日志系统一(elasticsearch+filebeat+logstash+kibana)
目录
一、es集群部署
安装java环境
部署es集群
安装IK分词器插件
二、filebeat安装(docker方式)
三、logstash部署
四、kibana部署
背景:因业务需求需要将nginx、java、ingress日志进行收集。
架构:filebeat+logstash+es+kibana
服务器规划:
192.168.7.250(es)
192.168.6.216(filebeat,es)
192.168.7.191(logstash,es)
一、es集群部署
安装java环境
官网:(Java Archive Downloads - Java SE 8u211 and later)
以下载jdk-8u391-linux-x64.tar.gz为例,并上传至服务器
mkdir -p /usr/local/java
tar xf jdk-8u391-linux-x64.tar.gz -C /usr/local/java/#在/etc/profile中添加以下内容
export JAVA_HOME=/usr/local/java/jdk1.8.0_391
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH#立即生效
source /etc/profile通过打印Java 版本验证 Java 安装校验:
java -version
部署es集群
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchtee /etc/yum.repos.d/elasticsearch.repo <<-'EOF'
[elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF使用YUM源进行安装
yum install -y elasticsearch-7.17.6修改配置文件:(/etc/elasticsearch/elasticsearch.yml)
#集群名称,三台节点必须一样
cluster.name: elasticsearch
#节点名称,三台节点必须都不一样
node.name: master
#是否有资格被选举为主节点
node.master: true
#是否存储索引数据
node.data: true
#数据存储位置
path.data: /elk/elasticsearch
#日志存储位置
path.logs: /var/log/elasticsearch
#设置绑定的ip,也是与其他节点交互的ip
network.host: 192.168.6.242
#http访问端口
http.port: 9200
#节点之间交互的端口号
transport.tcp.port: 9300
#是否支持跨域
http.cors.enabled: true
#当设置允许跨域,默认为*,表示支持所有域名
http.cors.allow-origin: "*"
#集群中master节点的初始列表
discovery.zen.ping.unicast.hosts: ["192.168.6.242:9300","192.168.6.170:9300","192.168.7.167:9300"]
#设置几台符合主节点条件的节点为主节点以初始化集群(低版本不适用此配置项,es默认会把第一个加入集群的服务器设置为master)
cluster.initial_master_nodes: ["master"]
discovery.zen.minimum_master_nodes: 2 # 为了避免脑裂,集群节点数最少为 半数+1
将/etc/elasticsearch/elasticsearch.yml拷贝至另外两台节点,并修改node.name、network.host、discovery.zen.ping.unicast.hosts参数,path.data及path.logs可自定义数据和日志存储位置
安装IK分词器插件
由于elastic官方未提供ik分词插件,需下载插件进行安装。(适配es7.17.6版本)
链接:https://pan.baidu.com/s/1_RGAzctJk17yJjHOb4OEJw?pwd=to96
提取码:to96
/usr/share/elasticsearch/bin/elasticsearch-plugin install file:///root/elasticsearch-analysis-ik-7.17.6.zip将elasticsearch加入开机自启动,并立即启动。
systemctl enable elasticsearch.service --now查看elasticsearch运行情况
curl -X GET "localhost:9200/"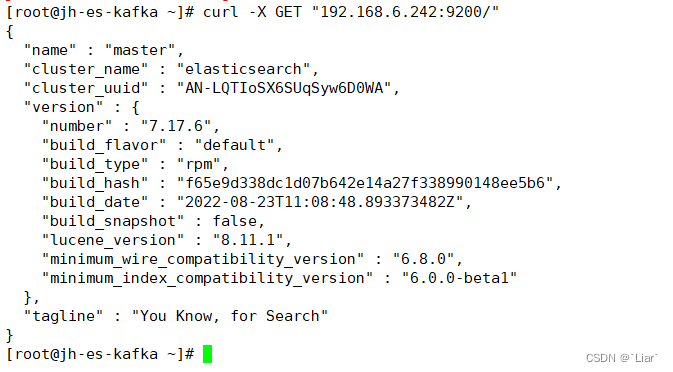
二、filebeat安装(docker方式)
cat /elk/filebeat/filebeat.ymlfilebeat.inputs:
- type: logenabled: truepaths:- /elk-log/*/access.*.log- /elk-log/*/error.*.logscan_frequency: 10sexclude_files: /elk-log/es-elk/*tail_files: truefields:index_name: "tomcat_log"
- type: logenabled: truepaths:- /elk-log/*/*.logexclude_files: ['/access.*', '/error.*', '/elk-log/es-elk/*']fields:tag_name: "java_log"
output.logstash:hosts: ["192.168.7.191:5044"]enabled: true# filebeat 部署
docker run -d -it \--name filebeat \--restart=always \--network host \-e TZ=Asia/Shanghai \-v /etc/localtime:/etc/localtime \-v /elk-log/:/elk-log/ \-v /elk/filebeat/data/:/usr/share/filebeat/data/ \-v /elk/filebeat/logs/:/usr/share/filebeat/logs/ \-v /elk/filebeat/filebeat.yml:/usr/share/filebeat/filebeat.yml \-v /var/lib/docker/containers:/var/lib/docker/containers:ro \-v /var/run/docker.sock:/var/run/docker.sock:ro \docker.elastic.co/beats/filebeat:7.17.10三、logstash部署
sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
vim /etc/yum.repos.d/logstash.repo
[logstash-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
yum install -y logstash目录结构:
数据目录:/usr/share/logstash/
配置目录:/etc/logstash/
日志目录:/var/log/logstash/
logstash.yml #配置Logstash的yml
pipelines.yml #包含在单个Logstash实例中运行多个管道的框架和说明
cat /etc/logstash/conf.d/tomcat-java.conf
input {beats {port => "5044" #收集主机5044端口}
}
filter {if [fields][index_name] == "tomcat_log" { #判断是否是tomcat_log标签进行执行以下操作json {source => "message"}}else if [fields][tag_name] == "java_log" { #判断是否是java_log标签进行执行以下操作grok {patterns_dir => ["/etc/logstash/patterns"] #引用自定义gork规则文件match => { "message" => "%{JAVA_TIME:javatime}"} #将message中的匹配JAVA_TIME规则的字段拿出来定义未javatime}date {match => ["javatime","HH:mm:ss.SSS"] #重新定义时间格式target => "java_time"}}
}
output {if [fields][index_name] == "tomcat_log" {elasticsearch {hosts => ["192.168.7.250:9200","192.168.6.216:9200","192.168.7.191:9200"]index => "tomcat-log-%{+YYYY.MM.dd}"}}if [fields][tag_name] == "java_log" {elasticsearch {hosts => ["192.168.7.250:9200","192.168.6.216:9200","192.168.7.191:9200"]index => "java-log-%{+YYYY.MM.dd}"}}
}四、kibana部署
下载地址:Download Kibana Free | Get Started Now | Elastic
#解压kibana软件包,可使用-C自定义解压路径
tar xf kibana-7.17.6-linux-x86_64.tar.gz
cd kibana-7.17.6-linux-x86_64/config
vim kibana.yml# Kibana 访问地址
server.host: 0.0.0.0
# elasticsearch集群列表
elasticsearch.hosts: ["http://***:9200","http://***:9200","http://***:9200"]#后台启动
nohup ./bin/kibana --allow-root &相关文章:
日志系统一(elasticsearch+filebeat+logstash+kibana)
目录 一、es集群部署 安装java环境 部署es集群 安装IK分词器插件 二、filebeat安装(docker方式) 三、logstash部署 四、kibana部署 背景:因业务需求需要将nginx、java、ingress日志进行收集。 架构:filebeatlogstasheskib…...

游戏版 ChatGPT,要用 AI 角色完善生成工具实现 NPC 自由
微软与 AI 初创公司 Inworld 合作,推出基于 AI 的角色引擎和 Copilot 助理,旨在提升游戏中 NPC 的交互力和生命力,提升游戏体验。Inworld 致力于打造拥有灵魂的 NPC,通过生成式 AI 驱动 NPC 行为,使其动态响应玩家操作…...
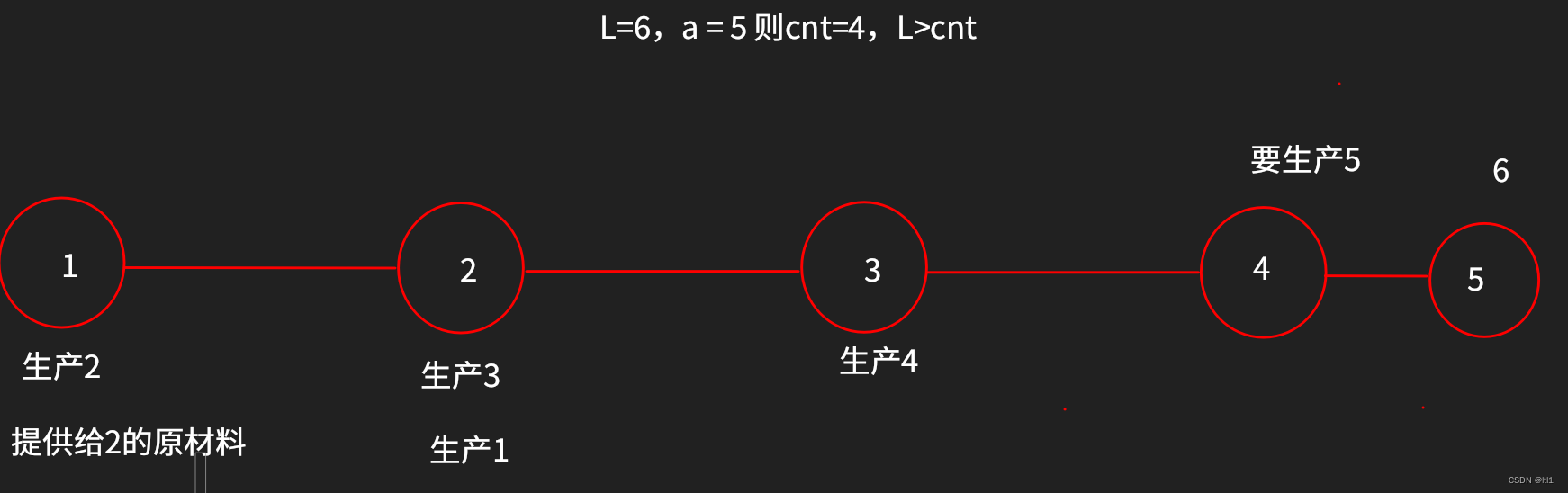
加工零件的题解
目录 原题描述: 题目描述 输入格式 输出格式 样例 #1 样例输入 #1 样例输出 #1 样例 #2 样例输入 #2 样例输出 #2 提示 题目大意: 主要思路: 但是我们怎么才能判断出x走到1时L是偶数还是奇数呢? 初始化:…...
走进shell
Linux系统启动时,会自动创建多个虚拟控制台。虚拟控制台是运行在Linux系统内存中的终端会话。 打开Linux控制台Terminal使用tty命令查看当前使用的虚拟控制台。 注:tty 表示电传打字机(teletypewriter) $ tty /dev/pts/0表示当前使用的是/dev/pts/0 虚拟…...
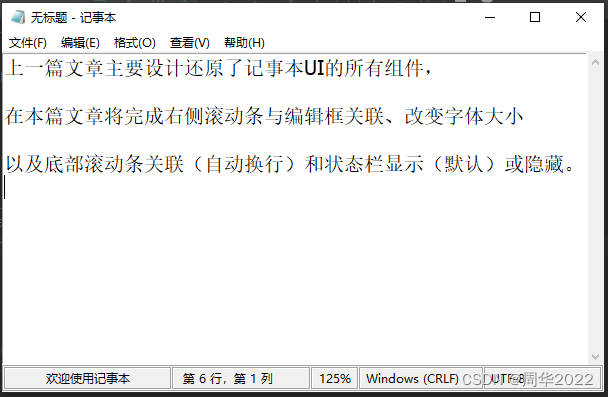
【Python】使用tkinter设计开发Windows桌面程序记事本(2)
上一篇:【Python】使用tkinter设计开发Windows桌面程序记事本(1)-CSDN博客 下一篇: 作者发炎 此代码模块是继承上一篇文章的代码模块的基础上开始设计开发的。 如果不知道怎么新建"记事本项目"文件夹,请参…...
Flutter DateTime 常用处理
今天介绍一下 DateTime 的一些常用功能,对其进行一个整理。 最近在开发过程中好多时候都会使用到时间方面的方法,心想还是统一处理一下,封装一个管理类,这个类可以满足我们开发过程中常用的时间方法。 今天正好整理了一下&#…...

【uniapp】APP打包上架应用商-注意事项
初雪云-uniapp启动图自定义生成(支持一键生成storyboard) HBuilderX需要的自定义storyboard文件格式为 " zip压缩包 " 一、“Android” — 设置targetSdkVersion 小米、OPPO、vivo、华为等主流应用商店,将于2023年12月采用 targetS…...

【算法题】43. 字符串相乘
题目 给定两个以字符串形式表示的非负整数 num1 和 num2,返回 num1 和 num2 的乘积,它们的乘积也表示为字符串形式。 注意:不能使用任何内置的 BigInteger 库或直接将输入转换为整数。 示例 1: 输入: num1 "2", num2 "3…...
CH341 SPI方式烧录BK7231U
CH341是一个USB总线的转接芯片,通过USB总线提供异步串口、打印口、并口以及常用的2线和4线等同步串行接口。 BK7231U Wi-Fi SOC芯片,内嵌处理器。1. 符合802.11b/g/n 1x1协议 2. 17dBm 输出功率3. 支持20/40 MHz带宽和STBC 4. 支持Wi-Fi STA、AP、…...

sd-webui-EasyPhoto win 安装笔记
目录 安装教程: 插件介绍 ControlNet 1.1 Tile: launch.py问题 依赖库 webui安装问题...

gradient_checkpointing
点评:本质是减少内存消耗的一种方式,以时间或者计算换内存 gradient_checkpointing(梯度检查点)是一种用于减少深度学习模型中内存消耗的技术。在训练深度神经网络时,反向传播算法需要在前向传播和反向传播之间存储中间计算结果,以便计算梯度并更新模型参数。这些中间结…...

回溯算法part05 算法
回溯算法part05 算法 今日任务 491.递增子序列46.全排列47.全排列 II 1.LeetCode 491.递增子序列 https://leetcode.cn/problems/non-decreasing-subsequences/description/ class Solution {List<List<Integer>> resultnew ArrayList<>();List<Inte…...

阿里云系统盘测评ESSD、SSD和高效云盘IOPS、吞吐量性能参数表
阿里云服务器系统盘或数据盘支持多种云盘类型,如高效云盘、ESSD Entry云盘、SSD云盘、ESSD云盘、ESSD PL-X云盘及ESSD AutoPL云盘等,阿里云百科aliyunbaike.com详细介绍不同云盘说明及单盘容量、最大/最小IOPS、最大/最小吞吐量、单路随机写平均时延等性…...
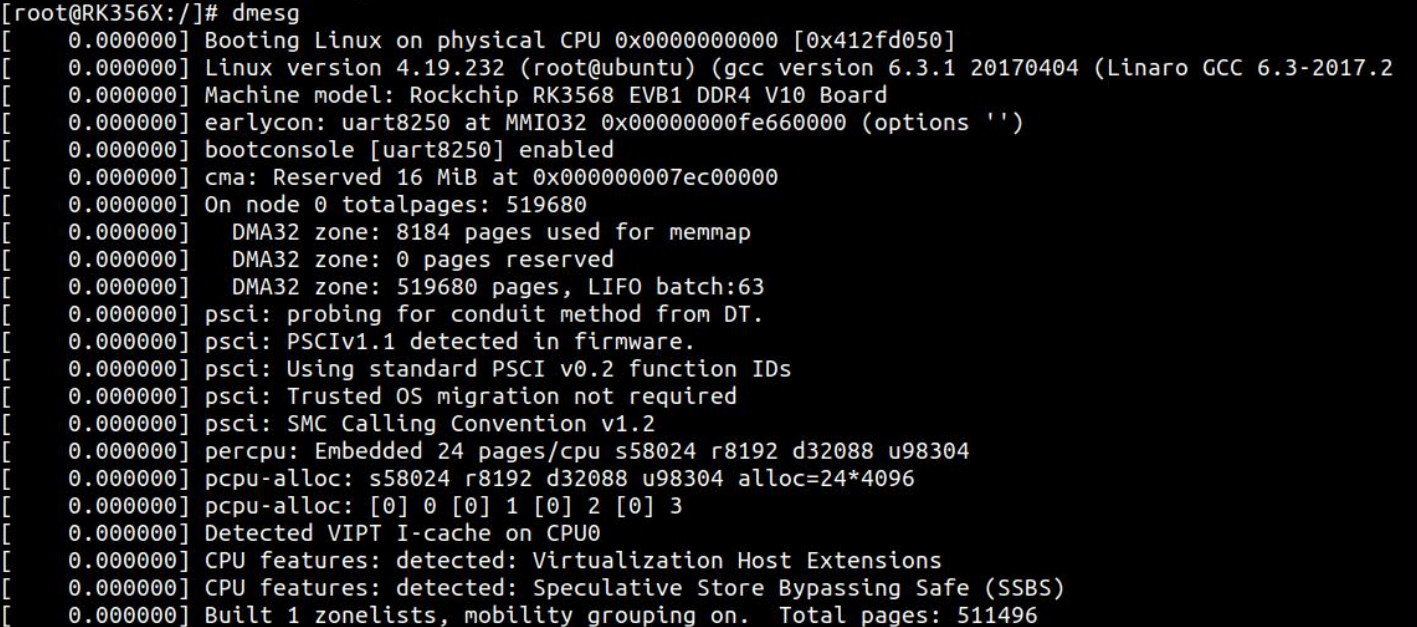
RK3568平台开发系列讲解(Linux系统篇)Linux 内核打印
🚀返回总目录 文章目录 一、方法一:dmseg 命令二、方法二:查看 kmsg 文件三、方法三:调整内核打印等级一、方法一:dmseg 命令 在终端使用 dmseg 命令可以获取内核打印信息,该命令的具体使用方法如下所示: 首先在串口终端使用 “dmseg”命令,可以看见相应的内核打印信息…...

迁移学习的最新进展和挑战
随着深度学习和人工智能技术的飞速发展,迁移学习作为一种有效的机器学习方法,已经在各个领域取得了显著的成果。迁移学习是指将一个领域(源领域)的知识应用到另一个领域(目标领域),以提高目标领…...

Python基础(二十二、自定义模块和包)
文章目录 一、自定义模块1.如何自定义模块并导入?2.__main__变量的功能3.注意事项 二、自定义包1.什么是Python的包?2.__init __.py文件的作用?3.__all__变量的作用?4.示例 三、自定义模块和自定义包的好处 一、自定义模块 1.如何自定义模块并导入? 在Python代码文件中正…...

C#-数组
数组 (array) 是一种包含若干变量的数据结构,这些变量都可以通过计算索引进行访问。数组中包含的变量(又称数组的元素)具有相同的类型,该类型称为数组的元素类型。 数组类型为引用类型,因此数组变量的声明只是为数组实…...

机器学习周刊第二期:300个机器学习应用案例集
大家好 前文:机器学习项目精选 第一期 继续分享我最近看过并觉得非常硬核的资源,包括Python、机器学习、深度学习、大模型等等。 1、Python编程挑战 地址:https://github.com/Asabeneh/30-Days-Of-Python 30天Python编程挑战是一个逐步学…...

【华为OD机试真题2023CD卷 JAVAJS】中文分词模拟器
华为OD2023(C&D卷)机试题库全覆盖,刷题指南点这里 中文分词模拟器 知识点图字符串 时间限制:5s 空间限制:256MB 限定语言:不限 题目描述: 给定一个连续不包含空格字符串,该字符串仅包含英文小写字母及英文文标点符号(逗号、分号、句号),同时给定词库,对该字符串进…...
检测)
基于YOLOv8-pose的画笔关键点(bic_markers)检测
💡💡💡本文解决什么问题:教会你如何用自己的数据集训练Yolov8-pose关键点检测 Yolov8-Pose关键点检测专栏介绍:https://blog.csdn.net/m0_63774211/category_12398833.html ✨✨✨手把手教你从数据标记到生成适合Yolov8-pose的yolo数据集;...

观察 Taotoken 在多地域请求下的延迟与稳定性表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察 Taotoken 在多地域请求下的延迟与稳定性表现 对于依赖大模型 API 进行开发的团队而言,服务的延迟与稳定性是影响开…...
实战:从零部署企业级WEB前后端项目)
TongWEB(东方通)实战:从零部署企业级WEB前后端项目
1. 环境准备:银河麒麟系统下的基础搭建 在银河麒麟桌面系统V10(SP1)兆芯版上部署企业级WEB项目,环境准备是第一步。我遇到过不少开发者直接跳过环境检查就急着部署,结果浪费大量时间排查兼容性问题。这里分享几个关键点: 首先是系…...

FanControl终极指南:免费开源的风扇控制神器,轻松解决Windows散热与噪音问题
FanControl终极指南:免费开源的风扇控制神器,轻松解决Windows散热与噪音问题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https:…...

高效跨平台游戏模组下载:WorkshopDL完全指南
高效跨平台游戏模组下载:WorkshopDL完全指南 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 你是否在Epic Games Store、GOG或其他非Steam平台购买了游戏࿰…...

Redis增强工具包:封装分布式锁、缓存模板与监控的最佳实践
1. 项目概述:一个Redis开发者的“瑞士军刀”在分布式系统和高并发场景下,Redis几乎成了标配。但用久了你会发现,官方客户端虽然稳定,但在日常开发、调试、运维中,总有些“不够顺手”的地方。比如,想批量按模…...

基于PIR传感器与LIFX智能灯泡的物联网运动感应照明系统实战
1. 项目概述与核心价值如果你对智能家居自动化感兴趣,并且想亲手打造一个既实用又有趣的照明项目,那么这个基于Adafruit FunHouse和LIFX智能灯泡的运动感应照明系统,绝对是一个绝佳的起点。它不仅仅是一个“开灯关灯”的简单触发器࿰…...

3步掌握yfinance:从金融数据获取到智能分析的完整指南
3步掌握yfinance:从金融数据获取到智能分析的完整指南 【免费下载链接】yfinance Download market data from Yahoo! Finances API 项目地址: https://gitcode.com/GitHub_Trending/yf/yfinance yfinance是一个强大的Python库,能够轻松从Yahoo! F…...

XHS-Downloader:小红书内容采集与管理的全栈解决方案
XHS-Downloader:小红书内容采集与管理的全栈解决方案 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&…...

Godot游戏集成Discord状态:RPC插件原理与实战指南
1. 项目概述:在Godot引擎中点亮你的Discord状态 如果你是一名独立游戏开发者,或者正在用Godot引擎捣鼓一些有趣的个人项目,你可能会想让你的朋友或社区成员知道你现在正在“玩”什么。不是通过截图发到社交媒体,而是更实时、更优…...

Arm Iris调试接口:架构设计与工程实践详解
1. Iris调试与追踪接口深度解析调试与追踪技术是嵌入式系统开发的核心支柱,而Arm的Iris接口代表了这一领域的最新进展。作为一名长期从事嵌入式调试工具开发的工程师,我将带您深入剖析这套接口的设计哲学与实战应用。1.1 接口架构设计理念Iris的架构设计…...