# 技术详解: 利用CI同步文章以及多端发布

技术详解: 利用CI同步文章以及多端发布
- 技术详解: 利用CI同步文章以及多端发布
- 前言
- 文章的同步
- 实现的细节
- 思路
- 文章元数据的定义和提取
- 修改文章的优化
- 本地图片资源上传CDN并替换本地link
- 终于到了 CI 的部分了
- 最后来一些碎碎念
前言
前几天我更新了一篇简单技术总结之后,不少人都对里面的技术细节感兴趣,问我具体是怎么实现的?
于是为了给群友答疑解惑,接下来陆续会聊聊我自己的实现,这篇文章的这个方案已经运行了很多年了,很久没有更新,居然有一天会被人问到,也是比较欣喜的。当然,出于自身水平的限制,目前肯定有更好的方案,所以也欢迎提出建议和意见。
文章的同步
今天先来解答小伙伴第一个小问题,文章同步CI。
目前我实现的效果是,在一个 github 的私有仓库里,写文章,格式为 markdown,提交到云端后,就自动呈现在我的博客网站和博客小程序里。
同时,如果要对已经存在的文章,进行内容上的修改,或者隐藏和显示,所做的也只需要修改 markdown 文件内容,然后 git commit & push 就可以了。
实现的细节
思路
看到这个方案,下意识就想到了一种实现思路:即我们只需要上传文章内容到数据库,然后在 h5 和 weapp 应用里面,各自装一个适配的 markdown 渲染器,再各自调用后端接口,获取内容直接渲染呈现就行。
于是立即动手开干,先设计数据库,再实现一下后端,最后再写个前端,然后就实现完成了。在实现的时候就会发现,创建一篇文章,并保存到数据库是很容易的,流程无非就是 fs 读取一下内容,提交到 createArticle 接口就完成了。然而,这个方案并没有解决文章的修改和删除问题。
那么,如何让修改后的文章push到remote的时候,也让程序知道是哪一篇文章被修改了,从而进行相应的数据库操作呢?显然基于文章标题或者内容的查询都是不妥的,因为它们都有被修改的可能。
所以这种情况下,我们必须给每一篇文章,设置一个唯一的 UNIQUE ID,这个 UNIQUE ID 不必是数据主键,只需要给它一个唯一性的约束即可。
新的问题接踵而至,这个 UNIQUE ID 应该在哪里进行体现,从而让我们写的文件扫描读取脚本,在获取内容的同时获取到它呢?
文章元数据的定义和提取
这个问题第一眼,我们可能会想到这样的解决方案:这些信息可以体现在文件的名称上呀!比如我们写了一篇文章,文件名叫 如何让霸道富婆爱上我_20230302_520_true.md,我们约定文件名格式为:${title}_${date}_${unique_id}_${valid}.md。这样在扫描的时候,除了获取文件的内容之外,还可以获取到这些信息,再把它们插入到数据库表里,这样似乎就解决了修改和隐藏显示的问题了!
然而这个方案却有一个很大的缺陷,即扩展性很差。这体现在,一旦文件元数据(metadata)多起来,很有可能会出现这样的文件名: 论答辩自产自销造就新时代经济永动机_20230303_666_true_1_999_fuck_your.md,这种文件名称,本身就是一坨答辩。而且每次要修改元数据提交,还会被 git 认为是新创建的文件,显然不好。
所以,我们不应该从文件名提取内容,而应该把这些文章的元数据,放在 md 文件内容中的一块指定区域里,比如放在文章开头。再通过 json/yml 这种格式,来把文章的元数据体现出来。然后再用特殊的分隔线,分隔元数据区域和内容区域。这样我们就可以在代码里,对文件内容块进行各自的处理,元数据区域用 JSON.parse/ js-yaml parse 进行解析,内容区域以字符串形式处理。这有没有让你想到 *.vue 文件的 template,script 和 style 区域块?
当然这个markdown提取分离方式,我之前找的时候也发现 gray-matter 这个 npm 包可以满足这样的需求。所以推荐使用它,将它加入你的文件扫描脚本中,去提取和分离元数据。
这里也给出一个示例:
---yml
unique_id: 20220330
title: 'icebreaker的垃圾话学习指南'
date: 2022-03-30
description: '不得不学会的垃圾话'
authors: - icebreaker
tags: - 'Trash-talk'
---# icebreaker的垃圾话学习指南...{{content}}...
修改文章的优化
按照上面的做法,我们看似解决了 CRUD 的问题,但是实现后我们会发现,这个做法效率太低了。比如你现在有 1000 篇文章,你改了 500 篇,难道你要让服务端依次把这 1000 篇的文章所有的元数据和内容,一个一个从数据库里取出来,然后和你 git 仓库里的文章,一个字段,一个字段进行比对,然后再把有改动的记录下来,执行 UPDATE 语句?
试想一下,你写了一本 绘声绘色的小黄书 准备发布,好几万个字,发布完了,一分钟后违规通知接踵而至,你需要修改内容。你改完之后,提交发布了,服务器去数据库里,取出原先那巨大的字符串到内存里,再和你提交的另外一坨巨大字符串(也在内存里)做是否相等的判断,而且这个行为还要重复很多次。服务器回复:地铁老人手机.jpg。
显然效率太低了,我们需要更精准的做法。所以我们在进行修改文章的时候,不应该拉出这么多的数据去进行比对,而是要充分利用 文件摘要算法 进行效率上的优化。
所以这里我选择 MD5,来对所有的元数据和内容做一个摘要,并且在一开始创建文章的时候,就把 Digest(摘要)存入数据库中,这样在修改的时候,就只要比较摘要是否相等这个结果,相等就跳过,不相等就执行 UPDATE。
用代码实现一下,就是:
const klaw = require('klaw')
const matter = require('gray-matter')
const md5 = require('md5')
const normalizeNewline = require('normalize-newline')async function getArticles () {const articles = []for await (const { path: klawPath, stats } of klaw(path.resolve(__dirname, 'path/to/articles'))) {if (path.extname(klawPath) === '.md' && stats.isFile()) {const str = await fs.readFile(klawPath, {encoding: 'utf-8'})const { content, data, orig } = matter(normalizeNewline(str))const digest = md5(orig)articles.push(createArticle({authors: data.authors,// 数据库字段叫 md5 放的就是 digest 摘要md5: digest,content,uniqueId: data.uniqueId,description: data.description,tags: data.tags,title: data.title}))}}return articles
}
这里有一个坑点,为什么需要 normalizeNewline?这源自于 win 和 linux/unix 这种默认的 EOL(End of Line) 的不同(其实就是老生常谈的\r\n和\n问题),这会导致在不同的系统上,文件摘要计算结果的不一致。所以我们需要预先 normalize 一下,这是使用 windows 会遇到的坑点之一,之二是 BOM。
接下来要做的,就是把这些文章结果进行分拣,分拣出哪些需要 insert,哪些需要 update 和 delete 的。这里可以在服务端写一个同步前的预检接口,返回数据库里文章数据,构建成一个这样结构: Map<uniqueId,md5>,这样就可以把所有本地的文章和这个 Map 进行执行策略上的映射:
- 假如这个
Map中,没有当前文章这个uniqueId, 则意味着这条数据要新增。 - 假如有这个
uniqueId,但是这个文章的valid标志位被设置为了false, 则意味着要softDelete或者置一个状态的标识位,让它不显示。 - 假如有这个
uniqueId,且数据是有效的(valid不为false),但是md5 digest的值不相等,则意味着这条数据要更新。 - 否则直接跳过,什么都不做
以上便是本地和远程数据库同步的逻辑。
本地图片资源上传CDN并替换本地link
我们可以用 regex(正则),或者 markdown ast 进行文件内容的匹配提取,匹配  成功后,获取后面的本地引用地址,fs 读取之后,上传到你的 oss,然后你的 oss 又关联了 cdn,那对应的 cdn 地址不就有了吗?本地替换一下就行。
推荐有闲钱的同学,可以这样搞。不想花钱的,可以去使用一些免费图床。
终于到了 CI 的部分了
没想到文章的 CRUD 就写了这么多的篇幅,终于到了 Github Action 的配置了,也很简单,核心就执行几段脚本,看我注释就知道都干了啥:
name: 'sync-article'on:# 允许手动触发workflow_dispatch:# 只有 main 分支的 content 下有 md 文件改动,才触发push:branches:- mainpaths:- 'content/**/*.md'jobs:# 同步 jobsync:runs-on: ubuntu-lateststeps:- uses: actions/checkout@v3- uses: actions/setup-node@v3with:# node_modules 缓存 node-version: 16cache: yarncache-dependency-path: 'yarn.lock'- run: yarn --production# 扫描提取仓库文章,然后对数据库进行 CRUD 操作- run: yarn sync# (可选) 重新部署 website 上传到 oss 静态网站并刷新 cdn 缓存- run: yarn website:deploy
最后来一些碎碎念
可能你看到我这篇文章,是在我的小程序上,其实我的小程序因为一些审核的原因,已经快一年没有更新了,同时我也关闭了评论系统,为了内容安全。
还有获取文章内容的接口,一定要用 token 保护好,入参也尽量使用uuid这种无法找到规律的字符串,不然很容易就被爬接口一下子全爬下来了(当然直接抓html还是可以的,你可以放一些垃圾在里面)。
还有,假如你使用的是那种,nextjs/nuxtjs 里一些基于文件系统的CMS npm包(比如@nuxtjs/content),然后你还要开源的话,你应该把你的文章放入另外一个私有仓库,然后通过git submodule 把它添加进来,接着在运行和部署的时候,通过软连接,放入这类内容CMS包的指定文件夹中,这点 Github Action 也是能做到的。
- name: Checkout Self Repouses: actions/checkout@v3with:submodules: 'true'token: ${{ secrets.PAT }}
相关文章:
# 技术详解: 利用CI同步文章以及多端发布
技术详解: 利用CI同步文章以及多端发布 技术详解: 利用CI同步文章以及多端发布 前言文章的同步实现的细节 思路文章元数据的定义和提取修改文章的优化本地图片资源上传CDN并替换本地link 终于到了 CI 的部分了最后来一些碎碎念 前言 前几天我更新了一篇简单技术总结之后&am…...

分形维数的计算方法汇总
以下是常用的时间序列分形维数计算方法及相应的参考文献:Hurst指数法Hurst指数法是最早用于计算分形维数的方法之一,其基本思想是通过计算时间序列的长程相关性来反映其分形特性。具体步骤是:(1) 对原始时间序列进行标准化处理。(2) 将序列分…...
)
微积分小课堂:积分(从微观趋势了解宏观变化)
文章目录 引言I. 预备知识: 积分效应1.1 闯黄灯1.2 公司利润(飞轮效应)1.3 飞轮效应II 积分2.1 积分的计算2.2 积分思想的本质引言 微分解决的问题是从宏观变化了解微观趋势;积分和微分刚好相反,是从微观去看宏观变化。 通过积分效应,提升我们的认识水平,同时能用一些工…...
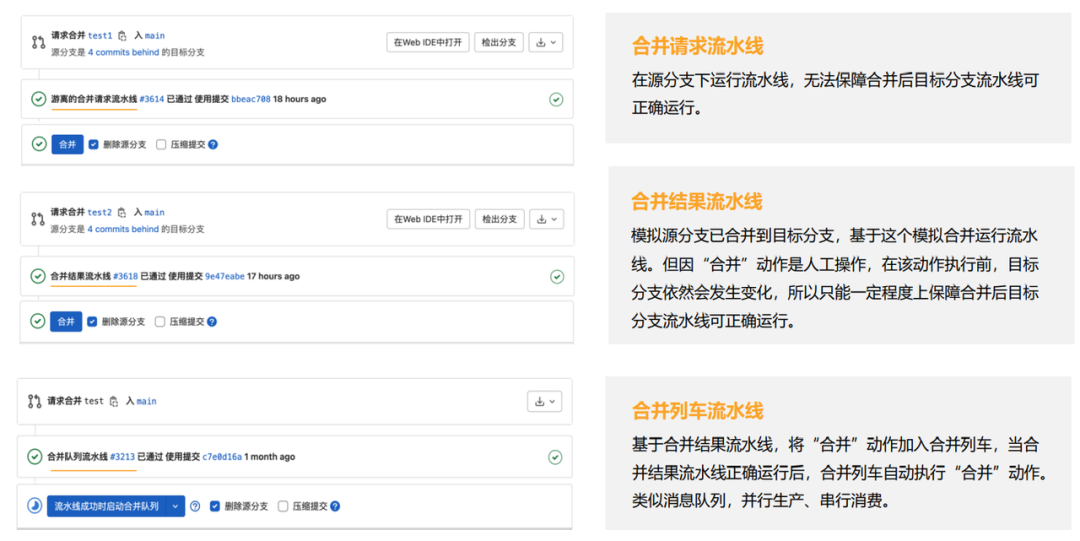
4道数学题,求解极狐GitLab CI 流水线|第4题:合并列车
本文来自: 武让 极狐GitLab 高级解决方案架构师 💡 极狐GitLab CI 依靠其一体化、轻量化、声明式、开箱即用的特性,在开发者群体中的使用率越来越高,在国内企业中仅次于 Jenkins ,排在第二位。 极狐GitLab 流水线有 4…...

代码规范简述
目录 命名规范 代码格式 OOP规约 集合规范 并发规范 SQL语句规范 SQL 建表规范 SQL 索引规范 SQL 查询规范 控制语句规范 Javadoc 规范 其他规范 命名规范 1、包名:使用小写字母,多个单词之间用"."分隔,例如ÿ…...

【Java集合框架】篇五:Map接口
1. Map及实现类特点 Map:存储key-value HashMap:线程不安全,效率高,key和value都可以为null,底层使用 数组单向链表红黑树 结构(jdk8)。 LinkedHashMap:是HashMap的子类࿰…...

Typroa安装教程
Markdown 是一种轻量级标记语言,创始人为约翰格鲁伯(John Gruber)。 它允许人们使用易读易写的纯文本格式编写文档,然后转换成有效的 XHTML(或者HTML)文档。这种语言吸收了很多在电子邮件中已有的纯文本标记…...
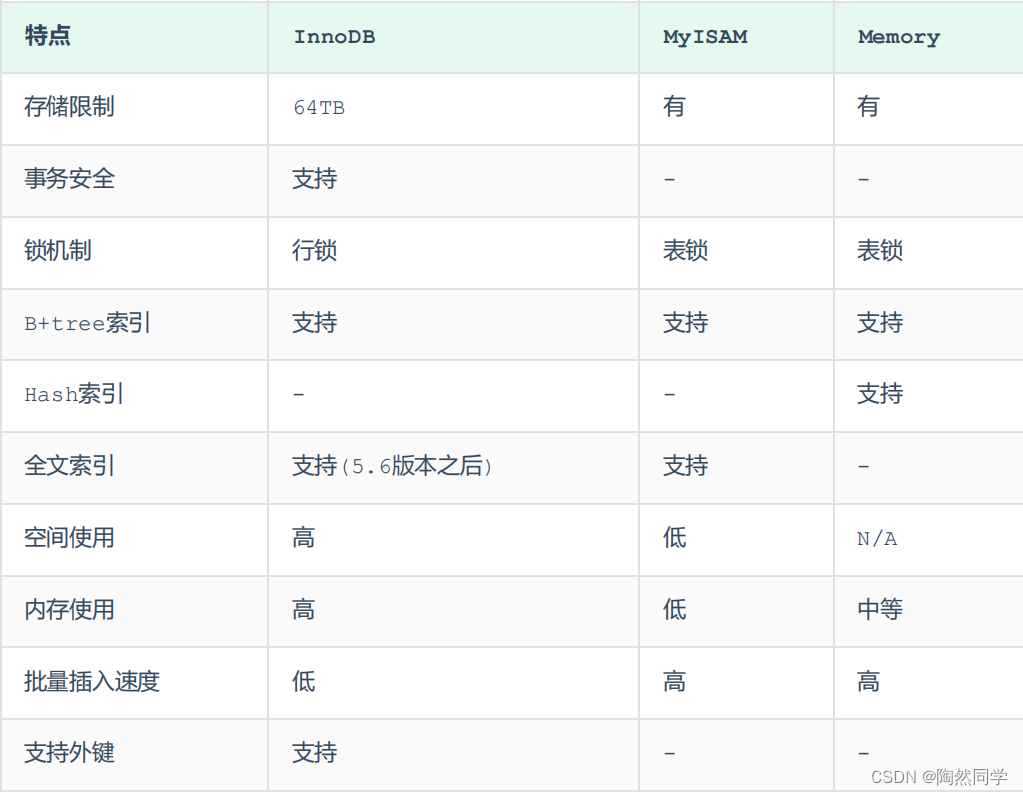
【MySQL】存储引擎
目录 1.MySQL体系结构 2.存储引擎介绍 3.存储引擎特点 4.存储引擎选择 1.MySQL体系结构 MySQL整体的逻辑结构可以分为4层,客户层、服务层、存储引擎层、数据层 客户层 客户层:进行相关的连接处理、权限控制、安全处理等操作 服务层 服务层负责与客户层进行连接处理、处…...
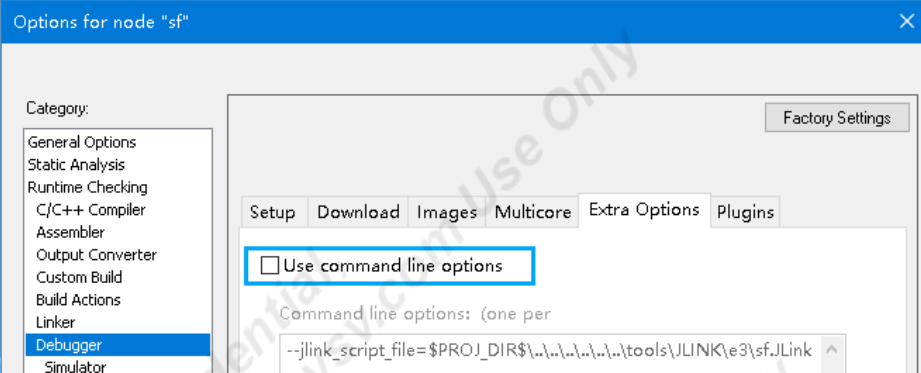
芯驰(E3-gateway)开发板环境搭建以及调试遇到问题的解决
1-Windows下环境配置 可以在Windows上使用命令行或者IAR IDE编译SSDK项目。Windows编译依赖的工具已经包含在 prebuilts/windows 目录中,包括编译器、Python和命令行工具。 1.1.1 CMD SSDK集成 msys 工具,可以在Windows命令行中完成SDK的配置、编译和…...
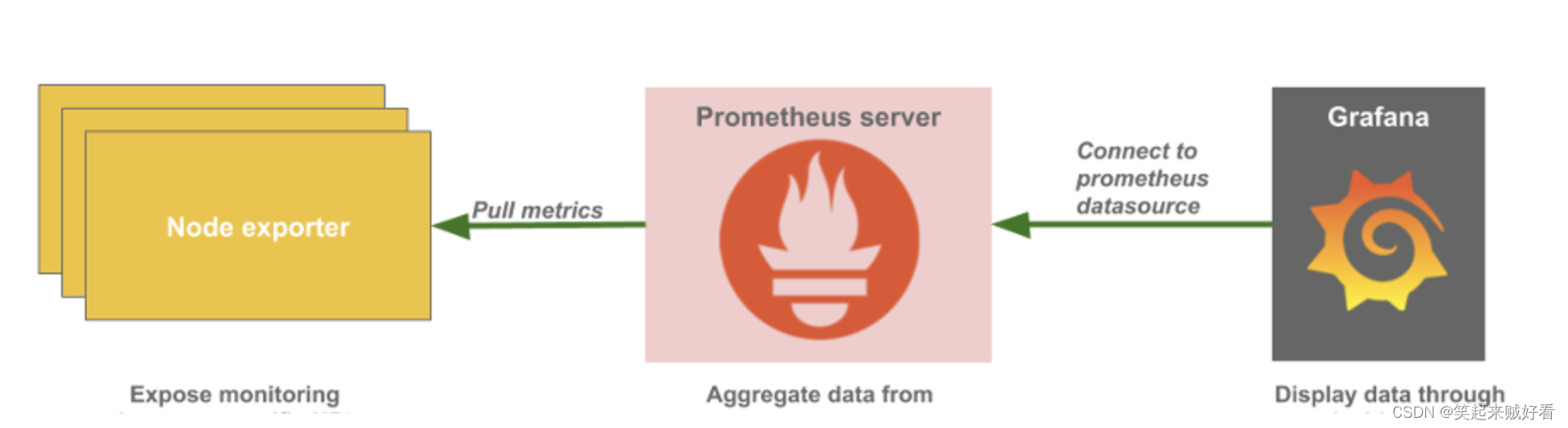
【大数据监控】Prometheus、Node_exporter、Graphite_exporter安装部署详细文档
目录Prometheus简介下载软件包安装部署创建用户创建Systemd服务修改配置文件prometheus.yml启动Prometheusnode exporter下载软件包安装部署添加用户创建systemd服务启动node_exportergraphite_exporter下载软件包安装部署创建systemd服务启动 graphite_exporterPrometheus 简介…...

《C++ Primer》 第十一章 关联容器
《C Primer》 第十一章 关联容器 11.1 使用关联容器 使用map: //统计每个单词在输入中出现的次数 map<string, size_t> word_count;//string到size_t的空map string word; while(cin>>word)word_count[word];//提取word的计数器并将其加1 for(const auto &w:…...

WebRTC标准与框架解读(1)
1、如果让我来设计webrtc框架我在分析源码的时候,都喜欢做这样一件事情:如果让我来设计它,我会怎么做?大家可以紧跟我的思路,分析一下WebRTC为什么如此设计。为了对整个框架有有一个全面的了解,我们首先要做…...
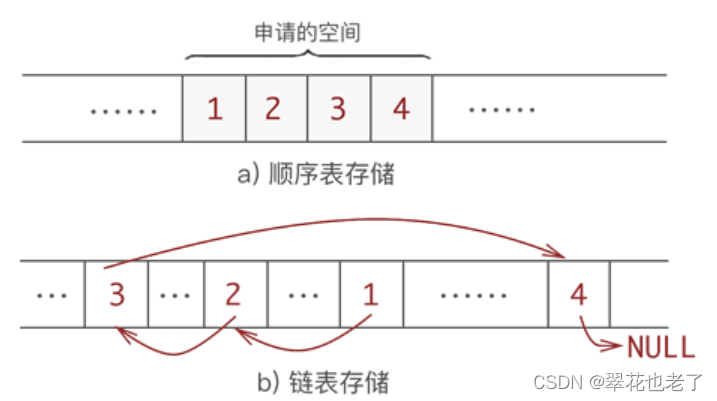
数据结构的一些基础概念
一 基本术语 数据:是描述客观事物的符号,是计算机中可以操作的对象,是能被计算机识别,并输入给计算机处理的符号集合。 数据元素:是组成数据的,有一定意义的基本单位,在计算机中通常作为整体处…...

【Python每日一练】总目录(不断更新中...)
Python 2023.03 20230303 1. 两数之和 ★ 2. 组合总和 ★★ 3. 相同的树 ★★ 20230302 1. 字符串统计 2. 合并两个有序链表 3. 下一个排列 20230301 1. 只出现一次的数字 2. 以特殊格式处理连续增加的数字 3. 最短回文串 Python 2023.02 20230228 1. 螺旋矩阵 …...
)
latex插入图片(自用)
加入宏包:\usepackage{graphicx} 使用 \includegraphics 命令进行插图。 \includegraphics[]{}: 第一参数[]:对图片做一些适当的调整(设定图片的高度和宽度或者按比例缩放) 第二参数{}:图片的名字…...

【微信小程序】-- 网络数据请求(十九)
💌 所属专栏:【微信小程序开发教程】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! &…...

K8S 实用工具之一 - 如何合并多个 kubeconfig?
开篇 📜 引言: 磨刀不误砍柴工工欲善其事必先利其器 K8S 集群规模,有的公司倾向于少量大规模 K8S 集群,也有的公司会倾向于大量小规模的 K8S 集群。 如果是第二种情况,是否有一个简单的 kubectl 命令来获取一个 kubec…...
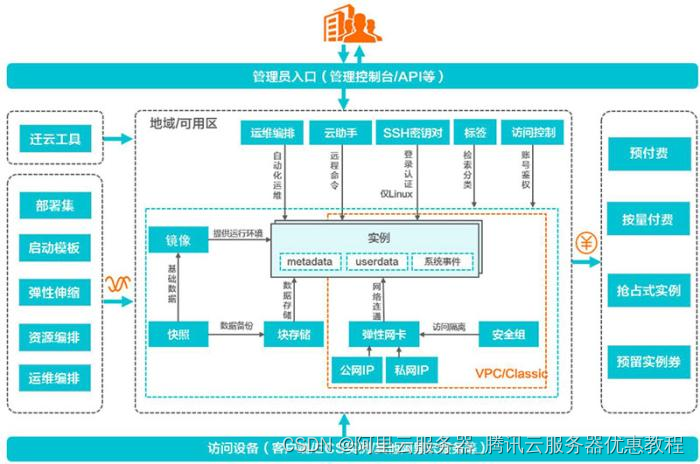
阿里云ECS服务器的6大功能组件
阿里的云服务在国内可以说是首屈一指的了,因此他们家的云服务器也是最受欢迎的。那么,你知道阿里云服务器ECS有哪些功能组件吗?不清楚不要紧,下面服务器吧小编带大家来看看。 在了解之前我们来看一张阿里云服务器ECS的产品组件架…...

外贸建站多少钱?不同预算对应的建站方案!
外贸建站多少钱? 答案是:3000左右。 作为一个外贸企业的经营者,我们深知一个优质的外贸网站对于企业的重要性。 然而,建立一个优质的外贸网站需要耗费大量的时间和资金,因此我们需要在预算有限的情况下,…...
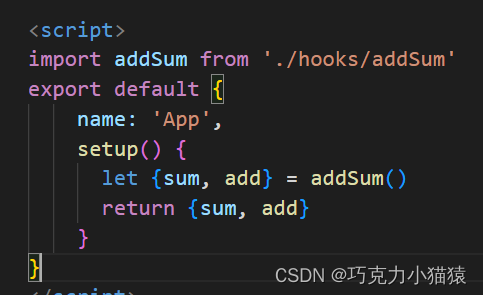
Vue3中hook的使用及使用中遇到的坑
目录前言一,什么是hook二, hook函数的使用2.1 铺垫2.2 hook函数的写法2.3 使用写好的hook函数后记前言 在学习Es6的时候,我们开始使用类与对象,开始模块化管理;在Vue中我们可以使用mixin进行模块化管理;Vu…...

免费LLM API实战指南:从选型到架构设计,低成本构建AI应用
1. 项目概述与核心价值 最近在折腾一些AI应用原型,或者想给现有产品加个智能对话功能,第一反应往往是去找OpenAI的API。但说实话,对于个人开发者、学生,或者只是想低成本验证想法的小团队来说,GPT-4级别的API调用费用&…...

SDR++:跨平台无线电接收软件入门实战指南
SDR:跨平台无线电接收软件入门实战指南 【免费下载链接】SDRPlusPlus Cross-Platform SDR Software 项目地址: https://gitcode.com/GitHub_Trending/sd/SDRPlusPlus 想要探索软件定义无线电的奇妙世界却不知从何入手?SDR作为一款轻量级、跨平台的…...

构建 AI Agent 应用商店的构想
构建 AI Agent 应用商店的构想:从“单骑救主”的工具到“生态协同”的智能枢纽关键词 AI Agent、应用商店、多Agent协作、工具调用链、Prompt工程标准化、安全沙箱、智能分发摘要 当你在凌晨2点对着一份混乱的月度财务报表焦虑时,有没有想过:…...

All-in-One Telegram机器人:加密货币监控与多功能集成部署指南
1. 项目概述 如果你和我一样,是个喜欢折腾各种效率工具,同时又对加密货币市场保持关注的玩家,那你肯定也经历过这样的场景:手机里塞满了各种功能的机器人——一个用来监控币价,一个用来下载视频,一个用来处…...
PyVideoTrans终极指南:5分钟掌握视频翻译与配音的完整流程
PyVideoTrans终极指南:5分钟掌握视频翻译与配音的完整流程 【免费下载链接】pyvideotrans Translate the video from one language to another and embed dubbing & subtitles. 项目地址: https://gitcode.com/gh_mirrors/py/pyvideotrans PyVideoTrans是…...
3分钟快速上手TransNet V2:视频镜头检测的终极完整指南
3分钟快速上手TransNet V2:视频镜头检测的终极完整指南 【免费下载链接】TransNetV2 TransNet V2: Shot Boundary Detection Neural Network 项目地址: https://gitcode.com/gh_mirrors/tr/TransNetV2 在视频内容爆炸式增长的今天,如何快速准确地…...

微信单向好友检测实战:3步智能发现谁悄悄删除了你
微信单向好友检测实战:3步智能发现谁悄悄删除了你 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFriends 你…...

从Apple TV与Fire TV拆解看硬件成本、供应链策略与商业逻辑差异
1. 项目概述:一场跨越两年的硬件成本对决作为一名长期关注消费电子硬件设计与供应链的从业者,我始终对设备背后的物料成本(BOM)分析抱有浓厚兴趣。这不单单是看热闹,更是理解厂商商业策略、产品定位乃至未来迭代方向的…...

终极SPT-AKI存档编辑器使用指南:快速掌握塔科夫单机版角色定制
终极SPT-AKI存档编辑器使用指南:快速掌握塔科夫单机版角色定制 【免费下载链接】SPT-AKI-Profile-Editor Программа для редактирования профиля игрока на сервере SPT-AKI 项目地址: https://gitcode.com/gh_m…...

基于WebAssembly的高效SQLite数据库在线解析方案
基于WebAssembly的高效SQLite数据库在线解析方案 【免费下载链接】sqlite-viewer View SQLite file online 项目地址: https://gitcode.com/gh_mirrors/sq/sqlite-viewer SQLite Viewer是一款采用纯前端技术的SQLite数据库在线查看工具,通过WebAssembly技术实…...