感知与认知的碰撞,大模型时代的智能文档处理范式
目录
- 0 写在前面
- 1 GPT4-V:拓宽文档认知边界
- 2 大语言模型的文档感知缺陷
- 3 大一统文档图像处理范式
- 3.1 像素级OCR任务
- 3.2 OCR大一统模型
- 3.3 长文档理解与应用
- 4 总结
- 抽奖福利
0 写在前面
由中国图象图形学学会青年工作委员会发起的第十九届中国图象图形学学会青年科学家会议于2023年12月28-31日在中国广州召开。会议面向国际学术前沿与国家战略需求,聚焦最新前沿技术和热点领域,邀请了学术界和企业界专家与青年学者进行深度交流,促进图象图形领域“产学研”合作。
随着信息技术的发展和应用场景的不断扩大,人们需要处理和利用大量的文档信息。而传统的手动处理方法效率低下,无法满足现代生活和工作的需求。文档图像智能分析与处理就是一个重要且极具挑战性的研究问题。虽然文档图像分析已经有了将近一百年的历史,但是到目前为止仍有大量的问题没有得到很好地解决,例如文档的多样性和复杂性问题:文档类型和格式繁多,包括报告、合同、发票、证明、证件等等。不同类型的文档有不同的格式和布局,难以用统一的方法处理。而且智能文档处理受到图像质量、文字字体、文字大小、文字颜色等噪声因素的影响,容易出现误识别。此外,图像质量不一、文档获取繁琐等问题,依旧是行业顽疾。
合合信息作为文档图像处理领域的代表性科技企业,在本次会议中分享了大模型时代下,智能文档图像处理研究范式的相关启发性思考。大语言模型的快速发展,能否和传统方法相结合,发挥出更强大的优势,注入更鲜活的生命力呢?合合信息智能技术平台事业部副总经理、高级工程师丁凯博士对此进行了进一步的探讨和分析,相信对这个领域感兴趣的同学一定有所收获,接下来就让我们一起看看吧!
1 GPT4-V:拓宽文档认知边界
大型语言模型(LLMs)在各种领域和任务中表现出了显著的多功能性和能力。下一步的发展是大型多模态模型(LMMs),它们通过整合多感官技能来扩展LLMs的能力,以实现更强的通用智能。考虑到视觉在人类感官中的主导地位,许多LMM研究从扩展视觉能力开始。GPT-4V(ision)是OpenAI在2023年9月25日为ChatGPT增加的新特性,其中的V意味着GPT-4将更加注重视觉理解,GPT-4将具备更多的输入形式,使得用户可以通过包括文本、图像、声音等多种数据类型与GPT4进行交互,并且GPT-4能够进行更加复杂的推理和逻辑推导。同时,这也标志着GPT4正式成为一个多模态模型。

丁凯博士首先介绍了GPT4-V强大的认知能力,相对于传统方法,大语言模型具备强大的上下文理解性能,可以根据文档中的文字内容和图像信息进行全面的语义分析。相比之下,传统方法通常只能依赖预定义规则或特定模式进行处理,难以捕捉到复杂的上下文关系。通过大量的训练数据进行学习和迭代,大语言模型可以从数据中学习到更丰富的特征表示和模式,从而更好地理解和处理文档图像。传统方法往往需要手动设计特征和规则,限制了其在复杂场景下的表现。

在多模态融合方面,大语言模型能够同时处理文本和图像信息,将文档图像中的文字和视觉元素进行联合分析和处理,提供更全面、准确的结果。传统方法通常是分别处理文本和图像,难以充分利用两者之间的相关性。此外,大语言模型的架构和训练方式具有较大的灵活性和可扩展性,可以根据任务需求进行调整和优化。相比之下,传统方法往往需要针对不同任务设计和实现特定的算法和流程,难以适应不同场景的需求。

丁凯博士举了一个复杂数据折线图的理解问题,这个问题涉及到多跳推理,因而属于复杂任务,例如,要回答
在图中,哪一年的6月份的平均汽油价格最高?
需要至少经过四个步骤
- 在 x x x轴上找到6月份
- 比较6月份每条线的数据点
- 确定最高值的线条颜色
- 在顶部的图例中将颜色与对应的年份匹配。
任何一个步骤出错都会导致预测不准确。GPT-4V最终得出了正确的答案并提供了解释其推理过程的中间步骤,取得了超出传统方法的巨大优势。

由于大语言模型通过迁移学习和远程监督等技术,将在其他领域或任务上获得的知识和经验应用于智能文档图像处理,大语言模型能够更快速地适应新的任务和场景,减少数据和资源的需求。
2 大语言模型的文档感知缺陷
虽然GPT4-V在认知方面展示出巨大的潜力,但它在处理智能文档任务时,仍然具有很多的缺陷。
首先是幻觉现象,即模型错误地关联了文本信息和图像细节之间的关系,导致产生了错误的推断和判断,或根据文本信息生成与图像不符合的内容,在补全图像时添加错误或不相关的细节。丁凯博士以手写中文诗歌识别为例解释了这个问题。

丁凯博士接着介绍了一项全面评估GPT-4V在OCR领域能力的工作——对GPT-4V在广泛任务范围内进行了定量性能分析,这些任务包括场景文本识别、手写文本识别、手写数学表达式识别、表格结构识别以及从视觉丰富的文档中提取信息。研究显示,虽然该模型表现出了精准识别拉丁内容并支持具有可变分辨率的输入图像的强大能力,但在多语言和复杂场景方面仍然存在明显的困难。此外,高推理成本和与持续更新相关的挑战对于GPT-4V在实际部署中构成了重要障碍。因此,OCR领域的专门模型仍然具有重要的研究价值。尽管存在这些限制,GPT-4V和其他现有的通用LMM模型仍然可以在OCR领域的发展中发挥重要作用。这些作用包括提升语义理解能力、针对下游任务进行微调,并促进自动/半自动数据构建。

目前多模态大模型在密集文本处理方面几乎不能使用,一个很重要的原因是:多模态大模型主要基于文本进行语义理解,对于视觉感知和图像特征的提取能力有限。在处理密集文本时,相邻的文本可能会重叠、相互遮挡或无明显的边界,这需要对视觉特征进行准确地提取和分析,大语言模型的主要优势是在自然语言文本处理方面,而不是直接处理视觉信息。因此,在图像文档处理方面,由于视觉感知限制和文字识别困难,大语言模型并不适合直接应用于该领域。在处理密集文本时,需要借助于文本检测、分割和OCR等专门的技术和算法来实现准确的文本识别和提取

细粒度文本通常指的是文字较小、笔画细致、字形复杂的文本,如签名、古汉字、特殊符号等。这类文本在OCR领域中往往是非常具有挑战性的,因为它们往往涉及到字形和结构上的细微差异,很难直接从图像中提取出精确的文字信息。此外,在真实场景下,这些细粒度文本可能会受到光照、噪声、变形等各种干扰,这也增加了文字识别的难度。多模态大模型中的视觉编码器通常基于卷积神经网络或Transformer等模型,在处理图像时会受到分辨率的限制;另一方面,由于训练数据集中缺少针对细粒度文本的标注数据,模型很难从数据中学到有效的细粒度文本特征表示。因此,现有多模态大模型对显著文本的处理较好,但是对于细粒度文本的处理很差,要克服这些局限性,需要开展更深入的研究和探索
3 大一统文档图像处理范式
总得来说,在智能文档处理领域,大语言模型支持识别和理解的文档元素类型远超传统IDP算法,大幅度提升了AI技术在文档分析与识别领域的能力边界,端到端实现了文档的识别到理解的全过程,不足在于OCR精度距离SOTA有较大差距,长文档依赖外部的OCR/文档解析引擎。因此将传统OCR感知与大语言模型认知能力相结合的研究范式具有积极意义。
3.1 像素级OCR任务
在印刷体的文字识别领域,开展最早,且技术上最成熟的是国外的西方文字识别技术。早在 1929 年,德国的科学家Taushek已经取得了一项光学字符识别(optical character recognition, OCR)专利。自上个世纪五十年代以来,欧美国家就开始研究关于西方各个国家的文字识别技术,以便对日常生活中产生的大量文字材料进行数字化处理。经过长时间的不断研究和完善,西文的OCR技术已经有一套完备的识别方案,并广泛地用在西文的各个领域中。而像素级OCR任务是指OCR领域中的一种任务,其目标是对图像中的每个像素进行文本识别和分割。传统的OCR任务通常是将整个文本区域或文本行作为一个整体进行识别,而像素级OCR任务则更加注重对文本边界和细节的精细识别。

丁凯博士介绍了目前合合信息-华南理工大学联合实验室在像素级OCR任务中的研究进展。首先是通用OCR模型UPOCR。近年来,OCR领域出现了大量前沿的方法,用于各种任务。然而这些方法是针对特定任务设计的,具有不同的范式、架构和训练策略,这显著增加了研究和维护的复杂性,并阻碍了在应用中的快速部署。与之相对,UPOCR统一了不同像素级OCR任务的策略,同时引入可学习的任务提示来指导基于ViT的编码器-解码器架构。UPOCR的主干网络ViTEraser联合文本擦除、文本分割和篡改文本检测等3个不同的任务提示词进行统一训练模型训练好后即可用于下游任务,无需针对下游任务进行专门的精调。UPOCR的通用能力在多种智能文档处理任务上得到了广泛验证,显著优于现有的专门模型
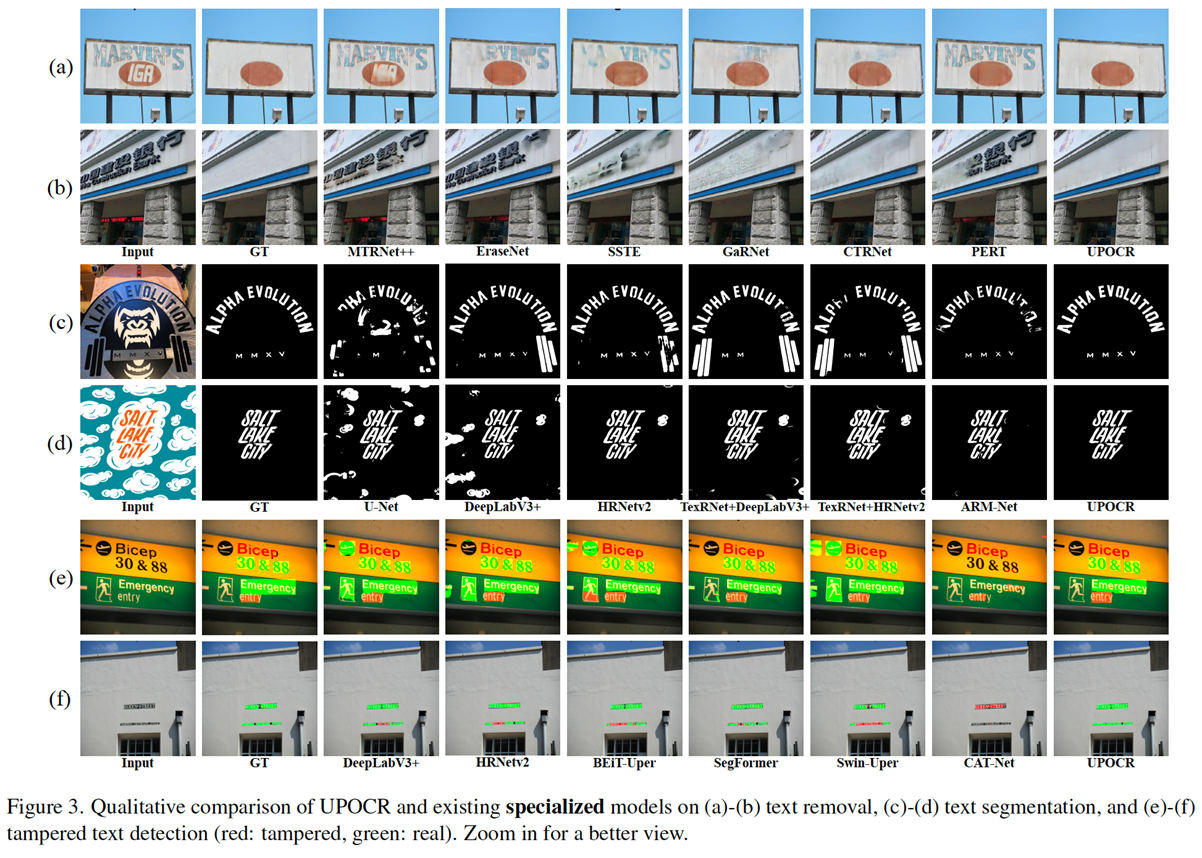
3.2 OCR大一统模型
在OCR大一统模型方面,已经有相关工作进行了积极的探索。例如无需OCR的用于文档理解的Transformer模型Donut;通过SwinTransformer和Transformer Decoder实现文档图像到文档序列输出模型NOUGAT,及微软提出的更大的模型KOSMOS2.5。
基于已有工作,丁凯博士分享了文档图像大模型的设计思路,主要是将文档图像识别分析的多种任务,通过序列预测的方式进行处理。具体来说,将每个任务所涉及的元素定义为一个序列,并设计相应的prompt来引导模型完成不同的OCR任务。例如,对于文本识别任务,可以使用prompt "识别文本: " 并将待处理的文本序列作为输入;对于段落分析任务,则可使用prompt "分析段落:"并将段落序列作为输入等等。这种方式可以保持一致的输入格式,方便模型进行多任务的处理。
此外,这个设计思路还支持篇章级的文档图像识别分析,可以输出Markdown/HTML/Text等标准格式,这样可以更好地适应用户的需求。同时,将文档理解相关的工作交给大语言模型,这意味着模型可以自动进行篇章级的文档理解和分析,从而提高了文档图像处理的效率和准确性。

总的来说,这种设计思路充分利用了序列预测的优势,在保持输入格式的统一性的同时,能够更好地解决文档图像处理中的多样化任务需求,并且通过与LLM的结合,实现了更高层次的文档理解和分析,为文档图像处理领域带来了更多可能性。
3.3 长文档理解与应用
丁凯博士给出了大语言模型赋能文档识别分析的技术路线:首先,文档识别分析技术需要输入文档的图像。这些图像可以是扫描得到的纸质文档、拍摄得到的照片或者从电子文档中提取的页面图像。接下来,文档图像会经过文档识别与版面分析处理。在这个阶段,技术会识别文档中的文字、图片、表格等元素,并分析文档的版面结构,包括标题、段落、页眉和页脚等。这可以帮助理解文档的整体结构和内容组织形式。在文档切分和召回阶段,技术会将文档进行切分,将不同部分的内容分离出来,以便后续的处理和分析。同时,也会实施召回策略,用于检索和提取特定的文档元素,比如标题、关键字、段落内容等。最后,在文档识别分析技术的流程中,大语言模型问答可以被应用于文档中提取信息的问答任务。通过训练大语言模型来理解文档内容,并能够回答用户提出的问题,从而实现对文档内容的智能理解和交互式查询。
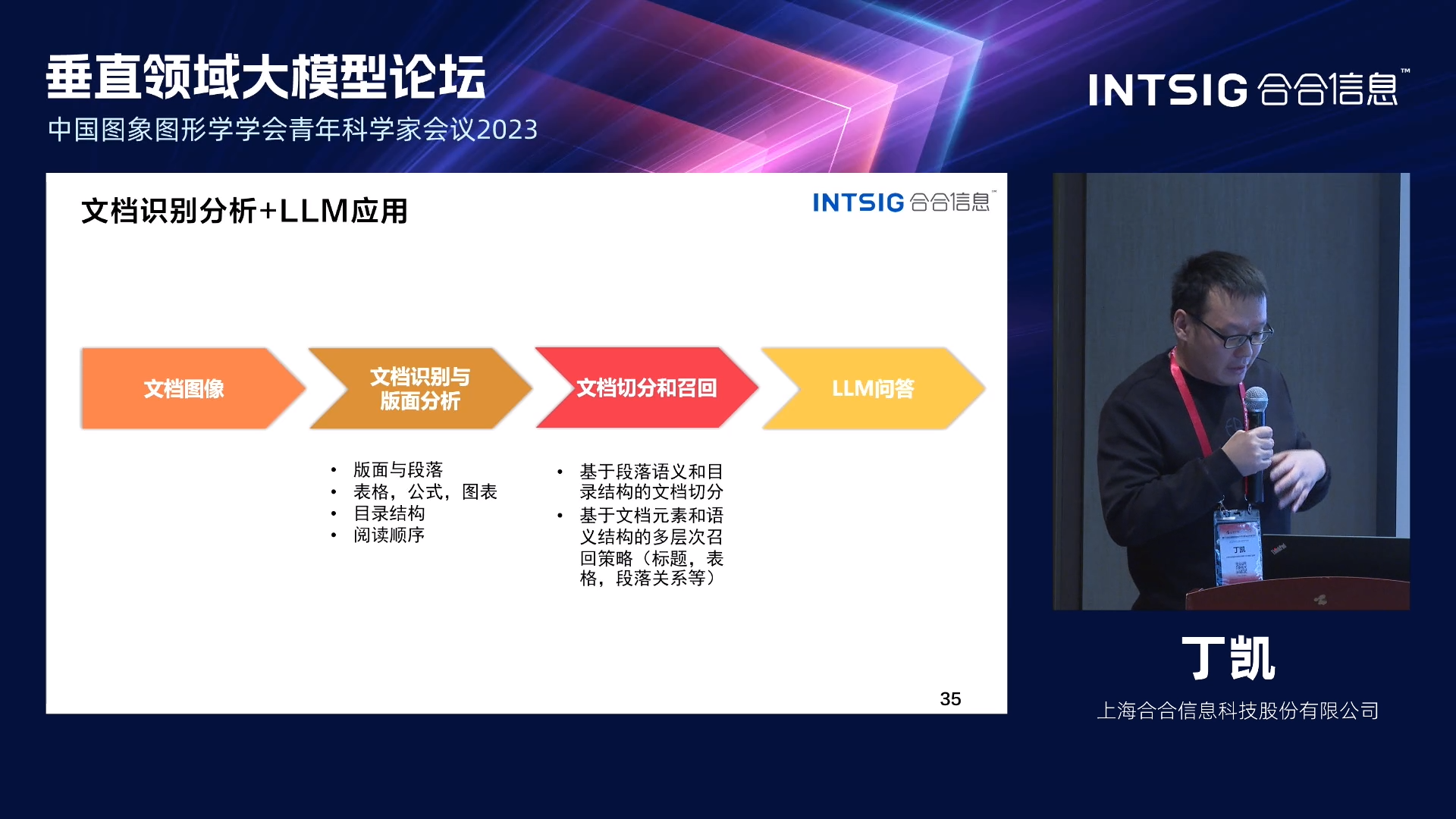
一个实例是财报/研报文档分析,这类文档内容长、图表多、版式杂、专业性强、数据和相似概念多,具有很高的处理难度。传统方法在处理时可能面临信息过载和处理效率低下的问题。而大语言模型具有更强大的处理能力,可以处理较长的文本内容,并从中提取关键信息。同时,大语言模型通过大规模的预训练和迁移学习,具备较强的领域适应能力,能够理解相关专业术语和结构,从而更好地进行识别和分析。

4 总结
GPT4-V为代表的多模态大模型技术极大的推进了文档识别与分析领域的技术进展,也给传统的图像文档处理技术带来了挑战。大模型并没有完全解决图像文档处理领域面临的问题,很多问题值得我们研究。如何结合大模型的能力,更好地解决图像文档处理的问题,值得我们做更多的思考和探索。我相信感知与认知的相互碰撞将为用户带来更智能化、高效率和个性化的文档处理体验。未来随着技术的不断进步,这种结合将在商业、教育、科研等领域发挥越来越重要的作用。让我们拭目以待,期待合合信息在模式识别、深度学习、图像处理、自然语言处理等领域的深耕厚积薄发,用技术方案惠及更多的人!
抽奖福利

合合信息给大家送福利了!填写问卷抽10个人送50元京东卡,1月12日开奖噢~
相关文章:
感知与认知的碰撞,大模型时代的智能文档处理范式
目录 0 写在前面1 GPT4-V:拓宽文档认知边界2 大语言模型的文档感知缺陷3 大一统文档图像处理范式3.1 像素级OCR任务3.2 OCR大一统模型3.3 长文档理解与应用 4 总结抽奖福利 0 写在前面 由中国图象图形学学会青年工作委员会发起的第十九届中国图象图形学学会青年科学…...

ECMAScript和JavaScript的区别
ECMAScript和JavaScript之间的关系和差异可以从以下几个方面来理解: 定义: ECMAScript:ECMAScript是一种由Ecma国际(前身为欧洲计算机制造商协会,英文名称是European Computer Manufacturers Association)通…...
[BUG]Datax写入数据到psql报不能序列化特殊字符
1.问题描述 Datax从mongodb写入数据到psql报错如下 org.postgresql.util.PSQLException: ERROR: invalid bytesequence for encoding "UTF8": 0x002.原因分析 此为psql独有的错误,不能对特殊字符’/u0000’,进行序列化,需要将此特殊字符替…...

用数据结构python写大数计算器
下面是一个基于Python的大数计算器的示例代码: class BigNumberCalculator:def __init__(self, num1, num2):self.num1 num1self.num2 num2staticmethoddef add(num1, num2):result carry 0len1, len2 len(num1), len(num2)max_len max(len1, len2)for i in …...
08.哲说建造者模式(Builder Pattern)
“The odds that we’re in ‘base reality’ is one in billions.” —— Elon Musk 这段话出自马斯克在2016年的一次演讲,“人类活在真实世界的几率,可能不到十亿分之一”。此言一出,可谓一石激起千层浪。有人嘲讽马斯克是“语不惊人死不休…...

ubuntu18.04查询实时内存、CPU占用率命令
gnome-system-monitor效果就是下面这样:...

Python计算圆的面积
Python 计算圆的面积 圆的面积公式为 : 公式中 r 为圆的半径。 # 定义一个方法来计算圆的面积 def findArea(r): PI 3.142 return PI * (r*r) # 调用方法 r float( input("请输入圆的半径:") ) print( "圆的面积为 %.3f&qu…...

(Java企业 / 公司项目)Nacos的怎么搭建多环境配置?(含相关面试题)(二)
上一篇讲了一个单体服务中配置,传统的Nacos配置但是在微服务架构当中肯定都是多环境下配置,比如生产环境,dev测试环境等等。 第一种方式模拟开始: 首先展示在生产环境中nacos如何配置,在模块下新建一个配置文件&…...
DolphinScheduler实际应用
前言 最近公司新启动了一个项目,然后领导想用一下新技术,并且为公司提供多个大数据调度解决方案,我呢就根据领导要求调研了下当前的开源调度工具,最终决定采用DolphinScheduler, 因此研究了一下DolphinScheduler &…...

P10 RV1126推流项目——ffmpeg输出参数初始化
前言 从本章开始我们将要学习嵌入式音视频的学习了 ,使用的瑞芯微的开发板 🎬 个人主页:ChenPi 🐻推荐专栏1: 《C_ChenPi的博客-CSDN博客》✨✨✨ 🔥 推荐专栏2: 《Linux C应用编程(概念类)_C…...
正定矩阵在格密码中的应用(知识铺垫)
目录 一. 写在前面 二. 最小值点 三. 二次型结构 四. 正定与非正定讨论 4.1 对参数a的要求 4.2 对参数c的要求 4.3 对参数b的要求 五. 最小值,最大值与奇异值 5.1 正定型(positive definite) 5.2 负定型(negative defin…...
关于使用Selenium获取网页控制台的数据
背景: 需要获取网页的控制台的数据,如下图 在此文章将使用到 Pycharm 和 Selenium4 Pycharm安装 Selenium安装 from selenium import webdriver from selenium.webdriver.common.by import By import time# 创建浏览器对象 browser webdriver.Chro…...

vue2和vue3中的路由使用及传参方式
文章目录 vue2中使用路由Vue3 中使用路由路由传参方式 Vue 2 和 Vue 3 中的路由系统有很多相似之处,但也存在一些重要的区别。下面将分别介绍 Vue 2 和 Vue 3 中的路由使用方式,并了解下它们之间的不同之处。 vue2中使用路由 在 Vue 2 中,通…...

论文管理器
论文管理器 这个论文管理器仍然存在许多漏洞。目前,通过按照一些例行程序操作,它可以正常工作。我将在有时间的时候改进代码,提供详细说明,并添加新功能。当该管理器的代码进行优化后,我会上传到github上。 一个建立…...

postfix配置tls加密
1.编译安装 编译安装openss【卸载原有openssl,然后下载新的安装,因为postfix需要新版本openssl】编译安装postfix,下面这行命令 make -f Makefile.init makefiles CCARGS"-DHAS_MYSQL -I/www/server/mysql/include -DUSE_SASL_AUTH -I/usr/include…...

虚拟专线网络(IP-VPN)
虚拟专线网络(IP-VPN),因为它的安全性和可靠性。通过亚洲领先的 IP VPN 提供商。享受更高的可管理性和可扩展性,在多个站点之间交付 IP 流量或数据包,拥有亚太地区最大的 IP 骨干网。 1,保证正常运行时间,在网络链路发…...

【Unity动画系统】Unity动画系统Animation详解,参数细节你是否弄清?
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:Uni…...

K8S Helm安装RocketMQ standalone单机版,配置外网地址注册到nameserver中方便本地开发
K8S Helm安装RocketMQ standalone单机版,配置外网地址注册到nameserver中方便本地开发 helm地址 rocketmq 3.0.2 sir5kong/rocketmq helm repo add rocketmq https://helm-charts.itboon.top/rocketmq helm pull rocketmq/rocketmq tar -xvf rocketmq-3.0.2.t…...
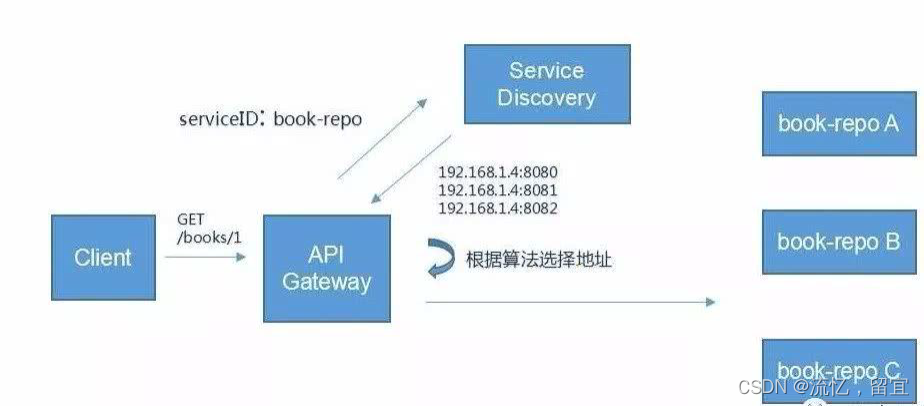
分布式基础概念
分布式基础概念 1 微服务 微服务架构风格,就像是把一个单独的应用程序开发为一套小服务,每个小服务运行在自己的进程中,并使用轻量级机制通信,通常是HTTP API。这些服务围绕业务能力来构建,并通过完全自动化部署机制…...
)
蓝桥杯python比赛历届真题99道经典练习题 (89-99)
【程序89】 题目:某个公司采用公用电话传递数据,数据是四位的整数,在传递过程中是加密的,加密规则如下: 每位数字都加上5,然后用和除以10的余数代替该数字,再将第一位和第四位交换,第二位和第三位交换。 1.程序分析: 2.程序源代码: from sys import stdout if __n…...

基于LangBot框架快速构建智能对话机器人:从工具集成到RAG应用实战
1. 项目概述:一个能“听懂人话”的智能对话机器人如果你正在寻找一个能快速搭建、高度定制,并且能真正理解你意图的智能对话机器人,那么langbot-app/LangBot这个项目绝对值得你花时间深入研究。它不是一个简单的聊天接口封装,而是…...

Python应用性能监控实战:New Relic探针架构与部署指南
1. 项目概述:一个现代应用性能管理的Python探针如果你正在用Python开发Web应用、微服务或者任何需要对外提供服务的后端系统,那么“性能”和“可观测性”这两个词一定不会陌生。当线上服务突然变慢、错误率飙升,或者用户反馈某个接口卡顿时&a…...

大语言模型智能体长期记忆解决方案:LightMem架构解析与LangChain实战
1. 项目概述:轻量化记忆增强的智能体新范式最近在探索大语言模型智能体应用时,一个核心痛点始终绕不开:如何让智能体在长对话或多轮任务中,记住关键信息,并做出连贯、精准的决策?传统的做法要么是将整个对话…...

工业级RS-485收发器自主设计:从电路原理到PCB布局的实战指南
1. 项目概述与核心价值 在工业自动化、楼宇控制、能源监控这些领域里,设备之间要“说话”,RS-485总线绝对是那个最可靠、最耐用的“方言”。你可能在PLC、变频器、智能电表或者一堆传感器上见过那两个标着A、B的端子,背后驱动它们的ÿ…...

基于Adafruit Trinket的光控互动玩具:嵌入式系统入门实战
1. 项目概述:给毛绒玩具注入灵魂几年前,我女儿的一个旧毛绒玩具被冷落在角落,除了偶尔被当作抱枕,几乎失去了“玩具”的活力。这让我萌生了一个想法:能不能用一些简单的电子元件,让这些静态的玩偶重新“活”…...

开发者会话管理工具:提升多任务开发效率的利器
1. 项目概述:一个为开发者打造的会话管理利器在开发日常中,我们常常会同时打开多个终端窗口、IDE项目、数据库连接或者远程服务器会话。一天下来,桌面上可能散落着十几个终端标签页,每个都承载着不同的上下文:一个在跑…...
)
告别adb命令行:用C++和libusb手撸一个USB调试工具(附完整源码)
告别adb命令行:用C和libusb手撸一个USB调试工具(附完整源码) 你是否厌倦了反复敲击adb命令,却对背后的USB通信机制充满好奇?本文将带你深入Android调试桥(ADB)的底层世界,用C和libus…...

Go语言WebSocket服务器tocket:轻量级高性能实时通信方案
1. 项目概述:一个轻量级、高性能的WebSocket服务器 最近在折腾一个需要实时双向通信的物联网项目,传统的HTTP轮询方案在延迟和服务器开销上都不太理想,WebSocket自然就成了首选。在技术选型时,我习惯性地会去GitHub上搜罗一番&…...

基于MCP协议构建阿里云SLS日志AI查询助手:原理、部署与实战
1. 项目概述:当阿里云SLS遇上MCP如果你正在用阿里云日志服务(SLS)做日志分析,同时又想用上像Claude、Cursor这类AI编程助手来帮你写查询、分析数据,那你可能已经感受到了一个痛点:如何在AI助手和你的日志数…...

怎么限制用户上传到MongoDB GridFS的文件总容量
GridFS不支持全局容量配额,需在应用层实现配额校验:上传前聚合查询fs.files中指定用户的length总和,判断是否超限,且须防范并发写入导致的超限问题。GridFS 本身不提供全局容量配额机制MongoDB 的 GridFS 是一个文件分片存储规范&…...