Redis性能大挑战:深入剖析缓存抖动现象及有效应对的战术指南
在实际应用中,你是否遇到过这样的情况,本来Redis运行的好好的,响应也挺正常,但突然就变慢了,响应时间增加了,这不仅会影响用户体验,还会牵连其他系统。
那如何排查Redis变慢的情况呢?首先有个问题需要确定,就是确定Redis是否真的变慢了。
Redis基线性能
要判断Redis是否变慢了,一个最直接的方法就是查看Redis的响应时间。
大部分情况下,Redis的延迟很低,但是在某些情况下,Redis会出现很高的延迟,可能会达到几秒甚至更长,不过持续的时间又不长,这到底是怎么情况呢?如果出现了响应延迟到秒级别就可以确定Redis变慢了。
首先需要先确定Redis的延迟绝对值,但是在不同运行环境下,Redis的绝对性能是不同的。所以就需要当前环境的基线性能,所谓基线性能,就是一个系统在低压力、无干扰下的基本性能,这个性能只由当前软硬件环境配置决定。
基线性能可以通过Redis提供的命令来确定,具体为在redis-cli中添加--intrinsic-latency选项,可以用来检测和统计Redis在运行期间内的最大延迟,这就可以作为基线性能。
redis-cli -h localhost --intrinsic-latency 120
Max latency so far: 1 microseconds.
Max latency so far: 29 microseconds.
Max latency so far: 31 microseconds.
Max latency so far: 34 microseconds.
Max latency so far: 53 microseconds.
Max latency so far: 68 microseconds.
Max latency so far: 103 microseconds.
Max latency so far: 106 microseconds.
Max latency so far: 142 microseconds.
Max latency so far: 158 microseconds.
Max latency so far: 164 microseconds.
Max latency so far: 273 microseconds.
Max latency so far: 296 microseconds.
Max latency so far: 673 microseconds.
Max latency so far: 946 microseconds.
Max latency so far: 2138 microseconds.
Max latency so far: 2234 microseconds.
Max latency so far: 16164 microseconds.2383205581 total runs (avg latency: 0.0504 microseconds / 50.35 nanoseconds per run).
Worst run took 321018x longer than the average latency.在自己的电脑上运行命令后,会打印120秒内检测到的最大延迟,可以看到这里的最大延迟为16164微妙,16ms左右。一般情况下,检测120s的时长已经够了。
一般来说,运行时响应时间和基线性能做对比,如果响应时间达到了基线性能的2倍以上,就可以认定Redis变慢了。
Redis变慢的原因
一旦发现变慢了,接下来就要查找原因解决这个问题了。这个过程要基于Redis本身的工作原理,并结合和它交互的操作系统、存储以及网络等外部系统的关键机制,在借助一些辅助工具来定位问题,并指定行之有效的解决方案。
Redis变慢的原因有几下几点,如图所示: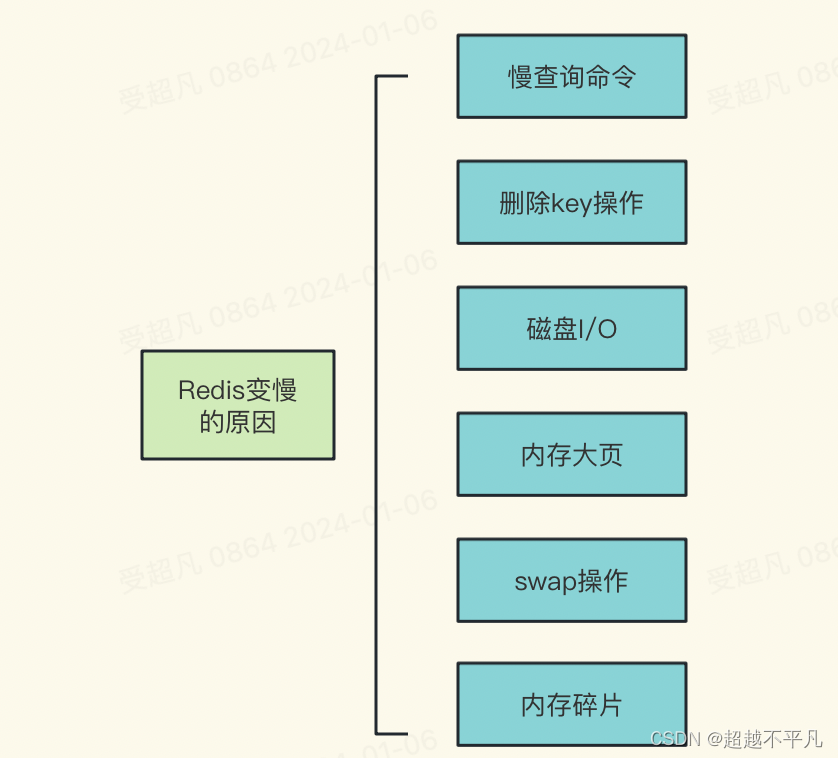
慢查询指令
慢查询命令,指在Redis中执行速度慢的命令,这会导致Redis延迟增加。Redis提供的命令操作很多,并不是所有命令都慢,这和命令操作的复杂度有关,所以我们必须知道不同命令的复杂度。
比如,操作的value为String类型时,由于操作的事hash表,这个操作的复杂度是固定的,都是O(1),除非出现了hash碰撞严重。但操作的数据类型为集合时,如果集合中包含大量的元素,那这个操作复杂度是比较高的,会比较耗时。
Redis官网提供了各个命令的复杂度:Commands | Redis![]() https://redis.io/commands/ 如果有复杂的操作,就要考虑是否需要用简单的命令来替换。如果使用keys命令,查询大量的key,也会导致慢查询,因为需要扫描所有的键值对,所以生产环境要禁用这样的命令。
https://redis.io/commands/ 如果有复杂的操作,就要考虑是否需要用简单的命令来替换。如果使用keys命令,查询大量的key,也会导致慢查询,因为需要扫描所有的键值对,所以生产环境要禁用这样的命令。
删除key操作
如果Redis中key过期了是会被自动删除的,这也是Redis的回收机制,Redis 的 key可以设置过期时间,默认情况下,每100ms就会扫描一次,删除过期的key,具体如下:
- 采样ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP个数的key,并将其中过期的key全部删除;
- 如果超过25%的key过期了,则重复删除过程,直到过期key的比例降至25%以下。
如果触发了第二条规则,Redis就会一直删除以释放内存空间。注意,删除操作是阻塞的(Redis 4.0提供了异步机制减少阻塞)。所以一旦触发了就会一直删除key,这样一来,就没办法给客户端提供服务了。
磁盘I/O:AOF
为了保证数据的可靠性,Redis提供了AOF和RDB两种机制(想具体了解请查看:Redis持久化(AOF、RDB)用到的写时复制到底是什么-CSDN博客)。其中AOF提供了三种写回策略:always、everysec、no,这三种写回策略依赖文件系统来完成,也就是write和fsync。
write把日志写到内核的缓冲区,就可以返回了,并不需要等待日志实际写回磁盘;而fsync需要把日志记录写回到磁盘才能返回,时间较长。
当写回策略配置为everysec和always时,Redis需要调用fsync把日志写回磁盘。但是这两种写回策略的具体情况不一样。但不管怎么说,都会涉及到写回磁盘,而且fsync通常比较耗时,如果Redis主线程执行写回,就会造成阻塞。
另外AOF日志重写时,也容易阻塞主线程,所以Redis使用了子线程来完成该操作。但是AOF重写会对磁盘又大量的IO操作,同时fsync又需要等到数据写到磁盘才能返回,所以,当AOF重写的压力比较大时,就会导致fsync阻塞,虽然fsync由后台子线程完成,但是主线程会监测fsync的执行进度。
当主线程使用子线程执行了一次fsync,需要再次把接收的数据写回磁盘,如果主线程发现上一次的fsync还没有执行完,那么它就会阻塞。所以,如果后台线程执行fsync频繁阻塞的话,主线程也会阻塞,导致Redis性能变慢。
内存大页
内存大页机制也会影响Redis性能。Linux内核从2.6.38开始支持内存大页,支持2MB大小的内存页分配,而常规的也大小是4KB。你可能会说,Redis是内存数据库,内存大页对Redis不是有好处的吗,减少了内存的分配,但是任何事都有两面性,这时一个权衡的过程。
Redis为了提高可靠性,提供了持久化的机制。这个过程需要额外的线程来执行,所以不会阻塞主线程为客户端提供服务。如果在持久化的过程中,客户端修改了数据,Redis会才用写时复制(Copy On Write)机制,数据一旦修改了不会直接修改内存中的数据,而是复制一份,然后再进行修改。
如果采用了内存大页,那Redis就需要拷贝该大页。如果关闭了内存大页,那需要拷贝的页数据只有4kb,可见内存大页会复制大量数据。
所以正常情况下,关闭内存大页就可以了。
swap操作
操作系统swap是将内存数据在内存和磁盘来回换入核换出的机制,涉及到磁盘的读写。所以一旦涉及到了swap,其性能都会收到磁盘性能的影响。
Redis是内存数据库,内存使用量大,如果用Redis保存海量数据,而且没有控制好内存使用量,就可能会触发swap机制,从而影响性能。一旦触发swap机制,Redis需要操作磁盘才能完成,这回极大的降低Redis的性能。
关于海量数据的处理请参考:面对海量数据Redis如何应对-CSDN博客
Redis对于swap的排查有现成的命令,具体这里不做详细介绍了。
内存碎片
内存碎片很好理解,明明有内存空间,但是申请时就是无法分配需要的内存空间,这对于使用内存的Redis来说无疑影响巨大。
内存碎片的原因
- 内存不是按需分配的,操作系统为了减少内存的分配次数,每次都是按照固定大小进行内存分配的,例如8字节、16字节、32字节等,比如申请了20字节的内存,但是实际上会分配32字节,此时如果在写入5字节数据,就不用再申请内存了,减少了内存申请的次数。
- Redis键值对大小不一和删除操作的影响,内存分配器只能按照固定大小分配内存。所以,分配的内存空间一般都会比申请的空间大一些,不会完全一直,这本身就会造成一定碎片,降低内存空存储效率。键值对会被修改或删除,这会导致空间的扩容和释放。一方面,如果修改后的键值对变大或变小了,就需要占用额外的空间或释放不用的空间。另一方面,删除的键值对就不在需要内存空间了,此时会把空间释放出来,变成空闲空间。
如何判断内存碎片
Redis是内存数据库,内存利用率的高低直接关系到Redis运行效率的高低。为了让用户能监控到实时的内存使用情况,Redis自身提供了info命令,可以用来查询内存使用的详细信息
info memory
# Memory
used_memory:1143520
used_memory_human:1.09M
used_memory_rss:1114112
used_memory_rss_human:1.06M
used_memory_peak:1144672
used_memory_peak_human:1.09M
used_memory_peak_perc:99.90%
used_memory_overhead:1096754
used_memory_startup:1079248
used_memory_dataset:46766
used_memory_dataset_perc:72.76%
allocator_allocated:1098416
allocator_active:1076224
allocator_resident:1076224
total_system_memory:8589934592
total_system_memory_human:8.00G
used_memory_lua:37888
used_memory_lua_human:37.00K
used_memory_scripts:0
used_memory_scripts_human:0B
number_of_cached_scripts:0
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
allocator_frag_ratio:1.1
allocator_frag_bytes:18446744073709529424
allocator_rss_ratio:1.00
allocator_rss_bytes:0
rss_overhead_ratio:1.04
rss_overhead_bytes:37888
mem_fragmentation_ratio:1.01
mem_fragmentation_bytes:15696
mem_not_counted_for_evict:0
mem_replication_backlog:0
mem_clients_slaves:0
mem_clients_normal:16986
mem_aof_buffer:0
mem_allocator:libc
active_defrag_running:0
lazyfree_pending_objects:0mem_fragmentation_ratio指标表示内存碎片化率,该值大于1但小于1.5时,这种情况是正常的,因为内存碎片是无法避免的。如果该值大于1.5,就表名内存碎片化率比较严重了,超过了50%,这时需要采取措施来处理内存碎片化。
Redis从4.0版本后提供了专门清理内存碎片化的参数,通过该参数来设置内存碎片化的清理的开始和结束时机,以及占用CPU比例,从而减少碎片清理对Redis本身请求处理的性能影响。
config set activedefrag yes这个命令只是启动了自动清理功能,但具体什么时候清理,会受下面两个参数的控制。这两个参数分别设置了触发内存清理的一个条件,如果同时满足这两个条件,就开始清理,清理过程中,只要有一个条件不满足,就停止清理。
- active-defrag-ignore-bytes 100mb:表示内存碎片的字节数达到100MB时,就开始清理。
- active-defrag-threshold-lower 10:表示内存碎片空间占操作系统分配给Redis的总空间比例达到10%时,开始清理。
总结
关于Redis变慢的问题排查就介绍到这里,不知道你有没有清晰的思路,欢迎关注并留言讨论。
相关文章:
Redis性能大挑战:深入剖析缓存抖动现象及有效应对的战术指南
在实际应用中,你是否遇到过这样的情况,本来Redis运行的好好的,响应也挺正常,但突然就变慢了,响应时间增加了,这不仅会影响用户体验,还会牵连其他系统。 那如何排查Redis变慢的情况呢?…...
基于SpringBoot的教学管理系统
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式 🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 &…...
)
机器学习之独热编码(One-Hot)
一、背景 在机器学习算法中,我们经常会遇到分类特征,例如:人的性别有男女,祖国有中国,美国,法国等。这些特征值并不是连续的,而是离散的,无序的。通常我们需要对其进行特征数字化。…...
IIS+SDK+VS2010+SP1+SQL server2012全套工具包及安装教程
前言 今天花了两个半小时安装这一整套配置,这个文章的目标是将安装时间缩短到1个小时 正文 安装步骤如下: VS2010 —> service pack 1 —>SQL server2012 —> IIS —> SDK 工具包链接如下: https://pan.baidu.com/s/1WQD-KfiUW…...

【昕宝爸爸小模块】HashMap用在并发场景存在的问题
HashMap用在并发场景存在的问题 一、✅典型解析1.1 ✅JDK 1.8中1.2 ✅JDK 1.7中1.3 ✅如何避免这些问题 二、 ✅HashMap并发场景详解2.1 ✅扩容过程2.2 ✅ 并发现象 三、✅拓展知识仓3.1 ✅1.7为什么要将rehash的节点作为新链表的根节点3.2 ✅1.8是如何解决这个问题的3.3 ✅除了…...

数据库索引
1、什么是索引?为什么要用索引? 1.1、索引的含义 数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询,更新数据库中表的数据。索引的实现通常使用B树和变种的B树(MySQL常用的索引就是B树&…...
开源知识库工具推荐:低成本搭建知识库
在信息爆炸的时代,企业和个体对知识的存储和管理需求日益增强。开源知识库工具因其开源、免费、高效的特性,成为了众多组织和个人的首选。如果你正在寻找一款优秀的开源知识库工具,本文将为你推荐三款性能优异的产品,感兴趣就往下…...

C# Chart控件
// 定义图表区域 this.chart1.ChartAreas.Clear(); ChartArea chartArea1 new ChartArea("C1"); this.chart1.ChartAreas.Add(chartArea1); //定义存储和显示点的容器 this.chart1.Series.Clear(); Series series1 new Series("OK"); //series1.ChartAre…...
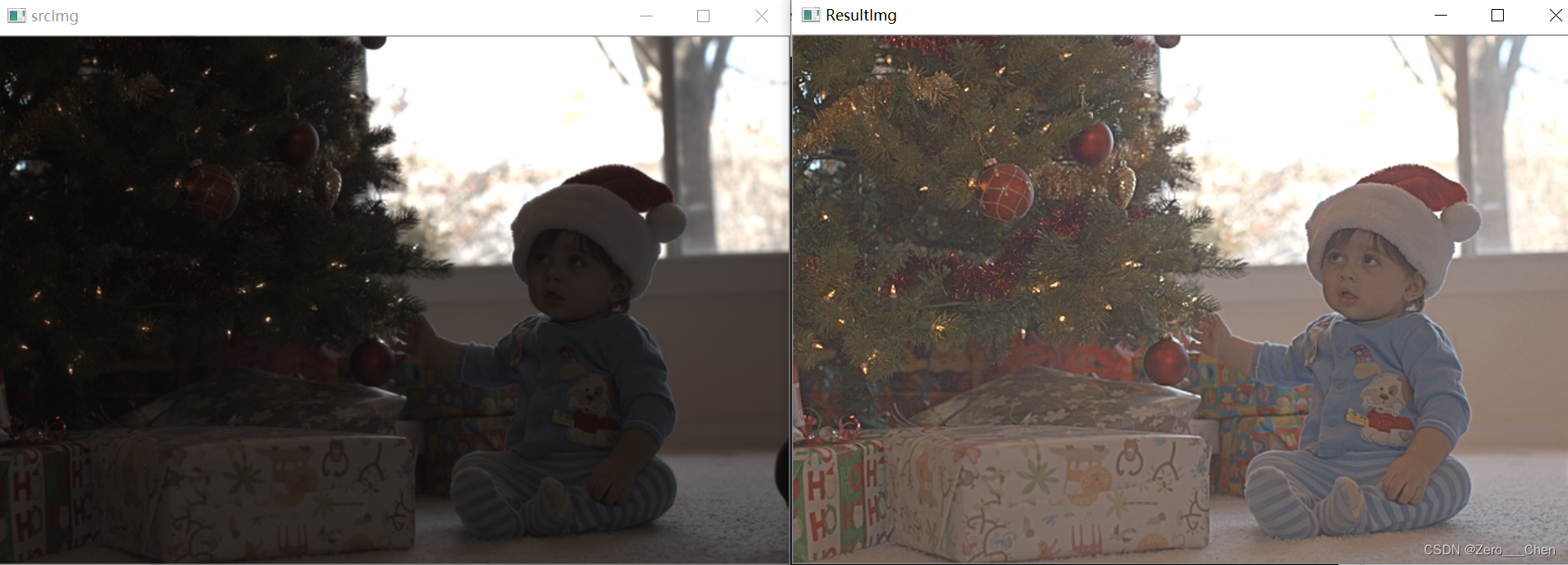
OpenCV C++ 图像处理实战 ——《多尺度自适应Gamma矫正的低照图像增强》
OpenCV C++ 图像处理实战 ——《多尺度自适应Gamma矫正的低照图像增强》 一、结果演示二、多尺度自适应Gamma矫正的低照度图像增强2.1HSI颜色空间2.1.1 功能源码2.2 自适应于直方图分布的 Gamma 矫正2.2.1 功能源码2.3 多尺度 Retinex 分解与明度增强2.3.1 功能源码三、源码测试…...

原型模式
为什么要使用原型模式 不用重新初始化对象,而是动态地获得对象运行时的状态。适用于当创建对象的成本较高时,如需进行复杂的数据库操作或复杂计算才能获得初始数据。 优点是可以隐藏对象创建的细节,减少重复的初始化代码;可以在…...

linux centos 账户管理命令
在CentOS或其他基于Linux的系统上,账户管理涉及到用户的创建、修改、删除以及密码的管理等任务。 linux Centos账户管理命令 1 创建用户: useradd username 这将创建一个新用户,但默认不会创建家目录。如果想要创建家目录,可以…...
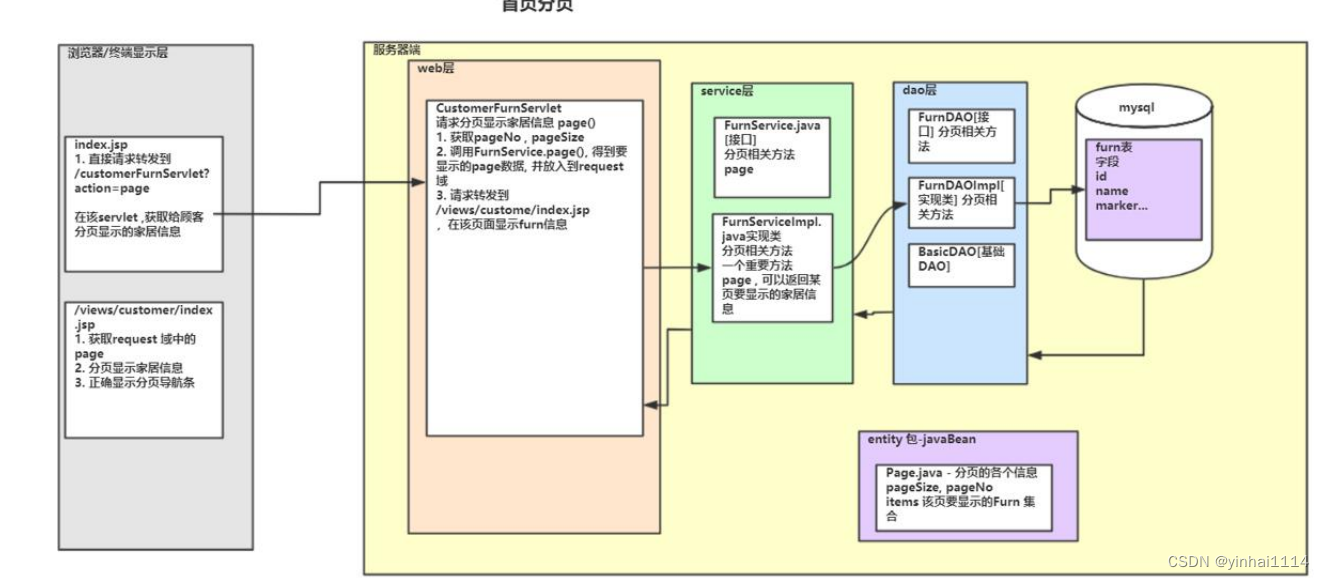
【JavaWeb学习笔记】19 - 网购家居项目开发(上)
一、项目开发流程 程序框架图 项目具体分层方案 MVC 1、说明是MVC MVC全称: Mode模型、View视图、Controller控制器。 MVC最早出现在JavaEE三层中的Web层,它可以有效的指导WEB层的代码如何有效分离,单独工作。 View视图:只负责数据和界面的显示&…...
强化学习的数学原理学习笔记 - RL基础知识
文章目录 Roadmap🟡基础概念贝尔曼方程(Bellman Equation)基本形式矩阵-向量形式迭代求解状态值 vs. 动作值 🟡贝尔曼最优方程(Bellman Optimality Equation,BOE)基本形式迭代求解 本系列文章介…...

winSCP是什么?它有什么功能和特性?它值不值得我们去学习?我们该如何去学习呢?
WinSCP是一款免费的开源SFTP、SCP、FTP和WebDAV客户端,用于Windows操作系统。它提供了一个图形化界面,使用户可以方便地在本地计算机和远程计算机之间传输文件。 WinSCP支持SSH加密通信和多种认证方法,包括密码、公钥和键盘交互。它还支持自…...

SpringBoot的数据层解决方案
🙈作者简介:练习时长两年半的Java up主 🙉个人主页:程序员老茶 🙊 ps:点赞👍是免费的,却可以让写博客的作者开心好久好久😎 📚系列专栏:Java全栈,…...

极客时间-《如何成为学习高手》文章笔记 + 个人思考
极客时间-《如何成为学习高手》文章笔记 个人思考 底层思维高效学习05|教你全面提升专注力,学习时不再走神06|教你高效复习:巧用学习神器取得好成绩07|我考北大中文系时,15 天背下 10 门专业课的连点成线法…...

【前端】下载文件方法
1.window.open 我最初使用的方法就是这个,只要提供了文件的服务器地址,使用window.open也就是在新窗口打开,这时浏览器会自动执行下载。 2.a标签 其实window.open和a标签是一样的,只是a标签是要用户点击触发,而wind…...
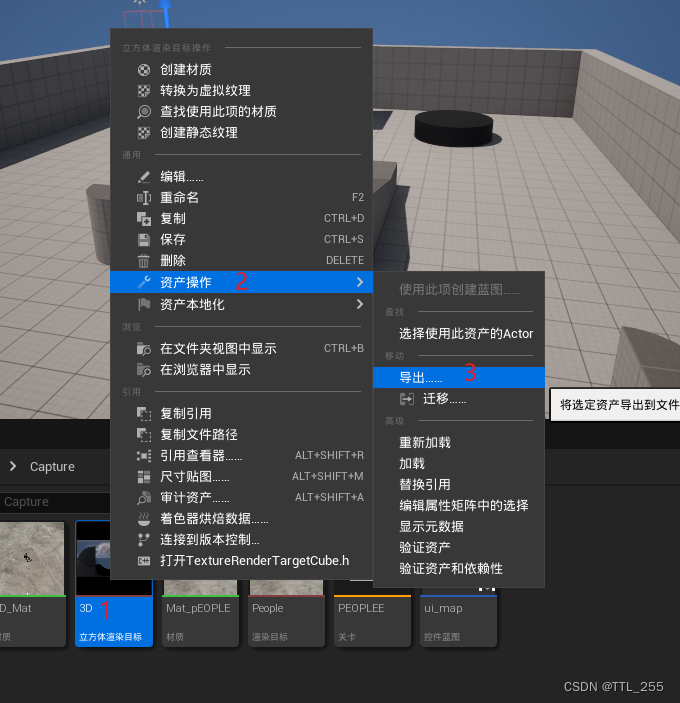
虚幻UE 材质-纹理 1
本篇笔记主要讲两个纹理内的内容:渲染目标和媒体纹理 媒体纹理可以参考之前的笔记:虚幻UE 媒体播放器-视频转成材质-播放视频 所以本篇主要讲两个组件:场景捕获2D、场景捕获立方体 两个纹理:渲染目标、立方体渲染目标 三个功能&am…...

回归预测 | Matlab实现RIME-HKELM霜冰算法优化混合核极限学习机多变量回归预测
回归预测 | Matlab实现RIME-HKELM霜冰算法优化混合核极限学习机多变量回归预测 目录 回归预测 | Matlab实现RIME-HKELM霜冰算法优化混合核极限学习机多变量回归预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab实现RIME-HKELM霜冰算法优化混合核极限学习机多变…...

【AWS系列】巧用 G5g 畅游Android流媒体游戏
序言 Amazon EC2 G5g 实例由 AWS Graviton2 处理器提供支持,并配备 NVIDIA T4G Tensor Core GPU,可为 Android 游戏流媒体等图形工作负载提供 Amazon EC2 中最佳的性价比。它们是第一个具有 GPU 加速功能的基于 Arm 的实例。 借助 G5g 实例,游…...

Habitat-Lab:Meta开源具身AI仿真平台,从零搭建智能体训练场
1. 项目概述:从虚拟到现实的智能体训练场如果你对机器人、具身智能或者强化学习感兴趣,那么“Habitat-Lab”这个名字你大概率不会陌生。简单来说,Habitat-Lab是一个由Meta AI(前Facebook AI Research)开源的、用于具身…...

Arm CADI 2.0调试接口架构与多调试器协同实践
1. CADI接口调试架构深度解析在嵌入式系统开发领域,调试接口的设计质量直接影响着开发效率。CADI(Component Architecture Debug Interface)作为Arm推出的标准化调试接口,其2.0版本通过创新的架构设计解决了传统调试方案中的诸多痛…...

PaddleOCR-VL 1.5 + ROCm:让开发者从文档解析 Demo 走向高性能生产部署
很多文档解析 Demo 看起来都很惊艳:上传一张图片,模型识别出文字、表格、公式,甚至还能输出 Markdown。但真正进入生产环境后,问题很快就会暴露出来。企业里的文档不是干净样例,而是 PDF、扫描件、合同、票据、财报、检…...
Pixelle-Video完整指南:如何用AI在3分钟内创建专业短视频
Pixelle-Video完整指南:如何用AI在3分钟内创建专业短视频 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 在当今内容爆炸的时…...

猫抓Cat-Catch:浏览器媒体资源捕获终极指南
猫抓Cat-Catch:浏览器媒体资源捕获终极指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾遇到过想下载网页视频却找不到下载…...

Dify工作流实战指南:零代码构建企业级应用系统的终极方案
Dify工作流实战指南:零代码构建企业级应用系统的终极方案 【免费下载链接】Awesome-Dify-Workflow 分享一些好用的 Dify DSL 工作流程,自用、学习两相宜。 Sharing some Dify workflows. 项目地址: https://gitcode.com/GitHub_Trending/aw/Awesome-Di…...

终极免费音频智能分割工具:快速解放你的音频处理工作流
终极免费音频智能分割工具:快速解放你的音频处理工作流 【免费下载链接】audio-slicer A simple GUI application that slices audio with silence detection 项目地址: https://gitcode.com/gh_mirrors/aud/audio-slicer 还在为处理长音频文件而烦恼吗&…...

基于本地大模型的字幕翻译:LM Studio集成方案与实战优化
1. 项目概述:当本地大模型遇上字幕翻译最近在折腾本地大模型应用时,发现了一个挺有意思的场景:字幕翻译。很多朋友喜欢看海外影视剧或学习资料,但苦于没有高质量的中文字幕。在线翻译工具要么有字数限制,要么担心隐私泄…...

5分钟搭建Windows离线语音转文字系统:TMSpeech让你的会议记录零压力
5分钟搭建Windows离线语音转文字系统:TMSpeech让你的会议记录零压力 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 在数字化办公时代,实时语音转文字已成为提升工作效率的关键技术。TMSpeec…...

CCPD车牌数据集预处理避坑指南:透视变换原理详解与OpenCV实战
CCPD车牌数据集预处理避坑指南:透视变换原理详解与OpenCV实战 车牌识别系统中,数据预处理的质量直接影响模型性能。CCPD作为目前最全面的中文车牌数据集,其四点标注特性为透视变换提供了基础,但也暗藏诸多陷阱。本文将手把手带您穿…...