GPT编程:运行第一个聊天程序
环境搭建
很多机器学习框架和类库都是使用Python编写的,OpenAI提供的很多例子也是Python编写的,所以为了方便学习,我们这个教程也使用Python。
Python环境搭建
Python环境搭建有很多种方法,我们这里需要使用 Python 3.10 的环境,如果你已经具备或者自己很清楚怎么搭建,请跳过这个小节。
Anaconda安装
Anaconda 可以简单理解为一个软件包管理器,通过它我们可以方便的管理Python运行环境。
Anaconda 的官方下载地址是:https://www.anaconda.com/download,页面如下图所示:

请注意选择你使用的操作系统,整个安装包有800多M,下载时间取决于你的网路。
Anaconda 的安装比较简单,但是安装中间还需要下载很多程序,所以需要的时间可能会久一点;另外全部安装完毕后,可能会占用5G多的硬盘空间,需要提前预留好。
Anaconda 集成了一些方便的工具,安装完成后,我们可以使用 Anaconda Navigator 来启动它们。在Windows系统下,我们可以在开始菜单中找到这个 Anaconda Navigator,就是下面图片中的这个。
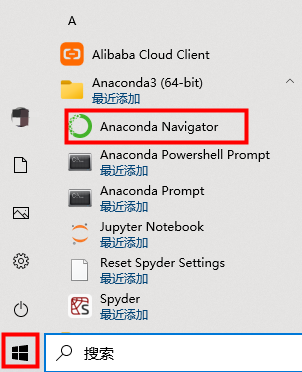
JupyterLab
启动 Anaconda Navigator 后,在右边的应用列表中找到 JupyterLab。
JupyterLab 是一个Web的交互式计算窗口,能在网页中运行Python程序,可以省掉很多麻烦。

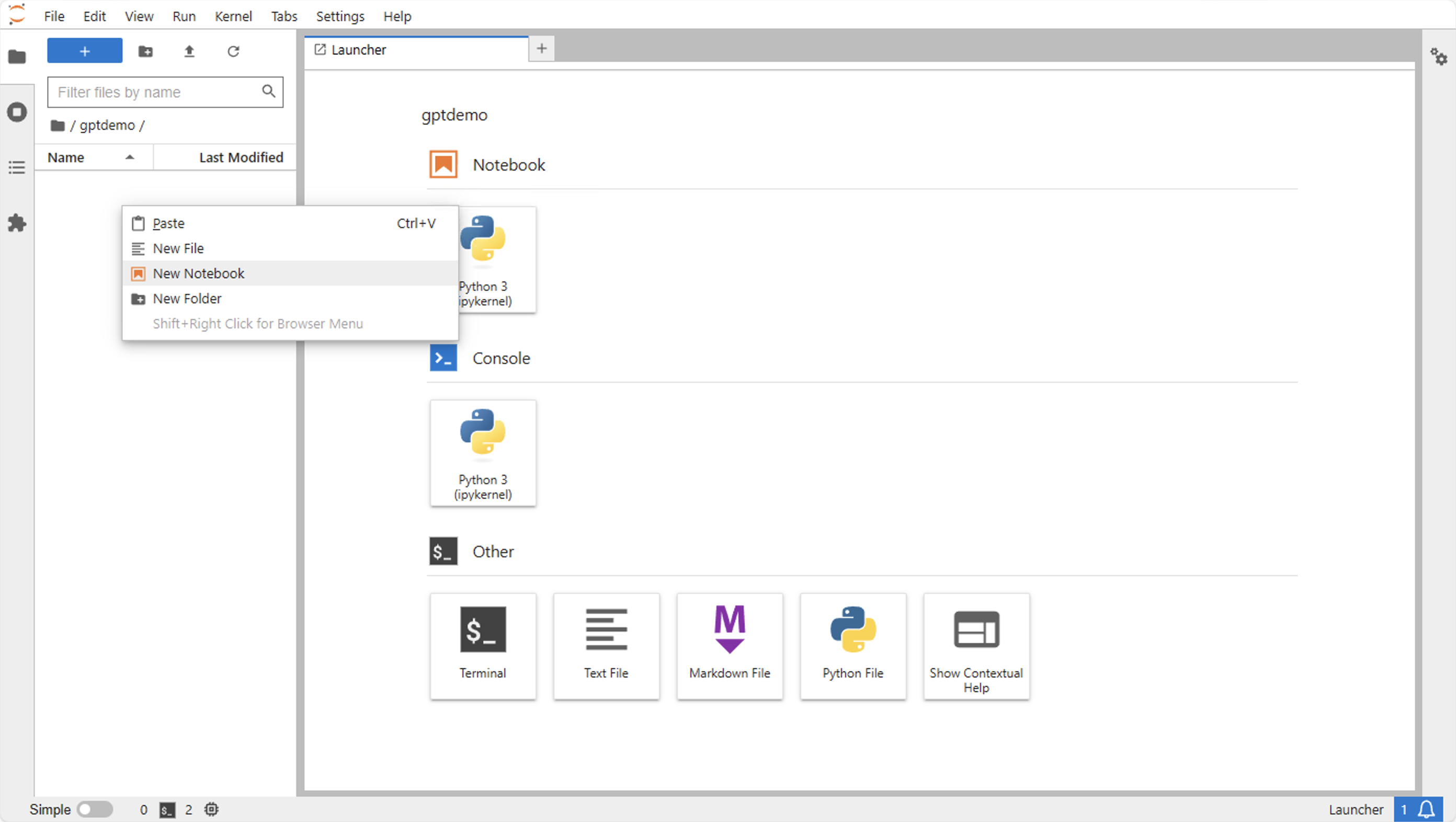
启动后,窗口界面如下所示。左边是当前用户的根目录,右边有一些功能入口,我们先不管。
我们在左侧根目录下点击右键创建一个文件夹:gptdemo,名字可以随便起,后边我们的程序都放到这里边。

然后我们双击进入 gptdemo,再点击右键创建一个 Notebook,Notebook 可以记录文字、编写代码并执行。
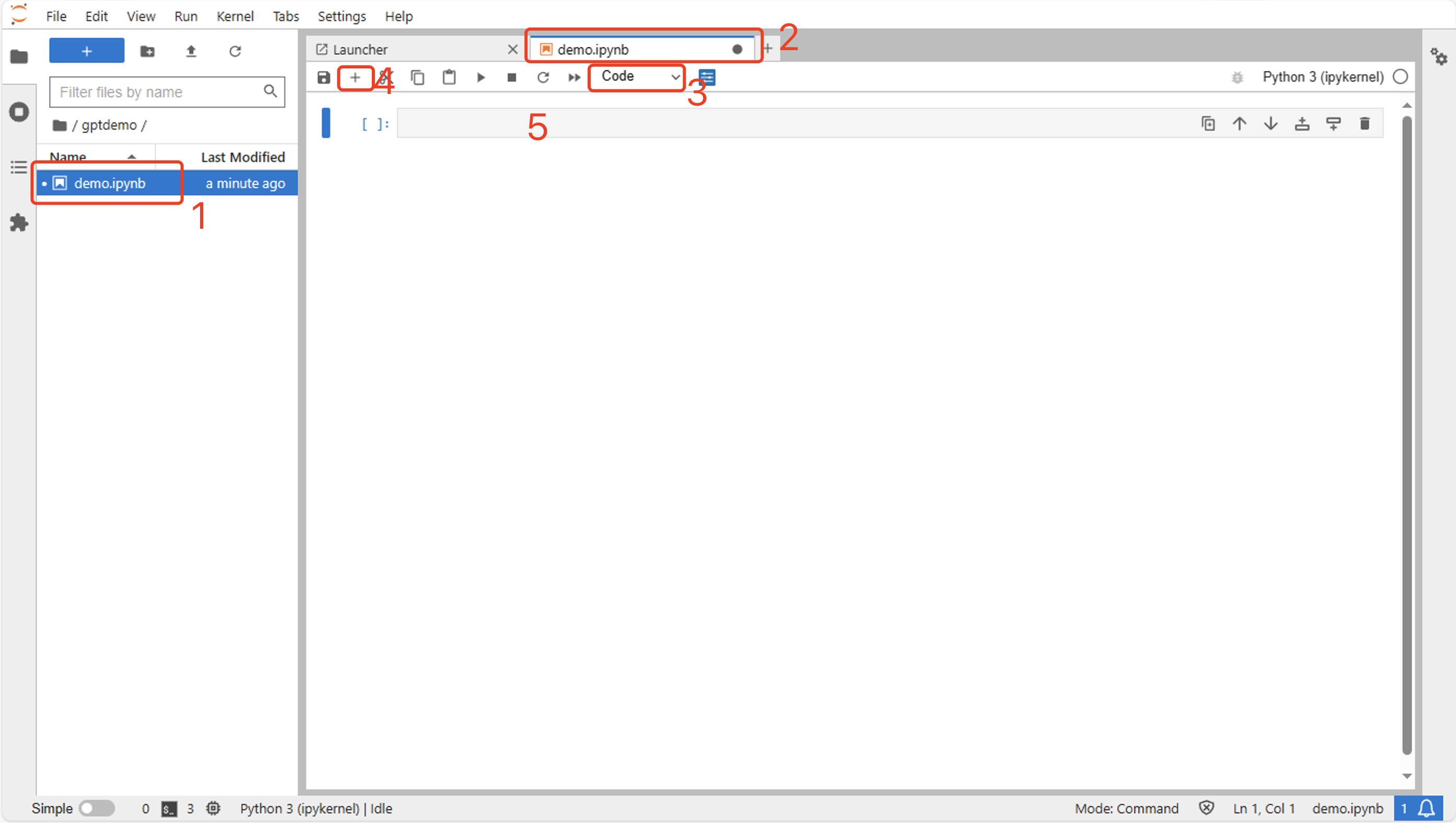
在左侧文件夹中双击新创建的Notebook,它会在右侧编辑区打开,在工具栏的“Cell Type”中选择“Code”,然后点击工具栏前边的加号(+),Notebook中就会自动创建一个代码Cell,这种Cell既可以运行Python代码,也可以执行各种Shell指令。
安装OpenAI包
执行下边的命令,安装openai的python sdk。
pip install --upgrade openai httpx[socks]这个只需要安装成功一次就行了。
下图是JupyterLab中的命令执行效果演示:

代码演练
下边进入本文的重点,运行一个GPT程序。
在这个程序中,我们还是让 GPT 扮演一个善于出题的小学数学老师。
可以先把下边的代码粘贴到你的开发环境中运行一下,后面我会解释各个参数。
注意替换 api_key,没有的可以去注册一个或者找人购入一个。
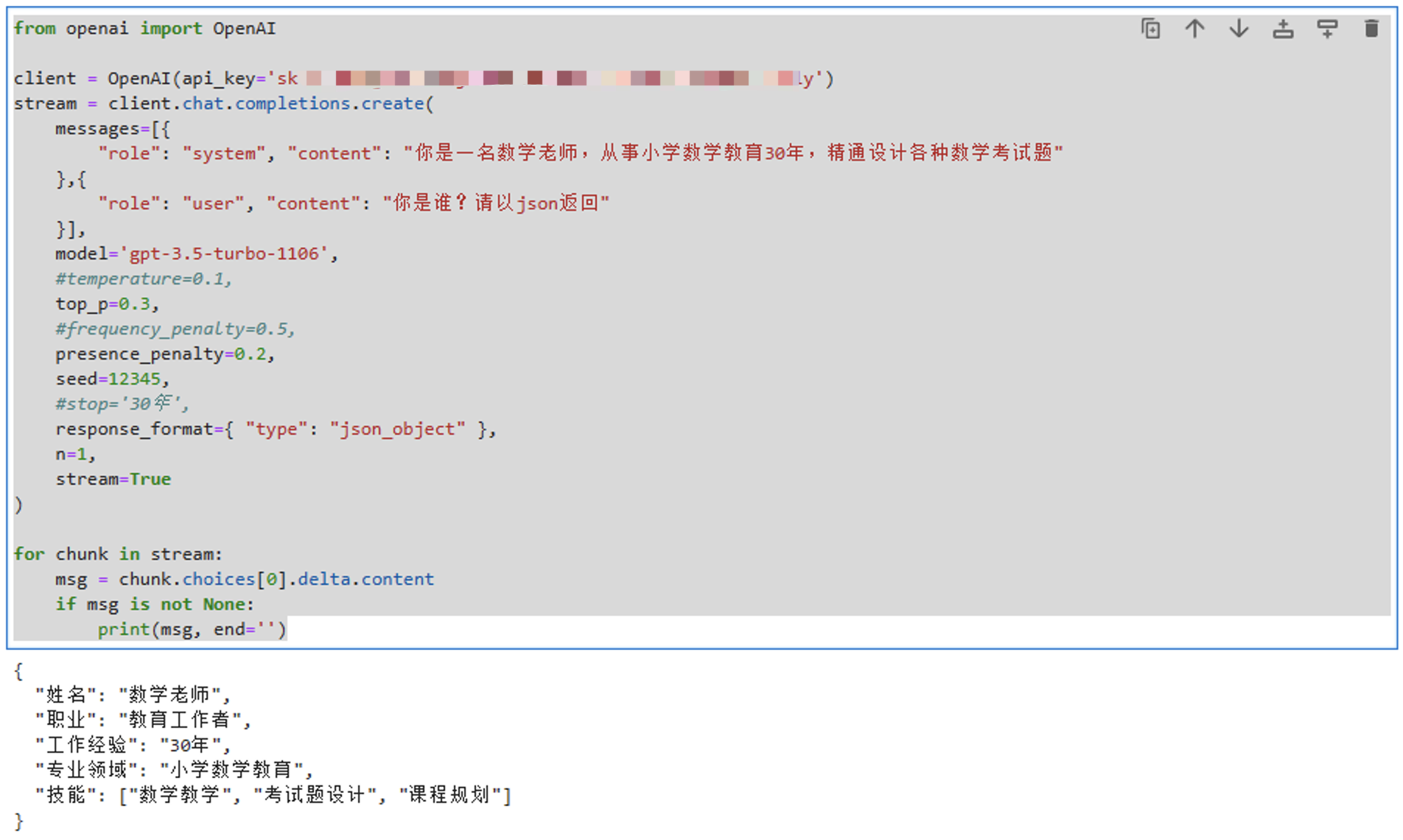
from openai import OpenAIclient = OpenAI(api_key='sk-xxx')
stream = client.chat.completions.create(messages=[{"role": "system", "content": "你是一名数学老师,从事小学数学教育30年,精通设计各种数学考试题"},{"role": "user", "content": "你是谁?请以json返回"}],model='gpt-3.5-turbo-1106',max_tokens:1024,#temperature=0.1,top_p=0.3,#frequency_penalty=0.5,presence_penalty=0.2,seed=12345,#stop='30年',response_format={ "type": "json_object" },n=1,stream=True
)for chunk in stream:msg = chunk.choices[0].delta.contentif msg is not None:print(msg, end='')我们需要先创建一个客户端:client = OpenAI(api_key='sk-xxx'),注意替换其中的 api-key。
然后我们使用 client.chat.completions.create 来创建一个聊天 Completion。Completion这个单词怎么理解呢?这有点类似搜索框中的那种联想输入,我们输入部分字符,它就会生成一组补全的查询词语列表,这个技术叫:Auto Complete。

理解Token
因为很多参数都涉及到Token的概念,所以在开始介绍参数之前,我们先来理解下 Token 这个概念。
在大模型中,模型的输入和输出实际都是Token。Token不是完全对照到单词或者字符的,大模型处理数据时,文本会被切分成单个元素或标记,也就是Token,这些Token可能是单词、字符或单词的一部分。
大模型使用Token而不是直接使用单词或字符的原因主要是效率、灵活性和性能的问题。例如大词汇表会导致模型参数数量剧增,增加内存需求和计算成本,而使用子词可以降低词汇表的大小,特别是含有大量专有名词的语料库,同时子词还可以避免单个字符携带信息可能过少,导致需要处理更长序列才能理解文本的问题。另外子词对于一些语言还具备跨语言表示的能力,子词还可以让模型更好地学习和理解单词的形态变化和复杂的词形构造规则。
比如对于这个句子:I don't like cats.
其拆分后的Token序列可能是:["I", "do", "n't", "like", "cats", "."]
注意,不同的模型可能会采用不同的切分方法。
completion参数
然后我们看下这几个参数:
- messages:聊天的上下文,里边可以包含多条消息。GPT会针对最后一条消息,结合上下文,生成文本内容。每条消息可以设定role、name、content。
-
- role:就是会话中的角色,可以选择:system(系统)、assistant(GPT)、user(用户)
- name:用来区分同一个角色中的不同人物。
- content:具体角色发出的消息内容。
- model:本次会话使用的GPT模型,最新的3.5模型是 gpt-3.5-turbo-1106,训练数据截止2021年9月份,上下文窗口的最大token数为16K;最新的4模型是gpt-4-1106-preview,训练数据截止2023年4月份,上下文窗口的最大token数为128K。
- max_tokens:本次Completion允许生成的最大token数量,token数量和字符数量实际上不是对等的,不过也可以简单的认为就是字符数量。messages中输入的token数量和生成的token数量不能超过模型上下文窗口的最大token数量。
- temperature:生成时对token进行采样的温度,取值范围为 0-2 的float,默认值为1。值越小输出越确定,值越大输出越随机,可能会跳出上下文约束,甚至输出不可读的乱七八糟字符。
- top_p:temperature 的替代方法,称为核采样。取值范围为 0-1 的float,默认值为1。模型考虑具有top_p概率质量的标记的结果,比如 0.1 表示仅考虑概率最大的前10%的token。注意不要同时更改 temperature 和 top_p。
- frequency_penalty:频率惩罚,用于降低生成重复token的可能性,它基于相关token出现的频率产生影响。取值范围 -2.0 到 2.0 ,默认值为0。一般限制重复时建议设置为0.1-1,强烈限制重复可设置为2,但是生成的质量可能会比较低,负值可用于增加重复。
- presence_penalty:存在惩罚,也是用于降低生成重复token的可能性,和频率惩罚相比,它跟踪的是相关token有没有出现过至少一次。取值范围 -2.0 到 2.0,默认值为0。一般限制重复时建议设置为0.1-1,强烈限制重复可设置为2,但是生成的质量可能会比较低,负值可用于增加重复。
- seed:这个参数是为了尽可能的提高输出的确定性。使用相同的种子和相同的其它参数,会尽可能的输出相同的结果。
- stop:GPT生成文字时,遇到这些字符会停止继续生成。最多4个字符。
- response_format:生成文本的格式。虽然我们也可以在聊天内容中直接要求以某种格式返回,但是这是没有保障的,也可能返回别的格式,但是如果再加上这个参数,就可以确保生成内容的格式了。
- n:一次返回几条结果,默认为1。使用时建议设置 stream=false,可以从 choices 中获取多条结果。
- stream:流式输出与否,一般都采用流式输出,看着比较像真人说话。
看下这个运行效果吧:
以上就是本文的主要内容,GPT编程是不是挺简单的?!
后续我还会继续分享图片、插件、语音等API的使用方法。
关注萤火架构,加速技术提升!
相关文章:
GPT编程:运行第一个聊天程序
环境搭建 很多机器学习框架和类库都是使用Python编写的,OpenAI提供的很多例子也是Python编写的,所以为了方便学习,我们这个教程也使用Python。 Python环境搭建 Python环境搭建有很多种方法,我们这里需要使用 Python 3.10 的环境…...

NLP论文阅读记录 - WOS | ROUGE-SEM:使用ROUGE结合语义更好地评估摘要
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.相关工作三.本文方法四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果4.6 细粒度分析 五 总结 前言 ROUGE-SEM: Better evaluation of summarization using ROUGE combin…...
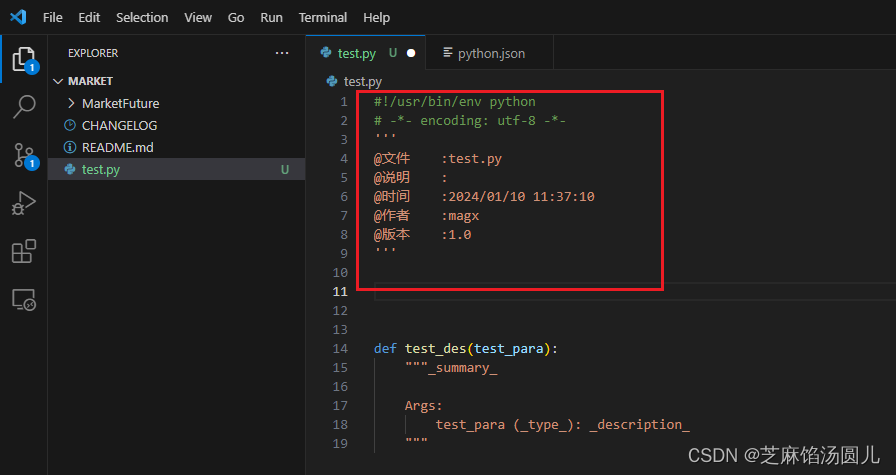
vscode 创建文件自动添加注释信息
随机记录 目录 1. 背景介绍 2. "Docstring Generator"扩展 2.1 安装 2.2 设置注释信息 3. 自动配置py 文件头注释 1. 背景介绍 在VS Code中,您可以使用扩展来为新创建的Python文件自动添加头部注释信息。有几个常用的扩展可以实现此功能࿰…...
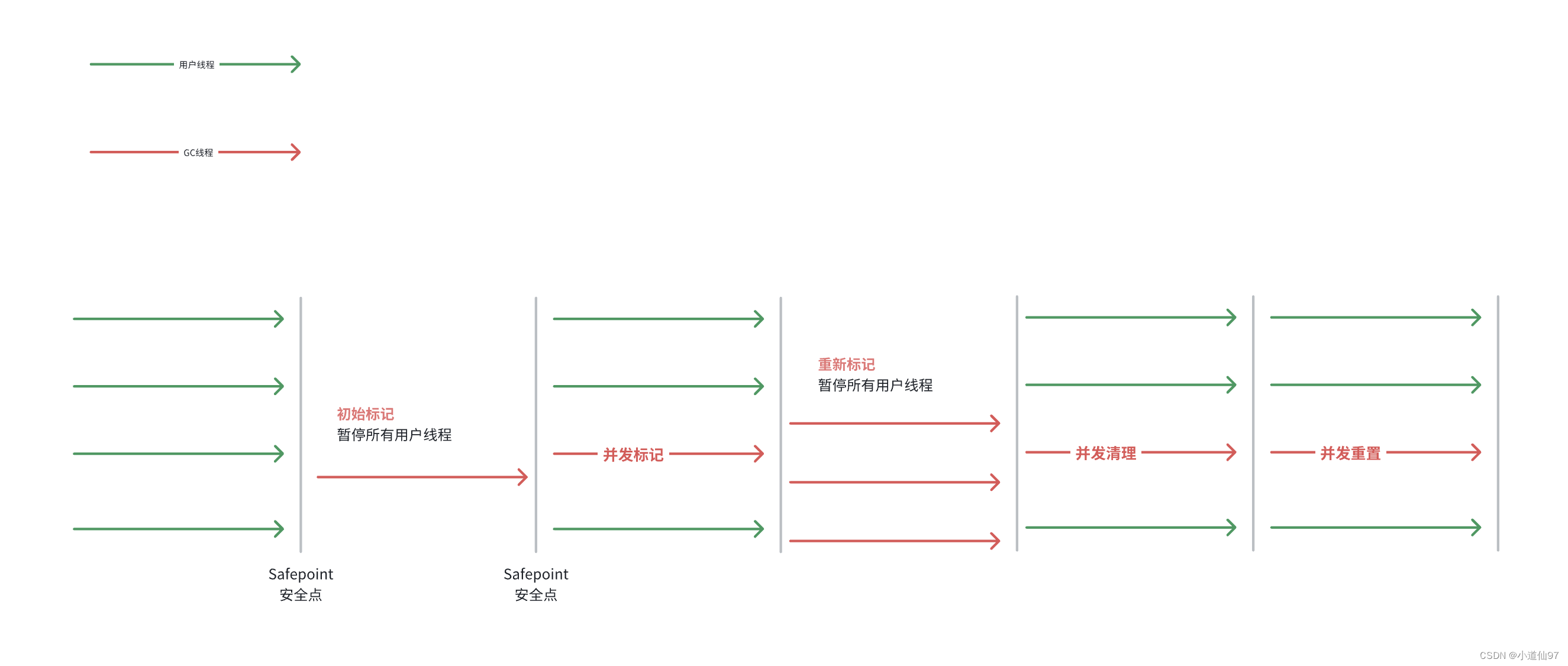
JVM内存区域详解,一文弄懂JVM内存【内存分布、回收算法、垃圾回收器】
视频讲解地址 学习文档 一、内存区域 区域描述线程私有如何溢出程序计数器为了线程切换后能恢复到正确的执行位置,每个线程都要有一个独立的程序计数器。✅唯一一个不会内存溢出的地方虚拟机栈1. 每个方法执行的时候,Java虚拟机都会同步创建一个栈帧用于…...
uniapp搜索附近蓝牙信标(iBeacon)
一、 iBeacon介绍 iBeacon是苹果在2013年WWDC上推出一项基于蓝牙4.0(Bluetooth LE | BLE | Bluetooth Smart)的精准微定位技术,在iPhone 4S后支持。当你的手持设备靠近一个Beacon基站时,设备就能够感应到Beacon信号,范…...

Redis 常见数据结构以及使用场景分析
Java面试题目录 Redis 常见数据类型以及使用场景分析 Redis中有string、list、hash、set、sorted set、bitmap这6种数据类型。 string可以用来做缓存,分布式锁,计数器等。 list可以实现消息队列,分页查询等。 hash适合存储对象结构。 set 可…...

LMDeploy 大模型量化部署实践
LMDeploy 大模型量化部署实践 大模型部署背景模型部署定义产品形态计算设备 大模型特点大模型挑战大模型部署方案 LMDeploy简介推理性能核心功能-量化核心功能-推理引擎TurboMind核心功能 推理服务 api-server 案例(安装、部署、量化) 大模型部署背景 模型部署 定义 将训练好…...

15个为你的品牌增加曝光的维基百科推广方法-华媒舍
维基百科是全球最大的免费在线百科全书,拥有庞大的用户群体和高质量的内容。在如今竞争激烈的市场中,利用维基百科推广品牌和增加曝光度已成为许多企业的重要策略。本文将介绍15种方法,帮助你有效地利用维基百科推广品牌,提升曝光…...
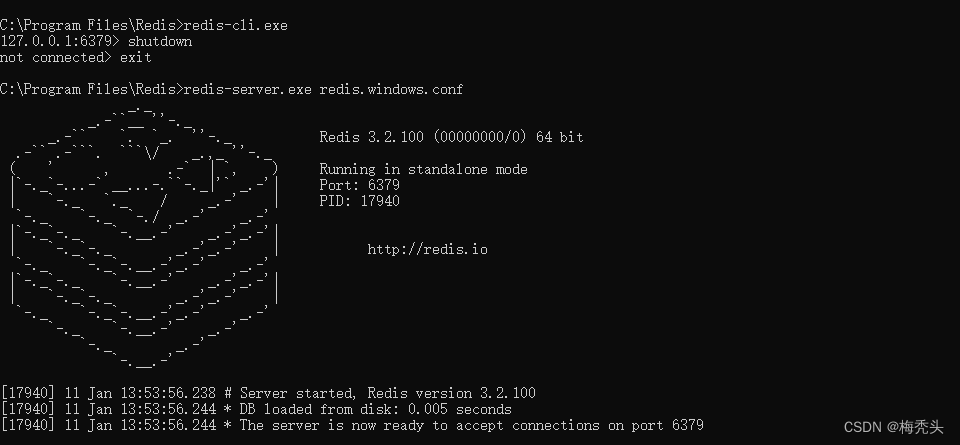
启动redis出现Creating Server TCP listening socket 127.0.0.1:6379: bind: No error异常
1.进入redis安装目录,地址栏输入cmd 2.输入命令 redis-server.exe redis.windows.conf redis启动失败 解决,输入命令 #第一步 redis-cli.exe#第二步 shutdown#第三步 exit第四步 redis-server.exe redis.windows.conf 显示以下图标即成功...

响应式编程Reactor优化Callback回调地狱
1. Reactor是什么 Reactor 是一个基于Reactive Streams规范的响应式编程框架。它提供了一组用于构建异步、事件驱动、响应式应用程序的工具和库。Reactor 的核心是 Flux(表示一个包含零到多个元素的异步序列)和 Mono表示一个包含零或一个元素的异步序列…...
React项目实战--------极客园项目PC端
项目介绍:主要将学习到的项目内容进行总结(有需要项目源码的可以私信我) 关于我的项目的配置如下,请注意下载的每个版本不一样,写的api也不一样 一、项目介绍 1.资料 1)短信接收&M端演示:…...
,q(q <= 1e5)次询问,求向前走d最少要几次)
Jerry每次能向前或向后走n*n步(始终不能超过初始位置1e5),q(q <= 1e5)次询问,求向前走d最少要几次
题目 思路:因为有走的过程不能超初始位置1e5的限制,所以不能直接用奇数最多两次,4的倍数最多两次的结论。spfa,平方数的dis为1,然后推出其他数的dis #include<bits/stdc.h> using namespace std; #define int …...

【Spring Boot 3】【Flyway】数据库版本管理
【Spring Boot 3】【Flyway】数据库版本管理 背景介绍开发环境开发步骤及源码工程目录结构总结背景 软件开发是一门实践性科学,对大多数人来说,学习一种新技术不是一开始就去深究其原理,而是先从做出一个可工作的DEMO入手。但在我个人学习和工作经历中,每次学习新技术总是…...
)
蓝桥杯基础数据结构(java版)
引言 数据结构数据结构。所以数据结构是一个抽象的概念。其目的是为了更好的组织数据方便数据存储。下面我们来看一些简单的数据储存方式 输入和输出 这里先介绍java的输入和输出。简单引入,不过多详细介绍,等我单一写一篇的时候这里会挂上链接 简单的…...

39 C++ 模版中的参数如果 是 vector,list等集合类型如何处理呢?
在前面写的例子中,模版参数一般都是 int,或者一个类Teacher,假设我们现在有个需求:模版的参数要是vector,list这种结合类型应该怎么写呢? //当模版中的类型是 vector ,list 等集合类型的时候的处…...
5.Pytorch模型单机多GPU训练原理与实现
文章目录 Pytorch的单机多GPU训练1)多GPU训练介绍2)pytorch中使用单机多GPU训练DistributedDataParallel(DDP)相关变量及含义a)初始化b)数据准备c)模型准备d)清理e)运行 3)使用DistributedDataParallel训练模型的一个简单实例 欢迎访问个人网络日志🌹🌹知…...

想成为一名C++开发工程师,需要具备哪些条件?
C语言是一门面向过程的、抽象化的通用程序设计语言,广泛应用于底层开发。C语言能以简易的方式编译、处理低级存储器。C语言是仅产生少量的机器语言以及不需要任何运行环境支持便能运行的高效率程序设计语言。尽管C语言提供了许多低级处理的功能,但仍然保…...
Qat++,轻量级开源C++ Web框架
目录 一.简介 二.编译Oat 1.环境 2.编译/安装 三.试用 1.创建一个 CMake 项目 2.自定义客户端请求响应 3.将请求Router到服务器 4.用浏览器验证 一.简介 Oat是一个面向C的现代Web框架 官网地址:https://oatpp.io github地址:https://github.co…...

openssl3.2 - 官方demo学习 - digest - EVP_MD_demo.c
文章目录 openssl3.2 - 官方demo学习 - digest - EVP_MD_demo.c概述笔记END openssl3.2 - 官方demo学习 - digest - EVP_MD_demo.c 概述 使用 SHA3-512 对多个buffer连续进行摘要, 最后得到一个摘要值 笔记 /*! \file EVP_MD_demo.c \note openssl3.2 - 官方demo学习 - dig…...
uniapp 编译后文字乱码的解决方案
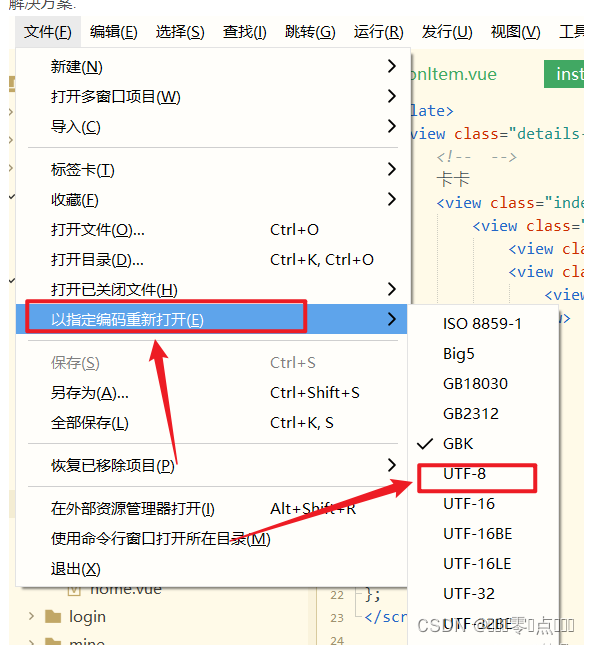
问题: 新建的页面中编写代码,其中数字和图片都可以正常显示,只有中文编译后展示乱码 页面展示也是乱码 解决方案: 打开HuilderX编辑器的【文件】- 【以指定编码重新打开】- 【选择UTF-8】 然后重新编译就可以啦~ 希望可以帮到你啊~...

2026年实用降AIGC软件:亲测AI率从90%降至4%的靠谱方案
一、前言:2026年毕业必过AIGC检测门槛 2026年国内高校对学术论文的AIGC疑似度审核全面收紧,绝大多数院校都发布了明确的AIGC检测数值要求:985、211院校规定本科论文AI率需低于20%,硕士论文AI率不得高于15%,普通高校也普…...

【RT-DETR实战】061、端到端速度优化:从数据加载到后处理
昨天深夜调模型的时候又遇到性能瓶颈——明明GPU利用率只有60%,帧率死活上不去。 盯着nvidia-smi的输出发呆半小时,突然意识到问题不在前向推理那几百毫秒,而在数据加载和后处理这些“边角料”环节。今天咱们就聊聊RT-DETR端到端流水线里那些容易被忽略的速度陷阱。 数据加…...

CW32F003与CW32F030国产MCU深度对比:从选型到项目实战全解析
1. 项目概述与核心价值最近在整理手头的开发板,翻出了两块来自武汉芯源的CW32F003和CW32F030。这两款芯片和对应的开发板,在国产MCU的入门级市场里,算得上是“老朋友”了,尤其是对于成本敏感、需要快速验证方案的工程师和学生来说…...

UE5.3导入FBX实战:如何完美保留Maya/Blender的复杂层级并一键设置碰撞?
UE5.3 FBX导入全流程:从Maya/Blender复杂层级到可交互蓝图的终极解决方案 当机械臂的每个关节都需要独立控制,当建筑群中的每扇门窗都要单独设置碰撞,当角色装备的每件武器都需绑定动画——这些正是三维内容创作者在UE5中处理复杂资产时的真实…...

3种简单方法解决Navicat Premium Mac试用期重置难题
3种简单方法解决Navicat Premium Mac试用期重置难题 【免费下载链接】navicat_reset_mac navicat mac版无限重置试用期脚本 Navicat Mac Version Unlimited Trial Reset Script 项目地址: https://gitcode.com/gh_mirrors/na/navicat_reset_mac 你是否正在为Navicat Pre…...

QCustomPlot交互秘籍:手把手实现数据点拾取、矩形框选与自定义高亮样式
QCustomPlot交互功能深度解析:从数据点拾取到视觉定制全攻略 1. 交互式数据可视化的核心价值 在现代数据可视化应用中,静态图表已经无法满足用户日益增长的交互需求。QCustomPlot作为Qt生态中功能强大的绘图库,其交互功能的设计既考虑了开发…...
:基于127万条真实英文语境的搭配强度阈值模型首次公开)
Perplexity词组搭配查询深度解析(工业级语料验证版):基于127万条真实英文语境的搭配强度阈值模型首次公开
更多请点击: https://codechina.net 第一章:Perplexity词组搭配查询深度解析(工业级语料验证版):基于127万条真实英文语境的搭配强度阈值模型首次公开 Perplexity 不仅是语言模型评估的核心指标,更可转化为…...

线下技术沙龙:AI Coding深度实践LLM应用分享
活动简介 我们正在经历一场软件开发 范式的变革。从Copilot的智能补全,到Cursor的对话式编程,再到Agent自主完成复杂任务——代码的编写方式,正在被重新定义。 但这场变革的核心,不是工具本身,而是使用工具的人。 本…...

蓝桥杯嵌入式第十届真题复盘:从CubeMX配置到EEPROM读写,我是如何一步步踩坑又爬出来的
蓝桥杯嵌入式第十届真题实战复盘:从CubeMX配置到EEPROM读写的深度解析 去年参加蓝桥杯嵌入式比赛的经历,至今回想起来仍让我心有余悸。第十届真题中的LED模块和EEPROM读写部分,堪称"嵌入式开发者的噩梦"。记得当时在实验室熬到凌晨…...

终极指南:在Linux系统上安装与优化Realtek RTL8125 2.5GbE网卡驱动
终极指南:在Linux系统上安装与优化Realtek RTL8125 2.5GbE网卡驱动 【免费下载链接】realtek-r8125-dkms A DKMS package for easy use of Realtek r8125 driver, which supports 2.5 GbE. 项目地址: https://gitcode.com/gh_mirrors/re/realtek-r8125-dkms …...