NLP论文阅读记录 - WOS | ROUGE-SEM:使用ROUGE结合语义更好地评估摘要
文章目录
- 前言
- 0、论文摘要
- 一、Introduction
- 1.1目标问题
- 1.2相关的尝试
- 1.3本文贡献
- 二.相关工作
- 三.本文方法
- 四 实验效果
- 4.1数据集
- 4.2 对比模型
- 4.3实施细节
- 4.4评估指标
- 4.5 实验结果
- 4.6 细粒度分析
- 五 总结
前言

ROUGE-SEM: Better evaluation of summarization using ROUGE combined with semantics(23)
0、论文摘要
随着预训练语言模型和大规模数据集的发展,自动文本摘要引起了自然语言处理界的广泛关注,但自动摘要评估的进展却停滞不前。尽管人们一直在努力改进自动摘要评估,但由于其具有竞争力的评估性能,ROUGE 近 20 年来仍然是最受欢迎的指标之一。
然而,ROUGE并不完美,有研究表明,它存在抽象摘要评估不准确和生成摘要多样性有限的问题,这都是由词汇偏差造成的。为了避免词汇相似性的偏差,人们提出了越来越多有意义的基于嵌入的度量,通过测量语义相似性来评估摘要。由于准确测量语义相似度的挑战,它们都无法完全取代 ROUGE 作为文本摘要的默认自动评估工具包。
为了解决上述问题,我们提出了一种折衷评估框架(ROUGE-SEM),用于利用语义信息改进ROUGE,通过语义相似度模块弥补语义意识的缺乏。根据语义相似度和词汇相似度的差异,首次将摘要分为四类:好摘要、珍珠摘要、玻璃摘要和坏摘要。
特别是,采用回译技术重写了ROUGE评估不准确的pearl-summary和glass-summary,以减轻词汇偏差。通过这个管道框架,摘要首先由候选摘要分类器分类,然后由分类摘要重写器重写,最后由重写的摘要评分器评分,以符合人类行为的方式进行有效评估。当使用 Pearson、Spearman 和 Kendall 等级系数进行测量时,我们的建议在连贯性、一致性、流畅性和相关性方面比几种最先进的自动摘要评估指标实现了与人类判断相当或更高的相关性。这也表明用语义改进 ROUGE 是自动摘要评估的一个有前途的方向。
一、Introduction
1.1目标问题
作为自然语言处理 (NLP) 最受关注的领域之一,自动文本摘要 (ATS) 已被广泛研究了数十年(El-Kassas、Salama、Rafea 和 Mohamed,2021;Garg 和 Kumar,2022;Xiao,何和金,2022)。特别是近年来,由于大规模数据集的引入(Cohen, Kalinsky, Ziser, & Moschitti, 2021; Fabbri, Li, She, Li, & Radev, 2019)以及预训练的提出,ATS 得到了快速发展。语言模型 (PLM)(Ghadimi & Beigy,2022;Mohd、Jan 和 Shah,2020;Xie、Bishop、Tiwari 和 Ananiadou,2022)。特别是,一个有效的自动摘要评估指标对于 ATS 来说将是一个巨大的福音,因为不仅可以将人们从耗时耗力的人工评价中解放出来,而且极大地促进了文本摘要的发展。
正如 Koto、Baldwin 和 Lau(2022)中提到的,ATS 的主流评估采用 ROUGE(Lin,2004),这是一种简单但有用的评估指标,用于计算候选摘要和参考摘要之间的重叠单位。然而,广泛使用的ROUGE对于自动摘要评估来说并不完美。 ROUGE因其直观、简单和易于计算而受到欢迎,但有研究指出它仍然存在缺陷(Lin et al., 2022; Schluter, 2017; ShafieiBavani, Ebrahimi, Wong, & Chen, 2018)。由于ROUGE可能通过测量候选摘要和参考摘要之间的词汇相似性而表现出词汇偏差(Ng&Abrecht,2015),因此它在评估ATS时具有以下局限性。首先,ROUGE 通常被认为不适合评估抽象摘要,因为它限制了生成摘要的多样性。众所周知,同一个源文档可以为具有不同知识或目的的人生成不同表达方式的多个摘要。然而,ROUGE 通过奖励具有较大词汇相似性的摘要并惩罚具有较小词汇相似性的摘要来限制生成摘要的多样性。其次,带有词汇偏差的ROUGE无法全面评估候选摘要。为了全面评估候选摘要,人工评估通常会考虑很多因素,包括冗余性、信息量和可读性等。然而,ROUGE本质上无法评估候选摘要的文本质量,因为它只考虑候选摘要之间的词汇相似度和参考摘要。具体来说,ROUGE 在连贯性和流畅性方面表现出更好的相关性,但在一致性和相关性方面表现出较差的相关性,这是基于词汇相似性的指标的常见问题。最后,ROUGE 已多次被证明与手动评估具有良好的相关性,但由于这些局限性,仍然有很大的改进空间。
为了改进自动摘要评估,人们做出了许多努力来解决 ROUGE 的上述局限性。一方面,一些研究通过同义词替换和释义对 ROUGE 进行了扩展,例如 ROUGE-WE (Ng & Abrecht, 2015)、ROUGE 2.0 (Ganesan, 2018) 和 ROUGE-G (ShafieiBavani et al., 2018)。另一方面,一些研究考虑了单词之间的语义关系来替代标准ROUGE。由于精确单词匹配的限制,近年来越来越多的基于语义嵌入的度量被提出,这些度量计算两个摘要的向量表示之间的相似度。作为基于语义嵌入的度量的早期代表,GM (Rus & Lintean, 2012)、VE (Forgues, Pineau, Larchevêque, & Tremblay, 2014) 和 SMS (Clark, Celikyilmaz, & Smith, 2019) 发挥了积极的作用在自动总结评价中。最近,Cao和Zhuge(2022)采用语义链接网络来评估候选摘要的保真度、简洁性和连贯性。尤其是随着PLM的快速发展,基于PLM的自动摘要评估研究引起了相当大的关注,例如MoverScore(Zhao et al., 2019)、BERTScore(Zhang, Kishore, Wu, Weinberger, & Artzi, 2020)和BARTScore(Yuan、Neubig 和 Liu,2021)。最近,SPEED(Akula & Garibay,2022)使用专门针对句子对任务进行预训练的句子级嵌入来计算两个文本的语义相似度。 Sem-nCG (Akter, Bansal, & Santu, 2022) 是一种基于增益的评估指标,它不仅具有语义意识,而且还根据句子的排名奖励摘要。此外,ENMS (He, Jiang, Chen, Le, & Ding, 2022) 利用语义信息来增强现有的基于 N-gram 的评估指标。由于获取参考摘要的困难,研究人员还提出了用于评估候选摘要的无参考指标,例如 SUPERT (Gao, Zhu, & Eger, 2020)、SDC* (Liu, Jia, & Zhu, 2022) 和 Shannon (伊根、瓦西里耶夫和博汉农,2022)。尽管不断努力改进自动摘要评估,但这些指标都不能完全取代 ROUGE 作为文本摘要的默认自动评估工具包,因为它已被反复证明与多个维度的人类判断良好相关。
在本文中,我们提出了一种折衷方法来解决 ROUGE 的上述局限性,因为准确测量语义相似性具有挑战性。受到 ShafieiBavani 等人的启发。 (2018),我们提出了一种管道框架(ROUGE-SEM),该框架使用 ROUGE 结合语义信息进行自动摘要评估。具体来说,采用具有对比学习的Siamese-BERT网络作为语义相似度模块来弥补语义意识的缺乏。如图1所示,所提出的评估框架由候选摘要分类器、分类摘要重写器和重写摘要评分器。这些单独的组件构成了符合人类行为的管道方法,即首先利用语义和词汇相似性对候选摘要进行分类,然后重写难以评估的摘要,最后根据分类和重写的结果对摘要进行重新评分。
为了更直观地说明所提出的 ROUGE-SEM,我们提供了 DialSummEval 数据集中的一些典型示例。如图2所示,源文档、参考摘要和候选摘要分别显示在前三列中。第四列和第五列分别评估候选摘要在词汇或语义上是否与参考摘要相似。然后,候选摘要的类别显示在第六列中。第七列展示了反向翻译的结果。最后,最后两列分别显示标准 ROUGE-1/2/L 分数和建议的 ROUGE-SEM-1/2/L 分数。从图2中,我们观察到,根据语义和词汇相似度的差异,候选摘要被分为四类,包括goodsummary、pearl-summary、glass-summary和bad-summary。由于词汇偏差,ROUGE很难准确评估语义相关但不相似的珍珠摘要和语义不相关但相似的玻璃摘要。通过使用反向翻译技术重写上述摘要,我们可以通过更多样化的同义表达来减轻其对词汇相似性的偏见。这样,被低估的珍珠摘要有很高的概率获得较高的分数,而高估的玻璃摘要有很高的概率获得较低的分数。这就是为什么ROUGE-SEM是比传统ROUGE更有效的评估指标,它通过解决词汇偏差问题,显着提高了pearl-summary和glass-summary的评估性能。
为了验证我们提出的评估指标,对 SummEval (Fabbri, Kryściński, McCann, Xiong, Socher, & Radev, 2021) 和 DialSummEval (Gao & Wan, 2022) 进行了广泛的实验。特别是,Pearson、Spearman 和 Kendall 相关系数用于衡量评估表现的连贯性、一致性、流畅性和相关性。实验结果表明,ROUGE-SEM 的性能优于或相当几个最先进的总结评估指标。与成熟的 ROUGE 指标相比,无论使用何种相关性度量,所提出的评估指标在四个维度上都显示出与人类判断更高且更一致的相关性。这些令人兴奋的结果证实了使用语义来增强 ROUGE 的有效性,表明这是自动摘要评估的一个有前途的方向。
1.2相关的尝试
1.3本文贡献
总之,我们的贡献如下:
• 我们提出了一种新颖的摘要评估指标(ROUGESEM),它通过具有对比学习的Siamese-BERT网络弥补语义意识的缺乏,从而改进了传统的ROUGE。所提出的评估指标由三个单独的组件组成,包括候选摘要分类器、分类摘要重写器和重写摘要评分器。通过这个管道框架,摘要首先被分类,然后重写,最后评分,以符合人类行为的方式进行有效评估。
• 根据候选摘要和参考摘要在词汇相似度和语义相似度上的差异,我们引入了候选摘要的分类。它包括语义相关且词汇相似的good-summary、语义相关但词汇不相似的pearl-summary、语义不相关但词汇相似的glass-summary、语义不相关且词汇不相似的bad-summary。我们相信这将有利于自动摘要评估的进展,特别是提供改进基于词汇重叠的度量的潜力。
• 我们在两个基准数据集上进行实验来验证ROUGE-SEM 的有效性。
实验结果表明,我们提出的指标优于或与 SummEval 和 DialSummEval 数据集上的几种最先进的摘要评估指标相当,这表明这是自动摘要评估的一个有前途的方向。我们还分享了拟议的 ROUGE-SEM,以促进文本摘要系统的未来工作。
二.相关工作
由于文本摘要的手动评估对于大规模数据集并不实用,因此自动摘要评估引起了研究人员的广泛关注(Deutsch, Dror, & Roth, 2021;Shapira, Pasunuru, Ronen, Bansal,Amsterdamer, & Dagan, 2021;Wang ,Otmakhova、DeYoung、Truong、Kuehl、Bransom 和 Wallace,2023;Zhao 和 Lui,2022)。到目前为止,已经使用了多种指标来衡量文本摘要系统的性能。近年来提出的自动摘要评估指标概述如表1所示。本节介绍ATS评估的相关工作,分为外在评估和内在评估两类。
三.本文方法
四 实验效果
4.1数据集
4.2 对比模型
4.3实施细节
4.4评估指标
4.5 实验结果
4.6 细粒度分析
五 总结
在本文中,我们提出了一种新的评估指标ROUGE-SEM,它通过结合语义信息来增强流行的ROUGE。为了实现这一目标,候选摘要分类器、分类摘要重写器和重写摘要评分器作为主要组件以符合人类行为的方式构成了管道框架。具体地,候选摘要分类器采用语义相似度模块来计算语义相似度,并使用词汇相似度模块来计算候选摘要和参考摘要之间的词汇相似度。然后,根据语义相似度和词汇相似度的差异,将候选摘要分为四组,包括好摘要、珍珠摘要、玻璃摘要和坏摘要。对于ROUGE错误评估的pearl-summary和glass-summary,分类摘要重写器采用回译技术,通过更多样化的同义表达来减轻词汇偏差。最后,重写摘要评分器根据候选摘要分类器和分类摘要重写器的结果输出更准确的评估分数。实验结果表明,ROUGE-SEM 的性能可与现有的强基线和广泛使用的指标(使用三个系数测量)相媲美。特别是,ROUGE-SEM 的变体始终优于 ROUGE 的相应变体。
在未来的工作中,我们将采用一些特定于任务的预训练语言模型作为语义编码器,以实现更准确的语义相似度。我们将考虑用各种文本生成模型替换反向翻译模块以进行离线评估。此外,我们将采用更高效的参数优化策略进行参数调优。最后,我们将应用建议的指标来评估现有的基线和最先进的总结器。我们希望这项工作能够对未来文本摘要系统的研究产生积极的影响。
相关文章:
NLP论文阅读记录 - WOS | ROUGE-SEM:使用ROUGE结合语义更好地评估摘要
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.相关工作三.本文方法四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果4.6 细粒度分析 五 总结 前言 ROUGE-SEM: Better evaluation of summarization using ROUGE combin…...
vscode 创建文件自动添加注释信息
随机记录 目录 1. 背景介绍 2. "Docstring Generator"扩展 2.1 安装 2.2 设置注释信息 3. 自动配置py 文件头注释 1. 背景介绍 在VS Code中,您可以使用扩展来为新创建的Python文件自动添加头部注释信息。有几个常用的扩展可以实现此功能࿰…...
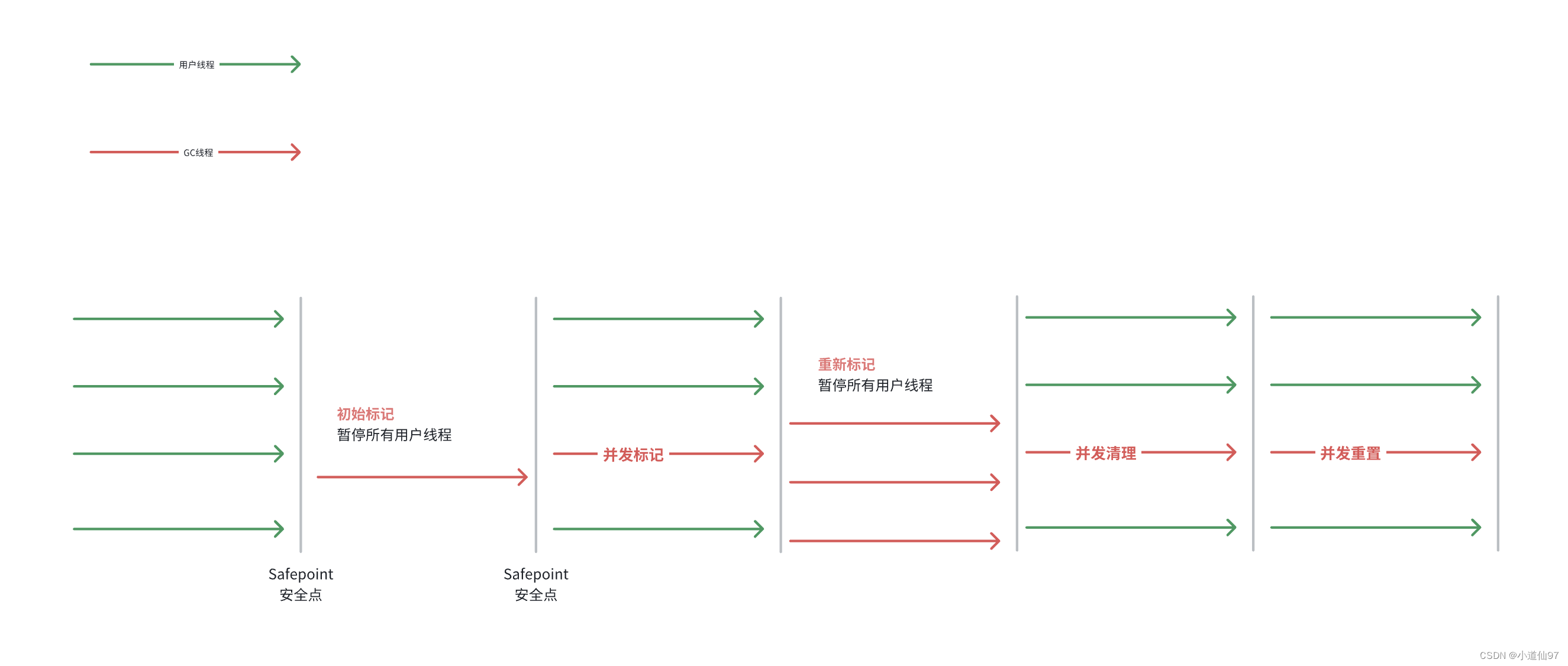
JVM内存区域详解,一文弄懂JVM内存【内存分布、回收算法、垃圾回收器】
视频讲解地址 学习文档 一、内存区域 区域描述线程私有如何溢出程序计数器为了线程切换后能恢复到正确的执行位置,每个线程都要有一个独立的程序计数器。✅唯一一个不会内存溢出的地方虚拟机栈1. 每个方法执行的时候,Java虚拟机都会同步创建一个栈帧用于…...
uniapp搜索附近蓝牙信标(iBeacon)
一、 iBeacon介绍 iBeacon是苹果在2013年WWDC上推出一项基于蓝牙4.0(Bluetooth LE | BLE | Bluetooth Smart)的精准微定位技术,在iPhone 4S后支持。当你的手持设备靠近一个Beacon基站时,设备就能够感应到Beacon信号,范…...

Redis 常见数据结构以及使用场景分析
Java面试题目录 Redis 常见数据类型以及使用场景分析 Redis中有string、list、hash、set、sorted set、bitmap这6种数据类型。 string可以用来做缓存,分布式锁,计数器等。 list可以实现消息队列,分页查询等。 hash适合存储对象结构。 set 可…...

LMDeploy 大模型量化部署实践
LMDeploy 大模型量化部署实践 大模型部署背景模型部署定义产品形态计算设备 大模型特点大模型挑战大模型部署方案 LMDeploy简介推理性能核心功能-量化核心功能-推理引擎TurboMind核心功能 推理服务 api-server 案例(安装、部署、量化) 大模型部署背景 模型部署 定义 将训练好…...

15个为你的品牌增加曝光的维基百科推广方法-华媒舍
维基百科是全球最大的免费在线百科全书,拥有庞大的用户群体和高质量的内容。在如今竞争激烈的市场中,利用维基百科推广品牌和增加曝光度已成为许多企业的重要策略。本文将介绍15种方法,帮助你有效地利用维基百科推广品牌,提升曝光…...
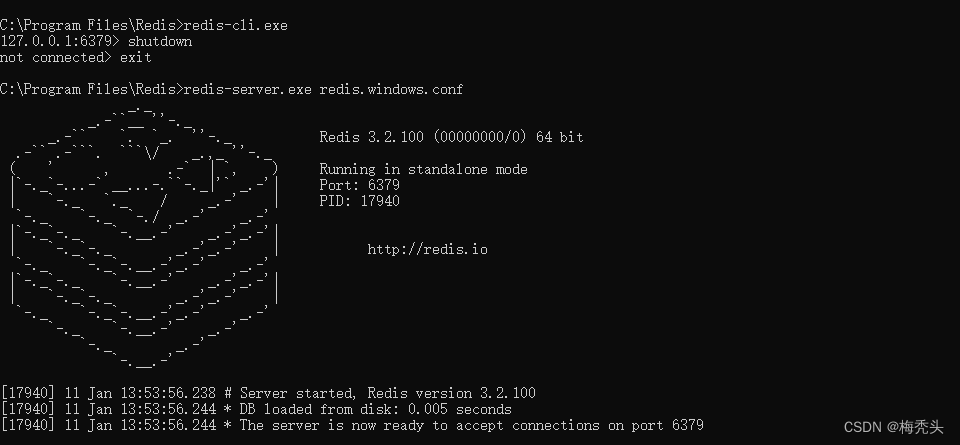
启动redis出现Creating Server TCP listening socket 127.0.0.1:6379: bind: No error异常
1.进入redis安装目录,地址栏输入cmd 2.输入命令 redis-server.exe redis.windows.conf redis启动失败 解决,输入命令 #第一步 redis-cli.exe#第二步 shutdown#第三步 exit第四步 redis-server.exe redis.windows.conf 显示以下图标即成功...

响应式编程Reactor优化Callback回调地狱
1. Reactor是什么 Reactor 是一个基于Reactive Streams规范的响应式编程框架。它提供了一组用于构建异步、事件驱动、响应式应用程序的工具和库。Reactor 的核心是 Flux(表示一个包含零到多个元素的异步序列)和 Mono表示一个包含零或一个元素的异步序列…...
React项目实战--------极客园项目PC端
项目介绍:主要将学习到的项目内容进行总结(有需要项目源码的可以私信我) 关于我的项目的配置如下,请注意下载的每个版本不一样,写的api也不一样 一、项目介绍 1.资料 1)短信接收&M端演示:…...
,q(q <= 1e5)次询问,求向前走d最少要几次)
Jerry每次能向前或向后走n*n步(始终不能超过初始位置1e5),q(q <= 1e5)次询问,求向前走d最少要几次
题目 思路:因为有走的过程不能超初始位置1e5的限制,所以不能直接用奇数最多两次,4的倍数最多两次的结论。spfa,平方数的dis为1,然后推出其他数的dis #include<bits/stdc.h> using namespace std; #define int …...

【Spring Boot 3】【Flyway】数据库版本管理
【Spring Boot 3】【Flyway】数据库版本管理 背景介绍开发环境开发步骤及源码工程目录结构总结背景 软件开发是一门实践性科学,对大多数人来说,学习一种新技术不是一开始就去深究其原理,而是先从做出一个可工作的DEMO入手。但在我个人学习和工作经历中,每次学习新技术总是…...
)
蓝桥杯基础数据结构(java版)
引言 数据结构数据结构。所以数据结构是一个抽象的概念。其目的是为了更好的组织数据方便数据存储。下面我们来看一些简单的数据储存方式 输入和输出 这里先介绍java的输入和输出。简单引入,不过多详细介绍,等我单一写一篇的时候这里会挂上链接 简单的…...

39 C++ 模版中的参数如果 是 vector,list等集合类型如何处理呢?
在前面写的例子中,模版参数一般都是 int,或者一个类Teacher,假设我们现在有个需求:模版的参数要是vector,list这种结合类型应该怎么写呢? //当模版中的类型是 vector ,list 等集合类型的时候的处…...
5.Pytorch模型单机多GPU训练原理与实现
文章目录 Pytorch的单机多GPU训练1)多GPU训练介绍2)pytorch中使用单机多GPU训练DistributedDataParallel(DDP)相关变量及含义a)初始化b)数据准备c)模型准备d)清理e)运行 3)使用DistributedDataParallel训练模型的一个简单实例 欢迎访问个人网络日志🌹🌹知…...

想成为一名C++开发工程师,需要具备哪些条件?
C语言是一门面向过程的、抽象化的通用程序设计语言,广泛应用于底层开发。C语言能以简易的方式编译、处理低级存储器。C语言是仅产生少量的机器语言以及不需要任何运行环境支持便能运行的高效率程序设计语言。尽管C语言提供了许多低级处理的功能,但仍然保…...
Qat++,轻量级开源C++ Web框架
目录 一.简介 二.编译Oat 1.环境 2.编译/安装 三.试用 1.创建一个 CMake 项目 2.自定义客户端请求响应 3.将请求Router到服务器 4.用浏览器验证 一.简介 Oat是一个面向C的现代Web框架 官网地址:https://oatpp.io github地址:https://github.co…...

openssl3.2 - 官方demo学习 - digest - EVP_MD_demo.c
文章目录 openssl3.2 - 官方demo学习 - digest - EVP_MD_demo.c概述笔记END openssl3.2 - 官方demo学习 - digest - EVP_MD_demo.c 概述 使用 SHA3-512 对多个buffer连续进行摘要, 最后得到一个摘要值 笔记 /*! \file EVP_MD_demo.c \note openssl3.2 - 官方demo学习 - dig…...
uniapp 编译后文字乱码的解决方案
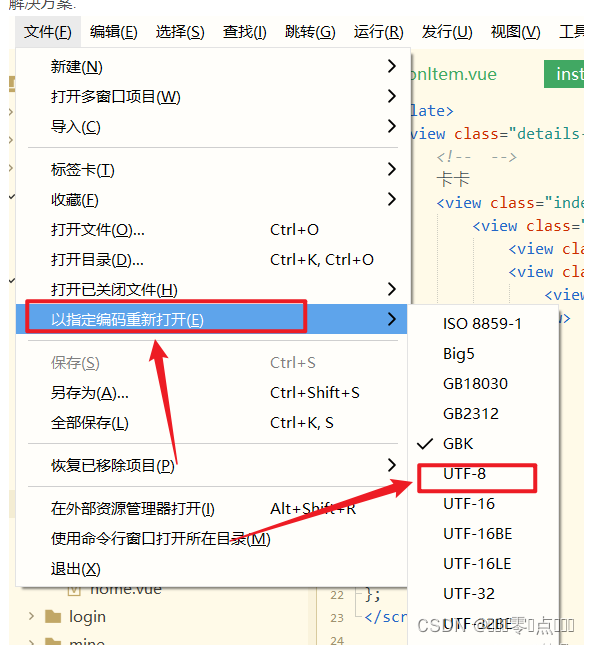
问题: 新建的页面中编写代码,其中数字和图片都可以正常显示,只有中文编译后展示乱码 页面展示也是乱码 解决方案: 打开HuilderX编辑器的【文件】- 【以指定编码重新打开】- 【选择UTF-8】 然后重新编译就可以啦~ 希望可以帮到你啊~...

iOS中利用KeyChain永久保存用户信息的方法示例
方法示例 一、新建一个LYKeychainTool类,导入系统Security框架 ,LYKeychainTool.h文件实现如下 // // LYKeychainTool.h // keyChainTest // // Created by Liyu on 2017/6/2. // Copyright © 2017年 liyu. All rights reserved. //#import <F…...

计算机专业生打 CTF 全指南:从新手小白到赛事拿分,附实战避坑手册_ctf比赛自己带电脑吗
作为计算机专业毕业的过来人,我始终觉得:CTF 比赛是大学生把课本知识落地成硬技能的最佳载体。 刚上大二时,我还是个只会敲基础代码、对 网络安全停留在课本概念的小白,靠着 3 次参赛经历,不仅吃透了操作系统、计算机…...

【Go Context】终极指南
一、Context 到底是干嘛的? 一句话: 用来在 Goroutine 之间传递:取消信号、超时信号、请求级数据。 核心目的:控制协程生命周期,防止泄漏、卡死、资源浪费。二、Context 四大核心能力 1. 取消信号(WithCanc…...

智慧养殖与猪行为实例分割数据集 动物行为分析数据集 生猪进食数据集 生猪睡觉站立姿态识别数据集 yolo格式数据集
猪行为实例分割数据集核心信息 类别 Tags 标签 Instance Segmentation 实例分割 Model 模型Classes (4) 类别(4) Eating 进食 Lying 躺着 Sitting 坐着 Standing 站立数据集关键信息表信息类别具体内容数据集类别猪行为实例分割数据集,聚焦猪…...

在珠宝首饰加工中,遨博协作机器人配合微力控技术,实现宝石的自动化镶嵌
在珠宝首饰的高端制造领域,宝石镶嵌是决定产品最终价值与艺术表现力的灵魂工序。这一过程要求近乎苛刻的精度、无可挑剔的稳定性,以及对脆性材料的极致呵护。长期以来,这依赖于镶嵌师多年练就的“手感”与专注力,属于劳动力高度密…...
)
中药实验管理系统|基于springboot+vue的中药实验管理系统(源码+数据库+文档)
中药实验管理系统 目录 基于springbootvue的中药实验管理系统 一、前言 二、系统设计 三、系统功能设计 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂码农|毕设布道师,…...

UE5.3导入FBX实战:如何完美保留Maya/Blender的复杂层级并一键设置碰撞?
UE5.3 FBX导入全流程:从Maya/Blender复杂层级到可交互蓝图的终极解决方案 当机械臂的每个关节都需要独立控制,当建筑群中的每扇门窗都要单独设置碰撞,当角色装备的每件武器都需绑定动画——这些正是三维内容创作者在UE5中处理复杂资产时的真实…...

PowerSetting下载慢?CDN加速+离线包分发方案
运维团队最怕什么?不是流量高峰,而是高峰期偏偏遇到软件包下载失败、更新卡死、内网带宽被打满。PowerSetting这类工具包虽然不大,但在大规模批量部署时,每一次从公网拉取都是一次不确定的赌博,网络抖动、节点失效、外…...

别再问SAP权限怎么配了!从MM01物料创建权限入手,5分钟搞懂PFCG角色配置核心逻辑
SAP权限配置实战:从MM01物料创建权限掌握PFCG角色设计精髓 在SAP项目实施中,权限配置往往是新手顾问最容易卡壳的环节。当用户抱怨"为什么我点这个按钮就报权限错误"时,很多刚入行的顾问只能尴尬地回应"我查查后台配置"。…...

Gemini 3.5 Flash 实测报告:快4倍、编程跑分超自家Pro,这6类场景到底该不该换?
Gemini 3.5 Flash 实测报告:快4倍、编程跑分超自家Pro,这6类场景到底该不该换? 问题背景 Google 在 2026 年 5 月发布了 Gemini 3.5 Flash,主打"前沿性能 Flash 价位"。从基准测试数据看,这款模型在编程跑分…...

从‘管理模式’到‘监听模式’:一张无线网卡在Kali Linux下的四种工作模式详解与切换实战
从‘管理模式’到‘监听模式’:一张无线网卡在Kali Linux下的四种工作模式详解与切换实战 当你第一次在Kali Linux中插入无线网卡时,它默认处于"管理模式"——就像普通笔记本电脑连接WiFi一样温顺。但在这张小小的硬件里,其实藏着四…...