Scrapy爬虫框架入门
Scrapy是Python开发的一个非常流行的网络爬虫框架,可以用来抓取Web站点并从页面中提取结构化的数据,被广泛的用于数据挖掘、数据监测和自动化测试等领域。下图展示了Scrapy的基本架构,其中包含了主要组件和系统的数据处理流程(图中带数字的红色箭头)。
Python爬虫学习教程:Scrapy爬虫框架入门
组件
Scrapy引擎(Engine):Scrapy引擎是用来控制整个系统的数据处理流程。
调度器(Scheduler):调度器从Scrapy引擎接受请求并排序列入队列,并在Scrapy引擎发出请求后返还给它们。
下载器(Downloader):下载器的主要职责是抓取网页并将网页内容返还给蜘蛛(Spiders)。
蜘蛛(Spiders):蜘蛛是有Scrapy用户自定义的用来解析网页并抓取特定URL返回的内容的类,每个蜘蛛都能处理一个域名或一组域名,简单的说就是用来定义特定网站的抓取和解析规则。
条目管道(Item Pipeline):条目管道的主要责任是负责处理有蜘蛛从网页中抽取的数据条目,它的主要任务是清理、验证和存储数据。当页面被蜘蛛解析后,将被发送到条目管道,并经过几个特定的次序处理数据。每个条目管道组件都是一个Python类,它们获取了数据条目并执行对数据条目进行处理的方法,同时还需要确定是否需要在条目管道中继续执行下一步或是直接丢弃掉不处理。条目管道通常执行的任务有:清理HTML数据、验证解析到的数据(检查条目是否包含必要的字段)、检查是不是重复数据(如果重复就丢弃)、将解析到的数据存储到数据库(关系型数据库或NoSQL数据库)中。
中间件(Middlewares):中间件是介于Scrapy引擎和其他组件之间的一个钩子框架,主要是为了提供自定义的代码来拓展Scrapy的功能,包括下载器中间件和蜘蛛中间件。
其实在前面的 Python爬虫学习教程中,有跟大家讲到过Scrapy
Python爬虫学习教程:Scrapy爬虫框架入门
数据处理流程
Scrapy的整个数据处理流程由Scrapy引擎进行控制,通常的运转流程包括以下的步骤:
引擎询问蜘蛛需要处理哪个网站,并让蜘蛛将第一个需要处理的URL交给它。
引擎让调度器将需要处理的URL放在队列中。
引擎从调度那获取接下来进行爬取的页面。
调度将下一个爬取的URL返回给引擎,引擎将它通过下载中间件发送到下载器。
当网页被下载器下载完成以后,响应内容通过下载中间件被发送到引擎;如果下载失败了,引擎会通知调度器记录这个URL,待会再重新下载。
引擎收到下载器的响应并将它通过蜘蛛中间件发送到蜘蛛进行处理。
蜘蛛处理响应并返回爬取到的数据条目,此外还要将需要跟进的新的URL发送给引擎。
引擎将抓取到的数据条目送入条目管道,把新的URL发送给调度器放入队列中。
上述操作中的2-8步会一直重复直到调度器中没有需要请求的URL,爬虫停止工作。
安装和使用Scrapy
可以先创建虚拟环境并在虚拟环境下使用pip安装scrapy。
项目的目录结构如下图所示。
(venv) $ tree
.
|____ scrapy.cfg
|____ douban
| |____ spiders
| | |____ init.py
| | |____ pycache
| |____ init.py
| |____ pycache
| |____ middlewares.py
| |____ settings.py
| |____ items.py
| |____ pipelines.py
【说明】:Windows系统的命令行提示符下有tree命令,但是Linux和MacOS的终端是没有tree命令的,可以用下面给出的命令来定义tree命令,其实是对find命令进行了定制并别名为tree。
alias tree=“find . -print | sed -e ‘s;[^/]*/;|;g;s;|; |;g’”
Linux系统也可以通过yum或其他的包管理工具来安装tree。
yum install tree
根据刚才描述的数据处理流程,基本上需要我们做的有以下几件事情:
1.在items.py文件中定义字段,这些字段用来保存数据,方便后续的操作。
-- coding: utf-8 --
Define here the models for your scraped items
See documentation in:
import scrapy
class DoubanItem(scrapy.Item):
name = scrapy.Field()
year = scrapy.Field()
score = scrapy.Field()
director = scrapy.Field()
classification = scrapy.Field()
actor = scrapy.Field()
2.在spiders文件夹中编写自己的爬虫。
(venv) $ scrapy genspider movie movie.douban.com --template=crawl
-- coding: utf-8 --
import scrapy
from scrapy.selector import Selector
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from douban.items import DoubanItem
class MovieSpider(CrawlSpider):
name = ‘movie’
allowed_domains = [‘movie.douban.com’]
start_urls = [‘]
rules = (
Rule(LinkExtractor(allow=(r’?start=\d+.‘))),
Rule(LinkExtractor(allow=(r’\d+‘)), callback=‘parse_item’),
)
def parse_item(self, response):
sel = Selector(response)
item = DoubanItem()
item[‘name’]=sel.xpath(’//[@id=“content”]/h1/span[1]/text()‘).extract()
item[‘year’]=sel.xpath(’//[@id=“content”]/h1/span[2]/text()‘).re(r’((\d+))‘)
item[‘score’]=sel.xpath(’//[@id=“interest_sectl”]/div/p[1]/strong/text()‘).extract()
item[‘director’]=sel.xpath(’//[@id=“info”]/span[1]/a/text()‘).extract()
item[‘classification’]= sel.xpath(’//span[@property=“v:genre”]/text()‘).extract()
item[‘actor’]= sel.xpath(’//[@id=“info”]/span[3]/a[1]/text()').extract()
return item
说明:上面我们通过Scrapy提供的爬虫模板创建了Spider,其中的rules中的LinkExtractor对象会自动完成对新的链接的解析,该对象中有一个名为extract_link的回调方法。Scrapy支持用XPath语法和CSS选择器进行数据解析,对应的方法分别是xpath和css,上面我们使用了XPath语法对页面进行解析,如果不熟悉XPath语法可以看看后面的补充说明。
到这里,我们已经可以通过下面的命令让爬虫运转起来。
(venv)$ scrapy crawl movie
可以在控制台看到爬取到的数据,如果想将这些数据保存到文件中,可以通过-o参数来指定文件名,Scrapy支持我们将爬取到的数据导出成JSON、CSV、XML、pickle、marshal等格式。
(venv)$ scrapy crawl moive -o result.json
3.在pipelines.py中完成对数据进行持久化的操作。
-- coding: utf-8 --
Define your item pipelines here
Don’t forget to add your pipeline to the ITEM_PIPELINES setting
See:
import pymongo
from scrapy.exceptions import DropItem
from scrapy.conf import settings
from scrapy import log
class DoubanPipeline(object):
def init(self):
connection = pymongo.MongoClient(settings[‘MONGODB_SERVER’], settings[‘MONGODB_PORT’])
db = connection[settings[‘MONGODB_DB’]]
self.collection = db[settings[‘MONGODB_COLLECTION’]]
def process_item(self, item, spider):
#Remove invalid data
valid = True
for data in item:
if not data:
valid = False
raise DropItem(“Missing %s of blogpost from %s” %(data, item[‘url’]))
if valid:
#Insert data into database
new_moive=[{
“name”:item[‘name’][0],
“year”:item[‘year’][0],
“score”:item[‘score’],
“director”:item[‘director’],
“classification”:item[‘classification’],
“actor”:item[‘actor’]
}]
self.collection.insert(new_moive)
log.msg(“Item wrote to MongoDB database %s/%s” %
(settings[‘MONGODB_DB’], settings[‘MONGODB_COLLECTION’]),
level=log.DEBUG, spider=spider)
return item
利用Pipeline我们可以完成以下操作:
清理HTML数据,验证爬取的数据。
丢弃重复的不必要的内容。
将爬取的结果进行持久化操作。
4.修改settings.py文件对项目进行配置。
-- coding: utf-8 --
Scrapy settings for douban project
For simplicity, this file contains only settings considered important or
commonly used. You can find more settings consulting the documentation:
BOT_NAME = ‘douban’
SPIDER_MODULES = [‘douban.spiders’]
NEWSPIDER_MODULE = ‘douban.spiders’
Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5’
Obey robots.txt rules
ROBOTSTXT_OBEY = True
Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 32
Configure a delay for requests for the same website (default: 0)
See #download-delay
See also autothrottle settings and docs
DOWNLOAD_DELAY = 3
RANDOMIZE_DOWNLOAD_DELAY = True
The download delay setting will honor only one of:
CONCURRENT_REQUESTS_PER_DOMAIN = 16
CONCURRENT_REQUESTS_PER_IP = 16
Disable cookies (enabled by default)
COOKIES_ENABLED = True
MONGODB_SERVER = ‘120.77.222.217’
MONGODB_PORT = 27017
MONGODB_DB = ‘douban’
MONGODB_COLLECTION = ‘movie’
Disable Telnet Console (enabled by default)
TELNETCONSOLE_ENABLED = False
Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8’,
‘Accept-Language’: ‘en’,
}
Enable or disable spider middlewares
See
SPIDER_MIDDLEWARES = {
‘douban.middlewares.DoubanSpiderMiddleware’: 543,
}
Enable or disable downloader middlewares
See
DOWNLOADER_MIDDLEWARES = {
‘douban.middlewares.DoubanDownloaderMiddleware’: 543,
}
Enable or disable extensions
See
EXTENSIONS = {
‘scrapy.extensions.telnet.TelnetConsole’: None,
}
Configure item pipelines
See
ITEM_PIPELINES = {
‘douban.pipelines.DoubanPipeline’: 400,
}
LOG_LEVEL = ‘DEBUG’
Enable and configure the AutoThrottle extension (disabled by default)
See
#AUTOTHROTTLE_ENABLED = True
The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
The average number of requests Scrapy should be sending in parallel to
each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
Enable and configure HTTP caching (disabled by default)
See #httpcache-middleware-settings
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = ‘httpcache’
HTTPCACHE_IGNORE_HTTP_CODES = []
HTTPCACHE_STORAGE = ‘scrapy.extensions.httpcache.FilesystemCacheStorage’
相关文章:

Scrapy爬虫框架入门
Scrapy是Python开发的一个非常流行的网络爬虫框架,可以用来抓取Web站点并从页面中提取结构化的数据,被广泛的用于数据挖掘、数据监测和自动化测试等领域。下图展示了Scrapy的基本架构,其中包含了主要组件和系统的数据处理流程(图中…...
最新使用nvm控制node版本步骤
一、完全卸载已经安装的node、和环境变量 ①、打开控制面板的应用与功能,搜索node,点击卸载 ②、打开环境变量,将node相关的所有配置清除 ③、打开命令行工具,输入node-v,没有版本号则卸载成功 二、下载nvm安装包 ①…...

Linux内核4.14版本——drm框架分析(1)——drm简介
目录 1. DRM简介(Direct Rendering Manager) 1.1 DRM发展历史 1.2 DRM架构对比FB架构优势 1.3 DRM图形显示框架 1.4 DRM图形显示框架涉及元素 1.4.1 DRM Framebuffer 1.4.2 CRTC 1.4.3 Encoder 1.4.4 Connector 1.4.5 Bridge 1.4.6 Panel 1.4.…...

Google的一道经典面试题 - 767. 重构字符串
文章目录Google的一道经典面试题 - 767. 重构字符串767. 重构字符串1054. 距离相等的条形码结论Google的一道经典面试题 - 767. 重构字符串 767. 重构字符串 题目链接:767. 重构字符串 题目大意:给定一个字符串 s ,检查是否能重新排布其中的…...

E8-公共选择框相关的表
起因 昨天同事和我说,要在一个表单里加一组可选项。于是我去了公共选择框维护。这时候才发了这么个问题,前几天我在本机的测试环境里做的流程,导入到我们的生产环境里,表单里所用到的共公选择框的选项都在,在表单里是…...
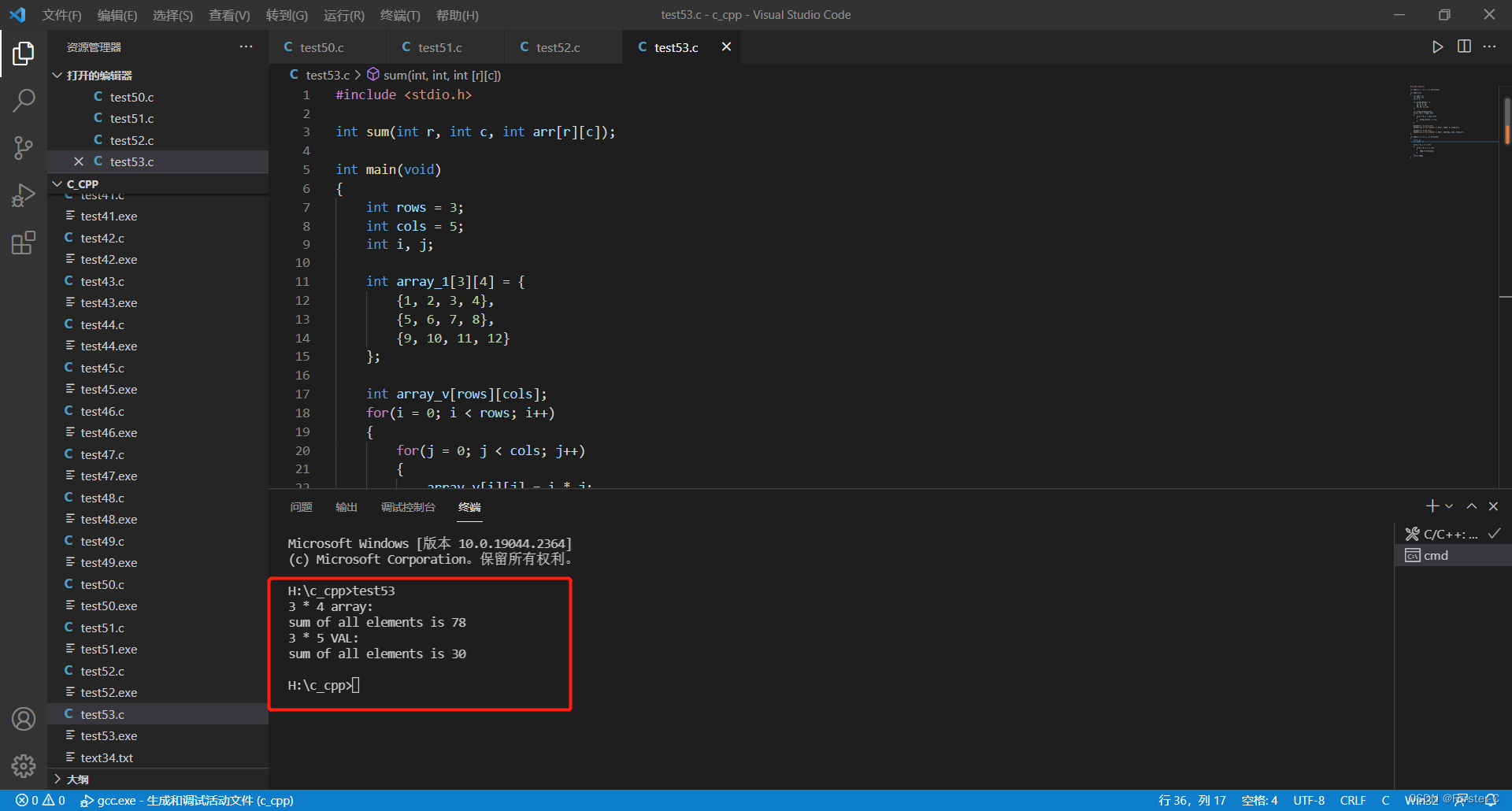
再学C语言41:变长数组(VLA)
处理二维数组的函数:数组的行可以在函数调用时传递,但是数组的列只能被预置在函数内部 示例代码: #define COLS 4 int sum(int arr[][COLS], int rows) {int r;int c;int temp 0;for(r 0; r < rows; r){for(c 0; c < COLS; c){tem…...

物联网WEB大屏数据可视化
最近了解WEB大屏显示。一般像嵌入式这类的,MQTT协议会走的多一些,走订阅和发布的策略,网上走了一圈之后,目前有几个实现方案。这里对比一下几个物联网协议,相对而言MQTT更合适物联网,其它几个协议不是干这个…...
新:DlhSoft Gantt Chart for WPF Crack
用于 Silverlight/WPF 4.3.48 的 DlhSoft 甘特图灯光库 改进甘特图、网络图和 PERT 图表组件的 PERT 关键路径算法。2023 年 3 月 2 日 - 17:09新版本特征 改进了甘特图、网络图和 PERT 图表组件的 PERT 关键路径算法。Silverlight/WPF 标准版的 DlhSoft 甘特图灯光库 DlhSoft …...
C++基础(一)—— C++概述、C++对C的扩展(作用域、struct类型、引用、内联函数、函数默认参数、函数占位参数、函数重载)
1. C概述1.1 c简介“c”中的来自于c语言中的递增运算符,该运算符将变量加1。c起初也叫”c withclsss”.通过名称表明,c是对C的扩展,因此c是c语言的超集,这意味着任何有效的c程序都是有效的c程序。c程序可以使用已有的c程序库。为什…...
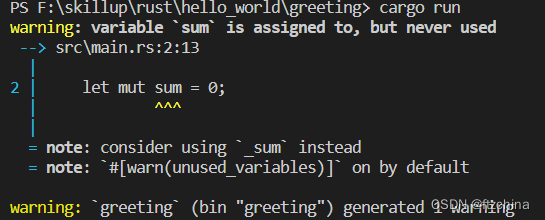
Rust学习总结之if,while,loop,for使用
目录 一:if的使用 二:while的使用 三:loop的使用 四:for的使用 本文总结的四种语句(if,while,loop,for)除了loop,其他的三个在C语言或者Python中都是常见…...
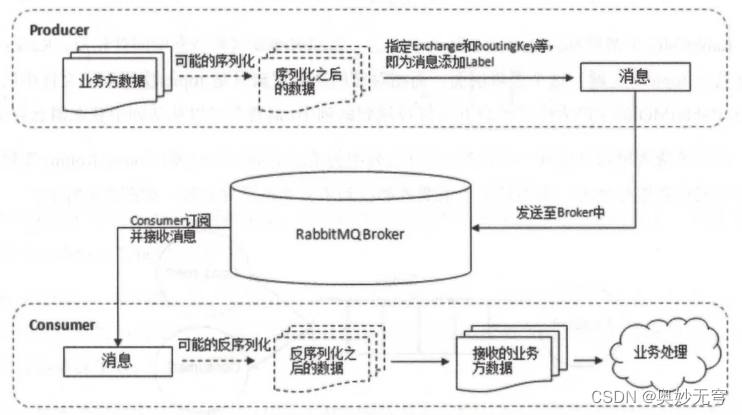
Java知识复习(十一)RabbitMQ
1、RabbitMQ简介 RabbitMQ 是采用 Erlang 语言实现 AMQP(Advanced Message Queuing Protocol,高级消息队列协议)的消息中间件 2、RabbitMQ核心概念 RabbitMQ 整体上是一个生产者与消费者模型,主要负责接收、存储和转发消息 3、Producer和…...

thinkphp图片压缩类
<?php namespace app\lib; /** * 图片压缩类:通过缩放来压缩。 * 如果要保持源图比例,把参数$percent保持为1即可。 * 即使原比例压缩,也可大幅度缩小。数码相机4M图片。也可以缩为700KB左右。如果缩小比例,则体积会更小。…...
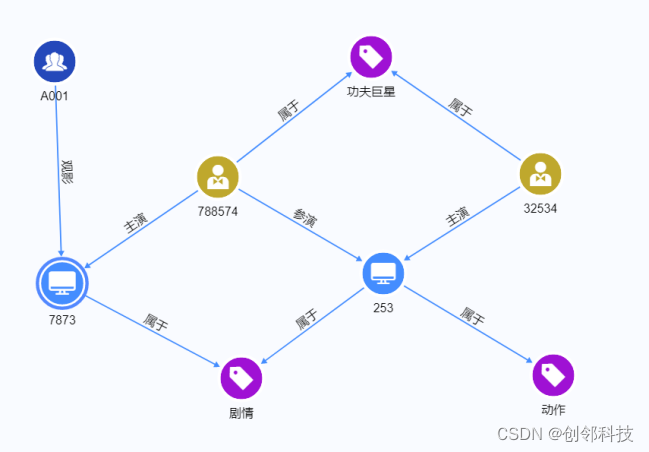
如何将图数据库应用于电影智能推荐
导读 电影,是一种结合视觉与听觉的现代艺术。如今,电影已不单是人们娱乐消遣的生活方式,也逐渐成为国家文化软实力的重要标志之一。据有关数据统计,2021年中国影视行业市场规模达2349亿元,同比增长23.2%,预…...
CSS实现动画效果的菜单收起展开图标,html实现动画效果的箭头
效果 实现代码 此处JS代码引入了jquery <!DOCTYPE html> <html><head><meta charset"UTF-8"><title></title><style>.menu-icon{position: absolute;left: 20%;top: 30%;transition: all .3s;}.menu-icon:before, .menu…...

大数据平台小结
搭建大数据平台启动流程1、启动Nginx服务(在bdp-web-mysql服务中)cd /usr/local/nginx/# 启动Nginx ./sbin/nginx# 查看端口是否存在 netstat -tunlp|grep 200012、启动zookeeper(在bdp-executor-realtime123)cd /app/bdp/apache-…...

力扣-139单词拆分
力扣-139单词拆分 1、题目 给你一个字符串 s 和一个字符串列表 wordDict 作为字典。请你判断是否可以利用字典中出现的单词拼接出 s 。 注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。 示例 1: 输入: s "…...

图机器学习-图神经网络
图神经网络 前面讲了图机器学习的一些传统方法,现在正式进入到课程的核心部分:图神经网络。 Design of GNN 那么图神经网络和我们之前接触的一些深度神经网络有什么不同呢? 对于别的类型的神经网络,往往我们都是处理一些类似网…...

配置Airbyte资源限制
资源限制有三种不同的级别配置:Instance-wide - 应用到Airbyte实例创建的Sync Job的所有容器上。Connector-specific - 应用到Airbyte实例创建的Sync Job的所有指定类型连接器的容器上Connection-specific - 应用到Airbyte实例创建的Sync Job的所有指定管道的容器上…...
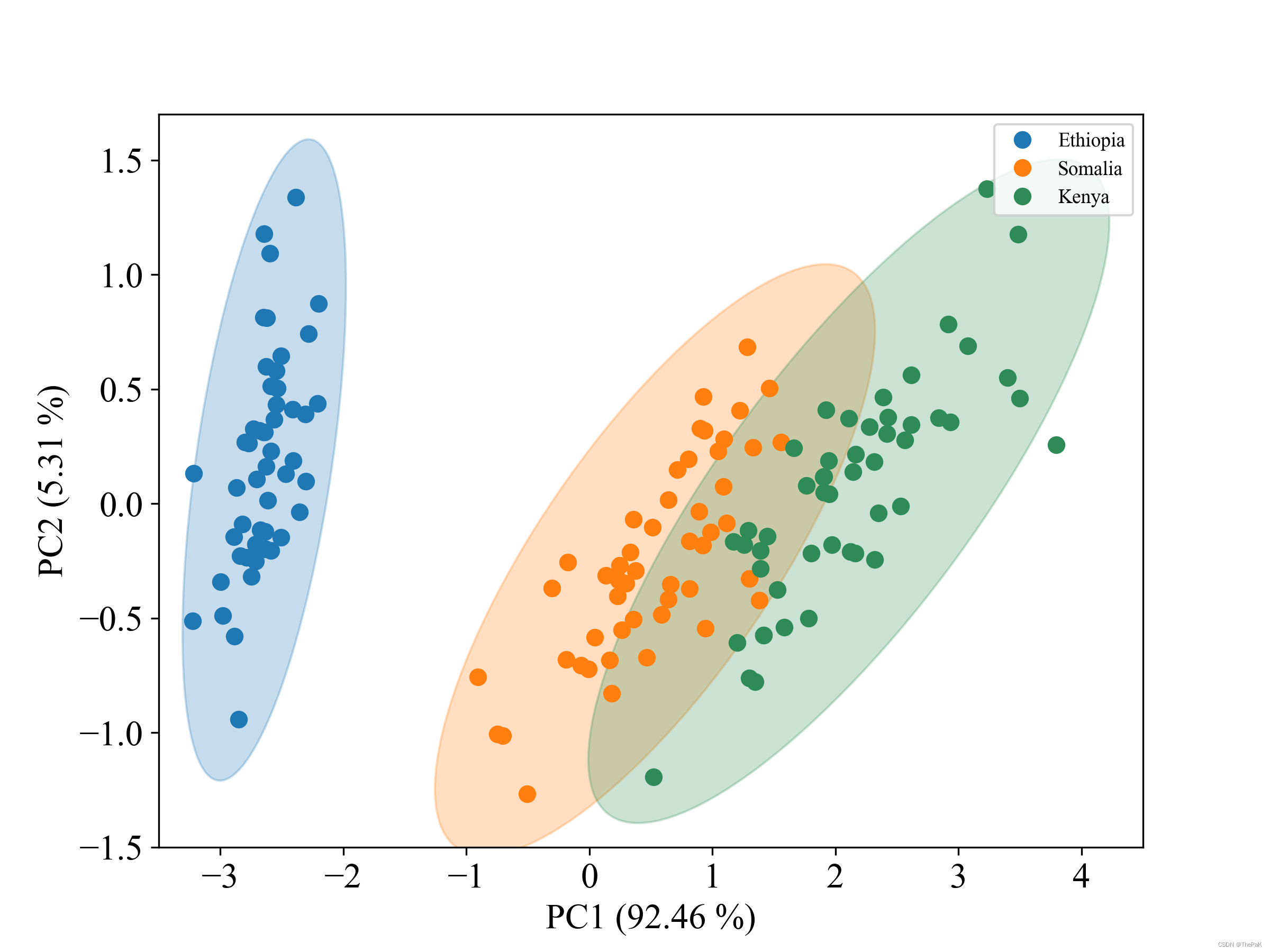
python实现PCA降维画分类散点图并标出95%的置信区间
此代码以数据集鸢尾花为例,对其使用PCA降维后,绘制了三个类别的样本点和对应的置信圆(即椭圆)。先放效果图。 下面是完整代码: from matplotlib.patches import Ellipsedef plot_point_cov(points, nstd3, axNone, **…...

Mysql高级之索引结构详解
Mysql的索引详解1.索引定义2.索引结构2.1数据结构分析2.1.1熟知的数据结构2.1.2分析为什么这么多的数据结构不全适用于索引结构2.2Hash结构2.3B tree结构3.索引分类3.1聚集索引(聚簇索引)3.2非聚集索引(稀疏索引)3.3联合索引3.4主…...

Nordic nRF52832蓝牙串口实战:手把手教你用SDK 15.3.0实现手机与设备双向通信
Nordic nRF52832蓝牙串口开发实战:从SDK配置到双向通信全解析 在嵌入式蓝牙开发领域,Nordic的nRF52832芯片凭借其优异的射频性能和丰富的外设资源,成为物联网设备开发的明星选择。但对于刚接触这款芯片的开发者来说,如何快速实现手…...

家庭Kubernetes集群实践:从硬件选型到GitOps自动化部署
1. 项目概述:从个人服务器到家庭集群的进化如果你和我一样,是个喜欢在家里折腾点技术玩意儿的爱好者,从一台树莓派跑点小服务,到后来升级成一台小主机,再到后来发现服务越来越多,备份、高可用、资源隔离这些…...

开源AI对话界面chat-ui:快速部署与定制化LLM前端实践
1. 项目概述:一个开源的AI对话界面如果你最近在折腾大语言模型(LLM),不管是想部署一个私有的ChatGPT替代品,还是想给自己训练或微调的模型配一个像样的“脸面”,那你大概率绕不开一个核心问题:前…...
)
机器视觉 Vs 智能体视觉(29)
重磅预告:本专栏将独家连载新书《智能体视觉技术与应用》(系列丛书)部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。…...
)
大模型小白入门指南:3分钟读懂核心逻辑+高性价比产品推荐(建议收藏+转发)
大模型小白入门指南:3分钟读懂核心逻辑高性价比产品推荐(建议收藏转发) 本文通俗易懂地拆解了大众对大模型的三个常见误区,如“大模型高级聊天机器人”、“大模型会说谎”、“AI会取代人类”。通过比喻方式解释了大语言模型和多模…...

NoSleep:3种工作模式,解决Windows自动休眠的9大场景难题
NoSleep:3种工作模式,解决Windows自动休眠的9大场景难题 【免费下载链接】NoSleep Lightweight Windows utility to prevent screen locking 项目地址: https://gitcode.com/gh_mirrors/nos/NoSleep 你是否曾因Windows自动休眠而中断重要的远程演…...

2026年AI开发一站式工作台选型:模力方舟MoArk实战价值解析
在2026年的AI产业实践中,技术落地的复杂性与效率瓶颈依然是开发者面临的核心挑战。当AI开发从实验走向规模化应用,对覆盖模型体验、微调训练、推理部署到商业变现的全流程一体化平台的需求变得尤为迫切。由Gitee(码云)推出的模力方…...

低成本组合导航系统:让精准导航不再昂贵
在无人系统、精准农业和自动驾驶快速发展的今天,高精度导航早已成为刚需。然而,传统高端导航系统动辄数万甚至数十万元的成本,让许多中小型企业和创新团队望而却步。如今,这一局面被彻底打破——ER-GNSS/MINS-05低成本组合导航系统…...

菲仕技术冲刺港股:年营收16亿,亏6189万 先进制造与京津冀基金是股东
雷递网 雷建平 5月14日宁波菲仕技术股份有限公司(简称:“菲仕技术”)日前更新招股书,准备在港交所上市。年营收16亿 亏6189万菲仕技术成立于2001年,是一家电驱动解决方案供应商,提供综合及定制化的电驱动系…...

OpencvSharp 算子学习教案之 - Cv2.Scharr
OpencvSharp 算子学习教案之 - Cv2.Scharr 大家好,Opencv在很多工程项目中都会用到,而OpencvSharp则是以C#开发与实现的Opencv操作库,对.NET开发人员友好,但很多API的中文资料、应用场景及常见坑点等缺乏系统性归纳,因…...