实现目标检测中的数据格式自由(labelme json、voc、coco、yolo格式的相互转换)
在进行目标检测任务中,存在labelme json、voc、coco、yolo等格式。labelme json是由anylabeling、labelme等软件生成的标注格式、voc是通用目标检测框(mmdetection、paddledetection)所支持的格式,coco是通用目标检测框(mmdetection、paddledetection)所支持的格式,yolo格式是yolo系列项目中所支持的格式。在进行实际项目中,通常不会局限于一个检测框架,故而数据格式也不会局限于一种。为此博主整理了互联网上相关的数据格式转换代码,方便各位的使用。
1、json格式转yolo
这里是指将json格式转yolo格式,具体包括目标检测、关键点检测、实例分割,旋转框检测等(最新的yolov8项目支持以上任务)。具体代码如下所示,其可以将json格式转为yolo格式,在json文件同目录下生成yolo格式的txt文件
import json
import numpy as np
import os,cv2
#把json格式的标注转换为yolo格式
def json2yolo(path,cls_dict,types="bbox"):# 打开文件,r是读取,encoding是指定编码格式with open(path ,'r',encoding = 'utf-8') as fp:# load()函数将fp(一个支持.read()的文件类对象,包含一个JSON文档)反序列化为一个Python对象data = json.load(fp)h=data["imageHeight"]w=data["imageWidth"]shapes=data["shapes"]all_lines=""for shape in shapes:if True:#转成np数组,为了方便将绝对数值转换为相对数值points=np.array(shape["points"]) #把二维list强制转换np数组 shape为n,2#print(points)#[[x1,y1],[x2,y2]]if types=="bbox":print(len(points))x, y, wi, hi = cv2.boundingRect(points.reshape((-1,1,2)).astype(np.float32))cx,cy=x+wi/2,y+hi/2cx,cy,wi,hi=cx/w,cy/h,wi/w,hi/hmsg="%.2f %.2f %.2f %.2f"%(cx,cy,wi,hi)else:points[:,0]=points[:,0]/w #n,2数组的第0列除以wpoints[:,1]=points[:,1]/h #n,2数组的第1列除以h#把np数组转换为yolo格式的strpoints=points.reshape(-1)points=list(points)points=['%.4f'%x for x in points]#把float型的list转换为str型的listmsg=" ".join(points)l=shape['label'].lower()line=str(cls_dict[l])+" "+msg+"\n"all_lines+=lineprint(all_lines)filename=path.replace('json','txt')fh = open(filename, 'w', encoding='utf-8')fh.write(all_lines)fh.close()
#定义文件路径
path="labelme-data"
path_list=os.listdir(path)
cls_dict={'cls0':0,'cls1': 1, 'cls2': 2, 'cls3': 3}
path_list2=[x for x in path_list if ".json" in x]
for p in path_list2:json2yolo(path+"/"+p,cls_dict)
2、yolo格式转voc
参考博客:python工具方法 41 对VOC|YOLO格式的数据进行resize操作(VOC与YOLO数据相互转换) 中2.2节的内容,可以实现将yolo格式转voc格式。yolo格式数据转换为voc数据后,可以使用mmdetecion、paddledetection等框架进行训练。
需要注意的是,yolo数据以id描述类别,而voc数据以name描述类别,故而需要设置cls_dict来描述id与name的对应关系

3、voc格式转yolo
参考博客:python工具方法 41 对VOC|YOLO格式的数据进行resize操作(VOC与YOLO数据相互转换) 中2.1节的内容,可以实现将voc格式转yolo格式。voc格式数据转换为yolo后,可以对图像进行resize操作,以训练模型提升图像加载速度。
需要注意的是,yolo数据以id描述类别,而voc数据以name描述类别,故而需要设置cls_dict来描述id与name的对应关系
4、voc数据转json
代码摘抄自互联网。其空将xml描述的voc数据转换为json格式,使得我们可以利用labelme等软件对标签进行可视化与调整
"""Author:DamonZhengFunction:xml2json(for labelme)Edition:1.0Date:2022.2.21
"""import argparse
import glob
import os
import xml.etree.ElementTree as ET
import json
from tqdm import tqdmdef parse_args():"""参数配置"""parser = argparse.ArgumentParser(description='xml2json')parser.add_argument('--raw_label_dir', help='the path of raw label', default=r'el-voc2/Annotations')parser.add_argument('--pic_dir', help='the path of picture', default=r'el-voc2/JPEGImages')parser.add_argument('--save_dir', help='the path of new label', default=r'el-voc2/Jsons')args = parser.parse_args()return argsdef read_xml_gtbox_and_label(xml_path):"""读取xml内容"""tree = ET.parse(xml_path)root = tree.getroot()size = root.find('size')width = int(size.find('width').text)height = int(size.find('height').text)depth = int(size.find('depth').text)points = []for obj in root.iter('object'):cls = obj.find('name').text#pose = obj.find('pose').textxmlbox = obj.find('bndbox')xmin = float(xmlbox.find('xmin').text)xmax = float(xmlbox.find('xmax').text)ymin = float(xmlbox.find('ymin').text)ymax = float(xmlbox.find('ymax').text)box = [xmin, ymin, xmax, ymax]point = [cls, box]points.append(point)return points, width, heightdef main():"""主函数"""args = parse_args()labels = glob.glob(args.raw_label_dir + '/*.xml')for i, label_abs in tqdm(enumerate(labels), total=len(labels)):_, label = os.path.split(label_abs)label_name = label.rstrip('.xml')img_path = os.path.join(args.pic_dir, label_name + '.jpg')points, width, height = read_xml_gtbox_and_label(label_abs)json_str = {}json_str['version'] = '4.5.6'json_str['flags'] = {}shapes = []for i in range(len(points)):shape = {}shape['label'] = points[i][0]shape['points'] = [[points[i][1][0], points[i][1][1]], [points[i][1][0], points[i][1][3]], [points[i][1][2], points[i][1][3]],[points[i][1][2], points[i][1][1]]]shape['group_id'] = Noneshape['shape_type'] = 'polygon'shape['flags'] = {}shapes.append(shape)json_str['shapes'] = shapesjson_str['imagePath'] = label_name + '.JPG'json_str['imageData'] = Nonejson_str['imageHeight'] = heightjson_str['imageWidth'] = widthwith open(os.path.join(args.save_dir, label_name + '.json'), 'w') as f:json.dump(json_str, f, indent=2)if __name__ == '__main__':main()5、voc数据转coco
coco格式也基于json文件描述标注的,在paddledetection中使用voc格式训练时输出的指标是map50,而使用coco格式数据训练时输出的指标是coco map。基于map50是看不出最佳模型的性能差异,而基于coco map5095 则可以明显的看出各个模型性能的差异。
这里主要描述基于paddledetection将voc格式的数据转换为coco格式。现有数据格式如下,在Annotations中存储的是xml,在JPEGImages存储的是图片。

基于以下代码可以进行voc数据的格式化(进行输出划分),
#数据集划分
import os
voc_path='dataset/el-voc/'
root=voc_path+'JPEGImages'
# 遍历训练集
name = [name for name in os.listdir(root) if name.endswith('.jpg')]train_name_list=[]
for i in name:tmp = os.path.splitext(i)train_name_list.append(tmp[0])#读取数据
data_voc=[]
data_paddle=[]
for i in range(len(train_name_list)):line='JPEGImages/'+train_name_list[i]+'.jpg'+" "+"Annotations/"+train_name_list[i]+'.xml' data_voc.append(train_name_list[i])data_paddle.append(line)
#把数据翻10倍
#data_voc=data_voc*10
#data_paddle=data_paddle*10# 构造label.txt
cls_dict={'heipian':0,'heiban': 1, 'yinglie': 2, 'beibuhuashang': 3}
labels=list(cls_dict.keys())
print(data_paddle)
with open(voc_path+"label_list.txt","w") as f:for i in range(len(labels)):line=labels[i]+'\n'f.write(line)# 将数据随机按照eval_percent分为验证集文件和训练集文件
# eval_percent 验证集所占的百分比
import random
eval_percent=0.2
seed=1234
index=list(range(len(data_paddle)))
random.seed(seed)
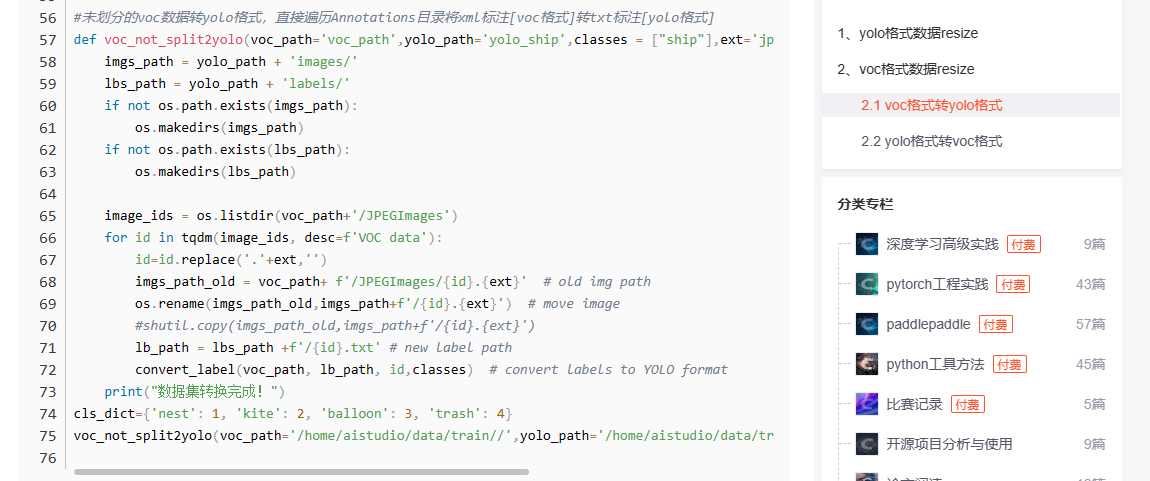
random.shuffle(index)os.makedirs(voc_path+"ImageSets",exist_ok=True)#--------用于将数据转换为voc格式--------
# 构造验证集文件
cut_point=int(eval_percent*len(data_voc))
with open(voc_path+"ImageSets/test.txt","w") as f:for i in range(cut_point):if i!=0: f.write('\n')line=data_voc[index[i]]f.write(line)# 构造训练集文件
with open(voc_path+"ImageSets/trainval.txt","w") as f:for i in range(cut_point,len(data_voc)):if i!=cut_point: f.write('\n')line=data_voc[index[i]]f.write(line)#--------用于paddle训练--------
# 构造验证集文件
cut_point=int(eval_percent*len(data_paddle))
with open(voc_path+"test.txt","w") as f:for i in range(cut_point):if i!=0: f.write('\n')line=data_paddle[index[i]]f.write(line)
# 构造训练集文件
with open(voc_path+"trainval.txt","w") as f:for i in range(cut_point,len(data_paddle)):if i!=cut_point: f.write('\n')line=data_paddle[index[i]]f.write(line)
同以上代码后生成的数据文件如下所示,其中绿框中的数据用于paddledetection训练,红框中的数用于格式转换,其是严格的voc格式。

绿框中的数据如下所示:
JPEGImages/A03-NB07-01-13_aug1.jpg Annotations/A03-NB07-01-13_aug1.xml
JPEGImages/A06-NB13-01-01_aug0.jpg Annotations/A06-NB13-01-01_aug0.xml
JPEGImages/A02-NB16-09-21_aug1.jpg Annotations/A02-NB16-09-21_aug1.xml
JPEGImages/A03-NB01-01-28_aug0.jpg Annotations/A03-NB01-01-28_aug0.xml
JPEGImages/A05-NB08-04-26_aug1.jpg Annotations/A05-NB08-04-26_aug1.xml
红框中的数据如下所示:
A03-NB07-01-13_aug1
A06-NB13-01-01_aug0
A02-NB16-09-21_aug1
A03-NB01-01-28_aug0
A05-NB08-04-26_aug1
基于现有的数据格式,可以使用paddledetection提供的工具将voc数据转换为coco格式。其中输出目录为--output_dir=dataset/el-coco/annotations
python tools/x2coco.py --dataset_type voc --voc_anno_dir dataset\el-voc\Annotations --voc_anno_list dataset\el-voc/ImageSets/trainval.txt --voc_label_list dataset/el-voc/label_list.txt --voc_out_name instances_train2017.json --output_dir dataset/el-coco/annotationspython tools/x2coco.py --dataset_type voc --voc_anno_dir dataset\el-voc\Annotations --voc_anno_list dataset\el-voc/ImageSets/test.txt --voc_label_list dataset/el-voc/label_list.txt --voc_out_name instances_val2017.json --output_dir dataset/el-coco/annotations
然后在dataset/el-coco/中创建images目录,将voc数据中的jpg图片拷贝到images目录中,具体如下所示:
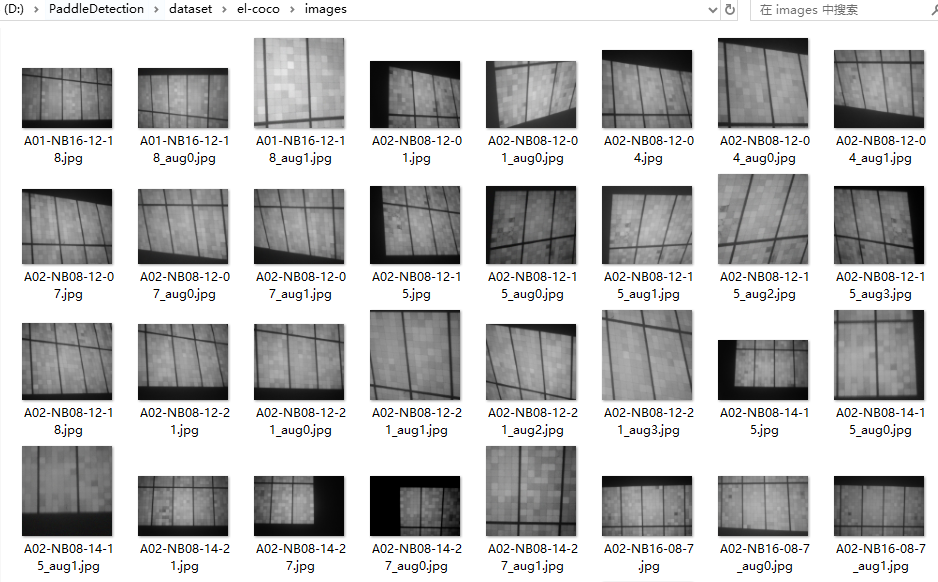
在训练时,yml文件的数据配置写法如下所示:
metric: COCO
num_classes: 4
TrainDataset:name: COCODataSetimage_dir: imagesanno_path: annotations/instances_train2017.jsondataset_dir: dataset/el-cocodata_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd']EvalDataset:name: COCODataSetimage_dir: imagesanno_path: annotations/instances_val2017.jsondataset_dir: dataset/el-cocoallow_empty: trueTestDataset:name: ImageFolderanno_path: annotations/instances_val2017.json # also support txt (like VOC's label_list.txt)dataset_dir: dataset/el-coco # if set, anno_path will be 'dataset_dir/anno_path'
相关文章:
实现目标检测中的数据格式自由(labelme json、voc、coco、yolo格式的相互转换)
在进行目标检测任务中,存在labelme json、voc、coco、yolo等格式。labelme json是由anylabeling、labelme等软件生成的标注格式、voc是通用目标检测框(mmdetection、paddledetection)所支持的格式,coco是通用目标检测框࿰…...

一文读懂JVS逻辑引擎如何调用规则引擎:含详细步骤与场景示例
在当今的数字化时代,业务逻辑和规则的复杂性不断增加,这使得逻辑引擎和规则引擎在处理业务需求时显得尤为重要。逻辑引擎和规则引擎通过定义、解析和管理业务逻辑和规则,能够帮助企业提高工作效率、降低运营成本,并增强决策的科学…...

苹果应用上架是否需要软件著作权?
苹果应用上架是否需要软件著作权? 摘要 随着移动互联网的发展,苹果应用在市场上占据了很大份额。但是,很多开发者在上传苹果应用到App Store时,都会遇到一个问题,即是否需要进行软著申请?本文将深入探讨这…...
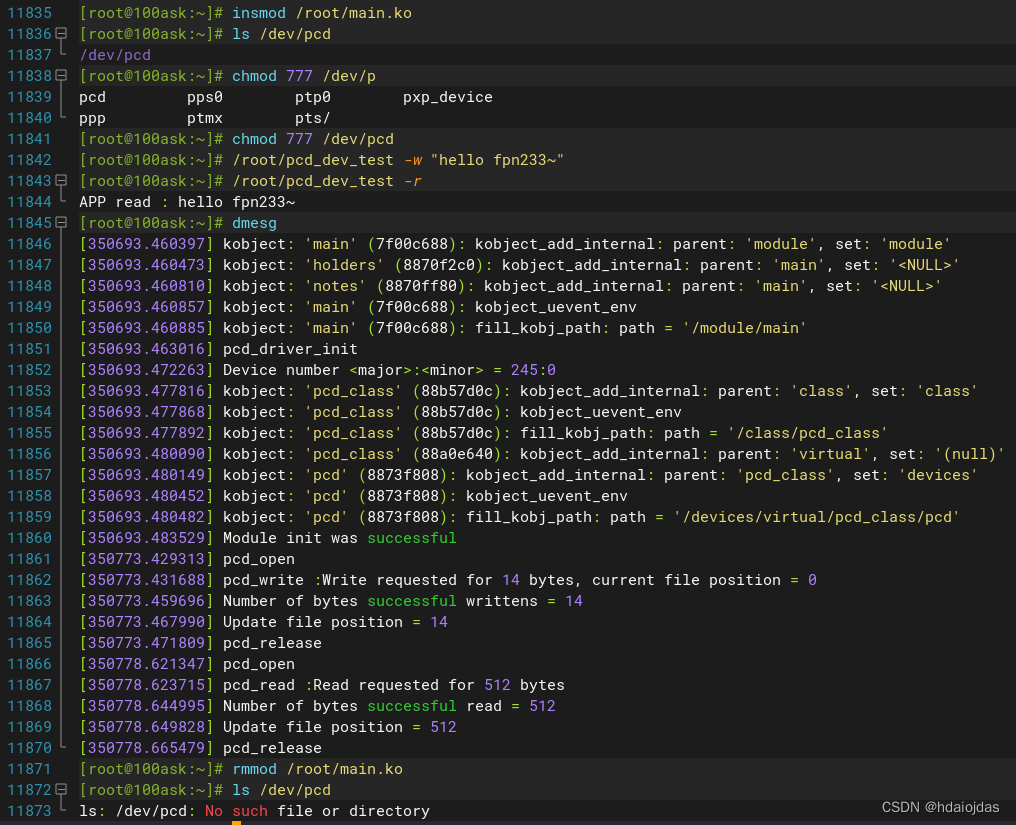
LDD学习笔记 -- Linux字符设备驱动
LDD学习笔记 -- Linux字符设备驱动 虚拟文件系统 VFS设备号相关Kernel APIs动态申请设备号动态创建设备文件内核空间和用户空间的数据交换系统调用方法readwritelseek 写一个伪字符设备驱动在主机上测试pcd(HOST)在目标板上测试pcd(TARGET) 字符驱动程序用于与Linux内核中的设备…...

杰理AC63串口收发实例
在event.h文件中预定义串口消息 #define DEVICE_EVENT_FROM_MY_UART ((M << 24) | (Y << 16) | (U << 8) | \0)在app_spp_and_le.c文件里对SYS_DEVICE_EVENT做处理,添加收到DEVICE_EVENT_FROM_MY_UART消息时的处理函数my_rx_handler(); cas…...
麦芯(MachCore)开发教程1 --- 设备软件中间件
黄国强 2024/1/10 acloud163.com 对任何公司来说,在短时间内开发一款高质量设备专用软件,是一件不太容易做到的事情。麦芯是笔者发明的一款设备软件中间件产品。麦芯致力于给设备厂商提供一个开发工具和平台,让客户快速高效的开发自己的设备专…...

reset命令
作用:将当前 HEAD 重置为指定状态 Git 的四个区域 Workspace:工作区,就是你平时存放项目代码的地方;Index / Stage:暂存区,用于临时存放你的改动,事实上它只是一个文件,保存即将提交到文件列表…...
LinuxIO基础知识与概念)
Linux内核--进程管理(十二)LinuxIO基础知识与概念
目录 一、引言 二、IO基本概念 ------>2.1、内存空间划分 ------>2.2、读写操作 ------>2.3、用户态切换到内核态的3种方式 三、PIO&DMA ------>3.1、PIO 工作原理 ------>3.2、DMA 工作原理 四、缓冲IO和直接IO ------>4.1、缓冲 IO ------&…...
gem5学习(11):将缓存添加到配置脚本中——Adding cache to the configuration script
目录 一、Creating cache objects 1、Classic caches and Ruby 二、Cache 1、导入SimObject(s) 2、创建L1Cache 3、创建L1Cache子类 4、创建L2Cache 5、L1Cache添加连接函数 6、为L1ICache和L1DCache添加连接函数 7、为L2Cache添加内存侧和CPU侧的连接函数 完整代码…...

上海雏鸟科技无人机灯光秀跨年表演点亮三国五地夜空
2023年12月31日晚,五场别开生面的无人机灯光秀跨年表演在新加坡圣淘沙、印尼雅加达、中国江苏无锡、浙江衢州、陕西西安等五地同步举行。据悉,这5场表演背后均出自上海的一家无人机企业之手——上海雏鸟科技。 在新加坡圣淘沙西乐索海滩,500架…...

学生备考护眼台灯怎么样选择?2024五款好用台灯安利
随着现代人生活水平的提高,人们对保护视力和眼健康的重视也日益提高。然而,长时间使用电子设备和不合适的光线环境却成为了我们眼健康的潜在威胁。所以,为了有效地保护我们的眼睛,护眼台灯成为了许多人的选择。 护眼台灯作为一种能…...

Java学习,一文掌握Java之SpringBoot框架学习文集(6)
🏆作者简介,普修罗双战士,一直追求不断学习和成长,在技术的道路上持续探索和实践。 🏆多年互联网行业从业经验,历任核心研发工程师,项目技术负责人。 🎉欢迎 👍点赞✍评论…...

美团点评秋招前端测评分享
一. 选择题 1. 甲乙二人各自加工一批同样数量的零件,甲完成一半时,乙完成150个,甲全部完成时,乙完成全部的5/6,求这批零件一共有(C)个 A. 320 B. 400 C. 360 D. 420 2. 分析如…...
docker安装nodejs,并更改为淘宝源
拉取官方 Node.js 镜像 docker pull node:latest创建 Dockerfile,并更改 NPM 下载源为淘宝源,设置为全局持久化 # 使用最新版本的Node.js作为基础镜像 FROM node:latest# 设置工作目录为/app WORKDIR /app # 更改 NPM 下载源为淘宝源,并设置…...

Vue中的class和style绑定
聚沙成塔每天进步一点点 本文内容 ⭐ 专栏简介动态绑定class对象语法数组语法 动态绑定style对象语法多重值 ⭐ 写在最后 ⭐ 专栏简介 Vue学习之旅的奇妙世界 欢迎大家来到 Vue 技能树参考资料专栏!创建这个专栏的初衷是为了帮助大家更好地应对 Vue.js 技能树的学习…...

出版实务 | 出版物的成本及其构成
文章目录 出版物成本的总体构成直接成本开发成本制作成本 间接成本期间费用 本量利分析原则特点和作用变动成本项目固定成本项目本量利分析的基本公式及其应用定价发行折扣率销售数量单位销售收入销售收入总额单位销售税金销售税金总额变动成本总额单位变动成本固定成本总额单位…...
docker 部署项目的操作文档,安装nginx
目录 1 部署环境检查2 相关知识点2.1 docker默认镜像存放地址2.2 docker 的镜像都是tar 包?2.3 Docker-compose 是直接使用镜像创建容器?2.4 Docker Compose down 就是将容器删除?2.5 删除,会删除挂载嘛2.6 DockerFile 和 docker …...

spring boot 源码解读与原理分析
一、概述 Spring Boot是一个基于Spring框架的开源项目,旨在简化Spring应用程序的创建和部署。它通过自动配置和约定大于配置的原则,使得开发者能够快速构建独立、可运行的、生产级别的Spring应用程序。本文将对Spring Boot的源码进行解读,并…...

Python基础(二十四、JSON和pyecharts)
文章目录 一、JSON1.JSON介绍2.JSON格式数据转化3.示例 二、pyecharts1.安装pyecharts包2.查看官方示例 三、开发示例 一、JSON 1.JSON介绍 JSON是一种轻量级的数据交互格式,采用完全独立于编程语言的文本格式来存储和表示数据(就是字符串)…...

Java 并发之《深入理解 JVM》关于 volatile 累加示例的思考
在周志明老师的 《深入理解 JVM》一书中关于 volatile 关键字线程安全性有一个示例代码(代码有些许改动,语义一样): public class MyTest3 {private static volatile int race 0;private static void increase() {race;}public …...

拆个汽车配件里的压电陶瓷片,用示波器和面包板实测它的‘发电’与‘震动’能力
从废弃汽车配件到电子实验神器:压电陶瓷片的深度拆解与实战应用 引言:压电陶瓷的奇妙世界 在电子爱好者的眼中,垃圾堆可能是最有趣的"宝藏库"。那些被丢弃的汽车配件、旧家电和电子设备中,往往藏着令人惊喜的元器件。其…...
)
从‘密码长度’到‘任意代码执行’:手把手复现攻防世界int_overflow靶场(附Python3 EXP)
从密码长度到系统控制:整数溢出漏洞实战攻防全解析 在网络安全领域,整数溢出漏洞往往因其隐蔽性而被开发者忽视,却可能成为攻击者打开系统大门的金钥匙。本文将带您深入一个典型场景:如何通过精心构造的密码输入,从简单…...
的3个隐藏技巧:从实时预览到多设备联调)
DevEco Studio预览器(Previewer)的3个隐藏技巧:从实时预览到多设备联调
DevEco Studio预览器的3个隐藏技巧:从实时预览到多设备联调 在鸿蒙应用开发中,DevEco Studio的Previewer功能早已超越了简单的UI查看工具。对于已经掌握基础操作的中级开发者而言,如何将这个看似简单的预览窗口转变为高效调试利器࿰…...

Linux依赖冲突回溯生产排障流程
Linux依赖冲突回溯生产排障流程这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在依赖冲突回溯,重点讨论库版本关系、安装失败和升级影响。在真实生产环境中,依赖冲突回溯相关问题往往不会以单一错误形式出现,而是混杂在日志、…...
)
保姆级教程:用VMware Workstation Pro 16给虚拟机装Win11,手把手教你用Ghost镜像(含UEFI/BIOS切换避坑)
VMware Workstation Pro 16实战:零基础Ghost安装Windows 11全流程解析 在虚拟化技术日益普及的今天,使用VMware Workstation Pro创建虚拟机已成为开发者测试新系统的首选方案。特别是对于Windows 11这样的新操作系统,直接在物理机上安装可能存…...

C++ STL set与multiset容器:红黑树实现、核心操作与性能优化指南
1. 容器概览:为什么我们需要 set 和 multiset?在C的日常开发里,尤其是处理需要快速查找、去重或排序的数据集合时,std::set和std::multiset这两个关联容器出场率极高。很多刚从顺序容器(如vector、list)转过…...

从ok-skills项目解析技能树:设计理念、技术实现与工程实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“ok-skills”。光看这个名字,可能有点摸不着头脑,但点进去一看,发现这是一个关于“技能树”或“知识图谱”的开源项目。简单来说,它试图用一种结构化的…...

C++中的重载、覆盖、隐藏介绍
前几天面试时被问及C中的覆盖、隐藏,概念基本答不上来,只答了怎么用指针实现多态,也还有遗漏。最终不欢而散。回来后在网上查找学习了一番,做了这个总结。其中部分文字借用了别人的博客,望不要见怪。概念一、重载&…...

避坑指南:STM32F407的ADC多通道采样,你的数据顺序真的对了吗?
STM32F407多通道ADC采样数据错位排查手册 在嵌入式开发中,ADC多通道采样是常见需求,但数据顺序错乱问题却让不少工程师深夜加班。上周有位同行发来求助:他的四通道温度监测系统运行两周后,突然出现通道数据交叉污染,导…...

为什么你的NotebookLM总“读不懂”Nature论文?生信老炮拆解7类专业语义断层及5种Prompt工程修复方案
更多请点击: https://kaifayun.com 第一章:NotebookLM生物技术研究 NotebookLM 是 Google 推出的基于 AI 的研究协作者工具,专为知识密集型工作流设计。在生物技术领域,它可高效整合海量文献、实验报告与基因组数据库摘要&#x…...