MySQL-多表联合查询

🎉欢迎您来到我的MySQL基础复习专栏
☆* o(≧▽≦)o *☆哈喽~我是小小恶斯法克🍹
✨博客主页:小小恶斯法克的博客
🎈该系列文章专栏:重拾MySQL
🍹文章作者技术和水平很有限,如果文中出现错误,希望大家能指正🙏
📜 感谢大家的关注! ❤️

目录
🚀联合查询
🚀子查询
🚀标量子查询
🚀列子查询
🚀行子查询
🚀表子查询
🚀联合查询
union查询,就是把多次查询的结果合并起来,形成一个新的查询结果集
主要代码:
SELECT 字段列表 FROM 表 A ...UNION [ ALL ]SELECT 字段列表 FROM 表B ;
联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。
union all 会将全部的数据直接合并在一起,并不会去重
union 会对合并之后的数据去重。
案例:将薪资低于 5000 的员工 , 和 年龄大于 50 岁的员工全部查询出来.
思路:
1.直接使用多条件查询,使用逻辑运算符 or 连接
2.通过union/union all来联合查询
select * from empcp where salary < 5000union allselect * from empcp where age > 50; --联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。执行:
第一部分
第二部分

联合(即要薪资低于5000的员工,又要年龄大于50的员工,那么就意味着这两条数据要合并,关键字union all)
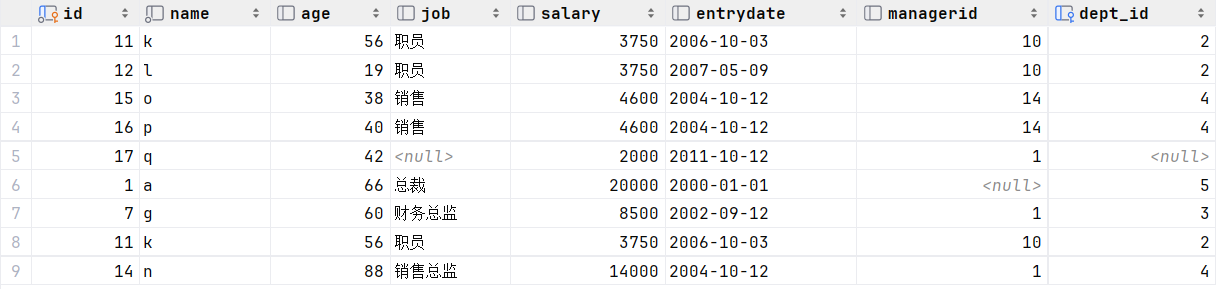
我们发现union all查询出来的结果,有一个员工k是重复的,k的薪资低于5000,年龄又大于50,所以查询了两次,数据直接合并,仅仅进行简单的合并,并未去重。
select * from empcp where salary < 5000unionselect * from empcp where age > 50;
执行:
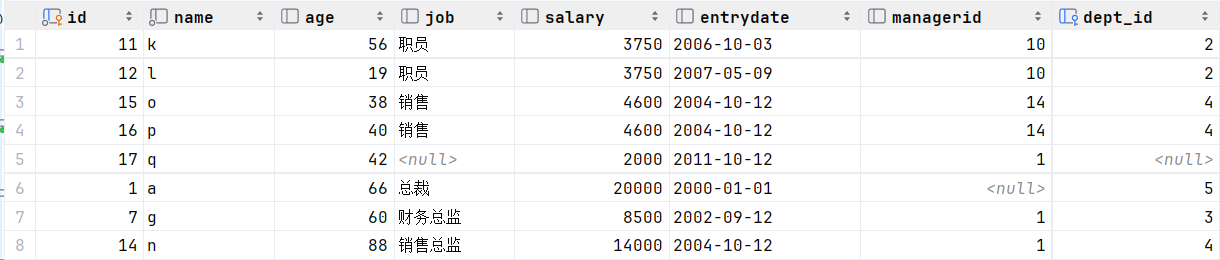
我们发现union联合查询,会对查询出来的结果进行去重处理。
注意:
如果多条查询语句查询出来的结果,字段数量不一致,在进行union/union all联合查询时,将会报错。如:

🚀子查询
SQL语句中嵌套的SELECT语句,称为嵌套查询,又称子查询。
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 ); 注意!子查询外部的语句可以是INSERT / UPDATE / DELETE / SELECT 的任何一个。
此时,子查询因为存在嵌套关系,逻辑性较强,代码是比较变通的,切不可死记硬背,根据逻辑去思考问题
根据子查询结果不同,可分为:
1.标量子查询(子查询结果为单个值)
2.列子查询(子查询结果为一列)
3.行子查询(子查询结果为一行)
4.表子查询(子查询结果为多行多列)
根据子查询位置,可分为:
1.WHERE之后
2.FROM之后
3.SELECT之后
🚀标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。 常用的操作符:= <> > >= < <=
案例:
查询 "销售部" 的所有员工信息
思路:
拆解为两步 (因为在员工表中是没有存储销售部这个部门名称的,仅仅只有部门id)
1.查询"销售部" 部门ID
select id from dept where name = '销售部';2.根据 "销售部" 部门ID, 查询员工信息,用*返回员工所有信息的字段
select * from empcp where dept_id = (select id from dept where name = '销售部'); 或者 select * from empcp where dept_id = 4 ;
执行:
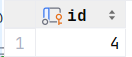
执行:

查询在 "e"这个员工 入职之后的员工信息
思路:
拆解为两步
1.查询 e 的入职日期
select entrydate from empcp where name = 'e';2.查询指定入职日期之后入职的员工信息
select * from empcp where entrydate > (select entrydate from empcp where name = 'e'); 或者 select * from empcp where entrydate > 2004-9-7 ;
执行:
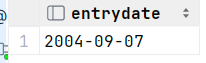
执行:
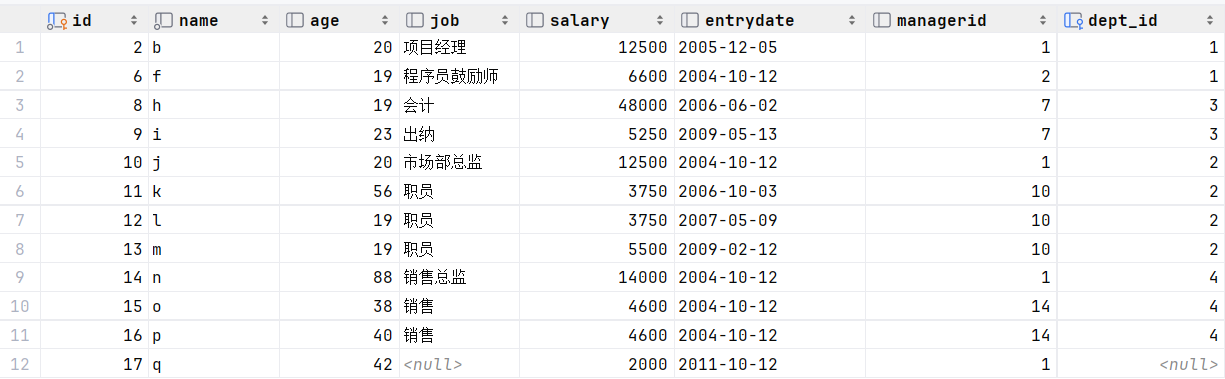
当然,我们需要了解entrydate是如何比较呢?
在SQL中,
entrydate是一个字段名,通常表示一个日期或日期时间类型的数据。要比较
entrydate字段,你可以使用各种比较运算符,如=、<、>、<=、>=、<>或!=。以下是一些示例,说明如何比较
entrydate字段:1.等于,大于,小于,小于等于,大于等于,不等于就不过多演示了,因为直接更改比较运算符即可
SELECT * FROM your_table WHERE entrydate = '2023-10-23'; -- =可以改为<,>,<>,<=,>=......2.BETWEEN: 如果你想选择一个日期范围内的记录,你可以使用BETWEEN:
SELECT * FROM your_table WHERE entrydate BETWEEN '2023-10-01' AND '2023-10-31';这个查询会返回所有
entrydate在'2023-10-01'和'2023-10-31'之间的记录。注意,BETWEEN运算符是包含边界值的。
3. LIKE 和日期: 如果你想基于日期的部分部分进行比较,例如查找以特定年份开始的日期,你可以使用LIKE:SELECT * FROM your_table WHERE entrydate LIKE '2023%';这个查询会返回所有以'2023'开头的
entrydate的记录。LIKE运算符通常与通配符一起使用,如%表示任何数量的任何字符。
4. DATE() 函数: 如果你只想比较日期部分而忽略时间部分,你可以使用DATE()函数:SELECT * FROM your_table WHERE DATE(entrydate) = '2023-10-23';这个查询只会比较日期部分,忽略时间部分。这对于只关心日期而不关心具体时间的情况很有用。
5. 时间间隔: 如果你想基于两个日期之间的时间间隔进行比较,你可以使用减法:
SELECT * FROM your_table WHERE DATEDIFF(day, entrydate, '2023-10-23') > 5;这个查询会返回所有与'2023-10-23'相差超过5天的
entrydate的记录。DATEDIFF()函数根据指定的时间间隔返回两个日期之间的差异。在这个例子中,我们使用天作为时间间隔单位。不同的数据库系统可能有不同的函数来计算日期差异,所以请根据你使用的系统查阅相应的文档。
🚀列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询
常用的操作符:IN 、NOT IN 、 ANY 、SOME 、 ALL
| 操作符 | 描述 |
| IN | 在指定的集合范围之内,多选一 |
| NOT IN | 不在指定的集合范围之内 |
| ANY | 子查询返回列表中,有任意一个满足即可 |
| SOME | 与ANY等同,使用SOME的地方都可以使用ANY |
| ALL | 子查询返回列表的所有值都必须满足 |
案例:
查询 "销售部" 和 "市场部" 的所有员工信息
思路:
分解为两步
1.查询 "销售部" 和 "市场部" 的部门ID
select id from dept where name = '销售部' or name = '市场部';2.根据部门ID, 查询员工信息 (由于是两个元素,所以用到了in)
select * from empcp where dept_id in (select id from dept where name = '销售部' or name = '市场部'); 或者 select * from empcp where dept_id in(2,4) --2.4是上述语句查询的结果,所以我们可以把2,4替换掉,让上面的语句作为子查询存在
而由于内部的sql查询出来不再是一个单个值了,而是一列,多行。所以这种子查询称为列子查询
执行:

执行:

查询比 财务部 所有人工资都高的员工信息
思路:
分解为以下两步
1.查询所有 财务部 人员工资
select id from dept where name = '财务部'; select salary from empcp where dept_id = (select id from dept where name = '财务部'); 或者 select salary from empcp where dept_id = 3;2.比 财务部 所有人工资都高的员工信息 (这个salary要大于这三个工资的所有值,比其中任何一个大,此时就要大于这个列表中所有值,要加上all)
select * from empcp where salary > all ( select salary from empcp where dept_id =(select id from dept where name = '财务部') );
执行:
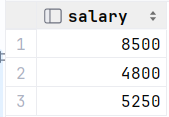
执行:

查询比 研发部 其中任意一人工资高的员工信息
思路:
分解为两步
1.查询研发部所有人工资
select salary from empcp where dept_id = (select id from dept where name = '研发部');2.比研发部其中任意一人工资高的员工信息 (关键字any)
select * from empcp where salary > any ( select salary from empcp where dept_id =(select id from dept where name = '研发部') );
执行:
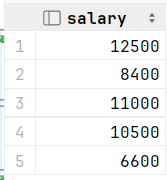
执行:
🚀行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
常用的操作符:= 、<> 、IN 、NOT IN
案例:
查询与 "b" 的薪资及直属领导相同的员工信息 ;
思路:行子查询一般来说,左边要给组合条件,右边再给子查询的结果,不能把条件分开,再给子查询结果
拆解为两步:
1.查询 "b" 的薪资及直属领导
select salary, managerid from empcp where name = 'b';2.查询与 "b" 的薪资及直属领导相同的员工信息 ;
第三个代码就是使用salary和managerid作为了一个组合条件,然后这个组合条件等于一个组合值
select * from empcp where (salary,managerid) = (select salary, managerid from empcpwhere name = 'b');或者select * from empcp where salary = 12500 and managerid = 1 ;或者select * from empcp where (salary , managerid) = (12500 ,1) ;
执行:

执行:

🚀表子查询
子查询返回的结果是多行多列,这种子查询称为表子查询。(子查询查询返回的结果就类似于一张表)
常用的操作符:IN
表子查询经常在from之后,把表子查询返回的结果作为一张临时表,再和其他表联查操作
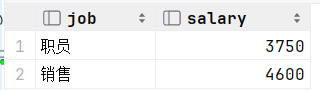
案例:1.查询与 "k" , "p" 的职位和薪资相同的员工信息
拆解为两步:
1.查询与 "k" , "p" 的职位和薪资
select job, salary from empcp where name = 'k' or name = 'p';2.查询与 "k" , "p" 的职位和薪资相同的员工信息 (注意,这里where之后给的是组合条件。如果where之后条件如果是单行,那么我们之前在这一块的写法是(job,salary)= 子查询的结果就ok了,但是现在查询的不是一个单行数据,而是一个多行数据吗,此时就不能等于了,这时候我们要使用的是in)
3.解读,这一块的含义指的是job和salary这个组合要么满足上面的,要么满足下面的,在这个列表里面多选一,只要能够满足一个这个员工的数据就可以查询出来
select * from empcp where (job,salary) in ( select job, salary from empcp where name ='k' or name = 'p' );
执行:
执行:

查询入职日期是 "2006-01-01" 之后的员工信息 , 及其部门信息
思路:
分解为两步
1.入职日期是 "2006-01-01" 之后的员工信息
select * from empcp where entrydate > '2006-01-01';2.查询这部分员工, 对应的部门信息;
3.要查询部门的相关信息就要再去联查另一个表,dept表
4.所以我们需要把第一次查询的结果作为一张表,再去联查dept表
✨先暂时写为*
select * from [刚刚查询的一个结果作为一张表放进来,子查询的结果作为一张临时表存在,取一个别名e] ;
select * from (select * from empcp where entrydate > '2006-01-01') e ;
✨接着查询部门信息,有一个员工q,id为17的没有部门信息,我们要不要查出来,也需要,所以要查全部数据我们要使用到左外连接,此时我们顺便把dept表取名为d
select * from (select * from empcp where entrydate > '2006-01-01') e left join dept d on e.dept_id = d.id ;
执行:
✨总结:此时我们就在from之后用到了子查询,它会把这个子查询的结果作为一张表来与另一张表做
select e.*, d.* from (select * from empcp where entrydate > '2006-01-01') e leftjoin dept d on e.dept_id = d.id ;或者select * from (select * from empcp where entrydate > '2006-01-01') e left join dept don e.dept_id = d.id ;

执行:

执行:

总结:本篇博客到这里就结束了,希望能帮到你,谢谢你这么好看还来看我
相关文章:
MySQL-多表联合查询
🎉欢迎您来到我的MySQL基础复习专栏 ☆* o(≧▽≦)o *☆哈喽~我是小小恶斯法克🍹 ✨博客主页:小小恶斯法克的博客 🎈该系列文章专栏:重拾MySQL 🍹文章作者技术和水平很有限,如果文中出现错误&am…...
商城小程序(8.购物车页面)
目录 一、商品列表区域1、渲染购物车商品列表的标题区域2、渲染商品列表区域的基本结构3、为my-goods组件封装radio勾选状态4、为my-goods组件封装radio-change事件5、修改购物车中商品的选择状态6、为my-goods组件封装NumberBox7、为my-goods封装num-change事件8、修改购物车商…...
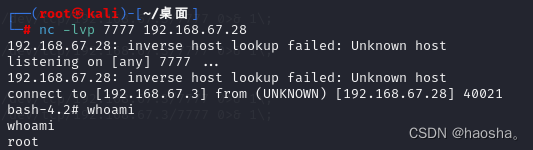
[Vulnhub靶机] DC-1
[Vulnhub靶机] DC-1靶机渗透思路及方法(个人分享) 靶机下载地址: https://download.vulnhub.com/dc/DC-1.zip 靶机地址:192.168.67.28 攻击机地址:192.168.67.3 一、信息收集 1.使用 arp-scan 命令扫描网段内存活的…...

【springboot 中集成 knife4j 时,报错 No mapping for GET /doc.html】
出现这种情况可能是项目中含有继承WebMvcConfigurationSupport的类,这会导致 swagger 配置失效。 解决方法,继承WebMvcConfigurationSupport下重写addResourceHandlers方法 Overridepublic void addResourceHandlers(ResourceHandlerRegistry registry)…...
-二元谓词(BinaryPredicate))
C++ 具名要求-全库范围的概念 -谓词(Predicate)-二元谓词(BinaryPredicate)
此页面中列出的具名要求,是 C 标准的规范性文本中使用的具名要求,用于定义标准库的期待。 某些具名要求在 C20 中正在以概念语言特性进行形式化。在那之前,确保以满足这些要求的模板实参实例化标准库模板是程序员的重担。若不这么做…...

MyBatis-Plus不写任何resultMap和SQL执行一对一、一对多、多对多关联查询
MyBatis-Plus不写任何resultMap和SQL执行一对一、一对多、多对多关联查询 MyBatis-Plus不写任何resultMap和SQL执行一对一、一对多、多对多关联查询 com.github.dreamyoung mprelation 0.0.3.2-RELEASE 注解工具使用优缺点: 优点: 使用简单…...
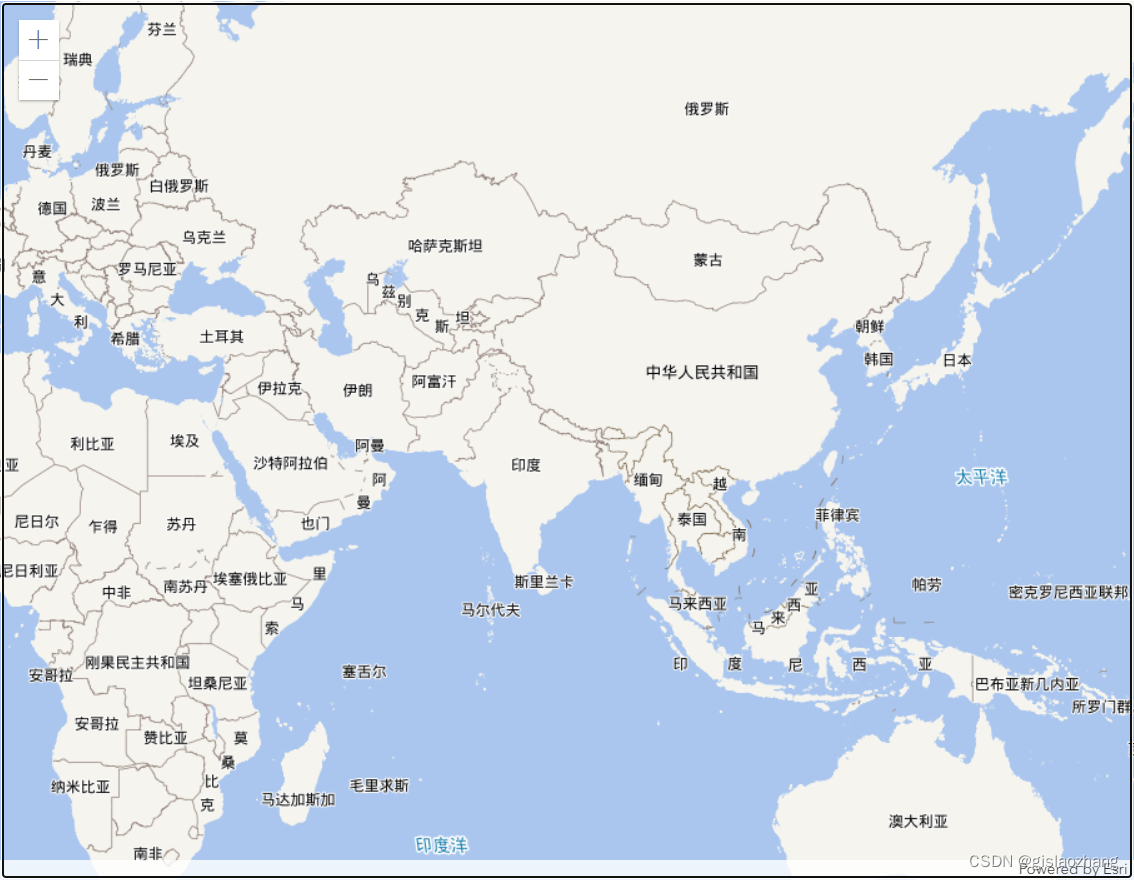
arcgis javascript api4.x加载天地图web墨卡托(wkid:3857)坐标系
效果: 示例代码: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><meta http-equiv&quo…...
中职组安全-win20230217-环境-解析
*任务说明: 仅能获取win20230217的IP地址 用户名:test,密码:123456 访问服务器主机,找到主机中管理员名称,将管理员名称作为Flag值提交; john 访问服务器主机,找到主机中补丁信息,将补丁编号作为Flag值提交ÿ…...
PMP学习考试经验总结
PMP备考日程计划表 我的PMP的备考大概花了三个月的时间, 可以分为以下几个阶段: Week 1-4: 读完PMBoK 前面7个知识领域(中英文版PMBoK一起看)。每看完一个知识领域,就看参考书里面的相应章节(汪博士那本)…...
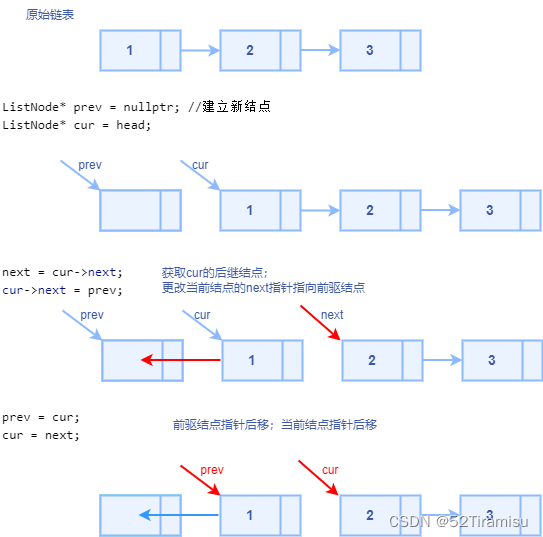
leetcode206.反转链表
https://leetcode.cn/problems/reverse-linked-list/description/ 题目 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。 示例 1: 输入:head [1,2,3,4,5] 输出:[5,4,3,2,1]示例 2: 输入&am…...

python每日学17:控制推导逻辑的子表达式不要超过两个
背景:今天放假在家,《python学习手册》不在身边,所以今天学习《Effective Python: 编写高质量Python代码的90个有效方法》第28条《控制推导逻辑的子表达式不要超过两个》,这本书已经是第二版了,第一版是《编写高质量py…...
)
地质时间与数值模拟时间转换(mm/Ma-->m/s)
一百万年(1Ma)等于315,576,000,0003.15576e11秒。 计算方法如下: 一年通常定义为365天(非闰年)。每天有24小时。每小时有60分钟。每分钟有60秒。 所以,一年的秒数为: 365天 24小时/天 60分钟/小时 60秒/分钟 31…...

linux文件描述符管理
在实际的项目开发中,文件描述符是经常用到的并且在释放资源过程中也是很容易忽略的,使用之后不释放就会增加cpu负担,无异于内存泄漏;所以时刻掌握文件描述符的状态是非常重要的!下面介绍文件描述符的管理方法。 1. 文…...

谷歌翻译不能使用 host添加IP
谷歌浏览器翻译不能使用解决教程_142.250.100.90 translate.googleapis.com-CSDN博客...
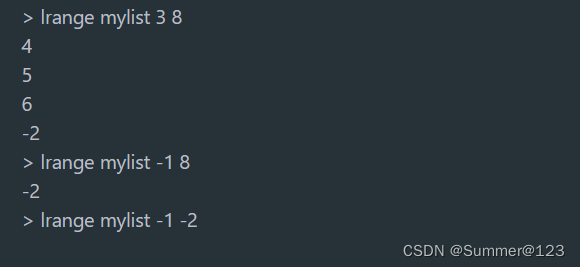
Redis命令 - Lists命令组常用命令
先创建一个 key 叫做 mylist,mylist存一个list。 list数据类型底层是一个链表。先进后出,后进先出。 命令中的L(Left)、R(Right)代表链表的头部L(下标0的位置)和尾部R(…...
切分大文件sql为小份
数据库太大了,整个备份导入出问题或者慢,需要将整个库按照表分割(一个表一个sql文件) 环境 win10 工具:python3.7pycharm 要分割的文件大小:6G,sql文件import redbname with open(best**.sql,…...
最新版CleanMyMac X4.14.7智能清理mac磁盘垃圾工具
CleanMyMac X是一款专业的Mac清理软件,可智能清理mac磁盘垃圾和多余语言安装包,快速释放电脑内存,轻松管理和升级Mac上的应用。同时CleanMyMac X可以强力卸载恶意软件,修复系统漏洞,一键扫描和优化Mac系统,…...

数据割据:当代社会数据治理的挑战
数据割据是指各个组织、企业或政府机构在数据的采集、存储和使用上形成了相对独立的局面,彼此之间缺乏有效的数据共享和流通机制。这种割据现象导致了数据的重复采集、冗余存储以及信息孤岛的出现,不仅浪费了大量的资源,还制约了数据的价值发…...

逻辑回归(解决分类问题)
定义:逻辑回归是一种用于解决分类问题的统计学习方法。它通过对数据进行建模,预测一个事件发生的概率。逻辑回归通常用于二元分类问题,即将数据分为两个类别。它基于线性回归模型,但使用了逻辑函数(也称为S形函数&…...

论文阅读:Feature Refinement to Improve High Resolution Image Inpainting
项目地址:https://github.com/geomagical/lama-with-refiner 论文地址:https://arxiv.org/abs/2109.07161 发表时间:2022年6月29日 项目体验地址:https://colab.research.google.com/github/advimman/lama/blob/master/colab/LaMa…...
)
【Perplexity语言学习资源黄金组合】:搭配Anki+TTS+语法解析器的「零依赖」自主学习系统(仅需1台设备)
更多请点击: https://codechina.net 第一章:Perplexity语言学习资源黄金组合的系统定位与核心价值 Perplexity 作为一款以实时检索增强生成(RAG)为核心架构的AI问答引擎,其在语言学习领域的独特价值并非源于通用对话能…...

微信聊天记录终极备份指南:如何永久保存你的珍贵回忆
微信聊天记录终极备份指南:如何永久保存你的珍贵回忆 【免费下载链接】WechatBakTool 基于C#的微信PC版聊天记录备份工具,提供图形界面,解密微信数据库并导出聊天记录。 项目地址: https://gitcode.com/gh_mirrors/we/WechatBakTool 你…...

谷歌 I/O 2026 炸场:Gemini 3.5 Flash 震撼发布!反超 3.1 Pro,开启“全自动 Agent 狂飙”时代
在刚刚开幕的 Google I/O 2026 开发者大会上,谷歌正式扔下了一颗重磅炸弹:发布全新 Gemini 3.5 系列 的首款旗舰轻量模型 —— Gemini 3.5 Flash。 这次的发布极为硬核,谷歌彻底打破了我们对 “Flash 是低配版/轻量版” 的固有认知。根据 Dee…...

3分钟搞定Windows右键菜单:ContextMenuManager终极优化指南
3分钟搞定Windows右键菜单:ContextMenuManager终极优化指南 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是否曾经在Windows右键菜单中迷失方向&…...
)
CE修改器进阶:通过内存结构分析,破解‘敌我同源’的游戏逻辑(以浮点数血量为例)
CE修改器进阶:内存结构分析与游戏逻辑破解实战 游戏修改器一直是技术爱好者探索虚拟世界底层逻辑的利器。在众多工具中,Cheat Engine(简称CE)以其强大的内存扫描和调试功能脱颖而出,成为逆向工程领域的瑞士军刀。今天&…...

五分钟完成Python环境配置,用Taotoken调用大模型API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 五分钟完成Python环境配置,用Taotoken调用大模型API 对于希望快速体验不同大模型能力的Python开发者而言,通…...

抖音视频批量下载神器:3分钟学会无水印批量下载技巧
抖音视频批量下载神器:3分钟学会无水印批量下载技巧 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support…...

从缺页异常看Linux内存管理的基石:写时复制、延迟分配与交换机制
从缺页异常看Linux内存管理的基石:写时复制、延迟分配与交换机制 当你在Linux终端敲下./a.out时,内核如何将磁盘上的程序转化为内存中的鲜活进程?这个看似简单的过程背后,隐藏着一套精妙的内存管理机制。缺页异常(Page…...

pip修改镜像源
pip临时使用pip install -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple some-package注意,simple 不能少。 pip 要求使用 https ,因此需要 https 而不是 http设为默认升级 pip 到最新的版本后进行配置:python -m pip install --u…...

SAE J1939请求与响应实战:用PCAN-View抓包分析‘要转速’的全过程
SAE J1939实战解析:从请求转速到数据解码的全链路操作指南 在车载诊断和商用车通信领域,SAE J1939协议如同神经系统般贯穿整个车辆架构。当工程师需要获取发动机转速这类关键参数时,协议中PGN(参数组编号)的请求与响应…...