微软最新研究成果:使用GPT-4合成数据来训练AI模型,实现SOTA!
文本嵌入是各项NLP任务的基础,用于将自然语言转换为向量表示。现有的大部分方法通常采用复杂的多阶段训练流程,先在大规模数据上训练,再在小规模标注数据上微调。此过程依赖于手动收集数据制作正负样本对,缺乏任务的多样性和语言多样性。
此外,大部分方法采用BERT作为编码器,如非常经典的Sentence-BERT和SimCSE通过在推理数据集上对BERT进行微调学习文本嵌入。
但现在LLMs技术发展得如火如荼,能否用LLMs来克服现有方法的限制,升级文本嵌入方法呢?
当然可以!
最近,微软发布了一种新颖的文本嵌入方法,使用专有的LLMs为93种语言中各种文本嵌入任务生成合成数据,并且涉及了多个任务场景。
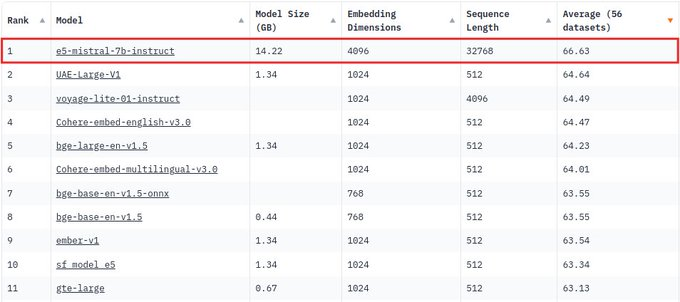
微软使用了Mistral-7B对合成数据和标记数据进行混合训练,**成功登顶Huggingface排行榜,比之前的方法高2%**。
论文标题:
Improving Text Embeddings with Large Language Models
论文链接:
https://arxiv.org/pdf/2401.00368.pdf
模型:
https://huggingface.co/intfloat/e5-mistral-7b-instruct
数据:
https://huggingface.co/datasets/andersonbcdefg/synthetic_retrieval_tasks
方法
合成数据生成
作者使用GPT-4集思广益产生一系列潜在的检索任务,然后为每个任务生成(查询,正例,困难反例)三元组,如下图所示。

为了生成多样化的合成数据,作者提出了一个简单的分类法,将嵌入任务分为几个组,并针对每个组应用不同的提示模板:
非对称任务:包括查询和文档在语义上相关但并不是互相改写的任务。根据查询和文档的长度,进一步分为四个子组:短-长匹配、长-短匹配、短-短匹配和长-长匹配。短-长匹配任务涉及短查询和长文档,是商业搜索引擎中的典型情况。
对称任务:涉及具有相似语义但表面形式不同的查询和文档。包括单语语义文本相似性(STS)和双语检索。
训练
给定一个相关的查询-文档配对(,),将以下指令模板应用于原始查询,生成一个新的查询 :
其中,嵌入任务的一句话描述的占位符。
给定一个预训练的LLM,将[EOS]标记附加到查询和文档的末尾,然后将它们输入LLM,通过获取最后一层的[EOS]向量来获得查询和文档的嵌入()。
为了训练嵌入模型,采用了标准的InfoNCE损失函数L,使用批内负样本和困难负样本进行计算。
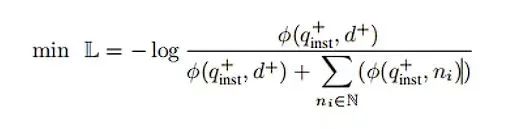
其中计算查询q和文档d之间匹配分数的函数,本文采用温度缩放余弦相似度函数,是温度超参,在本实验中设为0.02。
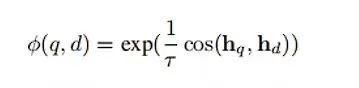
实验
合成数据统计
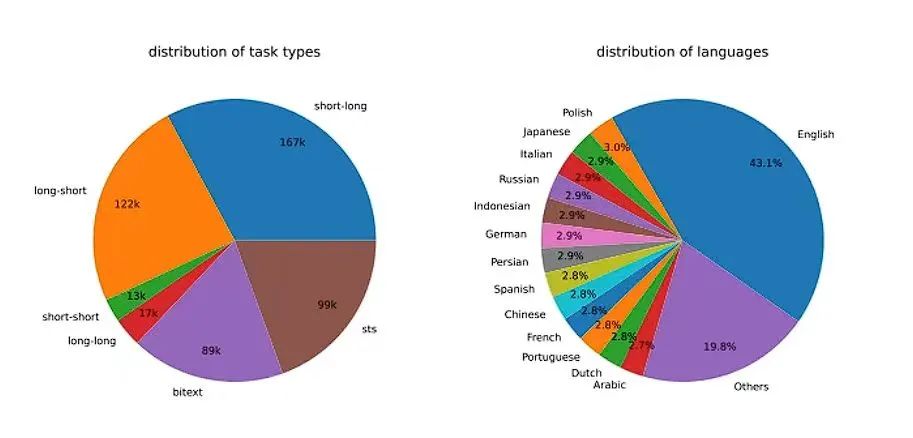
本文一共生成了500k个示例,其中包含150k个独特指令。25%由GPT-3.5-Turbo生成,其余由GPT-4生成。总的token消耗约为180M。主要语言为英语,覆盖了共计93种语言。对于75种低资源语言,平均每种语言约有1k个示例。
模型微调与评估
模型选用Mistral-7b进行1个epoch微调,评估基准选用MTEB基准测试。
训练数据:利用生成的合成数据和包含13个公共数据集的集合, 在采样后得到约180万个样例。为了与一些先前的工作进行公平比较,还报告了仅有标签监督的MS-MARCO数据集的结果。
主要结果

▲表1
如上表所示,本文提出的模型“E5mistral-7b + full data”在MTEB基准测试中获得了最高的平均得分,比之前的最先进模型高出2.4个点。
在“仅使用合成数据”的设置中,没有使用标记数据进行训练,其性能仍然相当有竞争力。生成式语言建模和文本嵌入都需要模型对自然语言有深刻的理解,。基于嵌入任务定义,一种真正强大的轻量级模型应该能够自动生成训练数据,然后通过轻量级微调转换为嵌入模型。
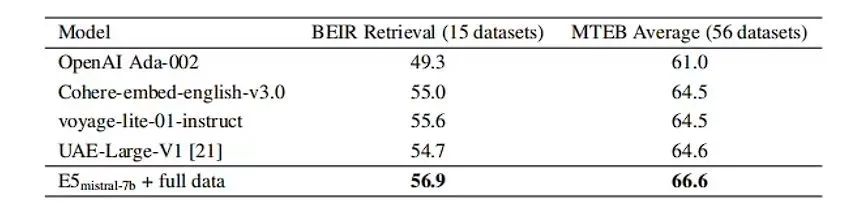
▲表2
在表2中,作者还对几个商业文本嵌入模型进行了比较。然而,由于这些模型缺乏透明度和文档说明,不可能做到完全公平的比较。作者主要关注BEIR基准测试的检索性能,因为RAG是未来LLMs应用的重要趋势之一。正如表2所示,本文的模型在性能上明显优于当前的商业模型。
多语言检索
为了评估模型的多语言能力,作者在包含18种语言的MIRACL数据集上进行了评估。该数据集包括人工注释的查询和相关性判断。
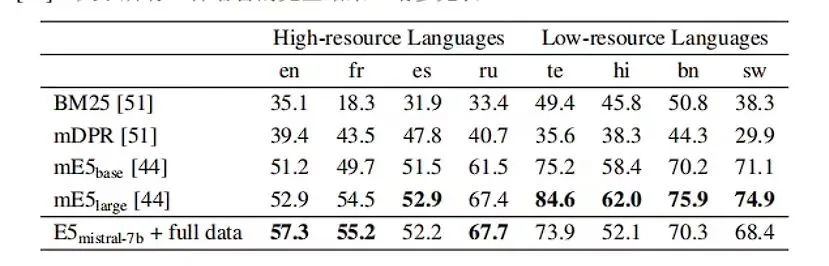
▲表3
如表3所示,该模型在高资源语言特别是英语上超过mE5large。对于低资源语言,本文的模型仍然不够优秀。这是因为Mistral-7B主要预训练于英语数据,未来将可以使用多语言LLM弥合这一差距。
除此之外,作者还探讨分析了几个问题。
分析
1. 对比预训练真的重要吗?
弱监督对比性预训练是现有文本嵌入模型取得成功的关键因素之一。例如,将随机裁剪的片段作为预训练的正样本对待,或者从各种来源收集并筛选文本对。
那么对于LLMs而言,对比预训练还有用吗?

如上图所示,对比预训练有益于XLM-Rlarge,在相同数据上微调时,其检索性能提高了8.2个点,与之前的研究结果一致。
然而,对于基于Mistral-7B的模型,对比预训练对模型质量几乎没有影响。这意味着广泛的自回归预训练使LLMs能够获取良好的文本表示,只需要进行最少限度的微调即可将其转化为有效的嵌入模型,而无需对比预训练。
个性化密码检索
为了评估模型的长上下文能力,作者引入了一项新的合成任务——个性化密码检索,如下图所示,包含多个文件,每个文件都有一个独特的人名和一个随机的密码,插入在随机的位置。任务是从100个候选项中找回包含给定个人密码的文件。通过这个过程测试模型将长上下文中的密码信息编码到嵌入中的能力。

作者通过改变滑动窗口大小和RoPE旋转基,比较了不同变体的性能。
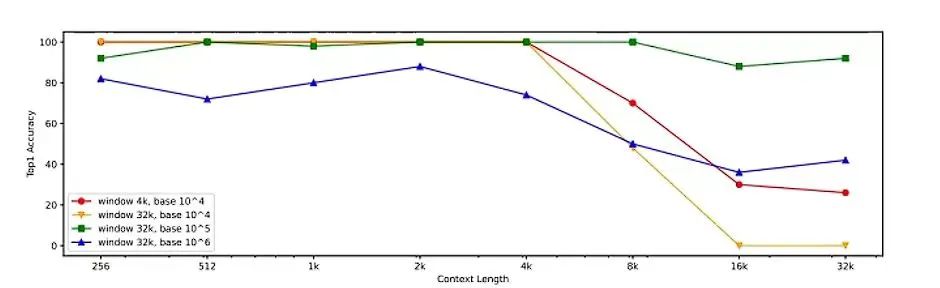
-
结果表明,默认配置下,使用4k滑动窗口在4k个token内达到了100%的准确率,但随着上下文长度的增加,准确率迅速下降。
-
将滑动窗口大小天真地扩展到32k会导致更差的性能。
-
通过将RoPE旋转基准更改为,模型可以在32k个标记内实现超过90%的准确率。但在短上下文不太适用。
结论
这篇工作证明了通过LLMs技术,文本嵌入的质量可以得到显著提升。 研究人员使用了专有的LLMs(如GPT-4),在多种语言环境下生成了多样化的合成数据,并结合Mistral模型强大的语言理解能力,在竞争激烈的MTEB基准测试中取得了SOTA。与现有的多阶段方法相比,既简单又高效,不再需要中间预训练的环节。
用网友的话说就是“Amazing Amazing Amazing!”,省去了人工采集数据的繁琐步骤,每个人都可以轻松地生成自己的数据集,并训练强大的嵌入模型。 语义检索模型不给力导致生成模型性能受影响的局面,总算有希望翻篇儿了!

相关文章:
微软最新研究成果:使用GPT-4合成数据来训练AI模型,实现SOTA!
文本嵌入是各项NLP任务的基础,用于将自然语言转换为向量表示。现有的大部分方法通常采用复杂的多阶段训练流程,先在大规模数据上训练,再在小规模标注数据上微调。此过程依赖于手动收集数据制作正负样本对,缺乏任务的多样性和语言多…...

爬虫案例—抓取小米商店应用
爬虫案例—抓取小米商店应用 代码如下: # 抓取第一页的内容 import requests from lxml import etree url ‘https://app.mi.com/catTopList/0?page1’ headers { ‘User-Agent’: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (K…...

geemap学习笔记047:边缘检测
前言 边缘检测适用于众多的图像处理任务,除了上一节[[geemap046:线性卷积–低通滤波器和拉普拉斯算子|线性卷积]]中描述的边缘检测核之外,Earth Engine 中还有几种专门的边缘检测算法。其中Canny 边缘检测算法使用四个独立的滤波器来识别对角…...
《Git学习笔记:IDEA整合Git》
在IDEA中集成Git去使用 通过Git命令可以完成Git相关操作,为了简化操作过程,我们可以在IDEA中配置Git,配置好后就可以在IDEA中通过图形化的方式来操作Git。 在IDEA开发工具中可以集成Git: 集成后在IDEA中可以看到Git相关图标&…...

Scipy 高级教程——统计学
Python Scipy 高级教程:统计学 Scipy 提供了强大的统计学工具,用于描述、分析和推断数据的分布和性质。本篇博客将深入介绍 Scipy 中的统计学功能,并通过实例演示如何应用这些工具。 1. 描述性统计 描述性统计是统计学中最基本的任务之一&…...
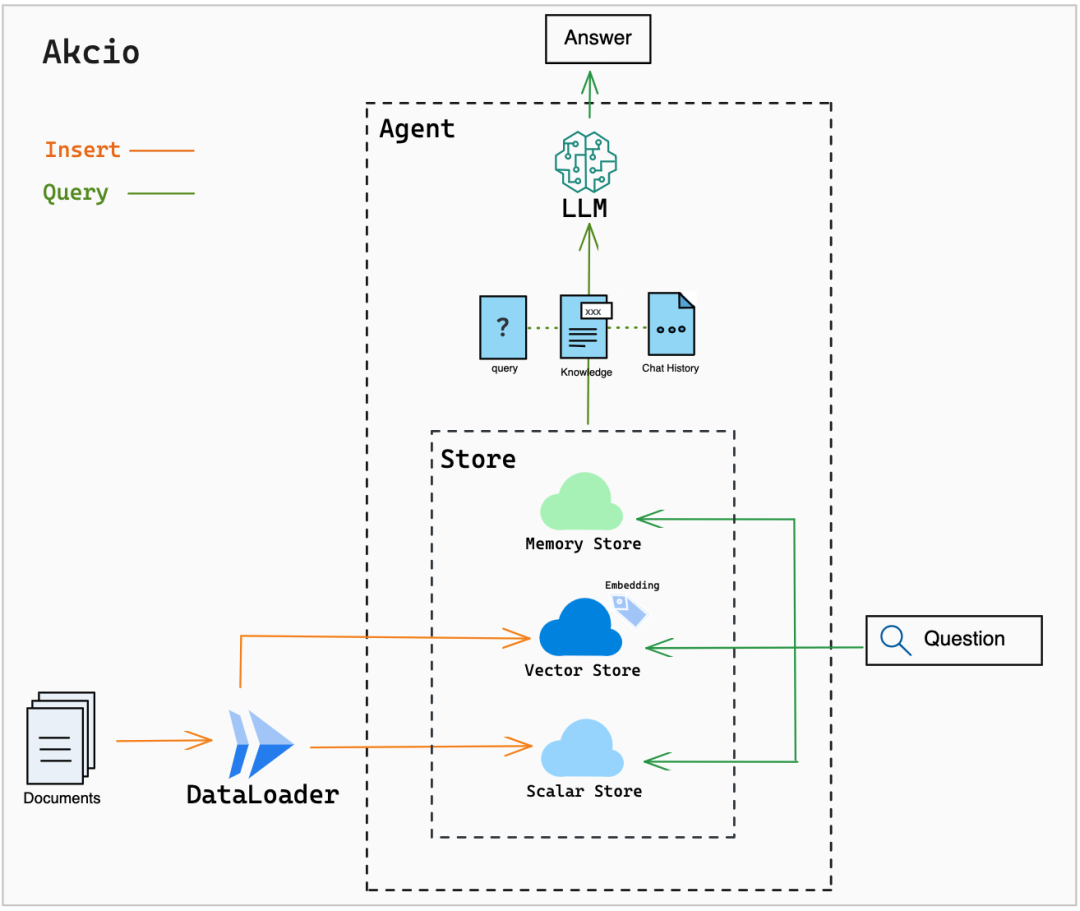
《向量数据库指南》RAG 应用中的指代消解——解决方案初探
随着 ChatGPT 等大语言模型(LLM)的不断发展,越来越多的研究人员开始关注语言模型的应用。 其中,检索增强生成(Retrieval-augmented generation,RAG)是一种针对知识密集型 NLP 任务的生成方法,它通过在生成过…...

CSS 一行三列布局,可换行(含grid网格布局、flex弹性布局/inline-block布局 + 伪类选择器)
效果 一、HTML <div class"num-wrap"><div class"num-item" v-for"num in 8" :key"num">{{ num }}</div></div> 二、CSS 1、grid网格布局(推荐) .num-wrap {// grid网格布局display…...

class_3:lambda表达式
1、lambda表达式是c11引入的一种匿名函数的方式,它允许你在需要函数的地方内联的定义函数,而无需单独命名函数; #include <iostream>using namespace std;bool compare(int a,int b) {return a > b; }int getMax(int a,int b,bool (…...

Hadoop 实战 | 词频统计WordCount
词频统计 通过分析大量文本数据中的词频,可以识别常见词汇和短语,从而抽取文本的关键信息和概要,有助于识别文本中频繁出现的关键词,这对于理解文本内容和主题非常关键。同时,通过分析词在文本中的相对频率࿰…...

SpringCloud.04.熔断器Hystrix( Spring Cloud Alibaba 熔断(Sentinel))
目录 熔断器概述 使用Sentinel工具 什么是Sentinel 微服务集成Sentinel 配置provider文件,在里面加入有关控制台的配置 实现一个接口的限流 基本概念 重要功能 Sentinel规则 流控规则 简单配置 配置流控模式 配置流控效果 降级规则 SentinelResource…...

python 八大排序_python-打基础-八大排序
## 排序篇 #### 二路归并排序 - 介绍 - 归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。归并排序是一种稳定的排序方法。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列…...

运维知识点-Sqlite
Sqlite 引入 依赖 引入 依赖 <dependency><groupId>org.xerial</groupId><artifactId>sqlite-jdbc</artifactId><version>3.36.0.3</version></dependency>import javafx.scene.control.Alert; import java.sql.*;public clas…...

我为什么要写RocketMQ消息中间件实战派上下册这本书?
我与RocketMQ结识于2018年,那个时候RocketMQ还不是Apache的顶级项目,并且我还在自己的公司做过RocketMQ的技术分享,并且它的布道和推广,还是在之前的首席架构师的带领下去做的,并且之前有一个技术神经质的人࿰…...

24校招,Moka测试开发工程师一面
前言 大家好,今天回顾一下楼主当时参加moka测试开发工程师的面试 对其中一些重要问题,我也给出了相应的答案 过程 自我介绍挑一个项目,详细介绍你在其中担任的职责如何安排工作的,有什么成果?回归测试如何设计&…...
)
Docker(网络,网络通信,资源控制,数据管理,CPU优化,端口映射,容器互联)
目录 docker网络 网络实现原理 网络实现实例 网络模式 查看Docker中的网络列表: 指定容器网络模式 模式详解 Host模式(主机模式): Container模式(容器模式): None模式(无网…...
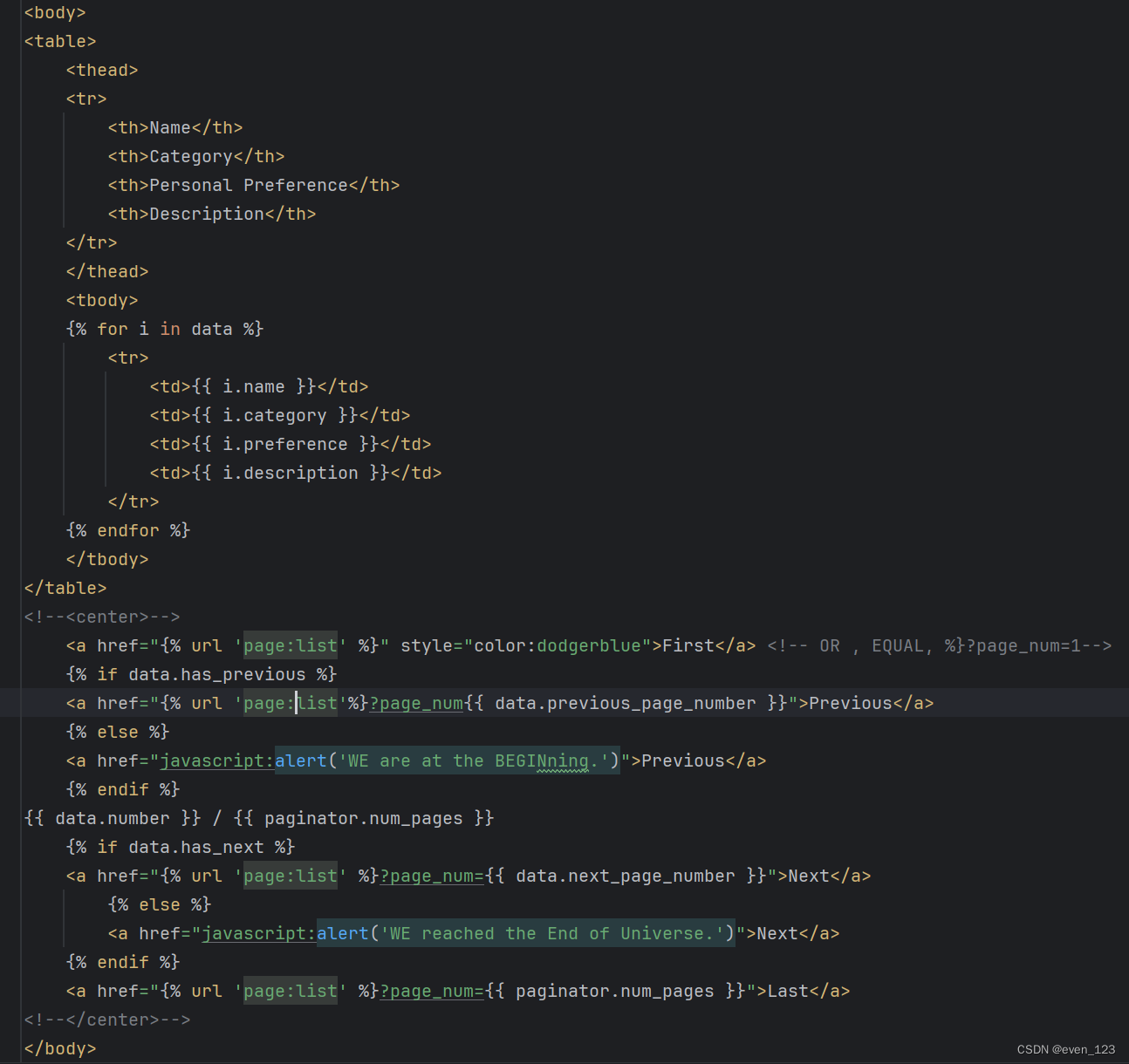
开发实践5_project
要求: (对作业要求的"Student"稍作了变换,表单名称为“Index”。)获得后台 Index 数据,作展示,要求使用分页器,包含上一页、下一页、当前页/总页。 结果: ① preparatio…...
蓝桥杯准备
书籍获取:Z-Library – 世界上最大的电子图书馆。自由访问知识和文化。 (zlibrary-east.se) 书评:(豆瓣) (douban.com) 一、观千曲而后晓声 别人常说蓝桥杯拿奖很简单,但是拿奖是一回事,拿什么奖又是一回事。况且,如果…...

AtCoder Beginner Contest 336 A-E 题解
比赛链接:https://atcoder.jp/contests/abc336比赛时间:2024 年 1 月 14 日 20:00-21:40 A题:Long Loong 标签:模拟题意:给定一个 n n n,输出 L L L、 n n n个 o o o和 n g ng ng。题解:按题意…...
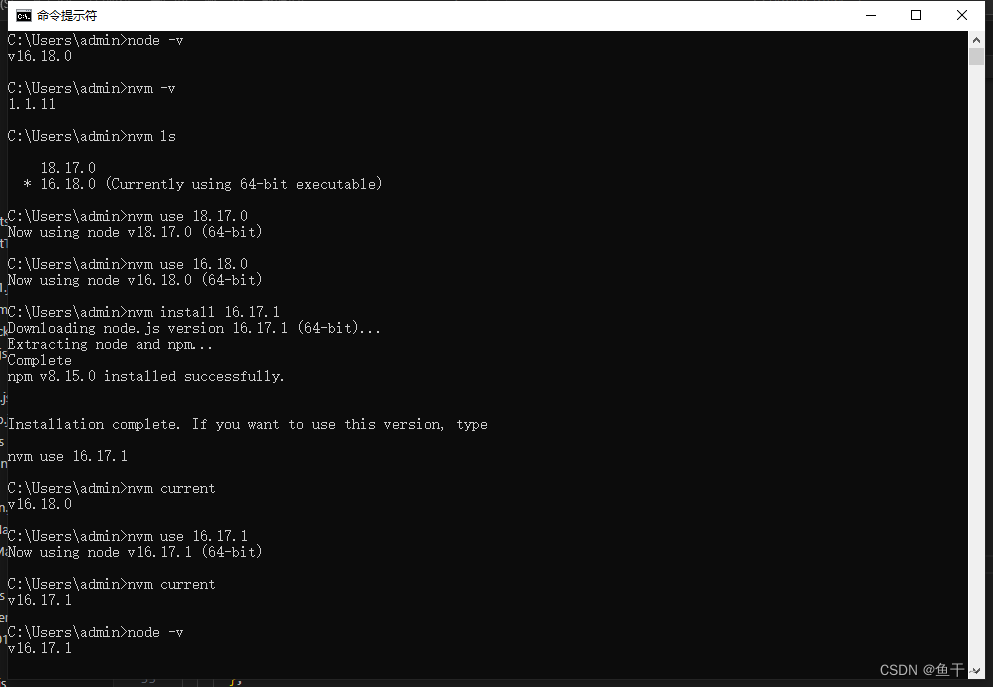
node各个版本的下载地址
下载地址: https://nodejs.org/dist/ 可以下载多个版本,使用nvm控制切换(需要先安装nvm再安装node) nvm下载地址(访问的是github,请科学上网,下载后解压安装exe即可):h…...
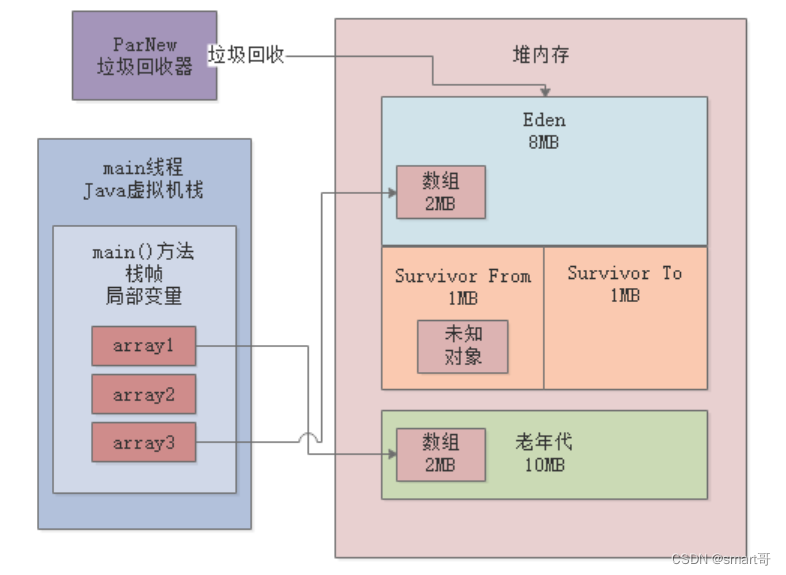
JVM实战(17)——模拟对象晋升
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO 联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬 学习必须往深处挖&…...

专业指南:高效在ARM设备上运行x86_64程序的完整解决方案
专业指南:高效在ARM设备上运行x86_64程序的完整解决方案 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 你是否正…...

右单旋的具体情况
右单旋的具体情况1、h为02、h为13、h为24、h为3在“AVL树的模拟实现”一文中,我们学习到旋转调整方法的时候,使用的需要旋转调整的示例,都是一些抽象的二叉搜索树: 如图的树a, b, c都是抽象的树。插入节点(红色方框&am…...
)
从淘宝几块钱的2804云台电机开始,手把手教你DIY一个桌面机械臂关节(STM32/GD32 + SimpleFOC)
从零打造低成本机械臂关节:2804云台电机FOC控制实战指南 在创客圈里,机械臂项目总是让人既向往又却步——商用伺服电机动辄上千元的单价,让许多爱好者望而却步。但当我发现淘宝上仅售几元的2804云台电机时,一个大胆的想法诞生了&a…...

深度解析Deep3D:专业级实时2D转3D视频转换技术实战指南
深度解析Deep3D:专业级实时2D转3D视频转换技术实战指南 【免费下载链接】Deep3D Real-Time end-to-end 2D-to-3D Video Conversion, based on deep learning. 项目地址: https://gitcode.com/gh_mirrors/dee/Deep3D Deep3D是一款基于深度学习的开源2D转3D视频…...

基于React与Docker构建可定制个人仪表盘:homepage项目实战指南
1. 项目概述:一个现代、轻量的个人仪表盘如果你和我一样,每天上班第一件事就是打开十几个浏览器标签页,在邮箱、项目管理工具、服务器监控、待办清单、常用文档之间来回切换,那么你一定能理解那种“数字工作台”杂乱无章带来的烦躁…...

README工匠技能:从自动化工具到工程化实践,打造项目黄金门面
1. 项目概述:一个为README注入灵魂的“工匠”技能 在开源社区和项目协作中,README文件就是项目的“门面”和“说明书”。一个优秀的README,能瞬间抓住潜在用户或贡献者的眼球,清晰地传达项目价值、快速引导上手,甚至能…...

射频PA中的ICC和ICQ电流是什么?
射频 PA 的 ICC 与 ICQ 深度解析 核心关联:ICQ(静态偏置)与 ICC(工作电流)直接决定 DLCA / ENDC / SRS / RX Desense 的系统稳定性。 一、拍板级定义:ICQ vs ICC 术语 全称 工作状态 核心关注点 ICQ Quiescent Current 静态(无信号或极小信号) 线性度、稳定性、瞬态响应…...

天线阻抗匹配原理与工程实践指南
1. 天线阻抗匹配基础概念解析阻抗匹配是射频工程师日常工作中最常遇到的技术挑战之一。简单来说,它就像是在为天线系统"调音",确保射频能量能够顺畅地从发射电路传递到天线,而不会在连接处产生"回声"(反射波&…...

通过Taotoken为OpenClaw配置自定义模型供应商的详细步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken为OpenClaw配置自定义模型供应商的详细步骤 OpenClaw是一个流行的AI智能体开发框架,它允许开发者灵活地配…...

手把手教你写一个能自动上网写研报的 Research Agent
手把手教你写一个能自动上网写研报的 Research Agent 引言 痛点引入 如果你是券商研究员、行业分析师、高校商科学生,或者企业战略岗的从业者,一定对「写研报」这件事的痛苦深有体会: 查资料耗时:一篇中等深度的行业研报,至少需要翻阅30+权威来源的信息,包括工信部政策…...