C语言从入门到实战——结构体与位段
结构体与位段
- 前言
- 一、结构体类型的声明
- 1.1 结构体
- 1.1.1 结构的声明
- 1.1.2 结构体变量的创建和初始化
- 1.2 结构的特殊声明
- 1.3 结构的自引用
- 二、 结构体内存对齐
- 2.1 对齐规则
- 2.2 为什么存在内存对齐
- 2.3 修改默认对齐数
- 三、结构体传参
- 四、 结构体实现位段
- 4.1 什么是位段
- 4.2 位段的内存分配
- 4.3 位段的跨平台问题
- 4.4 位段的应用
- 4.5 位段使用的注意事项
前言
C语言中的结构体是一种自定义的数据类型,可以用来表示多个不同类型的数据的集合。结构体是由多个变量组成的,每个变量称为结构体的成员。
使用结构体需要先定义结构体类型,然后可以声明该类型的变量。
定义结构体类型的语法如下:
struct 结构体类型名 {成员类型1 成员名1;成员类型2 成员名2;...
};
例如,定义一个表示学生的结构体类型:
struct Student {int id;char name[20];float score;
};
上面的代码定义了一个名为Student的结构体类型,该类型有三个成员:id、name和score。
声明结构体变量的语法如下:
struct 结构体类型名 变量名;
例如,声明一个名为student1的Student结构体变量:
struct Student student1;
可以使用.操作符来访问结构体变量的成员,例如:
student1.id = 1;
strcpy(student1.name, "Tom");
student1.score = 90.5;
上面的代码给student1结构体变量的成员赋值。
结构体变量的初始化可以使用赋值运算符=,例如:
struct Student student2 = {2, "Jerry", 85.5};
上面的代码创建了一个名为student2的Student结构体变量,并初始化了其成员的值。
结构体变量的成员可以使用.操作符来访问,例如:
printf("学生ID:%d\n", student1.id);
printf("学生姓名:%s\n", student1.name);
printf("学生成绩:%f\n", student1.score);
上面的代码输出了student1结构体变量的成员的值。
注意,结构体的成员可以是任意类型,包括基本数据类型、指针、数组、其他结构体等。可以通过.操作符来访问结构体的成员,也可以使用指针来访问结构体的成员,使用指针访问结构体的成员需要使用->操作符。
例如,使用指针访问结构体的成员:
struct Student *ptr_student = &student1;
ptr_student->id = 3;
strcpy(ptr_student->name, "Alice");
ptr_student->score = 95.5;
C语言中,位段(bit-field)是一种数据结构,用于将内存空间的位字段化。它可以让用户指定一个存储单元中需要使用的位数。
位段使用的语法形式如下:
struct {type [member_name] : width;
};
其中,type 可以是整型数据类型(如 int、char 等),[member_name] 是位段的名称,width 是位段的宽度,指定了需要使用的位数。
例如,下面的代码定义了一个具有 3 个位段的结构体:
struct {unsigned int a : 4;unsigned int b : 5;unsigned int c : 3;
} bitfield;
在这个结构体中,a 的宽度为 4 位,b 的宽度为 5 位,c 的宽度为 3 位。
位段可以用于节省内存空间,因为它只使用所需的位数,而不是整个字节或字的空间。
然而,由于位段是由编译器决定如何存储,它的具体实现可能在不同的编译器和平台上有所不同。因此,在使用位段时需要注意其可移植性和实现细节。
一、结构体类型的声明
1.1 结构体
结构体是一些值的集合,这些值称为成员变量。结构体的每个成员可以是不同类型的变量。
1.1.1 结构的声明
struct tag
{
member-list;
}variable-list;
例如描述一个学生:
struct Stu
{char name[20]; //名字int age; //年龄char sex[5]; //性别char id[20]; //学号
}; //分号不能丢
1.1.2 结构体变量的创建和初始化
#include <stdio.h>
struct Stu
{char name[20]; //名字int age; //年龄char sex[5]; //性别char id[20]; //学号
};
int main()
{//按照结构体成员的顺序初始化struct Stu s = { "张三", 20, "男", "20230818001" };printf("name: %s\n", s.name);printf("age : %d\n", s.age);printf("sex : %s\n", s.sex);printf("id : %s\n", s.id);//按照指定的顺序初始化struct Stu s2 = { .age = 18, .name = "lisi", .id = "20230818002", .sex = "女" };printf("name: %s\n", s2.name);printf("age : %d\n", s2.age);printf("sex : %s\n", s2.sex);printf("id : %s\n", s2.id);return 0;
}
1.2 结构的特殊声明
在声明结构的时候,可以不完全的声明。
比如:
//匿名结构体类型
struct
{int a;char b;float c;
}x;struct
{int a;char b;float c;
}a[20], *p;
上面的两个结构在声明的时候省略掉了结构体标签(tag)。
那么问题来了?
//在上面代码的基础上,下面的代码合法吗?
p = &x;
警告:
编译器会把上面的两个声明当成完全不同的两个类型,所以是非法的。
匿名的结构体类型,如果没有对结构体类型重命名的话,基本上只能使用一次。
1.3 结构的自引用
在结构体中包含一个类型为该结构本身的成员是否可以呢?
比如,定义一个链表的节点:
struct Node
{int data;struct Node next;
};
上述代码正确吗?如果正确,那 sizeof(struct Node) 是多少?
仔细分析,其实是不行的,因为一个结构体中再包含一个同类型的结构体变量,这样结构体变量的大小就会无穷的大,是不合理的。
正确的自引用方式:
struct Node
{int data;struct Node* next;
};
在结构体自引用使用的过程中,夹杂了 typedef 对匿名结构体类型重命名,也容易引入问题,看看下面的代码,可行吗?
typedef struct
{int data;Node* next;
}Node;
答案是不行的,因为Node是对前面的匿名结构体类型的重命名产生的,但是在匿名结构体内部提前使用Node类型来创建成员变量,这是不行的。
解决方案如下:定义结构体不要使用匿名结构体
typedef struct Node
{int data;struct Node* next;
}Node;
二、 结构体内存对齐
我们已经掌握了结构体的基本使用了。
现在我们深入讨论一个问题:计算结构体的大小。
2.1 对齐规则
首先得掌握结构体的对齐规则:
- 结构体的第一个成员对齐到和结构体变量起始位置偏移量为0的地址处
- 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
对齐数=编译器默认的一个对齐数与该成员变量大小的较小值。
- VS 中默认的值为 8
- Linux中gcc没有默认对齐数,对齐数就是成员自身的大小
- 结构体总大小为最大对齐数(结构体中每个成员变量都有一个对齐数,所有对齐数中最大的)的整数倍。
- 如果嵌套了结构体的情况,嵌套的结构体成员对齐到自己的成员中最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体中成员的对齐数)的整数倍。
当然,除上述之外,我们还可以使用宏定义来实现偏移量的计算
offsetof 计算结构体相较于起始位置的偏移量
//练习1
struct S1
{char c1;int i;char c2;
};printf("%d\n", sizeof(struct S1));
//练习2
struct S2
{char c1;char c2;int i;
};printf("%d\n", sizeof(struct S2));
//练习3
struct S3
{double d;char c;int i;
};printf("%d\n", sizeof(struct S3));
//练习4-结构体嵌套问题
struct S4
{char c1;struct S3 s3;double d;
};printf("%d\n", sizeof(struct S4));

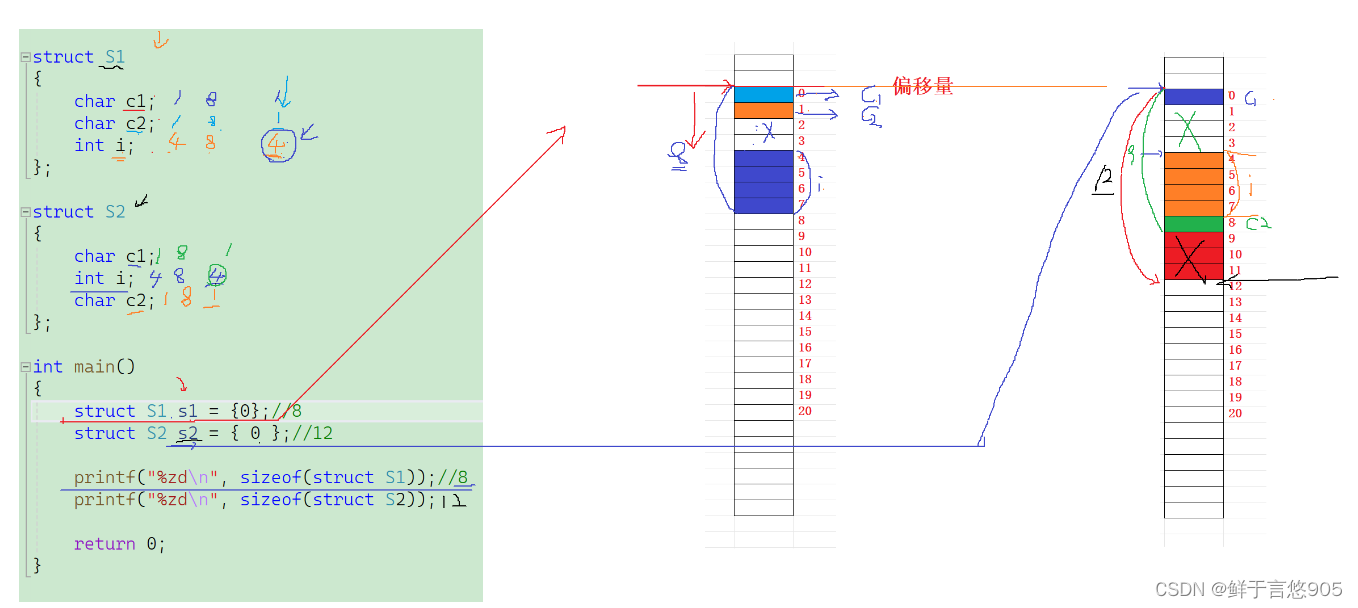
#include <stdio.h>
#include<stddef.h>
struct S1
{char c1;int i;char c2;
};
int main()
{printf("%d\n", offsetof(struct S1, c1));printf("%d\n", offsetof(struct S1, i));printf("%d\n", offsetof(struct S1, c2));return 0;
}
2.2 为什么存在内存对齐
大部分的参考资料都是这样说的:
- 平台原因(移植原因):
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。 - 性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。假设一个处理器总是从内存中取8个字节,则地址必须是8的倍数。如果我们能保证将所有的double类型的数据的地址都对齐成8的倍数,那么就可以用一个内存操作来读或者写值了。否则,我们可能需要执行两次内存访问,因为对象可能被分放在两个8字节内存块中。
总体来说:结构体的内存对齐是拿空间来换取时间的做法。
那在设计结构体的时候,我们既要满足对齐,又要节省空间,如何做到:让占用空间小的成员尽量集中在一起
//例如:
struct S1
{char c1;int i;char c2;
};
struct S2
{char c1;char c2;int i;
};
S1 和 S2 类型的成员一模一样,但是 S1 和 S2 所占空间的大小有了一些区别。
2.3 修改默认对齐数
#pragma 这个预处理指令,可以改变编译器的默认对齐数。
#include <stdio.h>
#pragma pack(1) //设置默认对齐数为1
struct S
{char c1;int i;char c2;
};.
#pragma pack() //取消设置的对齐数,还原为默认
int main()
{//输出的结果是什么?printf("%d\n", sizeof(struct S));return 0;
}
结构体在对齐方式不合适的时候,我们可以自己更改默认对齐数。
三、结构体传参
struct S
{int data[1000];int num;
};
struct S s = {{1,2,3,4}, 1000};
//结构体传参
void print1(struct S s)
{printf("%d\n", s.num);
}
//结构体地址传参
void print2(struct S* ps)
{printf("%d\n", ps->num);
}
int main()
{print1(s); //传结构体print2(&s); //传地址return 0;
}上面的print1和 print2 函数哪个好些?
答案是:首选print2函数。
原因:函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。
如果传递一个结构体对象的时候,结构体过大,参数压栈的的系统开销比较大,所以会导致性能的下降。
结论:结构体传参的时候,要传结构体的地址。
四、 结构体实现位段
结构体讲完就得讲讲结构体实现位段的能力。
4.1 什么是位段
位段的声明和结构是类似的,有两个不同:
- 位段的成员必须是
int、unsigned int或signed int,在C99中位段成员的类型也可以选择其他类型。 - 位段的成员名后边有一个冒号和一个数字。
比如:
位段的出现就是为了节约空间
struct A
{int _a:2;int _b:5;int _c:10;int _d:30;
};
A就是一个位段类型。
那位段A所占内存的大小是多少?
printf("%d\n", sizeof(struct A));
4.2 位段的内存分配
- 位段的成员可以是
intunsigned intsigned int或者是char等类型 - 位段的空间上是按照需要以4个字节(
int)或者1个字节(char)的方式来开辟的。 - 位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使用位段。
//一个例子
struct S
{char a:3;char b:4;char c:5;char d:4;
};struct S s = {0};s.a = 10;s.b = 12;s.c = 3;s.d = 4;
//空间是如何开辟的?
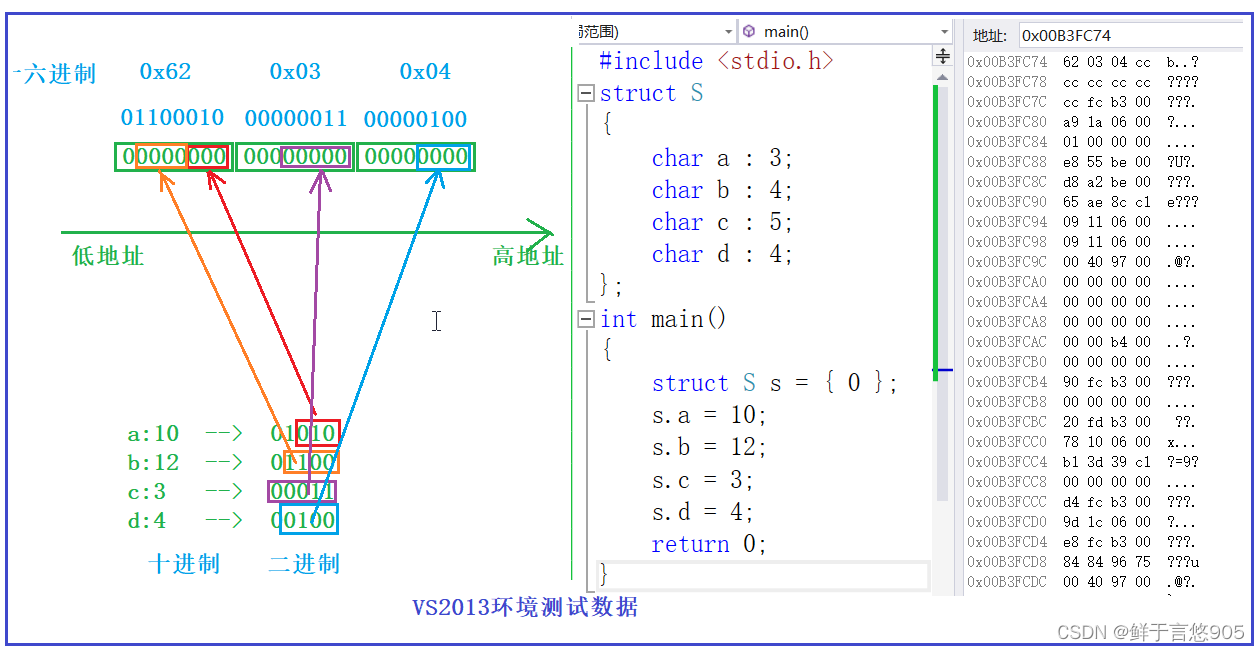
在vs里位段是从右向左使用的,在其他编译器下需要自己验证
4.3 位段的跨平台问题
int位段被当成有符号数还是无符号数是不确定的。- 位段中最大位的数目不能确定。(16位机器最大16,32位机器最大32,写成27,在16位机器会出问题。)
- 位段中的成员在内存中从左向右分配,还是从右向左分配标准尚未定义。
- 当一个结构包含两个位段,第二个位段成员比较大,无法容纳于第一个位段剩余的位时,是舍弃剩余的位还是利用,这是不确定的。
总结:跟结构体相比,位段可以达到同样的效果,并且可以很好的节省空间,但是有跨平台的问题存在。
4.4 位段的应用
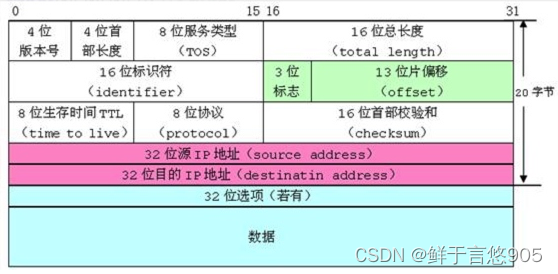
下图是网络协议中,IP数据报的格式,我们可以看到其中很多的属性只需要几个bit位就能描述,这里使用位段,能够实现想要的效果,也节省了空间,这样网络传输的数据报大小也会较小一些,对网络的畅通是有帮助的。
4.5 位段使用的注意事项
位段的几个成员共有同一个字节,这样有些成员的起始位置并不是某个字节的起始位置,那么这些位置处是没有地址的。内存中每个字节分配一个地址,一个字节内部的bit位是没有地址的。
所以不能对位段的成员使用&操作符,这样就不能使用scanf直接给位段的成员输入值,只能是先输入放在一个变量中,然后赋值给位段的成员。
struct A
{int _a : 2;int _b : 5;int _c : 10;int _d : 30;
};int main()
{struct A sa = {0};scanf("%d", &sa._b); //这是错误的//正确的示范int b = 0;scanf("%d", &b);sa._b = b;return 0;
}
相关文章:
C语言从入门到实战——结构体与位段
结构体与位段 前言一、结构体类型的声明1.1 结构体1.1.1 结构的声明1.1.2 结构体变量的创建和初始化 1.2 结构的特殊声明1.3 结构的自引用 二、 结构体内存对齐2.1 对齐规则2.2 为什么存在内存对齐2.3 修改默认对齐数 三、结构体传参四、 结构体实现位段4.1 什么是位段4.2 位段…...
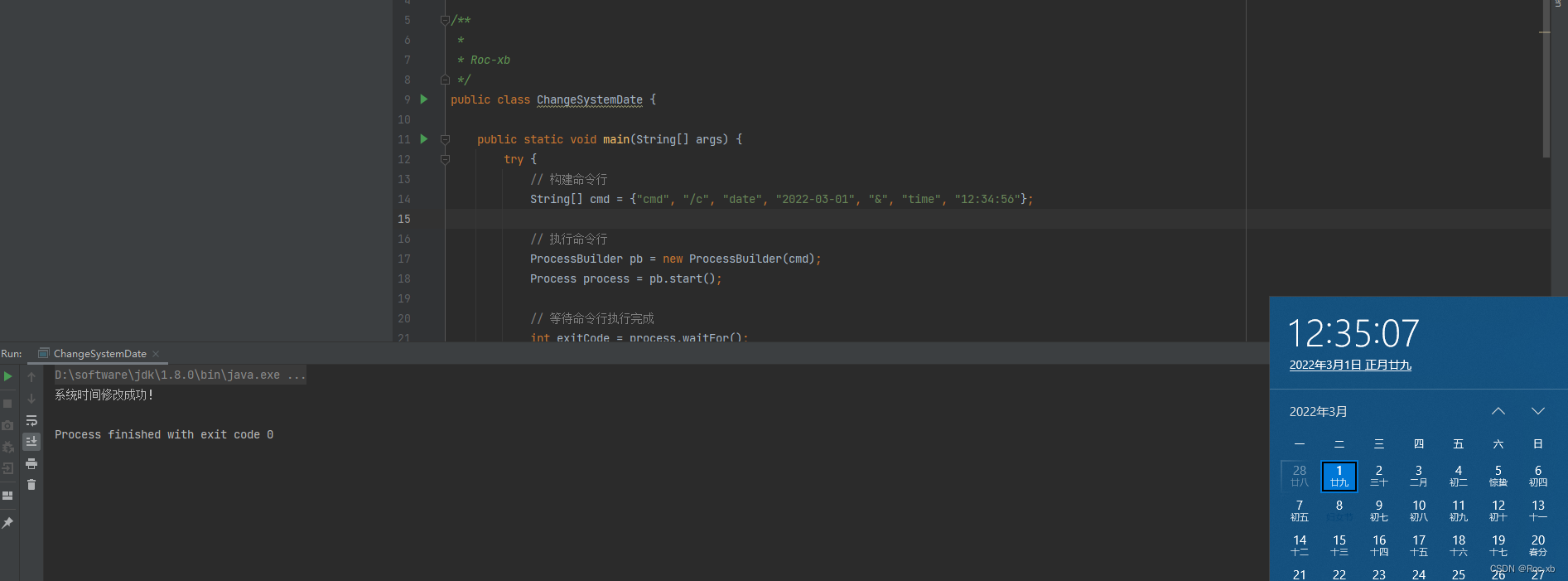
java如何修改windows计算机本地日期和时间?
本文教程,主要介绍,在java中如何修改windows计算机本地日期和时间。 目录 一、程序代码 二、运行结果 一、程序代码 package com;import java.io.IOException;/**** Roc-xb*/ public class ChangeSystemDate {public static void main(String[] args)…...

flink中的row类型详解
在Apache Flink中,Row 是一个通用的数据结构,用于表示一行数据。它是 Flink Table API 和 Flink DataSet API 中的基本数据类型之一。Row 可以看作是一个类似于元组的结构,其中包含按顺序排列的字段。 Row 的字段可以是各种基本数据类型&…...
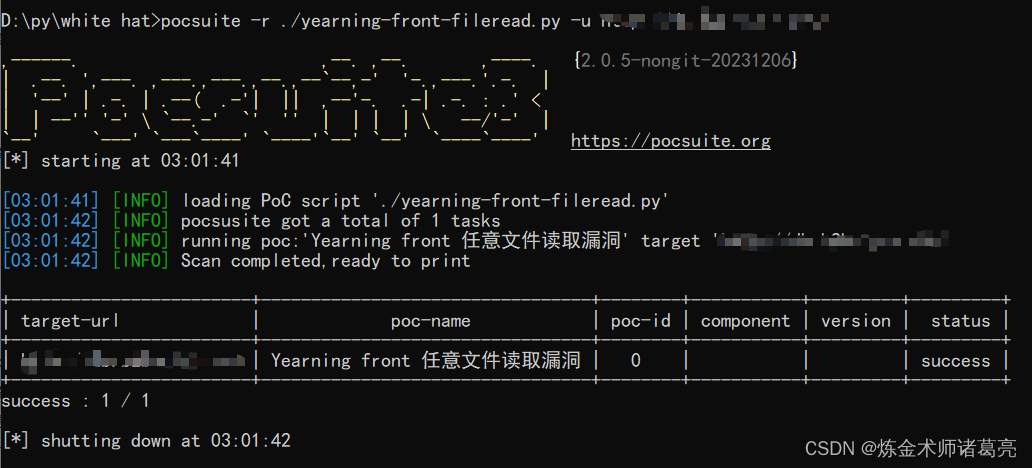
漏洞复现-Yearning front 任意文件读取漏洞(附漏洞检测脚本)
免责声明 文章中涉及的漏洞均已修复,敏感信息均已做打码处理,文章仅做经验分享用途,切勿当真,未授权的攻击属于非法行为!文章中敏感信息均已做多层打马处理。传播、利用本文章所提供的信息而造成的任何直接或者间接的…...
K8S中SC、PV、PVC的理解
存储类(StorageClass)定义了持久卷声明(PersistentVolumeClaim)所需的属性和行为,而持久卷(PersistentVolume)是实际的存储资源,持久卷声明(PersistentVolumeClaim&#…...
Agisoft Metashape 基于影像的外部点云着色
Agisoft Metashape 基于影像的外部点云着色 文章目录 Agisoft Metashape 基于影像的外部点云着色前言一、添加照片二、对齐照片三、导入外部点云四、为点云着色五、导出彩色点云前言 本教程介绍了在Agisoft Metashape Professional中,将照片中的真实颜色应用于从不同源获取的…...
图解结算平台:准确高效给商户结款
这是《百图解码支付系统设计与实现》专栏系列文章中的第(4)篇。 本章主要讲清楚支付系统中商户结算涉及的基本概念,产品架构、系统架构,以及一些核心的流程和相关领域模型、状态机设计等。 1. 前言 收单结算是支付系统最重要的子…...

修改和调试 onnx 模型
1. onnx 底层实现原理 1.1 onnx 的存储格式 ONNX 在底层是用 Protobuf 定义的。Protobuf,全称 Protocol Buffer,是 Google 提出的一套表示和序列化数据的机制。使用 Protobuf 时,用户需要先写一份数据定义文件,再根据这份定义文…...

不同整数的最少数目和单词直接最短距离
写是为了更好的思考,坚持写作,力争更好的思考。 今天分享两个关于“最小、最短”的算法题,废话少说,show me your code! 一、不同整数的最少数目 给你一个整数数组arr和一个整数k。现需要从数组中恰好移除k个元素&…...
 (64 位) 更新失败解决方案)
【Microsoft Edge】版本 109.0.1518.55 (正式版本) (64 位) 更新失败解决方案
Microsoft Edge 版本号 109.0.1518.55(正式版本)(64位) 更新直接报错 检查更新时出错: 无法创建该组件(错误代码 3: 0x80040154 – system level) 问题出现之前 之前电脑日常硬盘百分百(删文件和移动文件都慢得像…...

深度学习笔记(四)——使用TF2构建基础网络的常用函数+简单ML分类实现
文中程序以Tensorflow-2.6.0为例 部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。 截图和程序部分引用自北京大学机器学习公开课 TF2基础常用函数 1、张量处理类 强制数据类型转换: a1 tf.constant([1,2,3], dtypetf.floa…...
:初识大模型)
大模型学习篇(一):初识大模型
目录 一、大模型的定义 二、大模型的基本原理与特点 三、大模型的分类 四、大模型的相关落地产品 五、总结 一、大模型的定义 大模型是指具有数千万甚至数亿参数的深度学习模型。大模型具有以下特点: 参数规模庞大:大模型的一个关键特征是其包含了…...
uni-app的学习【第二节】
四 路由配置及页面跳转 (1)路由配置 uni-app页面路由全部交给框架统一管理,需要在pages.json里配置每个路由页面的路径以及页面样式(类似小程序在app.json中配置页面路由) 接着第一节的文件,在pages里面新建三个页面 将之前的首页替换为下面的内容,其他页面如下图 然…...
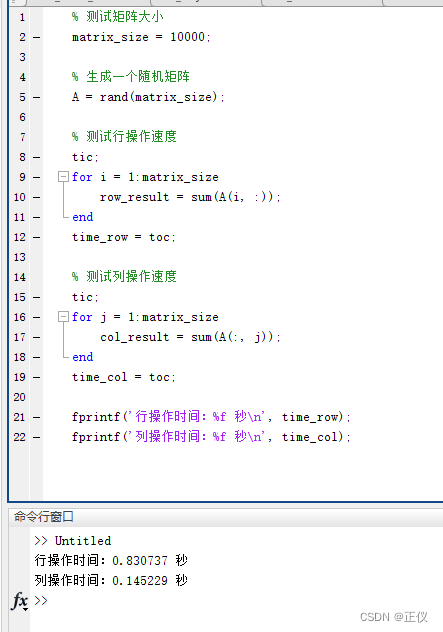
matlab行操作快?还是列操作快?
在MATLAB中,通常情况下,对矩阵的列进行操作比对行进行操作更有效率。这是因为MATLAB中内存是按列存储的,因此按列访问数据会更加连续,从而提高访问速度。 一、实例代码 以下是一个简单的测试代码, % 测试矩阵大小 ma…...
基于SSM的流浪动物救助站
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...
任务13:使用MapReduce对天气数据进行ETL(获取各基站ID)
任务描述 知识点: 天气数据进行ETL 重 点: 掌握MapReduce程序的运行流程熟练编写MapReduce程序使用MapReduce进行ETL 内 容: 编写MapReduce程序编写Shell脚本,获取MapReduce程序的inputPath将生成的inputPath文件传入到Wi…...

@Controller层自定义注解拦截request请求校验
一、背景 笔者工作中遇到一个需求,需要开发一个注解,放在controller层的类或者方法上,用以校验请求参数中(不管是url还是body体内,都要检查,有token参数,且符合校验规则就放行)是否传了一个token的参数&am…...

Ceph集群修改主机名
修改主机名 #修改主机名 rootlk02--test:~# hostnamectl set-hostname lk02--test01 #修改hosts rootlk02--test:~# vi /etc/hosts #修改ceph.conf rootlk02--test:~# vi /etc/ceph/ceph.conf rootlk02--test:~# cat /etc/ceph/ceph.conf |grep mon mon host [v2:192.168.3.1…...
玖章算术NineData通过阿里云PolarDB产品生态集成认证
近日,玖章算术旗下NineData 云原生智能数据管理平台 (V1.0)正式通过了阿里云PolarDB PostgreSQL版 (V11)产品集成认证测试,并获得阿里云颁发的产品生态集成认证。 测试结果表明,玖章算术旗下NineData数据管理平台 (V1.0ÿ…...
oracle静默安装runInstaller数据库软件 --参数说明+举例)
(实战)oracle静默安装runInstaller数据库软件 --参数说明+举例
安装数据库软件 su - oracle cd database/ export LANGen_US export LANGen_US.UTF-8 ./runInstaller 进行安装 yum install -y binutils-* libXp* compat-libstdc-33-* elfutils-libelf-* elfutils-libelf-devel-* gcc-* gcc-c-* glibc-* glibc-common-* glibc-devel-* g…...


卡梅德生物技术快报|蛋白的过表达质粒构建与生信分析实验全流程复盘
从事分子生物学实验的科研从业者,在开展功能蛋白研究时,蛋白的过表达质粒构建与诱导表达是必备核心技能。实操过程中,很多人会忽略前期生信分析的重要性,盲目设计引物、构建载体,导致蛋白的过表达失败、蛋白无活性、纯…...

初识递归算法
目录介绍例PythonC原理优缺点分析题目结尾本文由Jzwalliser原创,发布在CSDN平台上,遵循CC 4.0 BY-SA协议。 因此,若需转载/引用本文,请注明作者并附原文链接,且禁止删除/修改本段文字。 违者必究,谢谢配合。…...

从背包UI到聊天框:详解Unity ScrollRect在不同游戏场景下的实战应用与优化
从背包UI到聊天框:Unity ScrollRect全场景实战指南在RPG游戏的背包界面滑动查看装备,在社交系统中翻阅聊天记录,或是横向浏览角色画廊——这些看似不同的交互背后,都依赖同一个核心组件:Unity的ScrollRect。作为UGUI体…...

别再死记硬背F=G+H了!用Unity手搓一个A*寻路,从DFS、BFS到Dijkstra一步步讲透
从零构建A*寻路:用Unity可视化算法演进之路当我在开发第一个2D策略游戏时,遇到了一个经典问题:如何让单位智能地绕过障碍物找到最短路径?像许多初学者一样,我直接跳到了A*算法的实现,却被那个神秘的FGH公式…...
)
CentOS服务器上VNC连接总出问题?这份保姆级排错手册(含端口混乱、服务重启、密码修改)
CentOS服务器VNC连接全流程排错指南:从端口混乱到服务恢复当你正埋头调试一个关键的仿真任务,突然VNC连接断开,所有工作界面瞬间消失——这种场景对使用CentOS服务器的工程师和科研人员来说绝不陌生。VNC作为远程桌面的生命线,一旦…...

物理生物学研究报告【20260015】
文章目录抛球入框实验报告一、实验目的二、实验装置三、实验方法四、实验结果4.1 无弹跳实验(A组)4.2 允许弹跳实验(B组)五、分析与讨论5.1 无弹跳与弹跳的参数差异5.2 恢复系数的影响5.3 误差来源六、结论七、致谢抛球入框实验报…...

饲料颗粒机生产厂家
行业痛点分析:一场关于“磨损”与“成本”的持久战在饲料加工领域,颗粒机设备的稳定性与耐用性,直接决定了生产线的整体效率与运营成本。然而,长期困扰行业的核心痛点之一,是磨盘与压辊的耐磨性问题。根据行业调研数据…...

小学期学习——第二周
一、本周学习视频6-7学习了单电源供电的二阶低通滤波器以及电子计数法,并对仿真进行了改进。二、绘制了PCB原理图学习使用嘉立创EDA,并且绘制了PCB原理图。...
3分钟上手Translumo:免费实时屏幕翻译工具终极指南
3分钟上手Translumo:免费实时屏幕翻译工具终极指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否在游…...