任务13:使用MapReduce对天气数据进行ETL(获取各基站ID)
任务描述
知识点:
- 天气数据进行ETL
重 点:
- 掌握MapReduce程序的运行流程
- 熟练编写MapReduce程序
- 使用MapReduce进行ETL
内 容:
- 编写MapReduce程序
- 编写Shell脚本,获取MapReduce程序的inputPath
- 将生成的inputPath文件传入到Windows环境
- 运行MapReduce程序对天气数据进行ETL处理
任务指导
1. 准备2000-2022年气象数据
(如在任务12中,按照手册已自行处理好2000-2022年的所有气象数据,也可跳过此步骤,使用自己处理好的数据文件即可,但需要在后续步骤中注意数据路径的问题)
先前按照任务12处理了2021-2022年数据,在后续气象预测部分任务需要2000-2022年的数据作为支持,所以现将处理后的(解压后)2000年-2022年的气象数据进行提供,可通过下述的URL下载地址进行下载
数据集路径:
格式:url/dataSet/systemLib/b3084be184684ee18f3b00b048bab0cc.zip,url参见实验窗口右侧菜单“实验资源下载”。
例如:https://staticfile.eec-cn.com/dataSet/systemLib/b3084be184684ee18f3b00b048bab0cc.zip
- 在master机器的/home路径下载数据集
- 解压数据集
- 在/home/china_data目录中包含了2000-2022年,22年间的中国各个基站的气象数据
- 在每个文件夹下均已将气象数据文件解压完成

使用MapReduce对天气数据进行预处理,并在数据文件中添加对应基站ID,并将原来字段间的分隔符改为使用逗号分隔,以便于大Hive中使用该数据集。
2. 使用MapReduce对数据进行ETL
当前在数据集中不包含基站编号字段,每个基站的编号体现在各个文件名的前5位,例如在“450010-99999-2000”文件中包含的是编号为“45001”的基站数据,所以需要将各个基站的编号添加到对应的数据文件中,并且在各个文件中每个字段之间的分隔符也是不一致的,所以也需要对数据进行清理,由于数据量较大,可以考虑使用MapReduce进行数据清理的工作。
- 创建Maven项目:china_etl
- 编写MapReduce程序
- ChinaMapper:读取数据,对数据添加stn(基站ID)字段,并进行格式化处理
- ChinaReducer:对处理后的数据进行输出
- ChinaDriver:MapReduce程序的驱动类
- 在master机器编写Shell脚本获取MapReduce程序的inputPath
- 将生成的inputPath文件传入到Windows环境
- 在Windows运行MapReduce程序
- 程序运行完成,进入master机器查看结果
- 数据格式说明:
| 基站编号 | 年 | 月 | 日 | 时间 | 温度 | 露点温度 | 气压 | 风向 | 风速 | 云量 | 1小时雨量 | 6小时雨量 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 59997 | 2022 | 12 | 31 | 21 | 274 | 250 | 10133 | 70 | 20 | 5 | -9999 | -9999 |
任务实现
1. 准备2000-2022年气象数据
(如在任务12中,按照手册已自行处理好2000-2022年的所有气象数据,也可跳过此步骤,使用自己处理好的数据文件即可,但需要在后续步骤中注意数据路径的问题)
先前按照任务12处理了2021-2022年数据,在后续气象预测部分任务需要2000-2022年的数据作为支持,所以现将处理后的(解压后)2000年-2022年的气象数据进行提供,可通过下述的URL下载地址进行下载
数据集路径:
格式:url/dataSet/systemLib/b3084be184684ee18f3b00b048bab0cc.zip,url参见实验窗口右侧菜单“实验资源下载”。
例如:https://staticfile.eec-cn.com/dataSet/systemLib/b3084be184684ee18f3b00b048bab0cc.zip
- 在master机器的/home路径下载数据集
# cd /home
# wget https://staticfile.eec-cn.com/dataSet/systemLib/b3084be184684ee18f3b00b048bab0cc.zip- 解压数据集
# unzip /home/b3084be184684ee18f3b00b048bab0cc.zip- 在/home/china_data目录中包含了2000-2022年,22年间的中国各个基站的气象数据
- 在每个文件夹下均已将气象数据文件解压完成
- 将下载后的数据集上传至HDFS中
- 将2000-2022年的所有气象数据上传至HDFS的/china目录中
# hadoop fs -mkdir /china
# hadoop fs -put /home/china_data/* /china天气的格式如下:
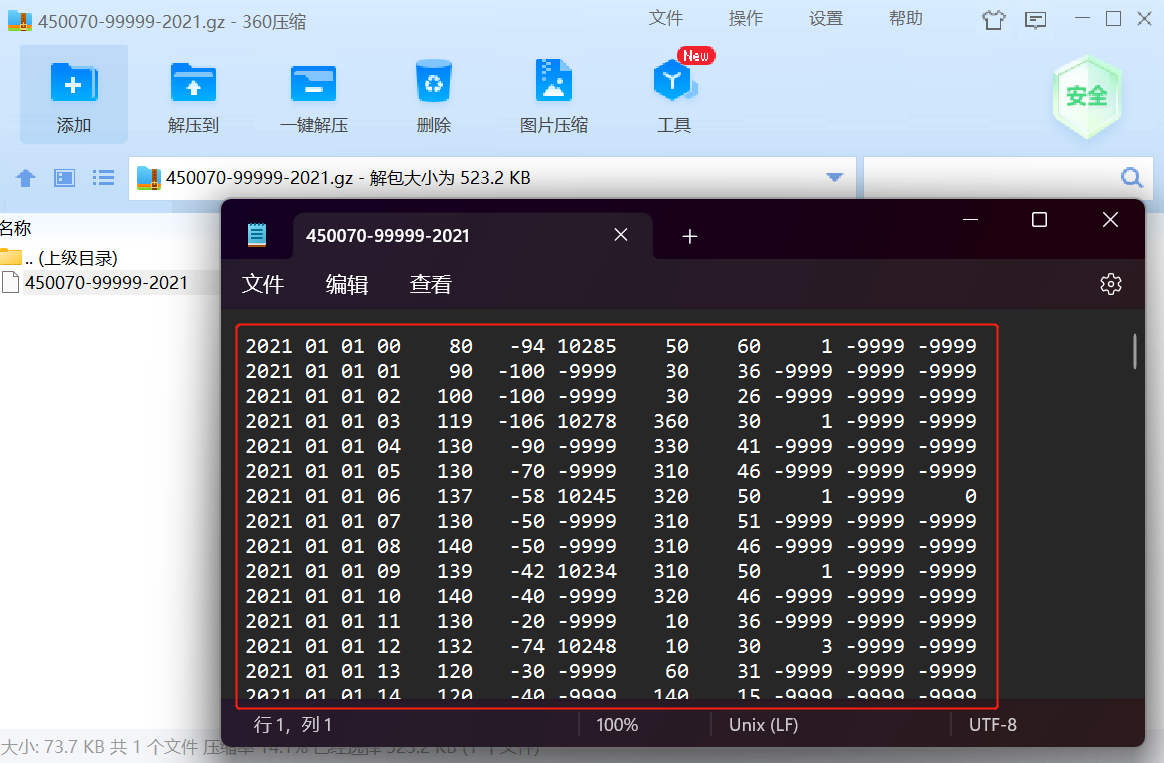
NCDC天气的格式说明:
气象要素包括:气温、气压、露点、风向风速、云量、降水量等。
- 例如:

- 各字段的含义如下:
| 年 | 月 | 日 | 时间 | 温度 | 露点温度 | 气压 | 风向 | 风速 | 云量 | 1小时雨量 | 6小时雨量 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2021 | 01 | 01 | 00 | 80 | -94 | 10285 | 50 | 60 | 1 | -9999 | -9999 |
当前在数据集中不包含基站编号字段,每个基站的编号体现在各个文件名的前5位,例如在“450010-99999-2000”文件中包含的是编号为“45001”的基站数据,所以需要将各个基站的编号添加到对应的数据文件中,并且在各个文件中每个字段之间的分隔符也是不一致的,所以也需要对数据进行清理,由于数据量较大,可以考虑使用MapReduce进行数据清理的工作。
2. 使用MapReduce对数据进行ETL
使用MapReduce对天气数据进行ETL流程如下:
- 打开IDEA,如先前创建过项目,需点击File --> Close Project返回IDEA初始界面

- 点击New Project新建项目

- 创建Maven项目:china_etl
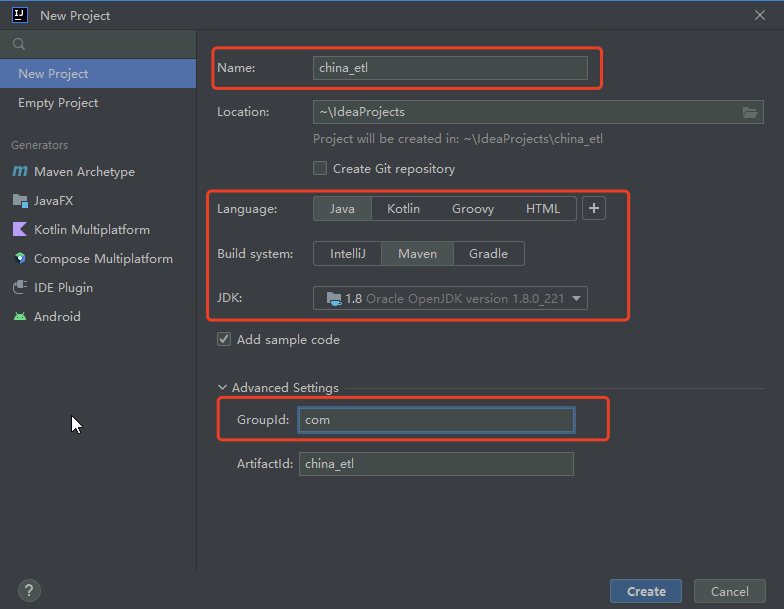
- 打开File --> Settings,按照之前的方式配置Maven
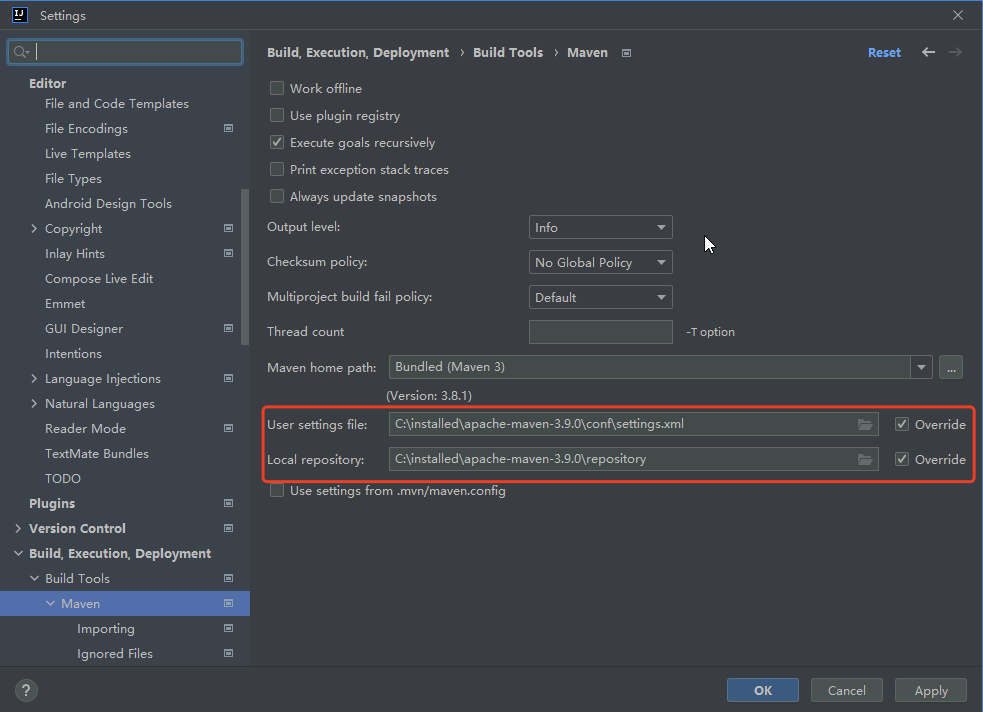
- 修改pom.xml文件,在标识位置填写<dependencies>标签中的内容,下载项目所需依赖
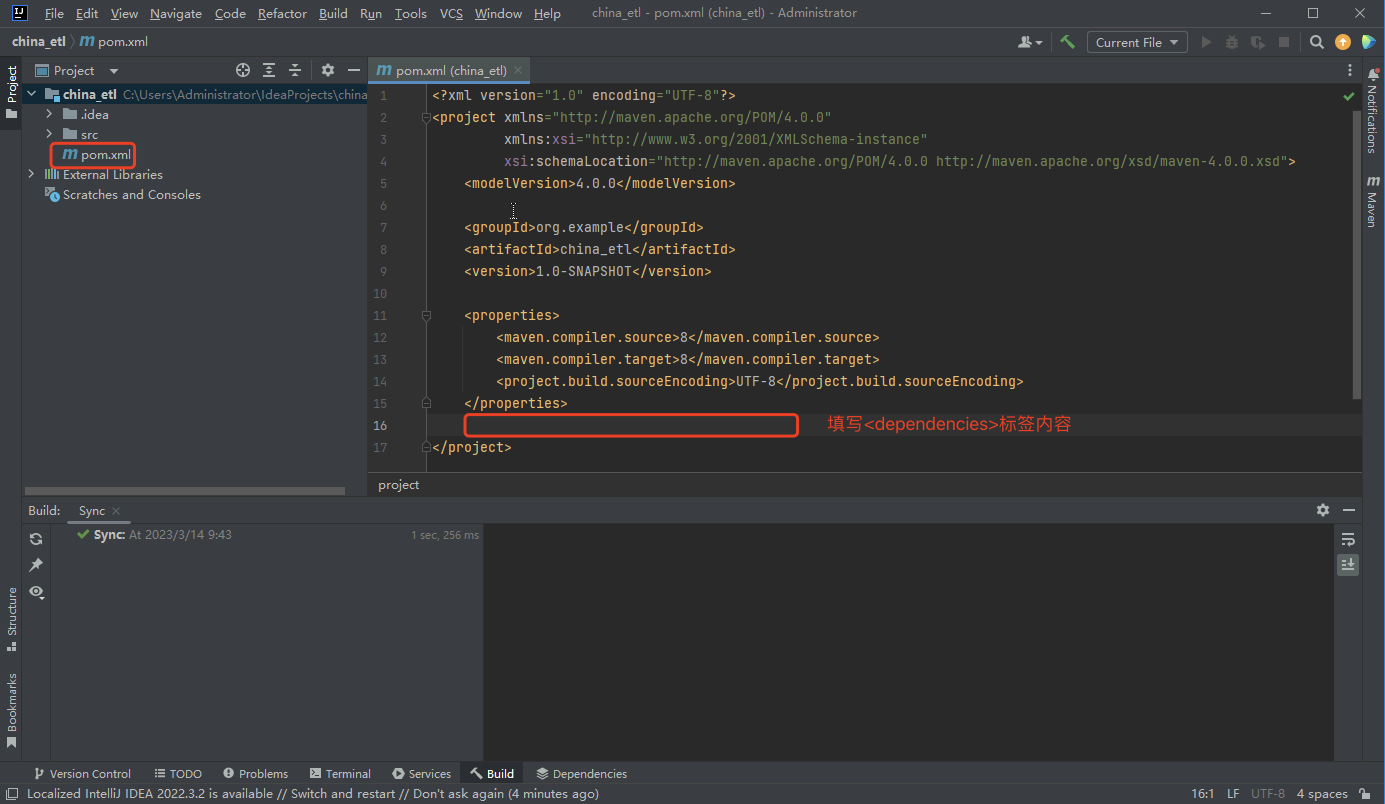
- <dependencies>标签内容如下:
<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.9.2</version> </dependency>
</dependencies>- 依赖下载完成后,将默认生成在src/main/java/com的Main类删除

- 在src/main/java/com包下创建Mapper类:ChinaMapper.java
本次MapReduce任务的主要处理逻辑在Map函数中,在Map中获取当前正在处理的文件信息,通过文件信息获取相应的文件名,然后获取到文件名的前五位,前五位则是每个基站对应的基站编号,然后获取到数据文件中的每条数据并进行分割,分割后根据索引获取所需的数据,最后通过","对数据进行分隔,作为每个字段数据的新分隔符,根据所需重新将数据进行拼接
package com;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileSplit;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class ChinaMapper extends Mapper<LongWritable, Text,Text, NullWritable> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 获取当前map正在处理的文件信息InputSplit inputSplit = (InputSplit) context.getInputSplit();
// 获取文件名,例如:当前获取到“450010-99999-2000”String fileName = inputSplit.toString().split("/")[5];NullWritable val = NullWritable.get();
// 取出基站编号,例如:“45001”String stn = fileName.substring(0,5);
// System.out.println(stn);/** 获取所需字段year=[] #年month=[] #月day=[] #日hour=[] #时间temp=[] #温度dew_point_temp=[] #露点温度pressure=[] #气压wind_direction=[] #风向wind_speed=[] #风速clouds=[] #云量precipitation_1=[] #1小时降水量precipitation_6=[] #6小时降水量
*/
// 获取输入的每一条数据String values = value.toString();
// 通过分隔符进行分割String[] lines = values.split("\\s+");String year = lines[0];String month = lines[1];String day = lines[2];String hour = lines[3];String temp = lines[4];String dew_point_temp = lines[5];String pressure = lines[6];String wind_direction = lines[7];String wind_speed = lines[8];String cloud=lines[9];String precipitation_1 = lines[10];String precipitation_6 = lines[11];
// 使用“,”对每条数据进行拼接,每条数据的分隔符设置为","String line = stn+","+year+","+month+","+day+","+hour+","+temp+","+dew_point_temp+","+pressure+","+wind_direction+","+wind_speed+","+cloud+","+precipitation_1+","+precipitation_6;System.out.println(line);
// 每条数据作为key进行输出context.write(new Text(line),val);}
}- 在src/main/java/com包下创建Reducer类:ChinaReducer.java
package com;import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class ChinaReducer extends Reducer<Text,NullWritable,Text,NullWritable> {@Overrideprotected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {NullWritable val = NullWritable.get();// 获取keyText outLine = key;context.write(outLine,val);}
}- 在src/main/java/com包下创建Driver类: ChinaDriver.java
package com;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;public class ChinaDriver {public static void main(String[] args) {Configuration conf = new Configuration();Job job = null;try {// 读取filename文件内容获取inputpathBufferedReader br = new BufferedReader(new FileReader("C:\\installed\\filename.txt"));String line = null;ArrayList list = new ArrayList();while((line=br.readLine())!=null){list.add(line);}Path[] inputPath = new Path[list.size()];for(int i = 0;i< inputPath.length;i++){inputPath[i] = new Path(list.get(i).toString());System.out.println(inputPath[i]);}job = Job.getInstance(conf);job.setJarByClass(ChinaDriver.class);job.setJobName("ChinaDriver");
// 设置Mapper类job.setMapperClass(ChinaMapper.class);
// 设置Reducer类job.setReducerClass(ChinaReducer.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(NullWritable.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);
// 设置输入路径FileInputFormat.setInputPaths(job, inputPath);
// 设置输出路径FileOutputFormat.setOutputPath(job, new Path("hdfs://master:9000/china_all/"));System.exit(job.waitForCompletion(true) ? 0 : 1);} catch (IOException e) {e.printStackTrace();} catch (ClassNotFoundException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}}
}- 编写完成后,进入master机器
由于本次MapRedcue任务需要处理2000-2022年的数据,每个年份的数据都保存在一个以年份命名的文件夹下,所以MapReduce需要读取22个文件夹下的所有数据,因此在运行MapReduce程序前,需要编写一个Shell脚本以生成MapReduce的inputPath文件,在该文件中包含所有需要处理的数据路径(该操作类似任务12中的generate_input_list.sh脚本)
- 在master机器的/home/shell目录下,编写getHDFSfile.sh脚本,以生成MapReduce的inputPath文件
# vim /home/shell/getHDFSfile.sh- 脚本内容如下:
#/bin/bash
rm -rf /home/filename.txt
# file = echo `hdfs dfs -ls /china | awk -F ' ' '{print $8}'`
for line in `hdfs dfs -ls /china | awk -F ' ' '{print $8}'`
dofilename="hdfs://master:9000$line"echo -e "$filename" >> /home/filename.txt
done- 为Shell脚本赋予执行权限
# chmod u+x /home/shell/getHDFSfile.sh- 运行Shell脚本,生成inputPath
# /home/shell/getHDFSfile.sh- 脚本运行完成,在/home目录下会生成一个filename.txt文件,在文件中包含所有需要处理的路径信息
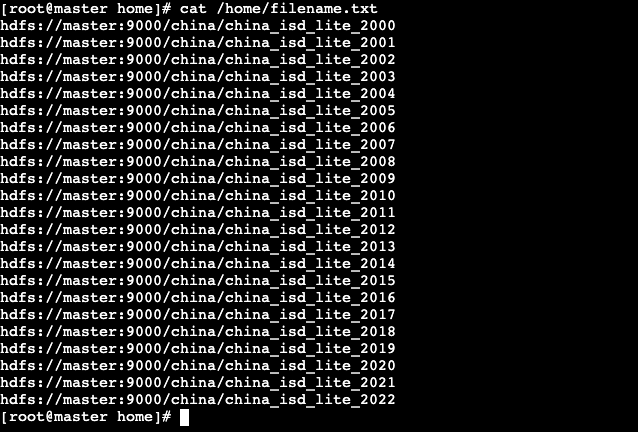
- 查看/home/filename.txt文件
# cat /home/filename.txt
- filename.txt文件生成后,将其通过filezilla工具传入到Windows环境的C:\installed目录
- 进入Windows环境,打开filezilla工具,filezilla需要配置master的主机名(IP地址)、用户名、密码以及端口;
- 可通过右侧工具栏,获取master机器的相关信息并将其进行填入
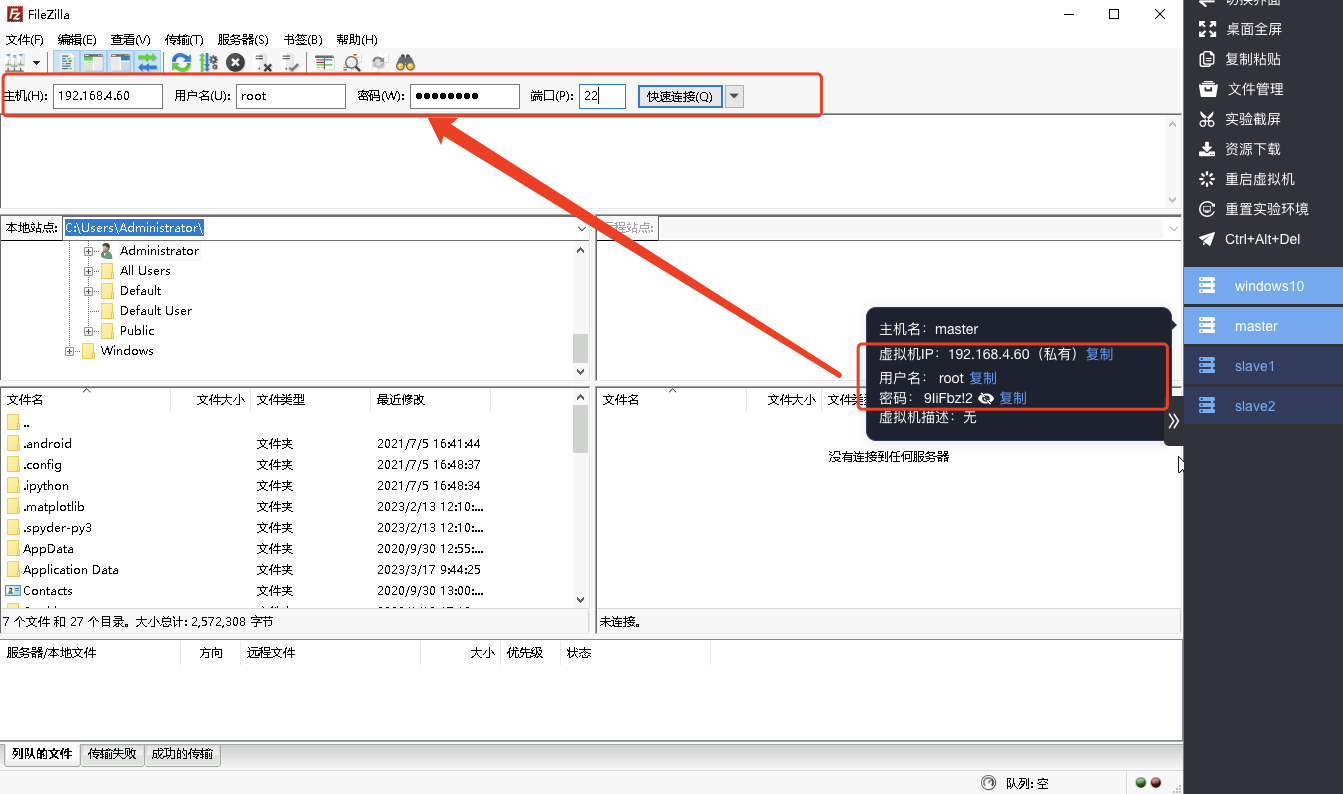
- 配置完成后,点击快速连接master机器
- 在左侧拦中是本地Windows环境的文件管理器,右侧是连接的远程Linux(master)机器文件管理器
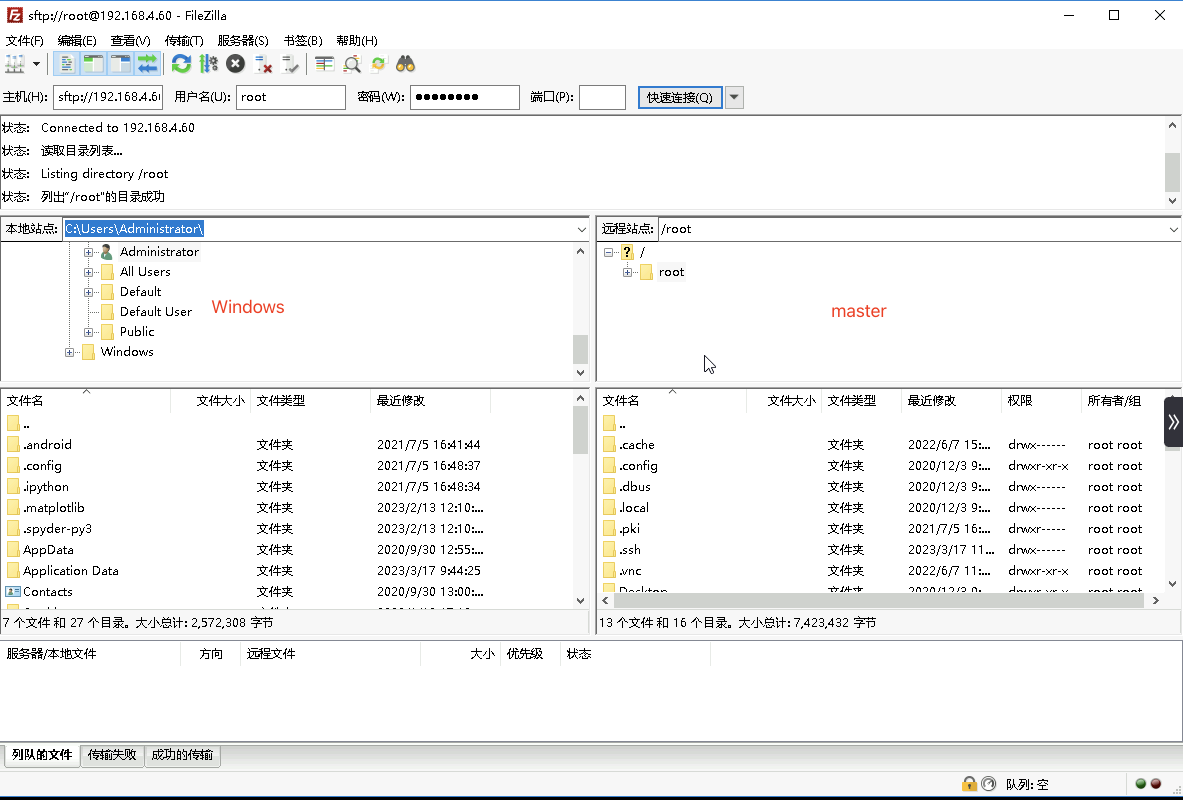
- 在Windows文件管理器,进入C:\installed目录,在右侧master机器中进入/home目录,找到生成的filename.txt文件,将其从master机器中拖拽到Windows机器

- 右键ChinaDriver,点击Run 'ChinaDriver.main()'运行MapReduce程序
- 控制台显示数据
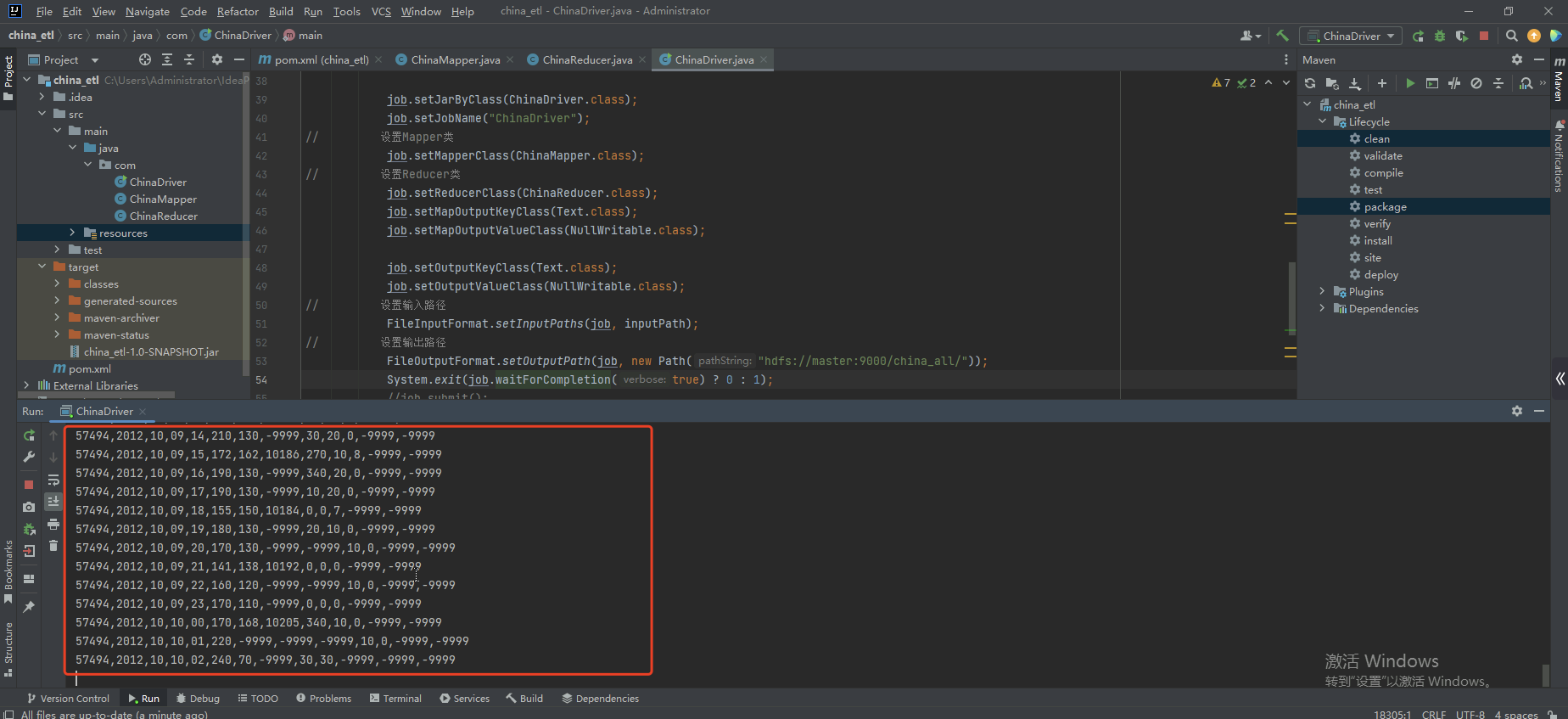
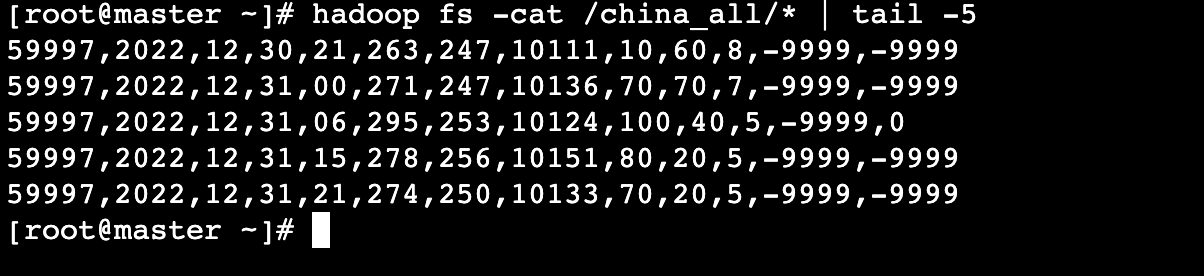
进入master机器,查看运行结果最后5行数据:
# hadoop fs -cat /china_all/* | tail -5
数据格式说明:
| 基站编号 | 年 | 月 | 日 | 时间 | 温度 | 露点温度 | 气压 | 风向 | 风速 | 云量 | 1小时雨量 | 6小时雨量 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 59997 | 2022 | 12 | 31 | 21 | 274 | 250 | 10133 | 70 | 20 | 5 | -9999 | -9999 |
上一个任务下一个任务
相关文章:
任务13:使用MapReduce对天气数据进行ETL(获取各基站ID)
任务描述 知识点: 天气数据进行ETL 重 点: 掌握MapReduce程序的运行流程熟练编写MapReduce程序使用MapReduce进行ETL 内 容: 编写MapReduce程序编写Shell脚本,获取MapReduce程序的inputPath将生成的inputPath文件传入到Wi…...

@Controller层自定义注解拦截request请求校验
一、背景 笔者工作中遇到一个需求,需要开发一个注解,放在controller层的类或者方法上,用以校验请求参数中(不管是url还是body体内,都要检查,有token参数,且符合校验规则就放行)是否传了一个token的参数&am…...

Ceph集群修改主机名
修改主机名 #修改主机名 rootlk02--test:~# hostnamectl set-hostname lk02--test01 #修改hosts rootlk02--test:~# vi /etc/hosts #修改ceph.conf rootlk02--test:~# vi /etc/ceph/ceph.conf rootlk02--test:~# cat /etc/ceph/ceph.conf |grep mon mon host [v2:192.168.3.1…...
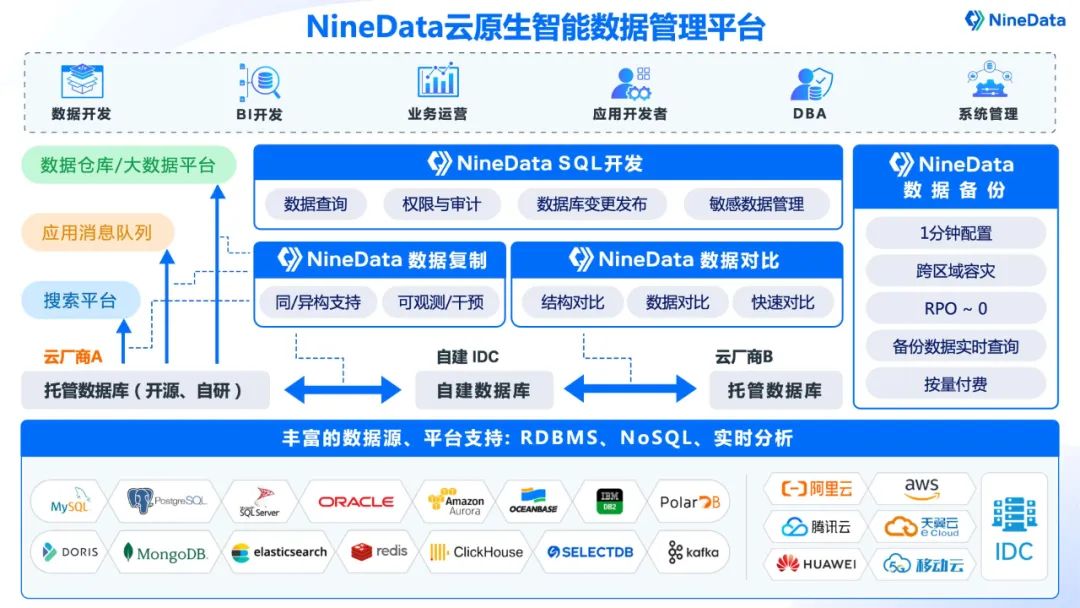
玖章算术NineData通过阿里云PolarDB产品生态集成认证
近日,玖章算术旗下NineData 云原生智能数据管理平台 (V1.0)正式通过了阿里云PolarDB PostgreSQL版 (V11)产品集成认证测试,并获得阿里云颁发的产品生态集成认证。 测试结果表明,玖章算术旗下NineData数据管理平台 (V1.0ÿ…...
oracle静默安装runInstaller数据库软件 --参数说明+举例)
(实战)oracle静默安装runInstaller数据库软件 --参数说明+举例
安装数据库软件 su - oracle cd database/ export LANGen_US export LANGen_US.UTF-8 ./runInstaller 进行安装 yum install -y binutils-* libXp* compat-libstdc-33-* elfutils-libelf-* elfutils-libelf-devel-* gcc-* gcc-c-* glibc-* glibc-common-* glibc-devel-* g…...
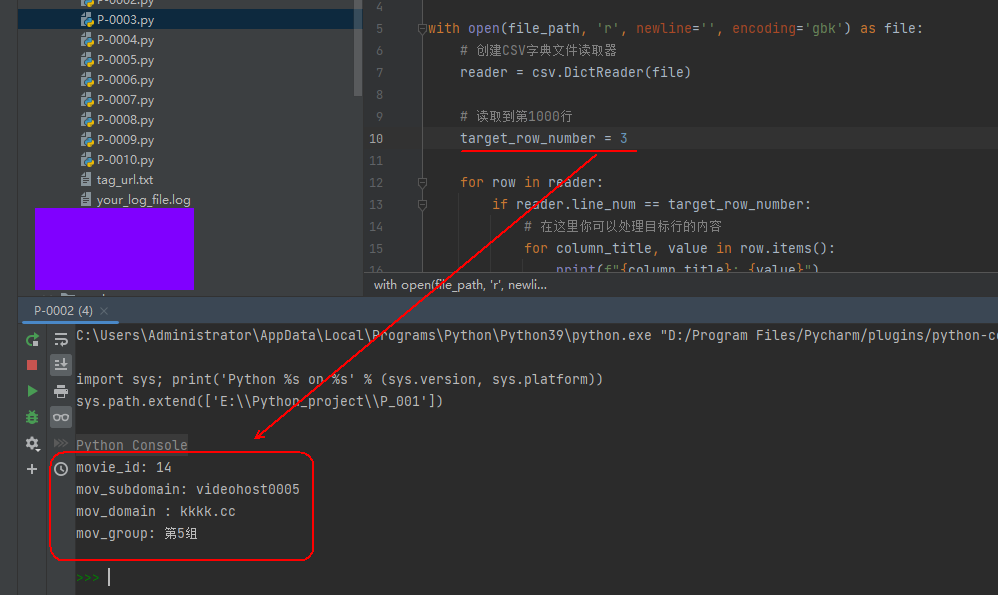
利用Python的csv(CSV)库读取csv文件并取出某个单元格的内容的学习过程
csv库在python3中是自带的。 利用它可以方便的进行csv文件内容的读取。 注意:要以gbk的编码形式打开,因为WPS的csv文件默认是gbk编码,而不是utf-8。 01-读取表头并在打印每一行内容时一并输出表头 表头为第1行,现在要读取并打…...
)
Http三种常见状态码的区别(401、403、500)
一、解释 401 Unauthorized(未经授权):表示请求需要进行身份验证,但客户端未提供有效的身份验证凭据。通常,当用户尝试访问需要身份验证的资源时,服务器会返回401状态码,以提示客户端提供有效的…...

分布式锁实现用户锁
用户锁的作用 秒杀、支付等场景,用户频繁点击按钮,会造成同一时刻调用多次接口【第一次请求接口还没响应数据,用户又进行了第二次请求】,造成数据异常和网络拥堵。添加用户锁,在用户第二次点击按钮时,拦击用…...
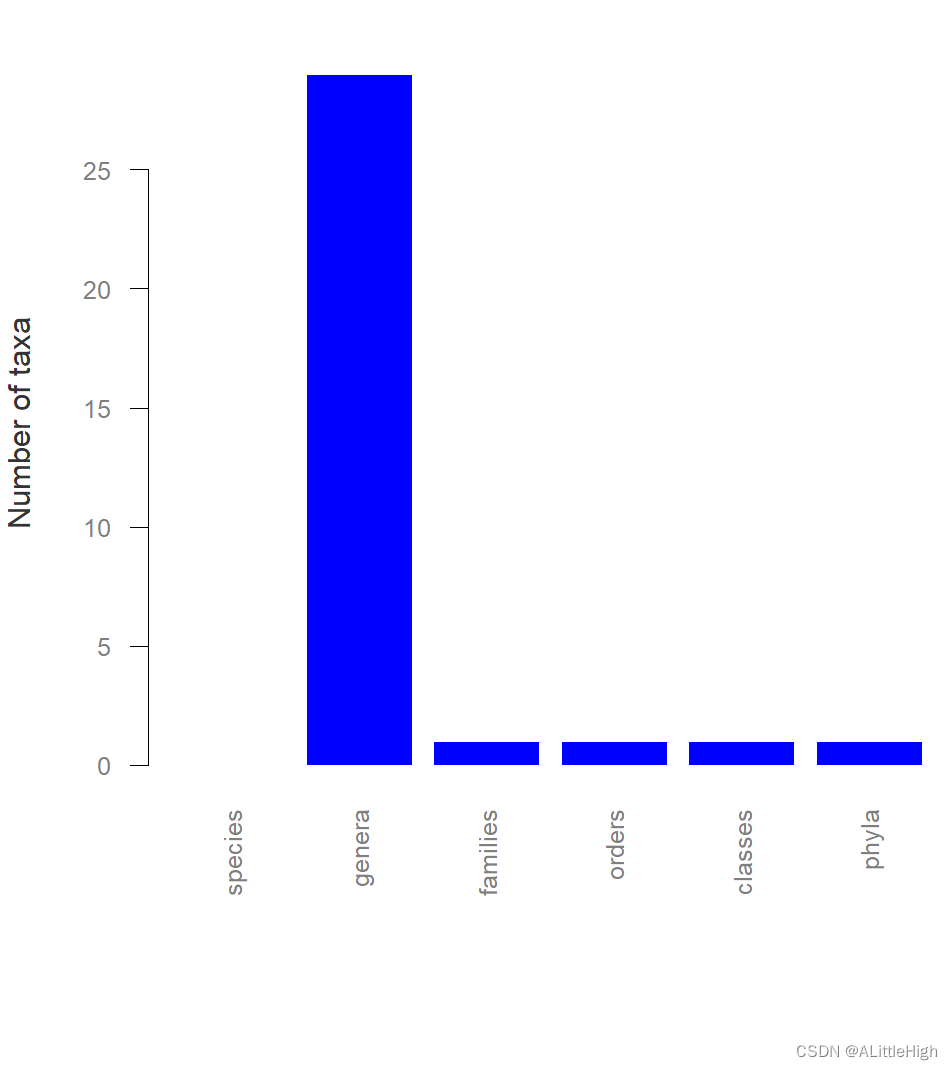
R语言【paleobioDB】——pbdb_subtaxa():统计指定类群下的子类群数量
Package paleobioDB version 0.7.0 paleobioDB 包在2020年已经停止更新,该包依赖PBDB v1 API。 可以选择在Index of /src/contrib/Archive/paleobioDB (r-project.org)下载安装包后,执行本地安装。 Usage pbdb_subtaxa (data, do.plot, col) Arguments…...
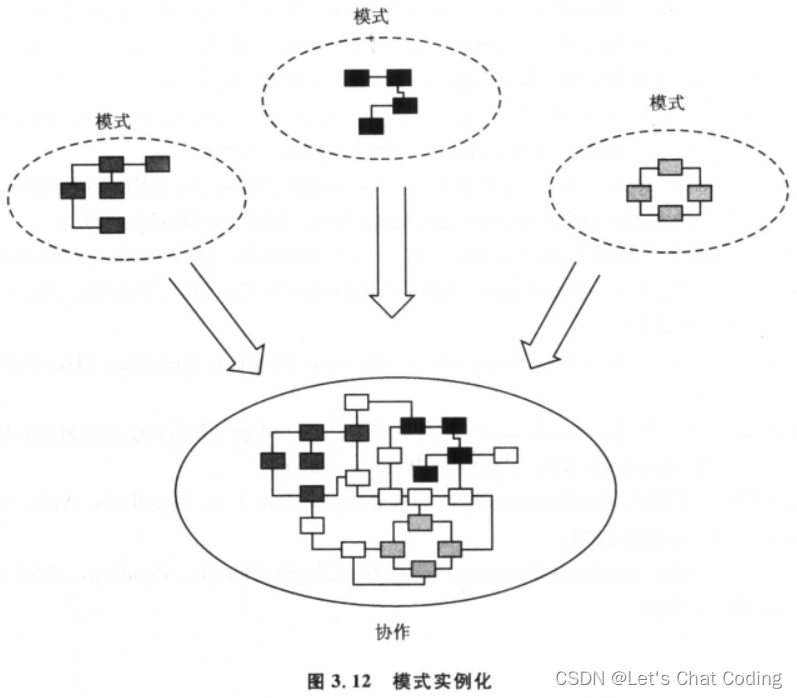
3.4 在开发中使用设计模式
现在,我们应该对设计模式的本质以及它们的组织方式有了初步的认识,并且能够理解ROPES过程在整体设计中的作用。通过之前章节对“体系结构”及其五个视图的探讨,我们打下了坚实的基础。初步了解了UML的基本构建模块后,我们现在可以…...
docker搭建SSH镜像、systemctl镜像、nginx镜像、tomcat镜像
目录 一、SSH镜像 二、systemctl镜像 三、nginx镜像 四、tomcat镜像 五、mysql镜像 一、SSH镜像 1、开启ip转发功能 vim /etc/sysctl.conf net.ipv4.ip_forward 1sysctl -psystemctl restart docker 2、 cd /opt/sshd/vim Dockerfile 3、生成镜像 4、启动容器并修改ro…...

[linux] git clone一个repo,包括它的子模块submodule
How do I "git clone" a repo, including its submodules? - Stack Overflow git clone git://github.com/foo/bar.git cd bar git submodule update --init --recursive...
K8S中使用helm安装MinIO
注意事项 使用helm部署MinIO分为两部分 helm部署MinIO operator,用来管理tenant(K8S集群中只能部署一个)helm部署MinIO tenant,真实的MinIO Cluster(K8S集群中可以部署多个) 使用helm部署到K8S集群&…...

寒假刷题第六天
PTA甲级 1030 Travel Plan 迪杰斯特拉 #include<iostream> #include<vector> #include<cstring>using namespace std;const int N 510 , INF 0x3f3f3f3f3f; int n , m , s , d; int g[N][N] , cost[N][N] , dist[N] , min_cost[N]; bool st[N]; int pat…...
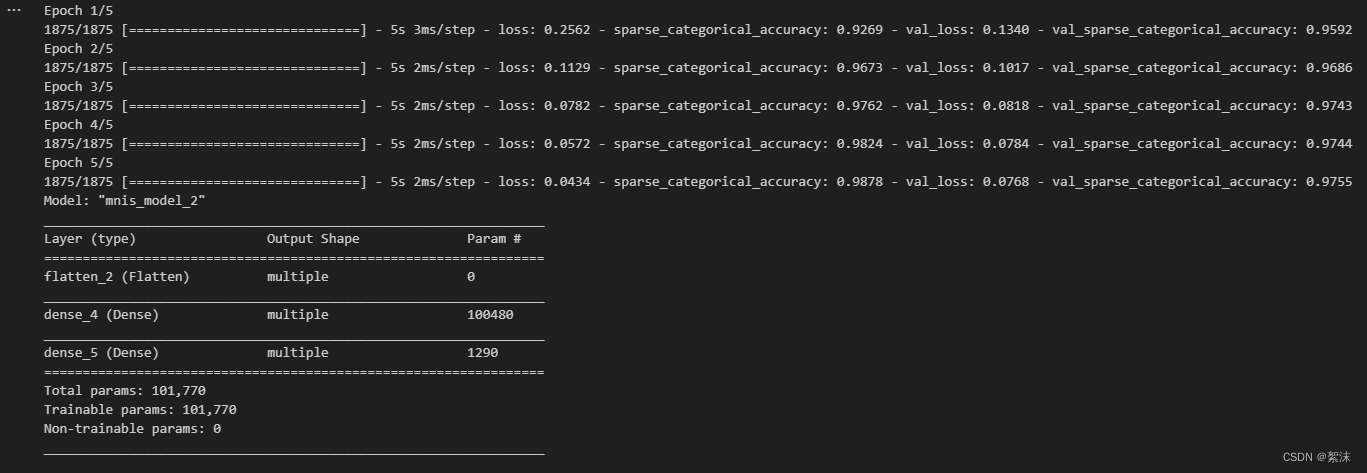
深度学习笔记(七)——基于Iris/MNIST数据集构建基础的分类网络算法实战
文中程序以Tensorflow-2.6.0为例 部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。 截图和程序部分引用自北京大学机器学习公开课 认识网络的构建结构 在神经网络的构建过程中,都避不开以下几个步骤: 导入网络和依…...

Windows启动MongoDB服务报错(错误 1053:服务没有及时响应启动或控制请求)
问题描述:修改MongoDB服务bin目录下的mongod.cfg,然后在任务管理器找到MongoDB服务-->右键-->点击【开始】,启动失败无提示: 右键点击任务管理器的MongoDB服务-->点击【打开服务】,跳转到服务页面-->找到M…...
定制CPUSET解决方案-system修改及编译部分调整)
Android Framework 常见解决方案(25-2)定制CPUSET解决方案-system修改及编译部分调整
1 原理说明 这个方案有如下基本需求: 构建自定义CPUSET,/dev/cpuset中包含一个全新的cpuset分组。且可以通过set_cpuset_policy和set_sched_policy接口可以设置自定义CPUSET。开机启动后可以通过zygote判定来对特定的应用进程设置CPUSET,并…...
OpenAI推出GPT商店和ChatGPT Team服务
🦉 AI新闻 🚀 OpenAI推出GPT商店和ChatGPT Team服务 摘要:OpenAI正式推出了其GPT商店和ChatGPT Team服务。用户已经创建了超过300万个ChatGPT自定义版本,并分享给其他人使用。GPT商店集结了用户为各种任务创建的定制化ChatGPT&a…...
3D建模素材分层渲染怎么操作?
在3D建模素材分层渲染过程中,需要将场景中的元素分到不同的层里,然后分别进行渲染。以下是一个简单的方法: 1、打开要渲染的3D建模素材。 2、在场景中选择要分层的元素,然后在软件的图层面板中新建图层,将元素拖拽到新…...
的实现)
SAICP(模拟退火迭代最近点)的实现
SAICP(模拟退火迭代最近点)的实现 注: 本系列所有文章在github开源, 也是我个人的学习笔记, 欢迎大家去star以及fork, 感谢! 仓库地址: pointcloud-processing-visualization 总结一下上周的学习情况 ICP会存在局部最小值的问题, 这个问题可能即使是没有实际遇到过, 也或多…...

融合UFF与机器学习势:高通量筛选MOF吸附剂的高效精准方案
1. 项目概述:当经典力场遇上机器学习势,如何实现MOF吸附剂的精准高效筛选?在材料研发的前沿,尤其是像金属-有机框架(MOFs)这样拥有近乎无限结构可能性的领域,我们常常面临一个“大海捞针”的困境…...

国密滑块登录实战:SM2+SM4密码链路全解析
1. 这不是“加个密”那么简单:滑块登录里藏着的国密链路真相你有没有试过,在某个政务类App或银行类Web端拖动滑块完成登录后,页面瞬间跳转,但控制台Network面板里却找不到任何明文密码字段?甚至抓包发现,提…...
)
别再手动敲命令了!用FinalShell一键连接Ubuntu虚拟机(附SSH服务完整配置流程)
FinalShell全自动连接Ubuntu虚拟机的终极指南每次启动Ubuntu虚拟机都要重复输入那十几条命令?还在为SSH连接失败而抓狂?作为一款国产SSH工具,FinalShell的图形化操作和内置文件管理功能确实能极大提升开发效率。但要让整个连接过程真正实现&q…...

GetSubtitles终极指南:5分钟掌握智能字幕下载,高效解决观影难题
GetSubtitles终极指南:5分钟掌握智能字幕下载,高效解决观影难题 【免费下载链接】GetSubtitles 一步下载匹配字幕 项目地址: https://gitcode.com/gh_mirrors/ge/GetSubtitles 还在为找不到匹配的字幕而烦恼吗?GetSubtitles是一款强大…...

胖瘦 AP 网络仿真实验
一.实验概述实验名称:胖瘦 AP 网络仿真实验实验目的:掌握胖 AP(FAT AP)与瘦 AP(FIT AP)两种无线组网模式的工作原理与配置方法,理解两者的核心差异实现指定网络连通性要求:瘦 AP 侧静…...
)
避坑指南:用SARIMA做时间序列预测时,这5个参数调优错误千万别犯(Python实战)
SARIMA模型调优实战:避开时间序列预测中的五大陷阱引言在数据分析领域,时间序列预测一直是个既迷人又充满挑战的课题。每当我看到那些起伏的曲线,总能感受到数据背后隐藏的故事和规律。SARIMA模型作为时间序列分析的重要工具,因其…...
)
OpenCV实战:用Python从零实现Canny边缘检测(含完整代码与调参技巧)
OpenCV实战:用Python从零实现Canny边缘检测(含完整代码与调参技巧)计算机视觉领域中,边缘检测是图像分析的基础步骤之一。1986年由John F. Canny提出的Canny边缘检测算法,至今仍是效果最佳的边缘检测方法之一。本文将带…...

深度学习篇---NVIDIA DeepStream
NVIDIA DeepStream 是一个功能强大的流媒体分析工具包,专为基于 AI 的多传感器处理、视频、音频和图像理解而设计。你可以把它想象成一个“视觉 AI 应用的乐高工厂”,它把视频解码、AI 推理、目标追踪这些复杂的“零件”,巧妙地组合成一条高效…...
)
2026年亲测一键生成论文工具指南(高效定稿版)
为解决学术写作中效率与合规两大核心痛点,本文精选8款高适配性AI论文写作工具(按综合优先级排序),围绕中文学术规范适配、真实参考文献生成、格式标准化、高性价比四大核心维度筛选,同时配套分场景精准选型方案与学术合…...
:为什么你的YOLO项目越用越废?对比TVA智能体四大核心差距)
TVA视觉智能体专栏(二):为什么你的YOLO项目越用越废?对比TVA智能体四大核心差距
摘要:常规YOLO模型只能完成目标识别,无推理、无决策、无迭代能力,面对光照波动、工件偏移、杂点干扰极易误漏检。本文从环境适配、缺陷推理、迭代能力、工程落地四个维度,精准对比传统深度学习与TVA智能体的本质差距,破…...