【flink番外篇】9、Flink Table API 支持的操作示例(14)- 时态表的join(java版本)
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。
-
1、Flink 部署系列
本部分介绍Flink的部署、配置相关基础内容。 -
2、Flink基础系列
本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。 -
3、Flik Table API和SQL基础系列
本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。 -
4、Flik Table API和SQL提高与应用系列
本部分是table api 和sql的应用部分,和实际的生产应用联系更为密切,以及有一定开发难度的内容。 -
5、Flink 监控系列
本部分和实际的运维、监控工作相关。
二、Flink 示例专栏
Flink 示例专栏是 Flink 专栏的辅助说明,一般不会介绍知识点的信息,更多的是提供一个一个可以具体使用的示例。本专栏不再分目录,通过链接即可看出介绍的内容。
两专栏的所有文章入口点击:Flink 系列文章汇总索引
文章目录
- Flink 系列文章
- 一、maven依赖
- 二、时态表的join
- 1、统计需求对应的SQL
- 2、Without connnector 实现代码
- 3、With connnector 实现代码
本文通过两个示例介绍了时态表TemporalTableFunction的join操作。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文除了maven依赖外,没有其他依赖。
本文更详细的内容可参考文章:
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
本专题分为以下几篇文章:
【flink番外篇】9、Flink Table API 支持的操作示例(1)-通过Table API和SQL创建表
【flink番外篇】9、Flink Table API 支持的操作示例(2)- 通过Table API 和 SQL 创建视图
【flink番外篇】9、Flink Table API 支持的操作示例(3)- 通过API查询表和使用窗口函数的查询
【flink番外篇】9、Flink Table API 支持的操作示例(4)- Table API 对表的查询、过滤操作
【flink番外篇】9、Flink Table API 支持的操作示例(5)- 表的列操作
【flink番外篇】9、Flink Table API 支持的操作示例(6)- 表的聚合(group by、Distinct、GroupBy/Over Window Aggregation)操作
【flink番外篇】9、Flink Table API 支持的操作示例(7)- 表的join操作(内联接、外联接以及联接自定义函数等)
【flink番外篇】9、Flink Table API 支持的操作示例(8)- 时态表的join(scala版本)
【flink番外篇】9、Flink Table API 支持的操作示例(9)- 表的union、unionall、intersect、intersectall、minus、minusall和in的操作
【flink番外篇】9、Flink Table API 支持的操作示例(10)- 表的OrderBy、Offset 和 Fetch、insert操作
【flink番外篇】9、Flink Table API 支持的操作示例(11)- Group Windows(tumbling、sliding和session)操作
【flink番外篇】9、Flink Table API 支持的操作示例(12)- Over Windows(有界和无界的over window)操作
【flink番外篇】9、Flink Table API 支持的操作示例(13)- Row-based(map、flatmap、aggregate、group window aggregate等)操作
【flink番外篇】9、Flink Table API 支持的操作示例(14)- 时态表的join(java版本)
【flink番外篇】9、Flink Table API 支持的操作示例(1)-完整版
【flink番外篇】9、Flink Table API 支持的操作示例(2)-完整版
一、maven依赖
本文maven依赖参考文章:【flink番外篇】9、Flink Table API 支持的操作示例(1)-通过Table API和SQL创建表 中的依赖,为节省篇幅不再赘述。
二、时态表的join
假设有一张订单表Orders和一张汇率表Rates,那么订单来自于不同的地区,所以支付的币种各不一样,那么假设需要统计每个订单在下单时候Yen币种对应的金额。
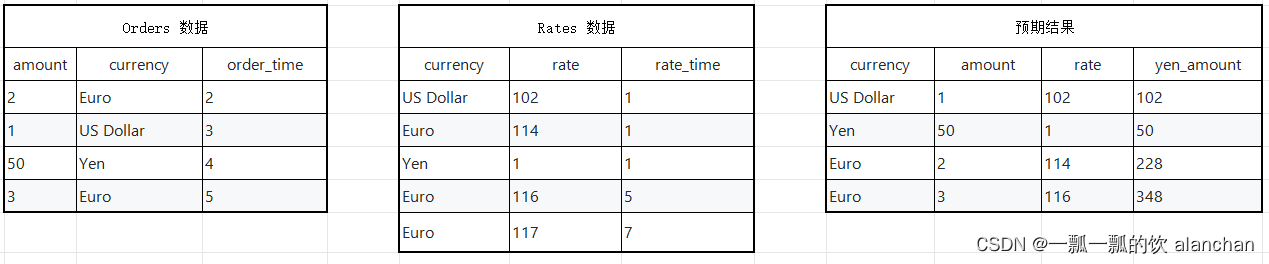
1、统计需求对应的SQL
SELECT o.currency, o.amount, r.rateo.amount * r.rate AS yen_amount
FROMOrders AS o,LATERAL TABLE (Rates(o.rowtime)) AS r
WHERE r.currency = o.currency
2、Without connnector 实现代码
就是使用静态数据实现,其验证结果在代码中的注释部分。
/** @Author: alanchan* @LastEditors: alanchan* @Description: */import static org.apache.flink.table.api.Expressions.$;import java.time.Duration;
import java.util.Arrays;
import java.util.List;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.TemporalTableFunction;
import org.apache.flink.types.Row;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;public class TestTemporalTableFunctionDemo {// 维表@Data@NoArgsConstructor@AllArgsConstructorpublic static class Rate {private String currency;private Integer rate;private Long rate_time;}// 事实表@Data@NoArgsConstructor@AllArgsConstructorpublic static class Order {private Long total;private String currency;private Long order_time;}final static List<Rate> rateList = Arrays.asList(new Rate("US Dollar", 102, 1L),new Rate("Euro", 114, 1L),new Rate("Yen", 1, 1L),new Rate("Euro", 116, 5L),new Rate("Euro", 119, 7L));final static List<Order> orderList = Arrays.asList(new Order(2L, "Euro", 2L),new Order(1L, "US Dollar", 3L),new Order(50L, "Yen", 4L),new Order(3L, "Euro", 5L));public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);// order 实时流 事实表DataStream<Order> orderDs = env.fromCollection(orderList).assignTimestampsAndWatermarks(WatermarkStrategy.<Order>forBoundedOutOfOrderness(Duration.ofSeconds(10)).withTimestampAssigner((order, rTimeStamp) -> order.getOrder_time()));// rate 实时流 维度表DataStream<Rate> rateDs = env.fromCollection(rateList).assignTimestampsAndWatermarks(WatermarkStrategy.<Rate>forBoundedOutOfOrderness(Duration.ofSeconds(10)).withTimestampAssigner((rate, rTimeStamp) -> rate.getRate_time()));// 转变为TableTable orderTable = tenv.fromDataStream(orderDs, $("total"), $("currency"), $("order_time").rowtime());Table rateTable = tenv.fromDataStream(rateDs, $("currency"), $("rate"), $("rate_time").rowtime());tenv.createTemporaryView("alan_orderTable", orderTable);tenv.createTemporaryView("alan_rateTable", rateTable);// 定义一个TemporalTableFunctionTemporalTableFunction rateDim = rateTable.createTemporalTableFunction($("rate_time"), $("currency"));// 注册表函数// tenv.registerFunction("alan_rateDim", rateDim);tenv.createTemporarySystemFunction("alan_rateDim", rateDim);String sql = "select o.*,r.rate from alan_orderTable as o,Lateral table (alan_rateDim(o.order_time)) r where r.currency = o.currency ";// 关联查询Table result = tenv.sqlQuery(sql);// 打印输出DataStream resultDs = tenv.toAppendStream(result, Row.class);resultDs.print();// rate 流数据(维度表)// rateList// order 流数据// orderList// 控制台输出// 2> +I[2, Euro, 1970-01-01T00:00:00.002, 114]// 5> +I[50, Yen, 1970-01-01T00:00:00.004, 1]// 16> +I[1, US Dollar, 1970-01-01T00:00:00.003, 102]// 2> +I[3, Euro, 1970-01-01T00:00:00.005, 116]env.execute();}}
3、With connnector 实现代码
本处使用的是kafka作为数据源来实现。其验证结果在代码中的注释部分。
/** @Author: alanchan* @LastEditors: alanchan* @Description: */
package org.tablesql.join;import static org.apache.flink.table.api.Expressions.$;import java.time.Duration;
import java.util.Properties;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.TemporalTableFunction;
import org.apache.flink.types.Row;
import org.tablesql.join.bean.CityInfo;
import org.tablesql.join.bean.CityInfoSchema;
import org.tablesql.join.bean.UserInfo;
import org.tablesql.join.bean.UserInfoSchema;public class TestJoinDimByKafkaEventTimeDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);// Kafka的ip和要消费的topic,//Kafka设置Properties props = new Properties();props.setProperty("bootstrap.servers", "192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092");props.setProperty("group.id", "group.cyb.2");// 读取用户信息KafkaFlinkKafkaConsumer<UserInfo> userConsumer = new FlinkKafkaConsumer<UserInfo>("user", new UserInfoSchema(),props);userConsumer.setStartFromEarliest();userConsumer.assignTimestampsAndWatermarks(WatermarkStrategy.<UserInfo>forBoundedOutOfOrderness(Duration.ofSeconds(0)).withTimestampAssigner((user, rTimeStamp) -> user.getTs()) // 该句如果不加,则是默认为kafka的事件时间);// 读取城市维度信息KafkaFlinkKafkaConsumer<CityInfo> cityConsumer = new FlinkKafkaConsumer<CityInfo>("city", new CityInfoSchema(), props);cityConsumer.setStartFromEarliest();cityConsumer.assignTimestampsAndWatermarks(WatermarkStrategy.<CityInfo>forBoundedOutOfOrderness(Duration.ofSeconds(0)).withTimestampAssigner((city, rTimeStamp) -> city.getTs()) // 该句如果不加,则是默认为kafka的事件时间);Table userTable = tableEnv.fromDataStream(env.addSource(userConsumer), $("userName"), $("cityId"), $("ts").rowtime());Table cityTable = tableEnv.fromDataStream(env.addSource(cityConsumer), $("cityId"), $("cityName"),$("ts").rowtime());tableEnv.createTemporaryView("userTable", userTable);tableEnv.createTemporaryView("cityTable", cityTable);// 定义一个TemporalTableFunctionTemporalTableFunction dimCity = cityTable.createTemporalTableFunction($("ts"), $("cityId"));// 注册表函数// tableEnv.registerFunction("dimCity", dimCity);tableEnv.createTemporarySystemFunction("dimCity", dimCity);Table u = tableEnv.sqlQuery("select * from userTable");// u.printSchema();tableEnv.toAppendStream(u, Row.class).print("user流接收到:");Table c = tableEnv.sqlQuery("select * from cityTable");// c.printSchema();tableEnv.toAppendStream(c, Row.class).print("city流接收到:");// 关联查询Table result = tableEnv.sqlQuery("select u.userName,u.cityId,d.cityName,u.ts " +"from userTable as u " +", Lateral table (dimCity(u.ts)) d " +"where u.cityId=d.cityId");// 打印输出DataStream resultDs = tableEnv.toAppendStream(result, Row.class);resultDs.print("\t关联输出:");// 用户信息格式:// {"userName":"user1","cityId":1,"ts":0}// {"userName":"user1","cityId":1,"ts":1}// {"userName":"user1","cityId":1,"ts":4}// {"userName":"user1","cityId":1,"ts":5}// {"userName":"user1","cityId":1,"ts":7}// {"userName":"user1","cityId":1,"ts":9}// {"userName":"user1","cityId":1,"ts":11}// kafka-console-producer.sh --broker-list server1:9092 --topic user// 城市维度格式:// {"cityId":1,"cityName":"nanjing","ts":15}// {"cityId":1,"cityName":"beijing","ts":1}// {"cityId":1,"cityName":"shanghai","ts":5}// {"cityId":1,"cityName":"shanghai","ts":7}// {"cityId":1,"cityName":"wuhan","ts":10}// kafka-console-producer.sh --broker-list server1:9092 --topic city// 输出// city流接收到::6> +I[1, beijing, 1970-01-01T00:00:00.001]// user流接收到::6> +I[user1, 1, 1970-01-01T00:00:00.004]// city流接收到::6> +I[1, shanghai, 1970-01-01T00:00:00.005]// user流接收到::6> +I[user1, 1, 1970-01-01T00:00:00.005]// city流接收到::6> +I[1, shanghai, 1970-01-01T00:00:00.007]// user流接收到::6> +I[user1, 1, 1970-01-01T00:00:00.007]// city流接收到::6> +I[1, wuhan, 1970-01-01T00:00:00.010]// user流接收到::6> +I[user1, 1, 1970-01-01T00:00:00.009]// user流接收到::6> +I[user1, 1, 1970-01-01T00:00:00.011]// 关联输出::12> +I[user1, 1, beijing, 1970-01-01T00:00:00.001]// 关联输出::12> +I[user1, 1, beijing, 1970-01-01T00:00:00.004]// 关联输出::12> +I[user1, 1, shanghai, 1970-01-01T00:00:00.005]// 关联输出::12> +I[user1, 1, shanghai, 1970-01-01T00:00:00.007]// 关联输出::12> +I[user1, 1, shanghai, 1970-01-01T00:00:00.009]env.execute("joinDemo");}}以上,本文通过两个示例介绍了时态表TemporalTableFunction的join操作。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文更详细的内容可参考文章:
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
本专题分为以下几篇文章:
【flink番外篇】9、Flink Table API 支持的操作示例(1)-通过Table API和SQL创建表
【flink番外篇】9、Flink Table API 支持的操作示例(2)- 通过Table API 和 SQL 创建视图
【flink番外篇】9、Flink Table API 支持的操作示例(3)- 通过API查询表和使用窗口函数的查询
【flink番外篇】9、Flink Table API 支持的操作示例(4)- Table API 对表的查询、过滤操作
【flink番外篇】9、Flink Table API 支持的操作示例(5)- 表的列操作
【flink番外篇】9、Flink Table API 支持的操作示例(6)- 表的聚合(group by、Distinct、GroupBy/Over Window Aggregation)操作
【flink番外篇】9、Flink Table API 支持的操作示例(7)- 表的join操作(内联接、外联接以及联接自定义函数等)
【flink番外篇】9、Flink Table API 支持的操作示例(8)- 时态表的join(scala版本)
【flink番外篇】9、Flink Table API 支持的操作示例(9)- 表的union、unionall、intersect、intersectall、minus、minusall和in的操作
【flink番外篇】9、Flink Table API 支持的操作示例(10)- 表的OrderBy、Offset 和 Fetch、insert操作
【flink番外篇】9、Flink Table API 支持的操作示例(11)- Group Windows(tumbling、sliding和session)操作
【flink番外篇】9、Flink Table API 支持的操作示例(12)- Over Windows(有界和无界的over window)操作
【flink番外篇】9、Flink Table API 支持的操作示例(13)- Row-based(map、flatmap、aggregate、group window aggregate等)操作
【flink番外篇】9、Flink Table API 支持的操作示例(14)- 时态表的join(java版本)
【flink番外篇】9、Flink Table API 支持的操作示例(1)-完整版
【flink番外篇】9、Flink Table API 支持的操作示例(2)-完整版
相关文章:
【flink番外篇】9、Flink Table API 支持的操作示例(14)- 时态表的join(java版本)
Flink 系列文章 一、Flink 专栏 Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。 1、Flink 部署系列 本部分介绍Flink的部署、配置相关基础内容。 2、Flink基础系列 本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的…...

【leetcode100-30】【链表】两两交换链表节点
【题干】 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。 【思路】 先说递归的,退出条件很明显,当剩…...

小秋SLAM入门实战ubuntu所有文章汇总
Ubuntu系统安装详细教程 Ubuntu系统安装ROS详细教程 Ubuntu系统下如何搭建深度学习和SLAM开发环境 Ubuntu系统搭建SLAM开发环境 ubuntu 终端如何停止快速打印的输出以及恢复命令 ubuntu 终端如何快速打开当前路径下的图形化窗口界面? killall -9用途用法 ps -xu | …...
深度学习课程实验二深层神经网络搭建及优化
一、 实验目的 1、学会训练和搭建深层神经网络; 2、掌握超参数调试正则化及优化。 二、 实验步骤 初始化 1、导入所需要的库 2、搭建神经网络模型 3、零初始化 4、随机初始化 5、He初始化 6、总结三种不同类型的初始化 正则化 1、导入所需要的库 2、使用非正则化…...
Elasticsearch:Serarch tutorial - 使用 Python 进行搜索 (二)
这个是继上一篇文章 “Elasticsearch:Serarch tutorial - 使用 Python 进行搜索 (一)” 的续篇。在今天的文章中,我们接着来完成如何进行分页及过滤。 分页 - pagination 应用程序处理大量结果通常是不切实际的。 因此࿰…...

力扣labuladong——一刷day84
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、力扣743. 网络延迟时间 前言 Dijkstra 算法(一般音译成迪杰斯特拉算法)无非就是一个 BFS 算法的加强版,它们都是从二叉…...

Linux环境vscode clang-format格式化:vscode clang format command is not available
问题现象 vscode安装了clang-format插件,但是使用就报错 问题原因 设置中配置的clang-format插件工具路径不正确。 解决方案 确认本地安装了clang-format工具:终端输入clang-format(也可能是clang-format-13等版本,建议tab自…...
【KingbaseES】实现MySql函数WEEKS_BETWEEN
WEEKS_BETWEEN CREATE OR REPLACE FUNCTION weeks_between(start_date date, end_date date) RETURNS integer AS $$ BEGIN RETURN EXTRACT(WEEK FROM end_date) - EXTRACT(WEEK FROM start_date); END; $$ LANGUAGE plpgsql IMMUTABLE;结果展示...
@Scheduled定时任务现状与改进
项目场景: 定时任务现状:每个项目都会有一些配置信息,这些信息我们是都放在一个配置服务中,这个服务会定时从配置表中加载所有配置存入本地JVM内存,以供调用方获取(调用方集成了配置服务的SDK,…...
python+selenium爬虫笔记
本文只是做例子,具体网站路径麻烦你们换下,还有xpath路径也换下 一、安装所需要的组件(此处采用谷歌) 1、安装驱动 查看你的浏览器版本,去安装对应的版本 下载驱动 下载驱动路径 之前版本的 输入这个路径下载下来解压…...
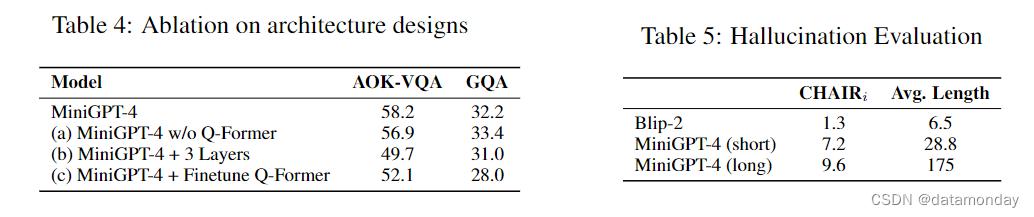
【LMM 009】MiniGPT-4:使用 Vicuna 增强视觉语言理解能力的多模态大模型
论文描述:MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models 论文作者:Deyao Zhu∗ Jun Chen∗ Xiaoqian Shen Xiang Li Mohamed Elhoseiny 作者单位:King Abdullah University of Science and Techn…...
SpringBoot学习(三)-整合JDBC、Druid、MyBatis
注:此为笔者学习狂神说SpringBoot的笔记,其中包含个人的笔记和理解,仅做学习笔记之用,更多详细资讯请出门左拐B站:狂神说!!! 一、整合JDBC使用(理解) 创建项目 勾选依赖启动器 查看依赖 …...

如何选择合适的语音呼叫中心?
市场上不同的语音呼叫中心提供商,都有其独特的优势和不足。企业在选择语音呼叫中心服务公司时,主要考虑以下因素:服务质量、价格、技术支持、客户支持等。 首先,服务质量是选择语音呼叫中心需关注的最重要因素之一。 为确保语音…...
使用qtquick调用python程序
一. 内容简介 使用qtquick调用python程序 二. 软件环境 2.1vsCode 2.2Anaconda version: conda 22.9.0 2.3pytorch 安装pytorch(http://t.csdnimg.cn/GVP23) 2.4QT 5.14.1 新版QT6.4,,6.5在线安装经常失败,而5.9版本又无法编译64位程序…...
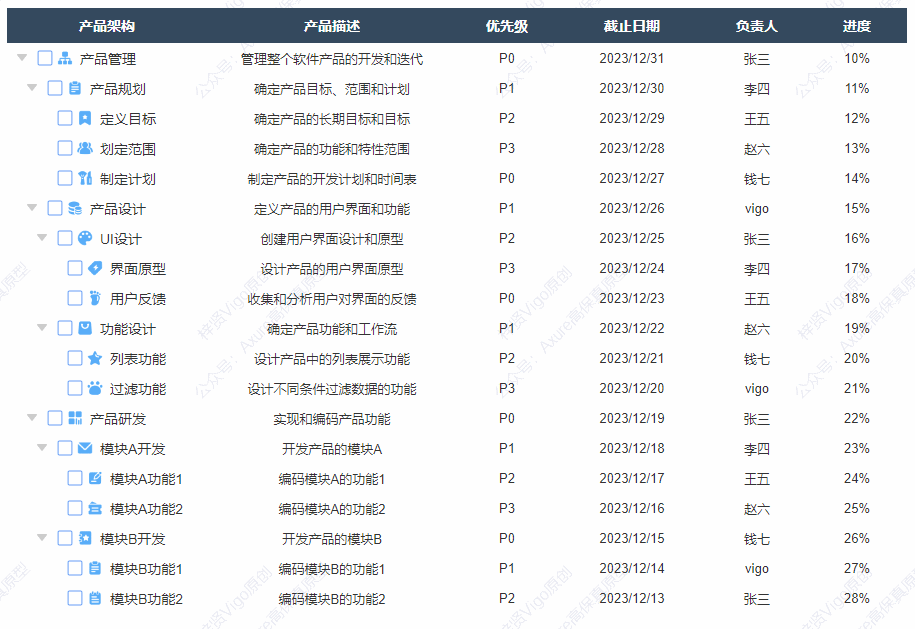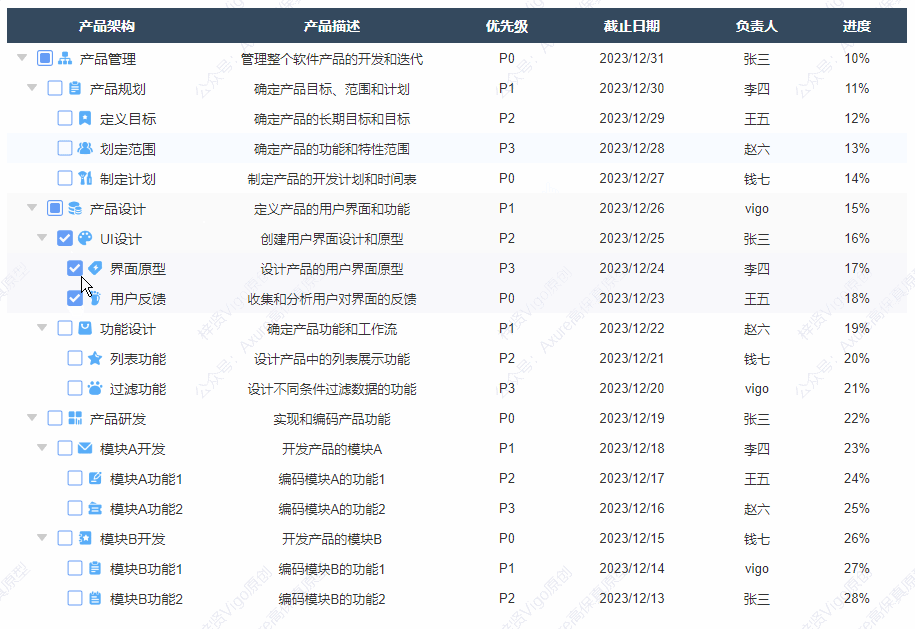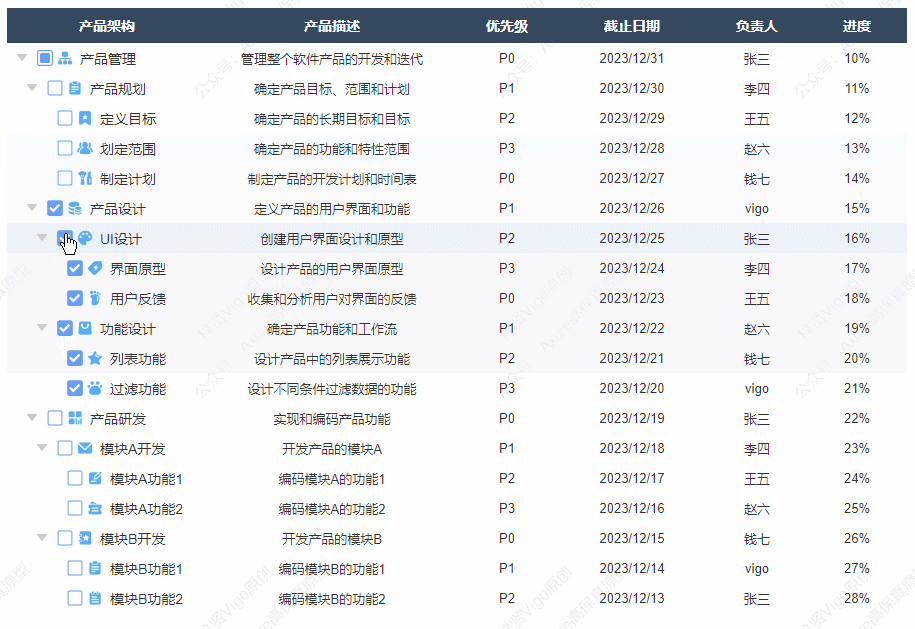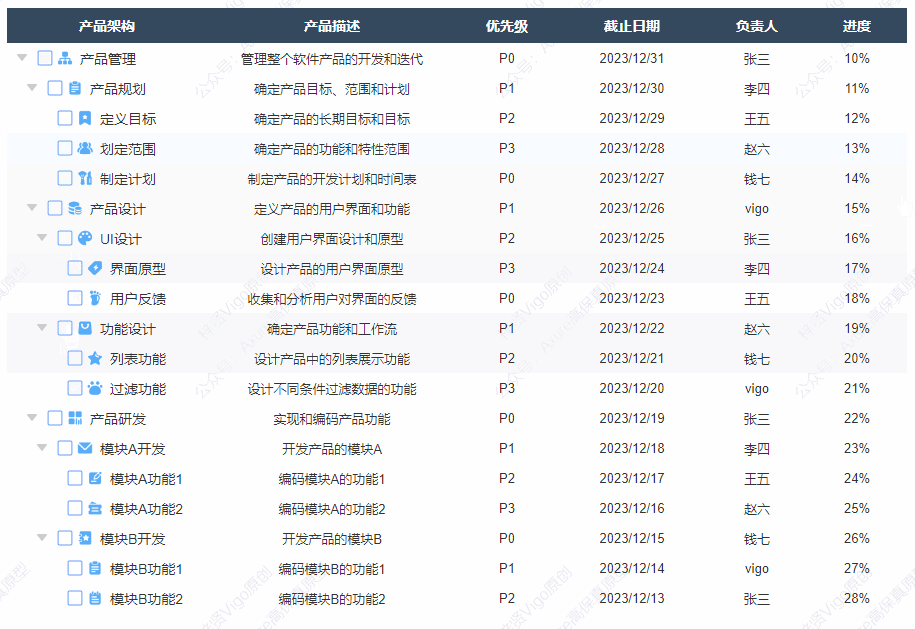
【Axure高保真原型】树形表格_多选效果
今天和大家分享树形表格_多选效果的原型模板,点击树的箭头可以展开或者收起子节点,点击多选按钮可以选中或取消选择该行以及子级行内容,同时反选父级行内容,父级行内容能根据子级选中的数量自动反选,包括全选、半选和未…...
【Filament】加载obj和fbx模型
1 前言 3D 模型的常用格式主要有 obj、fbx、gltf 等,Filament 中的 filamesh.exe 工具可以将 obj、fbx 格式转换为 filamesh 格式,然后再加载显示。对于 gltf 格式模型,可以通过 ModelViewer 加载显示,这不在本文的讨论范围内。 1…...

[USACO04OPEN] The Cow Lineup
题目描述 约翰的 N ( 1 ≤ N ≤ 100000 ) N ( 1 \leq N \leq 100000 ) N(1≤N≤100000) 只奶牛站成了一列。每只奶牛都写有一个号牌,表示她的品种,号牌上的号码在 1 … K &#x…...

软件工具集合
代码文档自动生成工具: Doxygen download 软件分析工具: perf gdb flamegraph 代码量统计: vscode插件:VS Code Counter 代码备注 vsocde插件: Line Note...

C#利用openvino部署PP-TinyPose人体姿态识别
【官方框架地址】 github.com/PaddlePaddle/PaddleDetection 【算法介绍】 关键点检测算法往往需要部署在轻量化、边缘端设备上,因此长期以来都存在一个难题:精度高、速度则慢、算法体积也随之增加。而PP-TinyPose的出世彻底打破了这个僵局,…...
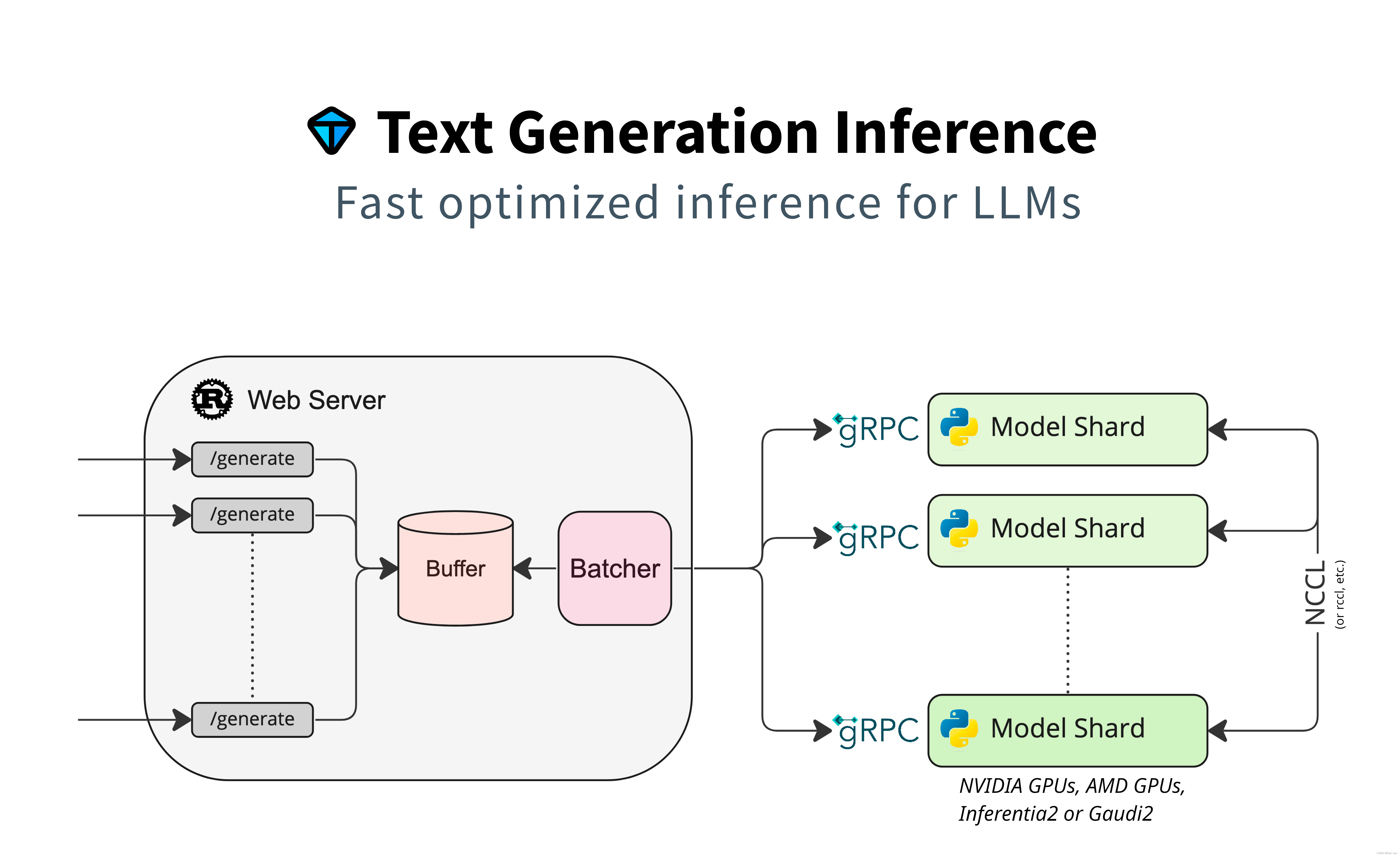
MindSpore Serving与TGI框架 の 对比
一、MindSpore Serving MindSpore Serving是一款轻量级、高性能的服务工具,帮助用户在生产环境中高效部署在线推理服务。 使用MindSpore完成模型训练>导出MindSpore模型,即可使用MindSpore Serving创建该模型的推理服务。 MindSpore Serving包含以…...

单片机I/O口阻抗特性及其在电路设计中的关键作用
1. 阻抗基础:从水管到电路的理解 第一次接触阻抗概念时,我盯着教科书上的公式发呆了半小时。直到有天修水管时突然开窍——这不就是水管的粗细对水流的影响吗?在电路中,阻抗就是电子流动遇到的"阻力"。但和水管不同&…...
)
告别网络烦恼:Stanza 1.5.1英文语言模型离线安装保姆级教程(Anaconda环境专用)
深度解析Stanza 1.5.1英文语言模型离线部署:Anaconda环境全流程实战 在企业内网或学术研究环境中,我们常常面临无法直接访问外部资源的情况。这时,掌握关键工具的离线部署能力就显得尤为重要。今天我们将全面剖析自然语言处理工具Stanza在受限…...

Java大文件分片上传完整实现教程
解决网络不稳定、服务器内存压力和用户体验差等问题是大文件分片上传的必要性。1. 分片上传允许在网络中断后只重传失败分片,提高成功率;2. 减少服务器单次处理的数据量,减少内存和i/o压力;3. 支持断点续传和秒传功能,…...

从零开始优化接口性能:QPS、TPS、OTPS、TP99的实战指南
从零开始优化接口性能:QPS、TPS、OTPS、TP99的实战指南 当你的电商系统在秒杀活动中突然崩溃,或是聊天机器人回复速度慢到用户流失时,性能指标就不再是枯燥的数字,而是决定业务存亡的关键。我曾经历过一次惨痛的教训:某…...

论文被吐槽逻辑乱?,有哪些真正实测靠谱的的降AI率工具推荐?
毕业论文降AIGC率,优先选语义重构 去AI痕迹 降查重率的工具,免费与付费结合最稳妥。下面按中文、英文、免费/付费分类推荐,附实测效果与适用场景。 一、中文论文降重工具(最常用) 1. 千笔AI(综合全能首选…...

BatchNorm实战避坑指南:为什么你的小批量训练总是不稳定?
BatchNorm实战避坑指南:小批量训练不稳定的深层解析与解决方案 1. 问题背景:为什么小批量训练总是不稳定? 在深度学习实践中,Batch Normalization(批归一化)已成为许多模型架构的标准组件。然而,…...

信号分析避坑指南:MATLAB里算相位差,为什么你的结果总是不准?
MATLAB相位差计算避坑指南:从频谱泄漏到四象限陷阱的深度解析 在信号处理领域,相位差计算看似简单却暗藏玄机。许多工程师在使用MATLAB进行相位差分析时,经常会遇到结果跳变、误差过大甚至完全不符合预期的情况。这并非MATLAB的"bug&quo…...

Qwen3-TTS-Tokenizer-12Hz实操手册:音频峰值检测与动态范围压缩联动
Qwen3-TTS-Tokenizer-12Hz实操手册:音频峰值检测与动态范围压缩联动 1. 引言:音频处理的关键挑战 音频处理中经常遇到两个棘手问题:一是音频信号动态范围过大导致某些部分听不清,二是峰值过高造成失真。传统方法需要分别处理这两…...

对于对话中的反讽识别,OpenClaw 的模型是否结合了语调特征?
关于OpenClaw模型在反讽识别中是否结合了语调特征,这个问题其实触及了当前自然语言处理中一个相当微妙的领域。从技术实现的角度来看,OpenClaw这类基于Transformer架构的大语言模型,其训练数据主要来源于互联网上的文本语料,比如网…...

如何用Java处理地震波?信号滤波算法
常用的地震波信号滤波算法包括傅里叶转换(fft)与频域滤波器、fir滤波器、iir滤波器和中值滤波器一起。. 通过将时域信号转换为频域,java可以通过apache实现特定频率组件的操作 commons math库中的fastfouriertransformer类实现;2.…...