haiku实现门控多头注意力模块
在多头注意力机制中,通常输入的数据包括查询(Q)、键(K)和值(V)。这些数据的维度以及权重矩阵的维度在多头注意力机制中扮演关键角色。下面对数据及权重的维度进行解释:
-
输入数据(Queries, Keys, Values):
- Queries (Q): 表示待查询的信息,通常对应输入序列的每个位置。其维度通常为 (batch_size, seq_length, q_dim),其中
q_dim是查询向量的维度。 - Keys (K): 表示用于计算注意力分数的信息,也通常对应输入序列的每个位置。其维度通常为 (batch_size, seq_length, key_dim),其中
key_dim是键向量的维度。 - Values (V): 表示待加权求和的信息,同样对应输入序列的每个位置。其维度通常为 (batch_size, seq_length, value_dim),其中
value_dim是值向量的维度。
- Queries (Q): 表示待查询的信息,通常对应输入序列的每个位置。其维度通常为 (batch_size, seq_length, q_dim),其中
-
权重矩阵:
- 查询权重矩阵 (Q_weights): 用于对查询(Q)进行线性变换,将其映射到多个注意力头的维度。其维度通常为 (q_dim, num_heads, head_dim),其中
num_heads是注意力头的数量,head_dim是每个注意力头的维度。 - 键权重矩阵 (K_weights): 用于对键(K)进行线性变换,同样映射到多个注意力头的维度。其维度通常为 (key_dim, num_heads, head_dim)。
- 值权重矩阵 (V_weights): 用于对值(V)进行线性变换,映射到多个注意力头的维度。其维度通常为 (value_dim, num_heads, head_dim)。
- 查询权重矩阵 (Q_weights): 用于对查询(Q)进行线性变换,将其映射到多个注意力头的维度。其维度通常为 (q_dim, num_heads, head_dim),其中
def glorot_uniform():return hk.initializers.VarianceScaling(scale=1.0,mode='fan_avg',distribution='uniform')def stable_softmax(logits: jax.Array) -> jax.Array:"""Numerically stable softmax for (potential) bfloat 16."""if logits.dtype == jnp.float32:output = jax.nn.softmax(logits)elif logits.dtype == jnp.bfloat16:# Need to explicitly do softmax in float32 to avoid numerical issues# with large negatives. Large negatives can occur if trying to mask# by adding on large negative logits so that things softmax to zero.output = jax.nn.softmax(logits.astype(jnp.float32)).astype(jnp.bfloat16)else:raise ValueError(f'Unexpected input dtype {logits.dtype}')return outputclass Attention(hk.Module):"""Multihead attention."""def __init__(self, config, global_config, output_dim, name='attention'):super().__init__(name=name)self.config = configself.global_config = global_configself.output_dim = output_dimdef __call__(self, q_data, m_data, mask, nonbatched_bias=None):"""Builds Attention module.Arguments:q_data: A tensor of queries, shape [batch_size, N_queries, q_channels].m_data: A tensor of memories from which the keys and values areprojected, shape [batch_size, N_keys, m_channels].mask: A mask for the attention, shape [batch_size, N_queries, N_keys].nonbatched_bias: Shared bias, shape [N_queries, N_keys].Returns:A float32 tensor of shape [batch_size, N_queries, output_dim]."""# Sensible default for when the config keys are missingkey_dim = self.config.get('key_dim', int(q_data.shape[-1]))value_dim = self.config.get('value_dim', int(m_data.shape[-1]))num_head = self.config.num_headassert key_dim % num_head == 0assert value_dim % num_head == 0key_dim = key_dim // num_headvalue_dim = value_dim // num_head# weights维度(数据最后一维的维度数,注意力头数量,每个注意力头映射的数据维度)q_weights = hk.get_parameter('query_w', shape=(q_data.shape[-1], num_head, key_dim),dtype=q_data.dtype,init=glorot_uniform())k_weights = hk.get_parameter('key_w', shape=(m_data.shape[-1], num_head, key_dim),dtype=q_data.dtype,init=glorot_uniform())v_weights = hk.get_parameter('value_w', shape=(m_data.shape[-1], num_head, value_dim),dtype=q_data.dtype,init=glorot_uniform())# bqa: 输入张量 q_data 的轴的标记。(batch_size, seq_length, q_dim)# 'b' :batch 维度,'q':查询序列维度,'a' 查询向量的维度。所以,'bqa' 表示 q_data 的三个轴。# ahc:查询权重矩阵的形状, a:查询向量的维度,h:注意力头的数量,c: 每个注意力头中查询的维度。# key_dim**(-0.5) 注意力缩放,避免注意力分数过大或过小# jnp.einsum:Einstein Summation Notation(爱因斯坦求和约定)。# 一种紧凑、灵活的方式来指定和计算张量的乘积、求和和转置等操作。q = jnp.einsum('bqa,ahc->bqhc', q_data, q_weights) * key_dim**(-0.5)k = jnp.einsum('bka,ahc->bkhc', m_data, k_weights)v = jnp.einsum('bka,ahc->bkhc', m_data, v_weights)# 注意力分数,计算每个查询(q)和键(k)之间的点积,以获得注意力分数。# 结果维度为bhqk (batch_size, num_heads, num_q, num_k), # num_q/num_k为查询/键的数量,一般为 seq_length。logits = jnp.einsum('bqhc,bkhc->bhqk', q, k)if nonbatched_bias is not None:logits += jnp.expand_dims(nonbatched_bias, axis=0)# 注意力分数中加入masklogits = jnp.where(mask, logits, _SOFTMAX_MASK)# 对注意力分数进行softmax操作,我们得到每个位置对输入序列的权重分配。weights = stable_softmax(logits)# 注意力分数对值进行加权求和,得到多头注意力机制的输出# 两个向量的点积可以用于度量它们之间的相似性。如果两个向量越相似,它们的点积就越大weighted_avg = jnp.einsum('bhqk,bkhc->bqhc', weights, v)if self.global_config.zero_init:init = hk.initializers.Constant(0.0)else:init = glorot_uniform()# 带有bias的门控注意力if self.config.gating:gating_weights = hk.get_parameter('gating_w',shape=(q_data.shape[-1], num_head, value_dim),dtype=q_data.dtype,init=hk.initializers.Constant(0.0))gating_bias = hk.get_parameter('gating_b',shape=(num_head, value_dim),dtype=q_data.dtype,init=hk.initializers.Constant(1.0))gate_values = jnp.einsum('bqc, chv->bqhv', q_data,gating_weights) + gating_biasgate_values = jax.nn.sigmoid(gate_values)# ⊙ 对应元素相乘weighted_avg *= gate_valueso_weights = hk.get_parameter('output_w', shape=(num_head, value_dim, self.output_dim),dtype=q_data.dtype,init=init)o_bias = hk.get_parameter('output_b', shape=(self.output_dim,),dtype=q_data.dtype,init=hk.initializers.Constant(0.0))# 线性变换到输出维度大小output = jnp.einsum('bqhc,hco->bqo', weighted_avg, o_weights) + o_biasreturn output相关文章:

haiku实现门控多头注意力模块
在多头注意力机制中,通常输入的数据包括查询(Q)、键(K)和值(V)。这些数据的维度以及权重矩阵的维度在多头注意力机制中扮演关键角色。下面对数据及权重的维度进行解释: 输入数据&…...

【React 常用的 TS 类型】持续更新
1)定义样式的 TS 类型 【 React.CSSProperties 】 一般定义样式时需要的类型限制,如下: const customStyle: React.CSSProperties {color: blue,fontSize: 16px,margin: 10px,}; 2)定义 Input Ref 属性时的 TS 类型限制 【 R…...

打破传统边界,VR技术与六西格玛设计理念的创新融合!
在科技飞速发展的今天,虚拟现实(VR)技术以其独特的沉浸式体验,正在改变我们的生活和工作方式。然而,要让VR真正成为主流,我们必须解决一些关键问题,其中最重要的就是用户体验。六西格玛设计&…...

[uniapp] uni-ui+vue3.2小程序评论列表组件 回复评论 点赞和删除
先看效果 下载地址 uni-app官方插件市场: cc-comment组件 环境 基于vue3.2和uni-ui开发; 依赖版本参考如下: "dependencies": {"dcloudio/uni-mp-weixin": "3.0.0-3090820231124001","dcloudio/uni-ui": "^1.4.28","…...
:TongLINKQ常用命令)
TongLINKQ(3):TongLINKQ常用命令
启动: tlq 暂停: tlq -cabort -y -w1 查看lic信息: tlqstat –lic 查看队列消息: tlqstat -qcu qcu名 -c 查看发送连接状态: tlqstat -snd qcu名 -1 -ct 1 查看指定的Qcu连接状态: tlqsta…...

抽水马桶出水慢解决记录
今天分享一些修马桶的小心得(雾) 家里的马桶出水很好,但是水却不怎么被冲下去(出水很慢),这会导致内容物滞留,造成很不好的使用体验。 出于成本考虑,首先选择自己维修。 首先直接…...

img标签的奇怪问题
本来只是为实现一个轮播图,img的url地址是从后端接口获取的,但不巧的是url地址的图片都过期了。 因为懒得重新到网上找图,就想直接用一下本地的图片,简单的想法遇到一堆问题。 问题一: 因为是springboot项目…...

深入探究Hibernate:优雅、强大的Java持久化框架
目录 1、前言 2、Hibernate简介 2.1 什么是Hibernate 2.2 为什么选择Hibernate 3、Hibernate核心概念 3.1 实体类和映射文件 3.2 数据库表和持久化类的映射 3.3 主键生成策略 3.4 持久化操作 3.5 查询语言(HQL和Criteria) 3.6 事务管理 4、Hibernate配置与连接 4…...

JavaScript高级特性详解
摘要:本文将深入探讨JavaScript中的一些高级特性,包括闭包、原型链、高阶函数和异步编程。我们将通过详细的注释和实例来帮助读者理解这些概念,并通过总结部分强调其在实际开发中的应用。 一、闭包 闭包是JavaScript中一个非常重要的概念&a…...
网站建设网络设计营销类网站eyouCMS模板(PC+WAP)
模板介绍: 本模板自带eyoucms内核,无需再下载eyou系统,原创设计、手工书写DIVCSS,完美兼容IE7、Firefox、Chrome、360浏览器等;主流浏览器;结构容易优化;多终端均可正常预览。...
迅为RK3568开发板Android11/12/Linux编译驱动到内核
在平时的驱动开发中,经常需要在内核中配置某种功能,为了方便大家开发和学习,本小 节讲解如何在内核中添加驱动。具体的讲解原理讲解请参考本手册的驱动教程。 Android11 源码如果想要修改内核,可以运行以下命令进行修改: cd ke…...

SaaS 应用深度解析:Marketo
随着数字营销的不断发展,企业需要强大而智能的工具来管理营销活动、吸引潜在客户、并实现销售目标。在众多营销自动化工具中,Marketo 是一款备受推崇的 SaaS 应用,为企业提供全面的营销解决方案。本文将深入了解 Marketo,探讨其功…...

闲聊篇-求职的点点滴滴~~
引言 求职之旅是一段充满挑战与机遇的旅程。它不仅仅是寻找工作的过程,更是一个自我探索和成长的过程。在这篇文章中,我们将探讨求职的各个方面,从准备简历到面试,再到最终拿到心仪的offer。 1. 简历:你的敲门砖 精…...

微软最新研究成果:使用GPT-4合成数据来训练AI模型,实现SOTA!
文本嵌入是各项NLP任务的基础,用于将自然语言转换为向量表示。现有的大部分方法通常采用复杂的多阶段训练流程,先在大规模数据上训练,再在小规模标注数据上微调。此过程依赖于手动收集数据制作正负样本对,缺乏任务的多样性和语言多…...

爬虫案例—抓取小米商店应用
爬虫案例—抓取小米商店应用 代码如下: # 抓取第一页的内容 import requests from lxml import etree url ‘https://app.mi.com/catTopList/0?page1’ headers { ‘User-Agent’: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (K…...

geemap学习笔记047:边缘检测
前言 边缘检测适用于众多的图像处理任务,除了上一节[[geemap046:线性卷积–低通滤波器和拉普拉斯算子|线性卷积]]中描述的边缘检测核之外,Earth Engine 中还有几种专门的边缘检测算法。其中Canny 边缘检测算法使用四个独立的滤波器来识别对角…...
《Git学习笔记:IDEA整合Git》
在IDEA中集成Git去使用 通过Git命令可以完成Git相关操作,为了简化操作过程,我们可以在IDEA中配置Git,配置好后就可以在IDEA中通过图形化的方式来操作Git。 在IDEA开发工具中可以集成Git: 集成后在IDEA中可以看到Git相关图标&…...

Scipy 高级教程——统计学
Python Scipy 高级教程:统计学 Scipy 提供了强大的统计学工具,用于描述、分析和推断数据的分布和性质。本篇博客将深入介绍 Scipy 中的统计学功能,并通过实例演示如何应用这些工具。 1. 描述性统计 描述性统计是统计学中最基本的任务之一&…...
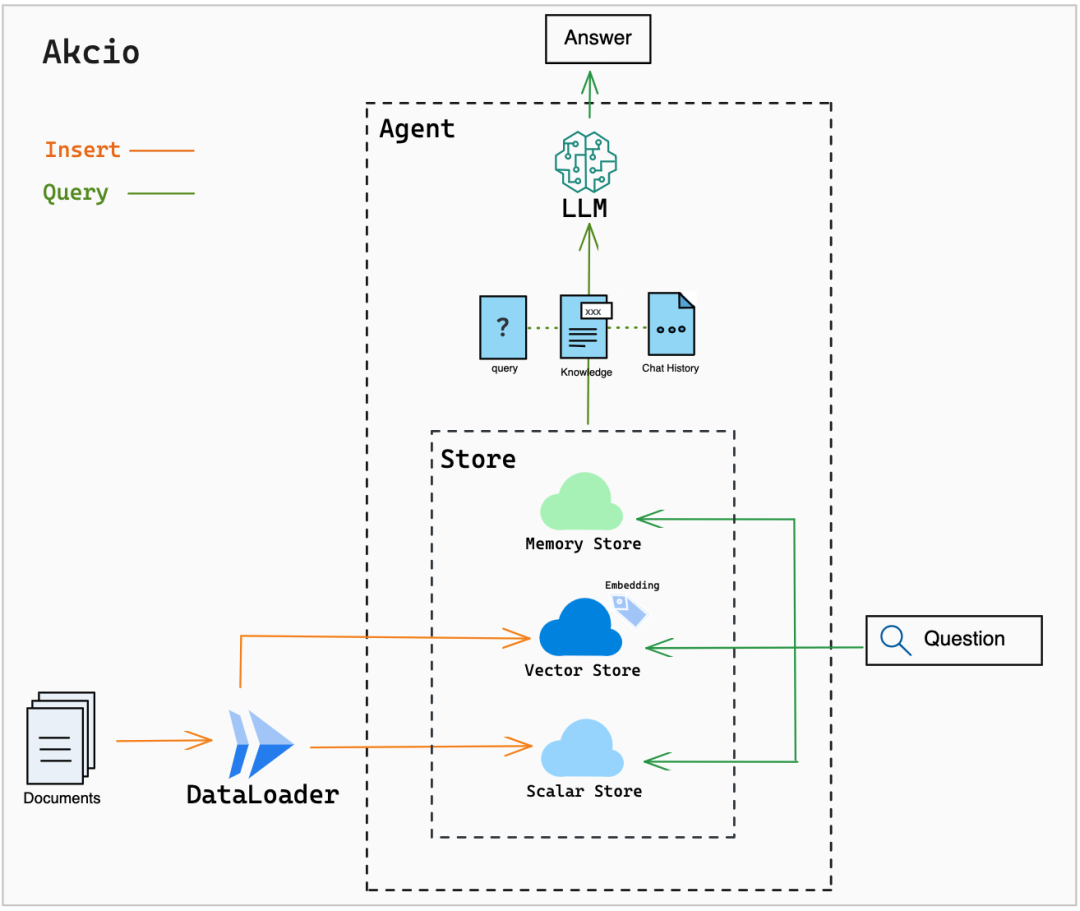
《向量数据库指南》RAG 应用中的指代消解——解决方案初探
随着 ChatGPT 等大语言模型(LLM)的不断发展,越来越多的研究人员开始关注语言模型的应用。 其中,检索增强生成(Retrieval-augmented generation,RAG)是一种针对知识密集型 NLP 任务的生成方法,它通过在生成过…...

CSS 一行三列布局,可换行(含grid网格布局、flex弹性布局/inline-block布局 + 伪类选择器)
效果 一、HTML <div class"num-wrap"><div class"num-item" v-for"num in 8" :key"num">{{ num }}</div></div> 二、CSS 1、grid网格布局(推荐) .num-wrap {// grid网格布局display…...

3PEAK思瑞浦 TP2272-SO1R SOP8 精密运放
特性 增益带宽积:7MHz 高斜率:20V/us 宽电源范围:3.1V至36V或2.25V至18V 低失调电压:0.5mV(最大值) 低输入偏置电流:30pA(典型值) 轨到轨输出电压范围 单位增益稳定: 工作温度范围:-40C至125C...

深度学习提取结构光条中心线项目的对比实验与消融实验统计分析方法研究
深度学习提取结构光条中心线项目的对比实验与消融实验统计分析方法研究 1 引言 线结构光三维测量技术凭借其非接触、高精度、快速测量等优势,在工业测量、三维重建、智能制造等领域得到了广泛应用。在结构光视觉测量系统中,光条中心线的提取精度直接决定了三维重建和尺寸测…...

Windows APK安装器完整指南:无需安卓手机直接安装应用
Windows APK安装器完整指南:无需安卓手机直接安装应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想要在Windows电脑上直接安装Android应用吗ÿ…...
)
基于深度学习的YOLOv8瞳孔识别+眼球识别与直径计算(代码+数据集+教程)
编写一个完整的从训练到推理YOLOv8瞳孔眼球识别与直径计算的指南,并包括模型转化和web界面交互式的实现,是一个相当庞大的项目。 1. 数据准备收集数据 对于瞳孔和眼球的检测,您需要收集大量的标注图像,这些图像应该包含不同光照条…...

从High-NA EUV到波长微缩:半导体光刻技术的未来路径与核心挑战
1. 从0.33 NA到High-NA EUV:我们走到了哪一步?EUV光刻技术从实验室走向大规模量产,这中间的十几年,可以说是半导体行业里最惊心动魄的技术长征之一。2018年那会儿,行业还在为EUV光源的功率能不能突破250瓦而焦虑&#…...

利用Taotoken的多模型能力为AIGC应用构建弹性后备方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken的多模型能力为AIGC应用构建弹性后备方案 对于开发图像生成、文案创作等AIGC应用的团队而言,服务连续性至…...
:企业级生产环境已验证)
DeepSeek R1模型API接入全流程(含鉴权失效应急手册):企业级生产环境已验证
更多请点击: https://intelliparadigm.com 第一章:DeepSeek R1模型API接入全流程(含鉴权失效应急手册):企业级生产环境已验证 DeepSeek R1 是当前高性能开源大语言模型之一,其官方 API 提供稳定、低延迟的…...

Cursor Pro功能解锁:3步实现免费无限制使用AI编辑器完整指南
Cursor Pro功能解锁:3步实现免费无限制使用AI编辑器完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached yo…...

选择Token Plan套餐后在实际开发中感受到的成本控制优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 选择Token Plan套餐后在实际开发中感受到的成本控制优势 1. 从按量计费到固定额度的转变 在项目开发的早期阶段,尤其是…...

基于Apify与NLP的大麻监管情报系统架构与MCP集成实践
1. 项目概述:当AI遇见大麻监管情报如果你在合规、法律科技或者生命科学领域工作,最近可能听过“监管情报”这个词。简单说,它就是利用技术手段,从海量的、不断变化的法规文件中,自动提取、分析和监控关键信息ÿ…...