DataFrame详解
清洗相关的API
清洗相关的API:
1.去重API: dropDupilcates
2.删除缺失值API: dropna
3.替换缺失值API: fillna
去重API: dropDupilcates
dropDuplicates(subset):删除重复数据
1.用来删除重复数据,如果没有指定参数subset,比对行中所有字段内容,如果全部相同,则认为是重复数据,会被删除
2.如果有指定参数subset,只比对subset中指定的字段范围
删除缺失值API: dropna
dropna(thresh,subset):删除缺失值数据.
1.如果不传递参数,只要任意一个字段值为null,就会删除整行数据
2.如果只指定了subset,那么空值的检查,就只会限定在subset指定范围内
3.如果只指定了thresh,那么空值检查的这些字段中,至少需要有thresh(>=thresh)个字段的值不为空,才不会被删除
替换缺失值API: fillna
fillna(value,subset):替换缺失值数据
1.value:必须要传递参数,指定填充缺失值的数据
2.subset:限定缺失值的替换范围
注意:
value如果不是字典,那么就只会替换字段类型匹配的空值
最常用的是value传递字典形式
# 直接基于DataFrame来处理
# 导包
import os
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, IntegerType, StringType, StructField
import pyspark.sql.functions as F# 绑定指定的python解释器
"""
基于RDD转换DataFrame的方式需求分析:1- 将每行内容切分得到单个的单词2- 组织DataFrame的数据结构2.1- 有两列。一列是单词,一列是次数
"""os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':print('API的清洗')# 创建Sparksession对象spark = SparkSession \.builder \.appName('api_etl_demo') \.master('local[*]') \.getOrCreate()# 数据输入init_df = spark.read.csv(path='file:///export/data/pyspark_projects/02_spark_sql/data/clear_data.csv',sep=',',header=True,inferSchema=True,encoding='utf8')# 查看数据init_df.show()init_df.printSchema()# 数据处理print('=' * 50)# 去重API: dropDuplicatesinit_df.dropDuplicates().show()# 指定字段去重init_df.dropDuplicates(subset=['id', 'name']).show()print('=' * 50)# 删除缺失值的API: dropnainit_df.dropna().show()# 指定字段删除init_df.dropna(subset='name').show()init_df.dropna(subset=['name', 'age', 'address']).show()init_df.dropna(thresh=1, subset=['name', 'age', 'address']).show()init_df.dropna(thresh=2, subset=['name', 'age', 'address']).show()print('=' * 50)# 替换缺失值APIinit_df.fillna(9999).show()# value传递字典形式init_df.fillna(value={'id': 9999, 'name': '刘亦菲', 'address': '北京'}).show()# 释放资源spark.stop()
Spark SQL的Shuffle分区设置
Spark SQL底层本质上还是Spark的RDD程序,认为 Spark SQL组件就是一款翻译软件,用于将SQL/DSL翻译为Spark RDD程序, 执行运行
Spark SQL中同样也是存在shuffle的分区的,在执行shuffle分区后, shuffle分区数量默认为 200个,但是实际中, 一般都是需要调整这个分区的, 因为当数据量比较少的数据, 200个分区相对来说比较大一些, 但是当数据量比较大的时候, 200个分区显得比较小
调整shuffle分区的数量:
方案一(不推荐):直接修改spark的配置文件spark-defaults.conf,全局设置,默认值为200
修改设置 spark.sql.shuffle.partitions 20
方案二(常用,推荐使用):在客户端通过指令submit命令提交的时候动态设置shuffle的分区数量,部署上线的时候,基于spark-submit提交运行的时候
"./spark-submit --conf "spark.sql.shuffle.partitions=20"
方案三(比较常用):在代码中设置,主要在测试环境中使用,一般部署上线的时候,会删除,优先级也是最高的,一般的使用场景是数据量未来不会发生太大的波动
sparksession.conf.set("spark.sql.shuffle.partitions",20)
# 直接基于DataFrame来处理
# 导包
import os
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, IntegerType, StringType, StructField
import pyspark.sql.functions as F# 绑定指定的python解释器
"""
1.2 直接基于DataFrame来处理需求分析:1- 将每行内容切分得到单个的单词2- 组织DataFrame的数据结构2.1- 有两列。一列是单词,一列是次数
"""os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':print('直接基于DataFrame来处理')spark = SparkSession \.builder \.config("spark.sql.shuffle.partitions", 1) \.appName('dataFrame_world_count_demo') \.master('local[*]') \.getOrCreate()# 数据输入# text方式读取hdfs上的文件init_df = spark.read.text(paths='hdfs://node1:8020/source/word.txt')# # 查看数据# init_df.show()# # 打印dataframe表结构信息# init_df.printSchema()# 创建临时视图init_df.createTempView('words')# 数据处理"""sparksql方式处理数据-子查询1.先切分每一行的数据2.使用炸裂函数获得一个word单词列3.使用子查询方式聚合统计每个单词出现的次数"""spark.sql("""select word,count(*) as cnt from (select explode(split(value,' ')) as word from words)group by word order by cnt desc""").show()"""sparksql方式处理数据-侧视图1.先切分每一行的数据2.使用炸裂函数获得一个word单词列3.使用侧视图方式聚合统计每个单词出现的次数炸裂函数配合侧视图使用如下:格式:select 原表别名.字段名,侧视图名.字段名 from 原表 原表别名 lateral view explode(要炸开的字段)侧视图名 as 字段名"""spark.sql("""select word,count(*) as cntfrom words w lateral view explode(split(value,' ')) t as wordgroup by word order by cnt desc""").show()print('=' * 50)"""DSL方式处理数据-方式一1.先切分每一行的数据2.使用炸裂函数获得一个word单词列3.调用API聚合统计单词个数再排序"""init_df.select(F.explode(F.split('value', ' ')).alias('word')).groupBy('word').count().orderBy('count', ascending=False).show()"""DSL方式处理数据-方式二1.先切分每一行的数据2.使用炸裂函数获得一个word单词列3.调用API聚合统计单词个数再排序4.agg():推荐使用,更加通用。执行聚合操作。如果有多个聚合,聚合之间使用逗号分隔即可"""init_df.select(F.explode(F.split('value', ' ')).alias('word')).groupBy('word').agg(F.count('word').alias('cnt'),F.max('word').alias('max_word'),F.min('word').alias('min_word'),).orderBy('cnt', ascending=False).show()"""DSL方式处理数据-方式三withColumnRenamed(参数1,参数2):给字段重命名操作。参数1是旧字段名,参数2是新字段名withColumn(参数1,参数2):用来产生新列。参数1是新列的名称;参数2是新列数据的来源"""init_df.withColumn('word',F.explode(F.split('value', ' '))).groupBy('word').agg(F.count('word').alias('cnt'),F.max('word').alias('max_word'),F.min('word').alias('min_word')).orderBy('cnt', ascending=False).show()# 数据输出# 是否资源spark.stop()
数据写出操作
统一的输出语法:
对应的简写API格式如下,以CSV为例:
init_df.write.csv(
path='存储路径',
mode='模式',
header=True,
sep='\t',
encoding='UTF-8'
)
输出到本地文件
常用参数说明:
1- path:指定结果数据输出路径。支持本地文件系统和HDFS文件系统
2- mode:当输出目录中文件已经存在的时候处理办法
2.1- append:追加。如果文件已经存在,那么继续在该目录下产生新的文件
2.2- overwrite:覆盖。如果文件已经存在,那么就先将已有的文件清除,再写入进去
2.3- ignore:忽略。如果文件已经存在,那么不执行任何操作
2.4- error:报错。如果文件已经存在,那么直接报错。会报错AnalysisException: path
file:xxx already exists.
3- sep:字段间的分隔符
4- header:数据输出的时候,是否要将字段名称输出到文件的第一行。推荐设置为True
5- encoding:文件输出的编码方式
# 直接基于DataFrame来处理
# 导包
import os
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, IntegerType, StringType, StructField
import pyspark.sql.functions as F# 绑定指定的python解释器
"""
基于RDD转换DataFrame的方式需求分析:1- 将每行内容切分得到单个的单词2- 组织DataFrame的数据结构2.1- 有两列。一列是单词,一列是次数
"""os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':print('数据输出本地文件')# 创建Sparksession对象spark = SparkSession \.builder \.appName('api_etl_demo') \.master('local[*]') \.getOrCreate()# 数据输入init_df = spark.read.csv(path='file:///export/data/pyspark_projects/02_spark_sql/data/clear_data.csv',sep=',',header=True,inferSchema=True,encoding='utf8')# 数据处理result = init_df.where('age>20')# 数据查看result.show()result.printSchema()# 数据输出# 以csv格式输出,简写APIresult.write.csv(path='file:///export/data/pyspark_projects/02_spark_sql/data/output',mode='append',header=True,sep=',',encoding='utf8')# 以json方式输出到本地文件系统,复杂APIresult.write \.format('json') \.option('encoding', 'utf8') \.mode('overwrite') \.save('file:///export/data/pyspark_projects/02_spark_sql/data/output_json')
数据输出到数据库
数据库的驱动包, 一般都是一些Jar包
如何放置【mysql-connector-java-5.1.41.jar】驱动包呢?
1- 放置位置一: 当spark-submit提交的运行环境为Spark集群环境的时候,以及运行模式为local, 默认从 spark的jars目录下加载相关的jar包,
目录位置: /export/server/spark/jars
2- 放置位置二: 当我们使用pycharm运行代码的时候, 基于python的环境来运行的, 需要在python的环境中可以加载到此jar包
目录位置:
/root/anaconda3/lib/python3.8/site-packages/pyspark/jars/
3- 放置位置三: 当我们提交选择的on yarn模式 需要保证此jar包在HDFS上对应目录下
hdfs的spark的jars目录下: hdfs://node1:8020/spark/jars
请注意: 以上三个位置, 主要是用于放置一些 spark可能会经常使用的jar包, 对于一些不经常使用的jar包, 在后续spark-submit 提交运行的时候, 会有专门的处理方案: spark-submit --jars ....
将中文输出到了数据表中乱码
解决办法:
1- 数据库连接要加上:useUnicode=true&characterEncoding=utf-8
2- 创建数据库的时候需要指定编码character set utf8
# 直接基于DataFrame来处理
# 导包
import os
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, IntegerType, StringType, StructField
import pyspark.sql.functions as F# 绑定指定的python解释器
"""
基于RDD转换DataFrame的方式需求分析:1- 将每行内容切分得到单个的单词2- 组织DataFrame的数据结构2.1- 有两列。一列是单词,一列是次数
"""os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':print('API的清洗')# 创建Sparksession对象spark = SparkSession \.builder \.appName('api_etl_demo') \.master('local[*]') \.getOrCreate()# 数据输入init_df = spark.read.csv(path='file:///export/data/pyspark_projects/02_spark_sql/data/clear_data.csv',sep=',',header=True,inferSchema=True,encoding='utf8')# 数据处理result = init_df.where('age>20')# 数据查看result.show()result.printSchema()# 数据输出# 以csv格式输出,简写APIresult.write.jdbc(url='jdbc:mysql://node1:3306/day06?useUnicode=true&characterEncoding=utf-8',table='student',mode='append',properties={'user': 'root', 'password': '123456'})相关文章:

DataFrame详解
清洗相关的API 清洗相关的API: 1.去重API: dropDupilcates 2.删除缺失值API: dropna 3.替换缺失值API: fillna 去重API: dropDupilcates dropDuplicates(subset):删除重复数据 1.用来删除重复数据,如果没有指定参数subset,比对行中所有字段内容,如果全部相同,则认为是重复数据,…...
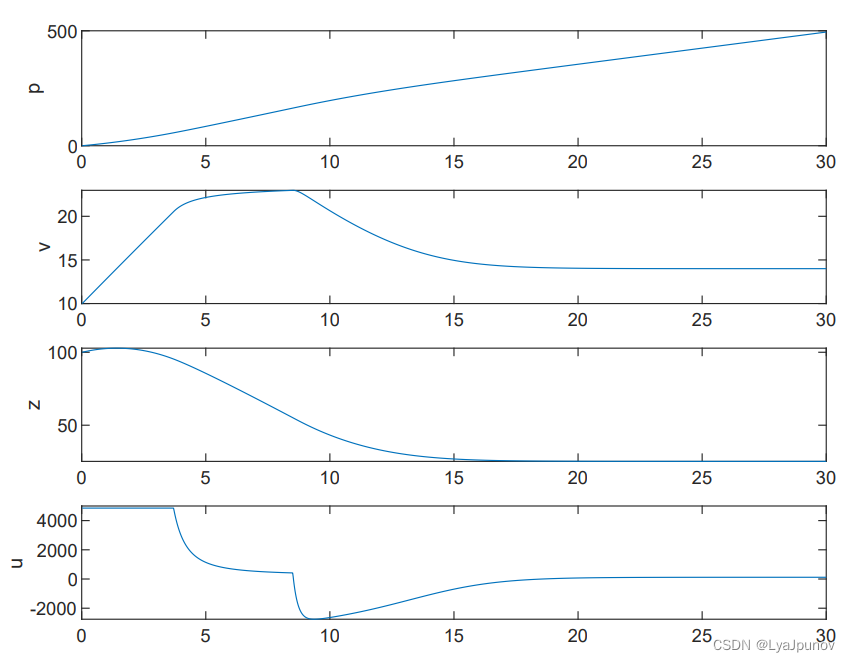
控制障碍函数(Control Barrier Function,CBF) 三、代码
三、代码实现 3.1、模型 这是一个QP问题,所以我们直接建模 这其实还是之前的那张图,我们把这个大的框架带入到之前的那个小车追击的问题中去,得到以下的一些具体的约束条件 CLF约束 L g V ( x ) u − δ ≤ − L f V ( x ) − λ V ( x ) …...

哈希表-散列表数据结构
1、什么是哈希表? 哈希表也叫散列表,哈希表是根据关键码值(key value)来直接访问的一种数据结构,也就是将关键码值(key value)通过一种映射关系映射到表中的一个位置来加快查找的速度,这种映射关系称之为哈希函数或者散列函数&…...

C# 强制类型转换和as区别和不同使用场景
文章目录 1.强制类型转换2. as 运算符3.实例总结: 在C#中,as 和 强制类型转换(例如 (T)value)的主要区别在于它们处理类型转换不成功时的行为和适用场景: 1.强制类型转换 使用语法:Type variable (Type)…...

什么是 DDoS 攻击
布式拒绝服务 (DDoS) 攻击是一种恶意尝试,通过大量互联网流量淹没目标或其周围基础设施,从而破坏目标服务器、服务或网络的正常流量。 DDoS 攻击通过利用多个受感染的计算机系统作为攻击流量源来实现有效性。被利用的机器可以包括计算机和其他网络资源。 从高层来看,DDoS 攻…...

c++隐式类型转换与explicit
我们知道,一个float与int做运算时,系统会首先个int类型转换为float类型之后再进行运算,这种隐式类型转换也会发生在类中 看以下例子,定义一个类 class myTime { public:int Hour;myTime() {};myTime(int h) :Hour(h) {}; }; 在…...
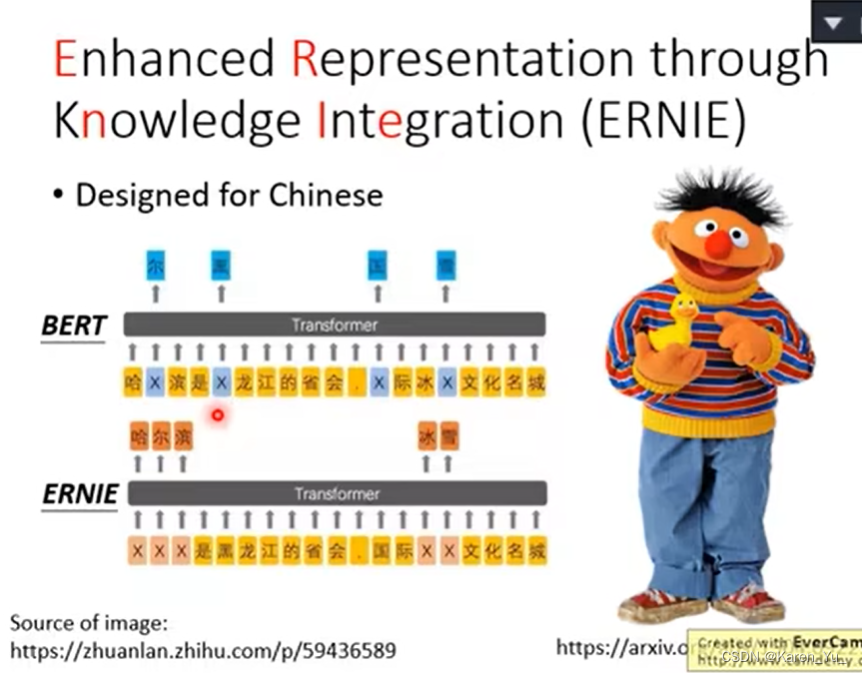
BERT Intro
继续NLP的学习,看完理论之后再看看实践,然后就可以上手去kaggle做那个入门的project了orz。 参考: 1810.04805.pdf (arxiv.org) BERT 论文逐段精读【论文精读】_哔哩哔哩_bilibili (强推!)2023李宏毅讲解大模型鼻祖BERT,一小时…...
“To-Do Master“ GPTs:重塑任务管理的趣味与效率
有 GPTs 访问权限的可以点击链接进行体验:https://chat.openai.com/g/g-IhGsoyIkP-to-do-master 部署私人的 To-Do Master 教程:https://github.com/Reborn14/To-Do-Master/tree/main 引言 在忙碌的日常生活中,有效地管理日常任务对于提高生…...

npm安装vue,添加淘宝镜像
如果是第一次使用命令栏可能会遇到权限问题。 解决vscode无法运行npm和node.js命令的问题-CSDN博客 安装 在vscode上面的导航栏选择terminal打开新的命令栏 另外可能会遇到网络或者其他的问题,可以添加淘宝镜像 npm install -g cnpm --registryhttps://registry.…...

LeetCode 2707. 字符串中的额外字符
一、题目 1、题目描述 给你一个下标从 0 开始的字符串 s 和一个单词字典 dictionary 。你需要将 s 分割成若干个 互不重叠 的子字符串,每个子字符串都在 dictionary 中出现过。s 中可能会有一些 额外的字符 不在任何子字符串中。 请你采取最优策略分割 s ÿ…...

Js进阶31-DOM 操作专题
1. JavaScript 的组成部分: ECMAScript:简称 ES,它是欧洲计算机协会,大概每年的六月中旬定制语法规范。DOM:全称 Document Object Model,即为文档对象类型。BOM:全称 Browser Object Model&…...

Hive之set参数大全-4
F 指定在使用 FETCH 命令提取查询结果时的序列化/反序列化器 hive.fetch.output.serde 是 Hive 的一个配置参数,用于指定在使用 FETCH 命令提取查询结果时的序列化/反序列化器。 以下是一个示例: -- 设置 hive.fetch.output.serde 为 org.apache.had…...
竞赛保研 基于深度学习的人脸识别系统
前言 🔥 优质竞赛项目系列,今天要分享的是 基于深度学习的人脸识别系统 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🧿 更多资料, 项目分享: https://gitee.com/dancheng-senior/…...

9.建造者模式
文章目录 一、介绍二、代码三、实际使用总结 一、介绍 建造者模式旨在将一个复杂对象的构建过程和其表示分离,以便同样的构建过程可以创建不同的表示。这种模式适用于构建对象的算法(构建过程)应该独立于对象的组成部分以及它们的装配方式的…...
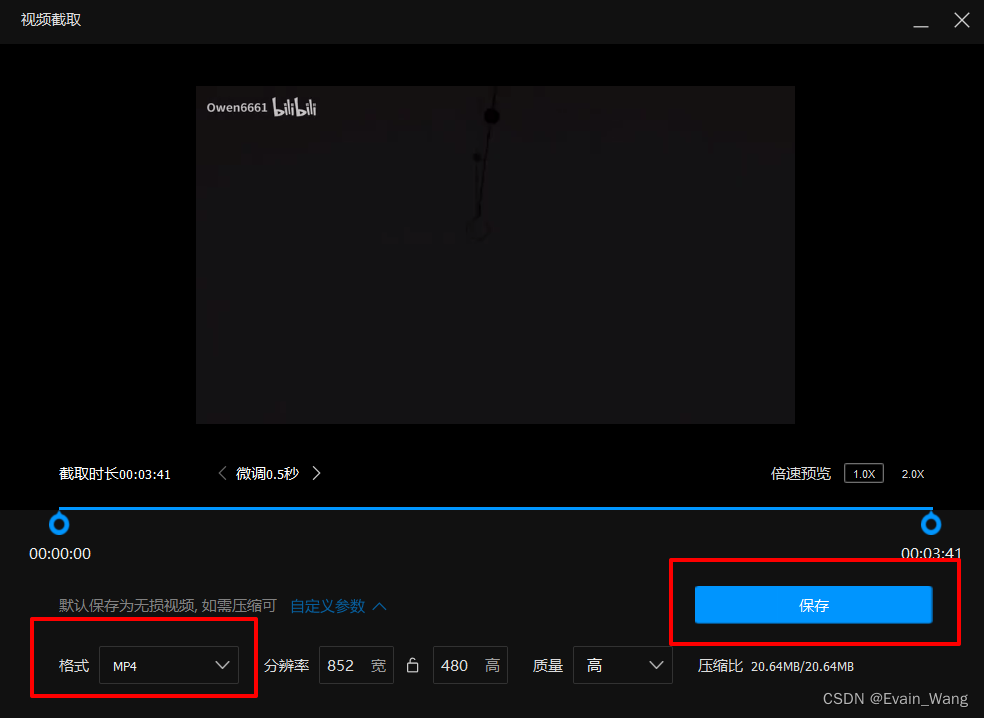
简单的MOV转MP4方法
1.下载腾讯的QQ影音播放器, 此播放器为绿色视频播放器, 除了播放下载好的视频外没有臃肿无用功能 官网 QQ影音 百度网盘链接:https://pan.baidu.com/s/1G0kSC-844FtRfqGnIoMALA 提取码:dh4w 2.用QQ影音打开MOV文件 3.右下角打开影音工具箱 , 选择截取…...
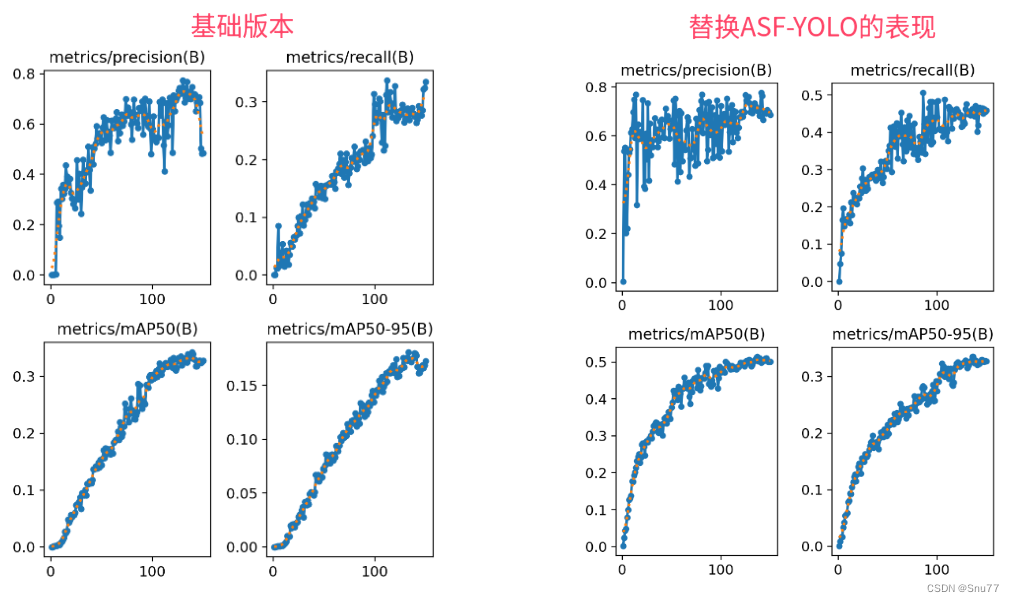
YOLOv8改进 | Neck篇 | 利用ASF-YOLO改进特征融合层(适用于分割和目标检测)
一、本文介绍 本文给大家带来的改进机制是ASF-YOLO(发布于2023.12月份的最新机制),其是特别设计用于细胞实例分割。这个模型通过结合空间和尺度特征,提高了在处理细胞图像时的准确性和速度。在实验中,ASF-YOLO在2018年数据科学竞赛数据集上取得了卓越的分割准确性和速度,…...

基于模块自定义扩展字段的后端逻辑实现(一)
目录 一:背景介绍 二:实现过程 三:字段标准化 四:数据存储 五:数据扩展 六:表的设计 一:背景介绍 最近要做一个系统,里面涉及一个模块是使用拖拉拽的形式配置模块使用的字段表…...
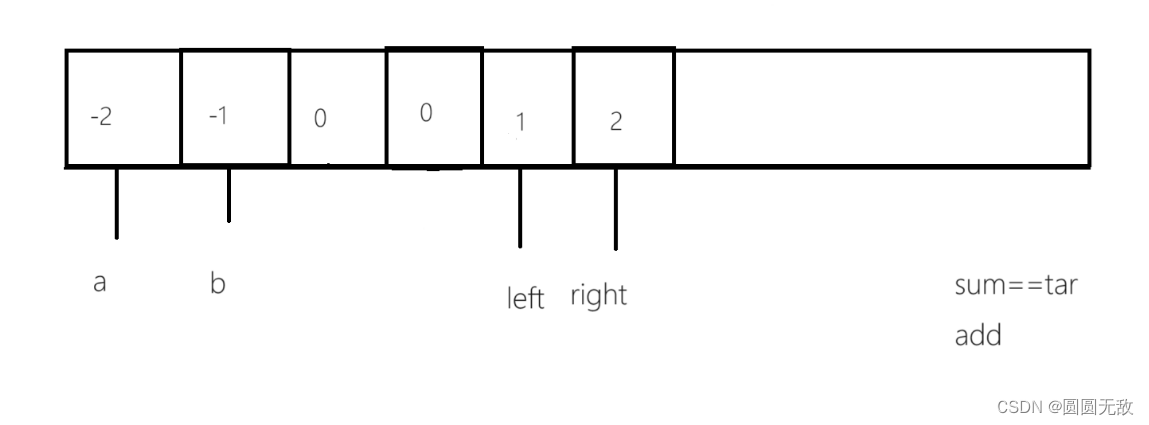
力扣:18.四数之和
一、做题链接:18. 四数之和 - 力扣(LeetCode) 二、题目分析 1.做这一道题之前本博主建议先看上一篇《三数之和》 2.题目分析 给你一个由 n 个整数组成的数组 nums ,和一个目标值 target 。请你找出并返回满足下述全部条件且不重…...

.netcore 6 ioc注入的三种方式
1、定义接口 public interface MyInterceptorInterface 2、实现接口 public class MyInterceptorImpl : MyInterceptorInterface 在构造中增加以下代码,便于观察 static ConcurrentDictionary<string, string> keyValues new ConcurrentDictionary<s…...
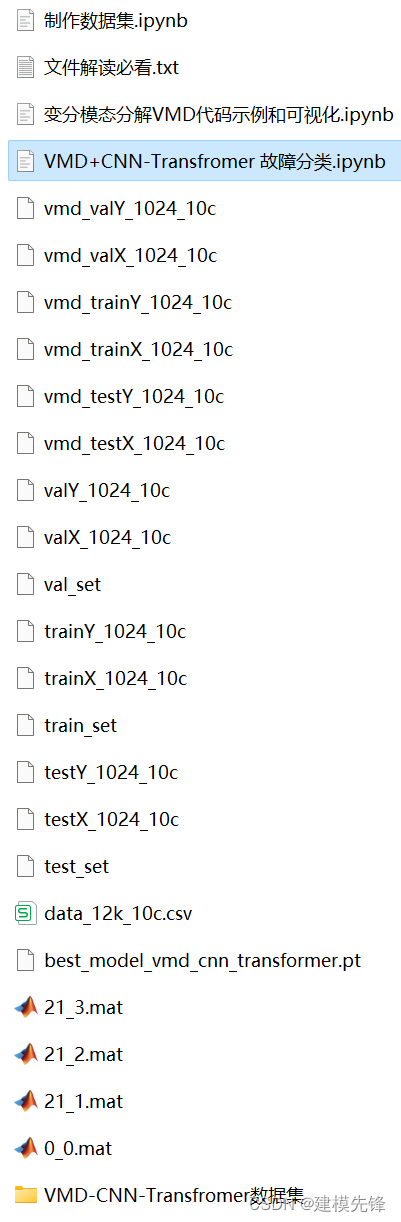
Python轴承故障诊断 (十)基于VMD+CNN-Transfromer的故障分类
目录 1 变分模态分解VMD的Python示例 2 轴承故障数据的预处理 2.1 导入数据 2.2 故障VMD分解可视化 3 基于VMDCNN-Transformer的轴承故障诊断分类 3.1 定义VMD-CNN-Transformer分类网络模型 3.2 设置参数,训练模型 3.3 模型评估 代码、数据如下:…...

Win10下mitie安装失败:subprocess.CalledProcessError的深度排查与实战修复
1. 问题现象与初步分析 最近在Windows10系统上折腾MITIE这个自然语言处理工具包时,遇到了一个让人头疼的错误。当时按照常规流程,先下载了mitie的源码压缩包,解压后执行python setup.py install,结果命令行突然弹出一堆红色报错&a…...

从SWF中提取供应链安全控制:JPEXS Free Flash Decompiler安全研究
从SWF中提取供应链安全控制:JPEXS Free Flash Decompiler安全研究 【免费下载链接】jpexs-decompiler JPEXS Free Flash Decompiler 项目地址: https://gitcode.com/gh_mirrors/jp/jpexs-decompiler JPEXS Free Flash Decompiler是一款强大的开源工具&#x…...
)
SEO_10个提升网站排名的实用SEO技巧分享(220 )
<h1 id"seo10seo">SEO:10个提升网站排名的实用SEO技巧分享</h1> <p>在当今互联网时代,搜索引擎优化(SEO)已经成为提升网站流量和吸引潜在客户的关键手段。百度作为中国最大的搜索引擎,其优化规则对整…...

Apache Doris 存储与查询优化实战:从架构设计到性能调优的完整指南
1. Apache Doris 架构设计精要 第一次接触Apache Doris时,我被它简洁的架构设计惊艳到了。这个MPP架构的分析型数据库,用计算存储分离的设计思路,把复杂的大数据分析变得像查普通MySQL表一样简单。FE(Frontend)和BE&am…...
从起点到终点-面向对象)
AI智能应用开发(Java)从起点到终点-面向对象
自定义对象Java中自定义对象的必要性就像我们之前用的Scanner 和Random 都是java里面已经写好的对象,直接拿来用就好了,不用再自己写一大串代码来实现键盘录入和随机数的需求,但是有些需求是java中没有定义和写好的,,但…...

如何用PPTist快速创建专业演示文稿:免费在线PPT制作完全指南
如何用PPTist快速创建专业演示文稿:免费在线PPT制作完全指南 【免费下载链接】PPTist 基于 Vue3.x TypeScript 的在线演示文稿(幻灯片)应用,还原了大部分 Office PowerPoint 常用功能,实现在线PPT的编辑、演示。支持导…...

3步打造开源工具效率引擎:QtScrcpy自定义配置全指南
3步打造开源工具效率引擎:QtScrcpy自定义配置全指南 【免费下载链接】QtScrcpy Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制。它不需要任何root访问权限 项目地址: https://gitcode.com/barry-ran/QtScrcpy …...
)
Python tkinter文件对话框实战:5分钟搞定文件选择与保存功能(附完整代码)
Python tkinter文件对话框实战:5分钟搞定文件选择与保存功能(附完整代码) 在开发桌面应用程序时,文件选择功能几乎是必不可少的。无论是需要用户上传文件、保存处理结果,还是选择工作目录,一个直观的文件对…...

gemma-3-12b-it实际作品:10张不同领域测试图的图文理解准确率统计表
gemma-3-12b-it实际作品:10张不同领域测试图的图文理解准确率统计表 1. 测试背景与方法 最近我在实际使用gemma-3-12b-it模型时,对其图文理解能力产生了浓厚兴趣。这个由Google推出的多模态模型号称能够同时处理文本和图像输入,并生成准确的…...

Obsidian插件本地化全攻略:从英文界面到中文体验的完整实施路径
Obsidian插件本地化全攻略:从英文界面到中文体验的完整实施路径 【免费下载链接】obsidian-i18n 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-i18n 在全球化协作与知识管理的场景中,Obsidian插件的英文界面常成为用户高效使用的障碍。…...