【复习】人工智能 第7章 专家系统与机器学习
专家系统就是让机器人当某个领域的专家,但这章专家系统不咋考,主要靠书上没有的机器学习。
一、专家系统的基本组成
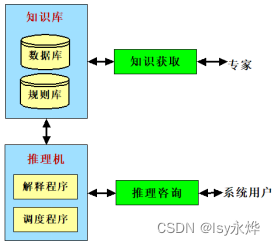

二、专家系统与传统程序的比较
(1)编程思想:
传统程序 = 数据结构 + 算法
专家系统 = 知识 + 推理
(2)知识存储位置:
传统程序:关于问题求解的知识隐含于程序中。
专家系统:知识单独组成知识库,与推理机分离。
(3)处理对象:
传统程序:数值计算和数据处理。
专家系统:符号处理。
(4)解释功能:
传统程序:不具有解释功能。
专家系统:具有解释功能。
(5)正确答案:
传统程序:产生正确的答案。
专家系统:通常产生正确的答案,有时产生错误的答案。
(6)系统的体系结构不同
三、知识获取的过程
抽取知识、知识的转换、知识的输入、知识的检测 。
四、7.4.2 知识获取的模式
非自动知识获取、自动知识获取、半自动知识获取。
五、机器学习
就是让机器不依靠外力,自己学习。
非显著式编程:让计算机自己总结规律的编程方法
举例说明,让机器人冲咖啡,人类规定机器人可以采取一系列行为,规定机器人在特定的环境下做这些行为所带来的收益称为 “ 收益函数 ” 。如:机器人自己摔倒,收益函数为负值;机器人自己摔倒,收益函数为负值;机器人自己取到咖啡,收益函数值为正值。
Tom Mitshell 对机器学习的定义:
一个计算机程序被称为可以学习,是指它能够针对某个任务T和某个性能指标P,从经验E中学习。这种学习的特点是,它在T上的被P所衡量的性能,会随着经验E的增加而提高。
人类在成长、生活过程中积累了很多的历史与经验。人类定期地对这些经验进行“归纳”,获得了生活的“规律”。当人类遇到未知的问题或者需要对未来进行“推测”的时候,人类使用这些“规律”,对未知问题与未来进行“推测”,从而指导自己的生活和工作 。而机器也可以。
机器学习工作流程总结:
1.获取数据
在数据集中一般,一行数据我们称为一个样本,一列数据我们成为一个特征。
所有的机器学习算法在应用场景、优势劣势、对数据要求、运行速度上都各有优劣,但有一点不变的是都是数据贪婪的,也就是说任何一个算法,都可以通过增加数据来达到更好的结果,因此第一步数据采集也是最基础,最重要的一步。
2.数据基本处理
即数据清洗,比如我们通过爬虫得来的数据很杂,甚至很多不是我们需要,然后我们对其进行筛选,这个就类似这个过程。
3.特征工程
把原始数据转变为模型的训练数据的过程,它的目的就是获取更好的训练数据特征
注:业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
4.机器学习
一般认为包括 特征构建、特征提取、特征选择三个部分。
特征构建是指从原始数据中人工的找出一些具有物理意义的特征。
5.构建模型
① 建立训练数据集和测试数据集,通常80%为训练数据集。
② 选择机器学习算法
选择合适的算法对模型进行训练,其中就要求有好的泛化能力(举一反三的能力)。
一般是拟合的模型是好的,但是过拟合就不好,因为要是过拟合肯定是模型比需要的更复杂导致的,不需要这样,这样只会导致变慢,在预测新数据方面的表现也非常糟糕。
6.模型评估
对训练好的模型进行评估。
模型评估主要分为离线评估和在线评估两个阶段。
六、模型评估指标
a. 准确率
就是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好。
(但是准确率只要没到百分百就肯定有问题,例如每次喝水都没事,但是有一次噎住了就g了,人的生命不能重来就是这个意思,老师加这句话我也不理解为什么)
(TP + TN) / (TP + FP +TN+FN)
b.精确率
这是针对预测结果而言的,它表示正确分类的正样本个数占分类器判定为正样本的样本个数的比例。把正类预测为正类(TP),另一种就是把负类预测为正类(FP)。
则 P = TP / ( TP + FP )
c.召回率
是指判定成功的正样本个数占真正的正样本数的比例。
把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)。
则:R = TP / ( TP + FN )
精确率也称为查准率p,召回率也称为查全率r,查准率和查全率是一对矛盾的度量。一般说查准率高时,查全率往往偏低,而查全率高时,查准率往往偏低。(因为计算能力终究是有极限的,你查的越准,那查的就不一定越全,但是未来肯定就不一样了)
计算:

true这列表示正例或者负例,hyp这列表示阈值0.5的情况下,概率是否大于0.5。
根据这个表格我们可以计算:TP=6(实际上有多少正类就是True),FN=0(相当于正类都预测对了,毕竟按0.5算,正类甚至到了8个之多),FP=2(有两个负类被预测成正类),TN=2(预测结果中有几个反例,这个用不到,我们应该一般不算准确率)。
所以
召回率recall = 6/(6+0)=1
精确率precison = 6/(6+2)=0.75
准确率 =(6+2)/(6+0+2+2)= 0.8
下面的在PR曲线里面用到:
那么得出PR曲线坐标(1,0.75)。
同理得到不同阈下的坐标,即可绘制出曲线。
七、PR曲线(本章重点)
(1)用于研究评估分类模型在不同阈值下的精确率(注意不是准确率)和召回率之间的权衡关系。
(2)在PR曲线中,横轴表示召回率,纵轴表示精确率。
(3)绘制PR曲线的方法
1.在测试集上使用分类模型进行预测,并得到相应的概率(或决策分数)。
2.使用不同的阈值将概率(或决策分数)将样本转化为正负例,例如将概率大于0.5的样本预测为正例,小于等于0.5的样本预测为负例。
3.根据阈值和模型预测结果,计算精确率和召回率。
4.使用不同的阈值重复步骤3和步骤4,记录不同阈值下的精确率和召回率。
5.绘制PR曲线时,可以使用线图或者散点图。将不同阈值下的精确率和召回率作为点绘制在图上,并将点按照阈值的大小进行连接,得到PR曲线。
6.可以通过计算PR曲线下的面积来评估模型在精确率和召回率之间的整体性能,面积越大,模型的性能越好。
需要注意的是,PR曲线适用于正负样本不平衡的分类问题,并且对于严重偏斜的数据集,PR曲线可能更能反映模型的性能。

优劣对比:
1:曲线越靠近右上方,性能越好。(例如上图黑色曲线)
2:根据曲线下方面积大小判断,面积更大的更优于面积小的。(例如橘蓝曲线,橘色优于蓝色)
3:平衡点F是查准率与查重率相等时的点。F计算公式为F =2*P*R /(P +R),F值越大,性能越好。
八、机器学习的分类
以下四个机器学习的任务,如何分类?
(1)教计算机下棋;
(2)垃圾邮件识别,教计算机自动识别某个邮件是否是垃圾邮件;
(3)人脸识别,教计算机通过人脸的图像识别这个人是谁;
(4)无人驾驶,教计算机自动驾驶汽车从一个指定地点到另一个指定地点。
(2)、(3)中的经验E是完全由人搜集起来输入进计算机的,称为监督学习。
(1)、(4)中的经验E是由计算机与环境互动获得的,称为强化学习。
1.按学习方式分:
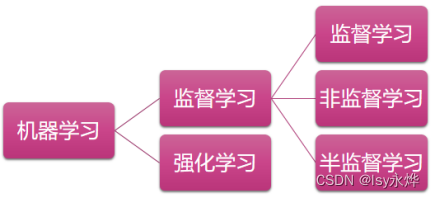
2.按照学习任务分:
有三种——分类,回归,聚类。
分类是预测一个标签 (是离散的),属于监督学习。
回归是预测一个数量 (是连续的),属于监督学习。
聚类属于无监督学习。
聚类是在预先不知道欲划分类的情况下,根据信息相似度原则进行信息聚类的一种方法。聚类的目的是使得属于同类别的对象之间的差别尽可能的小,而不同类别上的对象的差别尽可能的大。
因此,聚类的意义就在于将观察到的内容组织成类分层结构,把类似的事物组织在一起。
3.分类和回归的区别
1)输出不同
分类问题输出的是物体所属的类别,回归问题输出的是物体的值。
例如,根据天气情况预测明天穿衣服的量以及是否携带雨具做判断。
阴天就是分类,多少度就是回归,但是都可以用来判断明天带不带伞。
(2)目的不同
分类的目的是为了寻找决策边界,即分类算法得到是一个决策面。
回归的目的是为了找到最优拟合,通过回归算法得到是一个最优拟合线,这个线条可以最好的接近数据集中的各个点。
(3)结果不同
分类的结果只有一个,判断属于什么类别。
回归是对真实值的一种逼近预测,值不确定,当预测值与真实值相近时,误差较小时,认为这是一个好的回归。
本质一样,都是要建立映射关系。
相关文章:
【复习】人工智能 第7章 专家系统与机器学习
专家系统就是让机器人当某个领域的专家,但这章专家系统不咋考,主要靠书上没有的机器学习。 一、专家系统的基本组成 二、专家系统与传统程序的比较 (1)编程思想: 传统程序 数据结构 算法 专家系统 知识 推理 &…...
使用 Apache PDFBox 操作PDF文件
简介 Apache PDFBox库是一个开源的Java工具,专门用于处理PDF文档。它允许用户创建全新的PDF文件,编辑现有的PDF文档,以及从PDF文件中提取内容。此外,Apache PDFBox还提供了一些命令行实用工具。 Apache PDFBox提供了创建、渲染、…...

【Python 常用脚本及命令系列 3.2 -- 检测到弹框跳出然后关掉它--脚本实现】
文章目录 简介脚本实现 简介 在Python中,你可以使用第三方库如pyautogui和pygetwindow来检测屏幕上的弹框并关闭它。这些库可以模拟鼠标和键盘操作,也可以获取窗口信息。 首先,需要安装这些库(如果你还没有安装的话)&…...
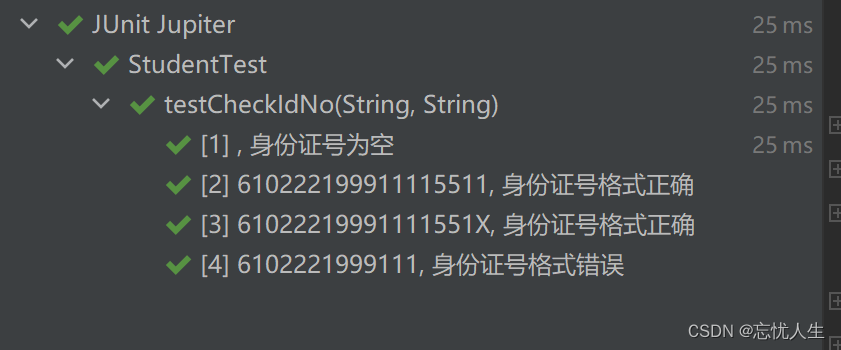
junit单元测试:使用@ParameterizedTest 和 @CsvSource注解简化单元测试方法
在平常的开发工作中,我们经常需要写单元测试。比如,我们有一个校验接口,可能会返回多种错误信息。我们可以针对这个接口,写多个单元测试方法,然后将其场景覆盖全。那么,怎么才能写一个测试方法,…...

C# winform判断自身程序是否已运行,如果已运行则激活窗体
C# winform判断自身程序是否已运行,如果已运行则激活窗体 using System; using System.Collections.Generic; using System.Diagnostics; using System.Linq; using System.Reflection; using System.Runtime.InteropServices; using System.Threading; using Syst…...
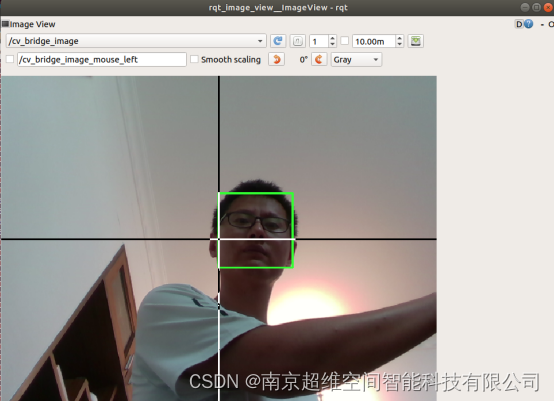
超维空间M1无人机使用说明书——21、基于opencv的人脸识别
引言:M1型号无人机不仅提供了yolo进行物体识别,也增加了基于opencv的人脸识别功能包,仅需要启动摄像头和识别节点即可 链接: 源码链接 一、一键启动摄像头和人脸识别节点 roslaunch robot_bringup bringup_face_detect.launch无报错&#…...
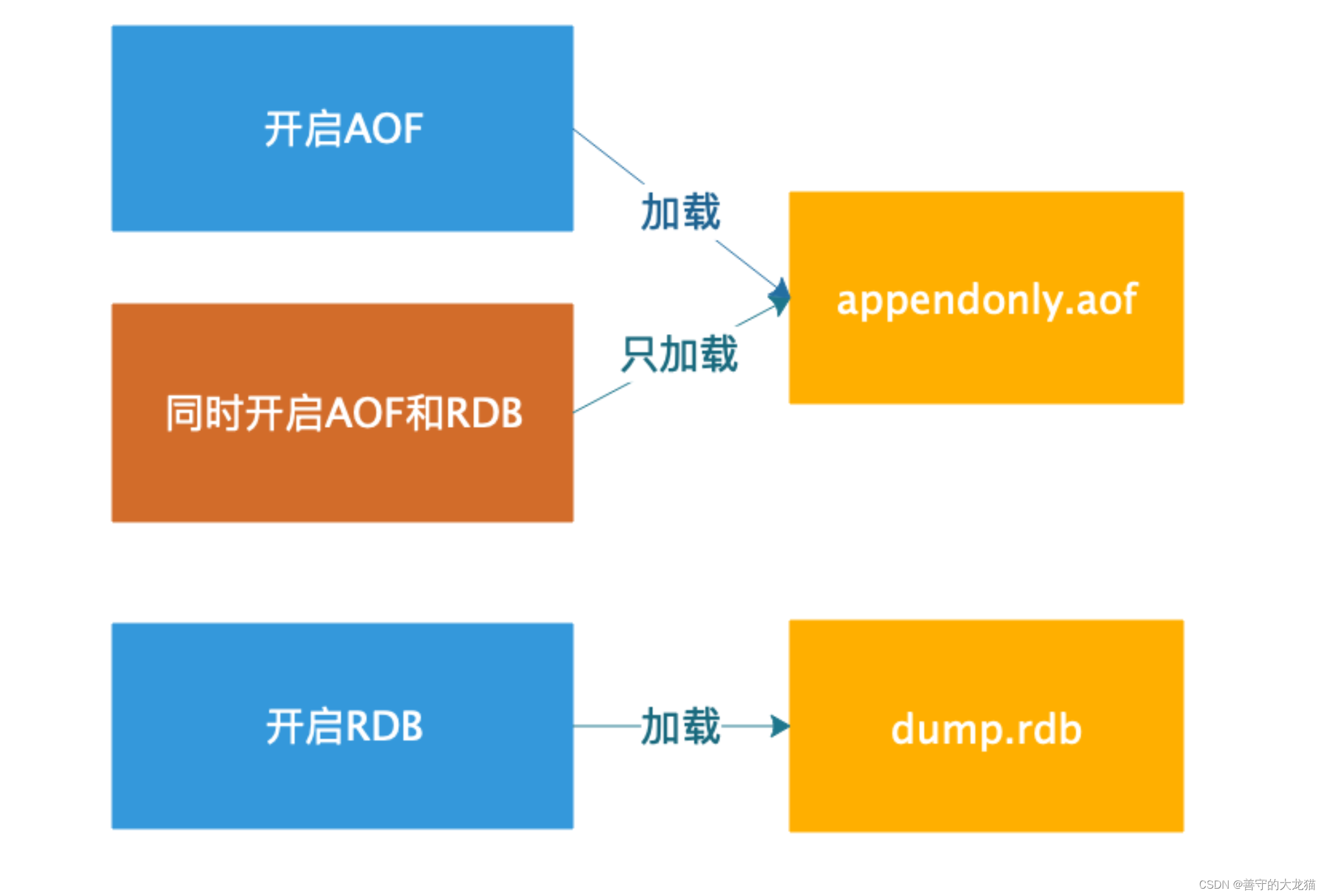
Redis 持久化——AOF
文章目录 为什么需要AOF?概念持久化查询和设置1. 查询AOF启动状态2. 开启AOF持久化2.1 命令行启动AOF2.2 配置文件启动 AOF 3. 触发持久化3.1 自动触发3.3 手动触发 4. AOF 文件重写4.1 什么是AOF重写?4.2 AOF 重写实现4.3 AOF 重写流程 5. 配置说明6. 数据恢复6.1…...
)
华为云服务介绍(二)
在 华为云服务介绍(一) 中我们看到华为云提供了一系列的云服务,包括计算、存储、网络、数据库、安全等方面的解决方案。通过灵活的系统架构设计,可以充分利用这些云服务技术,从而更好地满足用户的需求。 本文从系统架构的角度出发,通过充分利用华为云提供的各种云服务技…...

mysql列题
mysql列题 1.查询学过「张三」老师授课的同学的信息2.查询没有学全所有课程的同学的信息3.查询没学过"张三"老师讲授的任一门课程的学生姓名4.查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩5.检索" 01 "课程分数小于 60,…...

cpu缓存一致性
文章目录 cpu缓存一致性缓存的出现:多核之后带来的缓存一致性问题,如何解决LOCK 指令(刚好可以实现上述的目标)LOCK 指令特性内存屏障特性编译器屏障的作用MESI协议为什么有了 MESI协议 还需要 内存屏障问题:总结&…...
定制CPUSET解决方案-framework部分修改)
Android Framework 常见解决方案(25-1)定制CPUSET解决方案-framework部分修改
1 原理说明 这个方案有如下基本需求: 构建自定义CPUSET,/dev/cpuset中包含一个全新的cpuset分组。且可以通过set_cpuset_policy和set_sched_policy接口可以设置自定义CPUSET。开机启动后可以通过zygote判定来对特定的应用进程设置CPUSET,并…...

PyTorch 参数化深度解析:自定义、管理和优化模型参数
目录 torch.nn子模块parametrize parametrize.register_parametrization 主要特性和用途 使用场景 参数和关键字参数 注意事项 示例 parametrize.remove_parametrizations 功能和用途 参数 返回值 异常 使用示例 parametrize.cached 功能和用途 如何使用 示例…...
自承载 Self-Host ASP.NET Web API 1 (C#)
本教程介绍如何在控制台应用程序中托管 Web API。 ASP.NET Web API不需要 IIS。 可以在自己的主机进程中自托管 Web API。 创建控制台应用程序项目 启动 Visual Studio,然后从“开始”页中选择“新建项目”。 或者,从“ 文件 ”菜单中选择“ 新建 ”&a…...

Vue2-子传父和父传子的基本用法
在Vue 2中,可以使用props和$emit来实现子组件向父组件传值(子传父)和父组件向子组件传值(父传子)。 子传父(子组件向父组件传值)的基本用法如下: 在父组件中定义一个属性ÿ…...

使用numpy处理图片——镜像翻转和旋转
在《使用numpy处理图片——基础操作》一文中,我们介绍了如何使用numpy修改图片的透明度。本文我们将介绍镜像翻转和旋转。 镜像翻转 上下翻转 from PIL import Image import numpy as np img Image.open(example.png) data np.array(img)# axis0 is vertical, a…...

HTML5 article标签,<time>...</time>标签和pubdate属性的运用
1、<article>...</article>标签的运用 article标签代表文档、页面或应用程序中独立的、完整的、可以独自被外部引用的内容。它可以是一篇博客或报竟杂志中的文章、一篇论坛帖子、一段用户评论或一个独立的插件,或者其他任何独立的内容。把文章正文放在h…...
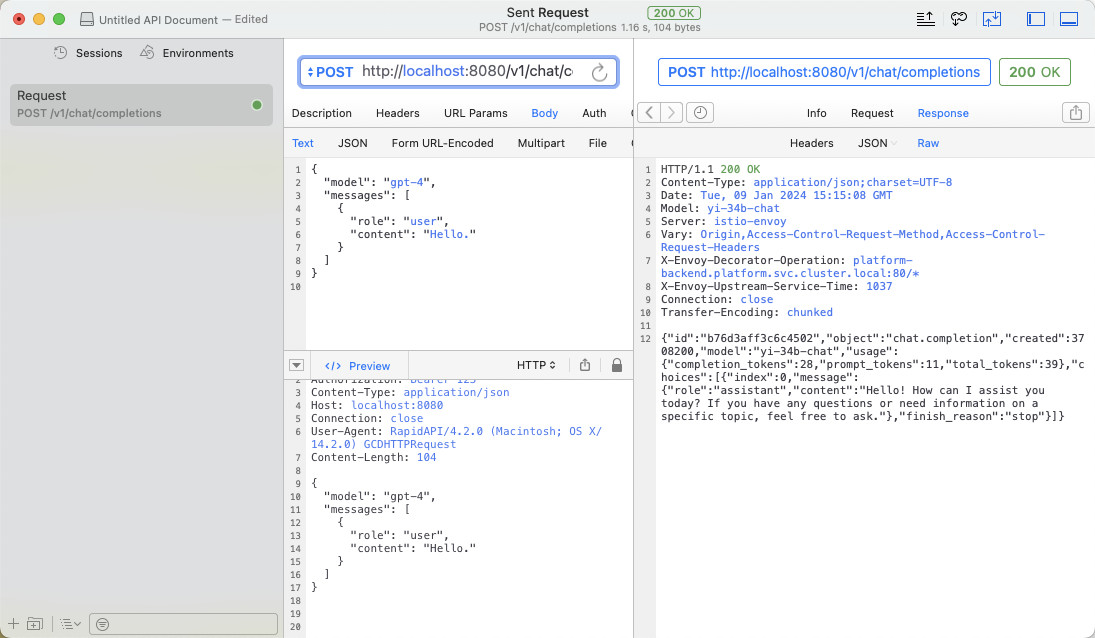
Amazing OpenAI API:把非 OpenAI 模型都按 OpenAI API 调用
分享一个有趣的小工具,10MB 身材的小工具,能够将各种不同的模型 API 转换为开箱即用的 OpenAI API 格式。 让许多依赖 OpenAI API 的软件能够借助开发者能够接触到的,非 OpenAI 的 API 私有部署和使用起来。 写在前面 这个小工具软件写于两…...

RK3568平台开发系列讲解(驱动篇)pinctrl 函数操作集结构体讲解
🚀返回专栏总目录 文章目录 一、pinctrl_ops二、pinmux_ops三、pinconf_ops沉淀、分享、成长,让自己和他人都能有所收获!😄 pinctrl_ops:提供有关属于引脚组的引脚的信息。pinmux_ops:选择连接到该引脚的功能。pinconf_ops:设置引脚属性(上拉,下拉,开漏,强度等)。…...

vue购物车案例,v-model 之 lazy、number、trim,与后端交互
购物车案例 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title><script src"./js/vue.js"></script> </head> <body> <div id"d1"&…...

云原生Kubernetes: Kubeadm部署K8S 1.29版本 单Master架构
目录 一、实验 1.环境 2.K8S master节点环境准备 3.K8S master节点安装kubelet、kubeadm、kubectl 3.K8S node节点环境准备与软件安装 4.K8S master节点部署服务 5.K8S node节点部署 6.K8S master节点查看集群 7.容器网络(CNI)部署 8.K8S 集群…...

蒙特卡洛方法赋能智能体决策:原理、实现与工程实践
1. 项目概述:一个为智能体注入“蒙特卡洛”思想的工具箱最近在探索智能体(Agent)开发时,我一直在思考一个问题:如何让智能体的决策过程不那么“一根筋”?我们常见的基于规则或简单LLM调用的智能体ÿ…...

不止于导航:用AI Habitat的语义分割数据,教你构建自己的室内物体识别与场景理解Pipeline
不止于导航:用AI Habitat的语义分割数据构建室内物体识别与场景理解Pipeline 在计算机视觉与机器人领域,室内场景理解一直是极具挑战性的研究方向。传统方法依赖于昂贵的传感器设备和人工标注数据,而仿真平台的出现为这一领域带来了革命性变…...
)
解决Modelsim SE 10.6c仿真Vivado 2019乘法器IP核的“.vhd only”难题(附完整脚本)
解决Modelsim SE 10.6c仿真Vivado 2019乘法器IP核的“.vhd only”难题(附完整脚本) 在FPGA设计流程中,Xilinx Vivado与Mentor Modelsim的组合是许多工程师的首选工具链。但当Vivado 2019生成的乘法器IP核仅提供VHDL接口文件(.vhd)时ÿ…...

德国工业4.0:从顶层设计到车间实践的制造业数字化转型
1. 工业4.0浪潮下的欧洲:一场由德国引领的深度变革提到德国制造,很多人脑海里蹦出来的词是“严谨”、“保守”甚至“刻板”。没错,德国人对于工业流程、制造工艺和质量标准的执着,有时近乎偏执。但正是这种对“传统”的极致坚守&a…...

从DataOperation接口到QuickSort实现:探究适配器模式在算法整合中的应用
1. 适配器模式:解决接口不兼容的桥梁 想象一下你从国外带回来一个三脚插头的电器,但家里的插座都是两孔的。这时候你会怎么做?大多数人会选择买一个转换插头。在编程世界里,适配器模式就是这个万能的"转换插头"。 最近我…...

MCP协议专用Linter:mcp-lint工具的设计、规则与集成实践
1. 项目概述:一个为MCP协议量身定制的代码质量守护者 最近在折腾MCP(Model Context Protocol)相关的开发,发现一个挺有意思的项目: robert19001-cmyk/mcp-lint 。光看名字,你大概能猜到它是个代码检查工具…...

给 Agent 用的搜索:Cloudflare AI Search 是什么,怎么工作的
原文:AI Search: the search primitive for your agents 发布时间:2026 年 4 月 16 日 作者:Gabriel Massadas、Miguel Cardoso、Anni Wang 每个 Agent 都需要搜索,但自己搭很麻烦 编码 Agent 要检索数百万个文件,客服…...

Python并发模型全景解析
Python并发模型全景解析:线程、协程、多进程与GIL深度实战 🐍 Python 的并发编程一直是个让人困惑的话题:GIL 是什么?什么时候用线程?什么时候用协程?什么时候用多进程?本文从底层原理到生产实战,彻底讲清楚 Python 的四种并发模型,附带性能对比测试和真实踩坑经验。…...

什么是dapr?为什么要使用它
官方文档https://docs.dapr.io/zh-hans/developing-applications/building-blocks/ 介绍 dapr是一个分布式运行时(Distributed Application Runtime)是一个开源项目,它把构建微服务的最佳实践沉淀为开发者可直接调用的标准化API,…...

Cropper.js进阶玩法:打造一个可撤销、可缩放、带滤镜的在线图片编辑器
Cropper.js进阶玩法:打造一个可撤销、可缩放、带滤镜的在线图片编辑器 在当今数字内容创作蓬勃发展的时代,轻量级在线图片编辑工具的需求与日俱增。Cropper.js作为一款优秀的JavaScript图片裁剪库,其潜力远不止于基础的裁剪功能。本文将带您深…...