竞赛保研 基于深度学习的人脸性别年龄识别 - 图像识别 opencv
文章目录
- 0 前言
- 1 课题描述
- 2 实现效果
- 3 算法实现原理
- 3.1 数据集
- 3.2 深度学习识别算法
- 3.3 特征提取主干网络
- 3.4 总体实现流程
- 4 具体实现
- 4.1 预训练数据格式
- 4.2 部分实现代码
- 5 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 毕业设计 人脸性别年龄识别系统 - 图像识别 opencv
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:3分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题描述
随着大数据与人工智能逐渐走入人们的生活,计算机视觉应用越发广泛。如医疗影像识别、无人驾驶车载视觉、通用物体识别、自然场景下的文本识别等,根据不同的应用场景,人脸研究方向可以分为人脸检测、身份识别、性别识别、年龄预测、种族识别、表情识别等。近年来,人脸身份识别技术发展迅猛,在生活应用中取得了较好的效果,也逐渐趋于成熟,而年龄识别与性别预测,仍然是生物特征识别研究领域中一项具有挑战性的课题。
课题意义
相比人脸性别属性而言,人脸年龄属性的研究更富有挑战性。主要有两点原因,首先每个人的年龄会随着身体健康状况、皮肤保养情况而表现得有所不同,即便是在同一年,表现年龄会随着个人状态的不同而改变,人类识别尚且具有较高难度。其次,可用的人脸年龄估计数据集比较少,不同年龄的数据标签收集不易,现有大多数的年龄数据集都是在不同的复杂环境下的照片、人脸图片存在光照变化较复杂、部分遮挡、图像模糊、姿态旋转角度较大等一系列问题,对人脸模型的鲁棒性产生了较大的影响。
2 实现效果
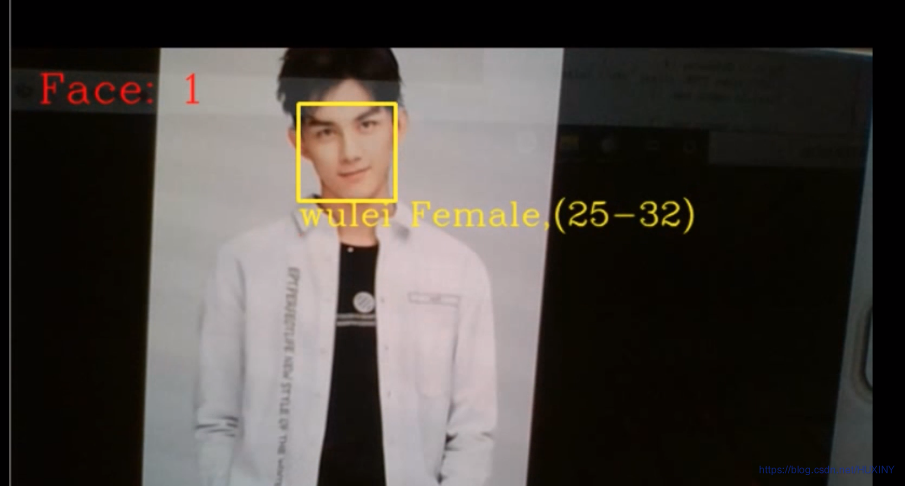
这里废话不多说,先放上大家最关心的实现效果:
输入图片:

识别结果:
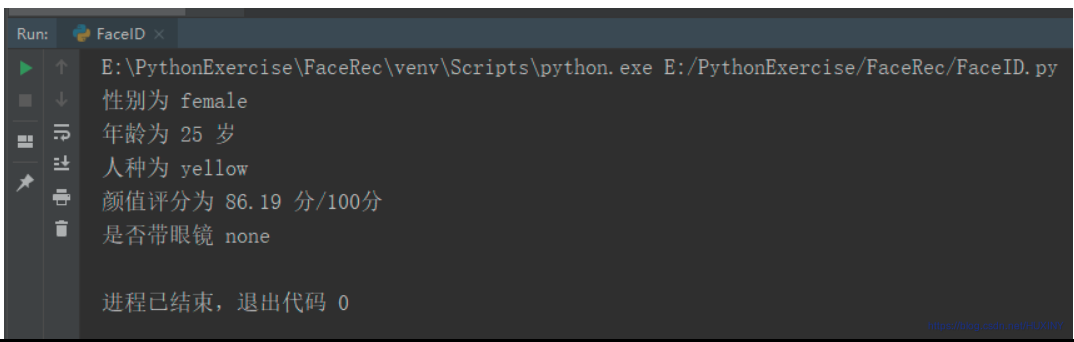
或者实时检测

3 算法实现原理
3.1 数据集
学长收集的数据集:
该人脸数据库的图片来源于互联网的爬取,而非研究机构整理,一共含有13000多张人脸图像,在这个数据集中大约有1860张图片是成对出现的,即同一个人的2张不同照片,有助于人脸识别算法的研究,图像标签中标有人的身份信息,人脸坐标,关键点信息,可用于人脸检测和人脸识别的研究,此数据集是对人脸算法效果验证的权威数据集.

该数据集包含的人脸范围比较全面,欧亚人种都有。
3.2 深度学习识别算法
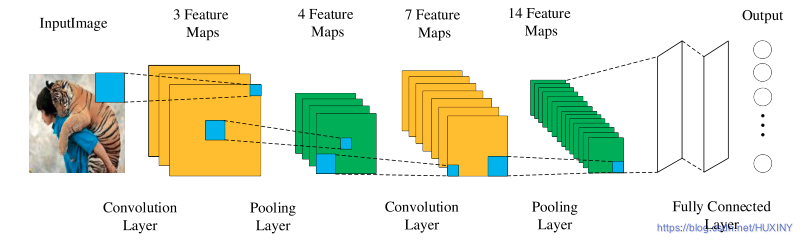
卷积神经网络是常见的深度学习架构,而在CNN出现之前,图像需要处理的数据量过大,导致成本很高,效率很低,图像在数字化的过程中很难保留原有的特征,导致图像处理的准确率不高。CNN的出现使得提取特征的能力变得更强,为更多优秀网络的研究提供了有力的支撑。CNN的核心思想是利用神经网络模拟人脑视觉神经系统,构造多个神经元并建立彼此之间的联系。不同的神经元进行分工,浅层神经元处理低纬度图像特征,深层神经元处理图像高级特征、语义信息等,CNN的网络结构主要由卷积层、BN层、激活层、池化层、全连接层、损失函数层构成,多个层协同工作实现了特征提取的功能,并通过特有的网络结构降低参数的数量级,防止过拟合,最终得到输出结果.
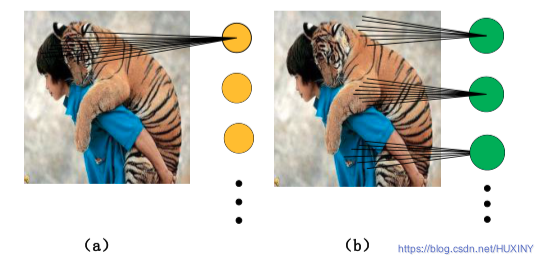
CNN传承了多层感知机的思想,并受到了生物神经科学的启发,通过卷积的运算模拟人类视觉皮层的“感受野”。不同于传统的前馈神经网络,卷积运算对图像的区域值进行加权求和,最终以神经元的形式进行输出。前馈神经网络对每一个输入的信号进行加权求和:
- (a)图是前馈神经网络的连接方式
- (b)图是CNN的连接方式。
cnn框架如下:
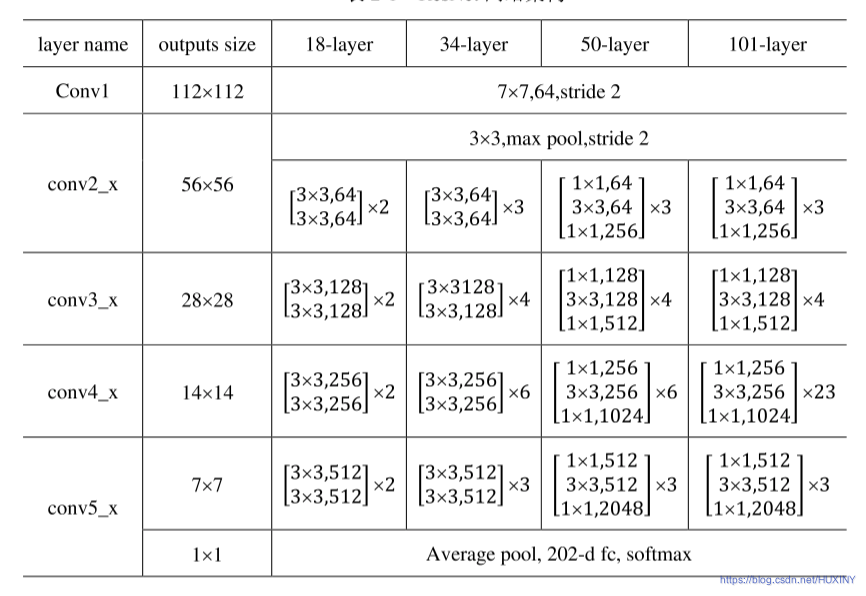
3.3 特征提取主干网络
在深度学习算法研究中,通用主干特征提取网络结合特定任务网络已经成为一种标准的设计模式。特征提取对于分类、识别、分割等任务都是至关重要的部分。下面介绍本文研究中用到的主干神经网络。
ResNet网络
ResNet是ILSVRC-2015的图像分类任务冠军,也是CVPR2016的最佳论文,目前应用十分广泛,ResNet的重要性在于将网络的训练深度延伸到了数百层,而且取得了非常好的效果。在ResNet出现之前,网络结构一般在20层左右,对于一般情况,网络结构越深,模型效果就会越好,但是研究人员发现加深网络反而会使结果变差。
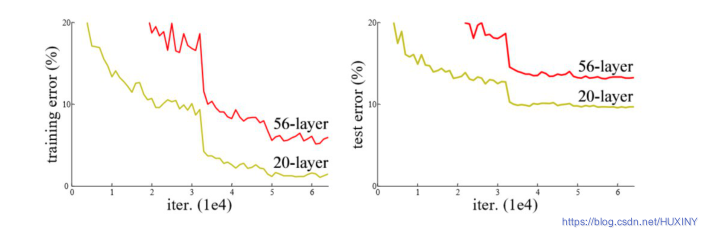
人脸特征提取我这里选用ResNet,网络结构如下:
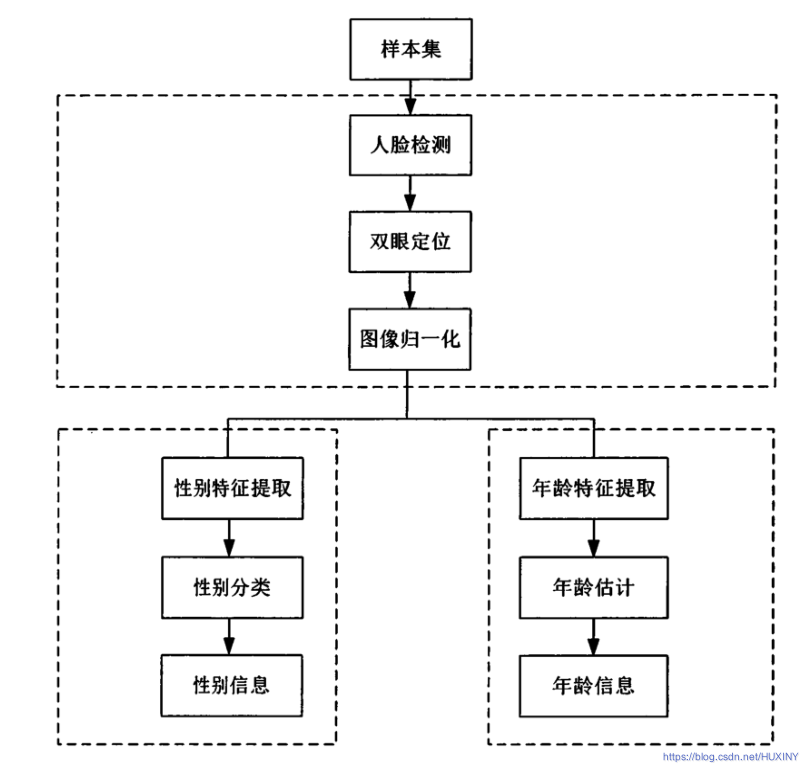
3.4 总体实现流程
4 具体实现
4.1 预训练数据格式
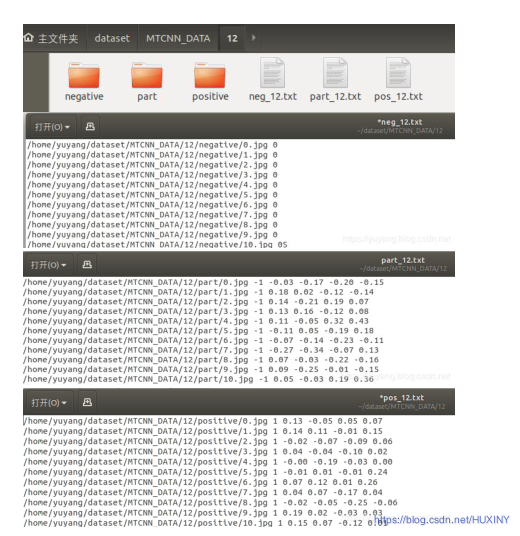
4.2 部分实现代码
训练部分代码:
from __future__ import absolute_importfrom __future__ import divisionfrom __future__ import print_functionfrom six.moves import xrangefrom datetime import datetimeimport timeimport osimport numpy as npimport tensorflow as tffrom data import distorted_inputsfrom model import select_modelimport jsonimport reLAMBDA = 0.01MOM = 0.9tf.app.flags.DEFINE_string('pre_checkpoint_path', '',"""If specified, restore this pretrained model """"""before beginning any training.""")tf.app.flags.DEFINE_string('train_dir', '/home/dpressel/dev/work/AgeGenderDeepLearning/Folds/tf/test_fold_is_0','Training directory')tf.app.flags.DEFINE_boolean('log_device_placement', False,"""Whether to log device placement.""")tf.app.flags.DEFINE_integer('num_preprocess_threads', 4,'Number of preprocessing threads')tf.app.flags.DEFINE_string('optim', 'Momentum','Optimizer')tf.app.flags.DEFINE_integer('image_size', 227,'Image size')tf.app.flags.DEFINE_float('eta', 0.01,'Learning rate')tf.app.flags.DEFINE_float('pdrop', 0.,'Dropout probability')tf.app.flags.DEFINE_integer('max_steps', 40000,'Number of iterations')tf.app.flags.DEFINE_integer('steps_per_decay', 10000,'Number of steps before learning rate decay')tf.app.flags.DEFINE_float('eta_decay_rate', 0.1,'Learning rate decay')tf.app.flags.DEFINE_integer('epochs', -1,'Number of epochs')tf.app.flags.DEFINE_integer('batch_size', 128,'Batch size')tf.app.flags.DEFINE_string('checkpoint', 'checkpoint','Checkpoint name')tf.app.flags.DEFINE_string('model_type', 'default','Type of convnet')tf.app.flags.DEFINE_string('pre_model','',#'./inception_v3.ckpt','checkpoint file')FLAGS = tf.app.flags.FLAGS# Every 5k steps cut learning rate in halfdef exponential_staircase_decay(at_step=10000, decay_rate=0.1):print('decay [%f] every [%d] steps' % (decay_rate, at_step))def _decay(lr, global_step):return tf.train.exponential_decay(lr, global_step,at_step, decay_rate, staircase=True)return _decaydef optimizer(optim, eta, loss_fn, at_step, decay_rate):global_step = tf.Variable(0, trainable=False)optz = optimif optim == 'Adadelta':optz = lambda lr: tf.train.AdadeltaOptimizer(lr, 0.95, 1e-6)lr_decay_fn = Noneelif optim == 'Momentum':optz = lambda lr: tf.train.MomentumOptimizer(lr, MOM)lr_decay_fn = exponential_staircase_decay(at_step, decay_rate)return tf.contrib.layers.optimize_loss(loss_fn, global_step, eta, optz, clip_gradients=4., learning_rate_decay_fn=lr_decay_fn)def loss(logits, labels):labels = tf.cast(labels, tf.int32)cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=labels, name='cross_entropy_per_example')cross_entropy_mean = tf.reduce_mean(cross_entropy, name='cross_entropy')tf.add_to_collection('losses', cross_entropy_mean)losses = tf.get_collection('losses')regularization_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)total_loss = cross_entropy_mean + LAMBDA * sum(regularization_losses)tf.summary.scalar('tl (raw)', total_loss)#total_loss = tf.add_n(losses + regularization_losses, name='total_loss')loss_averages = tf.train.ExponentialMovingAverage(0.9, name='avg')loss_averages_op = loss_averages.apply(losses + [total_loss])for l in losses + [total_loss]:tf.summary.scalar(l.op.name + ' (raw)', l)tf.summary.scalar(l.op.name, loss_averages.average(l))with tf.control_dependencies([loss_averages_op]):total_loss = tf.identity(total_loss)return total_lossdef main(argv=None):with tf.Graph().as_default():model_fn = select_model(FLAGS.model_type)# Open the metadata file and figure out nlabels, and size of epochinput_file = os.path.join(FLAGS.train_dir, 'md.json')print(input_file)with open(input_file, 'r') as f:md = json.load(f)images, labels, _ = distorted_inputs(FLAGS.train_dir, FLAGS.batch_size, FLAGS.image_size, FLAGS.num_preprocess_threads)logits = model_fn(md['nlabels'], images, 1-FLAGS.pdrop, True)total_loss = loss(logits, labels)train_op = optimizer(FLAGS.optim, FLAGS.eta, total_loss, FLAGS.steps_per_decay, FLAGS.eta_decay_rate)saver = tf.train.Saver(tf.global_variables())summary_op = tf.summary.merge_all()sess = tf.Session(config=tf.ConfigProto(log_device_placement=FLAGS.log_device_placement))tf.global_variables_initializer().run(session=sess)# This is total hackland, it only works to fine-tune iv3if FLAGS.pre_model:inception_variables = tf.get_collection(tf.GraphKeys.VARIABLES, scope="InceptionV3")restorer = tf.train.Saver(inception_variables)restorer.restore(sess, FLAGS.pre_model)if FLAGS.pre_checkpoint_path:if tf.gfile.Exists(FLAGS.pre_checkpoint_path) is True:print('Trying to restore checkpoint from %s' % FLAGS.pre_checkpoint_path)restorer = tf.train.Saver()tf.train.latest_checkpoint(FLAGS.pre_checkpoint_path)print('%s: Pre-trained model restored from %s' %(datetime.now(), FLAGS.pre_checkpoint_path))run_dir = '%s/run-%d' % (FLAGS.train_dir, os.getpid())checkpoint_path = '%s/%s' % (run_dir, FLAGS.checkpoint)if tf.gfile.Exists(run_dir) is False:print('Creating %s' % run_dir)tf.gfile.MakeDirs(run_dir)tf.train.write_graph(sess.graph_def, run_dir, 'model.pb', as_text=True)tf.train.start_queue_runners(sess=sess)summary_writer = tf.summary.FileWriter(run_dir, sess.graph)steps_per_train_epoch = int(md['train_counts'] / FLAGS.batch_size)num_steps = FLAGS.max_steps if FLAGS.epochs < 1 else FLAGS.epochs * steps_per_train_epochprint('Requested number of steps [%d]' % num_steps)for step in xrange(num_steps):start_time = time.time()_, loss_value = sess.run([train_op, total_loss])duration = time.time() - start_timeassert not np.isnan(loss_value), 'Model diverged with loss = NaN'if step % 10 == 0:num_examples_per_step = FLAGS.batch_sizeexamples_per_sec = num_examples_per_step / durationsec_per_batch = float(duration)format_str = ('%s: step %d, loss = %.3f (%.1f examples/sec; %.3f ' 'sec/batch)')print(format_str % (datetime.now(), step, loss_value,examples_per_sec, sec_per_batch))# Loss only actually evaluated every 100 steps?if step % 100 == 0:summary_str = sess.run(summary_op)summary_writer.add_summary(summary_str, step)if step % 1000 == 0 or (step + 1) == num_steps:saver.save(sess, checkpoint_path, global_step=step)if __name__ == '__main__':tf.app.run()5 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
竞赛保研 基于深度学习的人脸性别年龄识别 - 图像识别 opencv
文章目录 0 前言1 课题描述2 实现效果3 算法实现原理3.1 数据集3.2 深度学习识别算法3.3 特征提取主干网络3.4 总体实现流程 4 具体实现4.1 预训练数据格式4.2 部分实现代码 5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 毕业设计…...

JavaScript音视频,JavaScript简单获取电脑摄像头画面并播放
前言 本章实现JavaScript简单获取电脑摄像头画面并播放的功能 兼容性(不支持Node.js) 需要注意的是,由于涉及到用户的隐私和安全,获取用户媒体设备需要用户的明确同意,并且可能需要在用户的浏览器中启用相关的权限。在某些浏览器中,可能需要用户手动开启摄像头权限。 …...

《JVM由浅入深学习【五】 2024-01-08》JVM由简入深学习提升分享
目录 JVM何时会发生堆内存溢出?1. 堆内存溢出的定义2. 内存泄漏的原因3. 堆内存溢出的常见场景4. JVM参数调优5. 实际案例分析 JVM如何判断对象可以回收1.可达性分析的基本思路2.实际案例3.可以被回收的对象4.拓展, 谈谈 Java 中不同的引用类型? 结语感…...
FastDFS之快速入门、上手
知识概念 分布式文件系统 通过计算机网络将各个物理存储资源连接起来。通过分布式文件系统,将网络上任意资源以逻辑上的树形结构展现,让用户访问网络上的共享文件更见简便。 文件存储的变迁: 直连存储:直接连接与存储…...

Vue 中的 ref 与 reactive:让你的应用更具响应性(中)
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...
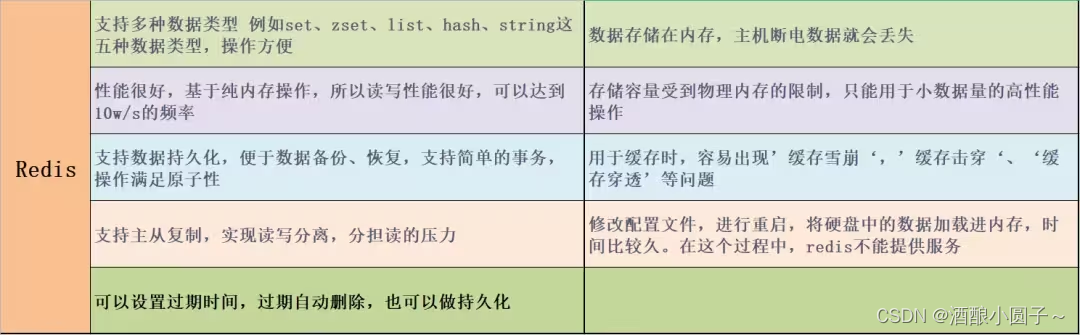
【数据库基础】Mysql与Redis的区别
看到一篇不错的关于“Mysql与Redis的区别”的文章,转过来记录下~ 文章目录 一、数据库类型二、运行机制三、什么是缓存数据库呢?四、优缺点比较五、区别总结六、数据可以全部直接用Redis储存吗?参考资料 一、数据库类型 Redis:NOS…...

JVM工作原理与实战(六):类的生命周期-连接阶段
专栏导航 JVM工作原理与实战 RabbitMQ入门指南 从零开始了解大数据 目录 专栏导航 前言 一、类的生命周期 1.加载(Loading) 2.连接(Linking) 3.初始化(Initialization) 4.使用(Using&…...

【OCR】 - Tesseract OCR在Windows系统中安装
Tesseract OCR 在Windows环境下安装Tesseract OCR(Optical Character Recognition)通常包括以下几个步骤: 下载Tesseract 访问Tesseract的GitHub发布页面:https://github.com/tesseract-ocr/tesseract/releases找到适合你操作系…...

YOLOv8改进 | 损失函数篇 | SlideLoss、FocalLoss分类损失函数助力细节涨点(全网最全)
一、本文介绍 本文给大家带来的是分类损失 SlideLoss、VFLoss、FocalLoss损失函数,我们之前看那的那些IoU都是边界框回归损失,和本文的修改内容并不冲突,所以大家可以知道损失函数分为两种一种是分类损失另一种是边界框回归损失,上一篇文章里面我们总结了过去百分之九十的…...
)
计算机网络试题——填空题(附答案)
在OSI模型中,第一层是____________层。 答案:物理(Physical) TCP协议是一种_____________连接的协议。 答案:面向连接(Connection-oriented) IPv6地址的位数是____________。 答案:1…...

第二证券:股票私募仓位指数创近八周新高
1月8日,A股几大首要指数全线收跌,上证指数收于日内最低点2887.54点,间隔上一年5月份的阶段高点3418.95点现已跌去了15.54%。 不过,虽然商场仍未清晰止跌,私募基金们却现已进场“抄底”。私募排排网最新发布的私募仓位…...

35-javascript基础,引入方式;变量命名规范
html分为三部分;结构html,表现css,行为js;js就是javascript js包含三部分: ECMAScript:简称ES,ES5,ES6核心语法 DOM:获取和操作html元素的标准方法;BOM&am…...

笔试案例2
文章目录 1、笔试案例22、思维导图 1、笔试案例2 09)查询学过「张三」老师授课的同学的信息 selects.*,c.cname,t.tname,sc.score from t_mysql_teacher t, t_mysql_course c, t_mysql_student s, t_mysql_score sc where t.tidc.cid and c.cidsc.cid and sc.sids…...

【嵌入式-网络编程】vmware中使用UDP广播失败问题
问题描述: 自己在vmware中搭建了2台虚拟机,虚拟机A向虚拟机A和虚拟机B发送广播信息,接收端在虚拟机A和虚拟机B,这个时候,由于没配置sin.sin_addr.s_addr htonl(INADDR_ANY);,而是配置的inet_pton(AF_INET,…...

2020年认证杯SPSSPRO杯数学建模D题(第二阶段)让电脑桌面飞起来全过程文档及程序
2020年认证杯SPSSPRO杯数学建模 D题 让电脑桌面飞起来 原题再现: 对于一些必须每天使用电脑工作的白领来说,电脑桌面有着非常特殊的意义,通常一些频繁使用或者比较重要的图标会一直保留在桌面上,但是随着时间的推移,…...

vue3 修饰符大全(近万字长文)
系列文章目录 TypeScript 从入门到进阶专栏 文章目录 系列文章目录前言一、事件修饰符(Event Modifiers)1、.stop(阻止事件冒泡)2、.prevent(阻止事件的默认行为)3、.capture(使用事件捕获模式…...
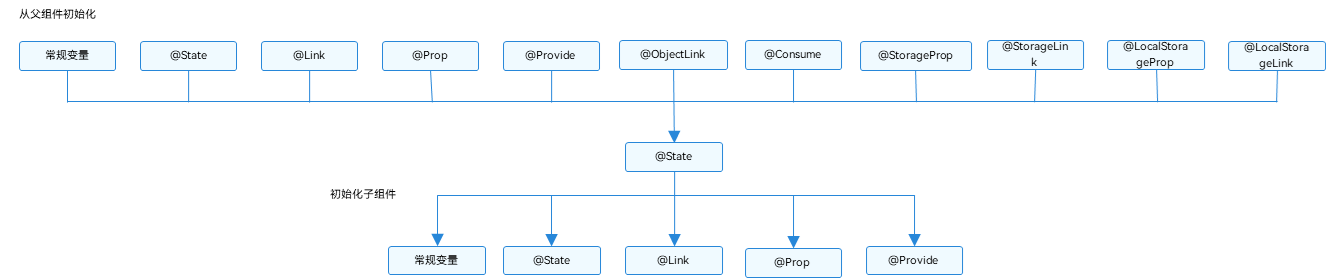
HarmonyOS@State装饰器:组件内状态
State装饰器:组件内状态 State装饰的变量,或称为状态变量,一旦变量拥有了状态属性,就和自定义组件的渲染绑定起来。当状态改变时,UI会发生对应的渲染改变。 在状态变量相关装饰器中,State是最基础的&…...
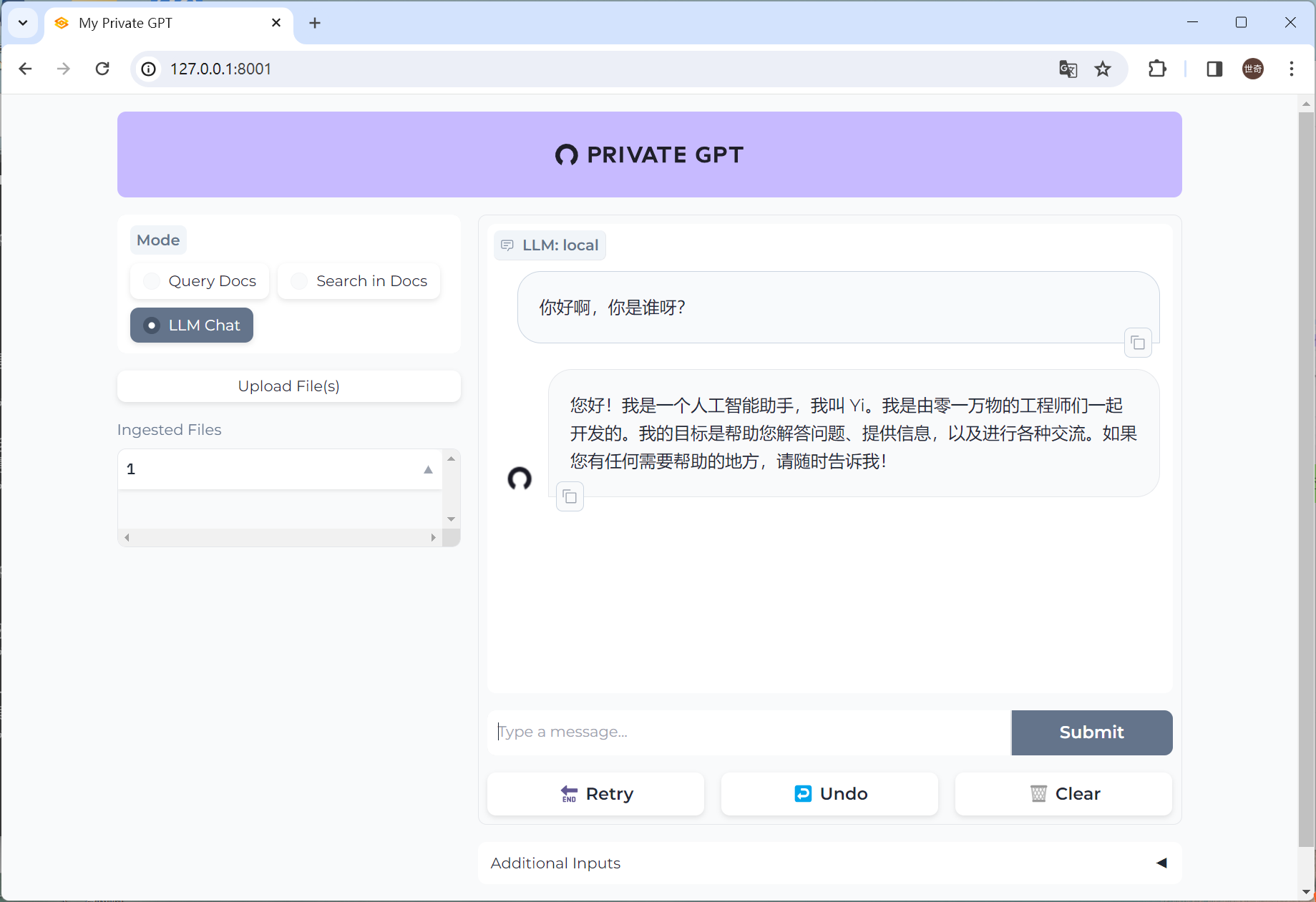
如何让GPT支持中文
上一篇已经讲解了如何构建自己的私人GPT,这一篇主要讲如何让GPT支持中文。 privateGPT 本地部署目前只支持基于llama.cpp 的 gguf格式模型,GGUF 是 llama.cpp 团队于 2023 年 8 月 21 日推出的一种新格式。它是 GGML 的替代品,llama.cpp 不再…...
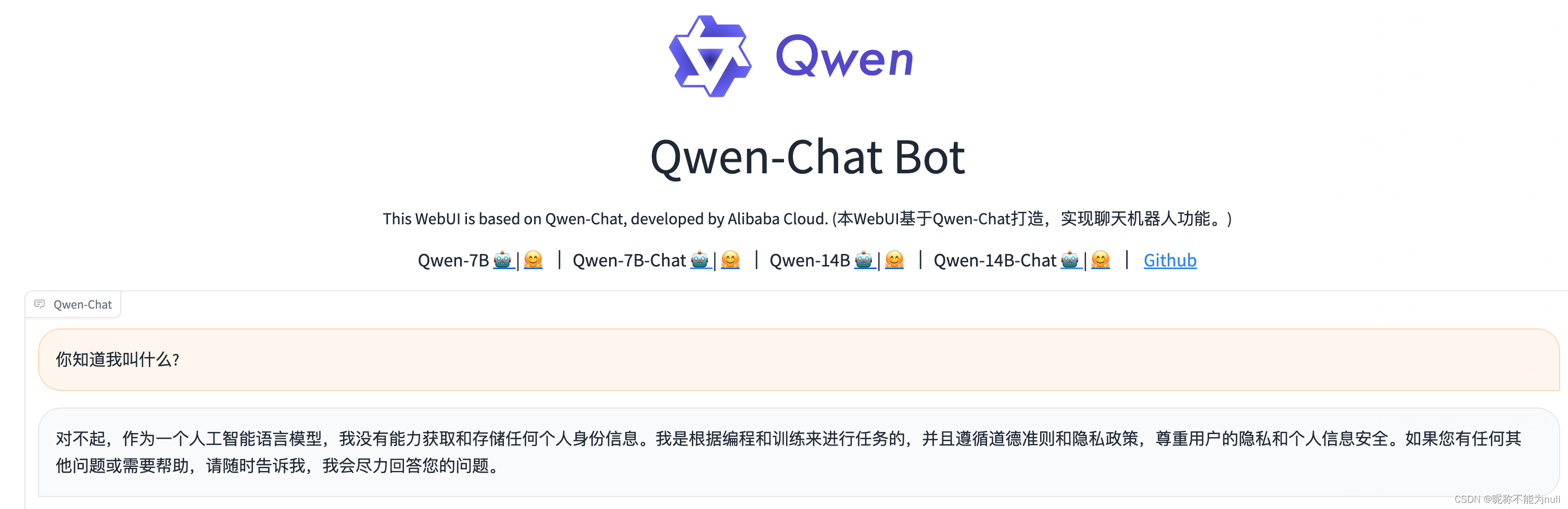
使用开源通义千问模型(Qwen)搭建自己的大模型服务
目标 1、使用开源的大模型服务搭建属于自己的模型服务; 2、调优自己的大模型; 选型 采用通义千问模型,https://github.com/QwenLM/Qwen 步骤 1、下载模型文件 开源模型库:https://www.modelscope.cn/models mkdir -p /data/…...

Java工程师面试题解析与深度探讨
Java工程师面试题解析与深度探讨 第一部分:引言 Java作为一门广泛应用的编程语言,拥有庞大的生态系统,Java工程师因此成为众多企业追逐的目标。而在Java工程师的招聘中,面试是了解候选人技能和经验的核心环节。本文将深入探讨一…...

用Arduino和MAX30102做个心率血氧仪,从硬件连线到算法调试全流程避坑
从零构建Arduino心率血氧仪:MAX30102实战指南 开篇:为什么选择MAX30102? 在可穿戴健康设备爆发的时代,心率血氧监测已成为智能手环的标配功能。而MAX30102这颗高度集成的光学传感器,正以医用级精度和低功耗特性成为创客…...

从引脚到协议:USB接口演进与Type-C双角色设计解析
1. USB接口的演进之路 记得我第一次拆解老式MP3播放器时,面对那个四针脚的USB接口,完全搞不懂为什么同样的接口有的能传数据有的只能充电。后来才发现,原来USB接口的发展史就是一部微型计算机外设的进化史。 1996年问世的USB 1.0标准只有12Mb…...

Python AutoCAD自动化开发指南:如何用5行代码替代8小时重复绘图工作
Python AutoCAD自动化开发指南:如何用5行代码替代8小时重复绘图工作 【免费下载链接】pyautocad AutoCAD Automation for Python ⛺ 项目地址: https://gitcode.com/gh_mirrors/py/pyautocad 你是否曾因AutoCAD中重复的绘图任务而加班到深夜?是否…...

联发科2012年崛起:从功能机到智能机的转型与挑战
1. 从功能机到智能机的惊险一跃:联发科的2012年2012年,对于全球移动芯片行业来说,是几家欢喜几家愁的一年。诺基亚和黑莓的持续衰落,直接拖垮了像ST-Ericsson这样深度绑定的芯片供应商;即便是巨头如高通,也…...

ARM TLB指令详解与虚拟化内存管理优化
1. ARM TLB指令基础与虚拟化背景 在ARM架构的虚拟化环境中,内存管理单元(MMU)通过TLB(Translation Lookaside Buffer)缓存虚拟地址到物理地址的转换结果,以提升内存访问性能。当页表发生变更时,…...

ARM PB11MPCore USB与DVI接口设计与信号完整性分析
1. ARM PB11MPCore接口架构解析PB11MPCore作为ARM经典的嵌入式开发平台,其外设接口设计体现了工业级嵌入式系统的典型特征。我们先从整体架构入手,理解USB和DVI接口在系统中的位置。1.1 系统级接口布局开发板采用前后面板分离设计,关键接口分…...

抖音内容高效采集实战:5个提升工作效率的开源方案
抖音内容高效采集实战:5个提升工作效率的开源方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. …...

基于星座匹配的眼动追踪角膜反射检测技术解析
1. 项目概述:基于星座匹配的角膜反射检测框架在眼动追踪技术领域,瞳孔-角膜反射(P-CR)方法一直是最可靠的解决方案之一。这种方法的核心在于准确检测和匹配角膜反射点(glints)——即红外LED在角膜表面形成的…...

轻量级Web代理moltron:架构解析与生产级部署实战
1. 项目概述:一个轻量级、高性能的Web代理工具在开发和运维的日常工作中,我们经常需要处理不同网络环境下的服务访问问题。比如,本地开发需要调试一个部署在内网测试环境的API,或者需要安全地访问某些仅限特定网络访问的资源。传统…...

AI工具搭建自动化视频生成GDPR
好的,我们直接切入正题。 1. 他到底是什么 很多人一听到“GDPR”,第一反应是欧洲那个让人头疼的数据隐私法规。别搞混了,这里说的“GDPR”是一个Python库的名字,全称是“General Data Protection Regulation … 哦不,开…...