony从入门到放弃(二) 一、OpenHarmony的基本概念和特性 OpenHarmony是由开放原子开源基金会孵化及运营的开源项目,其目标是构建一个面向全场景、全连接、全智能的时代的智能终端设备操作系统。 分布式架构 OpenHarmony采用分布式…...
Unity3D UGUI图集打包与动态使用(TexturePacker)
制作图集的好处: 众所周知CPU是用来处理游戏的逻辑运算的,而GPU是用来处理游戏中图像的。在GPU中,我们要绘制一个图像需要提交图片(纹理)到显存,然后再进行绘制(在这个过程中会产生一次DrawCall…...
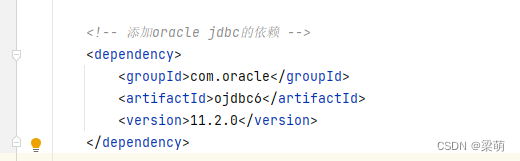
java maven项目添加oracle jdbc的依赖
一般添加依赖是直接在pom.xml中添加配置即可,Maven会自动获取对应的jar包,但是oracle驱动依赖添加后会显示红色,代表找不到依赖项,是因为Oracle授权问题,Maven3不提供Oracle JDBC driver,为了在Maven项目中…...

【UEFI基础】EDK网络框架(环境配置)
环境配置 为了能够让使用测试BIOS的QEMU与主机(就是指普通的Windows系统,我们使用它来编译BIOS和启动QEMU虚拟机)通过网络连接,需要额外的配置。 首先是下载和安装OpenVPN(这里安装的是OpenVPN-2.5.5-I601-amd64.msi…...
-K8S源代码走读之API-Server)
K8S学习指南(60)-K8S源代码走读之API-Server
文章目录 API Server 的代码结构API Server 的核心逻辑1. 请求处理流程1.1 HTTP 请求处理1.2 认证和授权1.3 API 版本处理1.4 资源路由1.5 资源处理1.6 响应生成 2. 存储层2.1 存储接口定义2.2 存储实现 二次开发扩展点1. 插件机制1.1 插件注册1.2 插件实现 2. 自定义资源定义&…...

基于深度学习的交通标志图像分类识别系统
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :) 1. 项目简介 本文详细探讨了一基于深度学习的交通标志图像识别系统。采用TensorFlow和Keras框架,利用卷积神经网络(CNN)进行模型训练和预测,并引入VGG16迁移学习…...
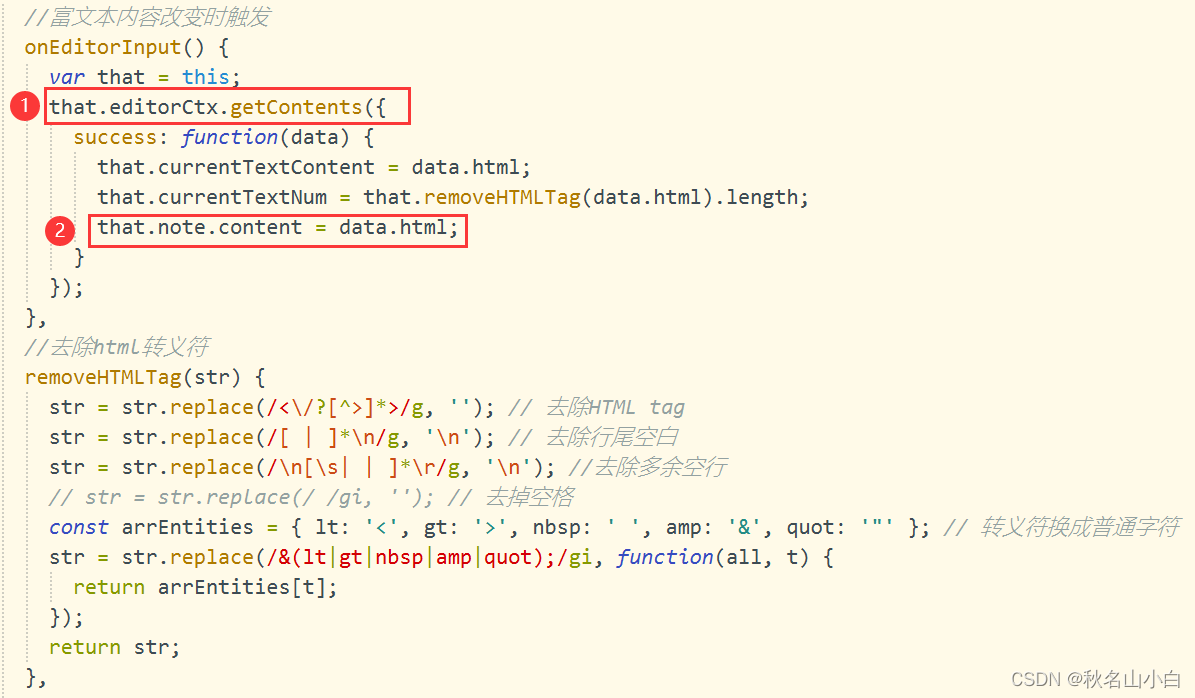
使用uni-app editor富文本组件设置富文本内容及解决@Ready先于onload执行,无法获取后端接口数据的问题
开始使用富文本组件editor时,不知如何调用相关API设置富文本内容和获取内容,本文将举例详解 目录 一.了解editor组件的常用属性及相关API 1.属性常用说明 2.富文本相关API说明 1)editorContext 2) editorContext.setContents…...
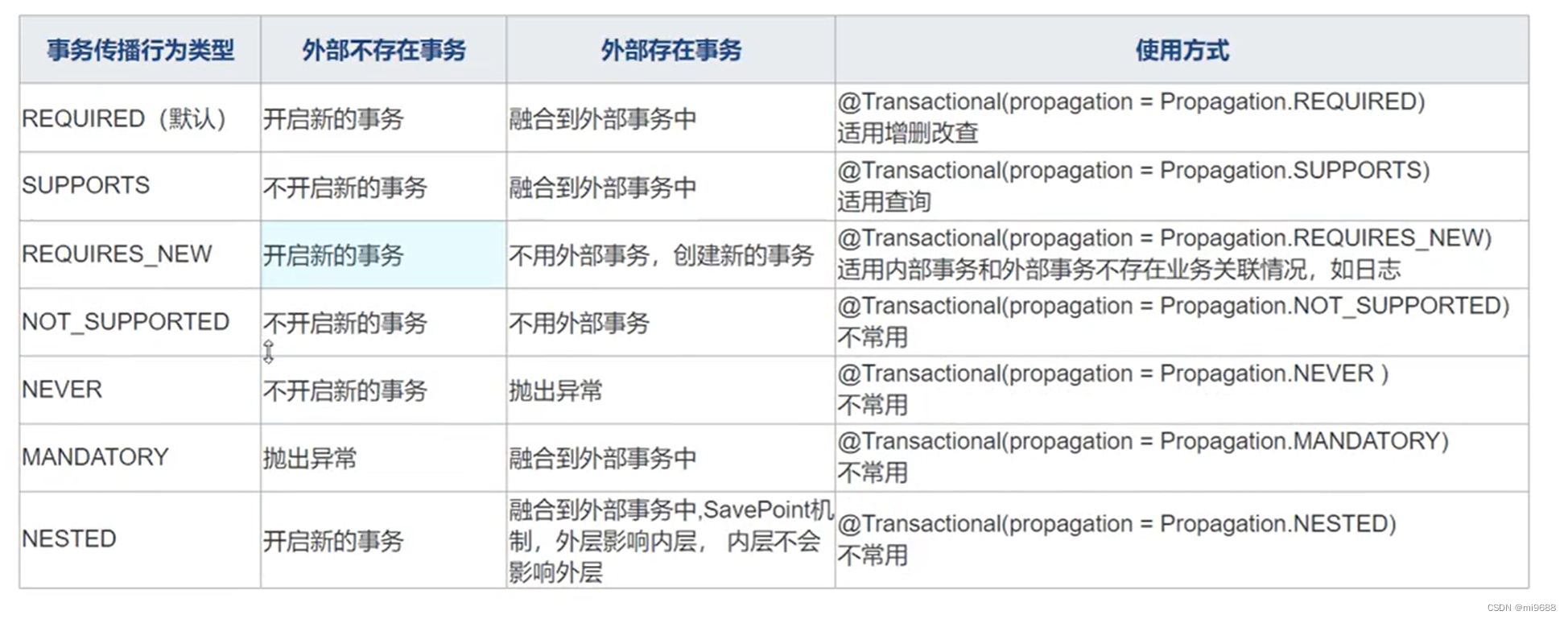
Spring高手之路-Spring事务的传播机制(行为、特性)
目录 含义 七种事务传播机制 1.REQUIRED(默认) 2.REQUIRES_NEW 3.SUPPORTS 4.NOT_SUPPORTED 5.MANDATORY 6.NEVER 7.NESTED 含义 Spring事务的传播机制是指在多个事务方法相互调用时,如何处理这些事务的传播行为。对应七种事务传播行为…...
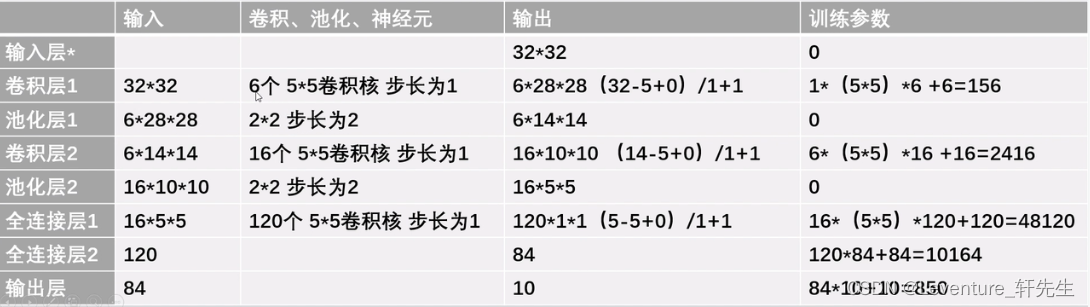
简易机器学习笔记(八)关于经典的图像分类问题-常见经典神经网络LeNet
前言 图像分类是根据图像的语义信息对不同类别图像进行区分,是计算机视觉的核心,是物体检测、图像分割、物体跟踪、行为分析、人脸识别等其他高层次视觉任务的基础。图像分类在许多领域都有着广泛的应用,如:安防领域的人脸识别和…...

Raycast扩展vscode-control:用全局启动器遥控VS Code提升开发效率
1. 项目概述:一个为Raycast打造的VS Code遥控器 如果你和我一样,每天大部分时间都泡在代码编辑器里,那么你一定对频繁在编辑器、终端、浏览器和启动器之间切换感到厌烦。尤其是当你需要快速执行一个格式化操作、运行一个NPM脚本,…...

如何快速解包Godot游戏资源:3分钟掌握PCK文件提取技巧
如何快速解包Godot游戏资源:3分钟掌握PCK文件提取技巧 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker 你是否曾经遇到过想要查看Godot游戏内部资源却无从下手的困境?那些神秘…...

Onyx:基于Next.js 14的全栈MVP模板,集成Supabase与现代化工具链
1. 项目概述:Onyx,一个开箱即用的全栈Next.js 14 MVP模板如果你正在寻找一个能让你在几天内,而不是几周内,就启动一个现代化、功能齐全的Web应用原型的起点,那么Onyx很可能就是你需要的那个“瑞士军刀”。这不是一个简…...

局域网监控软件评测:从数据主权视角看企业效能工具的取舍
很多管理者在巡视办公室时,看到员工手指在键盘上飞速跳动,屏幕上代码或表格交织,心中却往往悬着一块石头:他们是在攻克项目难关,还是在处理私人兼职?这种管理上的“黑盒状态”,不仅是效率的损耗…...

Claude API开发实战:从模型选型到工具调用,一站式资源与代码详解
1. 项目概述与核心价值最近在折腾AI应用开发的朋友,估计没少为Claude API的调用和管理头疼。官方文档虽然详尽,但当你需要快速查找某个特定端点、对比不同模型参数,或者只是想找个现成的代码片段时,那种在多个页面间跳转、反复搜索…...

基于LLM的智能体驱动文字冒险游戏引擎设计与实现
1. 项目概述:一个AI驱动的文字冒险游戏引擎最近在GitHub上闲逛,发现了一个挺有意思的项目,叫droxey/agentadventure。光看名字,大概能猜到它和“智能体”(Agent)以及“冒险”(Adventure…...

Windows平台APK部署技术探索:轻量级安卓应用安装实践指南
Windows平台APK部署技术探索:轻量级安卓应用安装实践指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在跨平台应用开发与部署日益普及的今天࿰…...

5个场景告诉你:为什么你需要这款免费的窗口分辨率神器
5个场景告诉你:为什么你需要这款免费的窗口分辨率神器 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 你是否曾遇到过这些困扰?游戏内分辨率选项有限,无法满足你对极致画质的…...

资深运维的Helm Chart私藏库:高质量K8s应用部署实战指南
1. 项目概述:一个资深运维的Helm Chart私藏库如果你和我一样,长期在Kubernetes(K8s)的“牧场”里当“牛仔”(Sysop),那你肯定明白,找到一个质量上乘、维护及时、配置合理的Helm Char…...

专业级macOS歌词同步方案:LyricsX核心功能深度解析
专业级macOS歌词同步方案:LyricsX核心功能深度解析 【免费下载链接】LyricsX 🎶 Ultimate lyrics app for macOS. 项目地址: https://gitcode.com/gh_mirrors/ly/LyricsX LyricsX是一款专为macOS设计的专业级歌词同步工具,通过智能歌词…...