1、理解Transformer:革新自然语言处理的模型
目录
一、论文题目
二、背景与动机
三、卖点与创新
四、解决的问题
五、具体实现细节
0. Transformer 架构的主要组件
1. 注意力、自注意力(Self-Attention)到多头注意力(Multi-Head Attention)
注意力到底是做什么的?一个例子。
自注意力
多头注意力
2. 位置编码(Positional Encoding)
3. 编码器和解码器层(Encoder & Decoder Layers)
编码器:
解码器:
六、一些好的资料:
一、论文题目
Attention Is All You Need
二、背景与动机
在 Transformer 问世之前,循环神经网络(RNN)和其变体,如长短期记忆网络(LSTM)和门控循环单元(GRU),是处理序列数据的主流技术。这些模型通过递归地处理序列的每个元素来捕捉序列之间的依赖关系,例如在机器翻译或文本生成任务中。然而,RNN 有一个明显的缺点:无法并行化序列中的步骤处理,因为每个步骤都依赖于前一个步骤的输出。
三、卖点与创新
Transformer 模型的主要创新之处在于其独特的注意力机制——"自注意力"(Self-Attention)。这种机制允许模型在处理序列的每个元素时考虑到序列中的所有元素,因此能够直接捕捉远距离的依赖关系。自注意力的这一特点使得 Transformer 模型在处理长序列时效果显著。
此外,Transformer 模型还引入了以下几个关键的新颖概念:
-
多头注意力(Multi-Head Attention):不只一次地计算自注意力,而是多次并行地计算,每一次都从不同的角度捕捉序列中的信息,然后将所有的信息合并起来,提供更全面的理解。
-
位置编码(Positional Encoding):由于模型缺乏递归结构和卷积层,因此无法自然地利用输入序列的顺序信息。位置编码通过向输入添加额外的信息来解决这个问题,使得模型能够考虑到序列的顺序。
-
层次化结构:Transformer 通过堆叠多个注意力和前馈网络层来构建深度模型,这使得它能够学习复杂的表示。
四、解决的问题
Transformer 主要用来解决机器翻译等任务中,之前 RNN 在处理长序列时效率低下的问题。由于其并行化的自注意力机制,Transformer 可以显著加快训练速度。
五、具体实现细节
Transformer 的核心是基于注意力的编码器-解码器架构。编码器由一系列相同的层组成,每一层都有两个主要的子层:多头注意力层和简单的前馈神经网络。解码器也有类似的结构,但在每一层中包含两个注意力层,其中一个为Masked Multi-Head Attention,用于在掩盖后续输入;另一个为Muti-Head Attention层,用于关注编码器的输出。
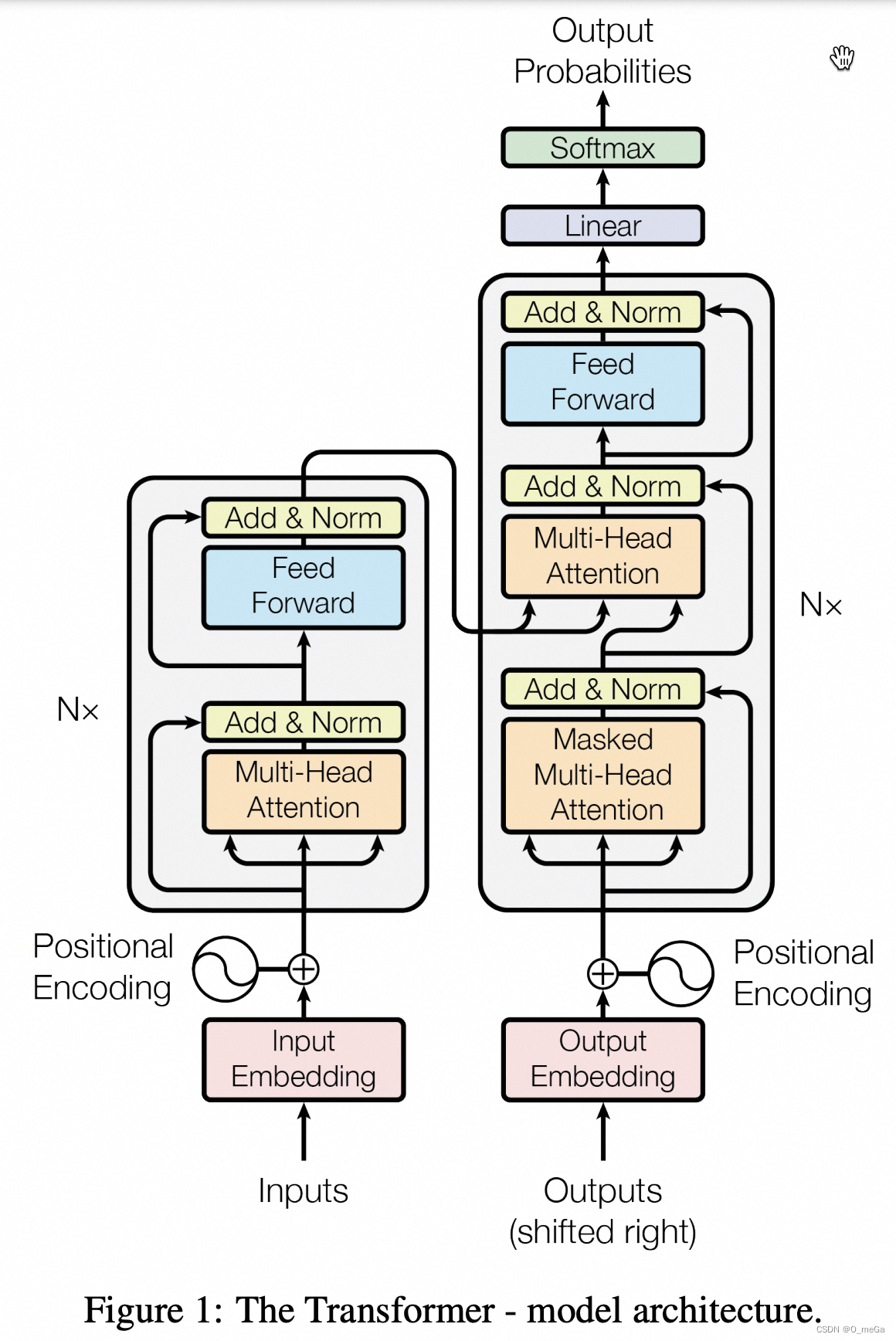
0. Transformer 架构的主要组件
- 自注意力(Self-Attention):允许模型在序列中的任何位置加权其他位置。
- 多头注意力(Multi-Head Attention):将自注意力的输出拆分为多个头,分别处理然后再合并。
- 位置编码(Positional Encoding):在输入中添加位置信息,因为 Transformer 没有递归和卷积结构去自然捕捉序列的顺序。
- 编码器和解码器层(Encoder & Decoder Layers):Transformer 模型的主体。
- 前馈神经网络(Feed-Forward Neural Network):编码器和解码器层中的一个组成部分。
- 最终的线性和 Softmax 层:将解码器输出转换为预测。
1. 注意力、自注意力(Self-Attention)到多头注意力(Multi-Head Attention)
一下内容引自:Attention Is All You Need (Transformer) 论文精读 - 知乎,推荐。
注意力到底是做什么的?一个例子。
其实,“注意力”这个名字取得非常不易于理解。这个机制应该叫做“全局信息查询”。做一次“注意力”计算,其实就跟去数据库了做了一次查询一样。假设,我们现在有这样一个以人名为key(键),以年龄为value(值)的数据库:
{张三: 18,张三: 20,李四: 22,张伟: 19
}现在,我们有一个query(查询),问所有叫“张三”的人的年龄平均值是多少。让我们写程序的话,我们会把字符串“张三”和所有key做比较,找出所有“张三”的value,把这些年龄值相加,取一个平均数。这个平均数是(18+20)/2=19。
但是,很多时候,我们的查询并不是那么明确。比如,我们可能想查询一下所有姓张的人的年龄平均值。这次,我们不是去比较key == 张三,而是比较key[0] == 张。这个平均数应该是(18+20+19)/3=19。
或许,我们的查询会更模糊一点,模糊到无法用简单的判断语句来完成。因此,最通用的方法是,把query和key各建模成一个向量。之后,对query和key之间算一个相似度(比如向量内积),以这个相似度为权重,算value的加权和。这样,不管多么抽象的查询,我们都可以把query, key建模成向量,用向量相似度代替查询的判断语句,用加权和代替直接取值再求平均值。“注意力”,其实指的就是这里的权重。
把这种新方法套入刚刚那个例子里。我们先把所有key建模成向量,可能可以得到这样的一个新数据库:
{[1, 2, 0]: 18, # 张三[1, 2, 0]: 20, # 张三 [0, 0, 2]: 22, # 李四[1, 4, 0]: 19 # 张伟
} 假设key[0]==1表示姓张。我们的查询“所有姓张的人的年龄平均值”就可以表示成向量[1, 0, 0]。用这个query和所有key算出的权重是:
dot([1, 0, 0], [1, 2, 0]) = 1
dot([1, 0, 0], [1, 2, 0]) = 1
dot([1, 0, 0], [0, 0, 2]) = 0
dot([1, 0, 0], [1, 4, 0]) = 1
之后,我们该用这些权重算平均值了。注意,算平均值时,权重的和应该是1。因此,我们可以用softmax把这些权重归一化一下,再算value的加权和。
softmax([1, 1, 0, 1]) = [1/3, 1/3, 0, 1/3]
dot([1/3, 1/3, 0, 1/3], [18, 20, 22, 19]) = 19 这样,我们就用向量运算代替了判断语句,完成了数据库的全局信息查询。那三个1/3,就是query对每个key的注意力。
刚刚完成的计算差不多就是Transformer里的注意力,这种计算在论文里叫做放缩点乘注意力(Scaled Dot-Product Attention)。它的公式是:

我们先来看看在刚刚那个例子里究竟是什么。
比较好理解,
其实就是key向量的数组,也就是
K = [[1, 2, 0], [1, 2, 0], [0, 0, 2], [1, 4, 0]]同样,就是value向量的数组。而在我们刚刚那个例子里,value都是实数。实数其实也就是可以看成长度为1的向量。因此,那个例子的
应该是
V = [[18], [20], [22], [19]]在刚刚那个例子里,我们只做了一次查询。因此,准确来说,我们的操作应该写成。
![]()
其中,query 就是
[1, 0, 0]了。
实际上,我们可以一次做多组query。把所有打包成矩阵
,就得到了公式
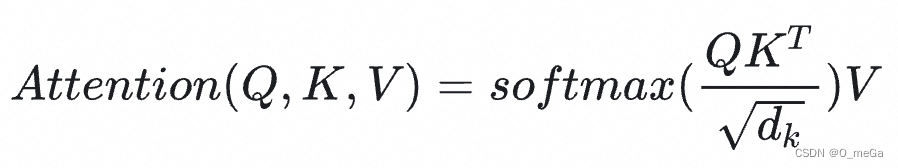
等等,这个是什么意思?
就是query和key向量的长度。由于query和key要做点乘,这两种向量的长度必须一致。value向量的长度倒是可以不一致,论文里把value向量的长度叫做
。在我们这个例子里,
=3,
=1。
为什么要用一个和成比例的项来放缩
呢?这是因为,softmax在绝对值较大的区域梯度较小,梯度下降的速度比较慢。因此,我们要让被softmax的点乘数值尽可能小。而一般在
较大时,也就是向量较长时,点乘的数值会比较大。除以一个和
相关的量能够防止点乘的值过大。
刚才也提到,其实是在算query和key的相似度。而算相似度并不只有求点乘这一种方式。另一种常用的注意力函数叫做加性注意力,它用一个单层神经网络来计算两个向量的相似度。相比之下,点乘注意力算起来快一些。出于性能上的考量,论文使用了点乘注意力。
自注意力
以上注意力机制中,通常涉及两个不同的序列:一个是查询序列(比如在机器翻译中的目标语言)、另一个是键-值序列(比如源语言)。模型在生成查询序列的每个元素时,会参考键-值序列来决定聚焦于哪些元素。
而在自注意力中,查询、键和值都来自于同一个序列。这意味着模型在处理序列的每个元素时,是在自身序列的上下文中进行的,而不是在另一个序列的上下文中。自注意力的这种特性使其特别适用于捕捉序列内部的长距离依赖关系。
换句话说,自注意力机制不依赖于源序列和目标序列之间的关系,它可以在输入序列内部建立元素之间的关联。
自注意力通常通过以下步骤实现:
- 对于序列中的每个元素(比如一个句子中的每个单词),模型通过可学习的线性变换生成三个不同的向量:查询向量(Query)、键向量(Key)和值向量(Value)。
- 自注意力计算每个查询向量与所有键向量的兼容性(通常是通过点积得到的),从而生成一个注意力分数。
- 应用 softmax 函数到注意力分数上,得到一个概率分布,表明每个位置对当前位置的重要性。
- 这些权重随后用于加权对应的值向量,加权和就形成了该位置的输出向量。
多头注意力
多头注意力机制是自注意力的一个扩展,它允许模型在不同的表示子空间中同时学习信息。多头注意力的工作原理:
在单头自注意力中,我们为序列中的每个元素生成一组查询(Q)、键(K)和值(V)向量。在多头注意力中,我们将这个过程重复多次(每个“头”一次),每次使用不同的、可学习的线性变换。
对于每个头,我们独立地进行自注意力计算。这意味着对于每个头,我们根据该头的查询、键和值来计算注意力分数,并使用这些分数来加权值向量,得到该头的输出。
一旦所有头的自注意力计算完成,将每个头产生的输出向量拼接起来,并对其应用另一个可学习的线性变换,这样就生成了最终的多头注意力输出。
代码示例:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass SelfAttention(nn.Module):def __init__(self, embed_size, heads):super(SelfAttention, self).__init__()self.embed_size = embed_sizeself.heads = heads # head的数量self.head_dim = embed_size // headsassert (self.head_dim * heads == embed_size), "Embed size needs to be divisible by heads"self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)self.fc_out = nn.Linear(heads * self.head_dim, embed_size)def forward(self, values, keys, query, mask):N = query.shape[0]value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]# Split the embedding into self.heads different piecesvalues = values.reshape(N, value_len, self.heads, self.head_dim)keys = keys.reshape(N, key_len, self.heads, self.head_dim)queries = query.reshape(N, query_len, self.heads, self.head_dim)values = self.values(values)keys = self.keys(keys)queries = self.queries(queries)# Self-attentionenergy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys]) # Query-Key dot productif mask is not None:energy = energy.masked_fill(mask == 0, float("-1e20"))attention = torch.softmax(energy / (self.embed_size ** (1/2)), dim=3)out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(N, query_len, self.heads * self.head_dim)out = self.fc_out(out)return out注:torch.einsum用法:torch.einsum用法-CSDN博客
再详细一点可好?torch.einsum("nqhd,nkhd->nhqk", [queries, keys])的等价代码如下:
import torch# 假设 queries 的形状为 (batch_size, num_queries, hidden_dim)
# 假设 keys 的形状为 (batch_size, num_keys, hidden_dim)# 使用等价代码实现
batch_size, num_queries, hidden_dim = queries.size()
num_keys = keys.size(1)# 将 queries 和 keys 进行扩展以匹配计算的维度
expanded_queries = queries.unsqueeze(2).expand(batch_size, num_queries, num_keys, hidden_dim)
expanded_keys = keys.unsqueeze(1).expand(batch_size, num_queries, num_keys, hidden_dim)# 逐元素相乘,得到内积结果
dot_product = torch.mul(expanded_queries, expanded_keys)# 将最后两个维度进行交换,得到结果
result = dot_product.permute(0, 2, 1, 3)# result 的形状为 (batch_size, num_keys, num_queries, hidden_dim)2. 位置编码(Positional Encoding)
位置编码(Positional Encoding)的作用是为模型提供关于单词在序列中位置的信息。由于 Transformer 的自注意力机制并不区分序列中不同位置的元素,即它本身不像循环神经网络(RNN)那样具有处理序列的固有顺序性,所以需要一种方法来保证模型能够利用单词的顺序信息。
位置编码通过向输入嵌入(Embeddings)添加额外的信息来解决这个问题。这使得模型能够根据单词在序列中的位置以及单词的实际含义来进行计算和学习。位置编码是以一种特定的模式添加的,它对每个位置上的嵌入向量进行修改,使得不同位置的嵌入向量能够反映出它们的位置关系。
在原始的 Transformer 论文中,位置编码使用正弦和余弦函数的固定频率来生成。对于每个维度 (d) ,位置编码 (PE) 采用以下公式:
其中:
- (pos) 是位置索引。
- (i) 是维度索引。
- (
) 是模型中单个词向量的维度。
直觉上,这种编码方法为每个维度提供了一个独特的“波长”,使得模型对于不同位置的词可以有区分性的理解。使用正弦和余弦函数是因为它们相对于位置的偏移具有周期性,并且能够让模型学习到相对位置信息。
位置编码通常与词嵌入向量相加,结果即作为 Transformer 模型的输入。这种做法保证了模型在处理单词时同时考虑了单词的含义和它们在序列中的位置。由于位置编码和词嵌入是相加的,因此它们必须具有相同的维度。
代码如下:
class PositionalEncoding(nn.Module):def __init__(self, embed_size, max_len, device):super(PositionalEncoding, self).__init__()self.encoding = torch.zeros(max_len, embed_size).to(device)for pos in range(max_len):for i in range(0, embed_size, 2):self.encoding[pos, i] = math.sin(pos / (10000 ** ((2 * i)/embed_size)))self.encoding[pos, i + 1] = math.cos(pos / (10000 ** ((2 * (i + 1))/embed_size)))def forward(self, x):return x + self.encoding[:x.size(0)]3. 编码器和解码器层(Encoder & Decoder Layers)
编码器:
Transformer 编码器的结构由多个相同的层(layer)堆叠而成,每一层都有两个主要子模块,以及一个残差连接跟随每个子模块,最后是层归一化(Layer Normalization)。每个编码器层包含以下部分:
- 自注意力(Self-Attention)子层 - 该层允许编码器在生成每个单词的表示时考虑输入序列中的所有位置。每个位置的输出是对整个序列的自注意力分数加权和。
- 残差连接和层归一化 - 自注意力子层的输出与其输入相加(残差连接),接着应用层归一化。
- 前馈网络(Feed-Forward Network) - 一个由两个线性变换组成的网络,中间有一个 ReLU 激活函数。这个前馈网络是逐位置应用的,也就是说每个位置的表示都会通过相同的前馈网络,但是不同位置之间是独立的。
- 残差连接和层归一化 - 前馈网络的输出与其输入相加(残差连接),接着应用层归一化。
简易代码如下:
class EncoderLayer(nn.Module):def __init__(self, embed_size, heads, forward_expansion, dropout, device):super(EncoderLayer, self).__init__()self.attention = SelfAttention(embed_size, heads)self.norm1 = nn.LayerNorm(embed_size)self.norm2 = nn.LayerNorm(embed_size)self.feed_forward = nn.Sequential(nn.Linear(embed_size, forward_expansion * embed_size),nn.ReLU(),nn.Linear(forward_expansion * embed_size, embed_size))self.dropout = nn.Dropout(dropout)def forward(self, x, mask):attention = self.attention(x, x, x, mask)x = self.dropout(self.norm1(attention + x))forward = self.feed_forward(x)out = self.dropout(self.norm2(forward + x))return out解码器:
Transformer 的解码器架构设计用来将编码器的输出转换成最终的输出序列(比如在机器翻译中将编码的源语言句子转换成目标语言)。解码器由多个相同的层堆叠而成,每层包含以下三个主要部分:
Masked Self-Attention Layer: 与编码器中的自注意力层类似,但使用了掩码(mask)来防止对未来位置的信息进行注意力计算(即,在生成第 i 个单词时,解码器只能看到第 1 到 i 个单词)。
Encoder-Decoder Attention Layer: 这个层使得解码器能够关注编码器的输出。解码器的查询(Q)来自于前面的 masked self-attention 层的输出,而键(K)和值(V)来自于编码器的输出。
Feed-Forward Neural Network: 与编码器中的前馈神经网络相同。
每个子层都有一个残差连接,并且之后跟着一个层归一化(layer normalization)。最终,解码器的输出传递给一个线性层和一个 softmax 层来生成输出序列。
以下是使用 PyTorch 实现的 Transformer 解码器的简化代码:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass TransformerDecoderLayer(nn.Module):def __init__(self, embed_size, heads, forward_expansion, dropout, device):super(TransformerDecoderLayer, self).__init__()self.self_attention = SelfAttention(embed_size, heads)self.norm1 = nn.LayerNorm(embed_size)self.encoder_decoder_attention = SelfAttention(embed_size, heads)self.norm2 = nn.LayerNorm(embed_size)self.feed_forward = nn.Sequential(nn.Linear(embed_size, forward_expansion * embed_size),nn.ReLU(),nn.Linear(forward_expansion * embed_size, embed_size))self.norm3 = nn.LayerNorm(embed_size)self.dropout = nn.Dropout(dropout)def forward(self, x, value, key, src_mask, trg_mask):# Masked self attentionattention = self.self_attention(x, x, x, trg_mask)query = self.dropout(self.norm1(attention + x))# Encoder-decoder attentionattention = self.encoder_decoder_attention(query, key, value, src_mask)query = self.dropout(self.norm2(attention + query))# Feed forwardout = self.dropout(self.norm3(self.feed_forward(query) + query))return outclass TransformerDecoder(nn.Module):def __init__(self, target_vocab_size, embed_size, num_layers, heads, forward_expansion, dropout, device, max_length):super(TransformerDecoder, self).__init__()self.device = deviceself.word_embedding = nn.Embedding(target_vocab_size, embed_size)self.position_embedding = nn.Embedding(max_length, embed_size)self.layers = nn.ModuleList([TransformerDecoderLayer(embed_size, heads, forward_expansion, dropout, device)for _ in range(num_layers)])self.fc_out = nn.Linear(embed_size, target_vocab_size)self.dropout = nn.Dropout(dropout)def forward(self, x, enc_out, src_mask, trg_mask):N, seq_length = x.shapepositions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)x = self.dropout(self.word_embedding(x) + self.position_embedding(positions))for layer in self.layers:x = layer(x, enc_out, enc_out, src_mask, trg_mask)out = self.fc_out(x)return out注:在解码器中,在输出第t+1个单词时,模型不应该提前知道t+1时刻之后的信息。因此,应该只保留t时刻之前的信息,遮住后面的输入。这可以通过添加掩码实现。添加掩码的一个不严谨的示例如下表所示:
| 输入 | 输出 |
|---|---|
| (y1, --, --, --) | y2 |
| (y1, y2, --, --) | y3 |
| (y1, y2, y3, --) | y4 |
这就是为什么解码器的多头自注意力层前面有一个masked。在论文中,mask是通过令注意力公式的softmax的输入为−∞来实现的(softmax的输入为−∞,注意力权重就几乎为0,被遮住的输出也几乎全部为0)。每个mask都是一个上三角矩阵。
注:transformer训练时是并行的,并行输出所有时刻的预测结果计算损失。而推理时是串行的,需要每次把前i个单词输入,预测第i+1个,然后把预测出来的第i+1个单词加入输入预测后续内容。
六、一些好的资料:
Attention Is All You Need (Transformer) 论文精读 - 知乎Attention Is All You Need (Transformer) 是当今深度学习初学者必读的一篇论文。但是,这篇工作当时主要是用于解决机器翻译问题,有一定的写作背景,对没有相关背景知识的初学者来说十分难读懂。在这篇文章里,我…![]() https://zhuanlan.zhihu.com/p/569527564(详细)Transformer完整版)_transformer论文-CSDN博客文章浏览阅读7k次,点赞7次,收藏41次。原文链接:https://blog.csdn.net/longxinchen_ml/article/details/86533005 作者: 龙心尘 时间:2019年1月 出处:https://blog.csdn.net/longxinchen_ml/article/details/_transformer论文
https://zhuanlan.zhihu.com/p/569527564(详细)Transformer完整版)_transformer论文-CSDN博客文章浏览阅读7k次,点赞7次,收藏41次。原文链接:https://blog.csdn.net/longxinchen_ml/article/details/86533005 作者: 龙心尘 时间:2019年1月 出处:https://blog.csdn.net/longxinchen_ml/article/details/_transformer论文https://blog.csdn.net/qq_43703185/article/details/120287945
相关文章:
1、理解Transformer:革新自然语言处理的模型
目录 一、论文题目 二、背景与动机 三、卖点与创新 四、解决的问题 五、具体实现细节 0. Transformer 架构的主要组件 1. 注意力、自注意力(Self-Attention)到多头注意力(Multi-Head Attention) 注意力到底是做什么的&…...
)
Acwing847 图中点的层次(bfs)
这道题用的是bfs,一开始用了dfs搜出了答案为4 题目 给定一个 n个点 m 条边的有向图,图中可能存在重边和自环。 所有边的长度都是 1,点的编号为 1∼n。 请你求出 1 号点到 n 号点的最短距离,如果从 1 号点无法走到 n 号点&…...
windows11通过虚拟机安装Ubuntu20.04
VMware 分为 VMware Workstation Pro 和 VMware Workstation Player, Pro体验期后收费,Player则免费。player 早期不能创建虚拟机,只能Pro创建好后给Player运行,而现在player早已加入创建虚拟机功能,所以使用体验上两者相差不大&a…...

时序预测 | Matlab实现EEMD-SSA-BiLSTM、EEMD-BiLSTM、SSA-BiLSTM、BiLSTM时序预测对比
时序预测 | Matlab实现EEMD-SSA-BiLSTM、EEMD-BiLSTM、SSA-BiLSTM、BiLSTM时间序列预测对比 目录 时序预测 | Matlab实现EEMD-SSA-BiLSTM、EEMD-BiLSTM、SSA-BiLSTM、BiLSTM时间序列预测对比预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.Matlab实现EEMD-SSA-BiLSTM、…...

Android14之解决Pixel手机联网出现感叹号(一百八十)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...
Vmware虚拟机问题解决方案 运行虚拟机系统蓝屏 运行虚拟机时报错VT-x
1. 运行虚拟机系统蓝屏 可能的原因有两个: 1). 虚拟机所在磁盘的空间不足 ; -------> 清理磁盘空间 。 2). 操作系统版本高, 需要适配新版本的Vmware ; ------> 卸载Vmware15版本, 安装Vmware16版本 。 2. 卸载Vmware步骤 1). 卸载已经安装的VMware 弹出确认框, 点击…...
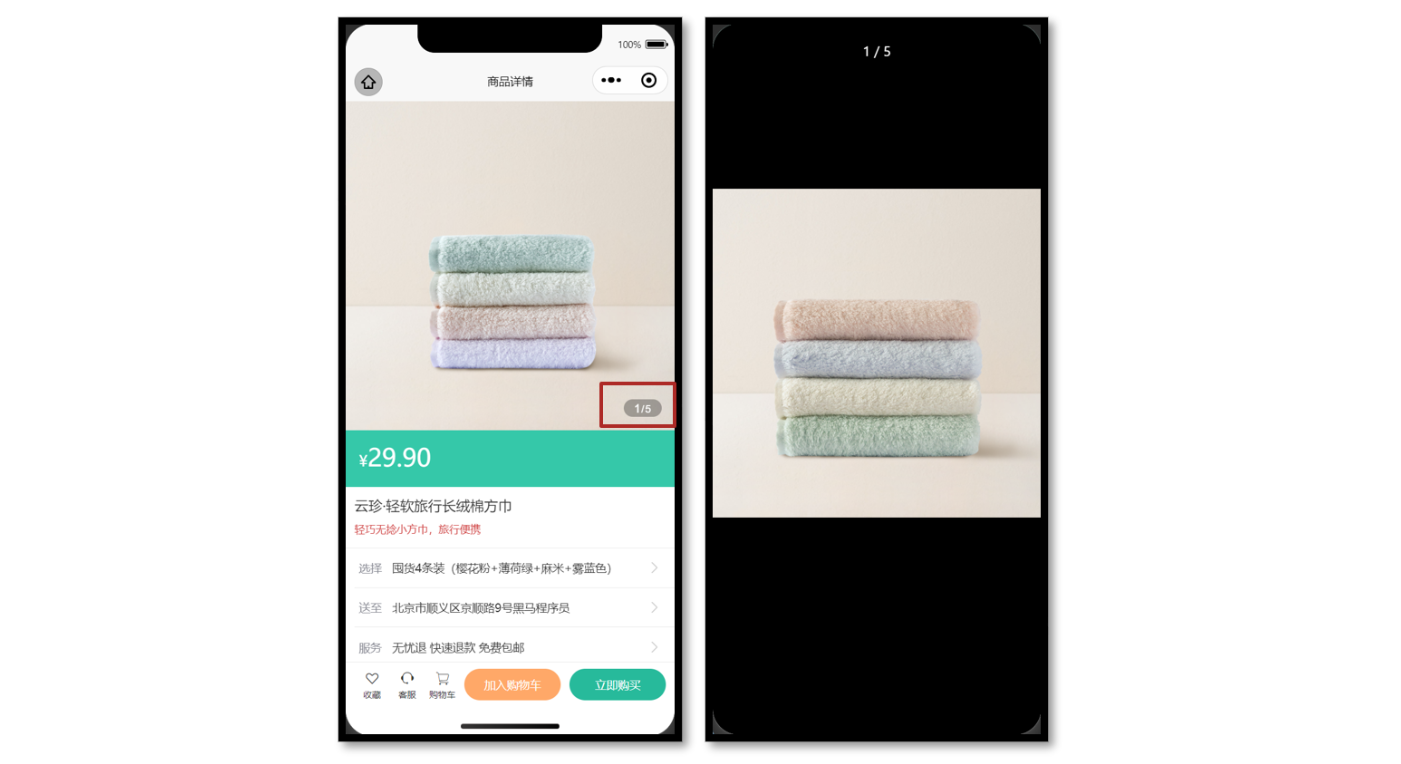
uni-app中轮播图实现大图预览
参考效果 当轮播图滑动切换的时候更新自定义下标,当图片被点击的时候大图预览。 参考代码 商品详情页轮播图交互 <script setup lang"ts"> // 轮播图变化时 const currentIndex ref(0) const onChange: UniHelper.SwiperOnChange (ev) > …...

了解什么是UV纹理?
在线工具推荐: 3D数字孪生场景编辑器 - GLTF/GLB材质纹理编辑器 - 3D模型在线转换 - Three.js AI自动纹理开发包 - YOLO 虚幻合成数据生成器 - 三维模型预览图生成器 - 3D模型语义搜索引擎 什么是UV? UV 是与几何图形的顶点信息相对应的二维纹理坐…...

【蓝桥备赛】wzy的数组Ⅱ——简单莫队问题
题目链接 wzy的数组Ⅱ 个人思路 本题需要统计区间范围内 数值为 x 在区间出现次数也为 x 的数的个数。区间询问 多次询问,我们选择 莫队。 将多次询问按照区间边界进行排序,每一次区间的移动,先去判断当前区间指针所指向的数是否符合题目…...
学习Qt笔记
前言: 学习笔记的内容来自B站up主阿西拜编程 《Qt6 C开发指南 》2023(上册,完整版)_哔哩哔哩_bilibili《Qt6 C开发指南 》2023(上册,完整版)共计84条视频,包括:00书籍介…...

pymssql 报错误解决办法:20002, severity 9
错误 解决办法 python3.6,安装pymssql低版本(pymssql-2.1.5-cp36-cp36m-win32.whl)...
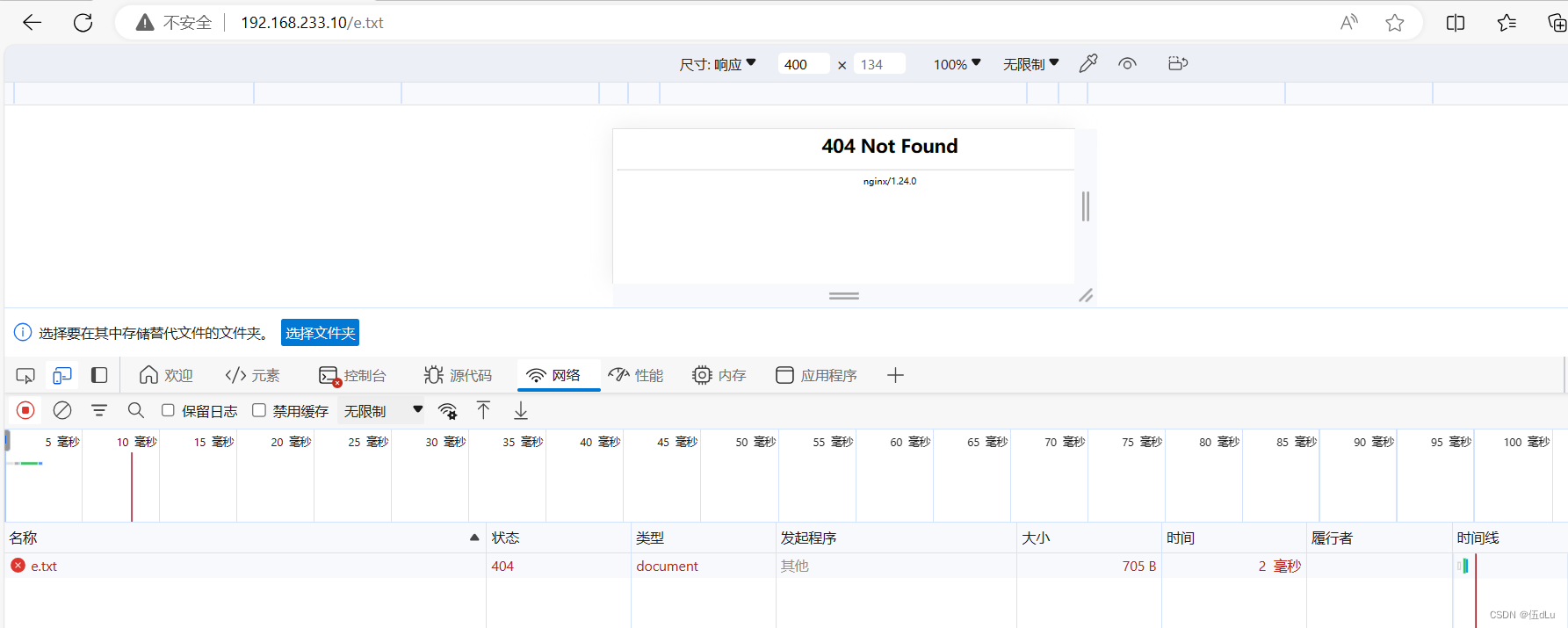
Web缓存代理
目录 一.Web缓存代理 配置Nginx 缓存代理: 修改web服务器的配置文件: 修改192.168.233.10代理服务器的配置文件: 访问页面看看: 对于一些实时性要求非常高的页面或数据来说,就不应该去设置缓存,下面来…...

Rust-模式解构
match 首先,我们看看使用match的最简单的示例: exhaustive 有些时候我们不想把每种情况一一列出,可以用一个下划线来表达“除了列出来的那些之外的其他情况”: 下划线 下划线还能用在模式匹配的各种地方,用来表示…...
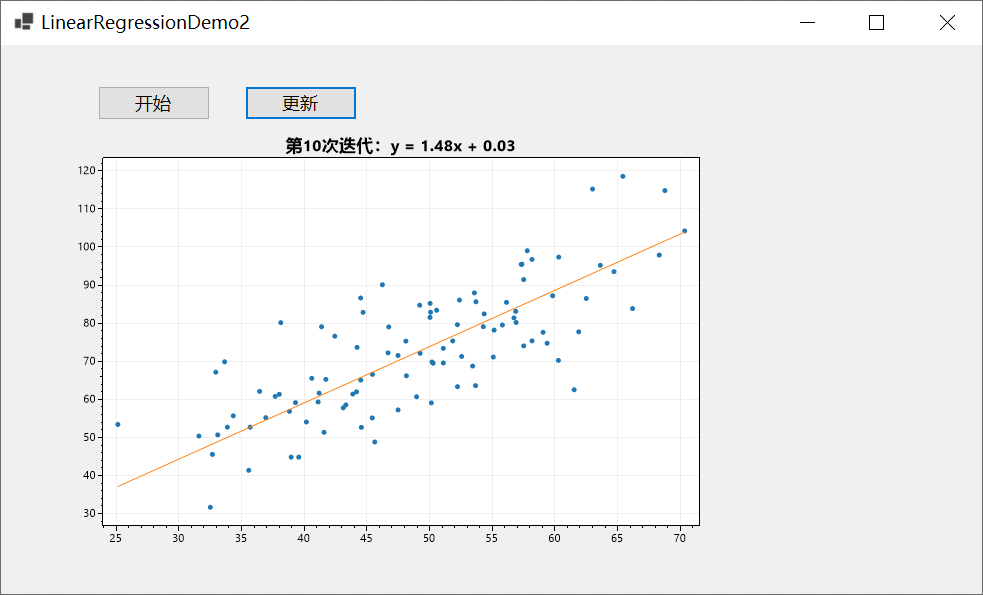
C#基于ScottPlot进行可视化
前言 上一篇文章跟大家分享了用NumSharp实现简单的线性回归,但是没有进行可视化,可能对拟合的过程没有直观的感受,因此今天跟大家介绍一下使用C#基于Scottplot进行可视化,当然Python的代码,我也会同步进行可视化。 P…...
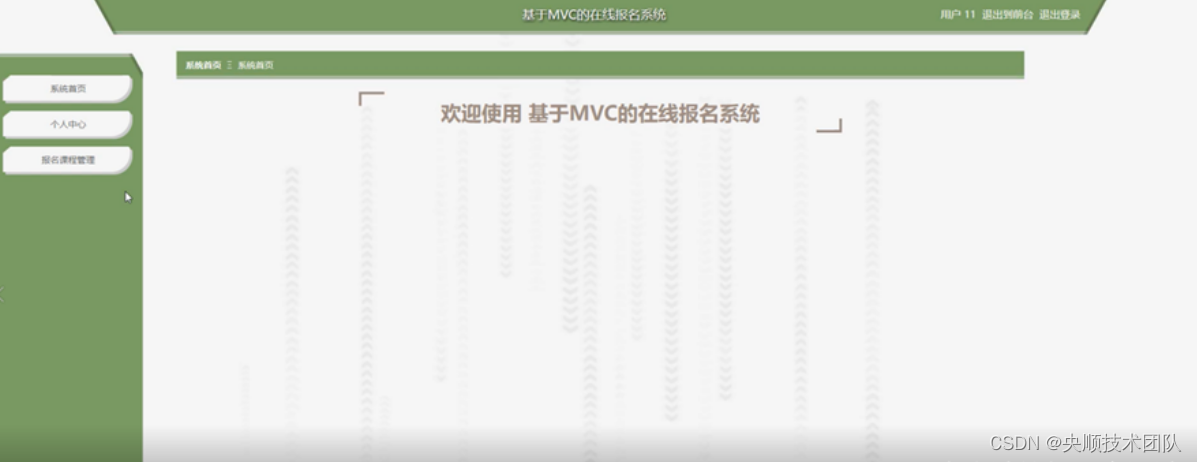
基于JAVA+ssm开发的在线报名系统设计与实现【附源码】
基于JAVAssm开发的在线报名系统设计与实现【附源码】 🍅 作者主页 央顺技术团队 🍅 欢迎点赞 👍 收藏 ⭐留言 📝 🍅 文末获取源码联系方式 📝 🍅 查看下方微信号获取联系方式 承接各种定制系统 …...
)
蓝桥——第 3 场 小白入门赛(A-D)
文章目录 一、题目A.召唤神坤基本思路:代码 B.聪明的交换策略基本思路:代码 C.怪兽突击基本思路:代码 D.蓝桥快打基本思路代码 一、题目 A.召唤神坤 基本思路: 贪心, 使结果最大,希望两边w[i],w[k]是较大…...
Java项目:06 Springboot的进销存管理系统
作者主页:舒克日记 简介:Java领域优质创作者、Java项目、学习资料、技术互助 文中获取源码 进销存管理系统 介绍 进销存系统是为了对企业生产经营中进货、出货、批发销售、付款等全程进行(从接获订单合同开 始,进入物料采购、入…...
数据结构与算法之美学习笔记:47 | 向量空间:如何实现一个简单的音乐推荐系统?
这里写自定义目录标题 前言算法解析总结引申 前言 本节课程思维导图: 很多人都喜爱听歌,以前我们用 MP3 听歌,现在直接通过音乐 App 在线就能听歌。而且,各种音乐 App 的功能越来越强大,不仅可以自己选歌听࿰…...

5《Linux》
文章目录 查看端口号查看进程号查看IP查看与某台机器连接情况 Linux查看日志的命令?head [-n 行数参数】tail [-n 行数参数】cat [-n 行号展示】tac [-n 行号展示】 Linux操作文本-三剑客grep-擅长过滤正则过滤sed-擅长取行awk-擅长取列 Linux性能监控的命令&#x…...

go-carbon v2.3.5 发布,轻量级、语义化、对开发者友好的 golang 时间处理库
carbon 是一个轻量级、语义化、对开发者友好的 golang 时间处理库,支持链式调用。 目前已被 awesome-go 收录,如果您觉得不错,请给个 star 吧 github.com/golang-module/carbon gitee.com/golang-module/carbon 安装使用 Golang 版本大于…...

SDMatte Web服务灰度发布:新模型版本AB测试与用户反馈闭环机制
SDMatte Web服务灰度发布:新模型版本AB测试与用户反馈闭环机制 1. 引言 在AI图像处理领域,模型迭代更新是持续提升服务质量的必经之路。SDMatte作为一款专注于高质量图像抠图的AI模型,近期完成了新版本SDMatte的研发工作。本文将详细介绍我…...
)
新手避坑指南:用Prometheus+PX4+ROS在Gazebo里复现无人机追踪小车(保姆级流程)
新手避坑指南:用PrometheusPX4ROS在Gazebo里复现无人机追踪小车(保姆级流程) 当第一次接触无人机仿真开发时,很多人会被复杂的工具链和晦涩的错误信息劝退。本文将手把手带你完成从零搭建仿真环境到实现视觉追踪的全过程ÿ…...

Deepfake Offensive Toolkit Docker部署:跨平台解决方案详解
Deepfake Offensive Toolkit Docker部署:跨平台解决方案详解 【免费下载链接】dot The Deepfake Offensive Toolkit 项目地址: https://gitcode.com/gh_mirrors/dot/dot Deepfake Offensive Toolkit(简称dot)是一款功能强大的深度学习…...

Qwen3.5-4B-Claude-Opus部署教程:模型路径软链失效时的容错加载机制
Qwen3.5-4B-Claude-Opus部署教程:模型路径软链失效时的容错加载机制 1. 模型概述 Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF是基于Qwen3.5-4B的推理蒸馏模型,特别强化了结构化分析、分步骤回答以及代码与逻辑类问题的处理能力。该版本以GG…...

OpenClaw硬件监控:nanobot定时报告系统资源使用情况
OpenClaw硬件监控:nanobot定时报告系统资源使用情况 1. 为什么需要自动化硬件监控 去年夏天,我的开发机因为内存泄漏问题突然宕机,导致一个重要的线上演示被迫推迟。当时我就意识到,手动检查系统资源的方式既不及时也不可靠。直…...

一文读懂大模型,彻底告别 AI 焦虑 | 零门槛
今天,不聊复杂代码、不晒专业论文,用最直白的语言,带非技术背景的你彻底读懂大模型:核心逻辑、实用场景、产品选型,以及普通人应对AI浪潮的正确姿势。全文干货密集,建议收藏转发,读完摆脱AI焦虑…...

2026年上海网站建设市场分析:企业官网从展示到增长的演进路径
2026年,上海企业数字化服务市场迎来结构性变革。据2026年上半年上海企业数字化服务市场调研数据显示,上海地区企业官网新建与升级需求同比增长45%,中大型企业对官网的核心诉求已从基础信息展示转向AI智能赋能、全球化跨境适配、全链路营销转化…...

从单片机到汽车座舱:ThreadX RTOS在嵌入式领域的真实应用场景与选型思考
ThreadX RTOS在汽车座舱与工业控制中的实战选型指南 当特斯拉Model S的17英寸触控屏在2012年首次亮相时,很少有人注意到支撑这套系统的幕后英雄——实时操作系统。如今,从智能手表到航空电子设备,实时操作系统(RTOS)已成为嵌入式世界的隐形支…...

Gradio项目快速公网演示:除了share=True,你还有这几种轻量级内网穿透方案
Gradio项目快速公网演示:5种轻量级内网穿透方案横向评测 当你开发了一个酷炫的机器学习模型演示,或是精心设计的数据可视化界面,最迫切的需求往往是如何快速分享给同事或客户。Gradio的shareTrue参数可能是大多数开发者首先想到的方案&#x…...

用DolphinScheduler实现数仓自动化:从零搭建ETL工作流实战
用DolphinScheduler构建电商数仓ETL流水线:实战设计与优化指南 电商平台每天产生的TB级订单数据,如何转化为精准的用户画像和实时销售报表?本文将带你从零搭建一个基于DolphinScheduler的自动化数据处理流水线,解决实际业务场景中…...