深度学习笔记(四)——使用TF2构建基础网络的常用函数+简单ML分类实现
文中程序以Tensorflow-2.6.0为例
部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。
截图和程序部分引用自北京大学机器学习公开课
TF2基础常用函数
1、张量处理类
强制数据类型转换:
a1 = tf.constant([1,2,3], dtype=tf.float64)
print(a1)
a2 = tf.cast(a1, tf.int64) # 强制数据类型转换
print(a2)
查找数据中的最小值和最大值:
print(tf.reduce_min(a2), tf.reduce_max(a2))
上一行例子中是对整个张量查找,也按照一定的方向查找,只按照行或只按照列,这由axis变量决定。通常axis=0代表按列查找,axis=1代表按行查找
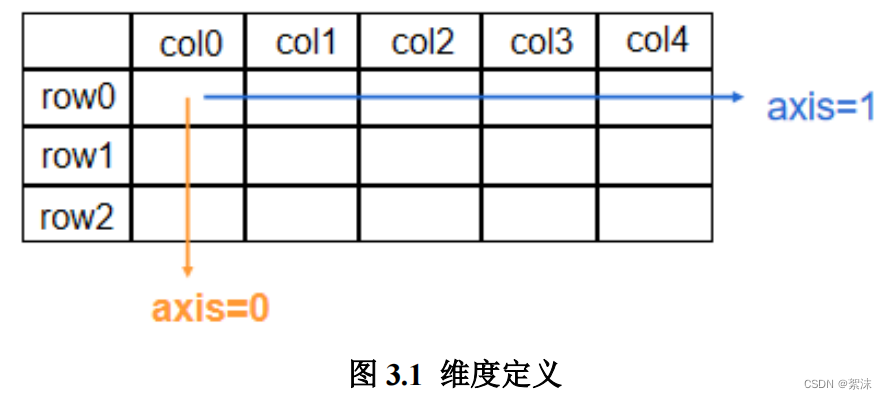
a1 = tf.constant([[1,2,3],[2,3,4]])
print(a1)
print(tf.reduce_max(a1, axis=0)) # 按照列查找最大的行
print(tf.reduce_sum(a1,axis=1)) # 按照行计算各列的和
常见的张量检索类函数在tf.reduce_xxx可以查看
张量中数据的索引,可以按照行,或者按照列索引一个张量数据中的最大值和最小值
test = np.array([[1, 2, 3],[2, 3, 4],[5, 6, 7], [7, 8, 2]])
print(test)
print(tf.argmax(test, axis=0)) # 按列查找,找到每一列的最大值序列号
print(tf.argmax(test, axis=1)) # 按行查找,找到每一行的最大值序列号
随机数生成,最常用的随机数生成是正态分布和均匀分布,有时候后我们期望生成的随机数在0到1之间,归一化的数据有利于网络的快速收敛。除了上一篇博客深度学习笔记(三) 中提及的tf中的随机数张量生成,也可以便捷的使用numpy(后文使用np表示)提供的随机数生成器,同时补充一点,大多数区间范围性质的函数,输入的区间都是前闭后开的,这点在tf np skl 甚至其他C++库中都是成立的。
# 生成[0,1)内的随机数
rdm = np.random.RandomState(seed=1) # 定义随机数生成器rdm,使用随机数种子seed=1
usr_random1 = rdm.rand() # 无输入维度时返回一个常量
usr_random2 = rdm.rand(2, 3) # 返回2行3列的随机数矩阵
print("usr_random1= {} \r\n usr_random2= {}".format(usr_random1, usr_random2))
下面继续归纳几个np中常用的数组处理函数。这几个np函数只做简单说明,具体用法可以用到时再深度查阅资料
数组垂直叠加
# 数组垂直叠加
a1 = np.array([1, 2, 3])
a2 = np.array([4, 5, 6])
b = np.vstack((a1, a2))
print(b)
根据多组范围和步长,生成多维数组,每组的起始结束和步长可以不同,最终输出的列数会以最长的那组为准,行数等于总的组数:
# np.mgrid[起始值:结束值:步长,起始值:结束值:步长, ...... ]
a1, a2 = np.mgrid[1:3:1, 3:6:0.5]
print(a1)
print(a2)
多维数组拉伸为一个维度,并且将多个数组对齐后一 一配对:
# a1 a2 续上一段代码
b = np.c_[np.ravel(a1), np.ravel(a2)] # a1.ravel()执行二维变一维拉伸,np.c_进行组合操作
print(b)
2、数学运算类
四则运算类:(注意:只有维度相同的数据才可以做四则运算,运算均是对应位置元素进行计算,同时tf中,除非指定,默认生成的张量数据时类型为int32或float32)
a1 = tf.constant([[1,2,3],[1,2,3]])
a2 = tf.constant([[2,3,4],[2,3,4]])
print(tf.add(a1, a2)) # 加
print(tf.subtract(a1, a2)) # 减
print(tf.multiply(a1, a2)) # 乘
print(tf.divide(a1, a1)) # 除
平方与开根号:(这里的计算同样是对应位置元素进行计算)
a1 = tf.fill([1,3], 3.) # 这里的指定值为3. 小数点是为了生成float32类型数据
print(a1)
print(tf.pow(a1, 3)) # 开三次方根,第二个参数就是开根的次数
print(tf.square(a1)) # 平方
print(tf.square(a1)) # 开方
张量的叉乘(向量积):
a = tf.ones([3, 2]) # 3行2列
b = tf.fill([2, 3], 3.) # 2行3列
print(tf.matmul(a, b)) # 矩阵叉乘得6行6列,叉乘的两个矩阵,前者的列数必须和后者的行数相等
3、训练处理类
标记训练参数,网络训练的过程实质上最重要的就是更新网络中的参数,所以需要告知网络中哪一个参数是可以被跟新的,这样tensorflow框架会自动的在网络反向传播的过程中记录每一层的梯度信息,便于处理。
# tf.Variable(初始值) 函数用于标记可变参数
tf.Variable(tf.random.normal([2,2],mean=0,stddev=1))
标签/特征数据匹配,训练之前,预先准备的特征数据和标签数据往往是区分开的,所以需要将他们一 一对应上。将输入数据的特征和标签对应匹配,构建出新的用于训练的变量:
# data = tf.data.Dataset.from_tensor_slices((特征数据, 标签数据)) 可以直接输入numpy或者tensor格式的数据
features = tf.constant([12, 15, 20, 11]) # 特征数据
labels = tf.constant([0, 1, 1, 0]) # 标签
dataset = tf.data.Dataset.from_tensor_slices((features, labels)) # 对应结合
for element in dataset:print(element) # 输出
在上面的程序中from_tensor_slices()函数要求两个数据的第一个维度的大小必须相同即可,所以第一行的特征数据也可以改为:
features = tf.constant([[12,13], [15,16], [20,21], [10,11]]) # 第一个维度任然是4
记录梯度,以及自动微分,在训练的过程中自动跟新参数是一个循环加反向传播的过程,反向传播时,我们需要知道每个网络层中损失函数的梯度,在tf中可以使用上下文记录器自动在迭代过程中记录每个层的梯度信息。这主要由两个函数组成tf.GradientTape() 函数起到上下文记录的作用,用于记录层信息,gradient()函数用于求导即求梯度
with tf.GradientTape() as tape: # 记录下两行的层信息w = tf.Variable(tf.constant(3.0)) # 标记可变参数loss = tf.pow(w, 2) # 设置损失函数类型
grad = tape.gradient(loss, w) # 损失函数对w求导
print(grad)
在上面的代码中tf.pow(w, 2)表示损失函数为 l o s s = w 2 loss = w^2 loss=w2 梯度求导后得到 ∂ w 2 ∂ w = 2 w \frac{\partial w^2}{\partial w} = 2w ∂w∂w2=2w 由于初始的参数w为3.0,求导后结果为6.0,程序结果grad为6。注意此处使用的with as结构中必须申明被导的变量,这样才能正常生效记录数据。
枚举数据,为了遍历数据并逐个处理,使用python中内置的enumerate(列表名)进行数据的枚举,通常配合for使用。
# 枚举列表
data = ['one', 'two', 'three']
for i, element in enumerate(data): # 返回的第一个是序列号,第二个是内容print(i, element)
条件循环,在tf训练输出时,我们计算得到的结果有时需要和一个标准数据进行匹配判断并根据判断结果输出数据。可以实现类似于C语言中的循环+三元操作符的效果。tf.where函数的传参依次是条件语句,真值返回,假值返回。
a = tf.constant([1, 2, 3, 4, 5])
b = tf.constant([0, 1, 3, 4, 5])
c = tf.where(tf.greater(a, b), a, b) # 如果条件为真返回第一个值,条件假返回第二个值
print(c)
上面的代码中配合tf.greater函数来比较大小,整行函数将会依次遍历a和b中的元素,当a>b为真时返回a,否则返回b
独热编码,在分类的问题中我们还需要了解独热码的概念,通常使用独热码作为标签数据,在被标记的类别中1表示是,0表示非,可以通俗理解为:有几类被分类数据独热码就有几个,每一类数据对应一个的独热码,类似译码器选址原理。
举例,有3个类
那么第一类的独热码是: 1 0 0
第2类的独热码是: 0 1 0
第3类的独热码是: 0 0 1
在tf中转化独热码:
classes = 4 # 标签数
labels = tf.constant([1, 0, 6 ,3]) # 输入标签数据
output = tf.one_hot(labels, depth=classes) # 独热码转换,第一个变量为输入的标签数据,第二个为类别数
print(output)
上面使用了tf.one_hot()函数用来转化独热码,值得注意的是输入的数据会自动的从小到大排序后再转化对应的独热码。所以上面的程序输出了
tf.Tensor(
[[0. 1. 0. 0.] # 对应1[1. 0. 0. 0.] # 对应0[0. 0. 0. 0.] # 对应6[0. 0. 0. 1.]], # 对应3shape=(4, 4), dtype=float32)
softmax()函数,在网络输出的结果中,如果直接按照最终输出的值判断类型结果往往比较抽象。比如网络最终会输出一个矩阵[2.52, -3.1, 5.62],那么如何确定这个矩阵是对应哪一个类别。这里我们需要通过归一化和概率来判断,假设这个输出的三列矩阵分别对应三个类别的得分数值,那我们可以将三个值相加求和再分别除以各自来得到每个数的百分比占比。当然在机器学习中softmax()也是类似这样做的,不过为了避免负数和特殊0值以及数据的连续性,引入指数函数辅助计算:
S o f t m a x ( y i ) = e y i ∑ j = 0 n e y i \mathit{Softmax(y_{i} )=\frac{e^{y_{i} } }{ {\textstyle \sum_{j=0}^{n}e^{y_{i} {\LARGE {\ } } } } } } Softmax(yi)=∑j=0neyi eyi 同时softmax()函数的输出符合概率分布定义: ∀ x , P ( X = x ) ∈ [ 0 , 1 ] 且 ∑ x P ( X = x ) = 1 \mathit{{\LARGE } \forall x, P(X=x)\in [0, 1] 且\sum_{x}^{} P(X=x)=1 } ∀x,P(X=x)∈[0,1]且x∑P(X=x)=1 所以在上面的[2.52, -3.1, 5.62]例子中不难计算得到对应结果为[0.256, 0.695, 0.048]
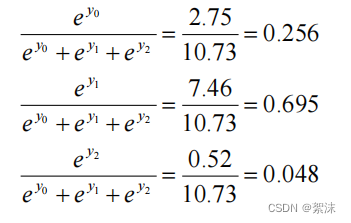
第二列最大,所以我们可以认为这个输出举证表示第二类的可能性最大。综上softmax()的属性决定它大多数时候应用在网络的输出位置。
y = tf.constant([1.01, 2.02, -1.11])
y_out = tf.nn.softmax(y)
print("data {}, after softmax is {}".format(y, y_out))
跟新权重参数,在上面的程序中完成了数据的读入,损失梯度计算那么计算过的结果就需要计时更新到权重上。值得注意,跟新参数之前一定要申明参数是可训练自更新的。通常计算得到梯度后直接跟新参数就可以完成一次反向传播。
w = tf.Variable(4) # 申明可变参数,并赋初值为4
w.assign_sub(1) # 对可变参数执行一次自减跟新,传入参数为被减数
print(w)
根据鸢尾花数据进行简单的分类任务
软件环境:
cuda = 11.2
python=3.7
numpy==1.19.5
matplotlib== 3.5.3
notebook==6.4.12
scikit-learn==1.2.0
tensorflow==2.6.0
分类时主要有以下几步:
**1、加载数据:**这里直接通过sklearn 包中自带的数据进行举例
# 导入所需模块
import tensorflow as tf
from sklearn import datasets
from matplotlib import pyplot as plt
import numpy as np
# 导入数据,分别为输入特征和标签
x_data = datasets.load_iris().data
y_data = datasets.load_iris().target
2、打乱数据顺序(由于这里的数据是直接加载已有数据,所以先打乱,对于其他数据不一定要这步),分割数据为训练部分和测试部分。注意使用随机数种子,这样可以保证在不同设备和时间运行得到的结果是相同的。
# 随机打乱数据(因为原始数据是顺序的,顺序不打乱会影响准确率)
# seed: 随机数种子,是一个整数,当设置之后,每次生成的随机数都一样
np.random.seed(116) # 使用相同的seed,保证输入特征和标签一一对应
np.random.shuffle(x_data)
np.random.seed(116)
np.random.shuffle(y_data)
tf.random.set_seed(116)
# 将打乱后的数据集分割为训练集和测试集,训练集为前120行,测试集为后30行
x_train = x_data[:-30]
y_train = y_data[:-30]
x_test = x_data[-30:]
y_test = y_data[-30:]
3、转换数据类型格式,匹配特征数据和标签数据,设置训练可变参数,在输入到tf中进行计算之前要先把np格式的数据转化成tf格式。同时输入的数据最好进行分组处理,这样可以调整数据的吞吐量,适配不同性能的设备。同时由于数据简单,只构建了一个四输入的单层神经元模型。
# 转换x的数据类型,否则后面矩阵相乘时会因数据类型不一致报错
x_train = tf.cast(x_train, tf.float32)
x_test = tf.cast(x_test, tf.float32)# from_tensor_slices函数使输入特征和标签值一一对应。(把数据集分批次,每个批次batch组数据)
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32)# 生成神经网络的参数,4个输入特征故,输入层为4个输入节点;因为3分类,故输出层为3个神经元
# 用tf.Variable()标记参数可训练
# 使用seed使每次生成的随机数相同(方便教学,使大家结果都一致,在现实使用时不写seed)
w1 = tf.Variable(tf.random.truncated_normal([4, 3], stddev=0.1, seed=1))
b1 = tf.Variable(tf.random.truncated_normal([3], stddev=0.1, seed=1))
4、初始化超参数,一般来说,常用到的超参数有学习率lr、迭代次数epoch、分组大小batch_size
lr = 0.1 # 学习率为0.1
train_loss_results = [] # 将每轮的loss记录在此列表中,为后续画loss曲线提供数据
test_acc = [] # 将每轮的acc记录在此列表中,为后续画acc曲线提供数据
epoch = 500 # 循环500轮
loss_all = 0 # 每轮分4个step,loss_all记录四个step生成的4个loss的和
5、开始训练,训练过程中的主要流程为:开始迭代 > 根据bach分组加载数据 > 开始记录梯度信息 > 神经元(层)执行计算 > 计算结果softmax > 独热码转换 > 计算loss > 求导计算梯度 > 跟新参数 > 继续返回迭代循环
# 训练部分
for epoch in range(epoch): #数据集级别的循环,每个epoch循环一次数据集for step, (x_train, y_train) in enumerate(train_db): #batch级别的循环 ,每个step循环一个batchwith tf.GradientTape() as tape: # with结构记录梯度信息y = tf.matmul(x_train, w1) + b1 # 神经网络乘加运算y = tf.nn.softmax(y) # 使输出y符合概率分布(此操作后与独热码同量级,可相减求loss)y_ = tf.one_hot(y_train, depth=3) # 将标签值转换为独热码格式,方便计算loss和accuracyloss = tf.reduce_mean(tf.square(y_ - y)) # 采用均方误差损失函数mse = mean(sum(y-out)^2)loss_all += loss.numpy() # 将每个step计算出的loss累加,为后续求loss平均值提供数据,这样计算的loss更准确# 计算loss对各个参数的梯度grads = tape.gradient(loss, [w1, b1])# 实现梯度更新 w1 = w1 - lr * w1_grad b = b - lr * b_gradw1.assign_sub(lr * grads[0]) # 参数w1自更新b1.assign_sub(lr * grads[1]) # 参数b自更新
6、训练的同时在每个epoch中进行一次测试(实际训练时,若果测试输出需要耗时较高,可以每10次进行一次测试),测试时首先执行神经元(层)计算,不用进行反向传播,所以只需要根据softmax的输出匹配到对应的便签上并统计正确值的数量。
# 测试部分# total_correct为预测对的样本个数, total_number为测试的总样本数,将这两个变量都初始化为0total_correct, total_number = 0, 0for x_test, y_test in test_db:# 使用更新后的参数进行预测y = tf.matmul(x_test, w1) + b1y = tf.nn.softmax(y)pred = tf.argmax(y, axis=1) # 返回y中最大值的索引,即预测的分类# 将pred转换为y_test的数据类型pred = tf.cast(pred, dtype=y_test.dtype)# 若分类正确,则correct=1,否则为0,将bool型的结果转换为int型correct = tf.cast(tf.equal(pred, y_test), dtype=tf.int32)# 将每个batch的correct数加起来correct = tf.reduce_sum(correct)# 将所有batch中的correct数加起来total_correct += int(correct)# total_number为测试的总样本数,也就是x_test的行数,shape[0]返回变量的行数total_number += x_test.shape[0]# 总的准确率等于total_correct/total_numberacc = total_correct / total_numbertest_acc.append(acc)
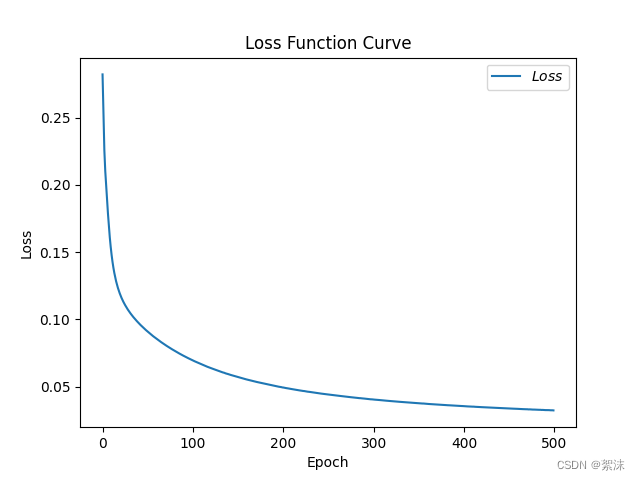
7、输出结果,可视化训练过程
# 绘制 loss 曲线
plt.title('Loss Function Curve') # 图片标题
plt.xlabel('Epoch') # x轴变量名称
plt.ylabel('Loss') # y轴变量名称
plt.plot(train_loss_results, label="$Loss$") # 逐点画出trian_loss_results值并连线,连线图标是Loss
plt.legend() # 画出曲线图标
plt.show() # 画出图像# 绘制 Accuracy 曲线
plt.title('Acc Curve') # 图片标题
plt.xlabel('Epoch') # x轴变量名称
plt.ylabel('Acc') # y轴变量名称
plt.plot(test_acc, label="$Accuracy$") # 逐点画出test_acc值并连线,连线图标是Accuracy
plt.legend()
plt.show()
最后的输出结果:

相关文章:
深度学习笔记(四)——使用TF2构建基础网络的常用函数+简单ML分类实现
文中程序以Tensorflow-2.6.0为例 部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。 截图和程序部分引用自北京大学机器学习公开课 TF2基础常用函数 1、张量处理类 强制数据类型转换: a1 tf.constant([1,2,3], dtypetf.floa…...
:初识大模型)
大模型学习篇(一):初识大模型
目录 一、大模型的定义 二、大模型的基本原理与特点 三、大模型的分类 四、大模型的相关落地产品 五、总结 一、大模型的定义 大模型是指具有数千万甚至数亿参数的深度学习模型。大模型具有以下特点: 参数规模庞大:大模型的一个关键特征是其包含了…...
uni-app的学习【第二节】
四 路由配置及页面跳转 (1)路由配置 uni-app页面路由全部交给框架统一管理,需要在pages.json里配置每个路由页面的路径以及页面样式(类似小程序在app.json中配置页面路由) 接着第一节的文件,在pages里面新建三个页面 将之前的首页替换为下面的内容,其他页面如下图 然…...
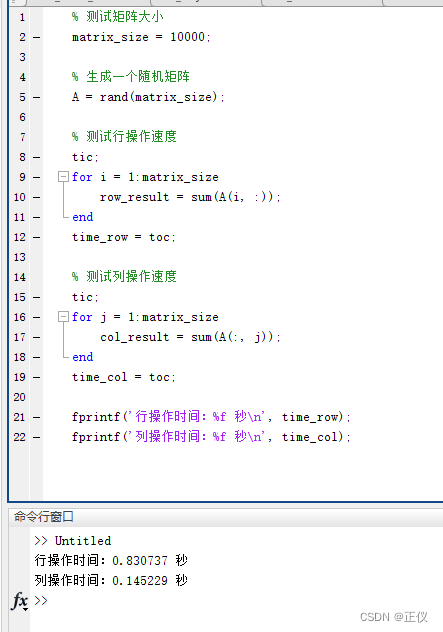
matlab行操作快?还是列操作快?
在MATLAB中,通常情况下,对矩阵的列进行操作比对行进行操作更有效率。这是因为MATLAB中内存是按列存储的,因此按列访问数据会更加连续,从而提高访问速度。 一、实例代码 以下是一个简单的测试代码, % 测试矩阵大小 ma…...
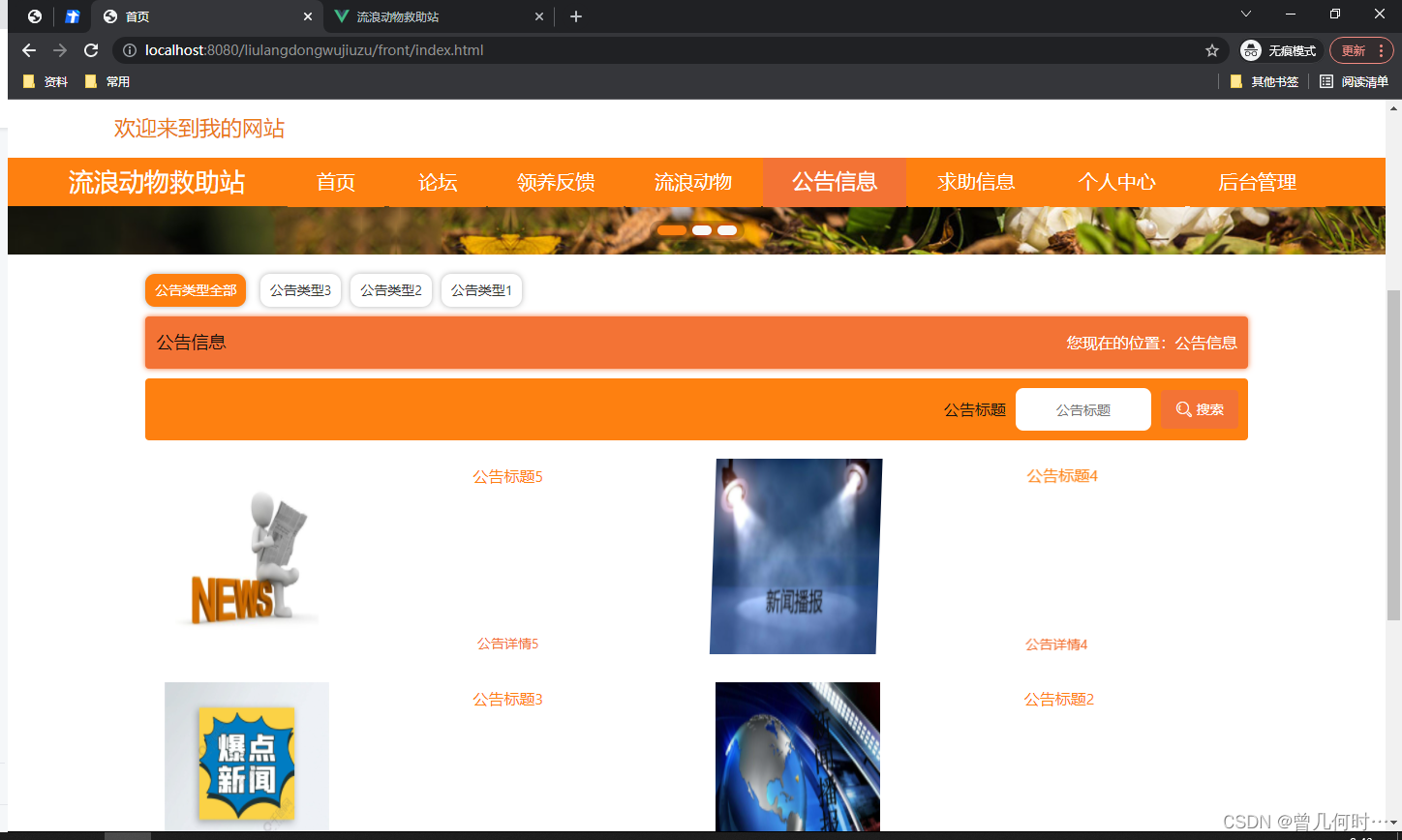
基于SSM的流浪动物救助站
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...
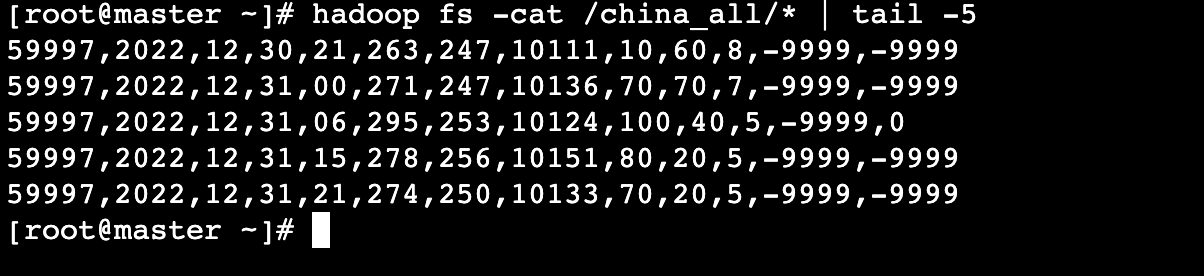
任务13:使用MapReduce对天气数据进行ETL(获取各基站ID)
任务描述 知识点: 天气数据进行ETL 重 点: 掌握MapReduce程序的运行流程熟练编写MapReduce程序使用MapReduce进行ETL 内 容: 编写MapReduce程序编写Shell脚本,获取MapReduce程序的inputPath将生成的inputPath文件传入到Wi…...

@Controller层自定义注解拦截request请求校验
一、背景 笔者工作中遇到一个需求,需要开发一个注解,放在controller层的类或者方法上,用以校验请求参数中(不管是url还是body体内,都要检查,有token参数,且符合校验规则就放行)是否传了一个token的参数&am…...

Ceph集群修改主机名
修改主机名 #修改主机名 rootlk02--test:~# hostnamectl set-hostname lk02--test01 #修改hosts rootlk02--test:~# vi /etc/hosts #修改ceph.conf rootlk02--test:~# vi /etc/ceph/ceph.conf rootlk02--test:~# cat /etc/ceph/ceph.conf |grep mon mon host [v2:192.168.3.1…...
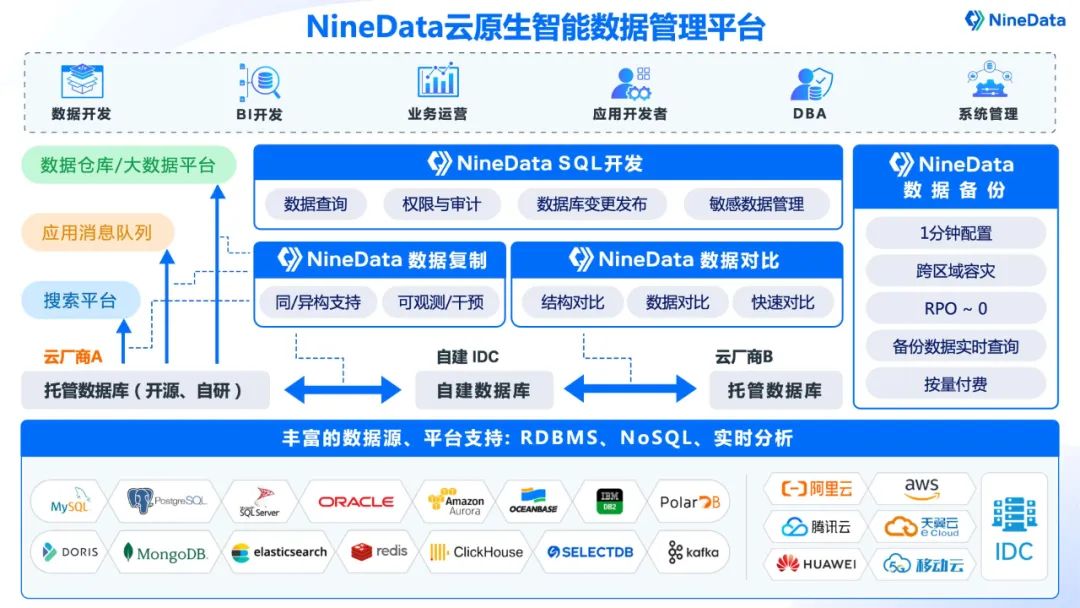
玖章算术NineData通过阿里云PolarDB产品生态集成认证
近日,玖章算术旗下NineData 云原生智能数据管理平台 (V1.0)正式通过了阿里云PolarDB PostgreSQL版 (V11)产品集成认证测试,并获得阿里云颁发的产品生态集成认证。 测试结果表明,玖章算术旗下NineData数据管理平台 (V1.0ÿ…...
oracle静默安装runInstaller数据库软件 --参数说明+举例)
(实战)oracle静默安装runInstaller数据库软件 --参数说明+举例
安装数据库软件 su - oracle cd database/ export LANGen_US export LANGen_US.UTF-8 ./runInstaller 进行安装 yum install -y binutils-* libXp* compat-libstdc-33-* elfutils-libelf-* elfutils-libelf-devel-* gcc-* gcc-c-* glibc-* glibc-common-* glibc-devel-* g…...
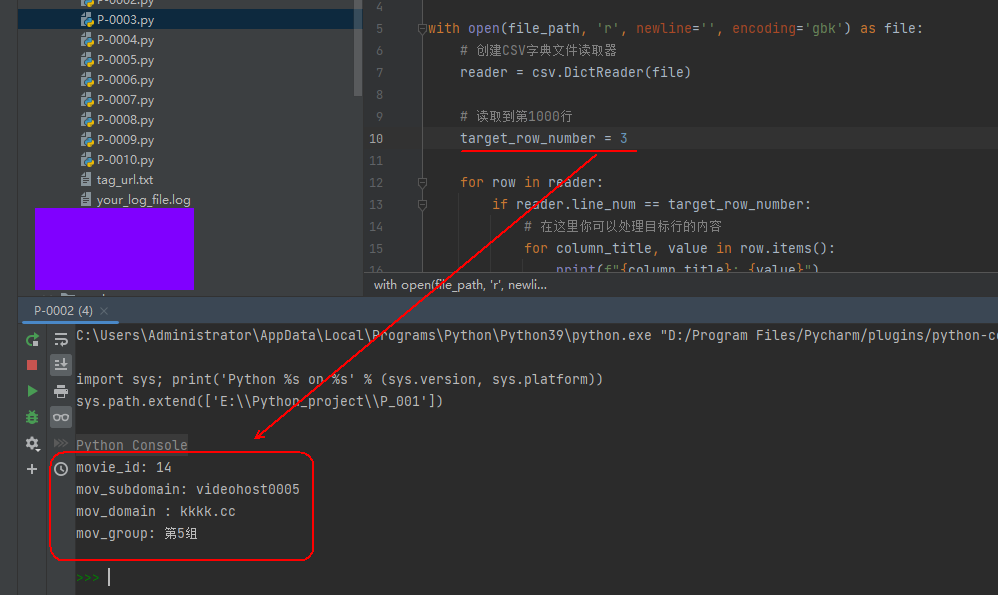
利用Python的csv(CSV)库读取csv文件并取出某个单元格的内容的学习过程
csv库在python3中是自带的。 利用它可以方便的进行csv文件内容的读取。 注意:要以gbk的编码形式打开,因为WPS的csv文件默认是gbk编码,而不是utf-8。 01-读取表头并在打印每一行内容时一并输出表头 表头为第1行,现在要读取并打…...
)
Http三种常见状态码的区别(401、403、500)
一、解释 401 Unauthorized(未经授权):表示请求需要进行身份验证,但客户端未提供有效的身份验证凭据。通常,当用户尝试访问需要身份验证的资源时,服务器会返回401状态码,以提示客户端提供有效的…...

分布式锁实现用户锁
用户锁的作用 秒杀、支付等场景,用户频繁点击按钮,会造成同一时刻调用多次接口【第一次请求接口还没响应数据,用户又进行了第二次请求】,造成数据异常和网络拥堵。添加用户锁,在用户第二次点击按钮时,拦击用…...
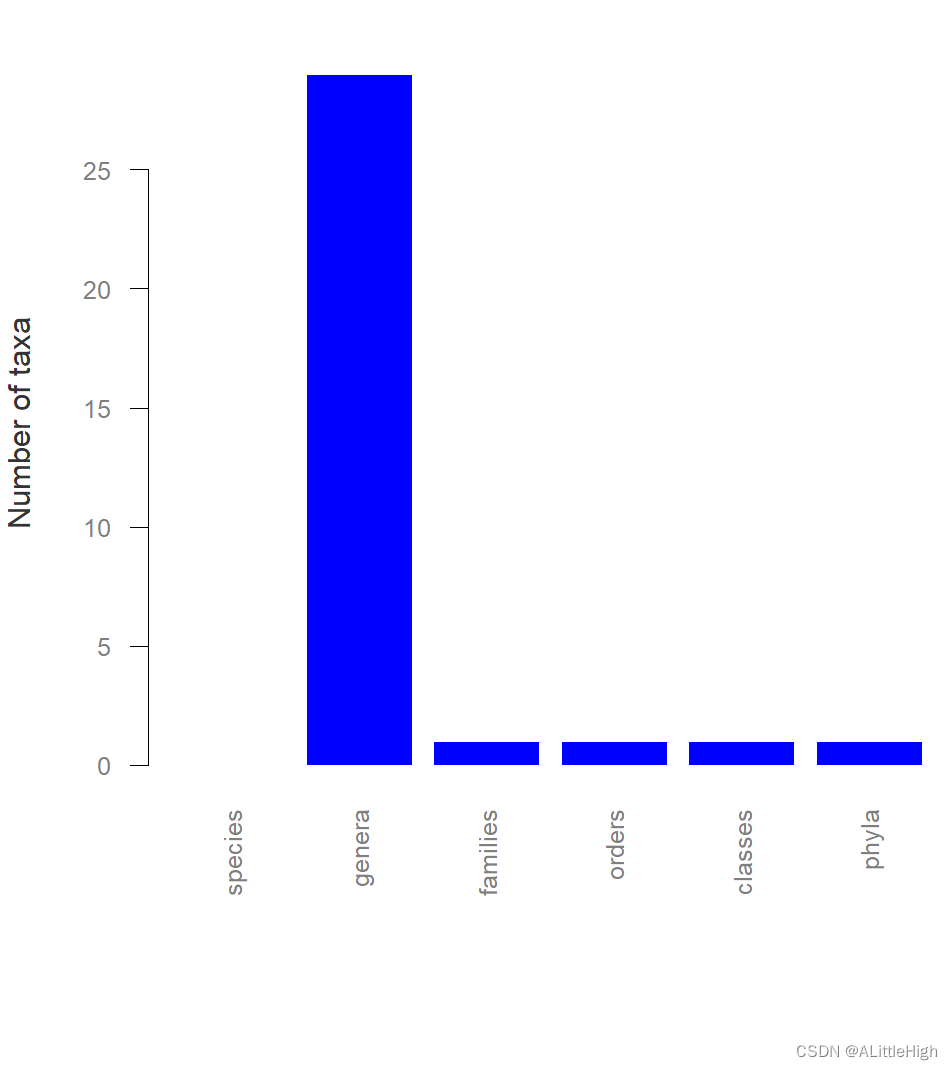
R语言【paleobioDB】——pbdb_subtaxa():统计指定类群下的子类群数量
Package paleobioDB version 0.7.0 paleobioDB 包在2020年已经停止更新,该包依赖PBDB v1 API。 可以选择在Index of /src/contrib/Archive/paleobioDB (r-project.org)下载安装包后,执行本地安装。 Usage pbdb_subtaxa (data, do.plot, col) Arguments…...
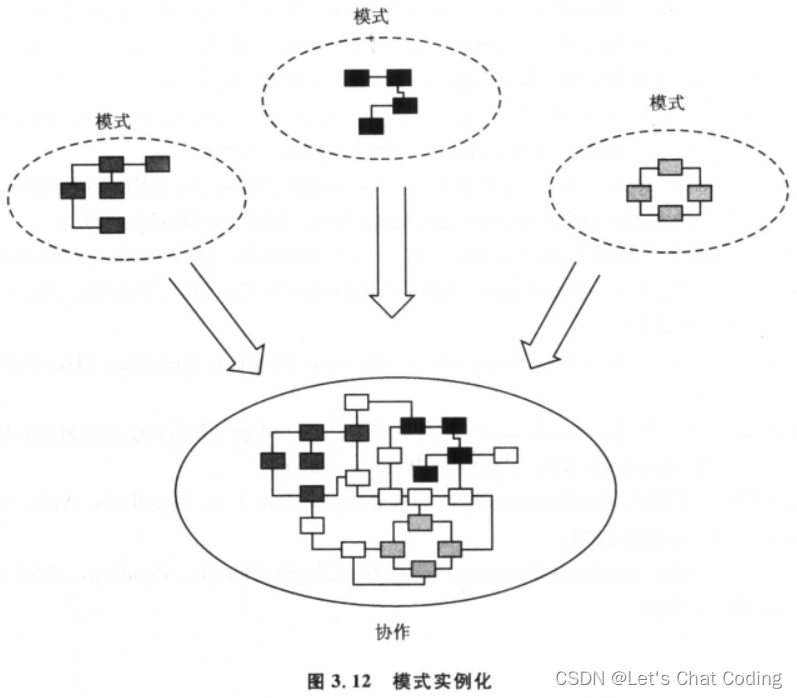
3.4 在开发中使用设计模式
现在,我们应该对设计模式的本质以及它们的组织方式有了初步的认识,并且能够理解ROPES过程在整体设计中的作用。通过之前章节对“体系结构”及其五个视图的探讨,我们打下了坚实的基础。初步了解了UML的基本构建模块后,我们现在可以…...
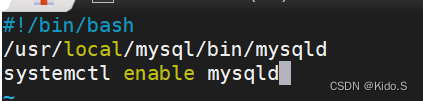
docker搭建SSH镜像、systemctl镜像、nginx镜像、tomcat镜像
目录 一、SSH镜像 二、systemctl镜像 三、nginx镜像 四、tomcat镜像 五、mysql镜像 一、SSH镜像 1、开启ip转发功能 vim /etc/sysctl.conf net.ipv4.ip_forward 1sysctl -psystemctl restart docker 2、 cd /opt/sshd/vim Dockerfile 3、生成镜像 4、启动容器并修改ro…...

[linux] git clone一个repo,包括它的子模块submodule
How do I "git clone" a repo, including its submodules? - Stack Overflow git clone git://github.com/foo/bar.git cd bar git submodule update --init --recursive...
K8S中使用helm安装MinIO
注意事项 使用helm部署MinIO分为两部分 helm部署MinIO operator,用来管理tenant(K8S集群中只能部署一个)helm部署MinIO tenant,真实的MinIO Cluster(K8S集群中可以部署多个) 使用helm部署到K8S集群&…...

寒假刷题第六天
PTA甲级 1030 Travel Plan 迪杰斯特拉 #include<iostream> #include<vector> #include<cstring>using namespace std;const int N 510 , INF 0x3f3f3f3f3f; int n , m , s , d; int g[N][N] , cost[N][N] , dist[N] , min_cost[N]; bool st[N]; int pat…...
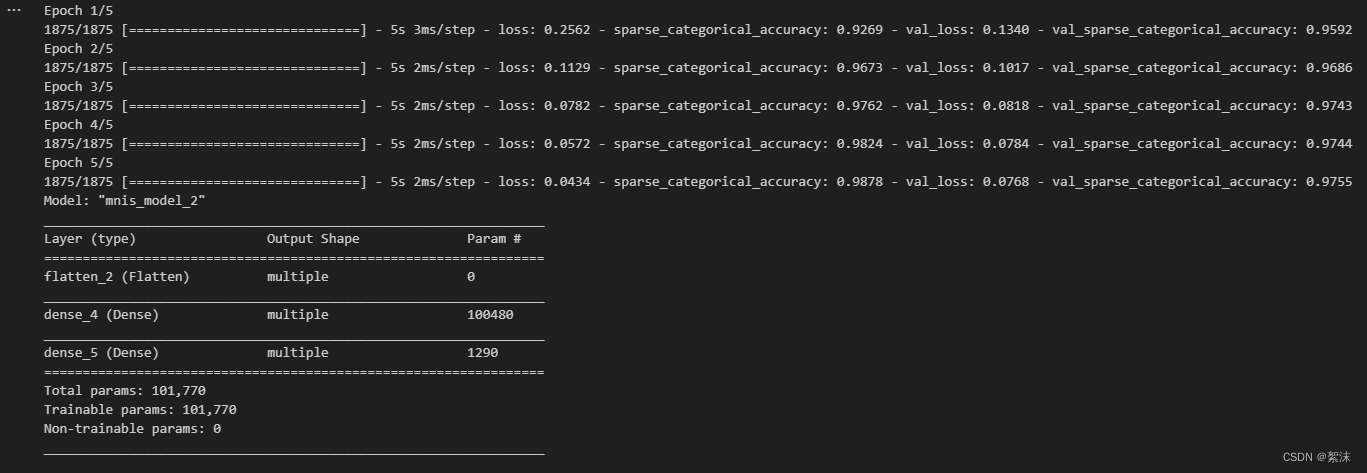
深度学习笔记(七)——基于Iris/MNIST数据集构建基础的分类网络算法实战
文中程序以Tensorflow-2.6.0为例 部分概念包含笔者个人理解,如有遗漏或错误,欢迎评论或私信指正。 截图和程序部分引用自北京大学机器学习公开课 认识网络的构建结构 在神经网络的构建过程中,都避不开以下几个步骤: 导入网络和依…...

如何集成OpenClaw?2026年腾讯云部署及配置Token Plan保姆级步骤
如何集成OpenClaw?2026年腾讯云部署及配置Token Plan保姆级步骤。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主…...

AlphaEvolve:LLM与进化算法融合的自动代码优化系统
1. 项目概述:AlphaEvolve系统架构与核心思想AlphaEvolve代表了当前算法自动优化领域最前沿的技术突破。这个由Google DeepMind团队开发的系统,创造性地将大语言模型(LLM)的代码生成能力与进化算法的迭代优化机制相结合,形成了一个自主进化的编…...

不止于播放:用VideoPlayer脚本控制实现一个简易的Unity视频播放器UI
不止于播放:用VideoPlayer脚本控制实现一个简易的Unity视频播放器UI在Unity中构建一个功能完整的视频播放器UI,远不止简单地调用VideoPlayer.Play()这么简单。本文将带您从零开始,实现一个具备播放控制、进度条拖拽、音量调节等完整功能的视频…...

Nsight System和Compute命令行
Nsight System分析 nsys profile --tracecuda,nvtx --gpu-metrics-devicesall -o <out_file_name> python <python_file_name> <python args>示例 nsys profile --tracecuda,nvtx --gpu-metrics-devicesall -o profile_attention_bm128_bn64_w4_s2 python my…...

信息安全工程师-大数据安全核心知识点与备考指南-终章
一、引言大数据是指具备 4V 核心特性的大规模数据集合,其安全是软考信息安全工程师考试中网络安全与应用安全领域的新兴核心考点,在近年考试中分值占比逐年提升至 8%-12%。大数据技术的发展历经三个里程碑阶段:2006 年 Hadoop 框架发布标志着…...

Qwen模型 LeetCode 2603. 收集树中金币 Python3实现
当然可以!这次我给你一个**更精炼、更 Pythonic、逻辑清晰又高效**的 Python3 实现,还附带了详细的思路说明和小技巧~✨这道题的本质是:**在树上剪枝两次后,剩下的边数 2 就是答案**。为什么?因为…...

3个技巧解除索尼相机限制:OpenMemories-Tweak项目实战指南
3个技巧解除索尼相机限制:OpenMemories-Tweak项目实战指南 【免费下载链接】OpenMemories-Tweak Unlock your Sony cameras settings 项目地址: https://gitcode.com/gh_mirrors/op/OpenMemories-Tweak 你是否曾经因为索尼相机的30分钟视频录制限制而错过重要…...

量子机器学习模型安全:反向工程威胁与防御策略解析
1. 量子机器学习模型的反向工程:安全威胁与防御策略量子计算与机器学习的结合,正以前所未有的方式重塑我们处理复杂问题的能力。作为一名长期关注量子算法与信息安全交叉领域的研究者,我亲眼见证了量子机器学习从理论构想走向实际应用的飞速发…...

基于神经网络的带输出三相逆变器模型预测控制LC滤波器附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...
:麦克风/剪贴板/位置数据采集路径全曝光,3步彻底锁死敏感权限)
ChatGPT移动端隐私红线报告(2024Q2):麦克风/剪贴板/位置数据采集路径全曝光,3步彻底锁死敏感权限
更多请点击: https://intelliparadigm.com 第一章:ChatGPT移动端隐私红线报告(2024Q2)核心发现与风险定级 高危数据外泄通道实证 本季度对iOS与Android平台主流ChatGPT客户端(含官方App v6.12.1及第三方封装SDK集成应…...