数据结构和算法学习
文章目录
- 精通一个领域
- 切题四件套
- 算法
- 算法的五个条件
- 流程图
- 数据结构
- 数据与信息
- 数据
- 信息
- 数据结构和算法
- 数据结构
- 算法
- 时间复杂度
- 空间复杂度
- 数组 Array
- 优点
- 缺点
- 数组和链表的区别
- 时间复杂度
- 链表 Linked List
- 优点
- 缺点
- 时间复杂度
- 单向链表
- 双向链表
- 循环链表
- 双向循环链表
- 堆栈 Stack
- 队列 Queue
- 优先队列 Priority Queue
- 哈希表 Hash Table
- 哈希函数设计原则
- 树、⼆叉树
- ⼆叉搜索树
- 二叉树遍历
- 常见算法:
- 递归 Recursion [rɪˈkɜːrʒn]
- 分治 Divde & Conquer [ˈkɑːŋkər]
- 迭代法
- 枚举法
- 回溯法
- 贪⼼算法(Greedy Algorithms)
- 广度优先搜索(Breadth-First-Search)
- 深度优先搜索(Depth-First-Search)
- 剪枝
- ⼆分查找(Binary Search)
- 字典树(Trie)
- 位运算的运⽤(Bitwise operations)
- 动态规划(Dynamic Programming)
- 图
- 无向图
- 有向图
- 加权图
精通一个领域
-
Chunk it up(切碎知识点)
- 庖丁解⽜
- 脉络连接
-
Deliberate practicing(刻意练习)
- 刻意练习
- 练习缺陷、不舒服、弱点地⽅
- 不爽、枯燥
-
Feedback(获得反馈)
- 即时反馈
- 主动型反馈(⾃己去找)
- ⾼手代码 (GitHub, LeetCode, etc.)
- 第一视角直播
- 被动式反馈(高手给你指点)
- code review
- 教练看你打,给你反馈
切题四件套
- Clarification [ˌklærəfɪˈkeɪʃn] 阐明
- Possible solutions
- compare(time/space)
- optimal(加强)
- Coding(多写)
- Test cases
算法
为了解决某项工作或某个问题,所需要有限数量的机械性或重复性指令与计算步骤。
算法的五个条件
- 输入:0个或多个输入数据,这些输入必须有清楚的描述或定义。
- 输出:至少有一个输出结果,不可以没有输出结果。
- 明确性:每一个指令或步骤必须是简洁明确的。
- 有限性:在有限步骤后一定会结束,不会产生无限循环。
- 有效性:步骤清楚且可行,能让用户用纸笔计算而求出答案。
流程图
是一种通用的以图形符号来表示程序执行流程的工具,也是常用描述算法的工具。
数据结构
主要是表示数据在计算机内存中所存储的位置及其模式:
基本数据类型
不能以其他类型来定义的数据类型,或称为标量数据类型:
整数、浮点、布尔数据类型和字符类型等
结构化数据类型
也称为虚拟数据类型:字符串、数组、指针、列表、文件等。
抽象数据类型
我们可以将一种数据类型看成是一种值的集合,以及在这些值上所进行的运算及其所代表的属性所成的集合。是指一个数学模型以及定义在此数学模型上的一组数学运算或操作。
表示的是一种“信息隐藏”的程序设计思想以及信息之间某一种特定的关系模式。
数据结构可通过程序设计语言所提供的数据类型、引用及其他操作加以实现。
程序能否快速而高效地完成预定的任务取决于是否选对了数据结构;
程序是否能清楚而正确地把问题解决取决于算法;
数据结构 + 算法 = 高效的可执行程序
数据与信息
数据
指的是一种未经处理的原始文字、数字、符号或图形等:
- 数值数据
- 字符数据
信息
利用大量的数据,经过有系统的整理、分析、筛选处理而提炼出来的,而且具有参考价格以及提供决策依据的文字、数字、符号或图表。
数据结构和算法
- 学习它的“来历”;
- 自身的特点;
- 适合解决的问题;
- 实际的应用场景
要多辩证地思考,多问为什么(主动)
内功、性能方面的问题(时间复杂度、空间复杂度)
学习数据结构最难的不是理解和掌握原理,而是能灵活地将各种场景和问题抽象成对应的数据结构和算法。
数据结构
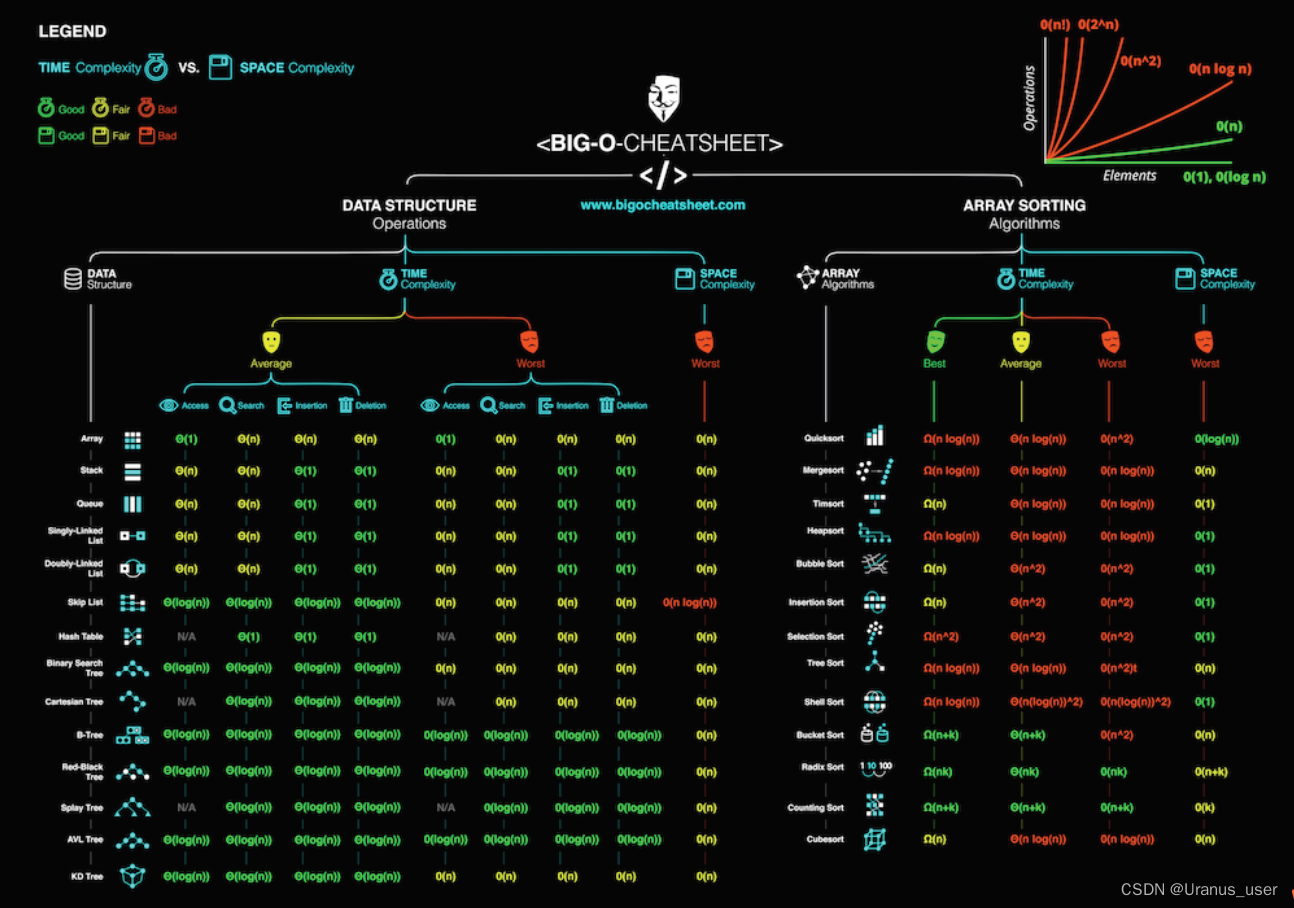
10个数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、tire树
-
线性表
数据排成像一条线一样的结构。每个线性表上的数据最多只有前和后两个方向。
-
数组
-
链表
-
栈
-
队列
-
-
散列表
- 哈希表
-
树
- 二叉树
- 二叉搜索树
- 堆
- 平衡二叉树 - 红黑树
- tire 树
-
图
算法
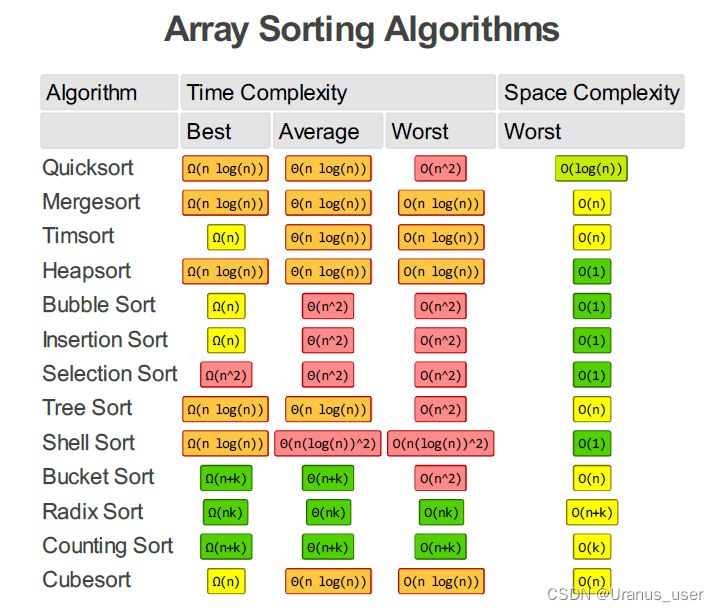
10个算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法
六种基本算法思想:
- 递归/回溯算法
- 分治算法
- 贪心算法
- 动态规划
- 枚举算法
- 迭代算法
- 八种排序算法
- 冒泡排序 O(n^2)
- 选择排序
- 希尔排序
- 基数排序
- 计数排序
- 插入排序 O(n^2)
- 归并排序 O(nlogn)
- 快速排序 O(nlogn)
- 搜索算法
- 广度优先
- 深度优先
- 查找算法
- 线性表查找
- 散列表查找
- 树结构查找
- 字符串匹配
- tire
- 其他
- 数论
- 计算几何
- 线性规划
- 矩阵运算
- 概率分析
- 并查集
- 拓扑网络
| Data Structure | Algorithm |
|---|---|
| Array 数组 | General Coding |
| Stack / Queue 栈/队列 | In-order/Pre-order/Post-order traversal |
| PriorityQueue (heap) 优先队列 | Greedy 贪心算法 |
| LinkedList (single / double) 链表 | Recursion/Backtrace 递归/回溯 |
| Tree / Binary Tree 树/二叉树 | Breadth-first search 广度优先 |
| Binary Search Tree 二叉搜索树 | Depth-first search 深度优先 |
| HashTable 哈希表 | Divide and Conquer 分治 |
| Disjoint Set 并查集 | Dynamic Programming 动态规划 |
| Trie | Binary Search 二分查找 |
| BloomFilter | Graph 图 |
| LRU Cache |
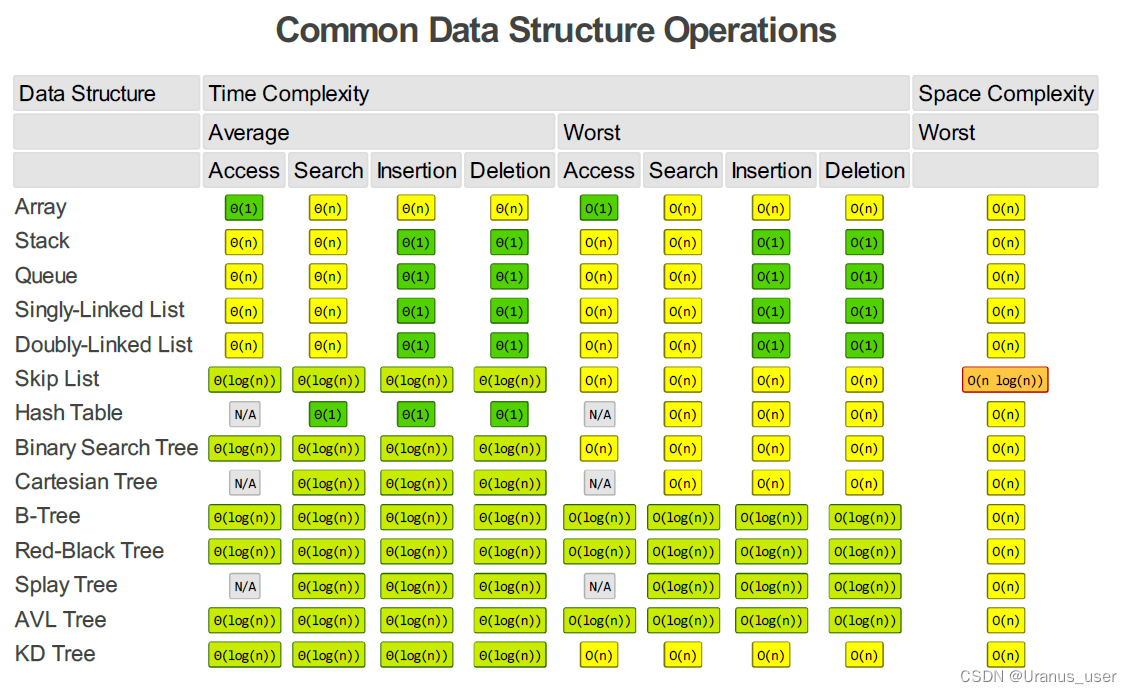
时间复杂度
-
大O时间复杂度表示法
大O时间复杂度实际上并不具体表示代码真正的执行时间,而是表示代码执行时间随数据规模增长的变化趋势,所以也叫做渐进时间复杂度,简称时间复杂度。
时间复杂度表示的是一个算法执行效率与数据规模增长的变化趋势。
-
时间复杂度分析
-
只关注循环执行次数最多的一段代码;
大 O 这种复杂度表示方法只是表示一种变化趋势。我们通常会忽略掉公式中的常量、低阶、系数,只需要记录一个最大阶的量级就可以了。所以,我们在分析一个算法、一段代码的时间复杂度的时候,也只关注循环执行次数最多的那一段代码就可以了。这段核心代码执行次数的 n 的量级,就是整段要分析代码的时间复杂度。
-
加法法则:总复杂度等于量级最大的那段代码的复杂度
如果 T1(n)=O(f(n)),T2(n)=O(g(n));那么 T(n)=T1(n)+T2(n)=max(O(f(n)), O(g(n))) =O(max(f(n), g(n))).
-
乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
如果 T1(n)=O(f(n)),T2(n)=O(g(n));那么 T(n)=T1(n)*T2(n)=O(f(n))*O(g(n))=O(f(n)*g(n)).
-
-
最好情况时间复杂度、最坏情况时间复杂度、平均情况时间复杂度、均摊时间复杂度
-
复杂度量级分为:多项式量级和非多项式量级(O(2^n)和O(n!),NP非确定多项式 问题)
-
O(1): Constant Complexity: Constant 常数复杂度
只要代码的执行时间不随 n 的增大而增长,这样代码的时间复杂度我们都记作 O(1)。或者说,一般情况下,只要算法中不存在循环语句、递归语句,即使有成千上万行的代码,其时间复杂度也是Ο(1)。jj
-
O(log n): Logarithmic Complexity: 对数复杂度
-
O(n): Linear Complexity: 线性时间复杂度
-
O(nlogn):线性对数阶
-
O(n^2): N square Complexity 平⽅
-
O(n^3): N square Complexity ⽴方
-
O(2^n): Exponential Growth 指数
-
O(n!): Factorial 阶乘
空间复杂度
空间复杂度全称是渐进空间复杂度(asymptotic space complexity),表示算法的存储空间与数据规模之间的增长关系。
常见的空间复杂度就是 O(1)、O(n)、O(n2 )
数组 Array
特点:数组是一种线性表数据结构。它用一组连续的内存空间(在进行数组的删除、插入操作时,为了保持内存数据的连续性,需要大量的数据搬移),来存储一组具有相同类型的数据
优点
- 支持随机访问,根据下标随机访问的时间复杂度为O(1)
- 数组简单易用,使用的是连续的内存空间,可以借助CPU的缓存机制,预读数组中的数据,提高访问效率。
缺点
- 插入、删除操作低效 O(n),因为需要进行数据迁移。
- 数组大小固定,一经声明就要占用整块连续内存空间。如果声明的数组过大,系统可能没有足够的连续内存空间分配,导致“内存不足”;如果声明的数组过小,则可能出现不够用的情况,需要申请更大的内存空间,把原数据拷贝进去,非常耗时。
数组和链表的区别
- 数组支持随机访问,适合查找,根据下标随机访问的时间复杂度为O(n)
- 链表适合插入、删除,时间复杂度O(1)
时间复杂度
- Access: O(1)
- Insert: 平均 O(n)
- Delete: 平均 O(n)
链表 Linked List
是由许多相同数据类型的数据项按特定顺序排列而成的线性表。
特点:内存不连续,各个数据项在计算机内存中的位置是不连续且随机存放的(链表通过指针将一组零散的内存块串联在一起)。
优点
- 数据的插入或删除都相当方便,有新数据加入就向系统申请一块内存空间,而数据被删除后,就可以把这块内存空间还给系统,加入或删除都不需要移动大量的数据(支持动态扩容)。
缺点
- 设计数据结构时较为麻烦,并且在查找数据时,无法像静态数据那样可随机读取数据,必须按顺序查找到该数据为止。
时间复杂度
- space O(n)
- prepend O(1)
- append O(1)
- lookup O(1)
- insert O(1)
- delete O(1)
单向链表
由数据字段和指针两个元素组成;
单向链表只有一个方向,节点只有一个后继指针next指向后面的节点。
“单向链表”中第一个节点是“链表头指针”,指向最后一个节点的指针设为None,表示它是“链表尾”,不指向任何地方。
双向链表
双向链表支持两个方向,每个节点不止有一个后继指针next指向后面的节点,还有一个前驱指针prev指向前面的节点。
优势:支持O(1)时间复杂度的情况下找到前驱节点,双向链表在某些情况下的插入、删除等操作都要比单链表简单、高效。
缺点:占用更多的内存空间(空间换时间),数据结构复杂。
循环链表
是一种特殊的单链表,单链表的尾节点指针指向空地址,而循环链表的尾节点指针指向链表的头节点。
和单链表相比,循环链表的优点是从链尾到链头比较方便,循环链表适合处理具有环型结构特点的数据。
双向循环链表
堆栈 Stack
是一组相同数据类型的组合,具有“后进先出”的特征,所有的操作均在堆栈结构的顶端进行。
抽象型数据结构
First In Last Out (FILO)
Array or Linked List
-
特性
- 只能从堆栈的顶端存取数据
- 数据的存取符合“后进先出”的原则
-
基本运算
基本运算 说明 create 创建一个空堆栈 push 把数据压入堆栈顶端,并返回新堆栈 pop 从堆栈顶端弹出数据,并返回新堆栈 isEmpty 判断堆栈是否为空栈,是则返回true,不是则返回false full 判断堆栈是否已满,是则返回true,不是则返回false
队列 Queue
是一种“先进先出”的数据结构,和堆栈一样都是一种有序线性表的抽象数据类型。
抽象数据结构
First In First Out (FIFO)
Array or Linked List
-
特性
- 具有先进先出的特性
- 拥有加入与删除两种基本操作,而且使用from与rear两个指针来分别指向队列的前端与末尾。
-
基本操作
基本操作 说明 create 创建空队列 add 将新数据加入队列的末尾,返回新队列 delete 删除队列前端的数据,返回新队列 front 返回队列前端的值 empty 若队列为空,返回“真”,否则返回“假”
优先队列 Priority Queue
是一种不必遵守队列特性FIFO(先进先出)的有序线性表,其中的每一个元素都赋予一个优先级,加入元素时可任意加入,但有最高优先级者则最先输出。
哈希表 Hash Table
是一种存储记录的连续内存,通过哈希函数的应用,可以快速存取与查找数据。基本上,所谓哈希法就是将本身的键值,通过特定的数学函数运算或使用其他方法,转换成相对应的数据存储地址。
- bucket(桶):哈希表中存储数据的位置,每一个位置对应到唯一的一个地址(bucket address)
- slot(槽):每一个记录中可能包含好几个字段,而slot指的是“桶”中的字段
- collision(碰撞):两项不同的数据,经过哈希函数运算后,对应到相同的地址。
- 溢出:如果数据经过哈希函数运算后,所对应到的bucket已满,就会使bucket发生溢出。
- 哈希表:存储记录的连续内存。哈希表示一种类似数据表的索引表格,可分为n个bucket,每个bucket又可分为m个slot。
- 同义词:两个标识符I1和I2经哈希函数运算后所得的数值相同,即f(I1)=f(I2),就称I1与I2对于f这个哈希函数是同义词。
- 加载密度:指标识符的使用数量除以哈希表内槽的总数
- 完美哈希:没有碰撞也没有溢出的哈希函数
哈希函数设计原则
- 降低碰撞和溢出的产生
- 哈希函数不宜过于复杂,越容易计算越佳
- 尽量把文字的键值转换成数字的键值,以利于哈希函数的运算
- 所设计的哈希函数计算得到的值,尽量能均匀地分布在每一个桶中,不要太过于集中在某些桶内,这样就可以降低碰撞,并减少溢出的处理。
树、⼆叉树
Linked List 就是特殊化的 Tree
Tree 就是特殊化的 Graph
-
度数:每个节点所有子树的个数
-
层数:树的层数
-
高度:树的最大层数
-
树叶或终端节点:度数为零的节点
-
父节点:每一个节点有连接的上一层节点(父节点)
-
子节点:每一个节点有连接的下一层节点(子节点)
-
祖先:指从树根到该节点路径上所包含的节点
-
子孙:该节点往下追溯子树中的任意节点
-
兄弟节点:有共同父节点的节点为兄弟节点
-
非终端节点:树叶以外的节点
-
同代:在同一颗中具有相同层数的节点
-
森林:n棵(n>=0)互斥树的集合
-
满二叉树
所有叶节点都在最底层的完全二叉树
-
完全二叉树
对于一颗二叉树,假设深度为d,除了d层外,其它各层的节点数均已达到最大值,并且第d层所有节点从左向右连续紧密排列
-
二叉排序树
任何一个节点,所有左边的值都会比此节点小,所有右边的值都会比此节点大
-
平衡二叉树
当且仅当任何节点的两棵子树的高度差不大于1的二叉树
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fR51LgSH-1677826933387)(C:\Users\F2849526\記事本\数据结构与算法\algorithm-1-master\algorithm-1-master\tree)]
⼆叉搜索树
- 若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 任意节点的左、右子树也分别为二叉查找树。
二叉树遍历
- 前序(Pre-order):根-左-右
- 中序(In-order):左-根-右
- 后序(Post-order):左-右-根
常见算法:
递归 Recursion [rɪˈkɜːrʒn]
定义:一个函数或子程序,是由自身所定义或调用的。
满足两个条件:
- 一个可以反复执行的递归过程;
- 一个可以离开递归执行的出口。
- 求解n!
def factorial(n):if n == 0: # 离开递归的终止条件return 1else:result = n * factorial(n - 1): # 反复执行的递归过程return result
- 斐波那契额数列的求解
# 数列的第0项是0、第1项是1,之后的各项的值是由前面两项的值相加的结果。
def fib(n):if n == 0:return 0elif n == 1 or n == 2:return 1else:return fib(n - 1) + fib(n - 2)
分治 Divde & Conquer [ˈkɑːŋkər]
核心思想是将一个难以直接解决的大问题依照相同的概念,分割成两个或更多的子问题,以便各个击破,即“分而治之”。
任何一个可以用程序求解的问题所需的计算时间都与其规模有关,问题的规模越小,越容易直接求解。分割问题也是遇到大问题的解决方式,可以使子问题规模不断缩小,直到这些子问题足够简单到可以解决,最后再将各子问题的解合并得到原问题的最终解答。
应用场景:
- 快速排序
- 递归算法
- 大整数乘法
迭代法
指无法使用公式一次求解,而需要使用迭代,如用循环去重复执行程序代码的某些部分来得到答案。
- 使用for循环来设计一个计算1! ~ n!阶乘的递归程序
sum = 1
n = int(input('请输入n='))
for i in range(0, n + 1):for j in range(i, 0, -1):sum *= jprint('%d! = %3d' % (i, sum))sum = 1
枚举法
核心思想是列举所有的可能。根据问题要求,逐一列举问题的解答,或者为了便于解决问题,把问题分为不重复、不遗漏的有限种情况,逐一列举各种情况,并加以解决,最终达到解决整个问题的目的。
- 列出1到500之间所有5的倍数(整数)
for num in range(1, 501):if num % 5 == 0:print('%d 是5的倍数' % num)
回溯法
也是枚举法中的一种,对于某些问题而言,回溯法是一种可以找出所有(或一部分)解的一般性算法,同时避免枚举不正确的数值。一旦发现不正确的数值,就不在递归到下一层,而是回溯到上一层,以节省时间,是一种走不通就退回再走的方式。
应用场景:在搜索过程中寻找问题的解,当发现不满足求解条件时,就回溯(返回),尝试别的路径,避免无效搜索。
贪⼼算法(Greedy Algorithms)
贪心法,又称贪婪算法:方法是从某一起点开始,在每一个解决问题步骤中使用贪心原则,即采取在当前状态下最有利或最优化的选择,不断地改进该解答,持续在每一步骤中选择最佳的方法,并且逐步逼近给定的目标,当达到某一步骤不能再继续前进时,算法就停止,就是尽可能块地求得更好的解。
适用 Greedy 的场景:简单地说,问题能够分解成子问题来解决,子问题的最优解能递推到最终问题的最优解。这种子问题最优解成为最优子结构。
应用场景:
- 找出图的最小生成树(MST)
- 最短路径
- 哈夫曼编码
贪心算法与动态规划的不同在于它对每个子问题的解决⽅案都做出选择,不能回退。动态规划则会保存以前的运算结果,并根据以前的结果对当前进行行选择,有回退功能。
广度优先搜索(Breadth-First-Search)
def BFS(graph, start, end):queue = []queue.append([start])visited.add(start)while queue:node = queue.pop()visited.add(node)process(node)nodes = generate_related_nodes(node)queue.push(nodes)# other procession work...
深度优先搜索(Depth-First-Search)
-
递归写法
visited = set() def dfs(node, visited):visited.add(node)# process current node here....for next_node in node.children():if not next_node in visited:dfs(next_node, visited) -
非递归写法
def DFS(self, tree):if tree.root is None:return []visited, stack = [], [tree.root]while stack:node = stack.pop()nodes = generate_related_nodes(node)stack.push(nodes)# other processing work...
剪枝
⼆分查找(Binary Search)
- Sorted(单调递增或者递减)
- Bounded(存在上下界)
- Accessible by index(能够通过索引访问)
字典树(Trie)
- Trie 树的数据结构
Trie树,即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于⽂本词频统计。
它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
- Trie 树的核⼼思想
Trie的核⼼思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的⽬的。
- Trie 树的基本性质
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符。
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符都不相同。
位运算的运⽤(Bitwise operations)
动态规划(Dynamic Programming)
- 递归+记忆化 —> 递推
- 状态的定义:opt[n], dp[n], fib[n]
- 状态转移⽅程:opt[n] = best_of(opt[n-1], opt[n-2], …)
- 最优子结构
类似于分治法,用于研究多个阶段决策过程的优化过程与求得一个问题的最佳解。
动态规划的主要做法:如果一个问题答案与子问题相关的话,就能大问题拆解成各个小问题,其中与分治法最大不同的地方是可以让每一个子问题的答案被存储起来,以供下次求解时直接取用。这样的做法不但能减少再次计算的时间,并可将这些解组合成大问题的解答,故而使用动态规划可以解决重复计算的问题。
- 求解斐波那契数列的解
output = [None] * 1000 # fibonacci的暂存区def Fibonacci(n):result = output[n]if result == None:if n == 0:result = 0elif n == 1:result = 1else:result = Fibonacci(n - 1) + Fibonacci(n - 2)output[n] = resultreturn result
图
图是由“定点”和“边”所组成的集合,通常用G=(V, E)来表示,其中V 是所有定点所组成的集合,而E代表所有变所组成的集合。
无向图
是一种变没有方向的图,即同边的两个定点没有次序关系。
V = {A, B, C, E}
E = {(A, B), (A, E), (B, C), (B, D), (C, D), (C, E), (D, E)}
有向图
是一种每一条边都可使用有序对<V1, V2>来表示的图, 并且<V1, V2>与<V2, V1>是表示两个方向不同的边,而所谓<V1, V2>,是指V1为尾端指向为头部的V2
加权图
相关文章:
数据结构和算法学习
文章目录精通一个领域切题四件套算法算法的五个条件流程图数据结构数据与信息数据信息数据结构和算法数据结构算法时间复杂度空间复杂度数组 Array优点缺点数组和链表的区别时间复杂度链表 Linked List优点缺点时间复杂度单向链表双向链表循环链表双向循环链表堆栈 Stack队列 Q…...

剑指 Offer II 012. 左右两边子数组的和相等
题目链接 剑指 Offer II 012. 左右两边子数组的和相等 easy 题目描述 给你一个整数数组 nums,请计算数组的 中心下标 。 数组 中心下标 是数组的一个下标,其左侧所有元素相加的和等于右侧所有元素相加的和。 如果中心下标位于数组最左端,那…...

Java货物摆放
题目描述 小蓝有一个超大的仓库,可以摆放很多货物。 现在,小蓝有 � n 箱货物要摆放在仓库,每箱货物都是规则的正方体。小蓝规定了长、宽、高三个互相垂直的方向,每箱货物的边都必须严格平行于长、宽、高。 小蓝希望所…...

计算机求解满足三角形各边数字之和相等的数字填充
圆圈处不重复的填入1至9,使得每条边的四个数字相加的总和相等。 求解思路: 数组中存放1到9的数字,每次随机交换两个数字,构建出新的数字组合,计算这个数字组合是否符合要求。 #include <stdio.h> #include <…...

python魔术方法
魔术方法 魔术方法就是一个类中的方法,和普通方法唯一的不同是普通方法需要调用,而魔术方法是在特定时刻自动触发。这些魔术方法的名字特定,不能更改,但是入口参数的名字可以自己命名。 基本魔术方法 new(cls[,…]) _new_ 是在…...

从0开始学python -48
Python CGI编程-3 CGI中使用Cookie 在 http 协议一个很大的缺点就是不对用户身份的进行判断,这样给编程人员带来很大的不便, 而 cookie 功能的出现弥补了这个不足。 cookie 就是在客户访问脚本的同时,通过客户的浏览器,在客户硬…...

当面试官问我前端可以做的性能优化有哪些
面试过程中面试官问到前端性能优化有哪些,当我咔咔一顿输出之后面试官追问:前端可以做的性能优化有哪些呢? 前端优化大概可以有以下几个方向: 网络优化页面渲染优化JS优化图片优化webpack打包优化React优化Vue优化 网络优化 D…...

一文读懂Java/O流的使用方法和技巧
1.前言 Java 中的 I/O 流是实现输入和输出的一种机制,可以用来读写文件、网络、内存等各种资源。Java 提供了各种类型的流,包括字节流和字符流,以及面向文本和二进制数据的流。在本文中,我们将深入探讨 Java I/O 流的各个方面&am…...

AI for Science系列(二):国内首个基于AI框架的CFD工具组件!赛桨v1.0 Beta API介绍以及典型案例分享!
AI for Science被广泛认为是下一代科研范式,可以有效处理多维度、多模态、多场景下的模拟和真实数据,解决复杂推演计算问题,加速新科学问题发现[1] 。百度飞桨科学计算工具组件赛桨PaddleScience是国内首个公开且可应用于CFD(Comp…...
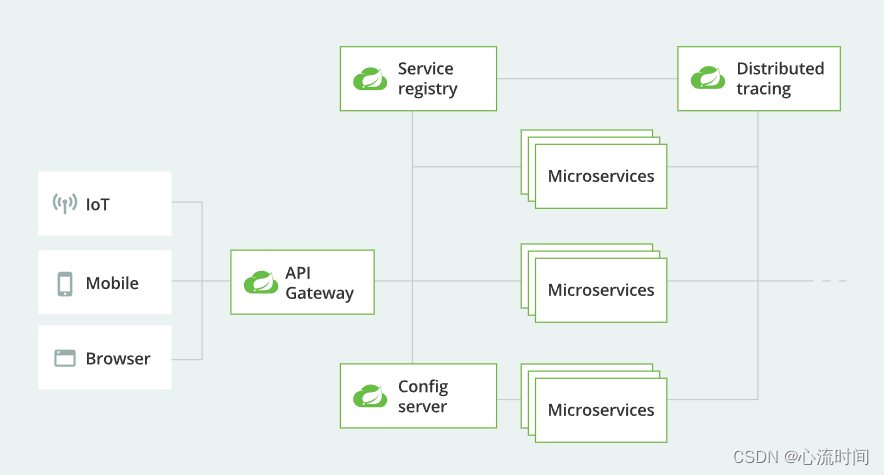
SpringCloud简单介绍
文章目录1. 开源组件2. CAP原则1. 开源组件 功能springcloud netflixspringcloud alibabaspringcloud官方其他服务注册与发现eurekanacosconsulzookeeper负载均衡ribbondubbo服务调用openFeigndubbo服务容错hystrixsentinel服务网关zuulgateway服务配置的同一管理cofig-server…...
《uniapp基础知识》学习笔记Day38-(Period2)全局文件一些常用的配置
如果进行开发的话,首先要配置路由页面 page.json 页面路由 pages.json 文件用来对 uni-app 进行全局配置,决定页面文件的路径、窗口样式、原生的导航栏、底部的原生tabbar 等。 {"pages": [{"path": "pages/component/index…...

APICloud 弹动与滚轴冲突的解决模拟
当打开页面的bounces开关来实现下拉刷新和上翻加载是,如果页面中有scroll-view,那么手指上下滑动时弹动会触发,而滚轴无法正常实现,只有按住不动再拖动滚轴才会触发。开始想通过获取手指点击屏幕的坐标点设置触发条件来解决两者的…...

Spring Cloud(微服务)学习篇(四)
Spring Cloud(微服务)学习篇(四) 1.nacos实现服务之间传参数 1.1 在dto包(shop-sms-api项目)中创建SmsDTO类 package com.zlz.shop.sms.api.dto;import lombok.Data;Data public class SmsDTO {private String tel; }1.2 复制SmsDTO类到shop-sms-server项目的dto包下面 1.3 …...

【Java Pro】001-Java基础:面向对象
【Java Pro】001-Java基础:面向对象 文章目录【Java Pro】001-Java基础:面向对象一、面向对象1、什么是对象现实生活中的对象与程序中的对象2、什么是面向对象面向过程面向对象3、面向过程与面向对象的比较思想方面设计方式方面实现方式方面4、面向过程与…...

ElasticSearch从0到1——基础知识
1.ES是什么? 是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能&…...

【面试系列】equals和==的区别
问题:两个对象值相同(x.equals(y) true),但是可能存在hashCode不同吗? 的定义 比较的是两个对象的内存地址,相等则意味着内存地址一样。 对象的equals方法 Object#equals public boolean equals(Object obj) {return (this obj);}Stri…...

存在重复元素模块-三道题
文章目录存在重复元素217. 存在重复元素219. 存在重复元素 II220. 存在重复元素 III (SortedList二分)小结存在重复元素 217. 存在重复元素 题目链接:217. 存在重复元素 题目大意:给你一个整数数组 nums 。如果任一值在数组中出…...

3种方法删除7-Zip压缩包的密码
7-Zip压缩软件是一款完全免费且开源的软件,不仅能压缩和解压7-Zip压缩包,还能给压缩包设置打开密码。 有些小伙伴可能会遇到这样的问题,7-Zip压缩包设置密码后,过了一段时间不需要密码保护了,或者一不小心忘记了密码&…...

Codeforces Round 855 (Div. 3)(A~F)
A. Is It a Cat?定义满足条件的字符串为:其中仅可能含有meow四种字母的大小写,而且相同种类的字母必须挨在一起,四种字母的顺序必须按照meow排列。给出一个字母串,求是否满足条件。思路:感觉是个很麻烦的模拟。首先把…...
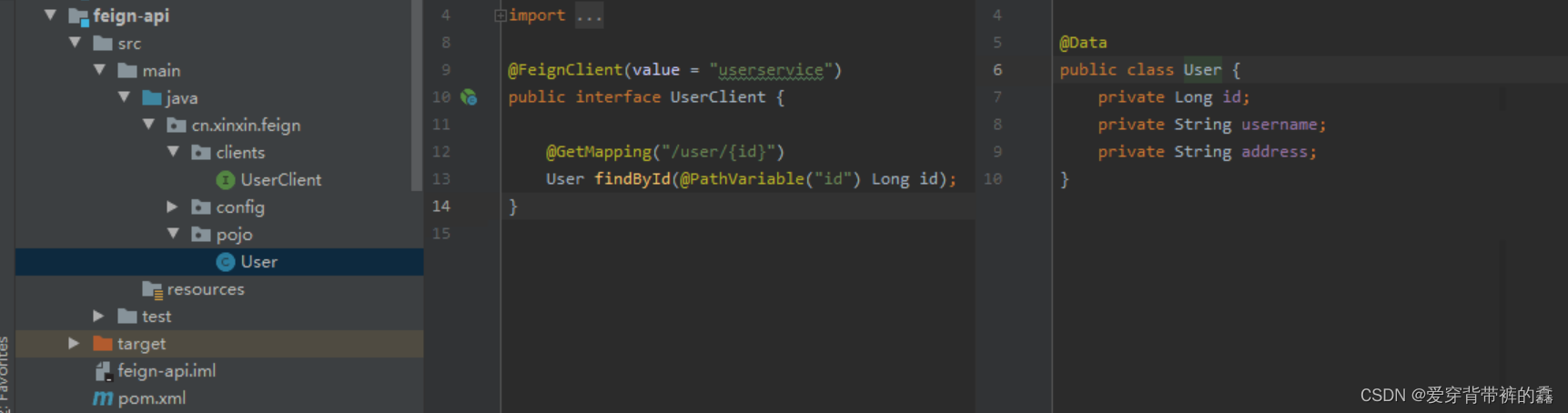
【SpringCloud】SpringCloud详解之Feign实战
目录前言SpringCloud Feign远程服务调用一.需求二.两个服务的yml配置和访问路径三.使用RestTemplate远程调用(order服务内编写)四.使用Feign远程调用(order服务内配置)五.自定义Feign配置(order服务内配置)六.Feign配置日志(oder服务内配置)七.Feign调优(order服务内配置)八.抽…...
5个关键步骤让zotero-pdf-translate翻译功能重新工作:完整解决方案指南
5个关键步骤让zotero-pdf-translate翻译功能重新工作:完整解决方案指南 【免费下载链接】zotero-pdf-translate Translate PDF, EPub, webpage, metadata, annotations, notes to the target language. Support 20 translate services. 项目地址: https://gitcode…...

深入解析session-guardian:分布式会话并发安全与生命周期管理实践
1. 项目概述与核心价值最近在折腾一个分布式系统的监控项目,遇到了一个挺典型的问题:用户会话(Session)在集群环境下频繁丢失,导致用户体验断崖式下跌。排查了一圈,从负载均衡策略到Redis集群配置ÿ…...

我让 AI 学会了“拆“App——Antigravity 逆向分析能力搭建手记
你能想象吗?对着 AI 说一句"帮我分析这个 APK",它就自己打开 IDA、拆解代码、Hook 运行时、提取密钥、还原源码……全程不用你碰一下鼠标。先说结论我给 AI 编程助手 Antigravity 装上了 4 把"瑞士军刀",让它从一个只会写…...

阴阳师自动化脚本终极指南:如何用OnmyojiAutoScript一键托管你的日常游戏
阴阳师自动化脚本终极指南:如何用OnmyojiAutoScript一键托管你的日常游戏 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 还在为阴阳师繁琐的日常任务而烦恼吗&#…...

Raw Accel终极指南:Windows鼠标加速的完整解决方案
Raw Accel终极指南:Windows鼠标加速的完整解决方案 【免费下载链接】rawaccel kernel mode mouse accel 项目地址: https://gitcode.com/gh_mirrors/ra/rawaccel 你是否厌倦了Windows系统自带的鼠标加速功能?是否在游戏和设计工作中需要更精准的鼠…...

最火 AI 生图模型 Nano Banana Pro 国内免费使用指南
最近在设计圈和 AI 圈,几乎无人不知 Nano Banana Pro。它是谷歌基于 Gemini 3 Pro 打造的最新图像模型,一上线就斩获 LMArena 生图和图像编辑榜单第一名。虽然 Nano Banana 2 的历史成绩更亮眼,但实测体验发现 Pro 版更好用、操作更顺手。 为…...

XSP25全协议 100W PD快充诱骗芯片_串口读电压电流信息
在Type-C快充技术普及的今天,快充诱骗协议芯片成为小家电、智能硬件、锂电设备等产品实现高效取电的核心器件。XSP25作为汇铭达推出的Type‑C受电端(Sink)多功能快充取电芯片,以全协议兼容、100W大功率输出、串口智能通信、极简外…...

疫情如何重塑GPU市场:从游戏硬件到数字基础设施的演变
1. 市场预期的“扭曲”:疫情如何重塑GPU行业逻辑如果你在2020年初问任何一位半导体行业的分析师,他们对当年第二季度GPU(图形处理器)市场的预测,大概率会得到一个基于历史季节性规律的保守或平稳的答案。然而ÿ…...

React Native Actions Sheet源码解析:深入理解其架构与实现原理
React Native Actions Sheet源码解析:深入理解其架构与实现原理 【免费下载链接】react-native-actions-sheet A Cross Platform(Android, iOS & Web) ActionSheet with a flexible api, native performance for react native. Create anything you want inside…...

DeepFlow:基于eBPF与Wasm的零代码全栈可观测性平台实战解析
1. 项目概述:从零代码到全栈可观测,DeepFlow 如何重塑云原生与AI应用的监控体验 如果你正在管理一个由微服务、容器和AI模型构成的复杂云原生环境,那么“可观测性”这个词对你来说,可能既熟悉又头疼。熟悉的是,你知道没…...