环信服务端下载消息文件---菜鸟教程
前言
在服务端,下载消息文件是一个重要的功能。它允许您从服务器端获取并保存聊天消息、文件等数据,以便在本地进行进一步的处理和分析。本指南将指导您完成环信服务端下载消息文件的步骤。
环信服务端下载消息文件是指在环信服务端上,通过调用相应的API接口,从服务器端下载聊天消息、文件等数据的过程。因环信服务端保存的消息漫游是有时间限制,有用户需要漫游全部的消息或者自己服务端做所有消息记录的备份。可以从环信服务端下载消息文件来进行解压,读取消息文件内容进行存储到自己的服务端。
前提条件
- 已在环信即时通讯控制台 开通配置环信即时通讯 IM 服务。
注册环信即时通讯IM - 了解环信 IM REST API 的调用频率限制
- 环信接口文档介绍:
一、下载消息文件
以下将介绍如何通过环信接口获取到的URL来进行下载文件,解压文件,读取文件。
注:
time参数: 历史消息记录查询的起始时间。UTC 时间,使用 ISO8601 标准,格式为 yyyyMMddHH。例如 time 为 2018112717,则表示查询 2018 年 11 月 27 日 17 时至 2018 年 11 月 27 日 18 时期间的历史消息。若海外集群为 UTC 时区,需要根据自己所在的时区进行时间转换。

上图是环信官方文档中给出的获取历史消息记录响应示例。从示例中可以看出我们请求以后可以得到一个URL,这个URL为消息文件的下载URL。
1、下载消息文件环信rest 接口请求代码如下:
String url = "https://{{RestApi}}/{{org_name}}/{{app_name}}/chatmessages/2023122010";
HttpHeaders headers = new HttpHeaders();
headers.add("Content-Type","application/json");
headers.add("Authorization","Bearer Authorization");
Map<String, String> body = new HashMap<>();
HttpEntity<Map<String, String>> entity = new HttpEntity<>(body, headers);
ResponseEntity<Map> response;
try {response = restTemplate.exchange(url, HttpMethod.GET, entity, Map.class);System.out.print("消息文件下载成功---"+response.toString());
} catch (Exception e) {System.out.print("消息文件下载失败---"+e.toString());
}
2、消息文件下载,通过请求环信下载历史消息文件接口获取到的URL 进行下载。
示例代码:
String url = "";
String targetUrl = "";
download(url,targetUrl);
/**
* 根据url下载文件,保存到filepath中
*
* @param url 文件的url
* @param diskUrl 本地存储路径
* @return
*/
public static String download(String url, String diskUrl) {String filepath = "";String filename = "";try {HttpClient client = HttpClients.createDefault();HttpGet httpget = new HttpGet(url);// 加入Referer,防止防盗链 httpget.setHeader("Referer", url);HttpResponse response = client.execute(httpget);HttpEntity entity = response.getEntity();InputStream is = entity.getContent();if (StringUtils.isBlank(filepath)){Map<String,String> map = getFilePath(response,url,diskUrl);filepath = map.get("filepath");filename = map.get("filename");}File file = new File(filepath);file.getParentFile().mkdirs();FileOutputStream fileout = new FileOutputStream(file);byte[] buffer = new byte[cache];int ch = 0;while ((ch = is.read(buffer)) != -1) {fileout.write(buffer, 0, ch);}is.close();fileout.flush();fileout.close();} catch (Exception e) {e.printStackTrace();}return filename;
}/**
* 获取response要下载的文件的默认路径
** @param response* @return */public static Map<String,String> getFilePath(HttpResponse response, String url, String diskUrl) {Map<String,String> map = new HashMap<>();String filepath = diskUrl;String filename = getFileName(response, url);String contentType = response.getEntity().getContentType().getValue();if(StringUtils.isNotEmpty(contentType)){// 获取后缀 String regEx = ".+(.+)$";Pattern p = Pattern.compile(regEx);Matcher m = p.matcher(filename);if (!m.find()) {// 如果正则匹配后没有后缀,则需要通过response中的ContentType的值进行匹配 filename = filename +".gz";}else{if(filename.length()>20){filename = getRandomFileName() + ".gz";}}}if (filename != null) {filepath += filename;} else {filepath += getRandomFileName();}map.put("filename", filename);map.put("filepath", filepath);return map;
}/*** 获取response header中Content-Disposition中的filename值* @param response * @param url* @return*/public static String getFileName(HttpResponse response,String url) {Header contentHeader = response.getFirstHeader("Content-Disposition");String filename = null;if (contentHeader != null) {// 如果contentHeader存在 HeaderElement[] values = contentHeader.getElements();if (values.length == 1) {NameValuePair param = values[0].getParameterByName("filename");if (param != null) {try {filename = param.getValue();} catch (Exception e) {e.printStackTrace();}}}}else{// 正则匹配后缀 filename = getSuffix(url);}return filename;
}/**
* 获取随机文件名
*
* @return
*/
public static String getRandomFileName() {return String.valueOf(System.currentTimeMillis());
}/**
* 获取文件名后缀
* @param url
* @return
*/
public static String getSuffix(String url) {// 正则表达式“.+/(.+)$”的含义就是:被匹配的字符串以任意字符序列开始,后边紧跟着字符“/”, // 最后以任意字符序列结尾,“()”代表分组操作,这里就是把文件名做为分组,匹配完毕我们就可以通过Matcher // 类的group方法取到我们所定义的分组了。需要注意的这里的分组的索引值是从1开始的,所以取第一个分组的方法是m.group(1)而不是m.group(0)。 String regEx = ".+/(.+)$";Pattern p = Pattern.compile(regEx);Matcher m = p.matcher(url);if (!m.find()) {// 格式错误,则随机生成个文件名 return String.valueOf(System.currentTimeMillis());}return m.group(1);}
- url为第一步中从环信下载历史消息文件接口中请求返回的url(消息文件下载地址)
- targetUrl 为下载的本地存储路径
下载以后从对应的路径下就可以看到所下载的文件。

3、消息文件解压,下载完的文件是以.gz结尾的压缩文件,需要对压缩文件进行解压
public static void unGzipFile(String gzFilePath,String directoryPath) {String ouputfile = "";try {//建立gzip压缩文件输入流 FileInputStream fin = new FileInputStream(gzFilePath);//建立gzip解压工作流 GZIPInputStream gzin = new GZIPInputStream(fin);//建立解压文件输出流// ouputfile = sourcedir.substring(0,sourcedir.lastIndexOf('.'));// ouputfile = ouputfile.substring(0,ouputfile.lastIndexOf('.')); FileOutputStream fout = new FileOutputStream(directoryPath);int num;byte[] buf=new byte[1024];while ((num = gzin.read(buf,0,buf.length)) != -1) {fout.write(buf,0,num);}gzin.close();fout.close();fin.close();} catch (Exception ex){System.err.println(ex.toString());}return;}
gzFilePath:压缩文件路径
directoryPath:加压到的文件目录路径
解压后的文件如下图所示:

4、文件读取,将解压后的文件读取出来
FileInputStream inputStream = null;
try {inputStream = new FileInputStream("/Users/liupeng/Downloads/download/1234567890");BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));String str = null;long i = 0;while(true){try {if (!((str = bufferedReader.readLine()) != null)) break;} catch (IOException e) {e.printStackTrace();}JSONObject jo = JSONObject.parseObject(str);System.out.println("==========================================" + i);System.out.println("消息id:" + jo.get("msg_id"));System.out.println("发送id:" + jo.get("from"));System.out.println("接收id:" + jo.get("to"));System.out.println("服务器时间戳:" + jo.get("timestamp"));System.out.println("会话类型:" + jo.get("chat_type"));System.out.println("消息扩展:" + jo.getJSONObject("payload").get("ext"));System.out.println("消息体:" + jo.getJSONObject("payload").getJSONArray("bodies").get(0));i ++;if (i > 100) break;}//close try {inputStream.close();bufferedReader.close();} catch (IOException e) {e.printStackTrace();}} catch (FileNotFoundException e) {e.printStackTrace();
}
解析完以后日志打印如下:
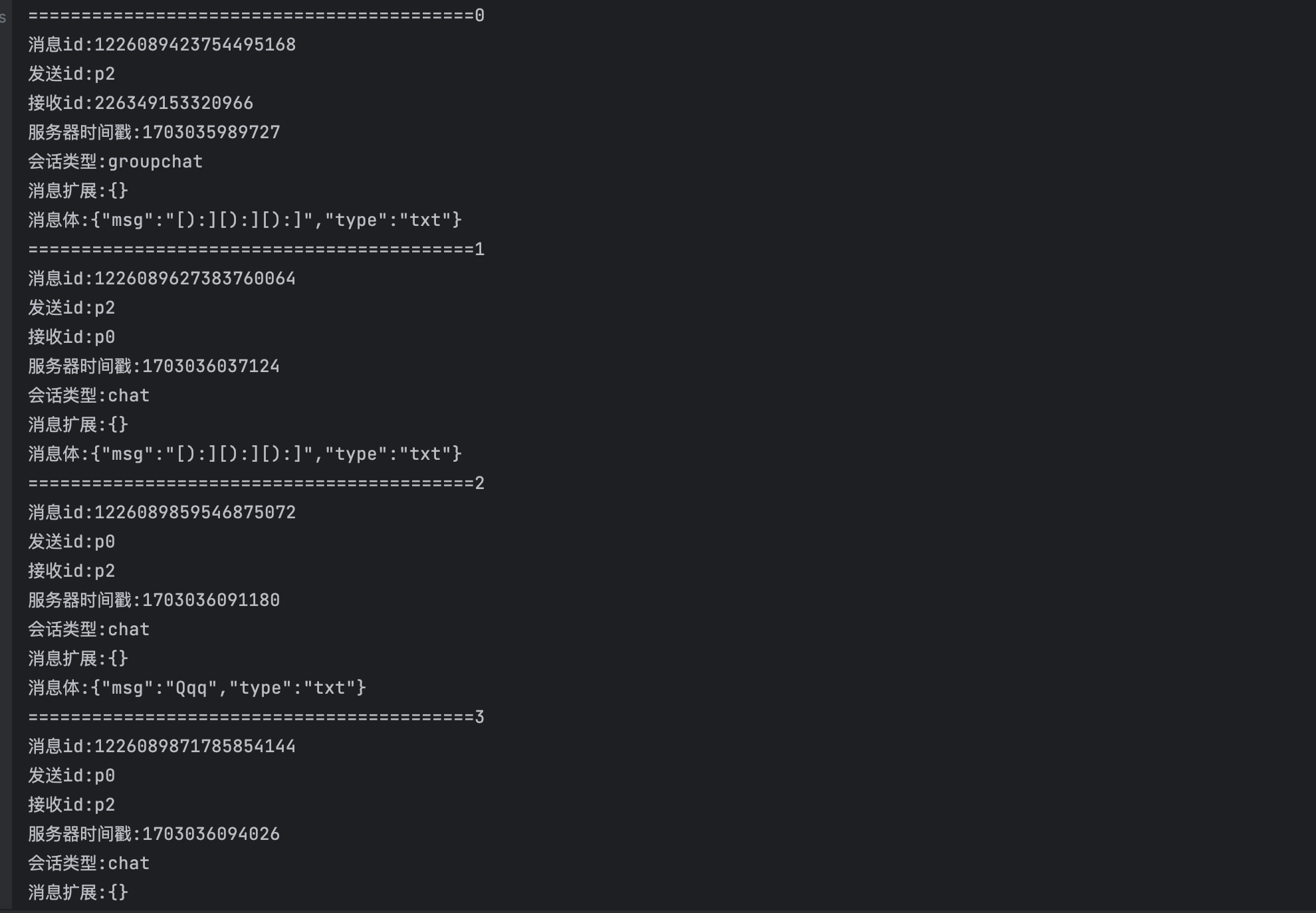
至此,解析完以后可以将解析的数据进行存储。
相关文档:
注册环信即时通讯IM:https://console.easemob.com/user/register
环信IM集成文档:https://docs-im-beta.easemob.com/document/ios/quickstart.html
IMGeek社区支持:https://www.imgeek.net/
相关文章:
环信服务端下载消息文件---菜鸟教程
前言 在服务端,下载消息文件是一个重要的功能。它允许您从服务器端获取并保存聊天消息、文件等数据,以便在本地进行进一步的处理和分析。本指南将指导您完成环信服务端下载消息文件的步骤。 环信服务端下载消息文件是指在环信服务端上,通过调…...
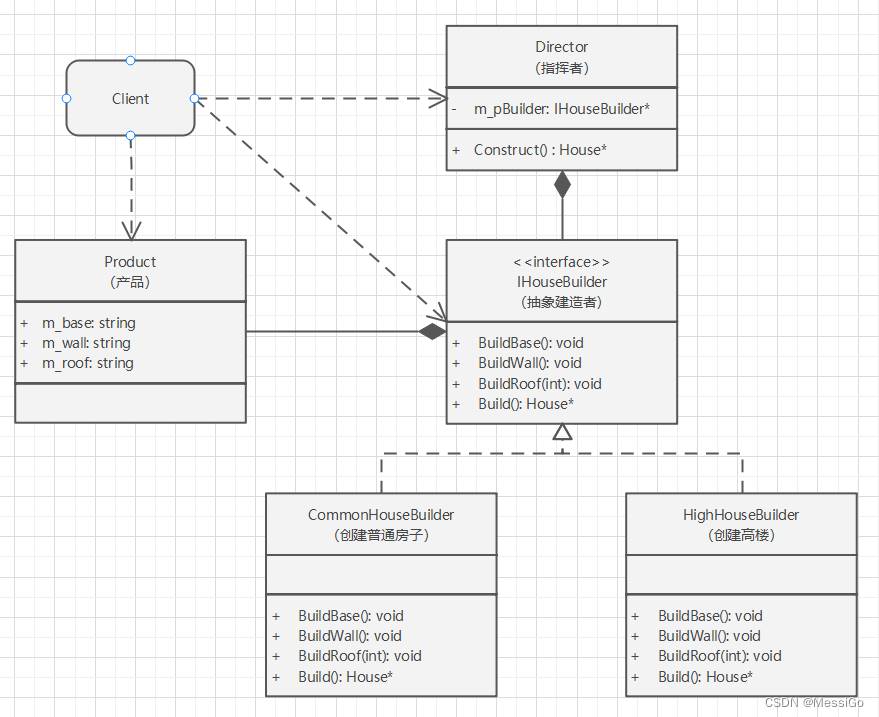
创建型模式 | 建造者模式
一、建造者模式 1、原理 建造者模式又叫生成器模式,是一种对象的构建模式。它可以将复杂对象的建造过程抽象出来,使这个抽象过程的不同实现方法可以构造出不同表现(属性)的对象。创建者模式是一步一步创建一个复杂的对象…...

MVC设计模式
在当今的软件开发领域,MVC(Model-View-Controller)设计模式已经成为了一种广泛使用的架构模式。它为应用程序提供了一种结构化的方法,将数据、用户界面和业务逻辑分开,从而使得应用程序更易于维护、扩展和重用。 一、…...
 ERROR: CreateProcessEntryCommon:493: chdir 错误解决)
WSL (2103) ERROR: CreateProcessEntryCommon:493: chdir 错误解决
[TOC](WSL (2103) ERROR: CreateProcessEntryCommon:493: chdir 错误解决) 1. 错误信息 <3>WSL (2103) ERROR: CreateProcessEntryCommon:493: chdir(/mnt/d/Program Files/PowerShell/7) failed 52. 解决方法 wsl --shutdownwslrefer: https://github.com/microsoft/…...
【二、自动化测试】为什么要做自动化测试?哪种项目适合做自动化?
自动化测试是一种软件测试方法,通过编写和使用自动化脚本和工具,以自动执行测试用例并生成结果。 自动化旨在替代手动测试过程,提高测试效率和准确性。 自动化测试可以覆盖多种测试类型,包括功能测试、性能测试、安全测试等&…...
)
用ChatGPT来造一个ChatGPT:计算机领域智能问答系统实践(2)
在PHP语言中,你可以使用MySQL数据库来存储知识库,并使用PHP来实现系统的逻辑。以下是一个简单的示例: 创建数据库表: 首先,创建一个名为 computer_knowledge 的表来存储计算机知识。可以使用以下SQL语句:…...

Ubuntu开机自动挂载硬盘
前言: 因为我的电脑是WIN10 Ubuntu18.04双系统,且两个系统都装在C盘上,而D盘作为数据和代码存储盘,经常会开机就被访问,例如上一次关机前用VS Code访问D盘代码,然后下一次开机的时候打开VSCode发现打不开…...

vue3基础:单文件组件介绍
介绍 Vue 的单文件组件 (即 *.vue 文件,简称 SFC,全称是single file component) 是一种特殊的文件格式,使我们能够将一个 Vue 组件的模板、逻辑与样式封装在单个文件中。下面是一个单文件组件的示例: <script> export def…...

OCR字符识别:开始批量识别身份证信息
身份证信息批量识别OCR是一项解决方案,它能够将身份证照片打包成zip格式或通过URL地址进行提交,并能够识别照片中的文本信息。最终,用户可以将识别结果生成为excel文件进行下载。 API接口功能: 1. 批量识别:支持将多…...
php多小区智慧物业管理系统源码带文字安装教程
多小区智慧物业管理系统源码带文字安装教程 运行环境 服务器宝塔面板 PHP 7.0 Mysql 5.5及以上版本 Linux Centos7以上 统计分析以小区为单位,统计如下数据:小区总栋数、小区总户数、小区总人数、 小区租户数量、小区每月收费金额统计、小区车位统计、小…...
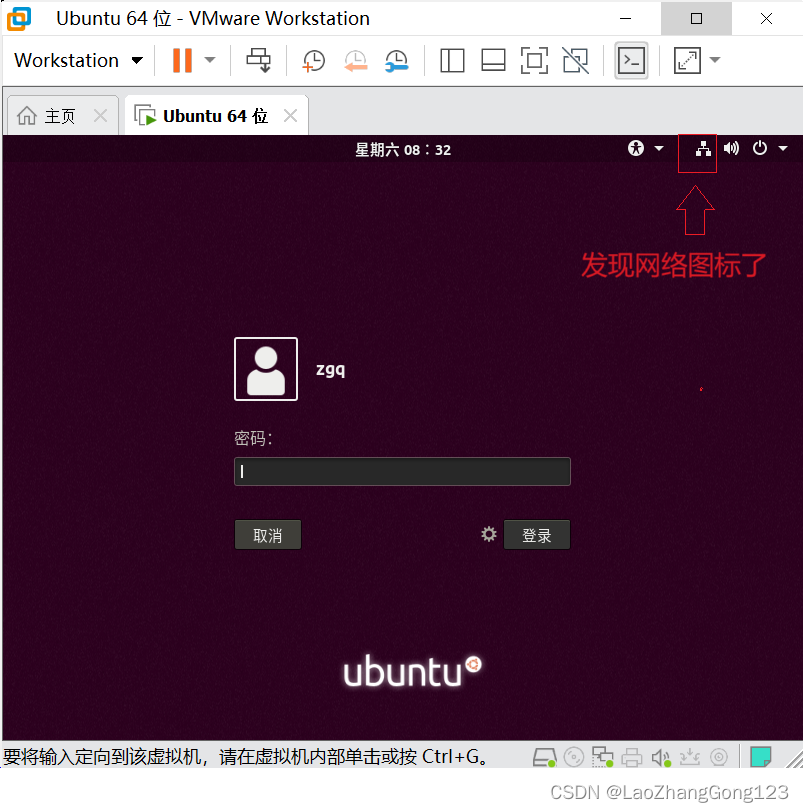
解决虚拟机的网络图标不见之问题
在WIN11中,启动虚拟机后,发现网络图标不见了,见下图: 1、打开虚拟机终端 输入“sudo server network-manager stop”,停止网络管理器 输入“cd /回车” , 切换到根目录 输入“cd var回车” ,…...

【Spring类路径Bean定义信息扫描】
Spring类路径Bean定义信息扫描 1. ClassPathBeanDefinitionScanner作用2. 类声明3. 属性4. 构造器5. 扫描方法6. 真正扫描方法7. postProcessBeanDefinition8. 注册bean定义 1. ClassPathBeanDefinitionScanner作用 扫描类路径下的类注册为bean定义。2. 类声明 public class …...

Ubuntu上安装VMware+win11系统手册
Ubuntu安装vmware 下载: Linux 版下载地址:https://www.vmware.com/go/getworkstation-linux 安装: sudo chmod x VMware-Workstation-Full-17.5.0-22583795.x86_64.bundle 执行安装命令: sudo ./VMware-Workstation-Full-17.5.0…...
2024年1月12日:清爽无糖rio留下唇齿之间的香甜
友利奈绪的时间管理 2024年1月12日08:02:28进行java程序设计的上课准备 2024年1月12日08:02:44知道java的题目有18道 2024年1月12日08:43:07随机数去重比较 2024年1月12日08:54:03C语言题目最小公倍数 2024年1月12日08:58:37C语言题目二维数组变一维数组 2024年1月12日10…...
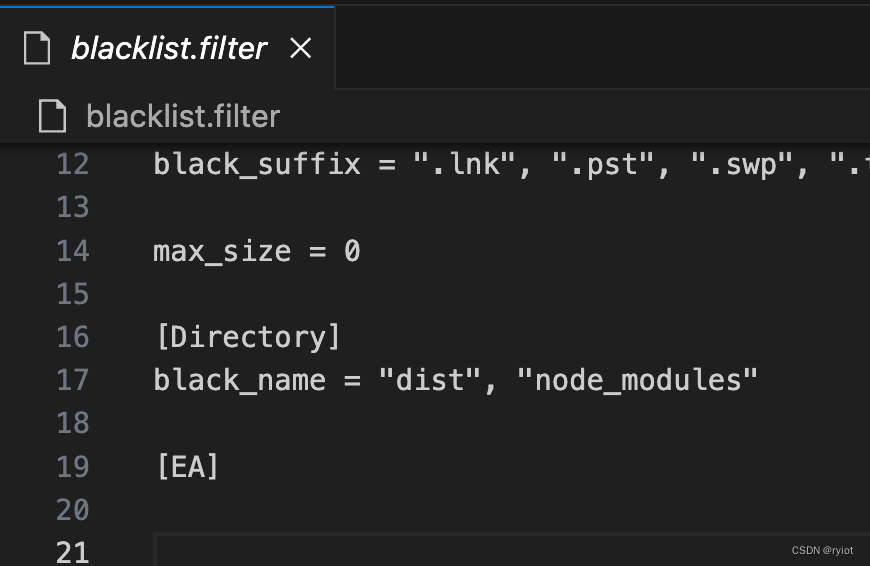
群晖Synology Drive同步文件时过滤指定文件夹“dist“, “node_modules“
群晖Synology Drive同步文件时过滤指定文件夹"dist", “node_modules” mac用户 安装Synology Drive创建同步任务修改Synology Drive配置 打开/Users/[用户名]/Library/Application Support/SynologyDrive/data/session/[同步任务序号,第一个同步任务就…...

小程序中滚动字幕
需求:在录像时需要在屏幕上提示字幕,整体匀速向上滚动 html部分: <view class"subtitles_main"><view style"font-size:34rpx;color: #fff;line-height: 60rpx;" animation"{{animation}}">人生的…...
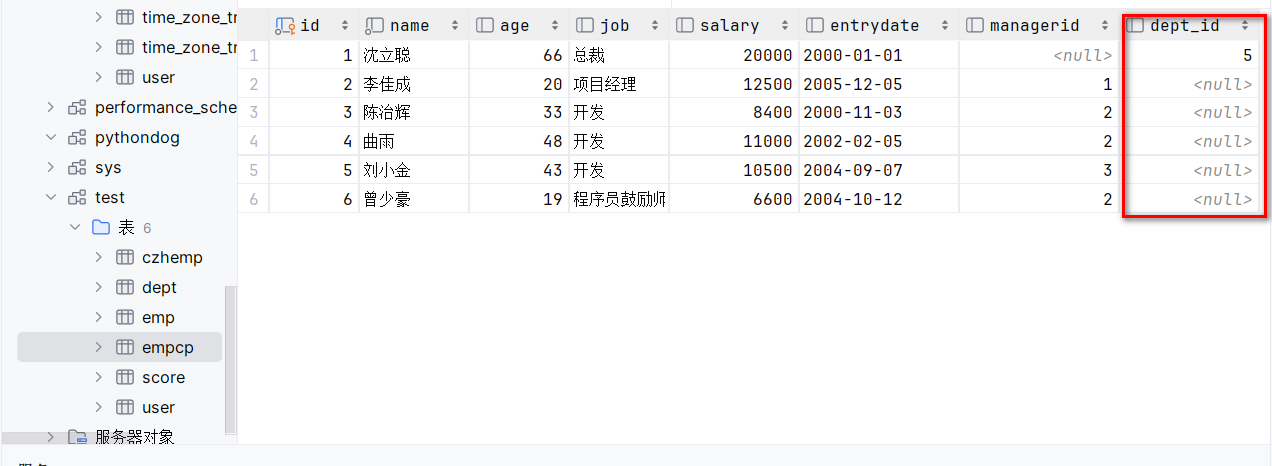
MySQL中约束是什么?
🎉欢迎您来到我的MySQL基础复习专栏 ☆* o(≧▽≦)o *☆哈喽~我是小小恶斯法克🍹 ✨博客主页:小小恶斯法克的博客 🎈该系列文章专栏:重拾MySQL 🍹文章作者技术和水平很有限,如果文中出现错误&am…...

若依在表格中如何将字典的键值转为中文
文章目录 一、需求:二、问题解决步骤1、给需要转换的列绑定formatter属性2、获取字典项3、编写formatter属性绑定的方法 一、需求: 后端有时候返回的是字典的键值,在前端展示时需要转成中文值 后端返回的是dictValue,现在要转换…...

用笨办法-刻意练习来提高自己的编程能力
尝试了很多学习方法,企图快速提高编程能力,但最终发现,唯有老老实实刻意练习1,在辛苦与时间积累下,逐渐提升能力,才是最有效的方式。 将自己的笨办法总结了一下,主要包含7个步骤: …...

FineBI报表页面大屏小屏自适应显示问题
大屏正常显示 显示正常 小屏BI自适应显示 存在遮挡字体情况 小屏浏览器缩放显示 等比缩放后显示正常...

零基础极速上手:十分钟用AI建站工具做出你的第一个网站
# 痛点共情:完全不懂技术,真的能自己做出吗?\你可能连“域名”和“服务器”都分不清,看到代码就头疼,更别说设计排版了。但心里又确实需要个网站:不管是展示作品、推广小店,还是给简历加分。你担…...

GPT-SoVITS语音克隆技术深度解析:从原理到实战的完整指南
GPT-SoVITS语音克隆技术深度解析:从原理到实战的完整指南 【免费下载链接】GPT-SoVITS 项目地址: https://gitcode.com/GitHub_Trending/gp/GPT-SoVITS 你是否曾幻想过,只需短短几秒钟的录音,就能让AI完美模仿任何人的声音࿱…...

【实战指南】Green Hills MULTI-IDE 从零安装到嵌入式开发环境搭建
1. Green Hills MULTI-IDE 初探:为什么选择它? 如果你正在寻找一款强大的嵌入式开发工具,Green Hills MULTI-IDE 绝对值得考虑。作为一个在嵌入式领域摸爬滚打多年的老手,我用过Keil、IAR等各种IDE,但MULTI-IDE给我的体…...

OpenClaw调试技巧:ollama-QwQ-32B任务失败日志分析方法
OpenClaw调试技巧:ollama-QwQ-32B任务失败日志分析方法 1. 为什么需要关注OpenClaw任务失败日志 上周我在尝试用OpenClaw自动整理项目文档时,遇到了一个令人抓狂的问题:明明配置好了ollama-QwQ-32B模型,任务却总是莫名其妙地卡在…...

Ubuntu 20.04 虚拟机环境快速克隆与迁移实战指南
1. 为什么需要虚拟机环境克隆与迁移? 作为常年和虚拟机打交道的开发者,我深刻理解重复搭建环境的痛苦。每次新项目启动都要从头配置Ubuntu环境,安装依赖库,调试网络,这个过程至少要浪费半天时间。更可怕的是当团队需要…...
)
从“机器会思考”的执念说起,聊聊神经网络到底是个啥(下篇)
一、神经网络的类型:别被名字搞晕,核心就几种 现在叫“神经网络”的东西五花八门,但绝大多数都是从下面这几类衍生出去的。 1. 前馈神经网络(FNN)—— 最朴素的直筒子 数据从输入层进,经过若干隐藏层&am…...

Python异步服务部署与无服务器架构实践指南
Python异步服务部署与无服务器架构实践指南 【免费下载链接】uvicorn An ASGI web server, for Python. 🦄 项目地址: https://gitcode.com/GitHub_Trending/uv/uvicorn 在云原生应用开发领域,Python异步服务部署正成为构建高性能后端系统的首选方…...

Hunyuan-MT Pro详细步骤:本地启动http://localhost:6666翻译终端
Hunyuan-MT Pro详细步骤:本地启动http://localhost:6666翻译终端 1. 快速了解Hunyuan-MT Pro Hunyuan-MT Pro是一个基于腾讯混元开源模型构建的现代化翻译工具,它把强大的AI翻译能力包装成了一个简单易用的网页应用。你不需要懂复杂的技术,…...

# 发散创新:基于 Rust的分布式数据库架构设计与实战演练在当前云原生和微服务架
发散创新:基于 Rust 的分布式数据库架构设计与实战演练 在当前云原生和微服务架构盛行的背景下,分布式数据库已成为高并发、高可用系统的核心基础设施。本文将深入探讨如何使用 Rust 编程语言构建一个轻量级但功能完整的分布式数据库原型,重点…...
)
破局与重构:基于“智慧大脑”的企业全面数据化经营深度解构(PPT)
“在数字时代,企业最大的风险不是数据的匮乏,而是决策依然依赖经验直觉而非数据驱动。” —— 这份《数字化建设企业经营解决方案》文档,不仅是一份技术蓝图,更是对传统企业经营管理模式的一次彻底颠覆。它描绘了一个从“人治”迈…...