【2023 CSIG垂直领域大模型】大模型时代,如何完成IDP智能文档处理领域的OCR大一统?
目录
- 一、像素级OCR统一模型:UPOCR
- 1.1、为什么提出UPOCR?
- 1.2、UPOCR是什么?
- 1.2.1、Unified Paradigm 统一范式
- 1.2.2、Unified Architecture统一架构
- 1.2.3、Unified Training Strategy 统一训练策略
- 1.3、UPOCR效果如何?
- 二、OCR大一统模型前沿研究速览
- 2.1、Donut:无需OCR的用于文档理解的Transformer模型
- 2.2、NouGAT:**实现文档图像到文档序列输出**
- 2.3、SPTS v3:基于SPTS的OCR大一统模型
- 三、大模型时代下的智能文档处理应用
- 3.1、LLM与文档识别分析应用
- 3.2、智能文档处理应用产品
- 四、文末抽奖
2023年12月28-31日,由中国图象图形学学会主办的第十九届CSIG青年科学家会议在中国广州隆重召开,会议吸引了学术界和企业界专家与青年学者,会议面向国际学术前沿与国家战略需求,聚焦最新前沿技术和热点领域,共同探讨图象图形学领域的前沿问题,分享最新的研究成果和创新观点,在垂直领域大模型专场,合合信息智能技术平台事业部副总经理、高级工程师丁凯博士为我们带来了《文档图像大模型的思考与探索》主题报告。
本文将围绕以下问题,分享主题报告中大模型时代下的智能文档图像处理领域研究问题与深度思考:
- 以GPT4-V Gemini为代表大模型能为IDP领域的技术方案和研发范式上带来什么样的启发?
- 能否吸取大模型的优点,提出精度好、泛化强的OCR大一统模型?
- 能否更好的将LLM与文档识别分析引擎相结合来解决IDP领域的核心问题?
一、像素级OCR统一模型:UPOCR
UPOCR是合合信息-华南理工大学文档图像分析识别与理解联合实验室于2023年12月提出的像素级OCR统一模型。UPOCR基于视觉Transformer(ViT)的编码器-解码器架构,将多样OCR任务统一为图像到图像变换范式,并引入了可学习任务提示,将编码器提取的通用特征表示推向任务特定空间,使解码器具有任务意识。实验表明,模型能够具有对不同任务的建模功能,能够同时实现文本擦除、文本分割和篡改文本检测等像素级OCR任务。
1.1、为什么提出UPOCR?
当前通用文字识别(OCR)领域面临多项主要问题,这些问题实然限制了其在各个应用领域的广泛应用。
- 任务特定性模型的碎片化:虽然OCR领域研究涌现出许多面向特定任务的模型,但每个模型都仅针对特定领域进行优化,模型过于碎片化,不同任务之间难以协同使用,跨领域和多场景的通用性受到较大限制。
- 缺乏统一接口:现有的一些通用模型依赖于特定的接口或解码机制如VQGAN,这种依赖性限制了模型在像素空间的灵活性和适应性,难以关联实现不同任务。
- 像素级OCR难题:当前模型在生成像素级的文本序列方面仍然面临挑战。这是因为文本生成不仅涉及语义理解,还需要考虑像素级别的细节,改善模型在生成像素级文本方面的能力仍是一个重要的研究方向。
1.2、UPOCR是什么?
UPOCR是一个通用的OCR模型,其采用了华南理工大学团队AAAI 2024录用论文中的ViTEraser作为主干网,同时借鉴基于MIM和分割图引导的一种自监督文档图像预训练方法SegMIM进行自监督预训练,然后结合文本擦除、文本分割和篡改文本检测等3个不同的任务提示词进行统一训练。
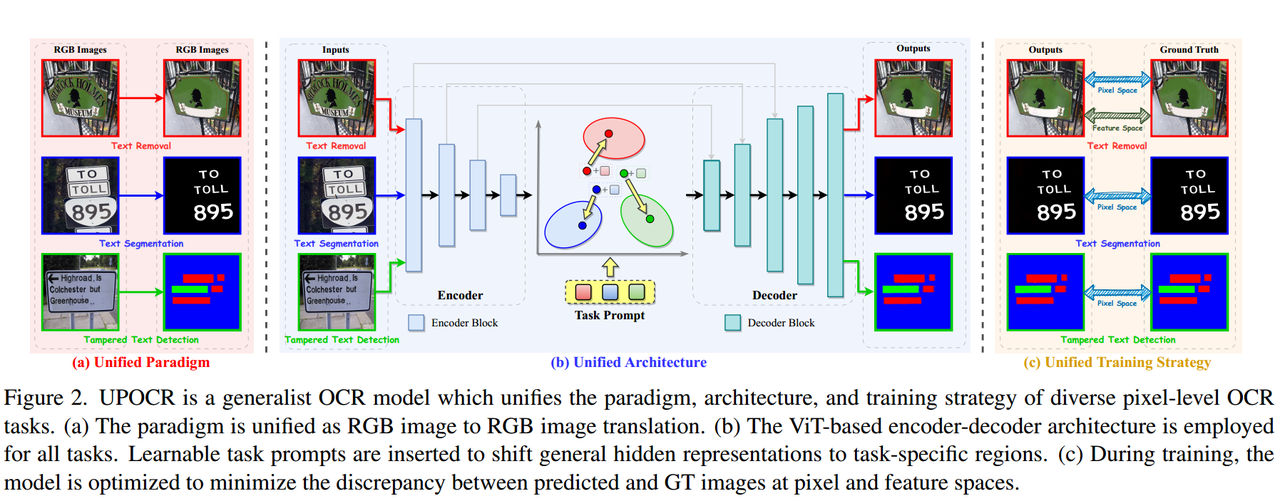
模型训练好后即可直接用于下游任务,无需再进行专门的精调,模型主要从统一范式、统一架构和统一训练策略三个方面进行研究。
1.2.1、Unified Paradigm 统一范式
如图所示,作者提出了一个OCR任务统一范式,其将各种像素级OCR任务转化为RGBtoRGB的转换问题。尽管这些任务的目标不同(例如图像生成和分割),但它们都可以被统一为在共享的特征空间中进行操作:
- 文本擦除任务:对于文本擦除任务,输出是与输入对应的去除文本的图像,属于RGBtoRGB任务。
- 文本分割任务:文本分割旨在将每个像素分配给前景(即文本笔画)或背景,在统一的图像到图像翻译范式下,UPOCR预测具有白色和黑色颜色的RGB图像,通过对比生成的RGB值与预定义的前景RGB值的距离来确定类别。
- 篡改文本检测任务:将篡改文本检测任务定义为篡改文本、真实文本和背景类别的每像素分类,进而UPOCR分别为篡改文本、真实文本和背景分配红色(255, 0, 0)、绿色(0, 255, 0)和蓝色(0, 0, 255)颜色。在推断过程中,通过比较预测的RGB值与这三种颜色的距离来确定每像素的类别。
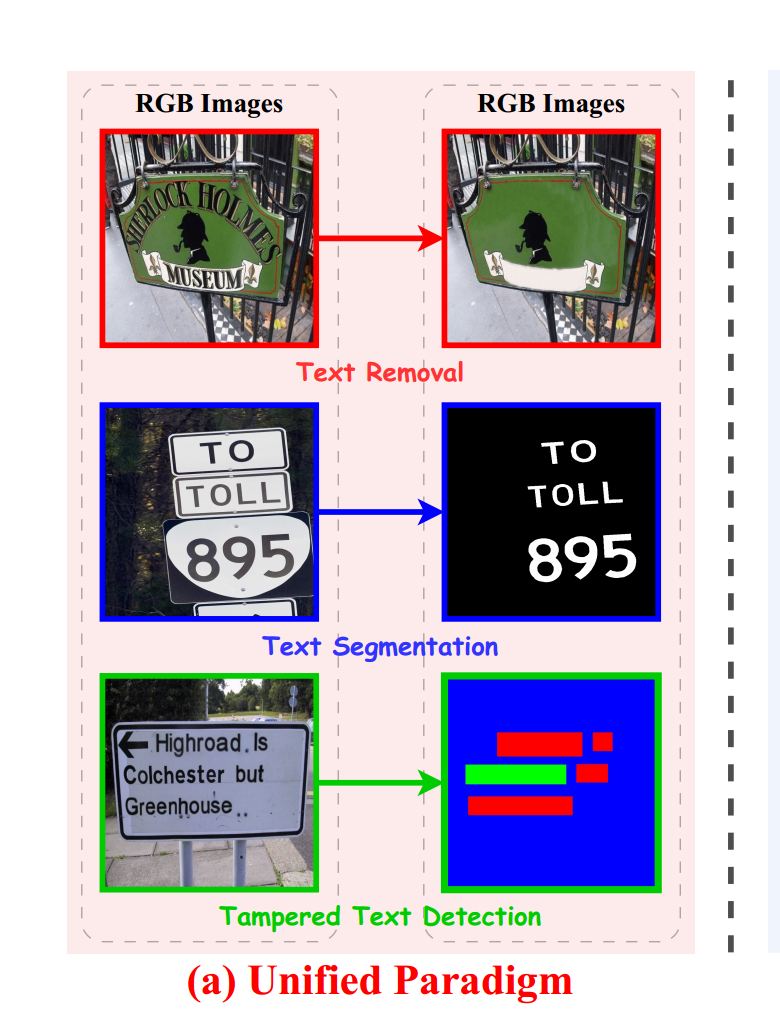
1.2.2、Unified Architecture统一架构
如图所示,作者通过采用基于ViT的编码器-解码器实现了一个统一的图像到图像翻译范式来处理各种像素级OCR任务。其中,编码器-解码器架构采用了ViTEraser作为主干网络,编码器包括四个顺序块,每个编码器块包含一个用于下采样的块嵌入层和Swin Transformer v2块。解码器部分包括五个顺序块,每个解码器块包含一个用于上采样的块分割层和Swin Transformer v2块。
另外,作者在编码器-解码器架构中引入可学习的任务提示,对应的提示被添加到编码器生成的隐藏特征的每个像素上,推动由编码器生成的通用OCR相关表示朝着任务特定区域。随后,解码器将调整后的隐藏特征转换为特定任务的输出图像。基于这种架构,UPOCR能够在极小的参数和计算开销下简单而有效地同时处理多样的任务。
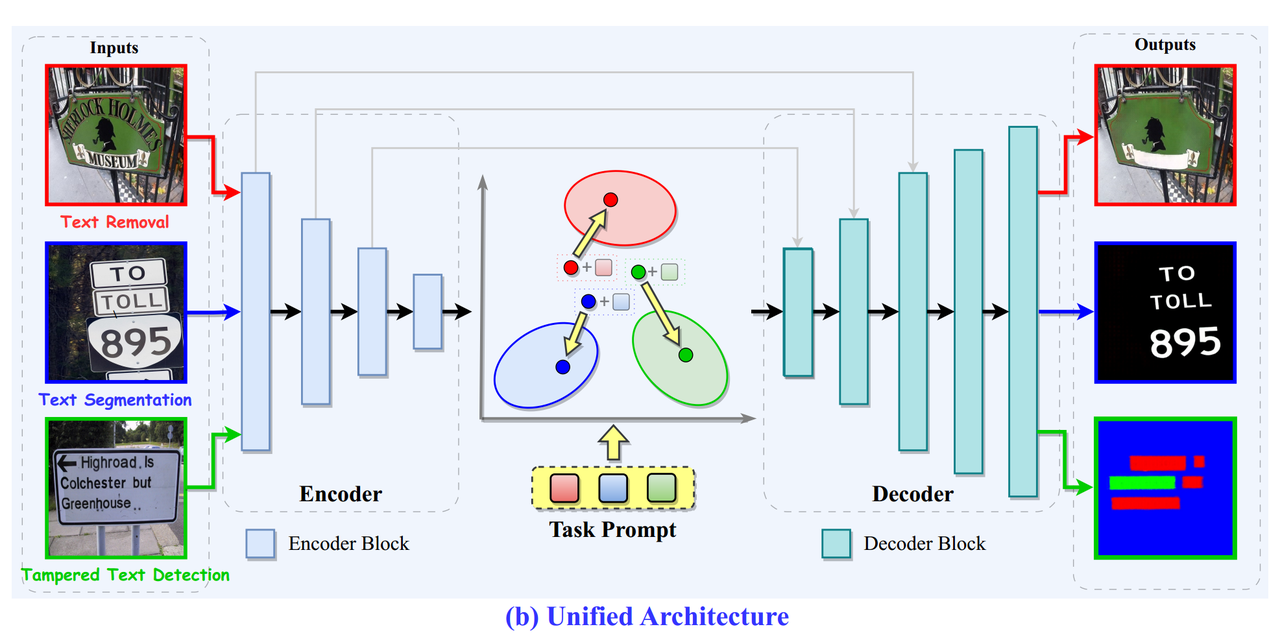
1.2.3、Unified Training Strategy 统一训练策略
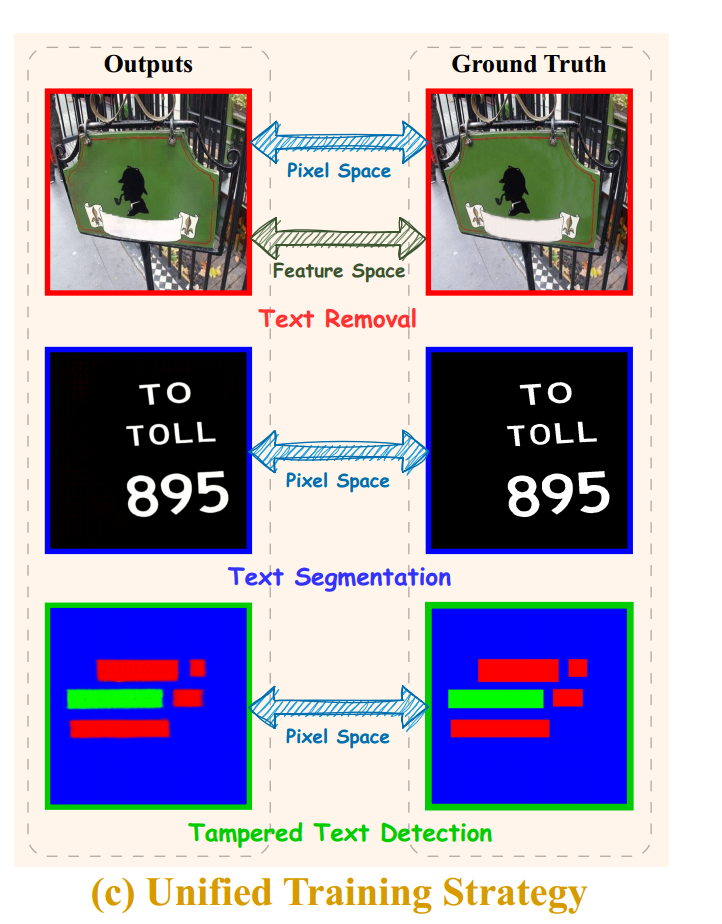
由于模型采用图像到图像的转换范式进行训练,所以在训练过程中,模型优化的目标只需要考虑最小化生成预测图像和真实图像在像素空间和特征空间上的差异,而不用考虑任务之间的差异。
- 像素 空间损失:通过输出图像和真实图像之间的L1距离来测量像素空间中的差异: L p i x = ∑ i = 1 3 α i ∥ I out i − I g t i ∥ 1 L_{p i x}=\sum_{i=1}^{3} \alpha_{i}\left\|\mathbb{I}_{\text {out }}^{i}-\mathbb{I}_{g t}^{i}\right\|_{1} Lpix=∑i=13αi Iout i−Igti 1,其中 I o u t i \mathbb{I}_{out}^{i} Iouti表示输出图像, I g t i \mathbb{I}_{g t}^{i} Igti表示真实图像。
- 特征空间损失:对于与真实图像生成相关联的任务,还需要将输出图像和真实图像在特征空间对齐: L feat = 0.01 × L per + 120 × L sty L_{\text {feat }}=0.01 \times L_{\text {per }}+120 \times L_{\text {sty }} Lfeat =0.01×Lper +120×Lsty
- 整体损失:模型整体损失是像素损失和特征损失的和: L total = L p i x + L feat L_{\text {total }}=L_{p i x}+L_{\text {feat }} Ltotal =Lpix+Lfeat
1.3、UPOCR效果如何?

实验结果如上图三个表所示,左上方表格是文本擦除实验对比,即使与擦除领域专用的精调模型相比,UPOCR统一模型在大部分指标上也领先领域的SOTA方法;右上方表格是文本图像分割实验对比,可以看到,UPOCR在所有指标都比专门单一任务的分割方法好;左下方表格是文本篡改检测,UPOCR也取得了很好的效果。图5显示UPOCR模型设计的任务相关Prompt也可以很好的区分不同的任务,下图是文本擦除、分割、及篡改检测与现有子任务的SOTA方法的可视化对比图。

综上所述,UPOCR提出了一种简单而有效的统一像素级OCR接口,其采用基于ViT的编码器-解码器,通过可学习的任务提示来处理各种任务,在文本去除、文本分割和篡改文本检测等任务上都表现出极高的性能。
二、OCR大一统模型前沿研究速览
2.1、Donut:无需OCR的用于文档理解的Transformer模型
论文地址:https://link.springer.com/chapter/10.1007/978-3-031-19815-1_29
项目地址:https://github.com/clovaai/donut
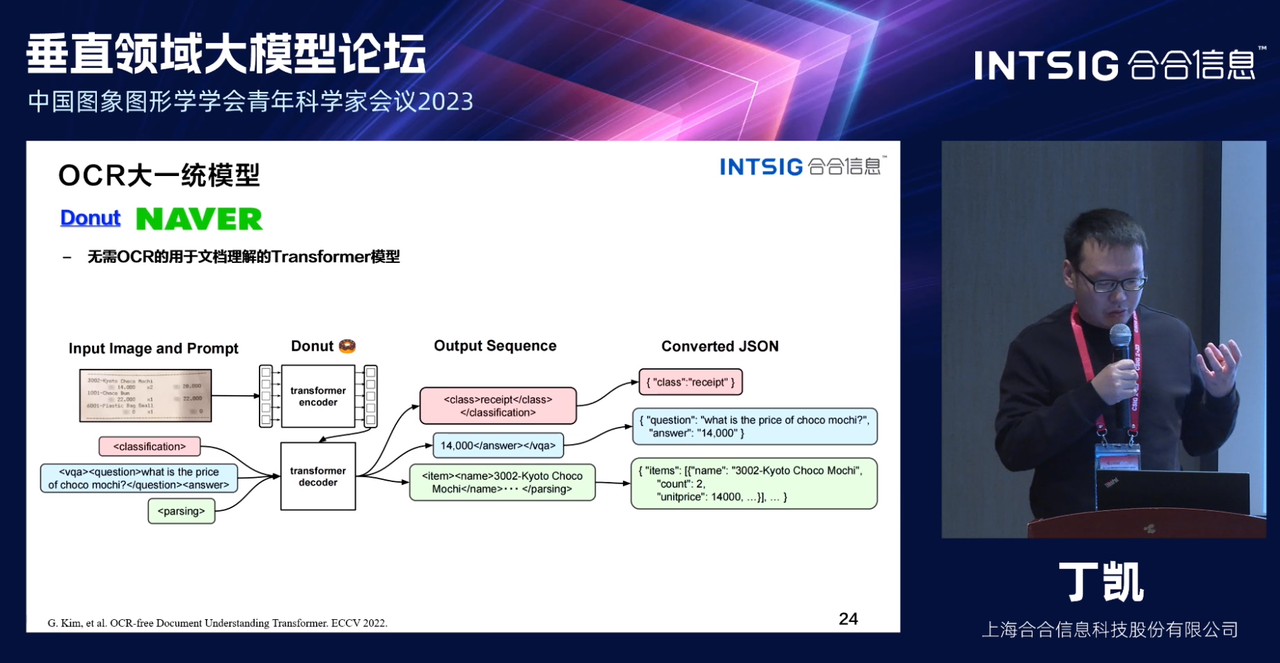
Donut模型是一种基于Transformer架构的新颖的OCR-free VDU模型,Donut模型首先通过一个简单的规则生成布局,然后应用一些图像渲染技术来模拟真实的文档,其通过预训练和微调两个阶段进行训练。在预训练阶段,模型使用IIT-CDIP数据集进行视觉语言建模,学习从图像中读取文本。在微调阶段,模型被训练为生成JSON格式的输出,以解决下游任务,如文档分类、文档信息提取和文档视觉问答等。与其他基于OCR的模型相比,Donut不需要依赖于OCR引擎,因此具有更高的速度和更小的模型大小。在多个公共数据集上进行的实验表明,Donut在文档分类任务中表现出了先进性能。
2.2、NouGAT:实现文档图像到文档序列输出
论文地址:https://arxiv.org/abs/2308.13418
项目地址:https://github.com/facebookresearch/nougat
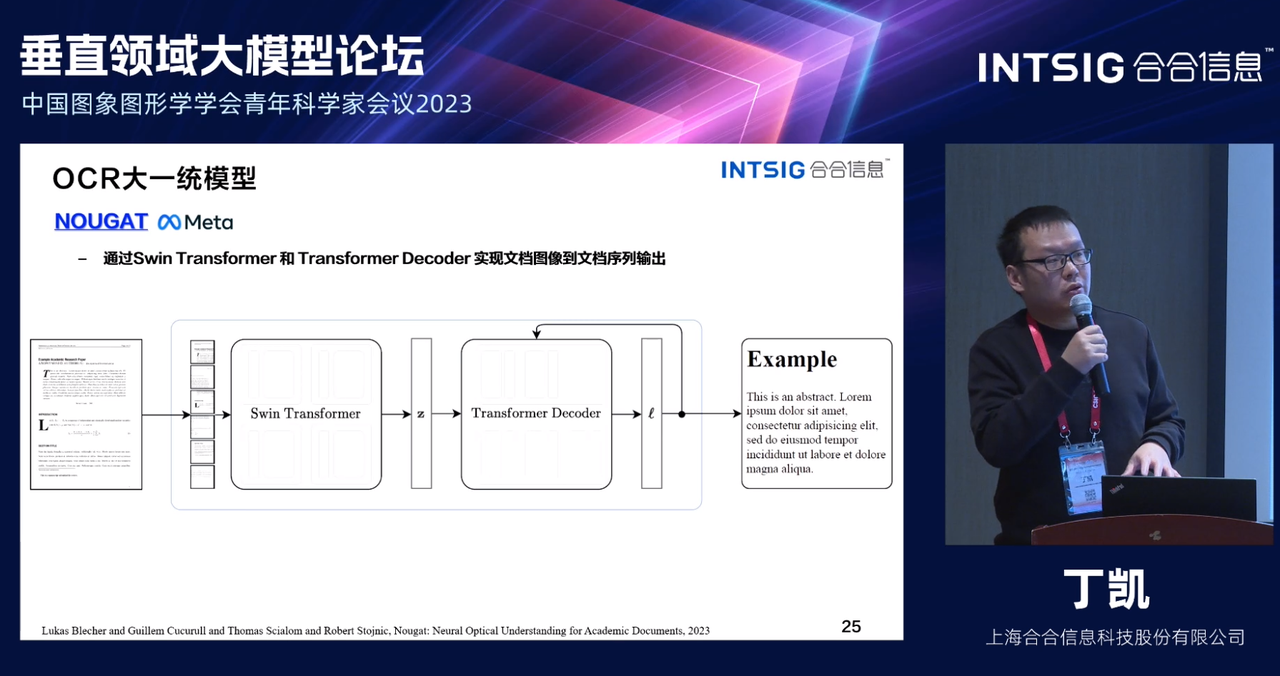
Nougat模型是一种通过Swing Transformer 和 Transformer Decoder实现文档图像到文档序列输出的OCR模型,模型采用基于OCR-free Transformer的端到端训练方法,采用预训练和微调的方式进行训练。在预训练阶段,Donut使用文档图像和它们的文本注释进行预训练,通过结合图像和之前的文本上下文来预测下一个词,从而学习如何读取文本。在微调阶段,Donut根据下游任务学习如何理解整个文档。各种VDU任务和数据集上的大量评估证明了Donut具有较强的理解能力。
2.3、SPTS v3:基于SPTS的OCR大一统模型
论文地址:https://arxiv.org/abs/2112.07917
项目地址:https://github.com/shannanyinxiang/SPTS
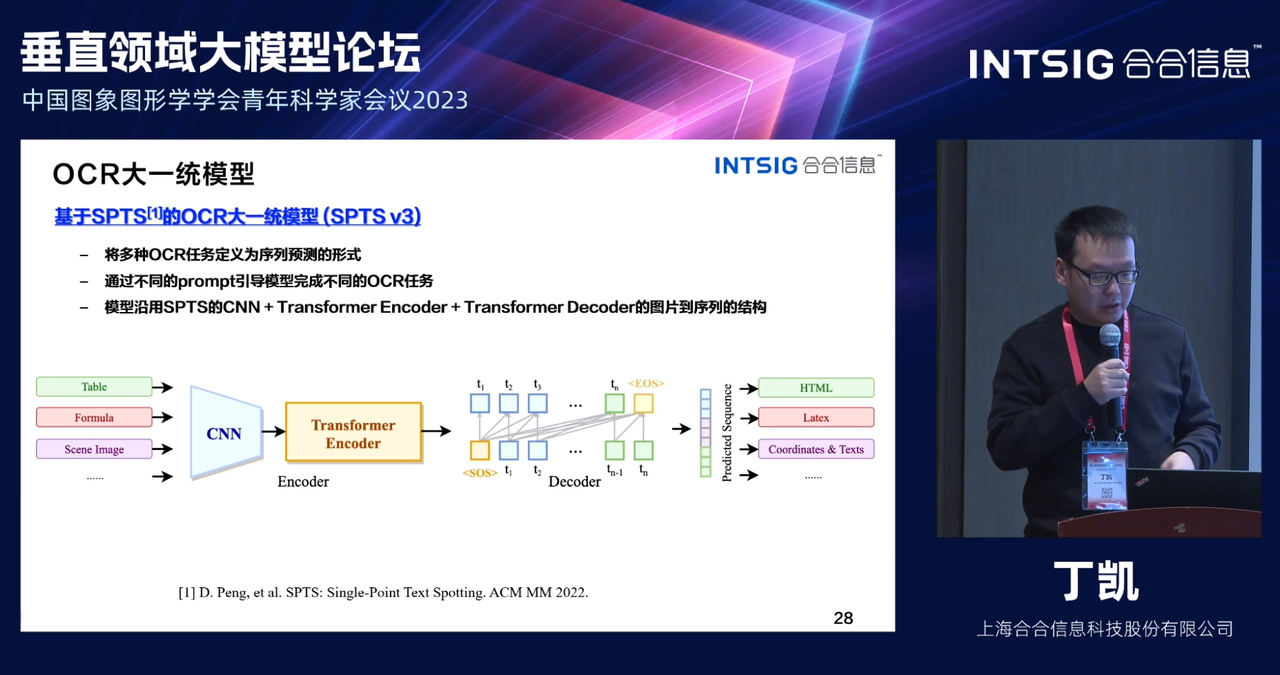
SPTS,全称Single-Point Text Spotting,是一种单点文本识别技术,它的主要创新之处在于:方法使用极低成本的单点标注进行训练将文本检测任务形式化为语言建模任务,只需要对每个文本实例进行单一点的标注,就可以训练出场景文本识别模型。SPTS基于自回归Transformer的框架,可以简单地将结果生成为顺序令牌,从而避免复杂的后处理或独占采样阶段。基于这样一个简洁的框架,SPTS在各种数据集上显示出先进性能。
三、大模型时代下的智能文档处理应用
3.1、LLM与文档识别分析应用
大语言模型能够理解自然语言文本,并具备上下文理解的能力,在文档识别分析应用中,将文档理解相关的工作交给大语言模型,自动进行篇章级的文档理解和分析,可以帮助系统更好地理解文档内容,包括上下文中的关系、实体识别、情感分析等。目前最常见和最广泛的应用包括检索增强生成(RAG)、文档问答。

- 检索增强生成:已经有大语言模型针对从大量文档中检索相关信息,并以生成的方式提供更详细、准确的答案。这在信息检索的场景中具有重要的应用价值。
- 文档问答:LLM可以直接用于构建文档问答系统,使用户能够通过提出问题来获取文档中的相关信息,可以应用于如法律文件的解读、技术手册的查询、知识库理解等场景。
3.2、智能文档处理应用产品
智能文档处理(Intelligent Document Processing,IDP)利用人工智能和机器学习技术来自动分析和理解文档,它通过识别、解析、理解文档内容,并将其转换成可操作的数据或信息,以提高业务流程的自动化程度,提升工作效率,降低成本。
丁凯博士还为我们带来合合信息文档图像识别与分析产品分享,基于这样的智能文档处理技术,产品可以快速、准确地处理大量的文档,帮助银行、保险、物流、供应链、客户服务等多个领域数智化转型,实现更高效、更可靠的业务流程管理。
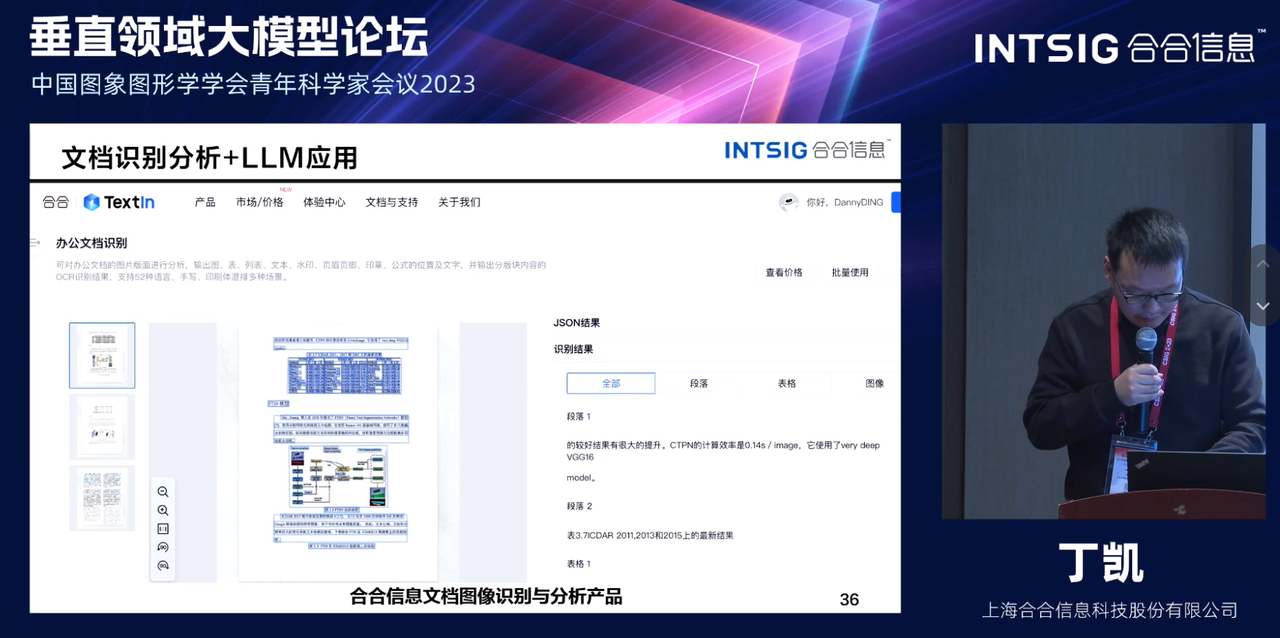
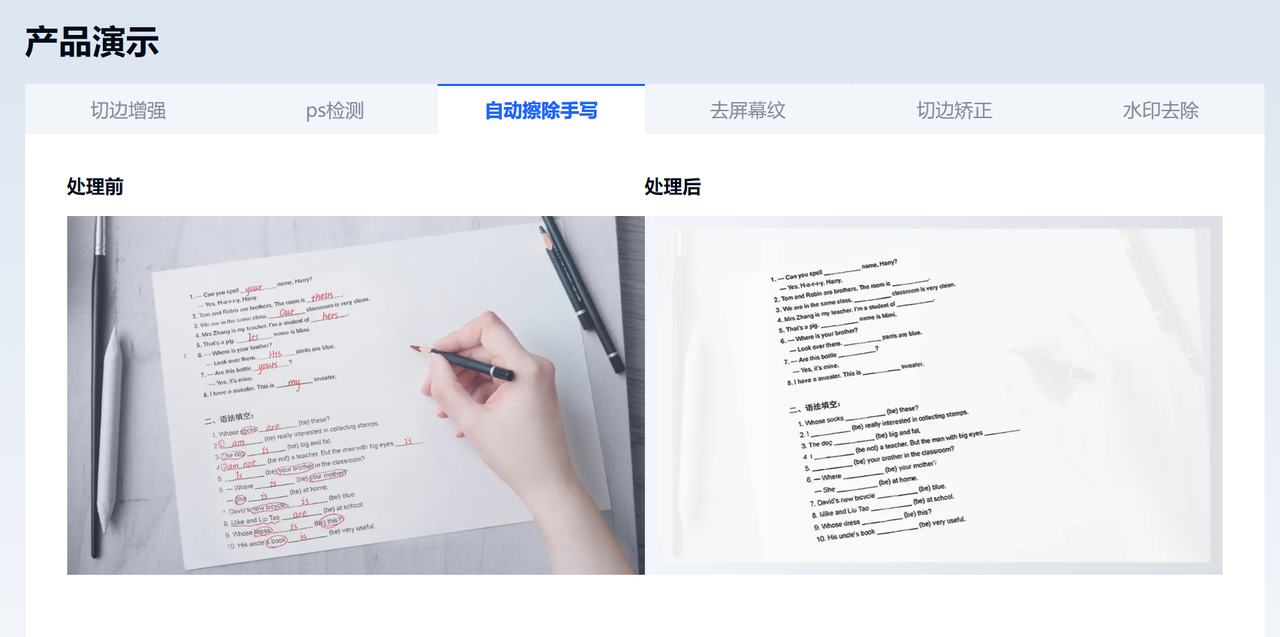
合合信息TextIn智能文字识别产品基于自研的文字识别技术、计算机图形图像技术和智能图像处理引擎,能够快速将纸质文档或图片中的文字信息转化为计算机可读的文本格式,在纸质文档电子化、办公文档/报表识别、教育类文本识别、快递面单识别、切边增强、弯曲矫正、阴影处理、印章检测、手写擦除等诸多场景中提供更好的文档管理解决方案,帮助企业实现数字化转型和自动化管理。
虽然GPT4-V为代表的多模态大模型技术极大的推进了文档识别与分析领域的技术进展,但并没有完全解决图像文档处理领域面临的问题,还有很多问题值得我们研究,如何结合大模型的能力,更好的解决IDP的问题,值得我们做更多的思考和探索。

四、文末抽奖

合合信息给大家送福利了!填写年度问卷:https://qywx.wjx.cn/vm/exOhu6f.aspx,1月12日将随机抽取10个人送50元京东卡,欢迎参与!
相关文章:
【2023 CSIG垂直领域大模型】大模型时代,如何完成IDP智能文档处理领域的OCR大一统?
目录 一、像素级OCR统一模型:UPOCR1.1、为什么提出UPOCR?1.2、UPOCR是什么?1.2.1、Unified Paradigm 统一范式1.2.2、Unified Architecture统一架构1.2.3、Unified Training Strategy 统一训练策略 1.3、UPOCR效果如何? 二、OCR大一统模型前…...
Phi-2小语言模型QLoRA微调教程
前言 就在不久前,微软正式发布了一个 27 亿参数的语言模型——Phi-2。这是一种文本到文本的人工智能程序,具有出色的推理和语言理解能力。同时,微软研究院也在官方 X 平台上声称:“Phi-2 的性能优于其他现有的小型语言模型&#…...

hadoop自动获取时间
1、自动获取前15分钟 substr(from_unixtime(unix_timestamp(concat(substr(20240107100000,1,4),-,substr(20240107100000,5,2),-,substr(20240107100000,7,2), ,substr(20240107100000,9,2),:,substr(20240107100000,11,2),:,00))-15*60,yyyyMMddHHmmss),1) unix_timestam…...

【面试高频算法解析】算法练习8 单调队列
前言 本专栏旨在通过分类学习算法,使您能够牢固掌握不同算法的理论要点。通过策略性地练习精选的经典题目,帮助您深度理解每种算法,避免出现刷了很多算法题,还是一知半解的状态 专栏导航 二分查找回溯(Backtracking&…...

ATTCK视角下的信息收集:Sysmon检测
目录 1、简介 2、使用Sysmon 3、检测Sysmon是否安装运行 4、检测Sysmon是否被卸载 5、使Sysmon在终端隐匿运行的技术 1、简介 Sysmon(系统监视器)是由windows sysinternals 出品的Sysinternals 系列工具中的一个 它是windows系统服务和设备驱动程…...

02、Kafka ------ 配置 Kafka 集群
目录 配置 Kafka 集群配置步骤启动各Kafka节点 配置 Kafka 集群 启动命令: 1、启动 zookeeper 服务器端 小黑窗输入命令: zkServer 2、启动 zookeeper 的命令行客户端工具 (这个只是用来看连接的节点信息,不启动也没关系&#…...

2024年全球网络安全预测报告
1.Gartner Gartners Top Strategic Predictions for 2024 and Beyond《Gartner顶级战略预测:2024年及未来》 https://www.gartner.com/en/articles/gartner-s-top-strategic-predictions-for-2024-and-beyond 2.IDC Top 10 Worldwide IT Industry 2024 Predict…...

Qt - QML与C++数据交互详解
文章目录 1 . 前言2 . Qml调用C的变量3 . Qml调用C的类4 . Qml调用C的方法5 . Qml接收C的信号6 . C接收Qml的信号(在Qml中定义信号槽)7 . C接收Qml的信号(在C中定义信号槽)8 . C调用Qml的函数9 . 总结 【极客技术传送门】 : https…...
Kettle Local引擎使用记录(一)(基于Kettle web版数据集成开源工具data-integration源码)
Kettle Web 📚第一章 前言📚第二章 demo源码📗pom.xml引入Kettle引擎核心文件📗java源码📕 controller📕 service📕 其它📕 maven settings.xml 📗测试📕 测试…...
Java--业务场景:在Spring项目启动时加载Java枚举类到Redis中(补充)
文章目录 前言步骤测试结果 前言 通过Java–业务场景:在Spring项目启动时加载Java枚举类到Redis中,我们成功将Java项目里的枚举类加载到Redis中了,接下来我们只需要写接口获取需要的枚举值数据就可以了,下面一起来编写这个接口吧。 步骤 在…...

WPF 基础入门(资源字典)
资源字典 每个Resources属性存储着一个资源字典集合。如果希望在多个项目之间共享资源的话,就可以创建一个资源字典。资源字段是一个简单的XAML文档,该文档就是用于存储资源的,可以通过右键项目->添加资源字典的方式来添加一个资源字典文件…...

文章解读与仿真程序复现思路——电网技术EI\CSCD\北大核心《考虑电氢耦合和碳交易的电氢能源系统置信间隙鲁棒规划》
本专栏栏目提供文章与程序复现思路,具体已有的论文与论文源程序可翻阅本博主免费的专栏栏目《论文与完整程序》 这标题涉及到一个复杂的能源系统规划问题,其中考虑了电氢耦合、碳交易和置信间隙鲁棒规划。以下是对标题各个部分的解读: 电氢耦…...

ubuntu设定时间与外部ntp同步
前言 在 Ubuntu 上,你可以通过配置 systemd-timesyncd 服务来与外部 NTP 服务器同步系统时间。下面是设置的步骤: 安装 NTP 工具: 如果你的系统中没有安装 ntpdate 工具,可以使用以下命令安装: sudo apt-get updat…...

DataFrame详解
清洗相关的API 清洗相关的API: 1.去重API: dropDupilcates 2.删除缺失值API: dropna 3.替换缺失值API: fillna 去重API: dropDupilcates dropDuplicates(subset):删除重复数据 1.用来删除重复数据,如果没有指定参数subset,比对行中所有字段内容,如果全部相同,则认为是重复数据,…...
控制障碍函数(Control Barrier Function,CBF) 三、代码
三、代码实现 3.1、模型 这是一个QP问题,所以我们直接建模 这其实还是之前的那张图,我们把这个大的框架带入到之前的那个小车追击的问题中去,得到以下的一些具体的约束条件 CLF约束 L g V ( x ) u − δ ≤ − L f V ( x ) − λ V ( x ) …...

哈希表-散列表数据结构
1、什么是哈希表? 哈希表也叫散列表,哈希表是根据关键码值(key value)来直接访问的一种数据结构,也就是将关键码值(key value)通过一种映射关系映射到表中的一个位置来加快查找的速度,这种映射关系称之为哈希函数或者散列函数&…...

C# 强制类型转换和as区别和不同使用场景
文章目录 1.强制类型转换2. as 运算符3.实例总结: 在C#中,as 和 强制类型转换(例如 (T)value)的主要区别在于它们处理类型转换不成功时的行为和适用场景: 1.强制类型转换 使用语法:Type variable (Type)…...

什么是 DDoS 攻击
布式拒绝服务 (DDoS) 攻击是一种恶意尝试,通过大量互联网流量淹没目标或其周围基础设施,从而破坏目标服务器、服务或网络的正常流量。 DDoS 攻击通过利用多个受感染的计算机系统作为攻击流量源来实现有效性。被利用的机器可以包括计算机和其他网络资源。 从高层来看,DDoS 攻…...

c++隐式类型转换与explicit
我们知道,一个float与int做运算时,系统会首先个int类型转换为float类型之后再进行运算,这种隐式类型转换也会发生在类中 看以下例子,定义一个类 class myTime { public:int Hour;myTime() {};myTime(int h) :Hour(h) {}; }; 在…...
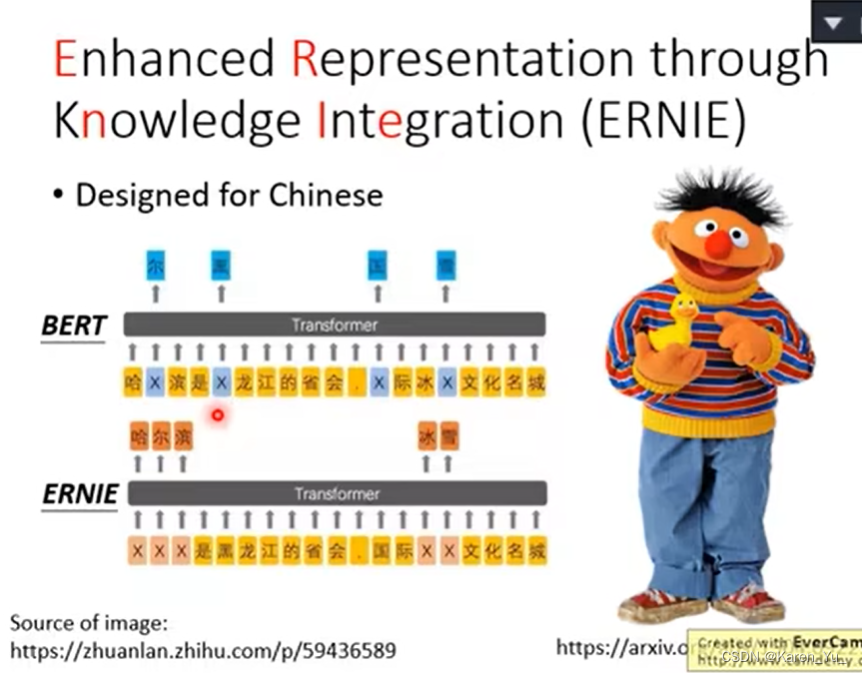
BERT Intro
继续NLP的学习,看完理论之后再看看实践,然后就可以上手去kaggle做那个入门的project了orz。 参考: 1810.04805.pdf (arxiv.org) BERT 论文逐段精读【论文精读】_哔哩哔哩_bilibili (强推!)2023李宏毅讲解大模型鼻祖BERT,一小时…...

如何快速将Figma设计文件转换为结构化JSON数据:完整指南
如何快速将Figma设计文件转换为结构化JSON数据:完整指南 【免费下载链接】figma-to-json 💾 Read/Write Figma Files as JSON 项目地址: https://gitcode.com/gh_mirrors/fi/figma-to-json 在当今的设计开发工作流中,Figma已成为UI/UX…...

Intel RealSense D435深度数据采集全流程:从Viewer截图到.csv/.raw文件深度解析
Intel RealSense D435深度数据采集全流程:从Viewer截图到.csv/.raw文件深度解析 深度视觉技术正在重塑工业检测、机器人导航和三维重建等领域的工作流程。作为Intel RealSense系列中的明星产品,D435深度相机以其出色的性价比和易用性,成为开发…...

用Python自动化Photoshop:解锁高效图像处理的终极指南
用Python自动化Photoshop:解锁高效图像处理的终极指南 【免费下载链接】photoshop-python-api Python API for Photoshop. 项目地址: https://gitcode.com/gh_mirrors/ph/photoshop-python-api Photoshop Python API 是一款强大的工具包,让开发者…...

华为MateBook D 2018 BIOS隐藏选项实战:手动解锁TPM2.0迎战Win11
1. 为什么需要手动解锁TPM2.0 去年Windows 11正式发布时,很多华为MateBook D 2018用户都遇到了一个尴尬问题:明明硬件配置完全达标,却因为BIOS里找不到TPM2.0开关而无法升级。我当时也卡在这个环节整整两天,直到发现原来TPM功能被…...

FanControl深度解析:完全掌控Windows风扇转速的专业级工具
FanControl深度解析:完全掌控Windows风扇转速的专业级工具 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...

AI时代就业真相:小白程序员如何抓住大模型机遇,收藏这份必看指南!
智联招聘数据显示,AI短期内替代部分岗位,但新增岗位同样显著。编辑、翻译等白领岗位需求缩减,而AI工程师、数据标注师等需求激增。初级职位衰减,中级与高级职位增长,企业招聘更看重软技能与AI应用能力。建议关注新质生…...

AI技能gate-of-oss:智能海巡GitHub,高效开源项目选型
1. 项目概述:一个帮你“海巡”GitHub的AI技能在软件开发这个行当里,我敢说,几乎每个开发者都经历过这样的时刻:为了解决一个具体问题,或者想给项目引入一个新功能,一头扎进GitHub的汪洋大海,试图…...

Cursor免费版高效使用指南:配置优化与本地工具链整合
1. 项目概述与核心价值最近在开发者圈子里,关于AI编程工具的讨论热度一直居高不下。Cursor作为一款深度集成AI能力的代码编辑器,凭借其强大的代码生成、理解和重构功能,迅速成为了许多程序员提升效率的“新宠”。然而,其Pro版本需…...

Apple Watch深度体验:从传感器融合到物联网节点的技术实践
1. 从怀疑到依赖:一个技术编辑的Apple Watch真实体验说实话,一开始我压根没打算写这篇关于Apple Watch的东西。作为一名在技术媒体圈混了十多年的老编辑,我太清楚这里面的“坑”了——只要你写点苹果产品的好话,就容易被贴上“果粉…...

AI应用配置管理实战:从环境变量到多租户架构的工程化解决方案
1. 项目概述:AI配置管理的“瑞士军刀”最近在折腾AI应用开发,特别是那些需要调用不同模型、处理复杂提示词的项目时,配置管理简直是个噩梦。每个模型API的密钥格式不一样,提示词模板散落在各个脚本里,环境变量多得记不…...