abseil中的微操
给分支预测器的建议
原始代码
以下代码用于实现多线程中只调用一次的效果,这里的if大多数情况下都是false,即已经被调用过了。这里是否被调用过用的是一个`std::atomic<uint32_t>`的原子变量
template <typename Callable, typename... Args>
void call_once(absl::once_flag& flag, Callable&& fn, Args&&... args) {std::atomic<uint32_t>* once = base_internal::ControlWord(&flag);uint32_t s = once->load(std::memory_order_acquire);if (ABSL_PREDICT_FALSE(s != base_internal::kOnceDone)) {base_internal::CallOnceImpl(once, base_internal::SCHEDULE_COOPERATIVE_AND_KERNEL,std::forward<Callable>(fn), std::forward<Args>(args)...);}
}
用于做分支预测建议的宏
// Recommendation: Modern CPUs dynamically predict branch execution paths,
// typically with accuracy greater than 97%. As a result, annotating every
// branch in a codebase is likely counterproductive; however, annotating
// specific branches that are both hot and consistently mispredicted is likely
// to yield performance improvements.
#if ABSL_HAVE_BUILTIN(__builtin_expect) || \(defined(__GNUC__) && !defined(__clang__))
#define ABSL_PREDICT_FALSE(x) (__builtin_expect(false || (x), false))
#define ABSL_PREDICT_TRUE(x) (__builtin_expect(false || (x), true))
#else
#define ABSL_PREDICT_FALSE(x) (x)
#define ABSL_PREDICT_TRUE(x) (x)
#endif
解释
(__builtin_expect(false || (x), true)) 是一个使用了 GCC 内置函数 __builtin_expect 的表达式。这个内置函数通常用于向编译器提供分支预测信息,以优化代码的执行。
__builtin_expect 函数的语法是:
__builtin_expect(EXPRESSION, EXPECTED_VALUE)
EXPRESSION是一个表达式,可以是任何布尔表达式。EXPECTED_VALUE是一个编译器期望表达式EXPRESSION的结果为真或假的值。通常使用true或false。
__builtin_expect 函数告诉编译器表达式 EXPRESSION 的结果很可能是 EXPECTED_VALUE,以便编译器对代码进行优化。这种优化涉及到对条件分支的预测,使得最有可能的分支能够更快地执行,提高代码的性能。
在你的表达式中,(__builtin_expect(false || (x), true)) 使用了 __builtin_expect 函数,期望 (false || (x)) 的结果为真。这样的编码风格通常用于告诉编译器,(false || (x)) 表达式中的 x 很可能为真,以便编译器在生成机器代码时进行相关的优化。
需要注意的是,__builtin_expect 是 GCC 提供的特定于编译器的内置函数,因此它在其他编译器或开发环境中可能不可用。如果你的代码需要在其他编译器中编译,可能需要进行适当的修改或条件编译。
其他
讲讲这个call_once在面对多线程竞争时的实现原理。
- 第一个进入的线程可以执行
- 后续进入的线程需要等待
有了这个认识,剩下的就是看原子变量的改变过程和等待过程了。
template <typename Callable, typename... Args>
ABSL_ATTRIBUTE_NOINLINE
void CallOnceImpl(std::atomic<uint32_t>* control,base_internal::SchedulingMode scheduling_mode, Callable&& fn,Args&&... args) {static const base_internal::SpinLockWaitTransition trans[] = {{kOnceInit, kOnceRunning, true},{kOnceRunning, kOnceWaiter, false},{kOnceDone, kOnceDone, true}};// Must do this before potentially modifying control word's state.base_internal::SchedulingHelper maybe_disable_scheduling(scheduling_mode);// Short circuit the simplest case to avoid procedure call overhead.// The base_internal::SpinLockWait() call returns either kOnceInit or// kOnceDone. If it returns kOnceDone, it must have loaded the control word// with std::memory_order_acquire and seen a value of kOnceDone.uint32_t old_control = kOnceInit;if (control->compare_exchange_strong(old_control, kOnceRunning,std::memory_order_relaxed) ||base_internal::SpinLockWait(control, ABSL_ARRAYSIZE(trans), trans,scheduling_mode) == kOnceInit) {base_internal::invoke(std::forward<Callable>(fn),std::forward<Args>(args)...);old_control =control->exchange(base_internal::kOnceDone, std::memory_order_release);if (old_control == base_internal::kOnceWaiter) {base_internal::SpinLockWake(control, true);}} // else *control is already kOnceDone
}
// See spinlock_wait.h for spec.
uint32_t SpinLockWait(std::atomic<uint32_t> *w, int n,const SpinLockWaitTransition trans[],base_internal::SchedulingMode scheduling_mode) {int loop = 0;for (;;) {uint32_t v = w->load(std::memory_order_acquire);int i;for (i = 0; i != n && v != trans[i].from; i++) {}if (i == n) {SpinLockDelay(w, v, ++loop, scheduling_mode); // no matching transition} else if (trans[i].to == v || // null transitionw->compare_exchange_strong(v, trans[i].to,std::memory_order_acquire,std::memory_order_relaxed)) {if (trans[i].done) return v;}}
}
这里精彩的地方有两个,一个是多线程进入时候的状态机转换过程,即原子变量遵循的trans数组。第二个是SpinLockDelay在多个平台下的实现。
//posix linux
ABSL_ATTRIBUTE_WEAK void ABSL_INTERNAL_C_SYMBOL(AbslInternalSpinLockDelay)(std::atomic<uint32_t>* /* lock_word */, uint32_t /* value */, int loop,absl::base_internal::SchedulingMode /* mode */) {absl::base_internal::ErrnoSaver errno_saver;if (loop == 0) {} else if (loop == 1) {sched_yield();} else {struct timespec tm;tm.tv_sec = 0;tm.tv_nsec = absl::base_internal::SpinLockSuggestedDelayNS(loop);nanosleep(&tm, nullptr);}
}
//win32
void ABSL_INTERNAL_C_SYMBOL(AbslInternalSpinLockDelay)(std::atomic<uint32_t>* /* lock_word */, uint32_t /* value */, int loop,absl::base_internal::SchedulingMode /* mode */) {if (loop == 0) {} else if (loop == 1) {Sleep(0);} else {// SpinLockSuggestedDelayNS() always returns a positive integer, so this// static_cast is safe.Sleep(static_cast<DWORD>(absl::base_internal::SpinLockSuggestedDelayNS(loop) / 1000000));}
}
//sleep ms consideration
// Return a suggested delay in nanoseconds for iteration number "loop"
int SpinLockSuggestedDelayNS(int loop) {// Weak pseudo-random number generator to get some spread between threads// when many are spinning.uint64_t r = delay_rand.load(std::memory_order_relaxed);r = 0x5deece66dLL * r + 0xb; // numbers from nrand48()delay_rand.store(r, std::memory_order_relaxed);if (loop < 0 || loop > 32) { // limit loop to 0..32loop = 32;}const int kMinDelay = 128 << 10; // 128us// Double delay every 8 iterations, up to 16x (2ms).int delay = kMinDelay << (loop / 8);// Randomize in delay..2*delay range, for resulting 128us..4ms range.return delay | ((delay - 1) & static_cast<int>(r));
}
L1数据预取
abseil里面还定义了三个函数用于数据预取(prefetch)到本地缓存的函数。
数据预取是一种优化技术,通过提前将数据移动到CPU的缓存中,以便在数据被使用之前加速访问。这些函数的作用是将指定地址的数据预取到L1缓存中,以便在读取数据之前移动数据到缓存中。这样,当读取发生时,数据可能已经在缓存中,以提高访问速度。
下面是这些函数的简要说明:
-
void PrefetchToLocalCache(const void* addr): 将数据预取到L1缓存中,具有最高程度的时间局部性(temporal locality)。在可能的情况下,数据将预取到所有级别的缓存中。这个函数适用于具有长期重复访问的数据。 -
void PrefetchToLocalCacheNta(const void* addr): 与PrefetchToLocalCache函数相同,但具有非时间局部性(non-temporal locality)。这意味着预取的数据不应该留在任何缓存层级中。这在数据只使用一次或短期使用的情况下很有用,例如对对象调用析构函数。 -
void PrefetchToLocalCacheForWrite(const void* addr): 将具有修改意图的数据预取到L1缓存中。这个函数类似于PrefetchToLocalCache,但会预取带有“修改意图”的缓存行。通常包括在所有其他缓存层级中使该地址的缓存条目无效,并具有独占访问意图。这个函数用于在修改数据之前将数据预取到缓存中。
这些函数需要注意的是,不正确或滥用使用这些函数可能会降低性能。只有在经过充分的基准测试表明有改进时,才应使用这些函数。
ABSL_ATTRIBUTE_ALWAYS_INLINE inline void PrefetchToLocalCache(const void* addr) {_mm_prefetch(reinterpret_cast<const char*>(addr), _MM_HINT_T0);
}ABSL_ATTRIBUTE_ALWAYS_INLINE inline void PrefetchToLocalCacheNta(const void* addr) {_mm_prefetch(reinterpret_cast<const char*>(addr), _MM_HINT_NTA);
}ABSL_ATTRIBUTE_ALWAYS_INLINE inline void PrefetchToLocalCacheForWrite(const void* addr) {
#if defined(_MM_HINT_ET0)_mm_prefetch(reinterpret_cast<const char*>(addr), _MM_HINT_ET0);
#elif !defined(_MSC_VER) && defined(__x86_64__)// _MM_HINT_ET0 is not universally supported. As we commented further// up, PREFETCHW is recognized as a no-op on older Intel processors// and has been present on AMD processors since the K6-2. We have this// disabled for MSVC compilers as this miscompiles on older MSVC compilers.asm("prefetchw (%0)" : : "r"(addr));
#endif
}
编译器静态检查
#if ABSL_HAVE_ATTRIBUTE(guarded_by)
#define ABSL_GUARDED_BY(x) __attribute__((guarded_by(x)))
#else
#define ABSL_GUARDED_BY(x)
#endif
__attribute__((guarded_by(x))) 是一个GCC/Clang的扩展属性(attribute),用于指定一个互斥量(mutex)或锁(lock)来保护变量的访问。
这个属性的语法如下:
__attribute__((guarded_by(x)))
其中,x 是一个标识符,用于指定用于保护变量访问的互斥量或锁的名称。
该属性的作用是向编译器提供关于变量的额外信息,以帮助进行静态分析和检查多线程代码中的数据竞争问题。通过将 __attribute__((guarded_by(x))) 应用于变量,我们可以指示编译器该变量受特定互斥量的保护,从而在编译时进行检查。
例如,考虑以下示例:
#include <mutex>std::mutex mutex;
int shared_data __attribute__((guarded_by(mutex)));void foo()
{std::lock_guard<std::mutex> lock(mutex);// 访问 shared_datashared_data = 42;
}
在上面的示例中,shared_data 变量被 guarded_by 属性修饰,指示它受 mutex 互斥量的保护。这样,当在没有获取 mutex 互斥量的情况下访问 shared_data 时,编译器会发出警告或错误,以帮助检测潜在的数据竞争问题。
需要注意的是,__attribute__((guarded_by(x))) 是GCC/Clang的扩展属性,不是标准C++的一部分。因此,它在不同编译器之间可能具有不同的行为或不受支持。在使用该属性时,应注意编译器的兼容性和文档。
相关文章:

abseil中的微操
给分支预测器的建议 原始代码 以下代码用于实现多线程中只调用一次的效果,这里的if大多数情况下都是false,即已经被调用过了。这里是否被调用过用的是一个std::atomic<uint32_t>的原子变量 template <typename Callable, typename... Args>…...

NLP论文阅读记录 - 2022 | WOS 数据驱动的英文文本摘要抽取模型的构建与应用
文章目录 前言0、论文摘要一、Introduction1.1目标问题1.2相关的尝试1.3本文贡献 二.相关工作三.本文方法四 实验效果4.1数据集4.2 对比模型4.3实施细节4.4评估指标4.5 实验结果4.6 细粒度分析 五 总结 前言 Construction and Application of a Data-Driven Abstract Extractio…...

虹科新闻丨LIBERO医药冷链PDF温度计完成2024年航空安全鉴定,可安全空运!
来源:虹科环境监测技术 虹科新闻丨LIBERO医药冷链PDF温度计完成2024年航空安全鉴定,可安全空运! 原文链接:https://mp.weixin.qq.com/s/XHT4kU27opeKJneYO0WqrA 欢迎关注虹科,为您提供最新资讯! 虹科LIBE…...

智能搬运机器人作为一种新型的物流技术
随着物流行业的快速发展,货物转运的效率和准确性成为了企业竞争的关键因素之一。智能搬运机器人作为一种新型的物流技术,已经在许多企业中得到了广泛应用。本文将介绍富唯智能智能搬运机器人在物流行业的应用和优势。 在实际应用中,智能搬运机…...

UI自动化测试工具对企业具有重要意义
随着软件行业的不断发展,企业对高质量、高效率的软件交付有着越来越高的要求。在这个背景下,UI自动化测试工具成为了企业不可或缺的一部分。以下是UI自动化测试工具对企业的重要作用: 1. 提高软件质量 UI自动化测试工具能够模拟用户的操作&am…...

Linux--进程状态与优先级
概念 进程指的是程序在执行过程中的活动。进程是操作系统进行资源分配和调度的基本单位。 进程可以看作是程序的一次执行实体,它包含了程序代码、数据以及相关的执行上下文信息。操作系统通过创建、调度和管理多个进程来实现对计算机系统资源的有效利用。 每个进程…...
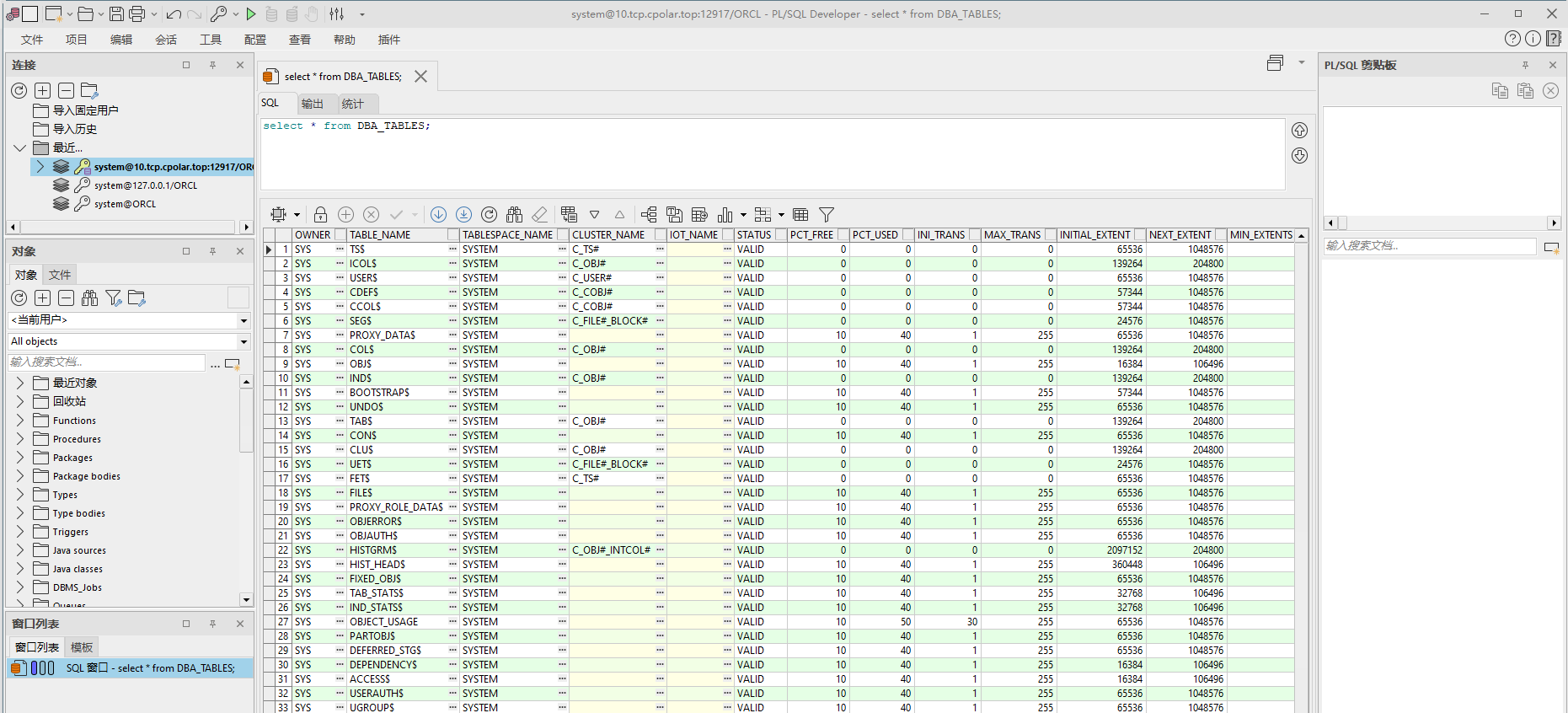
如何实现无公网ip固定TCP端口地址远程连接Oracle数据库
文章目录 前言1. 数据库搭建2. 内网穿透2.1 安装cpolar内网穿透2.2 创建隧道映射 3. 公网远程访问4. 配置固定TCP端口地址4.1 保留一个固定的公网TCP端口地址4.2 配置固定公网TCP端口地址4.3 测试使用固定TCP端口地址远程Oracle 前言 Oracle,是甲骨文公司的一款关系…...
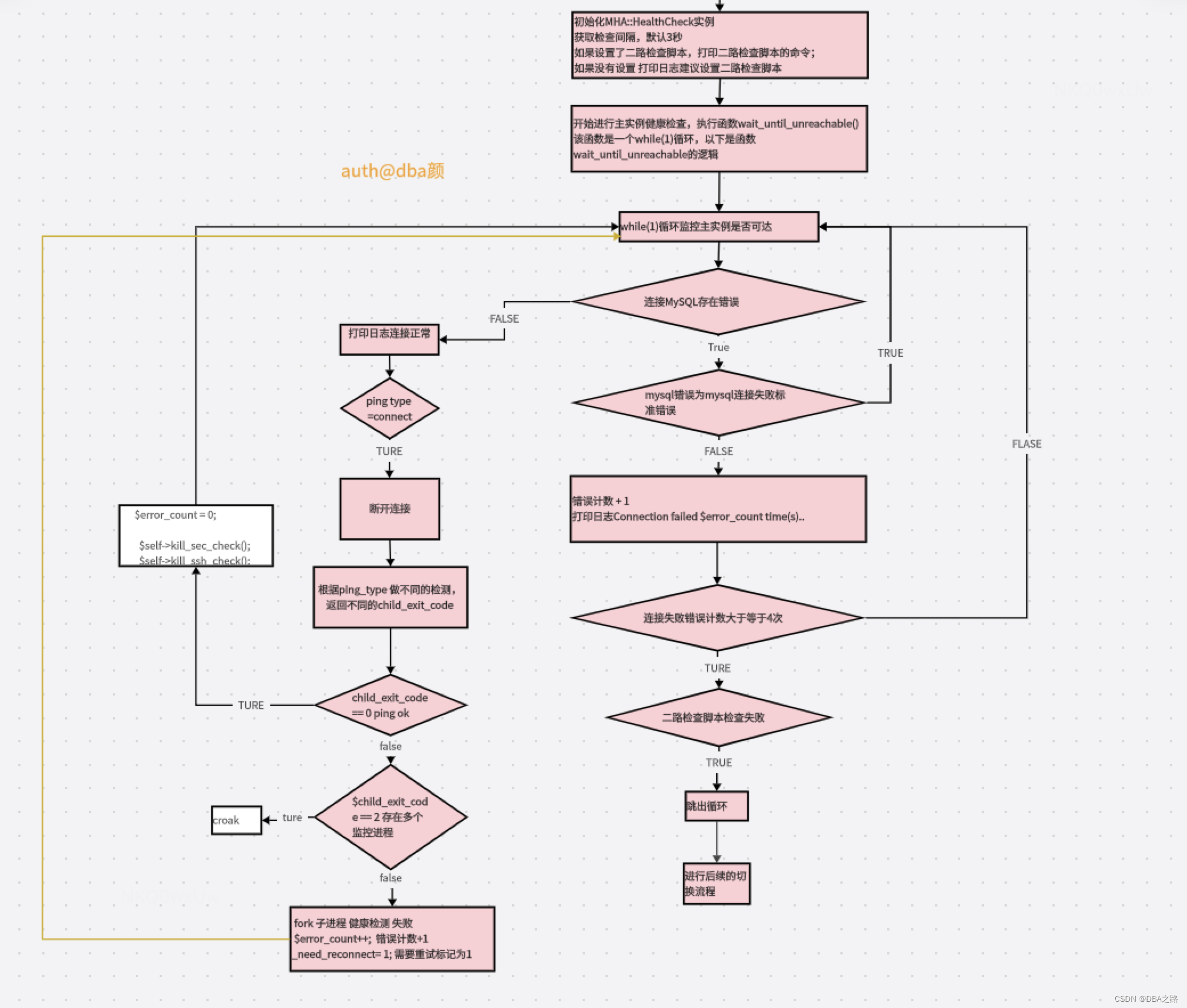
Orchestrator源码解读2-故障失败发现
目录 前言 核心流程函数调用路径 GetReplicationAnalysis 故障类型和对应的处理函数 编辑 拓扑结构警告类型 核心流程总结 与MHA相比 前言 Orchestrator另外一个重要的功能是监控集群,发现故障。根据从复制拓扑本身获得的信息,它可以识别各种故…...

REST2SQL是什么?它有什么功能和特性?它值不值得我们去学习?我们该如何去学习呢?
REST2SQL是一种将RESTful API转换为SQL查询的工具或技术。它可以将RESTful API中的请求转换为对数据库的SQL查询,以便从数据库中检索、更新或删除数据。 REST2SQL的工作原理是通过分析RESTful API的请求参数和路径,将其转换为相应的SQL查询语句。这样可…...

Android 实现获取集合中出现重复数据的值和数量
方法一:使用HashMap和HashSet 创建一个HashMap,用于存储集合中的元素及其出现次数。 Map<String, Integer> map new HashMap<>();遍历集合,将每个元素作为键,将其出现次数作为值添加到HashMap中。 for (String it…...

【QT学习十一】QThread
一、引言 在现代软件开发中,多线程编程变得越来越重要,尤其是对于需要处理并发任务的应用程序。Qt C 框架提供了强大的多线程支持,使得开发者能够轻松地创建和管理多线程应用。 在 Qt 中,多线程的实现主要基于 QThread 类。QThrea…...

Mybatis 39_使用MBG生成代码
此2个插件均未晚装成功!!!! 安装 MyBatipse插件 MyBatipse插件 - 开发MyBatis应用的Eclipse插件- 自动完成- 有效性验证- Mapper视图使用MBG MyBatis Generator (MBG):根据底层数据表来自动生成Mapper组件只要两步即可: (1) 提供一个简单的配置文件,告诉MBG连接数据…...
)
Hudi metadata table(元数据表)
什么是metadata表 Metadata表即Hudi元数据表,是一种特殊的Hudi表,对用户隐藏。该表用于存放普通Hudi表的元数据信息。Metadata表包含在普通Hudi表内部,与Hudi表是一一对应关系。 元数据表的作用 ApacheHudi元数据表可以显著提高查询的读/写性能。元数据表的主要目的是消…...

提高iOS App开发效率的方法
引言 随着智能手机的普及,iOS App开发成为越来越受欢迎的技术领域之一。许多人选择开发iOS应用程序来满足市场需求,但是iOS App开发需要掌握一些关键技术和工具,以提高开发效率和质量。本文将介绍一些关键点,可以帮助你进行高效的…...

MPU机制与实现详解
目录 MPU机制与实现详解 Partition元素-MPU Partition实现元素OSApplication Partition元素-RTE MPU机制与实现详解 1、freedom from interference 此概念来自ISO26262-1:多个元素之间没有可能导致违反安全目标的级联故障,称之为免于干涉。 在左侧的…...
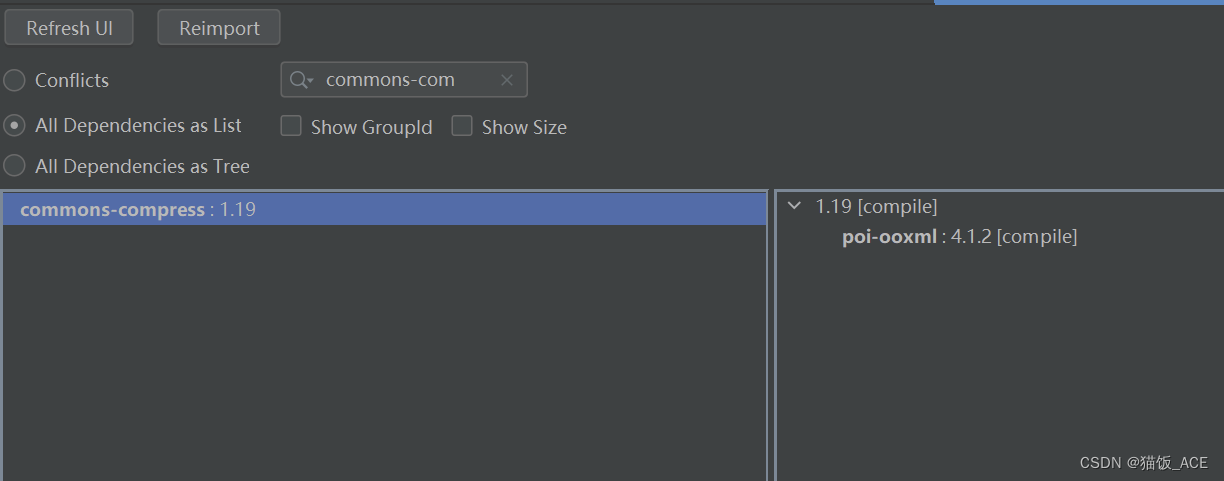
pom文件冲突引起的Excel无法下载
问题一:之前生产环境上可以进行下载Excel的功能突然不能用了 报错提示信息: NoClassDefFoundError: Could not initialize class org.apache.poi.xssf.usermodel.XSSFWorkbook, 在最开始初始化的时候找不到对应的类,虽然我的Libr…...

【HarmonyOS4.0】第十篇-ArkUI布局容器组件(二)
三、层叠布局容器(Stack) 堆叠容器组件 Stack的布局方式是把子组件按照设置的对齐方式顺序依次堆叠,后一个子组件覆盖在前一个子组件上边。 注意:Stack 组件层叠式布局,尺寸较小的布局会有被遮挡的风险, …...

PLECS如何下载第三方库并导入MOSFET 的xml文件,xml库路径添加方法及相关问题
1. 首先xml库的下载,PLECS提供了一个跳转的链接。 https://www.plexim.com/download/thermal_models 2. 下载一个库(以最后一个Wolfspeed为例,属于CREE的SiC MOSFET) 下载这个就行,都包含了。不信自己可以试试再下载…...
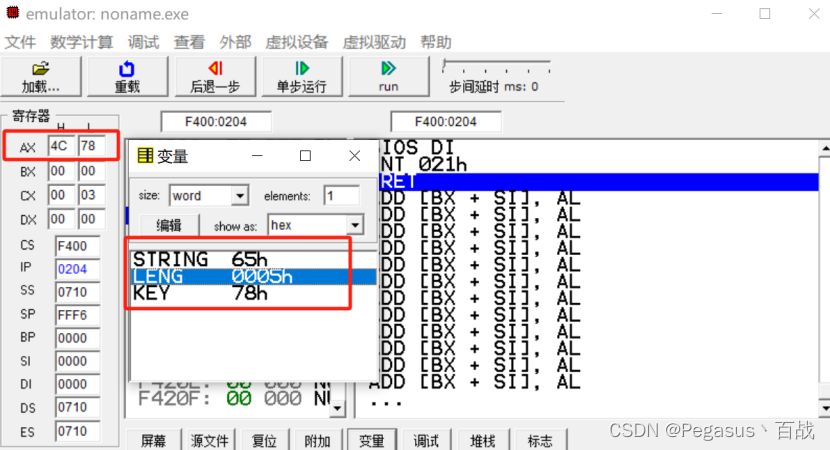
使用emu8086实现——子程序的设计
一、实验目的 学习子程序的结构、特点,以及子程序的设计和调试方法 二、实验内容 1、从字符串中删除一个字符,并存储到寄存器AX中。 代码及注释: data segmentstring db exas ;字符串内容leng dw $-string ; 字符串长度key db x …...
)
快速排序、归并排序、希尔排序(2023-12-25)
参考文章 十大经典排序算法总结整理_十大排序算法-CSDN博客 推荐文章 算法:归并排序和快排的区别_归并排序和快速排序的区别-CSDN博客 package com.tarena.test.B20; import java.util.Arrays; import java.util.StringJoiner; public class B25 { static i…...

NExT-GPT:从多模态对齐到任意模态生成的架构与实战
1. 项目概述:从“多模态”到“任意模态”的进化 如果你在过去一年里关注过AI领域,一定对“多模态大模型”这个词不陌生。从GPT-4V到Gemini,主流模型都在努力让AI能同时理解文本和图像。但不知道你有没有想过一个问题:为什么我们和…...

稳压二极管数据手册参数深度解析:从符号到实战选型
1. 稳压二极管核心参数全解析 第一次拿到稳压二极管的数据手册时,我完全被那些密密麻麻的符号搞懵了。VZ、IZK、ZZT这些字母组合到底代表什么?后来在项目中踩过几次坑才明白,这些参数直接关系到电路的稳定性。就拿去年做的一个电源模块来说&a…...

Unity性能优化实战:Mesh Baker 纹理合并与UV重映射详解
1. 为什么需要纹理合并与UV重映射 在开发开放世界游戏时,场景中往往会出现大量重复的建筑、植被等模型。每个模型通常都有自己的材质球和贴图,这会导致两个严重问题:首先是Draw Call数量激增,每个材质球都会产生一次Draw Call&…...

Neovim集成ChatGPT:AI编程助手插件配置与实战指南
1. 项目概述:当Neovim遇上ChatGPT,一个插件如何重塑你的编码体验 如果你是一个Neovim的深度用户,同时又对AI辅助编程抱有极大的热情,那么你很可能已经听说过或者正在寻找一个完美的结合点。 jackMort/ChatGPT.nvim 这个项目&…...
)
告别繁琐配置:Jprotobuf注解驱动序列化实战(新手友好)
1. 为什么选择Jprotobuf注解方案 如果你正在用Java开发需要频繁序列化数据的应用,比如缓存系统、微服务通信或者游戏服务器,肯定遇到过这样的纠结:用JSON虽然方便但性能差体积大,用Protobuf性能好但配置太麻烦。我去年做电商订单系…...

语言启蒙到底要不要背单词
语言启蒙阶段到底要不要背单词?我更愿意把这个问题换一种问法:这些词是不是能和声音、图像、语境连起来,并且隔几天还能回来一次。 如果只是拿一张词表硬记,入门用户很容易觉得枯燥。可如果完全不接触词汇,后面的听读…...

TigerVNC终极指南:快速掌握跨平台远程桌面控制
TigerVNC终极指南:快速掌握跨平台远程桌面控制 【免费下载链接】tigervnc High performance, multi-platform VNC client and server 项目地址: https://gitcode.com/gh_mirrors/ti/tigervnc TigerVNC是一款高性能、跨平台的VNC客户端和服务器软件࿰…...
)
STM32L4低功耗实战:用RTC内部唤醒定时1秒,让设备续航翻倍(附CubeIDE配置)
STM32L4低功耗实战:RTC唤醒中断与CubeIDE配置全解析 在电池供电的物联网终端设计中,每微安电流都关乎产品寿命。曾有个智能农业项目,原本预计6个月的传感器续航,因未优化低功耗模式,实际仅维持了3周。这促使我们深入研…...
)
【紧急更新】Google官方刚推送的Veo 2 v2.3.1补丁深度解析:新增胶片扫描模拟、物理光晕建模与导演模式(Director Mode)
更多请点击: https://intelliparadigm.com 第一章:Google Veo 2 v2.3.1补丁核心特性概览 Google Veo 2 v2.3.1 补丁是面向视频生成模型推理优化与安全增强的关键更新,聚焦于低延迟部署、多模态对齐稳定性及合规性强化。该版本并非架构重构&a…...

弯曲波触觉反馈技术:为触摸屏注入真实按键手感的工程实践
1. 项目概述:当触摸屏需要“手感”在2012年,如果你告诉一个家电设计师,未来的微波炉、冰箱或烤箱面板将是一块完全平整、没有任何物理凸起的玻璃或塑料板,他可能会皱起眉头。因为这意味着用户将失去最直接的交互反馈——那个“咔哒…...