竞赛保研 基于深度学习的人脸识别系统
前言
🔥 优质竞赛项目系列,今天要分享的是
基于深度学习的人脸识别系统
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
机器学习-人脸识别过程
基于传统图像处理和机器学习技术的人脸识别技术,其中的流程都是一样的。
机器学习-人脸识别系统都包括:
- 人脸检测
- 人脸对其
- 人脸特征向量化
- 人脸识别

人脸检测
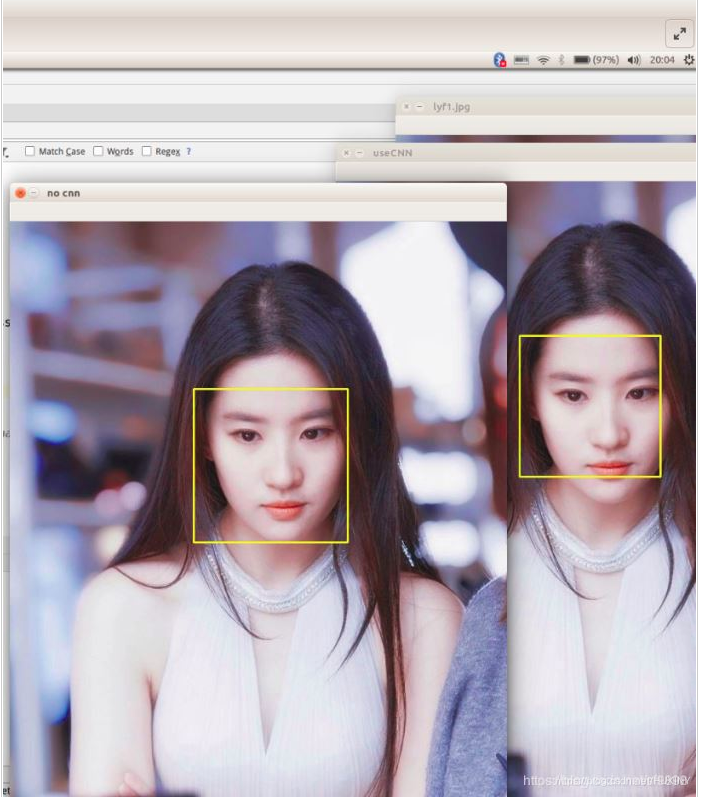
人脸检测用于确定人脸在图像中的大小和位置,即解决“人脸在哪里”的问题,把真正的人脸区域从图像中裁剪出来,便于后续的人脸特征分析和识别。下图是对一张图像的人脸检测结果:
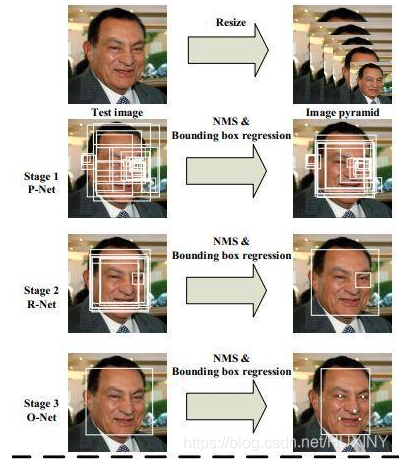
人脸对其
同一个人在不同的图像序列中可能呈现出不同的姿态和表情,这种情况是不利于人脸识别的。
所以有必要将人脸图像都变换到一个统一的角度和姿态,这就是人脸对齐。
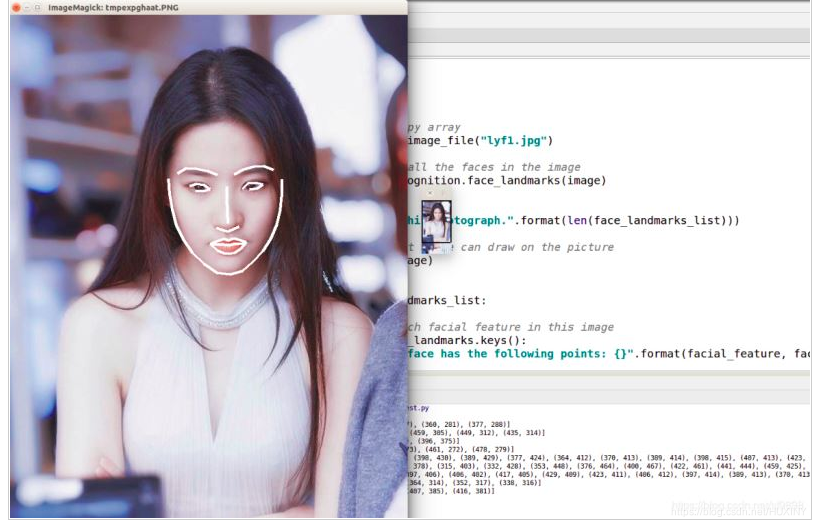
它的原理是找到人脸的若干个关键点(基准点,如眼角,鼻尖,嘴角等),然后利用这些对应的关键点通过相似变换(Similarity
Transform,旋转、缩放和平移)将人脸尽可能变换到标准人脸。
下图是一个典型的人脸图像对齐过程:
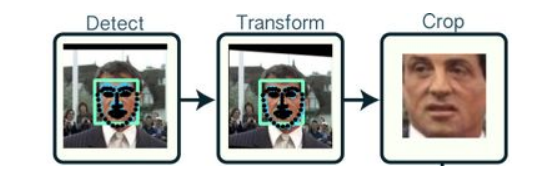
这幅图就更加直观了:
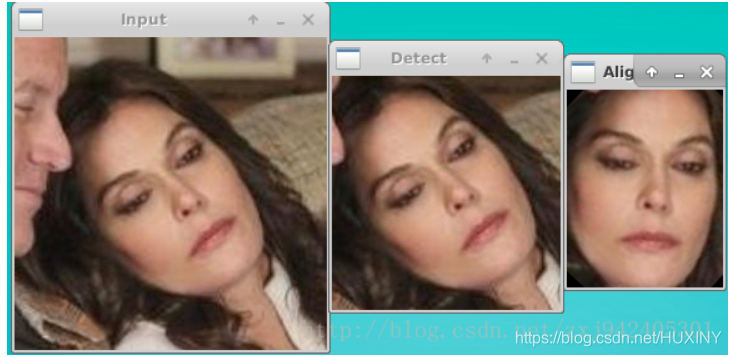
人脸特征向量化
这一步是将对齐后的人脸图像,组成一个特征向量,该特征向量用于描述这张人脸。
但由于,一幅人脸照片往往由比较多的像素构成,如果以每个像素作为1维特征,将得到一个维数非常高的特征向量, 计算将十分困难;而且这些像素之间通常具有相关性。
所以我们常常利用PCA技术对人脸描述向量进行降维处理,保留数据集中对方差贡献最大的人脸特征来达到简化数据集的目的
PCA人脸特征向量降维示例代码:
#coding:utf-8
from numpy import *
from numpy import linalg as la
import cv2
import osdef loadImageSet(add):FaceMat = mat(zeros((15,98*116)))j =0for i in os.listdir(add):if i.split('.')[1] == 'normal':try:img = cv2.imread(add+i,0)except:print 'load %s failed'%iFaceMat[j,:] = mat(img).flatten()j += 1return FaceMatdef ReconginitionVector(selecthr = 0.8):# step1: load the face image data ,get the matrix consists of all imageFaceMat = loadImageSet('D:\python/face recongnition\YALE\YALE\unpadded/').T# step2: average the FaceMatavgImg = mean(FaceMat,1)# step3: calculate the difference of avgimg and all image data(FaceMat)diffTrain = FaceMat-avgImg#step4: calculate eigenvector of covariance matrix (because covariance matrix will cause memory error)eigvals,eigVects = linalg.eig(mat(diffTrain.T*diffTrain))eigSortIndex = argsort(-eigvals)for i in xrange(shape(FaceMat)[1]):if (eigvals[eigSortIndex[:i]]/eigvals.sum()).sum() >= selecthr:eigSortIndex = eigSortIndex[:i]breakcovVects = diffTrain * eigVects[:,eigSortIndex] # covVects is the eigenvector of covariance matrix# avgImg 是均值图像,covVects是协方差矩阵的特征向量,diffTrain是偏差矩阵return avgImg,covVects,diffTraindef judgeFace(judgeImg,FaceVector,avgImg,diffTrain):diff = judgeImg.T - avgImgweiVec = FaceVector.T* diffres = 0resVal = inffor i in range(15):TrainVec = FaceVector.T*diffTrain[:,i]if (array(weiVec-TrainVec)**2).sum() < resVal:res = iresVal = (array(weiVec-TrainVec)**2).sum()return res+1if __name__ == '__main__':avgImg,FaceVector,diffTrain = ReconginitionVector(selecthr = 0.9)nameList = ['01','02','03','04','05','06','07','08','09','10','11','12','13','14','15']characteristic = ['centerlight','glasses','happy','leftlight','noglasses','rightlight','sad','sleepy','surprised','wink']for c in characteristic:count = 0for i in range(len(nameList)):# 这里的loadname就是我们要识别的未知人脸图,我们通过15张未知人脸找出的对应训练人脸进行对比来求出正确率loadname = 'D:\python/face recongnition\YALE\YALE\unpadded\subject'+nameList[i]+'.'+c+'.pgm'judgeImg = cv2.imread(loadname,0)if judgeFace(mat(judgeImg).flatten(),FaceVector,avgImg,diffTrain) == int(nameList[i]):count += 1print 'accuracy of %s is %f'%(c, float(count)/len(nameList)) # 求出正确率
人脸识别
这一步的人脸识别,其实是对上一步人脸向量进行分类,使用各种分类算法。
比如:贝叶斯分类器,决策树,SVM等机器学习方法。
从而达到识别人脸的目的。
这里分享一个svm训练的人脸识别模型:
from __future__ import print_functionfrom time import timeimport loggingimport matplotlib.pyplot as pltfrom sklearn.cross_validation import train_test_splitfrom sklearn.datasets import fetch_lfw_peoplefrom sklearn.grid_search import GridSearchCVfrom sklearn.metrics import classification_reportfrom sklearn.metrics import confusion_matrixfrom sklearn.decomposition import RandomizedPCAfrom sklearn.svm import SVCprint(__doc__)# Display progress logs on stdoutlogging.basicConfig(level=logging.INFO, format='%(asctime)s %(message)s')################################################################################ Download the data, if not already on disk and load it as numpy arrayslfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)# introspect the images arrays to find the shapes (for plotting)n_samples, h, w = lfw_people.images.shape# for machine learning we use the 2 data directly (as relative pixel# positions info is ignored by this model)X = lfw_people.datan_features = X.shape[1]# the label to predict is the id of the persony = lfw_people.targettarget_names = lfw_people.target_namesn_classes = target_names.shape[0]print("Total dataset size:")print("n_samples: %d" % n_samples)print("n_features: %d" % n_features)print("n_classes: %d" % n_classes)################################################################################ Split into a training set and a test set using a stratified k fold# split into a training and testing setX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)################################################################################ Compute a PCA (eigenfaces) on the face dataset (treated as unlabeled# dataset): unsupervised feature extraction / dimensionality reductionn_components = 80print("Extracting the top %d eigenfaces from %d faces"% (n_components, X_train.shape[0]))t0 = time()pca = RandomizedPCA(n_components=n_components, whiten=True).fit(X_train)print("done in %0.3fs" % (time() - t0))eigenfaces = pca.components_.reshape((n_components, h, w))print("Projecting the input data on the eigenfaces orthonormal basis")t0 = time()X_train_pca = pca.transform(X_train)X_test_pca = pca.transform(X_test)print("done in %0.3fs" % (time() - t0))################################################################################ Train a SVM classification modelprint("Fitting the classifier to the training set")t0 = time()param_grid = {'C': [1,10, 100, 500, 1e3, 5e3, 1e4, 5e4, 1e5],'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1], }clf = GridSearchCV(SVC(kernel='rbf', class_weight='balanced'), param_grid)clf = clf.fit(X_train_pca, y_train)print("done in %0.3fs" % (time() - t0))print("Best estimator found by grid search:")print(clf.best_estimator_)print(clf.best_estimator_.n_support_)################################################################################ Quantitative evaluation of the model quality on the test setprint("Predicting people's names on the test set")t0 = time()y_pred = clf.predict(X_test_pca)print("done in %0.3fs" % (time() - t0))print(classification_report(y_test, y_pred, target_names=target_names))print(confusion_matrix(y_test, y_pred, labels=range(n_classes)))################################################################################ Qualitative evaluation of the predictions using matplotlibdef plot_gallery(images, titles, h, w, n_row=3, n_col=4):"""Helper function to plot a gallery of portraits"""plt.figure(figsize=(1.8 * n_col, 2.4 * n_row))plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)for i in range(n_row * n_col):plt.subplot(n_row, n_col, i + 1)# Show the feature faceplt.imshow(images[i].reshape((h, w)), cmap=plt.cm.gray)plt.title(titles[i], size=12)plt.xticks(())plt.yticks(())# plot the result of the prediction on a portion of the test setdef title(y_pred, y_test, target_names, i):pred_name = target_names[y_pred[i]].rsplit(' ', 1)[-1]true_name = target_names[y_test[i]].rsplit(' ', 1)[-1]return 'predicted: %s\ntrue: %s' % (pred_name, true_name)prediction_titles = [title(y_pred, y_test, target_names, i)for i in range(y_pred.shape[0])]plot_gallery(X_test, prediction_titles, h, w)# plot the gallery of the most significative eigenfaceseigenface_titles = ["eigenface %d" % i for i in range(eigenfaces.shape[0])]plot_gallery(eigenfaces, eigenface_titles, h, w)plt.show()深度学习-人脸识别过程
不同于机器学习模型的人脸识别,深度学习将人脸特征向量化,以及人脸向量分类结合到了一起,通过神经网络算法一步到位。
深度学习-人脸识别系统都包括:
- 人脸检测
- 人脸对其
- 人脸识别
人脸检测
深度学习在图像分类中的巨大成功后很快被用于人脸检测的问题,起初解决该问题的思路大多是基于CNN网络的尺度不变性,对图片进行不同尺度的缩放,然后进行推理并直接对类别和位置信息进行预测。另外,由于对feature
map中的每一个点直接进行位置回归,得到的人脸框精度比较低,因此有人提出了基于多阶段分类器由粗到细的检测策略检测人脸,例如主要方法有Cascade CNN、
DenseBox和MTCNN等等。
MTCNN是一个多任务的方法,第一次将人脸区域检测和人脸关键点检测放在了一起,与Cascade
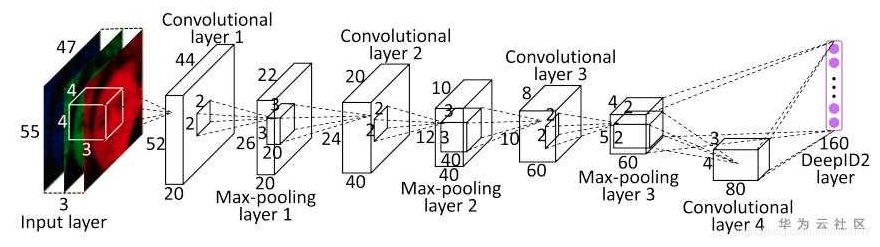
CNN一样也是基于cascade的框架,但是整体思路更加的巧妙合理,MTCNN总体来说分为三个部分:PNet、RNet和ONet,网络结构如下图所示。
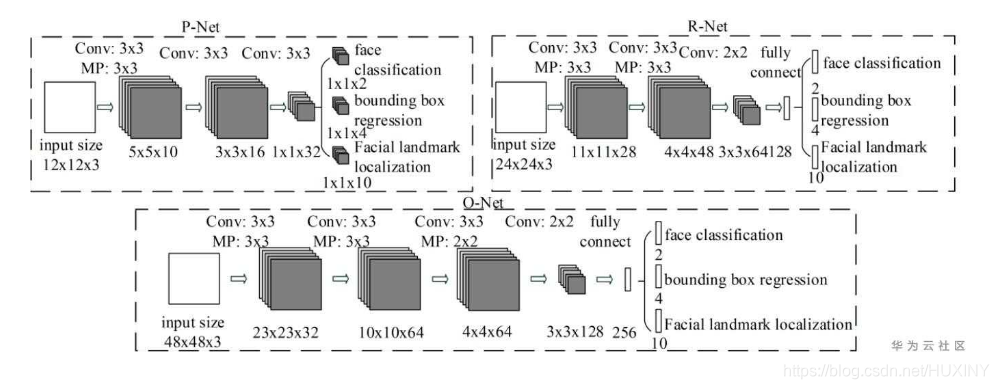
人脸识别
人脸识别问题本质是一个分类问题,即每一个人作为一类进行分类检测,但实际应用过程中会出现很多问题。第一,人脸类别很多,如果要识别一个城镇的所有人,那么分类类别就将近十万以上的类别,另外每一个人之间可获得的标注样本很少,会出现很多长尾数据。根据上述问题,要对传统的CNN分类网络进行修改。
我们知道深度卷积网络虽然作为一种黑盒模型,但是能够通过数据训练的方式去表征图片或者物体的特征。因此人脸识别算法可以通过卷积网络提取出大量的人脸特征向量,然后根据相似度判断与底库比较完成人脸的识别过程,因此算法网络能不能对不同的人脸生成不同的特征,对同一人脸生成相似的特征,将是这类embedding任务的重点,也就是怎么样能够最大化类间距离以及最小化类内距离。
Metric Larning
深度学习中最先应用metric
learning思想之一的便是DeepID2了。其中DeepID2最主要的改进是同一个网络同时训练verification和classification(有两个监督信号)。其中在verification
loss的特征层中引入了contrastive loss。
Contrastive
loss不仅考虑了相同类别的距离最小化,也同时考虑了不同类别的距离最大化,通过充分运用训练样本的label信息提升人脸识别的准确性。因此,该loss函数本质上使得同一个人的照片在特征空间距离足够近,不同人在特征空间里相距足够远直到超过某个阈值。(听起来和triplet
loss有点像)。
最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
竞赛保研 基于深度学习的人脸识别系统
前言 🔥 优质竞赛项目系列,今天要分享的是 基于深度学习的人脸识别系统 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🧿 更多资料, 项目分享: https://gitee.com/dancheng-senior/…...

9.建造者模式
文章目录 一、介绍二、代码三、实际使用总结 一、介绍 建造者模式旨在将一个复杂对象的构建过程和其表示分离,以便同样的构建过程可以创建不同的表示。这种模式适用于构建对象的算法(构建过程)应该独立于对象的组成部分以及它们的装配方式的…...
简单的MOV转MP4方法
1.下载腾讯的QQ影音播放器, 此播放器为绿色视频播放器, 除了播放下载好的视频外没有臃肿无用功能 官网 QQ影音 百度网盘链接:https://pan.baidu.com/s/1G0kSC-844FtRfqGnIoMALA 提取码:dh4w 2.用QQ影音打开MOV文件 3.右下角打开影音工具箱 , 选择截取…...
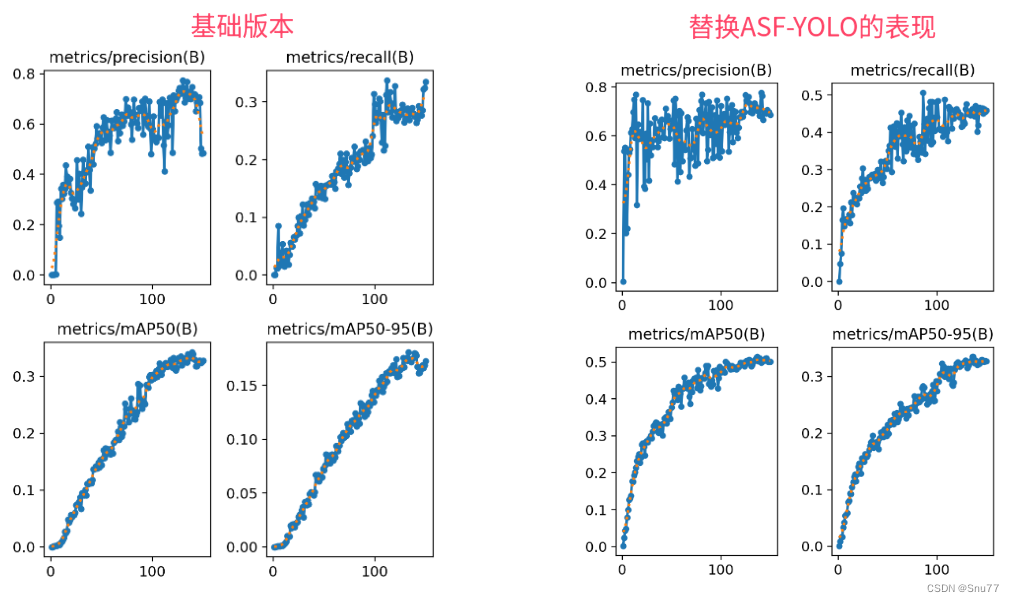
YOLOv8改进 | Neck篇 | 利用ASF-YOLO改进特征融合层(适用于分割和目标检测)
一、本文介绍 本文给大家带来的改进机制是ASF-YOLO(发布于2023.12月份的最新机制),其是特别设计用于细胞实例分割。这个模型通过结合空间和尺度特征,提高了在处理细胞图像时的准确性和速度。在实验中,ASF-YOLO在2018年数据科学竞赛数据集上取得了卓越的分割准确性和速度,…...

基于模块自定义扩展字段的后端逻辑实现(一)
目录 一:背景介绍 二:实现过程 三:字段标准化 四:数据存储 五:数据扩展 六:表的设计 一:背景介绍 最近要做一个系统,里面涉及一个模块是使用拖拉拽的形式配置模块使用的字段表…...
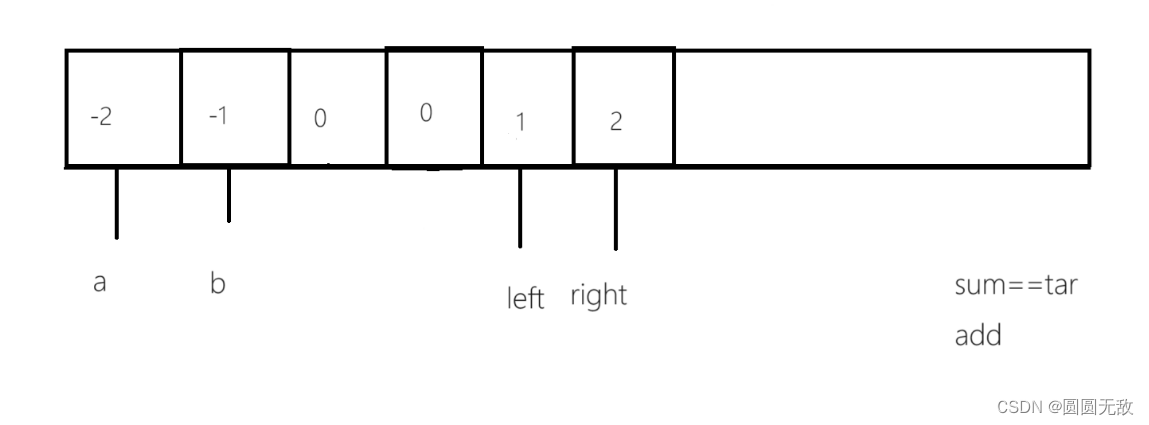
力扣:18.四数之和
一、做题链接:18. 四数之和 - 力扣(LeetCode) 二、题目分析 1.做这一道题之前本博主建议先看上一篇《三数之和》 2.题目分析 给你一个由 n 个整数组成的数组 nums ,和一个目标值 target 。请你找出并返回满足下述全部条件且不重…...

.netcore 6 ioc注入的三种方式
1、定义接口 public interface MyInterceptorInterface 2、实现接口 public class MyInterceptorImpl : MyInterceptorInterface 在构造中增加以下代码,便于观察 static ConcurrentDictionary<string, string> keyValues new ConcurrentDictionary<s…...
Python轴承故障诊断 (十)基于VMD+CNN-Transfromer的故障分类
目录 1 变分模态分解VMD的Python示例 2 轴承故障数据的预处理 2.1 导入数据 2.2 故障VMD分解可视化 3 基于VMDCNN-Transformer的轴承故障诊断分类 3.1 定义VMD-CNN-Transformer分类网络模型 3.2 设置参数,训练模型 3.3 模型评估 代码、数据如下:…...
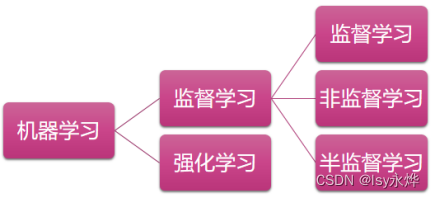
【复习】人工智能 第7章 专家系统与机器学习
专家系统就是让机器人当某个领域的专家,但这章专家系统不咋考,主要靠书上没有的机器学习。 一、专家系统的基本组成 二、专家系统与传统程序的比较 (1)编程思想: 传统程序 数据结构 算法 专家系统 知识 推理 &…...
使用 Apache PDFBox 操作PDF文件
简介 Apache PDFBox库是一个开源的Java工具,专门用于处理PDF文档。它允许用户创建全新的PDF文件,编辑现有的PDF文档,以及从PDF文件中提取内容。此外,Apache PDFBox还提供了一些命令行实用工具。 Apache PDFBox提供了创建、渲染、…...

【Python 常用脚本及命令系列 3.2 -- 检测到弹框跳出然后关掉它--脚本实现】
文章目录 简介脚本实现 简介 在Python中,你可以使用第三方库如pyautogui和pygetwindow来检测屏幕上的弹框并关闭它。这些库可以模拟鼠标和键盘操作,也可以获取窗口信息。 首先,需要安装这些库(如果你还没有安装的话)&…...
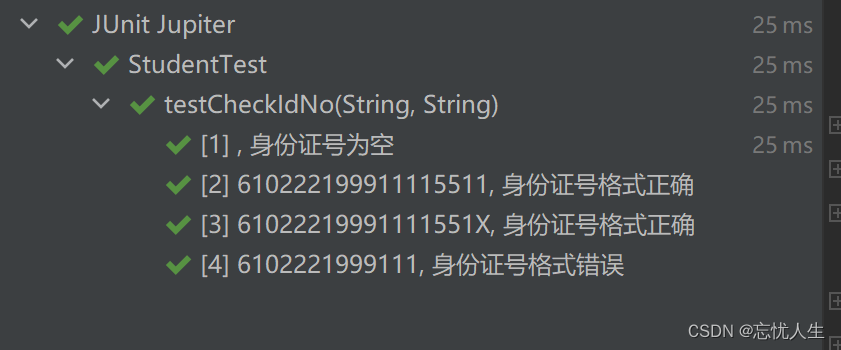
junit单元测试:使用@ParameterizedTest 和 @CsvSource注解简化单元测试方法
在平常的开发工作中,我们经常需要写单元测试。比如,我们有一个校验接口,可能会返回多种错误信息。我们可以针对这个接口,写多个单元测试方法,然后将其场景覆盖全。那么,怎么才能写一个测试方法,…...

C# winform判断自身程序是否已运行,如果已运行则激活窗体
C# winform判断自身程序是否已运行,如果已运行则激活窗体 using System; using System.Collections.Generic; using System.Diagnostics; using System.Linq; using System.Reflection; using System.Runtime.InteropServices; using System.Threading; using Syst…...
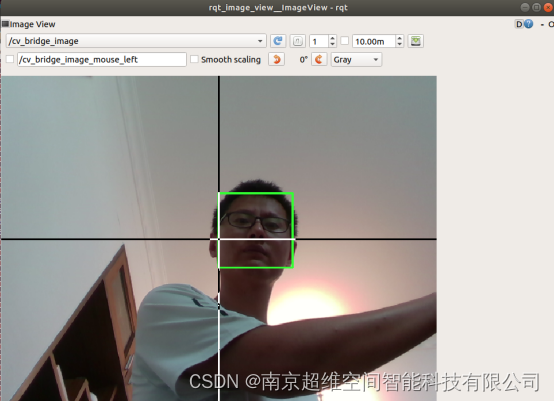
超维空间M1无人机使用说明书——21、基于opencv的人脸识别
引言:M1型号无人机不仅提供了yolo进行物体识别,也增加了基于opencv的人脸识别功能包,仅需要启动摄像头和识别节点即可 链接: 源码链接 一、一键启动摄像头和人脸识别节点 roslaunch robot_bringup bringup_face_detect.launch无报错&#…...
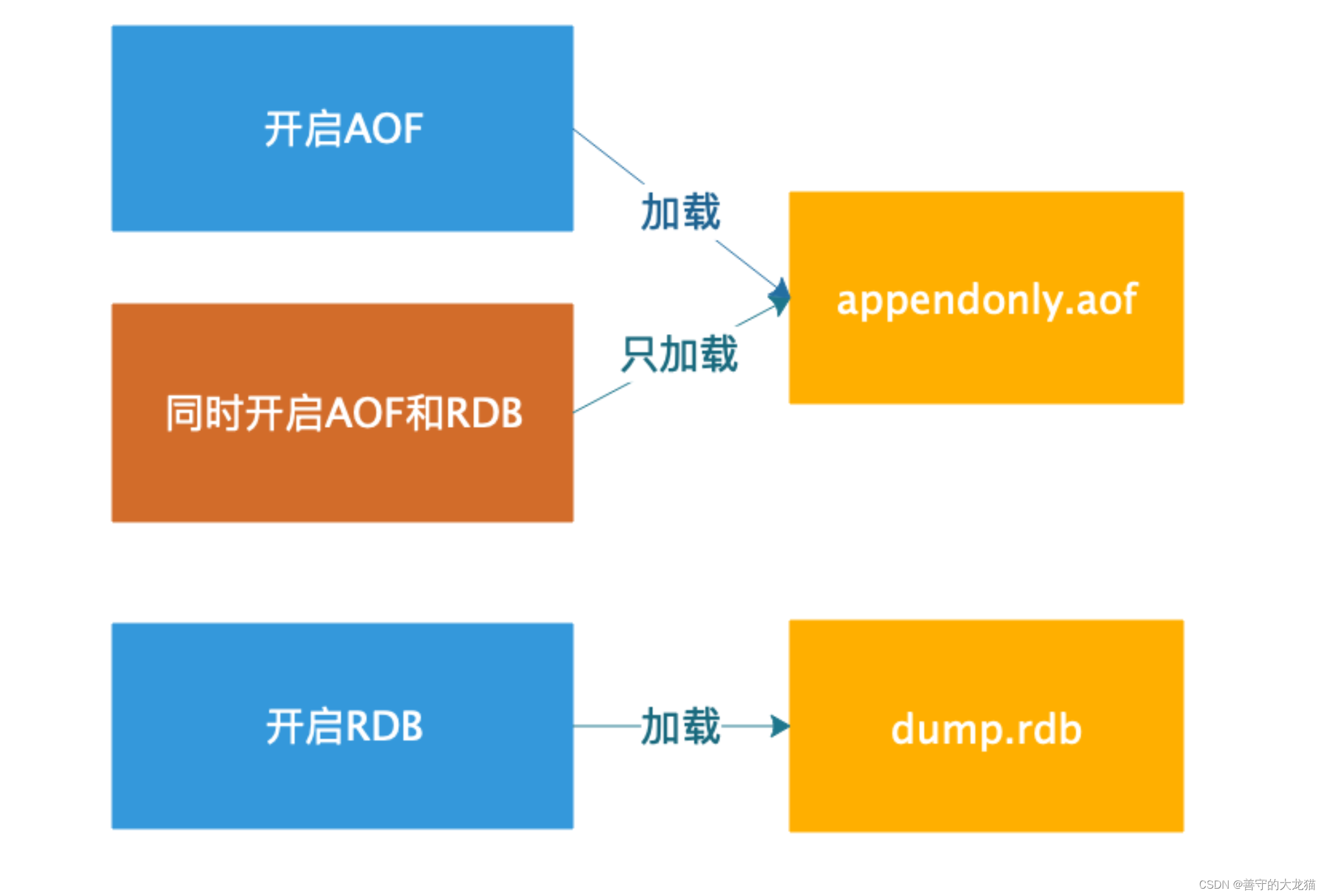
Redis 持久化——AOF
文章目录 为什么需要AOF?概念持久化查询和设置1. 查询AOF启动状态2. 开启AOF持久化2.1 命令行启动AOF2.2 配置文件启动 AOF 3. 触发持久化3.1 自动触发3.3 手动触发 4. AOF 文件重写4.1 什么是AOF重写?4.2 AOF 重写实现4.3 AOF 重写流程 5. 配置说明6. 数据恢复6.1…...
)
华为云服务介绍(二)
在 华为云服务介绍(一) 中我们看到华为云提供了一系列的云服务,包括计算、存储、网络、数据库、安全等方面的解决方案。通过灵活的系统架构设计,可以充分利用这些云服务技术,从而更好地满足用户的需求。 本文从系统架构的角度出发,通过充分利用华为云提供的各种云服务技…...

mysql列题
mysql列题 1.查询学过「张三」老师授课的同学的信息2.查询没有学全所有课程的同学的信息3.查询没学过"张三"老师讲授的任一门课程的学生姓名4.查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩5.检索" 01 "课程分数小于 60,…...

cpu缓存一致性
文章目录 cpu缓存一致性缓存的出现:多核之后带来的缓存一致性问题,如何解决LOCK 指令(刚好可以实现上述的目标)LOCK 指令特性内存屏障特性编译器屏障的作用MESI协议为什么有了 MESI协议 还需要 内存屏障问题:总结&…...
定制CPUSET解决方案-framework部分修改)
Android Framework 常见解决方案(25-1)定制CPUSET解决方案-framework部分修改
1 原理说明 这个方案有如下基本需求: 构建自定义CPUSET,/dev/cpuset中包含一个全新的cpuset分组。且可以通过set_cpuset_policy和set_sched_policy接口可以设置自定义CPUSET。开机启动后可以通过zygote判定来对特定的应用进程设置CPUSET,并…...

PyTorch 参数化深度解析:自定义、管理和优化模型参数
目录 torch.nn子模块parametrize parametrize.register_parametrization 主要特性和用途 使用场景 参数和关键字参数 注意事项 示例 parametrize.remove_parametrizations 功能和用途 参数 返回值 异常 使用示例 parametrize.cached 功能和用途 如何使用 示例…...

Tiny AI Client:零依赖、轻量化的AI API调用库设计与实战
1. 项目概述与核心价值最近在折腾AI应用本地化部署和轻量化客户端时,发现了一个挺有意思的项目——piEsposito/tiny-ai-client。这名字起得就很直白,“tiny”意味着小巧,“ai-client”点明了它是一个AI客户端。乍一看,你可能会觉得…...

Navicat导入Excel实战:从数据准备到成功入库的完整避坑指南
1. 数据准备:Excel规范整理实战 第一次用Navicat导入Excel时,我对着报错提示整整折腾了两小时。后来才发现,90%的问题都出在数据准备阶段。就像做饭前要洗菜切配,数据导入前也需要做好这些准备工作: 字段命名要像给变量…...

绩效考核的量化迷思:如何衡量不可直接测量的技术贡献
一、量化绩效考核的困境:软件测试的“隐形”价值在软件行业的绩效考核体系中,量化指标似乎成了“公平”与“高效”的代名词。代码行数、Bug数量、测试用例覆盖率……这些清晰可统计的数字,被当作衡量技术人员贡献的核心标尺。然而,…...

5分钟彻底解决Windows软件DLL缺失问题:VisualCppRedist AIO完整修复方案
5分钟彻底解决Windows软件DLL缺失问题:VisualCppRedist AIO完整修复方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过新安装的软…...

后端开发必看:设计高并发系统时,如何估算你的RTT和时延带宽积?
高并发系统设计实战:从RTT到时延带宽积的性能优化指南 在分布式系统的世界里,网络性能指标往往成为制约整体吞吐量的隐形瓶颈。我曾亲眼见证过一个日活百万的社交平台,因为微服务间调用的RTT估算偏差,导致高峰期请求堆积如山的惨状…...

TlbbGmTool:从数据库小白到《天龙八部》单机版管理大师的蜕变之旅
TlbbGmTool:从数据库小白到《天龙八部》单机版管理大师的蜕变之旅 【免费下载链接】TlbbGmTool 某网络游戏的单机版本GM工具 项目地址: https://gitcode.com/gh_mirrors/tl/TlbbGmTool 你是否曾经面对《天龙八部》单机版数据库的复杂结构感到无从下手&#x…...
✅)
计算机毕业设计:Python医疗文本挖掘与可视化决策平台 Flask框架 随机森林 机器学习 疾病数据 智慧医疗 深度学习(建议收藏)✅
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与…...

Go+SQLite构建极简自托管笔记共享平台:从原理到部署实战
1. 项目概述:一个极简、自托管的笔记共享平台最近在折腾个人知识管理工具时,我一直在寻找一个能让我快速分享单篇笔记或代码片段,同时又不想依赖第三方云服务的方案。市面上的Pastebin类工具很多,但要么功能臃肿,要么隐…...

技术Leader的困境:为什么你越努力,团队越依赖你?
在软件测试领域,我们比任何角色都更懂“依赖”这个词。测试环境依赖稳定、测试数据依赖真实、测试用例依赖需求文档。但有一种依赖,最致命却也最容易被忽视——团队对你的依赖。很多从一线测试骨干晋升为测试Leader的人,都会陷入一个怪圈&…...

VLSI时代下74系列离散逻辑芯片的现代应用与设计实践
1. 从“胶水逻辑”到“系统粘合剂”:离散逻辑芯片的现代生存法则 在今天的数字电路设计领域,提起“7400系列”或者“74HC04”,很多年轻工程师的第一反应可能是博物馆里的古董,或者教科书上的历史章节。主流叙事已经被SoC、FPGA和高…...