Kafka(四)Broker
目录
- 1 配置Broker
- 1.1 Broker的配置
- broker.id=0
- listerers
- zookeeper.connect
- log.dirs
- log.dir=/tmp/kafka-logs
- num.recovery.threads.per.data.dir=1
- auto.create.topics.enable=true
- auto.leader.rebalance.enable=true, leader.imbalance.check.interval.seconds=300, leader.imbalance.per.broker.percentage=10
- delete.topic.enable=true
- broker.rack
- replica.lag.time.max.ms=30000 (30 seconds)
- zookeeper.session.timeout.ms=18000 (18 seconds)
- flush.messages=9223372036854775807
- flush.ms=9223372036854775807
- 1.2 主题的默认配置
- num.partition=1
- default.replication.factor=1
- min.insync.replicas=1
- log.retention.hours=168
- log.retention.minutes
- log.retention.ms
- log.retention.bytes=-1
- log.segment.bytes=1073741824 (1 gibibyte)
- log.roll.hours=168
- log.roll.ms
- message.max.bytes=1048588
- compression.type
- metadata.max.age.ms=300000 (5 minutes)
- delete.retention.ms
- min.compaction.lag.ms
- max.compaction.lag.ms
- min.cleanable.ratio
- log.cleanup.policy
- replication.factor
- 1.3 默认的producer配置
- quota.producer.default=10485760(memoved from 3.0)
- quota.consumer.default=10485760(memoved from 3.0)
- 1.4 默认的consumer配置
- group.min.session.timeout.ms=6000 (6 seconds)
- group.max.session.timeout.ms=1800000 (30 minutes)
- replica.selector.class
- 2 控制器(controller)
- 2.1 控制器选举过程
- 3 复制(replacate)
- 3.1 首领副本
- 3.1.1 首领选举流程
- 3.2 跟随者副本
- 3.3 同步副本
- 3.4 首选首领
- 4 处理客户端请求
- 4.1 元数据请求
- 4.2 生产请求
- 4.3 获取请求
- 4.4 其他请求
- 5 物理存储
- 5.1 分层存储
- 5.2 分区的分配
- 5.3 文件管理
- 5.4 文件格式
- 5.5 偏移量索引
- 5.6 压实(compact)
- 5.6.1 相关配置
- log.cleaner.enable=true
- log.cleanup.policy=delete
- log.cleaner.delete.retention.ms
- log.cleaner.min.cleanable.ratio=0.5
- log.cleaner.max.compaction.lag.ms
- log.cleaner.min.compaction.lag.ms
- 6 为broker选择硬件
- 6.1 磁盘
- 6.2 内存
- 6.3 网络
- 6.4 CPU
- 7 云端Kafka
- 8 Kafka集群
- 8.1 broker的数量
- 8.2 操作系统调优
- 9 生产环境
- 9.1 垃圾回收
- 9.2 数据中心布局
- 9.3 共享Zookeeper
- Appendix
- 零复制技术
- 面临的问题
- DMA技术
- 零复制技术
- sendfile
- 利用 DMA 技术
- 传递文件描述符代替数据拷贝
- 利用传递文件描述符代替内核中的数据拷贝
Kafka Broker是Apache Kafka中的一个重要组件,它负责接收、存储和转发消息。Kafka Broker是一个分布式系统,可以在多台服务器上运行,以实现高可用性和水平扩展性。
Kafka Broker通过分区将消息存储在主题中,并且可以处理多个生产者和消费者之间的消息传递。它还负责管理消息的持久性和复制,以确保消息不会丢失,并且可以在发生故障时进行恢复。
Kafka Broker使用Zookeeper来协调集群中的各个节点,以确保数据的一致性和可靠性。它还提供了一系列的API,使得开发者可以方便地与Kafka Broker进行交互,包括生产消息、消费消息和管理主题等操作。
总的来说,Kafka Broker是Apache Kafka中的核心组件,它为分布式消息系统提供了高性能、可靠性和可扩展性的基础。
1 配置Broker
1.1 Broker的配置
broker.id=0
标识符,任意整数,默认值为0。在集群中必须唯一,否则注册到ZooKeeper会失败。
listerers
对外提供服务的URI列表,格式为:
<protocol>://<hostname>:<port>
例如:
listeners=PLAINTEXT://172.26.143.96:9092,SSL://172.26.143.96:9093,SASL_SSL://172.26.143.96:9094
zookeeper.connect
ZooKeeper的地址列表,格式为:
<hostname>:<port>/path
其中path为可选
例如:
127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002
log.dirs
日志片段的存放目录,格式为逗号分隔的本地文件系统路径。
例如:
/tmp/kafka-logs,/tmp/kafka-logs-1,/tmp/kafka-logs-2
log.dir=/tmp/kafka-logs
如果没有指定log.dirs,日志片段保存路径由它指定。
例如:
/tmp/kafka-logs
num.recovery.threads.per.data.dir=1
处理每一个日志片段目录的线程数,默认为1。此线程的职责:
- 服务正常启动时打开日志片段
- 服务崩溃重启时,检查和截短每个分区的日志片段
- 服务器正常关闭时,用于关闭日志片段
auto.create.topics.enable=true
默认为true,以下情况会自动创建主题:
- 生产者开始写入消息时
- 消费者开始读取消息时
- 客户端发送获取元数据请求时
auto.leader.rebalance.enable=true, leader.imbalance.check.interval.seconds=300, leader.imbalance.per.broker.percentage=10
为了确保主题分区的首领权不会集中在一个broker身上,如果设置为true,有一个后台线程会定期(leader.imbalance.check.interval.seconds)扫描broker是否超过了比重(leader.imbalance.per.broker.percentage),如果超过了,就会触发一次领袖再均衡。
在首领再均衡的过程中,Kafka会检查首选首领是否是同步的,当前首领是否时首选首领。如果同步,但不是当前首领,就会触发首领选举,让首选首领成为当前首领。
delete.topic.enable=true
是否允许删除主题。如果关闭,管理工具将无法删除主题。
broker.rack
用来指定broker的机架。用于机架感知副本分配,以实现容错。将broker部署在不同的机架上,同一个分区的不同副本可以分配给位于不同机架上的broker。
例如: ‘RACK1‘, ’us-east-1d‘
replica.lag.time.max.ms=30000 (30 seconds)
如果一个follower这段时间内没有发送任何fetch请求,或者没有消费leader最新偏移量的消息,那么leader将从isr中删除该follower。
zookeeper.session.timeout.ms=18000 (18 seconds)
允许broker不向ZooKeeper发送心跳的时间间隔。如果超过这个时间不向ZK发送心跳,ZK会认为broker已经死亡,会将其移除出集群。
flush.messages=9223372036854775807
此设置允许指定一个间隔,在该间隔,我们将强制对写入日志的数据进行fsync。例如,如果将其设置为1,我们将在每条消息之后进行fsync;如果是5,我们将在每5条消息之后进行fsync。通常,我们建议您不要设置此项,并使用复制以提高耐用性,并允许操作系统的后台刷新功能,因为它更高效。此设置可以在每个主题的基础上覆盖(请参阅每个主题配置部分)。
flush.ms=9223372036854775807
此设置允许指定一个时间间隔,在该时间间隔内,我们将强制对写入日志的数据进行fsync。例如,如果将其设置为1000,我们将在1000毫秒后进行fsync。通常,我们建议您不要设置此项,并使用复制以提高耐用性,并允许操作系统的后台刷新功能,因为它更高效。
1.2 主题的默认配置
Kafka为新创建的主题提供了很多默认配置参数,想要修改这些参数,必须通过管理工具或程序来修改。
num.partition=1
要修改分区数,只能增加,不能减少。如果要创建分区数小于默认值的主题,必须手动创建。
如何选择分区数量
- 主题的吞吐量
- 单个分区读取的吞吐量
- 单个分区写入的吞吐量
- 按键写入分区,未来预期吞吐量
- 每个broker的分区数,可用磁盘,网络带宽
- 避免使用太多分区,消耗过多资源和首领选举时间
- 镜像吞吐量
云服务有IOPS的限制吗经验数据:将分区每天保留的数据限制在6G以内
default.replication.factor=1
自动创建主题的默认复制因子。建议为min.insync.replicas+1或+2
min.insync.replicas=1
最小同步副本数。min.insync.replicas(默认值为1)代表了正常写入生产者数据所需要的最少ISR个数, 当ISR中的副本数量小于min.insync.replicas时,Leader停止写入生产者生产的消息,并向生产者抛出NotEnoughReplicas异常,阻塞等待更多的 Follower 赶上并重新进入ISR, 因此能够容忍min.insync.replicas-1个副本同时宕机。当与min.insync.replicas和acks一起使用时,可以实现更大的耐用性保证。一个典型的场景是创建一个复制因子为3的主题,将min.insync.replicas设置为2,并使用acks “all”进行生产。
log.retention.hours=168
数据保留的时间:小时。数据保留时间时根据检查日志片段文件的最后修改时间来开始计算的。一般是日志片段文件关闭时间,如果在分区间移动文件,可能导致时间不准确。
log.retention.minutes
数据保留的时间:分钟。
log.retention.ms
数据保留的时间:毫秒。
log.retention.bytes=-1
数据保留的字节数,对应的是每一个分区。-1代表无限期保留数据。它和时间保留策略哪一个先满足哪一个生效。
log.segment.bytes=1073741824 (1 gibibyte)
日志片段文件达到多大会关闭当前文件,打开一个新的文件。
按照时间戳获取偏移量时,会查找在时间戳之前打开,之后关闭的日志片段文件,然后获取开头的偏移量。
log.roll.hours=168
多长时间后日志片段可以被关闭:单位小时。
log.roll.ms
多长时间后日志片段可以被关闭:单位毫秒。
message.max.bytes=1048588
Kafka允许的最大记录批处理大小(如果启用压缩,则在压缩之后)。如果增加了这个值,并且有0.10.2以上的消费者,那么消费者的提取大小也必须增加,这样他们才能提取这么大的记录批次。在最新的消息格式版本中,为了提高效率,总是将记录分组为批。在以前的消息格式版本中,未压缩的记录不会分组为批,在这种情况下,此限制仅适用于单个记录。这可以通过主题级别的max.message.bytes配置为每个主题设置。
compression.type
指定给定主题的最终压缩类型。此配置接受标准压缩编解码器(“zip”、“snappy”、“lz4”、“zstd”)。它还接受“uncompressed”,这相当于没有压缩;以及“producer”,即保留生产者设置的原始压缩编解码器。
metadata.max.age.ms=300000 (5 minutes)
以毫秒为单位的时间段,在此之后,即使我们没有看到任何分区领导的变化,我们也会强制刷新元数据,以主动发现任何新的broker或分区。
delete.retention.ms
min.compaction.lag.ms
max.compaction.lag.ms
min.cleanable.ratio
log.cleanup.policy
replication.factor
1.3 默认的producer配置
quota.producer.default=10485760(memoved from 3.0)
https://issues.apache.org/jira/browse/KAFKA-12591
quota.consumer.default=10485760(memoved from 3.0)
1.4 默认的consumer配置
group.min.session.timeout.ms=6000 (6 seconds)
已注册消费者允许的最小会话超时。较短的超时导致更快的故障检测,而代价是更频繁的消费者心跳,这可能会使代理资源不堪重负。
group.max.session.timeout.ms=1800000 (30 minutes)
已注册消费者允许的最大会话超时值。更长的超时时间使消费者有更多的时间在检测信号之间处理消息,而检测故障的时间更长。
replica.selector.class
实现ReplicaSelector的完全限定类名。这被代理用来查找首选的读取复制副本。默认情况下,我们使用一个返回leader的实现。
如果对于跨区域,数据中心,为了让消费者从同一区域的分区副本读取消息,需要实现机架感知,需要配置为:apache.kafka.common.replica.RackAwareReplicaSelector。并且Consumer端需要配置client.rack来标识其物理位置,并且与broker的broker.rack参数相匹配。
2 控制器(controller)
控制器其实也是一个broker,只不过除了一般的broker功能之外,它还负责选举分区首领。
2.1 控制器选举过程

- Broker加入集群
- controller/broker启动时注册其ID到指定路径下/brokers/ids,controller/broker/其他应用可以监听这个路径。broker id必须唯一,否则注册会失败。
- controller/broker/其他应用可以监听路径/brokers/ids,以便在broker加入和退出时,可以得到通知。
- Broker发送心跳请求给ZooKeeper
- 尝试注册为控制器
- broker尝试创建临时节点/controller,如果此节点不存在,它就会成为controller。
- 如果已存在,说明已经存在controller,随即监听这个路径,在原来的controller关闭时可以尝试成为新的controller。
- 如果broker注册称为controller,那么Zookeeper会为其生成一个epoch。
- 每一次产生新的controller都会生成新的更大的epoch,用来防止僵尸controller。
- 其他broker如果收到小于当前控制器的epoch的消息,会直接忽略,因为那是将是控制器发送的。
- 获取分区副本集群的元数据信息。
3 复制(replacate)
数据保存在主题中,每个主题被分成若干个分区,每个分区可以有多个副本。副本保存在broker中。

3.1 首领副本
每个分区都有一个首领副本。所有生产者和消费者请求都会经过这个副本。
3.1.1 首领选举流程

3.2 跟随者副本
首领以外的副本都是跟随者副本。
如果不特别直指定,跟随者副本不处理来自客户端的请求,它们主要从首领哪里复制消息,与首领保持一致。
消费者可以被允许从最近的同步副本而不是首领副本读取数据,以此来降低网络流量成本,也即是机架感知。
需要进行如下配置:
消费者配置:client.rack=usa.zone1
broker配置:broker.rack=usa.zone1, replica.selector.class=apache.kafka.common.replica.RackAwareReplicaSelector
一旦首领发生崩溃,其中一个跟随者就会被提拔为新首领。
首领副本会将“当前高水位标记”发送给跟随者副本,是的跟随者副本知道数据同步延迟有多少。
3.3 同步副本
持续发出获取最新消息的副本称为同步副本。
首领副本需要搞清楚哪些跟随者副本的状态与自己是一致的,因为只有同步副本有资格被选为新首领,只有这样切换首领后才不会导致消息丢失。
如果一个follower一段时间内(replica.lag.time.max.ms默认30秒)没有发送任何fetch请求,或者发送了请求但是没有消费首领最新偏移量的消息,那么首领将将认为这个副本是不同步的。
3.4 首选首领
除了当前首领每个分区都有一个首选首领,即创建主题时选定的首领。因为在创建分区时首领在broker之间的分布时最均衡的。
如果auto.leader.rebalance.enable=true,在首领再均衡的过程中,Kafka会检查首选首领是否是同步的,当前首领是否时首选首领。如果同步,但不是当前首领,就会触发首领选举,让首选首领成为当前首领。
如果用工具查看主题副本,列表中第一个副本一般就是首选首领。
4 处理客户端请求

- 客户端发送请求到指定端口
- 接收线程监听端口,并获取到网络请求
- 交请求交给网络线程处理
- 网络线程将请求放入请求队列
4.1 如果请求需要延迟处理,会将请求放入缓冲区,名为炼狱(purgatory)。例如当以下情况时,请求会被放入炼狱:- 当acks=all时,broker处理生产请求,需等待同步副本完成消息同步。
- 处理消费者请求时,暂时无可用数据。
- 发送DeleteTopic请求的客户端要求删除完成时返回响应。
- IO线程从队列中获取请求
- IO线程读取磁盘文件,获取消息数据
- IO线程将处理结果放入响应队列
- 网络线程获取到处理结果
- 网路线程将响应返回给客户端
4.1 元数据请求
请求中包含了客户端感兴趣的主题清单,响应中返回了主题包含的分区,每个分区都有哪些副本,以及哪个副本是首领。
元数据请求可以发给任意一个broker。
客户端会缓存这些元数据,并在指定时间间隔发送请求刷新缓存。

- 发送生产或消费请求之前,先发送元数据请求到任意一个broker,包含了主题清单
- 返回元数据包含主题包含的分区,每个分区都有哪些副本,以及哪个副本是首领。
- 知道了目标broker,发送请求给broker 0
4.2 生产请求
broker会对请求做如下校验:
- 检查发送数据的用户是否有主题的写入权限
- acks参数是否是有效值:0,1,-1/all
- 如果acks=all,是否有足够多的同步副本?
- 如果有,消息会被写入炼狱(purgatory),等待所有同步副本完成同步,才会返回客户端。
- 如果没有,直接返回错误响应
4.3 获取请求

- 消费者发送请求,获取指定主题,分区,偏移量的请求。消费者只能请求已经复制给同步副本的消息。
- broker会累积足够上限的数据或者达到超时时间才返回给消费者。
请求会话缓存
为了避免消费者每次请求数据都包含整个分区清单,并让broker返回所有元数据,消费者可以创建一个会话,会话中保存了他们正在读取的分区及其元数据信息。消费者每次发送增量请求。 - broker返回数据。
Kafka使用零复制技术向客户端发送消息。Kafka会将数据从文件系统缓存直接发送到网络通道,而不经过任何其他缓存。
技术细节参见附录: link
4.4 其他请求
如数据管理,元数据管理,安全相关的请求。
5 物理存储
Kafka的存储单元时分区,分区无法在broker之间再细分,也无法在broker的多个磁盘间再细分,所以分区大小受单个挂载点可用空间的限制。
5.1 分层存储
在分层存储的架构中,Kafka集群配置了两个存储层:
- 本地存储层
使用broker本地磁盘存储,延迟小,成本高,数据保留时间短 - 远程存储层
使用HDFS,S3等专用存储。延迟大,成本低,可长期保留数据,让Kafka成为一种长期数据保存方案。
5.2 分区的分配
分区分配原则:
- 在broker间平均分布分区副本
- 在broker间平均分布分区首领
- 确保每个分区的副本分布在不同的broker上
- 如果为broker指定了机架信息,那么尽可能把每个分区的副本分配给不同的机架上的broker。
- 新分区总是被放在分区最少的那个磁盘目录,而不看剩余空间。
如下图例子,有3个主题分别用蓝绿黄表示,每个主题包含4个分区,这些分区需要分配给6个broker。下图演示了一种可能的分布方案。

5.3 文件管理
为了避免分区文件过大,将一个分区分成若干个片段(segment)。当前正在写入的片段叫活动片段,活动片段永远不会被删除。
5.4 文件格式
为了能够使用零复制技术,Kafka的磁盘存储和网络传输采用的相同的格式。
从Kafka 0.11和V2版消息格式开始,生产者都是以批次的方式发送消息。
如果不支持V2版消息的消费者消费V2版本的消息,broker会将V2格式转换成v1格式。这样会小号更多的CPU和内存,需尽量避免。
5.5 偏移量索引
Kafka维护了两个索引:
- 偏移量与片段文件以及偏移量在文件中的位置做了映射。
指定偏移量读取消息场景下,broker能更快找到消息。 - 时间戳与消息偏移量做了映射。
指定时间戳搜索消息时能用到这个索引。
5.6 压实(compact)
有一些应用场景,Kafka只需要保留最新的一条数据,而不需要关心数据的变化过程。例如用户的最新地址,应用程序的最新状态等。
可以通过配置主题的保留策略:压实(compact)来满足这些应用场景。压实针对当前活动的片段文件,完成后,相同的键只保留一条最新的消息。
一个片段文件可以分为两部分:
干净部分:经过压实的部分
浑浊部分:上次压实之后写入的部分
5.6.1 相关配置
log.cleaner.enable=true
启用日志清理程序进程以在服务器上运行。如果将任何主题与cleanup.policy=compact一起使用,则应启用该选项,包括内部偏移主题。如果禁用,这些主题将不会被压缩并不断扩大。
log.cleanup.policy=delete
超出保留窗口的段的默认清理策略,可是指定使用逗号分隔的列表,及删除又压实。有效的策略是:“delete”和“compact”
log.cleaner.delete.retention.ms
为日志压缩主题保留逻辑删除消息标记的时间量。如果想删除某个键对应的所有消息,应该怎么做?应用程序发送指定键并且值为null的消息,借助压实,只会保留值为null的消息。这条消息被称为墓碑消息(tombstore message)。而墓碑消息的保留时间就由当前参数指定。
log.cleaner.min.cleanable.ratio=0.5
符合清理条件的日志的脏日志与总日志的最小比率。如果还指定了log.cleaner.max.com.paction.lag.ms或log.clealer.min.com.paction.loag.ms配置,则日志压缩程序认为该日志符合压缩条件,只要:(i)已达到脏比率阈值,并且该日志至少在log.cleaner.min.com.Paction.lag.ms持续时间内具有脏(未压缩)记录,或者(ii)如果日志最多在log.cleaner.max.compation.lag.ms时段内具有脏(未压缩)记录。
log.cleaner.max.compaction.lag.ms
消息在日志中保持未压缩状态的最长时间。
log.cleaner.min.compaction.lag.ms
消息在日志中保持未压缩状态的最短时间。
6 为broker选择硬件
6.1 磁盘
- 吞吐连
- 容量
6.2 内存
可提供更多内存用于系统页面缓存
6.3 网络
至少10G网卡
6.4 CPU
Kafka对计算处理能力的要求相对较低。
需要用到计算处理能力的地方:需要解压客户端消息,检查每条消息的校验并分配偏移量,然后再将其压缩保存至磁盘。
7 云端Kafka
Asure
AWS
8 Kafka集群
8.1 broker的数量
一个aKafka集群需要多少个broker由以下因素决定:
- 磁盘容量
需要多少磁盘容量来保存数据?单个broker的磁盘容量 - 单个broker的复制容量
每个broker的复制系数会导致磁盘容量成倍增长 - CPU
如果有很多客户端连接和请求,可能CPU会称为瓶颈 - 网络
需要关注网络接口流量。
官方建议每个broker的分区副本不超过14000个,每个集群的分区副本不超过100万个。
8.2 操作系统调优
- 虚拟内存
尽量避免内存交换
vm.swappiness=1 除非发生内存溢出,否则不进行从内存交换
vm.dirty_background_ratio=5 脏页站系统内存百分比。 是内存可以填充“脏数据”的百分比。这些“脏数据”在稍后是会写入磁盘的,pdflush/flush/kdmflush这些后台进程会稍后清理脏数据。举一个例子,我有32G内存,那么有3.2G的内存可以待着内存里,超过3.2G的话就会有后来进程来清理它。
vm.dirty_ratio=60到80之间 脏页站系统内存百分比。 是绝对的脏数据限制,内存里的脏数据百分比不能超过这个值。如果脏数据超过这个数量,新的IO请求将会被阻挡,直到脏数据被写进磁盘。这是造成IO卡顿的重要原因,但这也是保证内存中不会存在过量脏数据的保护机制。
vm.mx_map_count=40w到60w vm.max_map_count是一个与内核虚拟内存子系统相关的参数,用于控制进程可以拥有的内存映射区域的最大数量。它通常用于限制一个进程可以打开的文件数量,特别是在使用大量内存映射文件的情况下。
vm.overcommit_momery=0 #vm.overcommit_memory 表示内核在分配内存时候做检查的方式。这个变量可以取到0,1,2三个值。默认值为:0
从内核文档里得知,该参数有三个值,分别是:
0:当用户空间请求更多的的内存时,内核尝试估算出剩余可用的内存。
1:当设这个参数值为1时,内核允许超量使用内存直到用完为止,主要用于科学计算
2:当设这个参数值为2时,内核会使用一个决不过量使用内存的算法,即系统整个内存地址空间不能超过swap+50%的RAM值,50%参数的设定是在overcommit_ratio中设定。 - 磁盘
文件系统:XFS
挂载点:noatime。禁用最后访问时间 - 网络
所有协议的socket缓冲区:
net.core.wmem_default=131,072(128KB)
net.core.rmem_default=131,072(128KB)
net.core.wmem_max=2,097,152(2MB)
net.core.rmem_max=2,097,152(2MB)
TCP协议缓冲区:
net.ipv4.tcp_wmem=4096 65536 2048000(最小值4KB,默认值64KB,最大值2MB)
net.ipv4.tcp_rmem=4096 65536 2048000(最小值4KB,默认值64KB,最大值2MB)
net.ipv4.tcp_window_scaling=1 TCP时间窗口扩展
net.ipv4.tcp_max_syn_backlog=1024(default)
net.core.netdev_max_backlog=1000(default)
9 生产环境
9.1 垃圾回收
G1 GC
export KAFKA_JVM_PERFORMANCE_OPTS=“-server -Xmx6g -Xms6g
-XX:MetaspaceSize=96m -XX:+UseG1GC
-XX:MaxGCPauseMillis=20 -XX: InitiatingHeapOccupancyPercent=35
-XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatto=50
-XX:MaxMetaspaceFreeRatio=80 -XX:+ExplicitGCInvokesConcurrent”
/usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
9.2 数据中心布局
机架感知(rack awareness):broker.rack
broker安装在不同的机架上
9.3 共享Zookeeper
Appendix
零复制技术
内容来源:深入理解零拷贝技术
面临的问题
很多应用程序在面临客户端请求时,可以等价为进行如下的系统调用:
- File.read(file, buf, len);
- Socket.send(socket, buf, len);
例如消息中间件 Kafka 就是这个应用场景,从磁盘中读取一批消息后原封不动地写入网卡(NIC,Network interface controller)进行发送。
在没有任何优化技术使用的背景下,操作系统为此会进行 4 次数据拷贝,以及 4 次上下文切换,如下图所示:

如果没有优化,读取磁盘数据,再通过网卡传输的场景性能比较差:
4 次 copy:
- CPU 负责将数据从磁盘搬运到内核空间的 Page Cache 中;
- CPU 负责将数据从内核空间的 Socket 缓冲区搬运到的网络中;
- CPU 负责将数据从内核空间的 Page Cache 搬运到用户空间的缓冲区;
- CPU 负责将数据从用户空间的缓冲区搬运到内核空间的 Socket 缓冲区中。
4 次上下文切换: - read 系统调用时:用户态切换到内核态;
- read 系统调用完毕:内核态切换回用户态;
- write 系统调用时:用户态切换到内核态;
- write 系统调用完毕:内核态切换回用户态。
我们不免发出抱怨:
- CPU 全程负责内存内的数据拷贝还可以接受,因为效率还算可以接受,但是如果要全程负责内存与磁盘、网络的数据拷贝,这将难以接受,因为磁盘、网卡的速度远小于内存,内存又远远小于 CPU;
- 4 次 copy 太多了,4 次上下文切换也太频繁了。
DMA技术
所以引入了DMA技术,用于释放CPU。
DMA 技术很容易理解,本质上,DMA 技术就是我们在主板上放一块独立的芯片。在进行内存和 I/O 设备的数据传输的时候,我们不再通过 CPU 来控制数据传输,而直接通过 DMA 控制器(DMA Controller,简称 DMAC)。这块芯片,我们可以认为它其实就是一个协处理器(Co-Processor)。
DMAC 最有价值的地方体现在,当我们要传输的数据特别大、速度特别快,或者传输的数据特别小、速度特别慢的时候。
比如说,我们用千兆网卡或者硬盘传输大量数据的时候,如果都用 CPU 来搬运的话,肯定忙不过来,所以可以选择 DMAC。而当数据传输很慢的时候,DMAC 可以等数据到齐了,再发送信号,给到 CPU 去处理,而不是让 CPU 在那里忙等待。
注意,这里面的“协”字。DMAC 是在“协助”CPU,完成对应的数据传输工作。在 DMAC 控制数据传输的过程中,我们还是需要 CPU 的进行控制,但是具体数据的拷贝不再由 CPU 来完成。
原本,计算机所有组件之间的数据拷贝(流动)必须经过 CPU;现在,DMA 代替了 CPU 负责内存与磁盘以及内存与网卡之间的数据搬运,CPU 作为 DMA 的控制者。
但是 DMA 有其局限性,DMA 仅仅能用于设备之间交换数据时进行数据拷贝,但是设备内部的数据拷贝还需要 CPU 进行,例如 CPU 需要负责内核空间数据与用户空间数据之间的拷贝(内存内部的拷贝)
零复制技术
零复制技术是一个思想,指的是指计算机执行操作时,CPU 不需要先将数据从某处内存复制到另一个特定区域。
可见,零复制的特点是 CPU 不全程负责内存中的数据写入其他组件,CPU 仅仅起到管理的作用。但注意,零复制不是不进行拷贝,而是 CPU 不再全程负责数据拷贝时的搬运工作。如果数据本身不在内存中,那么必须先通过某种方式拷贝到内存中(这个过程 CPU 可以不参与),因为数据只有在内存中,才能被转移,才能被 CPU 直接读取计算。
零复制技术的具体实现方式有很多,例如:
- sendfile
一次代替 read/write 系统调用,通过使用 DMA 技术以及传递文件描述符,实现了 zero copy - mmap
仅代替 read 系统调用,将内核空间地址映射为用户空间地址,write 操作直接作用于内核空间。通过 DMA 技术以及地址映射技术,用户空间与内核空间无须数据拷贝,实现了 zero copy - splice
- 直接 Direct I/O
读写操作直接在磁盘上进行,不使用 page cache 机制,通常结合用户空间的用户缓存使用。通过 DMA 技术直接与磁盘/网卡进行数据交互,实现了 zero copy
不同的零复制技术适用于不同的应用场景。
DMA 技术回顾:DMA 负责内存与其他组件之间的数据拷贝,CPU 仅需负责管理,而无需负责全程的数据拷贝;
使用 page cache 的 zero copy:
sendfile:
mmap:
不使用 page cache 的 Direct I/O:
sendfile
snedfile 的应用场景是:用户从磁盘读取一些文件数据后不需要经过任何计算与处理就通过网络传输出去。此场景的典型应用是消息队列。
在传统 I/O 下,正如第一节所示,上述应用场景的一次数据传输需要四次 CPU 全权负责的拷贝与四次上下文切换,正如本文第一节所述。
sendfile 主要使用到了两个技术:
- DMA 技术
- 传递文件描述符代替数据拷贝。
利用 DMA 技术
sendfile 依赖于 DMA 技术,将四次 CPU 全程负责的拷贝与四次上下文切换减少到两次,如下图所示:

利用 DMA 技术减少 2 次 CPU 全程参与的拷贝
DMA 负责磁盘到内核空间中的 Page cache(read buffer)的数据拷贝以及从内核空间中的 socket buffer 到网卡的数据拷贝。
传递文件描述符代替数据拷贝
传递文件描述可以代替数据拷贝,这是由于两个原因:
- page cache 以及 socket buffer 都在内核空间中;
- 数据传输过程前后没有任何写操作。

利用传递文件描述符代替内核中的数据拷贝
注意事项:只有网卡支持 SG-DMA(The Scatter-Gather Direct Memory Access)技术才可以通过传递文件描述符的方式避免内核空间内的一次 CPU 拷贝。这意味着此优化取决于 Linux 系统的物理网卡是否支持(Linux 在内核 2.4 版本里引入了 DMA 的 scatter/gather – 分散/收集功能,只要确保 Linux 版本高于 2.4 即可)。
一次系统调用代替两次系统调用
由于 sendfile 仅仅对应一次系统调用,而传统文件操作则需要使用 read 以及 write 两个系统调用。
正因为如此,sendfile 能够将用户态与内核态之间的上下文切换从 4 次讲到 2 次。

sendfile 系统调用仅仅需要两次上下文切换
另一方面,我们需要注意 sendfile 系统调用的局限性。如果应用程序需要对从磁盘读取的数据进行写操作,例如解密或加密,那么 sendfile 系统调用就完全没法用。这是因为用户线程根本就不能够通过 sendfile 系统调用得到传输的数据。
相关文章:
Kafka(四)Broker
目录 1 配置Broker1.1 Broker的配置broker.id0listererszookeeper.connectlog.dirslog.dir/tmp/kafka-logsnum.recovery.threads.per.data.dir1auto.create.topics.enabletrueauto.leader.rebalance.enabletrue, leader.imbalance.check.interval.seconds300, leader.imbalance…...

代码随想录第五十二天——最长递增子序列,最长连续递增序列,最长重复子数组
leetcode 300. 最长递增子序列 题目链接:最长递增子序列 dp数组及下标的含义 dp[i]表示i之前包括i的以nums[i]结尾的最长递增子序列的长度递推公式 位置i的最长升序子序列等于j从0到i-1各个位置的最长升序子序列 1 的最大值 所以if (nums[i] > nums[j]) dp[i]…...
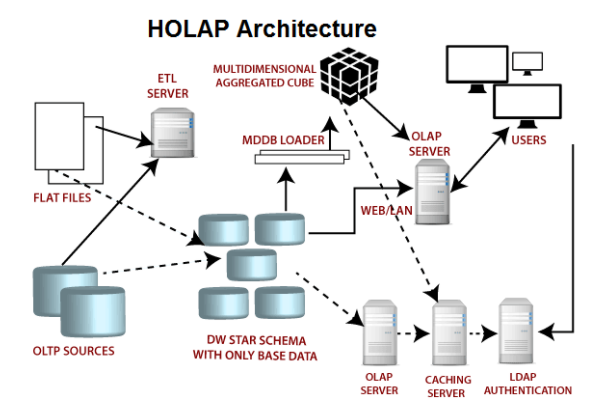
【大数据架构】OLAP实时分析引擎选型
OLAP引擎面临的挑战 常见OLAP引擎对比 OLAP分析场景中,一般认为QPS达到1000就算高并发,而不是像电商、抢红包等业务场景中,10W以上才算高并发,毕竟数据分析场景,数据海量,计算复杂,QPS能够达到1…...
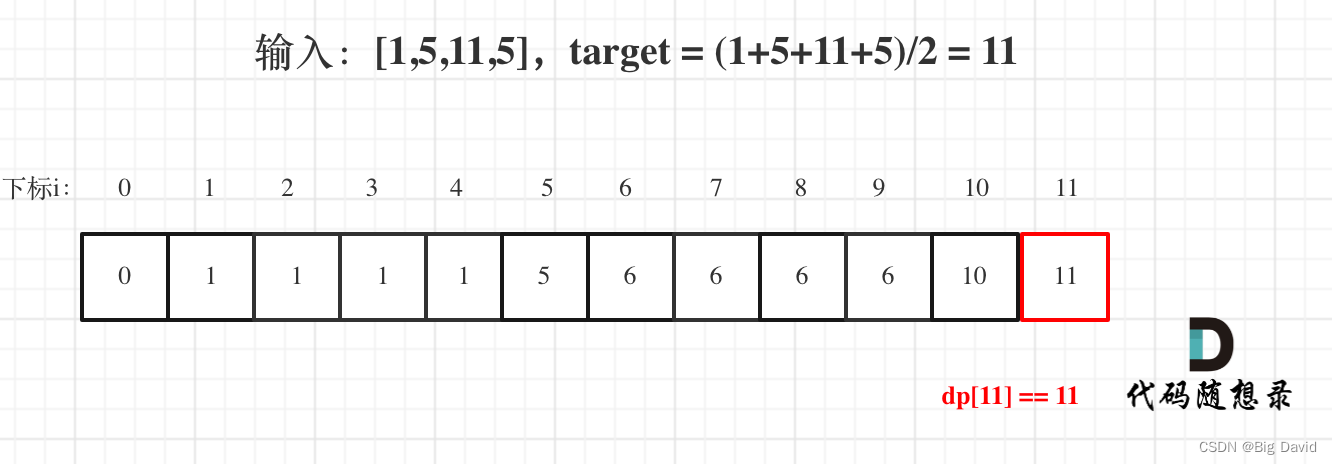
代码随想录刷题题Day29
刷题的第二十九天,希望自己能够不断坚持下去,迎来蜕变。😀😀😀 刷题语言:C Day29 任务 ● 01背包问题,你该了解这些! ● 01背包问题,你该了解这些! 滚动数组 …...
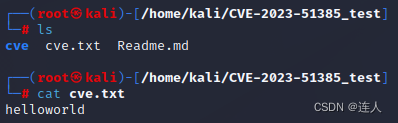
CVE-2023-51385 OpenSSH ProxyCommand命令注入漏洞
一、背景介绍 ProxyCommand 是 OpenSSH ssh_config 文件中的一个配置选项,它允许通过代理服务器建立 SSH 连接,从而在没有直接网络访问权限的情况下访问目标服务器。这对于需要经过跳板机、堡垒机或代理服务器才能访问的目标主机非常有用。 二、漏洞简…...

如何寻找到相对完整的真正的游戏的源码 用来学习?
在游戏开发的学习之路上,理论与实践是并重的两个方面。对于许多热衷于游戏开发的学习者来说,能够接触到真实的、完整的游戏源码无疑是一个极好的学习机会。但问题来了:我们该如何寻找到这些珍贵的资源呢? 开源游戏项目 GitHub:地…...
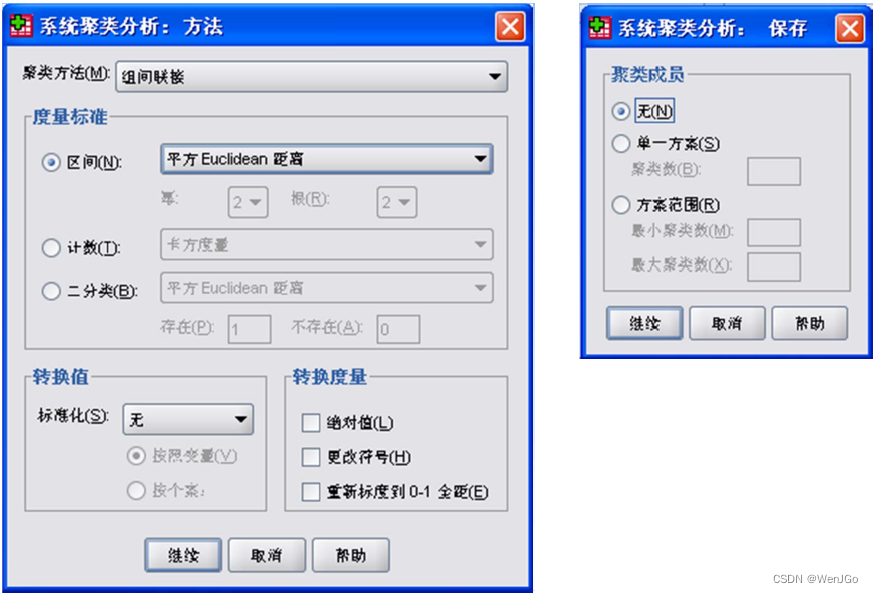
数模学习day11-系统聚类法
本文参考辽宁石油化工大学于晶贤教授的演示文档聚类分析之系统聚类法及其SPSS实现。 目录 1.样品与样品间的距离 2.指标和指标间的“距离” 相关系数 夹角余弦 3.类与类间的距离 (1)类间距离 (2)类间距离定义方式 1.最短…...

SpringBoot+Redis实现接口防刷功能
场景描述: 在实际开发中,当前端请求后台时,如果后端处理比较慢,但是用户是不知情的,此时后端仍在处理,但是前端用户以为没点到,那么再次点击又发起请求,就会导致在短时间内有很多请求…...

TensorRT加速推理入门-1:Pytorch转ONNX
这篇文章,用于记录将TransReID的pytorch模型转换为onnx的学习过程,期间参考和学习了许多大佬编写的博客,在参考文章这一章节中都已列出,非常感谢。 1. 在pytorch下使用ONNX主要步骤 1.1. 环境准备 安装onnxruntime包 安装教程可…...

springboot常用扩展点
当涉及到Spring Boot的扩展和自定义时,Spring Boot提供了一些扩展点,使开发人员可以根据自己的需求轻松地扩展和定制Spring Boot的行为。本篇博客将介绍几个常用的Spring Boot扩展点,并提供相应的代码示例。 1. 自定义Starter(面试常问) Sp…...
19道ElasticSearch面试题(很全)
点击下载《19道ElasticSearch面试题(很全)》 1. elasticsearch的一些调优手段 1、设计阶段调优 (1)根据业务增量需求,采取基于日期模板创建索引,通过 roll over API 滚动索引; (…...

向爬虫而生---Redis 拓宽篇3 <GEO模块>
前言: 继上一章: 向爬虫而生---Redis 拓宽篇2 <Pub/Sub发布订阅>-CSDN博客 这一章的用处其实不是特别大,主要是针对一些地图和距离业务的;就是Redis的GEO模块。 GEO模块是Redis提供的一种高效的地理位置数据管理方案,它允许我们存储和查询…...

Vue项目里实现json对象转formData数据
平常调用后端接口传参都是json对象,当提交表单遇到有附件需要传递时,通常是把附件上传单独做个接口,也有遇到后端让提交接口一并把附件传递到后端,这种情况需要把参数转成formData的数据,需要用到new FormData()。json…...

leetcode刷题记录
栈 2696. 删除子串后的字符串最小长度 哈希表 1. 两数之和 用map来保存每个数和他的索引 383. 赎金信 用map来存储字符的个数 链表 2. 两数相加 指针的移动 动态规划 53. 最大子数组和 2707. 字符串中的额外字符 递归 101. 对称二叉树 数学 1276. 不浪费原料的汉堡…...
SpringMVC通用后台管理系统源码
整体的SSM后台管理框架功能已经初具雏形,前端界面风格采用了结构简单、 性能优良、页面美观大的Layui页面展示框架 数据库支持了SQLserver,只需修改配置文件即可实现数据库之间的转换。 系统工具中加入了定时任务管理和cron生成器,轻松实现系统调度问…...

深度解析Dubbo的基本应用与高级应用:负载均衡、服务超时、集群容错、服务降级、本地存根、本地伪装、参数回调等关键技术详解
负载均衡 官网地址: http://dubbo.apache.org/zh/docs/v2.7/user/examples/loadbalance/ 如果在消费端和服务端都配置了负载均衡策略, 以消费端为准。 这其中比较难理解的就是最少活跃调用数是如何进行统计的? 讲道理, 最少活跃数…...

备战2024美赛数学建模,文末获取历史优秀论文
总说(历年美赛优秀论文可获取) 数模的题型千变万化,我今天想讲的主要是一些「画图」、「建模」、「写作」和「论文结构」的思路,这些往往是美赛阅卷官最看重的点,突破了这些点,才能真正让你的美赛论文更上…...
)
Java加密解密大全(MD5、RSA)
目录 一、MD5加密二、RSA加解密(公加私解,私加公解)三、RSA私钥加密四、RSA私钥加密PKCS1Padding模式 一、MD5加密 密文形式:5eb63bbbe01eeed093cb22bb8f5acdc3 import java.math.BigInteger; import java.security.MessageDigest; import java.security…...
)
C语言程序设计考试掌握这些题妥妥拿绩点(写给即将C语言考试的小猿猴们)
目录 开篇说两句1. 水仙花数题目描述分析代码示例 2. 斐波那契数列题目描述分析代码示例 3. 猴子吃桃问题题目描述分析代码示例 4. 物体自由落地题目描述分析代码示例 5. 矩阵对角线元素之和题目描述分析代码示例 6. 求素数题目描述分析代码示例 7. 最大公约数和最小公倍数题目…...
编译ZLMediaKit(win10+msvc2019_x64)
前言 因工作需要,需要ZLMediaKit,为方便抓包分析,最好在windows系统上测试,但使用自己编译的第三方库一直出问题,无法编译通过。本文档记录下win10上的编译过程,供有需要的小伙伴使用 一、需要安装的软件…...

CoPaw:让AI代码助手深度适配个人项目与团队规范的工程化实践
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫CoPaw,作者是 alexgzx。光看名字可能有点摸不着头脑,但如果你对 AI 辅助编程、代码生成或者想提升自己的开发效率感兴趣,那这个项目绝对值得你花时间研究一下。简单来说…...
)
别再乱装CUDA了!用Anaconda为你的3060 Ti一键搞定PyTorch GPU环境(含CUDA 11.3实战)
3060 Ti显卡玩家的PyTorch环境配置指南:用Anaconda避开CUDA版本地狱 在深度学习领域,GPU加速已经成为提升模型训练效率的标配。然而,对于许多刚入门的开发者来说,配置PyTorch的GPU支持往往成为第一道门槛——尤其是当涉及到CUDA版…...

3大突破性功能:如何用QtScrcpy彻底改变你的Android投屏体验
3大突破性功能:如何用QtScrcpy彻底改变你的Android投屏体验 【免费下载链接】QtScrcpy Android real-time display control software 项目地址: https://gitcode.com/GitHub_Trending/qt/QtScrcpy 你是否曾经为了在电脑上操作手机而烦恼?无论是游…...

暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手
暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款专为暗黑破坏神3玩…...

2019 年旧作升级!用木材与电路打造更美观的电压表时钟
2019 年旧作升级!用木材与电路打造更美观的电压表时钟早在 2019 年,作者制作了一个简单的电压表时钟,这类时钟使用模拟面板电压表来显示时间,而非传统钟面。不过,网上大多数此类设计过于复杂且不太美观,于是…...

WandEnhancer技术解密:如何通过本地化增强重新定义游戏修改体验
WandEnhancer技术解密:如何通过本地化增强重新定义游戏修改体验 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 你是否曾经面对游戏修改工具…...

如何3秒破解百度网盘提取码难题:开源工具baidupankey的技术解析与实战指南
如何3秒破解百度网盘提取码难题:开源工具baidupankey的技术解析与实战指南 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 你是否曾在寻找百度网盘资源时,被一个小小的提取码卡住,不得不花费…...

Qdrant客户端库实战:从向量数据库连接到生产级应用开发
1. 项目概述:从向量数据库到应用落地的桥梁如果你最近在折腾大模型应用,或者想给自己的产品加上一个“智能大脑”,那你大概率绕不开一个词:向量数据库。简单来说,它就像一个能理解“意思”的超级搜索引擎,不…...

去中心化AI市场BloomBee:技术架构、挑战与开发者实践指南
1. 项目概述:当AI遇见去中心化,BloomBee想解决什么?最近在AI和Web3的交叉领域,一个名为BloomBee的项目引起了我的注意。它的名字很有意思,“Bloom”是开花、繁荣的意思,“Bee”是蜜蜂,合起来像是…...

基于IMAP的邮件自动化处理工具mymailclaw配置与实战指南
1. 项目概述:一个轻量级的邮件抓取与处理工具最近在折腾一个需要自动化处理邮件通知的小项目,发现市面上的方案要么太重,要么不够灵活。直到我遇到了psandis/mymailclaw这个项目,它就像一把小巧而锋利的瑞士军刀,专门用…...