面试宝典进阶之redis缓存面试题
R1、【初级】Redis常用的数据类型有哪些?
(1)String(字符串)
(2)Hash(哈希)
(3)List(列表)
(4)Set(集合)
(5)zset(sorted set:有序集合)
它还有三种特殊的数据结构类型
- Geospatial
- Hyperloglog
- Bitmap
理解思路
- 说出5种类型
- 说出每种类型的应用场景,要跟项目的业务结合
R2、redis的持久化方式有几种,项目中怎么选择?
(1)RDB:全量备份,节省磁盘空间,恢复速度快。但是可能会丢失数据。
(2)AOF:日志增量备份,数据保存完整。但是整体的恢复效率低,占空间。
(3)如果数据比较敏感的情况下,建议两个都开启。如果只是做纯缓存,数据不敏感,可以都不开启
(4)默认开启的是RDB。
R3、如果想在redis里面存储一个Java对象,能存吗?
(1)可以存储,项目中使用的redisTemplate默认的是将Vule值序列化后存储到redis。
(2)也可以将Java对象转成json字符串存储到redis。
R4、RedisTemplate和StringRedisTemplate区别?
(1)StringRedisTemplate继承了RedisTemplate但是两者的数据不能共用,RedisTemplate存储的数据只能通过RedisTemplate获取。
(2)StringRedisTemplate和RedisTemplate最大的区别就是默认采用的序列化策略不同,StringRedisTemplate默认的是String序列化,RedisTemplate默认使用的是JDK的序列化方式。
(3)StringRedisTemplate存储效率比RedisTemplate高,同时存储占用空间小。但是不如RedisTemplate灵活方便。当操作的数据是复杂的Java对象而不想做任何数据类型转换的时候那么建议使用RedisTemplate
理解思路
- 序列化方式不一样
R5、如何保证redis中存放的都是热点数据?
(1)设置redis的最大存储空间,建议设置为服务器内存的3/4。
(2)设置redis的内存淘汰策略,设置为volatile-lru或allkeys-lru。
(3)到达redis的最大值触发内存淘汰机制:
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰。
- allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰)
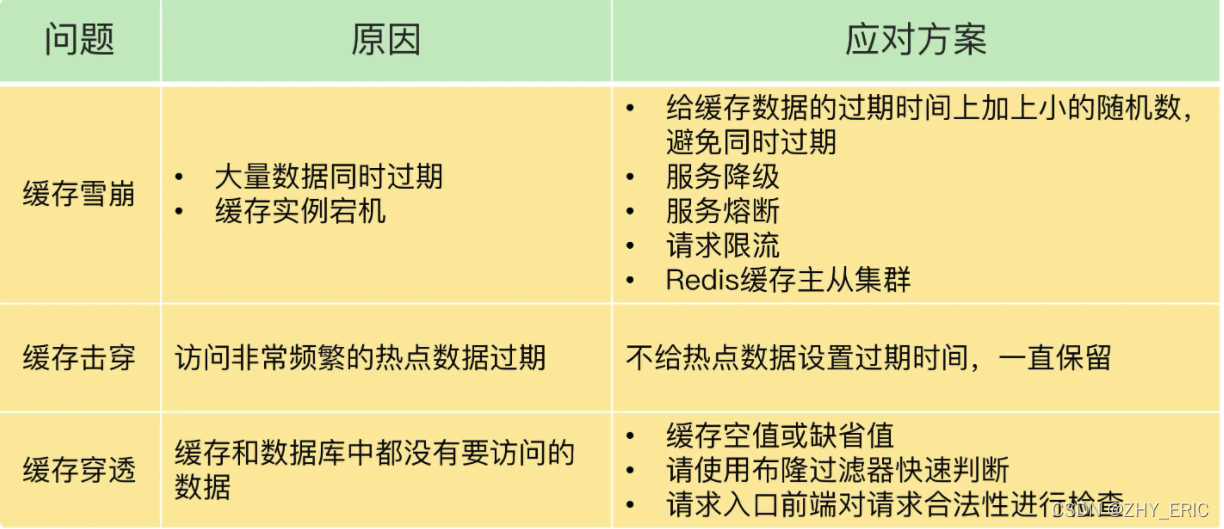
R6、什么是缓存击穿?
是针对缓存中没有但数据库有的数据。场景是,当一个热Key失效后,假如瞬间突然涌入大量的请求,来请求同一个Key,这些请求不会命中Redis,都会请求到DB,导致数据库压力过大,甚至扛不住,挂掉。
理解思路
- 某个热KEY
- 突然过期
- 数据库宕机
- 解决方式:设置永不过期
R7、什么是Redis的缓存雪崩?
(1)是指大量的热Key同时失效,对这些Key的请求就会瞬间打到DB上,同样会导致数据库压力过大甚至挂掉。
(2)解决方案:
- 设置KEY永不过期,但缺点是占用大量内存
- 设置KEY的过期时间为一个随机值,这样就能够防止大量的热KEY同时过期
理解思路
- 大量的
- 热KEY
- 短时间内过期
- 数据库宕机
- 解决方案:设置过期时间为随机数
R8、什么是缓存穿透?
(1)Redis缓存穿透指的是,在Redis缓存和数据库中都找不到相关的数据。也就是说这是个非法的查询,客户端发出了大量非法的查询 比如id是负的 ,导致每次这个查询都需要去Redis和数据库中查询。导致MySql直接爆炸!
(2)解决方案:
- 缓存空对象:如果他的查询数据是合法的,但是确实Redis和MySql中都没有,那么我们就在Redis中储存一个空对象,这样下次客户端继续查询的时候就能在Redis中返回了。但是,如果客户端一直发送这种恶意查询,就会导致Redis中有很多这种空对象,浪费很多空间
- 布隆过滤器:当我们想新增一个元素时(例如新增python),布隆过滤器就会使用hash函数计算出几个索引值,然后将二进制数组中对应的位置修改为1。
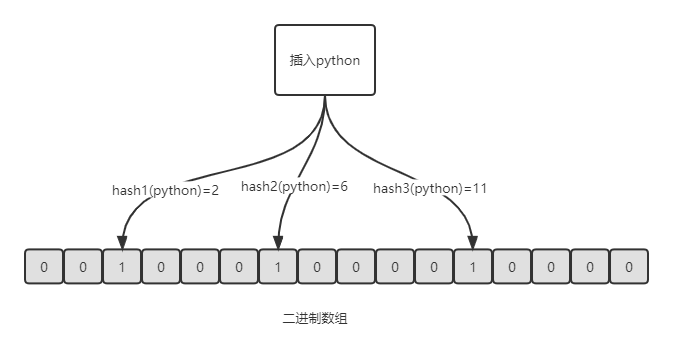
理解思路
- 大量的不存在的KEY
- 这些访问可能是恶意的
- 数据库宕机
- 解决:缓存前面布置布隆过滤器
R9、缓存击穿、缓存穿透、缓存雪崩的解决方案是什么?
R10、Redis是单线程的为什么速度还那么快?
(1)完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。
(2)数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
(3)采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
(4)使用多路I/O复用模型,非阻塞IO;所以可以一次性接收多个客户端请求,然后放到队列中;
理解思路
- 存储设备:内存
- 单线程:没有锁
- 数据结构专门设计
- 多路I/O复用
R11、Redis 是单进程单线程的吗?
(1)Redis 在设计上采用将网络数据读写和协议解析通过多线程的方式来处理,对于命令执行来说,仍然使用单线程操作。
(2)从Redis6 版本开始,已经引入了多线程。
理解思路
- 数据操作一直都是单线程的
- 在6.0以后,在网络数据传输、数据解析等使用了多线程,但是数据操作仍是单线程的
R12、Redis 的Key过期,他是怎么删除的?
(1)定时删除:在设置某个 key 的过期时间同时,我们创建一个定时器,让定时器在该过期时间到来时,立即执行对其进行删除的操作。
(2)惰性删除:设置该 key 过期时间后,我们不去管它,当需要该 key 时,我们在检查其是否过期,如果过期,我们就删掉它,反之返回该 key。
(3)定期删除:每隔一段时间,我们就对一些 key 进行检查,删除里面过期的 key。
R13、如何设置 Redis 的最大内存?
在配置文件 redis.conf 中,可以通过参数 maxmemory 来设定最大内存:
# In short... if you have slaves attached it is suggested that you set a lower
# limit for maxmemory so that there is some free RAM on the system for slave
# output buffers (but this is not needed if the policy is 'noeviction').
#
maxmemory <bytes># MAXMEMORY POLICY: how Redis will select what to remove when maxmemory
# is reached. You can select among five behaviors:
#
# volatile-lru -> remove the key with an expire set using an LRU algorithm
# allkeys-lru -> remove any key according to the LRU algorithm
# volatile-random -> remove a random key with an expire set
# allkeys-random -> remove a random key, any key
# volatile-ttl -> remove the key with the nearest expire time (minor TTL)
# noeviction -> don't expire at all, just return an error on write operations
理解思路
- 修改配置文件
R14、Redis 内存淘汰策略有哪些?
当使用的内存大于 maxmemory 时,就会触发 Redis 主动淘汰内存方式:
(1)volatile-lru:利用 LRU 算法移除设置过过期时间的 key (LRU:最近使用 Least Recently Used );
(2)allkeys-lru:利用 LRU 算法移除任何key (和上一个相比,删除的 key 包括设置过期时间和不设置过期时间的),通常使用该方式;
(3)volatile-random:移除设置过过期时间的随机key ;
(4)allkeys-random:无差别的随机移除;
(5)volatile-ttl:移除即将过期的 key (minor TTL);
(6)noeviction:不移除任何 key,只是返回一个写错误 ,默认选项,一般不会选用。
在 redis.conf 配置文件中,可以设置 maxmemory-policy 来设置内存淘汰方式:
# Note: with any of the above policies, Redis will return an error on write
# operations, when there are no suitable keys for eviction.
#
# At the date of writing these commands are: set setnx setex append
# incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd
# sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby
# zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby
# getset mset msetnx exec sort
#
# The default is:
#
maxmemory-policy noeviction
理解思路
- 不要背英文
- 说淘汰方式
R15、Redis定期删除策略是定时删除所有过期的KEY吗?
Redis 的定期删除策略并不是一次运行就检查所有的库、所有的键,而是随机检查一定数量的键。
定期删除函数的运行频率,在 Redis2.6 版本中,规定每秒运行 10 次,大概 100ms 运行一次。在 Redis2.8 版本后,可以通过修改配置文件 redis.conf 的 hz 选项来调整这个次数:
# The range is tetween 1 and 500, however a value over 100 is usually not
# a good idea. Most users should use the default of 10 and raise this up to
# 100 only in environments where very low latency is requiried.
hz 10
才这个参数的上面注释可以看出,建议不要将这个值设置超过100,一般使用默认的10,只有当在需要非常低延迟的场景才设置为100。
R16、Redis的主从全量同步流程能说说吗?
(1)slave节点请求增量同步
(2)master节点判断replid,发现不一致,拒绝增量同步,使用全量同步
(3)master将完整数据生成RDB,发送RDB到slave
(4)slave清空本地数据,加载RDB文件
(5)master将RDB期间产生的命令记录在repl_baklog,并持续性的将repl_baklog发送到slave
(6)slave接收到这些命令,保持与master数据同步。
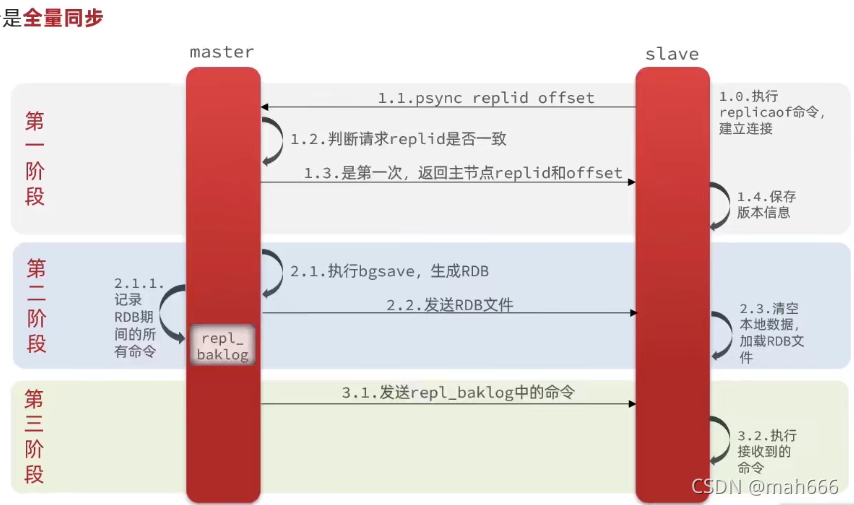
理解思路
- 谁先连谁
- 连接时,带什么东西
- 主收到id后,发送什么
R17、Redis的主从增量同步流程能说说吗?
(1)slave节点请求增量同步
(2)master节点判断replid,如果一致返回continue
(3)从repl_baklog中获取增量数据
(4)发送offset后面的命令
repl_baklog的容量是有上线的,写满后会覆盖最早的数据。如果slave断开的时间太久,导致尚未备份的数据被覆盖(offset会标记repl_baklog中备份的数据),就无法做增量同步,只能去做全量同步。

R18、能说说你对布隆过滤器的理解吗?
(1)布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。
(2)布隆过滤器的结构
R19、如果Redis服务崩溃了怎么办?
(1)给Redis设置持久化,这样服务器重启能够快速恢复到工作状态。
(2)搭建Redis集群实现高可用。
R20、你知道怎么实现Redis的高可用吗?
我们在项目中使用Redis,肯定不会是单点部署Redis服务的。因为,单点部署一旦宕机,就不可用了。为了实现高可用,通常的做法是,将数据库复制多个副本以部署在不同的服务器上,其中一台挂了也可以继续提供服务。
Redis 实现高可用有三种部署模式:
- 主从模式
- 哨兵模式
- 集群模式。
R21、说说你对Redis哨兵模式的理解?
主从模式中,一旦主节点由于故障不能提供服务,需要人工将从节点晋升为主节点,同时还要通知应用方更新主节点地址。显然,多数业务场景都不能接受这种故障处理方式。Redis从2.8开始正式提供了Redis Sentinel(哨兵)架构来解决这个问题。
哨兵模式,由一个或多个Sentinel实例组成的Sentinel系统,它可以监视所有的Redis主节点和从节点,并在被监视的主节点进入下线状态时,自动将下线主服务器属下的某个从节点升级为新的主节点。但是呢,一个哨兵进程对Redis节点进行监控,就可能会出现问题(单点问题),因此,可以使用多个哨兵来进行监控Redis节点,并且各个哨兵之间还会进行监控。
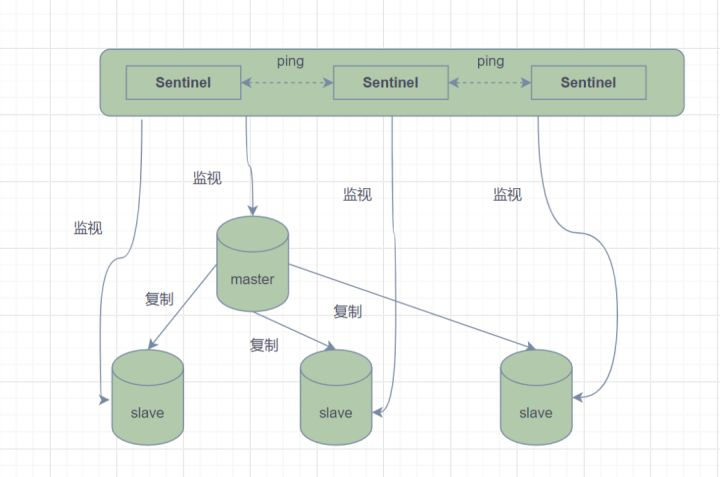
理解思路
- 哨兵是一个独立的进程
- 每个哨兵监控一个服务器
- 哨兵实现消息通知和执行选举
R22、Redis哨兵模式的作用是什么?
简单来说,哨兵模式就三个作用:
(1)发送命令,等待Redis服务器(包括主服务器和从服务器)返回监控其运行状态;
(2)哨兵监测到主节点宕机,会自动将从节点切换成主节点,然后通过发布订阅模式通知其他的从节点,修改配置文件,让它们切换主机;
(3)哨兵之间还会相互监控,从而达到高可用。
R23、Redis哨兵模式故障切换的过程是怎样的呢?
(1)每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他Sentinel实例发送一个 PING命令。
(2)如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel标记为主观下线。
(3)如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。
(4)当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线。
(5)在一般情况下, 每个 Sentinel 会以每10秒一次的频率向它已知的所有Master,Slave发送 INFO 命令。
(6)当Master被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次
(7)若没有足够数量的 Sentinel同意Master已经下线, Master的客观下线状态就会被移除;若Master 重新向 Sentinel 的 PING 命令返回有效回复, Master 的主观下线状态就会被移除。
R24、Redis的Cluster集群模式解决了什么问题?
哨兵模式基于主从模式,实现读写分离,它还可以自动切换,系统可用性更高。但是它每个节点存储的数据是一样的,浪费内存,并且不好在线扩容。因此,Cluster集群应运而生,它在Redis3.0加入的,实现了Redis的分布式存储。对数据进行分片,也就是说每台Redis节点上存储不同的内容,来解决在线扩容的问题。并且,它也提供复制和故障转移的功能。
理解思路
- 高可用
- 提高性能
- 实现扩容
R25、Redis的Cluster集群节点之间是如何通讯的?
一个Redis集群由多个节点组成,各个节点之间是通过Gossip协议!
Redis Cluster集群通过Gossip协议进行通信,节点之前不断交换信息,交换的信息内容包括节点出现故障、新节点加入、主从节点变更信息、slot信息等等。常用的Gossip消息分为4种,分别是:ping、pong、meet、fail。
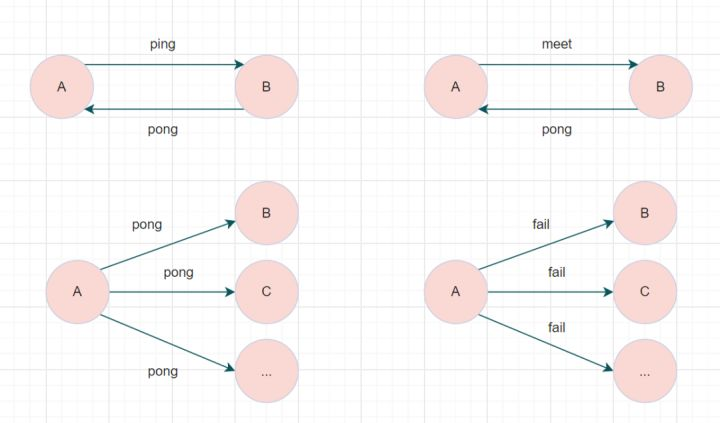
- meet消息:通知新节点加入。消息发送者通知接收者加入到当前集群,meet消息通信正常完成后,接收节点会加入到集群中并进行周期性的ping、pong消息交换。
- ping消息:集群内交换最频繁的消息,集群内每个节点每秒向多个其他节点发送ping消息,用于检测节点是否在线和交换彼此状态信息。
- pong消息:当接收到ping、meet消息时,作为响应消息回复给发送方确认消息正常通信。pong消息内部封装了自身状态数据。节点也可以向集群内广播自身的pong消息来通知整个集群对自身状态进行更新。
- fail消息:当节点判定集群内另一个节点下线时,会向集群内广播一个fail消息,其他节点接收到fail消息之后把对应节点更新为下线状态。
特别的,每个节点是通过集群总线(cluster bus) 与其他的节点进行通信的。通讯时,使用特殊的端口号,即对外服务端口号加10000。例如如果某个node的端口号是6379,那么它与其它nodes通信的端口号是 16379。nodes 之间的通信采用特殊的二进制协议。
R26、能说说Redis分布式集群是如何存储数据的吗?
Hash Slot插槽算法
既然是分布式存储,Cluster集群使用的分布式算法是一致性Hash嘛?并不是,而是Hash Slot插槽算法。
插槽算法把整个数据库被分为16384个slot(槽),每个进入Redis的键值对,根据key进行散列,分配到这16384插槽中的一个。使用的哈希映射也比较简单,用CRC16算法计算出一个16 位的值,再对16384取模。数据库中的每个键都属于这16384个槽的其中一个,集群中的每个节点都可以处理这16384个槽。
集群中的每个节点负责一部分的hash槽,比如当前集群有A、B、C个节点,每个节点上的哈希槽数 =16384/3,那么就有:
- 节点A负责0~5460号哈希槽
- 节点B负责5461~10922号哈希槽
- 节点C负责10923~16383号哈希槽
R27、如何保证mysql和redis的数据的一致性?
这是一个redis双写一致性的问题,我们的策略是**先删缓存,再写数据库,数据更新完成后,再删缓存**。
相关文章:
面试宝典进阶之redis缓存面试题
R1、【初级】Redis常用的数据类型有哪些? (1)String(字符串) (2)Hash(哈希) (3)List(列表) (4)Se…...

调试(c语言)
前言: 我们在写程序的时候可能多多少少都会出现一些bug,使我们的程序不能正常运行,所以为了更快更好的找到并修复bug,使这些问题迎刃而解,学习好如何调试代码是每个学习编程的人所必备的技能。 1. 什么是bug…...
opencv-4.8.0编译及使用
1 编译 opencv的编译总体来说比较简单,但必须记住一点:opencv的版本必须和opencv_contrib的版本保持一致。例如opencv使用4.8.0,opencv_contrib也必须使用4.8.0。 进入opencv和opencv_contrib的github页面后,默认看到的是git分支&…...

Jmeter 性能-监控服务器
Jmeter监控Linux需要三个文件 JMeterPlugins-Extras.jar (包:JMeterPlugins-Extras-1.4.0.zip) JMeterPlugins-Standard.jar (包:JMeterPlugins-Standard-1.4.0.zip) ServerAgent-2.2.3.zip 1、Jemter 安装插件 在插件管理中心的搜索Servers Perform…...
Excel学习
文章目录 学习链接Excel1. Excel的两种形式2. 常见excel操作工具3.POI1. POI的概述2. POI的应用场景3. 使用1.使用POI创建excel2.创建单元格写入内容3.单元格样式处理4.插入图片5.读取excel并解析图解POI 4. 基于模板输出POI报表5. 自定义POI导出工具类ExcelAttributeExcelExpo…...

【技能---labelme软件的安装及其使用--ubuntu】
文章目录 概要Labelme 是什么?Labelme 能干啥? Ubuntu20.04安装Labelme1.Anaconda的安装2.Labelme的安装3.Labelme的使用 概要 图像检测需要自己的数据集,为此需要对一些数据进行数据标注,这里提供了一种图像的常用标注工具——la…...

回归预测 | Matlab实现SSA-CNN-LSTM-Attention麻雀优化卷积长短期记忆神经网络注意力机制多变量回归预测(SE注意力机制)
回归预测 | Matlab实现SSA-CNN-LSTM-Attention麻雀优化卷积长短期记忆神经网络注意力机制多变量回归预测(SE注意力机制) 目录 回归预测 | Matlab实现SSA-CNN-LSTM-Attention麻雀优化卷积长短期记忆神经网络注意力机制多变量回归预测(SE注意力…...

css垂直水平居中的几种实现方式
垂直水平居中的几种实现方式 一、固定宽高: 1、定位 margin-top margin-left .box-container{position: relative;width: 300px;height: 300px;}.box-container .box {width: 200px; height: 100px;position: absolute; left: 50%; top: 50%;margin-top: -50px;…...

OpenHarmony之hdc
OpenHarmony之hdc 简介 hdc(OpenHarmony Device Connector)是 OpenHarmony 为开发人员提供的用于调试的命令行工具,通过该工具可以在Windows/Linux/MacOS等系统上与开发机或者模拟器进行交互。 类似于Android的adb,和adb类似&a…...
【爬虫实战】-爬取微博之夜盛典评论,爬取了1.7w条数据
前言: TaoTao之前在前几期推文中发布了一个篇weibo评论的爬虫。主要就是采集评论区的数据,包括评论、评论者ip、评论id、评论者等一些信息。然后有很多的小伙伴对这个代码很感兴趣。TaoTao也都给代码开源了。由于比较匆忙,所以没来得及去讲这…...

CST2024的License服务成功启动,仍报错——“The desired daemon is down...”,适用于任何版本!基础设置遗漏!
CST2024的License服务成功启动,仍报错——“The desired daemon is down…”,适用于任何版本!基础设置遗漏! CST2024的License服务成功启动后报错 若不能成功启动License服务,有可能是你的计算机名称带中文ÿ…...

matlab中any()函数用法
一、帮助文档中的介绍 B any(A) 沿着大小不等于 1 的数组 A 的第一维测试所有元素为非零数字还是逻辑值 1 (true)。实际上,any 是逻辑 OR 运算符的原生扩展。 二、解读 分两步走: ①确定维度;②确定运算规则 以下面二维数组为例 >>…...
Apache ECharts | 一个数据可视化图表库
文章目录 1、简介1.1、主要特点1.2、使用场景 2、安装方式一:从下载的源代码或编译产物安装方法二:从 npm 安装方法三:⭐定制安装echarts.js 3、使用 官网: 英语:https://echarts.apache.org/en/index.html 中文&a…...
m1 + swoole(hyperf) + yasd + phpstorm 安装和debug
参考文档 Mac M1安装报错 checking for boost... configure: error: lib boost not found. Try: install boost library Issue #89 swoole/yasd GitHub 1.安装boost库 brew install boostbrew link boost 2.下载yasd git clone https://github.com/swoole/yasd.git 3.编…...
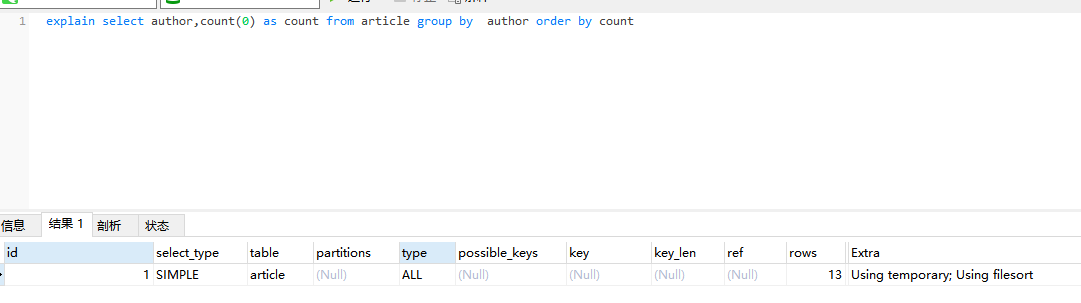
group by 查询慢的话,如何优化?
1、说明 根据一定的规则,进行分组。 group by可能会慢在哪里?因为它既用到临时表,又默认用到排序。有时候还可能用到磁盘临时表。 如果执行过程中,会发现内存临时表大小到达了上限(控制这个上限的参数就是tmp_table…...

【重学C语言】一、C语言简介
【重学C语言】一、C语言简介 什么是编程语言?编程语言 C语言发展史C语言标准变迁开发软件CLion安装步骤 VIsual Studio安装步骤 Clion 和 VS2022 绑定 电脑常识 什么是编程语言? 人类语言:语言就是人类进行沟通交流的表达方式,应…...
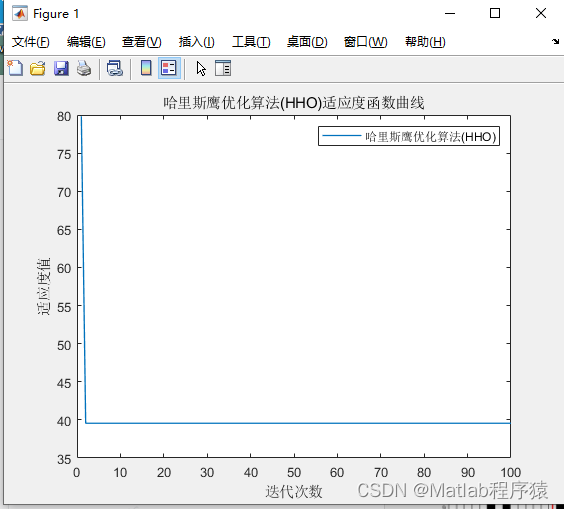
【MATLAB源码-第109期】基于matlab的哈里斯鹰优化算发(HHO)机器人栅格路径规划,输出做短路径图和适应度曲线。
操作环境: MATLAB 2022a 1、算法描述 哈里斯鹰优化算法(Harris Hawk Optimization, HHO)是一种受自然界捕食行为启发的优化算法。它基于哈里斯鹰的捕猎策略和行为模式,主要用于解决各种复杂的优化问题。这个算法的核心特征在于…...

NestJS 如何自定义中间件以及实际项目基于中间件提升项目开发效率
前言 NestJS 作为一个强大的 Node.js 框架,允许你通过中间件对请求和响应进行处理。中间件的概念在其他许多框架中也存在,它们在请求处理流程的早期执行,因此非常适合执行如日志记录、请求验证、设置响应头等任务。 在这篇教程中࿰…...

CMake入门教程【核心篇】设置和使用缓存变量
😈「CSDN主页」:传送门 😈「Bilibil首页」:传送门 😈「动动你的小手」:点赞👍收藏⭐️评论📝 文章目录 概述设置缓存变量使用缓存变量更改缓存变量完整代码示例实战使用技巧注意事项总结与分析...
 .net core实现分片上传)
MinIO (五) .net core实现分片上传
开发环境 Win11 vs2022 appsettings.json添加配置项 //minIO配置"MinIO": {//服务器IP"Endpoint": "192.168.xx.xx:9090",//账号"AccessKey": "3xR7i4zs1vLnxxxxxxxx",//密码"SecretKey": "P6bAnyzJm47Ub…...

Excel办公必备4个技巧:格式转换、隔列插入、限制编辑、文本数字分离
在日常办公中,Excel是我们使用频率最高的软件之一,但很多人只掌握了最基础的录入和简单计算功能,遇到一些“卡脖子”的小问题就束手无策,不得不手动折腾半天。其实,Excel中隐藏着不少实用的小技巧,能帮你轻…...
)
手把手教你用魔塔社区+LLaMA-Factory,免费微调Qwen2.5-7B模型(保姆级避坑指南)
零成本玩转Qwen2.5-7B微调:魔塔社区LLaMA-Factory实战手册 最近在开源模型社区里,Qwen2.5系列凭借其优秀的对话能力和中文理解表现,迅速成为开发者们的新宠。但很多朋友反馈,虽然想尝试微调这个模型来适配自己的业务场景ÿ…...
)
MySQL视图实战:用SQL视图搞定学生奖学金评定与补考名单(附完整代码)
MySQL视图实战:用SQL视图搞定学生奖学金评定与补考名单(附完整代码) 教务管理系统中,数据处理效率直接影响决策质量。想象一下每学期末,教务处老师需要从数十万条记录中筛选奖学金候选人和补考名单——传统的手写SQL查…...

acjscsdbhvusfd
一、yolo v1是什么? YOLO(You Only Look Once)算法 是一种目标检测算法,是经典的one-stage方法。YOLO v1 开创了单阶段目标检测的先河,其简洁的架构 和高效的推理为后续版本奠定了基础。尽管存在小目标检测和定位精度的…...

Charticulator:数据可视化的自由创作平台与技术革命
Charticulator:数据可视化的自由创作平台与技术革命 【免费下载链接】charticulator Interactive Layout-Aware Construction of Bespoke Charts 项目地址: https://gitcode.com/gh_mirrors/ch/charticulator 当数据分析师面对预设模板无法表达复杂数据关系时…...

半导体放电管TSS选型避坑指南:从RS485到CAN接口的实战经验分享
半导体放电管TSS选型避坑指南:从RS485到CAN接口的实战经验分享 在工业通信设备的电路保护设计中,浪涌防护是一个不可忽视的关键环节。作为一名长期奋战在一线的硬件工程师,我深知半导体放电管(TSS)选型过程中的种种陷阱…...

NaViL-9B多模态提示词工程:提升图文理解准确率的10个实用技巧
NaViL-9B多模态提示词工程:提升图文理解准确率的10个实用技巧 1. 认识NaViL-9B多模态模型 NaViL-9B是一款原生支持多模态交互的大语言模型,能够同时处理文本和图像输入。与传统的纯文本模型不同,它可以直接"看懂"图片内容&#x…...

LeetDown完全指南:系统降级功能解决A6/A7设备用户的卡顿痛点
LeetDown完全指南:系统降级功能解决A6/A7设备用户的卡顿痛点 【免费下载链接】LeetDown a GUI macOS Downgrade Tool for A6 and A7 iDevices 项目地址: https://gitcode.com/gh_mirrors/le/LeetDown LeetDown是一款专为macOS设计的图形化降级工具࿰…...

Spring AI:Spring生态的AI工程框架全面解析
Spring AI:Spring生态的AI工程框架全面解析 【免费下载链接】spring-ai An Application Framework for AI Engineering 项目地址: https://gitcode.com/GitHub_Trending/spr/spring-ai Spring AI是Spring生态系统中的AI工程框架,为Java开发者提供…...

LangChainJS审计日志:AI操作可追溯性的完整指南
LangChainJS审计日志:AI操作可追溯性的完整指南 【免费下载链接】langchainjs 项目地址: https://gitcode.com/GitHub_Trending/la/langchainjs 在当今AI应用开发中,确保AI操作的可追溯性和透明性至关重要。LangChainJS提供了强大的审计日志系统…...