Kafka高级应用:如何配置处理MQ百万级消息队列?
在大数据时代,Apache Kafka作为一款高性能的分布式消息队列系统,广泛应用于处理大规模数据流。本文将深入探讨在Kafka环境中处理百万级消息队列的高级应用技巧。
本文,已收录于,我的技术网站 ddkk.com,有大厂完整面经,工作技术,架构师成长之路,等经验分享
1、合理配置分区
// 自定义分区策略
public class CustomPartitioner implements Partitioner {@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {// 根据key分配分区int partitionCount = cluster.partitionCountForTopic(topic);return (key.hashCode() & Integer.MAX_VALUE) % partitionCount;}// 其他必要的方法实现...
}这段代码展示了如何创建一个自定义分区器。它根据消息键值的哈希值将消息分配到不同的分区,有助于均衡负载和提高并发处理能力。
2、消息批量处理
Properties props = new Properties();
props.put("bootstrap.servers", "kafka-server1:9092,kafka-server2:9092");
props.put("linger.ms", 10); // 消息延迟时间
props.put("batch.size", 16384); // 批量大小// 创建生产者实例
KafkaProducer<String, String> producer = new KafkaProducer<>(props);通过linger.ms和batch.size的设置,生产者可以积累一定数量的消息后再发送,减少网络请求,提高吞吐量。
3、消息压缩策略
props.put("compression.type", "snappy"); // 启用Snappy压缩算法// 创建生产者实例
KafkaProducer<String, String> producer = new KafkaProducer<>(props);这段代码启用了Snappy压缩算法。数据压缩可以显著减少消息的大小,提高网络传输效率。
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。
这是大佬写的, 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
4、消费者群组和负载均衡
Properties consumerProps = new Properties();
consumerProps.put("bootstrap.servers", "kafka-server1:9092,kafka-server2:9092");
consumerProps.put("group.id", "consumer-group-1"); // 消费者群组
consumerProps.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumerProps.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");// 创建消费者实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps);在这段代码中,通过配置不同的消费者群组(group.id),可以实现负载均衡和高效的消息消费。
5、Kafka流处理
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> kstream = builder.stream("source-topic");
kstream.mapValues(value -> "Processed: " + value).to("destination-topic");// 创建并启动Kafka Streams应用
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();这段代码使用Kafka Streams API实现了简单的流处理。这允许对数据流进行实时处理和分析。
6、幂等性生产者配置
Properties props = new Properties();
props.put("bootstrap.servers", "kafka-server1:9092,kafka-server2:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("enable.idempotence", true); // 启用幂等性// 创建生产者实例
KafkaProducer<String, String> producer = new KafkaProducer<>(props);通过设置enable.idempotence为true,可以确保生产者即使在网络波动等情况下也不会产生重复数据。
7、消费者偏移量管理
consumerProps.put("enable.auto.commit", false); // 关闭自动提交偏移量
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps);// 在应用逻辑中手动提交偏移量
while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {// 处理消息// ...// 手动提交偏移量consumer.commitSync();}
}关闭自动提交并手动控制偏移量的提交,可以更精确地控制消息的消费状态,避免消息丢失或重复消费。
8、使用Kafka Connect集成外部系统
// Kafka Connect配置示例(通常为JSON格式)
{"name": "my-connector","config": {"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector","tasks.max": "1","topics": "my-topic","connection.url": "jdbc:mysql://localhost:3306/mydb","key.converter": "org.apache.kafka.connect.json.JsonConverter","value.converter": "org.apache.kafka.connect.json.JsonConverter",// 更多配置...}
}这个示例展示了如何配置Kafka Connect来连接外部系统(如数据库)。Kafka Connect是一种流行的方式,用于在Kafka和其他系统之间高效地传输数据。
9、Kafka安全配置
props.put("security.protocol", "SSL");
props.put("ssl.truststore.location", "/var/private/ssl/kafka.client.truststore.jks");
props.put("ssl.truststore.password", "test1234");
props.put("ssl.keystore.location", "/var/private/ssl/kafka.client.keystore.jks");
props.put("ssl.keystore.password", "test1234");
props.put("ssl.key.password", "test1234");// 创建安全的生产者或消费者实例
KafkaProducer<String, String> producer = new KafkaProducer<>(props);配置SSL/TLS可以为Kafka通信增加加密层,提高数据传输的安全性。
10、Kafka监控与运维
// Kafka监控的伪代码示例
Monitor monitor = new KafkaMonitor(kafkaServers);
monitor.on("event", event -> {if (event.type == EventType.BROKER_DOWN) {alert("Broker down: " + event.brokerId);}// 其他事件处理...
});monitor.start();虽然这是一个伪代码示例,但它展示了如何监控Kafka集群的关键事件(如Broker宕机),并根据需要采取相应的响应措施。在实际生产环境中,可以使用各种监控工具和服务来实现类似的功能。
本文总结
Kafka在处理大规模、高吞吐量的消息队列方面有着突出的性能。通过合理配置分区、优化批量处理、应用消息压缩、设置消费者群组和利用流处理,可以有效地提高Kafka处理百万级消息队列的能力。当然,这些技巧的应用需要结合具体的业务场景和环境来调整和优化。
项目文档&视频:
开源:项目文档 & 视频 Github-Doc
本文,已收录于,我的技术网站 ddkk.com,有大厂完整面经,工作技术,架构师成长之路,等经验分享
求一键三连:点赞、分享、收藏
点赞对我真的非常重要!在线求赞,加个关注我会非常感激!
相关文章:

Kafka高级应用:如何配置处理MQ百万级消息队列?
在大数据时代,Apache Kafka作为一款高性能的分布式消息队列系统,广泛应用于处理大规模数据流。本文将深入探讨在Kafka环境中处理百万级消息队列的高级应用技巧。 本文,已收录于,我的技术网站 ddkk.com,有大厂完整面经…...

LIN总线学习笔记(1)-总线传输规范
关注菲益科公众号—>对话窗口发送 “CANoe ”或“INCA”,即可获得canoe入门到精通电子书和INCA软件安装包(不带授权码)下载地址。 接触LIN是从最近负责项目中开始的。项目已经快要量产了,因为中间遇到的大大小小的问题…...

Qt界面篇:Qt停靠控件QDockWidget、树控件QTreeWidget及属性控件QtTreePropertyBrowser的使用
1、功能介绍 本篇主要使用Qt停靠控件QDockWidget、树控件QTreeWidget及Qt属性控件QtTreePropertyBrowser来搭建一个简单实用的主界面布局。效果如下所示。 2、控件使用详解 2.1 停靠控件QDockWidget QDockWidget可以停靠在 QMainWindow 内或作为桌面上的顶级窗口浮动。默认值…...
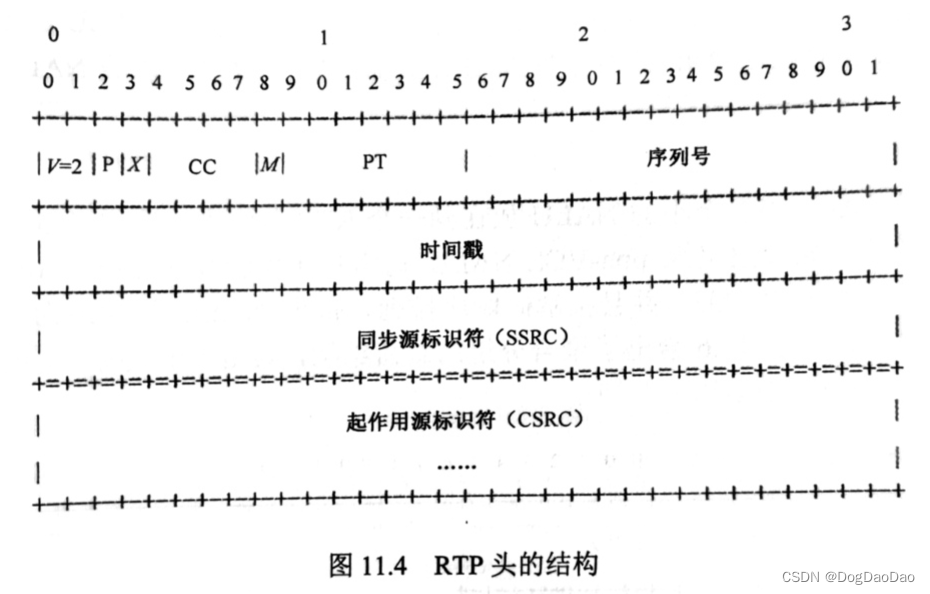
H266/VVC网络适配层概述
视频编码标准的分层结构 视频数据分层的必要性:网络类型的多样性、不同的应用场景对视频有不同的需求。 编码标准的分层结构:为了适应不同网络和应用需求,视频编码数据根据其内容特性被分成若干NAL单元(NAL Unit,NALU…...
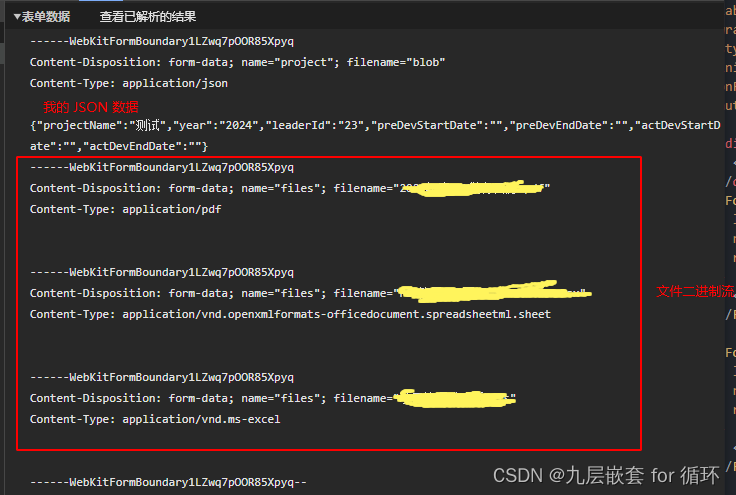
new FormData 同时发送表单 json 以及文件二进制流
需要新增时同时发送表单 json 以及对应的文件即可使用以下方法传参 let formDataParams new FormData(); 首先通过 new FormData() 创建你需要最后发送的表单 接着将你的对象 json 存储,注意使用 new Blob 创建大表单转换成 json 格式。以…...
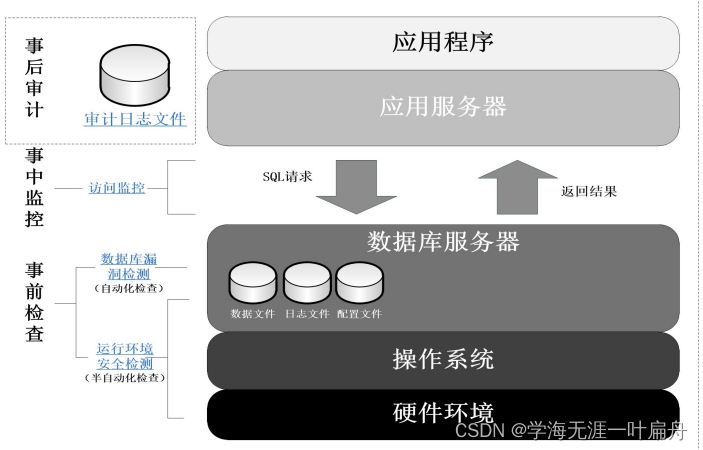
计算机环境安全
操作系统安全----比如windows,linux 安全标识--实体唯一性 windows---主体:账户,计算机,服务 安全标识符SID-Security Identifier 普通用户SID是1000,管理用SID是500 linux---主体:用户,用户组…...

Activiti7工作流引擎:多租户
一:多租户 表示每个租户之间数据隔离互不影响,互不可见。通常一个租户表示一个系统应用(类似于appid的作用)或者一家公司。 通过数据库级别进行隔离,每个租户对应一个数据库;通过表记录级别进行隔离&…...
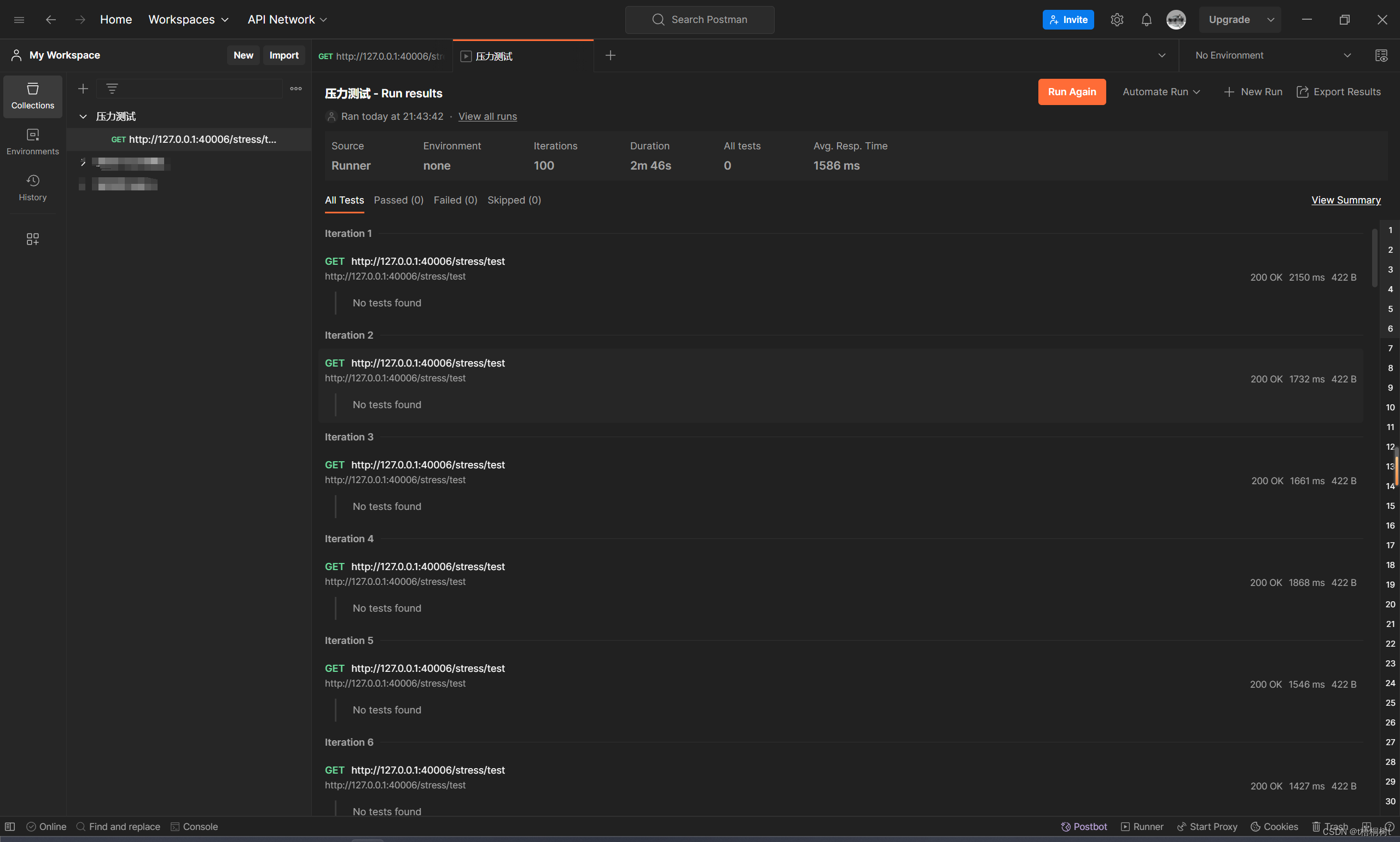
Postman实现压力测试
从事软件开发对于压力测试并不陌生,常见的一些压测软件有Apache JMeter LoadRunner Gatling Tsung 等,这些都是一些比较专业的测试软件,对于我的工作来说一般情况下用不到这么专业的测试,有时候需要对一些接口进行压力测试又不想再安装新软件,那么可以使用Postman来实现对…...
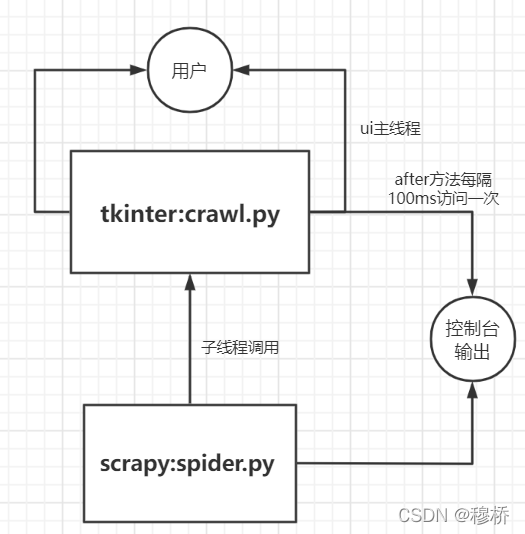
爬虫工具(tkinter+scrapy+pyinstaller)
需求介绍输入:关键字文件,每一行数据为一爬取单元。若一行存在多个and关系的关键字 ,则用|隔开处理:爬取访问6个网站的推送,获取推送内容的标题,发布时间,来源,正文第一段࿰…...

MySQL常用sql语句记录
1,创建用户及赋权 -- 创建用户 CREATE USER usernamelocalhost IDENTIFIED BY password;-- 赋予所有权限 GRANT ALL PRIVILEGES ON database_name.* TO usernamelocalhost;-- 赋予特定表的某些权限 GRANT SELECT, INSERT ON table_name TO usernamelocalhost;-- 更…...

2024.1.4力扣每日一题——被列覆盖的最多行数
2024.1.4 题目来源我的题解方法一 回溯位运算优化 题目来源 力扣每日一题;题序:2397 我的题解 方法一 回溯位运算优化 这道题一看就会想到使用回溯法,但是采用回溯法后如何判断有多少行被覆盖,直接计算矩阵时间复杂度较高&…...
Elasticsearch:Serarch tutorial - 使用 Python 进行搜索 (一)
本实践教程将教你如何使用 Elasticsearch 构建完整的搜索解决方案。 在本教程中你将学习: 如何对数据集执行全文关键字搜索(可选使用过滤器)如何使用机器学习模型生成、存储和搜索密集向量嵌入如何使用 ELSER 模型生成和搜索稀疏向量如何使用…...

第五讲_css元素显示模式
css元素显示模式 1. 元素的显示模式1.1 块元素1.2 行内元素1.3 行内块元素 2. 元素根据显示模式分类3. 修改元素的显示模式 1. 元素的显示模式 1.1 块元素 块元素的特性: 在页面中独占一行,从上到下排列。默认宽度,撑满父元素。默认高度&a…...

Shell脚本入门实战:探索自动化任务与实用场景
引言 Shell脚本作为一种强大的自动化工具,在现代操作系统中具有广泛的应用。无论是简单的文件操作,还是复杂的系统管理,Shell脚本都能提供高效、快速的解决方案。在本文中,我们将探索Shell脚本的基础知识,并通过实战场…...

【AI视野·今日Sound 声学论文速览 第四十二期】Fri, 5 Jan 2024
AI视野今日CS.Sound 声学论文速览 Fri, 5 Jan 2024 Totally 10 papers 👉上期速览✈更多精彩请移步主页 Daily Sound Papers PosCUDA: Position based Convolution for Unlearnable Audio Datasets Authors Vignesh Gokul, Shlomo Dubnov深度学习模型需要大量干净的…...

Java中如何使用SQLite数据库
目录 SQLite简介SQLite优势安装 SQLite基本使用Java使用SQLite Springboot使用SQLite1.添加依赖2.配置数据库3.创建实体类 4.创建Repository接口5.创建控制器6.运行应用程序 SQLite简介 SQLite 是一个开源的嵌入式关系数据库,实现了自给自足的、无服务器的、配置无…...

kettle的基本介绍和使用
1、 kettle概述 1.1 什么是kettle Kettle是一款开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。 1.2 Kettle核心知识点 1.2.1 Kettle工程存储方式 以XML形式存储以资源库方式存储…...

数据结构第2章 栈和队列
名人说:莫听穿林打叶声,何妨吟啸且徐行。—— 苏轼《定风波莫听穿林打叶声》 本篇笔记整理:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 0、思维导图栈和队列1、栈1)特点2࿰…...

Axure鲜花商城网站原型图,网上花店订花O2O本地生活电商平台
作品概况 页面数量:共 30 页 兼容软件:仅支持Axure RP 9/10,非程序软件无源代码 应用领域:鲜花网、花店网站、本地生活电商 作品特色 本作品为「鲜花购物商城」网站模板,高保真高交互,属于O2O本地生活电…...
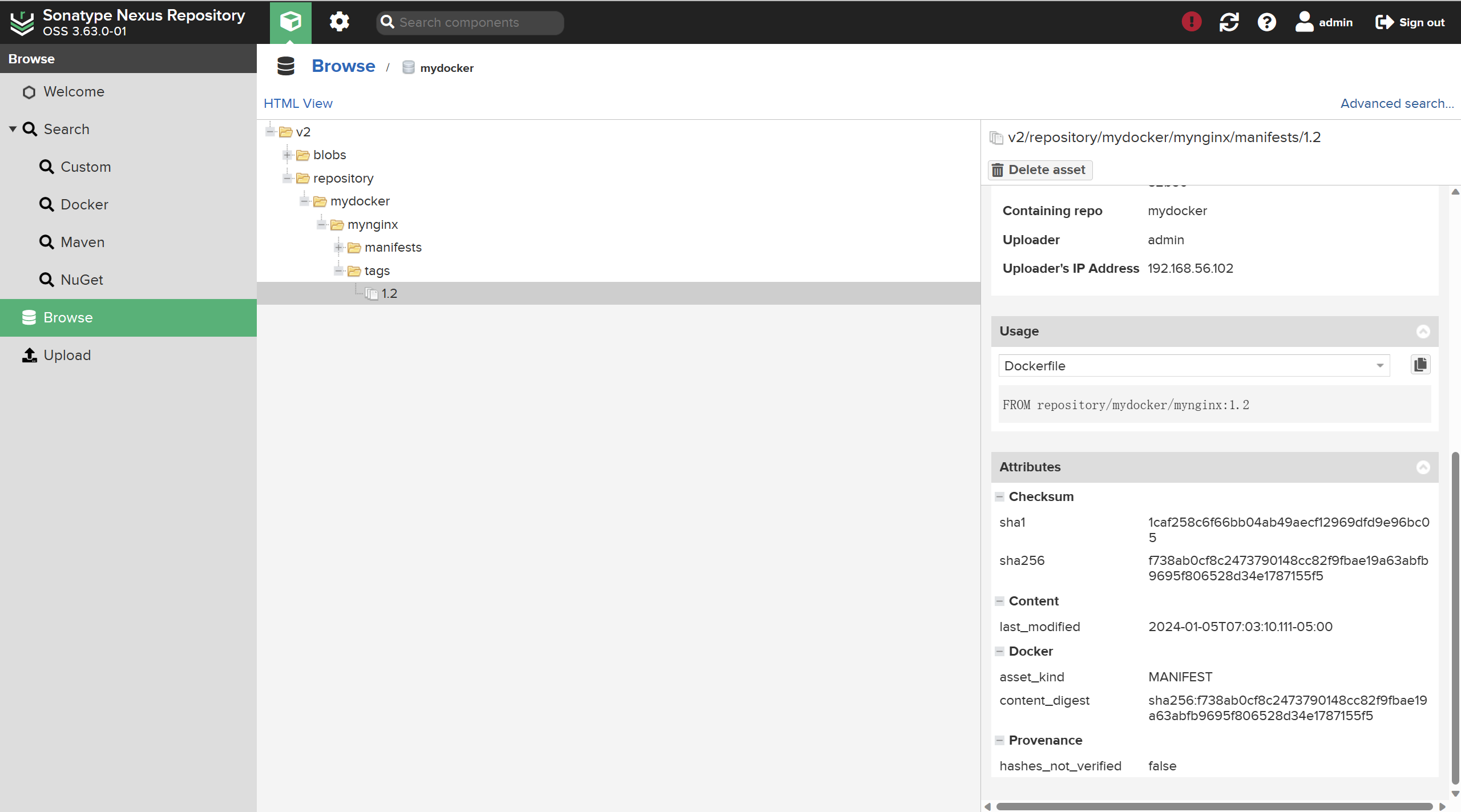
【docker】centos 使用 Nexus Repository 搭建私有仓库
Nexus Repository 是一种流行的软件仓库管理工具,它可以帮助您搭建私有仓库,以便在内部网络或私有云环境中存储、管理和分发各种软件包和组件。 它常被用于搭建Maven的镜像仓库。本文演示如何用Nexus Repository搭建docker 私有仓库。 使用Nexus Repos…...

基于OpenClaw构建智能家居环境感知系统:从传感器到自动化规则
1. 项目概述与核心价值如果你正在捣鼓一个智能家居系统,尤其是围绕着OpenClaw这类AI助手来构建,那你可能和我一样,经常遇到一个痛点:家里的设备虽然能联网、能控制,但它们大多“又聋又瞎”。空调能开能关,但…...

AbMole丨CL 316243:β3-肾上腺素受体激动剂,在代谢调控与能量消耗研究中的应用
CL 316243是一种高选择性的β3-肾上腺素受体(β3-AR)激动剂,其对β3-AR的选择性远高于β1-AR和β2-AR[1]。CL 316243(CAS No.:138908-40-4)通过激活β3-AR,刺激腺苷酸环化酶(AC&…...

3分钟掌握TestDisk:开源数据恢复终极解决方案
3分钟掌握TestDisk:开源数据恢复终极解决方案 【免费下载链接】testdisk TestDisk & PhotoRec 项目地址: https://gitcode.com/gh_mirrors/te/testdisk 你是否曾因为误删除重要文件而彻夜难眠?是否经历过硬盘分区突然消失的恐慌?别…...

S19|MCP 与插件:多 Agent 平台 —— 外部能力总线,让外部工具安全接入
在前十八章,我们的 Agent 已经拥有完整的内部能力体系:循环、工具、计划、子代理、技能、压缩、权限、Hook、记忆、提示词流水线、错误恢复、任务系统、后台任务、定时调度、多 Agent 团队、团队协议、自主代理、Worktree 隔离,所有工具都写在…...

Vigil与其他监控工具集成:构建全方位监控体系的3种方案
Vigil与其他监控工具集成:构建全方位监控体系的3种方案 【免费下载链接】vigil 🚦 Microservices Status Page. Monitors a distributed infrastructure and sends alerts (Slack, SMS, etc.). 项目地址: https://gitcode.com/gh_mirrors/vig/vigil …...

iMeta | 伦敦国王学院量化系统生物学组-解析肝硬化中口腔-肠道转移细菌与宿主互作
点击蓝字 关注我们整合宿主–微生物组建模揭示了口腔–肠道微生物转移在晚期肝硬化中的潜在作用iMeta主页:http://www.imeta.science研究论文● 期刊: iMeta (IF 33.2,中科院双一区Top)● 英文题目: Integrative host-microbiome modelling uncovers the implicatio…...

【紧急预警】NotebookLM在广义相对论语境下的概念漂移现象:基于57篇PRL论文的偏差审计报告
更多请点击: https://intelliparadigm.com 第一章:【紧急预警】NotebookLM在广义相对论语境下的概念漂移现象:基于57篇PRL论文的偏差审计报告 现象复现与基准测试协议 我们在标准LIGO-PRL语料集(v2.3)上对NotebookLM…...

AI驱动的智能监控:从时序异常检测到自动化运维实战
1. 项目概述:AI驱动的系统守护者最近在折腾一个服务器监控项目时,发现了一个挺有意思的开源工具,叫bhusingh/ai-watchdog。这个名字直译过来就是“AI看门狗”,听起来就很有画面感。它本质上是一个利用人工智能技术来监控系统、预测…...

Windows热键侦探:3分钟快速找出占用快捷键的程序
Windows热键侦探:3分钟快速找出占用快捷键的程序 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾经遇到…...

基于ESP32-S3的免焊接RGB矩阵屏驱动方案:从硬件解析到项目实战
1. 项目概述:从零到一的免焊接RGB矩阵显示方案如果你曾经尝试过驱动一块RGB LED矩阵屏,大概率会经历一段“痛并快乐着”的时光。快乐在于,当代码跑通,绚丽的色彩在眼前流动时,那种成就感无与伦比;痛苦则在于…...