2.1.2 一个关于y=ax+b的故事
跳转到根目录:知行合一:投资篇
已完成:
1、投资&技术
1.1.1 投资-编程基础-numpy
1.1.2 投资-编程基础-pandas
1.2 金融数据处理
1.3 金融数据可视化
2、投资方法论
2.1.1 预期年化收益率
2.1.2 一个关于y=ax+b的故事
3、投资实证
[3.1 2023这一年] 被鸽
文章目录
- 1. 系统自己画!最佳拟合线
- 1.1. 沪深300的最佳拟合线
- 1.2. 横向对比:一个个算
- 1.3. 横向对比:数据标准化
- 1.4. 看图说话
- 2. 系统自己算!线性回归
- 2.1. 沪深300线性回归,斜率0.00099414
- 2.2. 沪深300线性回归的年化,年化8.5%
- 2.3. 沪深300首尾点的年化,4.72%
- 2.4. 中证500线性回归,斜率0.0008
- 2.5. 中证500线性回归的年化
- 2.6. 中证500首尾点的年化
- 3. 总结
当看到一个在k线图上画直线的时候,斜率是可以自动计算的吗?
最佳拟合的直线,计算出来的斜率是多少?最佳拟合直线代表的年化是多少?
1. 系统自己画!最佳拟合线
1.1. 沪深300的最佳拟合线
顾名思义,这就是对于散点图,画一条最佳拟合的直线。那什么又叫最佳拟合线?
最佳拟合直线是指,我们可以找到一条直线,样本点到该直线的[离差平方和]达到最小的直线。这条直线用公式y = ax + b表示。
a表示回归系数,b表示截距。
再简单的说,就是存在一条线,这条线,能让各个点,都比较“满意”地分布在其上下。
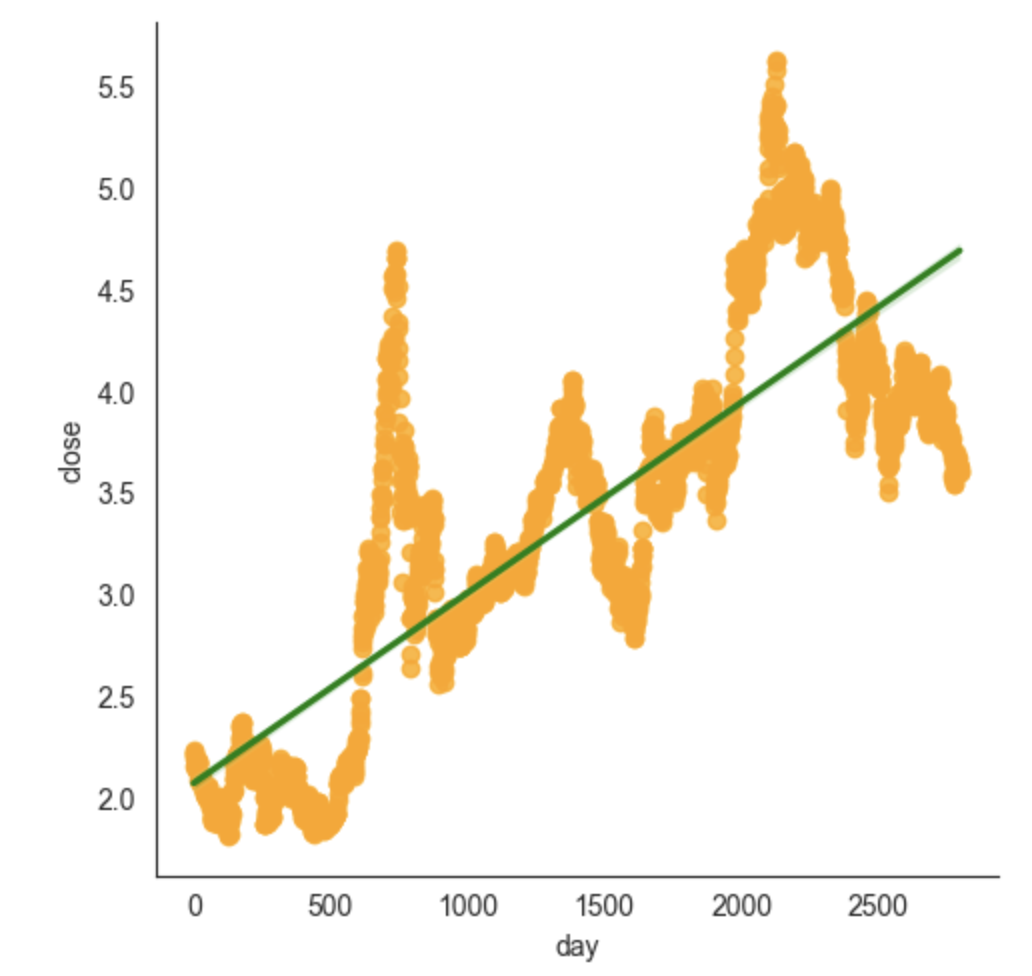
我们拿沪深300的历史收盘价作为散点图,来看看其所谓的最佳拟合线是什么样的。
import qstock as qs
import seaborn as sns
import numpy as npsh300=qs.get_data('510300')
# 因为设想中,x轴,可以是一个顺序的数组,比如从0开始往后数,step为1。这其实就是暗合着,随着时间的增加,close是否能拟合一条向上的直线?
sh300['day'] = np.arange(0, sh300.shape[0], 1)sns.set_style("white")
gridobj = sns.lmplot(x="day", y="close", data=sh300, ci=95, scatter_kws={'color': 'orange'}, line_kws={'color': 'green'}, markers='o')
1.2. 横向对比:一个个算
看过了沪深300,肯定会有疑惑啊,总是要横向对比的吧?比如沪深300和中证500、券商ETF、红利ETF、房地产ETF、黄金ETF等标的,能进行横向对比来看谁的斜率(赚钱效应)更好吗?
Of course ,动手!
import qstock as qs
import seaborn as sns
import numpy as npstocks_info = [{'code': '510300', 'name': '沪深300'},{'code': '510500', 'name': '中证500'},{'code': '512010', 'name': '医药ETF'},{'code': '512000', 'name': '券商ETF'},{'code': '516160', 'name': '新能源ETF'},{'code': '510800', 'name': '红利ETF'},{'code': '518880', 'name': '黄金ETF'},{'code': '512200', 'name': '房地产ETF'}
]
for stock in stocks_info:df=qs.get_data(stock['code'])# 因为设想中,x轴,可以是一个顺序的数组,比如从0开始往后数,step为1。这其实就是暗合着,随着时间的增加,close是否能拟合一条向上的直线?df['day'] = np.arange(0, df.shape[0], 1)df['标的'] = stock['name']sns.set_style("white")# 这个是seaborn中文乱码的处理。经过试验,在这里,plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'],这种设置是不行的。sns.set_style(rc= {'font.sans-serif':"Arial Unicode MS"})gridobj = sns.lmplot(x="day", y="close", data=df, hue="标的", ci=95, scatter_kws={'color': 'orange'}, line_kws={'color': 'green'}, markers='o')
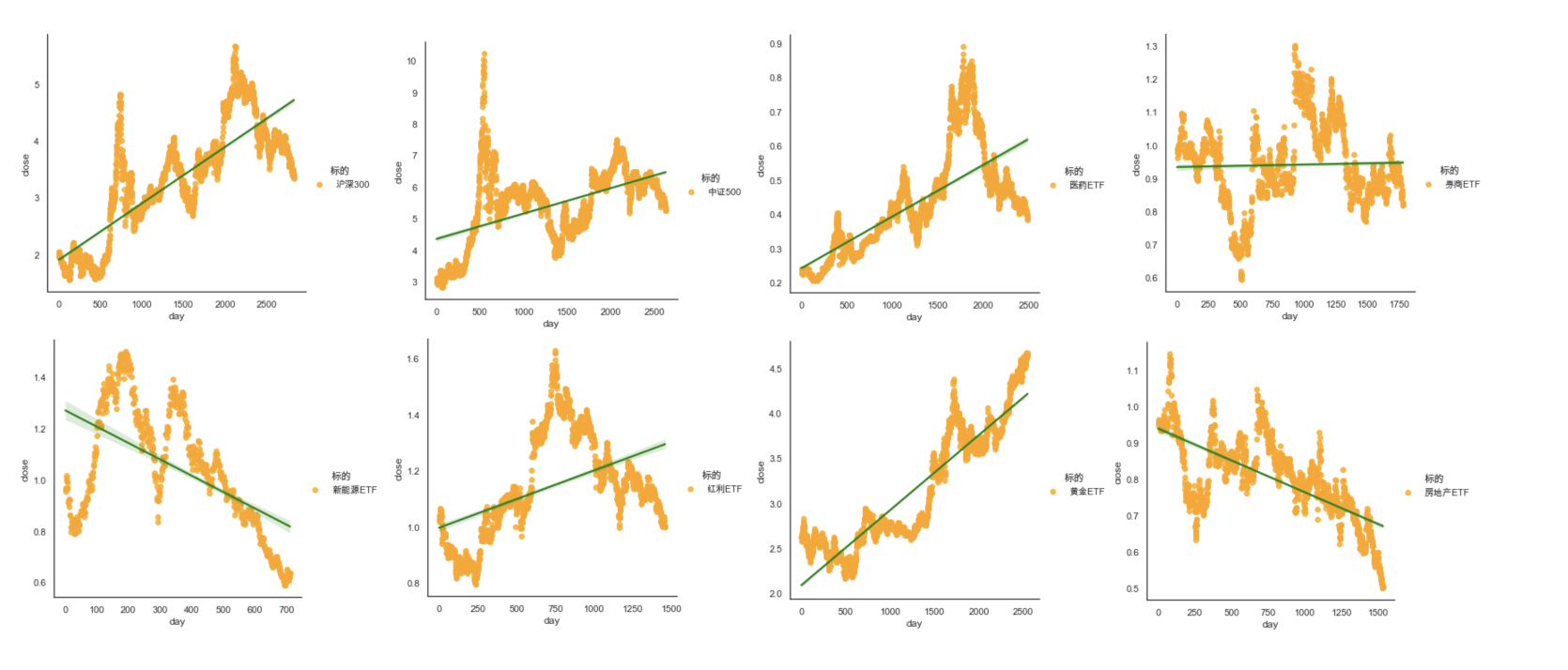
这里要说明一下,上面其实是一个个图生成的,然后我一张张图拼接起来的结果。
如果想直接横向着来看,还需要对数据进行标准化处理,如果不进行标准化,那比如不同标的的收盘价,差异很大,有的是十几块,像ETF,可能就是1块,那结果就很难看,就像下面这种:

1.3. 横向对比:数据标准化
所以,下面就是要将不同的标的进行标准化处理,这种标准化,意味着,将价格进行处理变成相对值,才可以进行比较,这里使用的是sklearn模块的StandardScaler,核心方法是fit_transform(df_all)。如果没有安装sklearn,需要先进行安装pip install -U scikit-learn
下面是一个完整的案例:
import qstock as qs
import pandas as pd#默认日频率、前复权所有历史数据
#open:开盘价,high:最高价,low:最低价,close:收盘价 vol:成交量,turnover:成交金额,turnover_rate:换手率
# 沪深300, 中证500, 医药ETF, 券商ETF, 新能源ETF, 红利ETF, 黄金ETF, 房地产ETF
stocks_info = [{'code': '510300', 'name': '沪深300'},{'code': '510500', 'name': '中证500'},{'code': '512010', 'name': '医药ETF'},{'code': '512000', 'name': '券商ETF'},{'code': '516160', 'name': '新能源ETF'},{'code': '510800', 'name': '红利ETF'},{'code': '518880', 'name': '黄金ETF'},{'code': '512200', 'name': '房地产ETF'}
]
for stock in stocks_info:df = qs.get_data(stock['code']) # 从qstock获取对应的股票历史数据stock['history_df'] = df # 将其存在 history_df 这个key里面。# 只保留收盘价,合并数据
df_all = pd.DataFrame()
for stock in stocks_info:df = stock['history_df']df = df[['close']] # 只需要 date 和 close 2列就行了。df.rename(columns={'close': stock['name']}, inplace=True) # 用股票的名字来重命名close列if df_all.size == 0:df_all = dfelse:df_all = df_all.join(df) # join是按照index来连接的。# print(df_all)# 对dataframe的数据进行标准化处理
import sklearn
from sklearn import preprocessing
z_scaler = preprocessing.StandardScaler() # 建立 StandardScaler 对象
z_data = z_scaler.fit_transform(df_all) #数据标准化(从第三列开始)
z_data = pd.DataFrame(z_data) #将数据转为Dataframe
z_data.columns = df_all.columns
df_all = z_data
print(df_all)# 只保留收盘价,合并数据
df_new = pd.DataFrame()
for stock in stocks_info:df = df_all[[stock['name']]]df.columns = ['close']df['标的'] = stock['name']if df_new.size == 0:df_new = dfelse:df_new = pd.concat([df_new, df], axis=0)print(df_new)
df_new['day'] = df_new.index# 这个是seaborn中文乱码的处理。经过试验,在这里,plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'],这种设置是不行的。
sns.set_style(rc= {'font.sans-serif':"Arial Unicode MS"})
df = sns.lmplot(x="day", y="close",data=df_new,col="标的")

close 标的
0 -1.316309 沪深300
1 -1.275999 沪深300
2 -1.284061 沪深300
3 -1.290107 沪深300
4 -1.290107 沪深300
... ... ...
2826 -2.711143 房地产ETF
2827 -2.684416 房地产ETF
2828 -2.702234 房地产ETF
2829 -2.666598 房地产ETF
2830 -2.675507 房地产ETF[22648 rows x 2 columns]
1.4. 看图说话
从上面的横向对比图可以看出:
- 沪深300的斜率,是高于中证500的
- 券商ETF,基本是一条横线,说明什么?做T啊,稳赚不赔!
- 新能源ETF、房地产ETF,可能是时间还太短,所处的周期内,就是向下的。
- 其他的,黄金看的是长周期,可能是几十年,还是慎重为好;红利,说不好,不懂的就先不碰了。
2. 系统自己算!线性回归
2.1. 沪深300线性回归,斜率0.00099414
首先从 sklearn 下的 linear_model 中引入 LinearRegression,再创建估计器起名 model,设置超参数 normalize 为 True,指的在每个特征值上做标准化,这样会加速数值运算。(可能是版本不同,有时候会报错LinearRegression got an unexpected keyword argument 'normalize',此时反而要去掉normalize=True这个参数。)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegressiondf=qs.get_data('510300')model = LinearRegression()
model
x = np.arange(df.shape[0])
y = df['close']X = x[:, np.newaxis]
model.fit( X, y )print( model.coef_ ) # 斜率 0.00099414,就是y=ax+b的a
print( model.intercept_ ) # 截距 1.9,就是y=ax+b的b# 根据上面计算的结果,我们绘制一个收盘价走势图和一条y=ax=b的直线
plt.plot( x, y, linestyle='-', color='green' )
plt.plot(x, 0.00099414*x + 1.9, linestyle='--', color='r') # 这个是根据最后计算的“斜率”和“截距”,再叠加绘制的斜线
2.2. 沪深300线性回归的年化,年化8.5%
之前计算的沪深300最佳拟合的直线,斜率和截距:
plt.plot(x, 0.00099414*x + 1.9, linestyle='--', color='r') # 这个是根据最后计算的“斜率”和“截距”,再叠加绘制的斜线
沪深300,如果按照上面的直线来看,那:
起始点:1.9
终点:y=ax+b,即y=0.00099414*x + 1.9,最后的x,其实是x轴的个数,是:df.shape[0],也就是行数:x=2832;那么计算的y = 0.00099414 * 2832 + 1.9 = 4.71540448
按照上面的计算:
import mathbegin = 1.9
end = 4.71540448
year = 2832/255.0# 年化收益率计算
rate = math.pow(end / begin, 1.0 / year) - 1
print('开始价=%s, 最终价=%s, year=%s,年化收益率=%s' % (str(begin), str(end), str(year), str(rate)))开始价=1.9, 最终价=4.71540448, year=11.105882352941176,年化收益率=0.0852895190354479
2.3. 沪深300首尾点的年化,4.72%
如果不考虑中间的波动,那沪深300的年化收益率计算:
import pandas as pd
import mathdf=qs.get_data('510300')begin = df['close'][0]
end = df['close'][-1]
year = df.shape[0]/255.0# 年化收益率计算
rate = math.pow(end / begin, 1.0 / year) - 1
print('开始价=%s, 最终价=%s, year=%s,年化收益率=%s' % (str(begin), str(end), str(year), str(rate)))开始价=2.004, 最终价=3.345, year=11.105882352941176,年化收益率=0.047211214375309396
2.4. 中证500线性回归,斜率0.0008
对比看下中证500斜率如何
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegressiondf=qs.get_data('510500')model = LinearRegression()
model
x = np.arange(df.shape[0])
y = df['close']X = x[:, np.newaxis]
model.fit( X, y )print( model.coef_ ) # 斜率 0.00080245,就是y=ax+b的a
print( model.intercept_ ) # 截距 4.353948387096773,就是y=ax+b的b# 根据上面计算的结果,我们绘制一个收盘价走势图和一条y=ax=b的直线
plt.plot( x, y, linestyle='-', color='green' )
plt.plot(x, 0.00080245*x + 4.353948387096773, linestyle='--', color='r') # 这个是根据最后计算的“斜率”和“截距”,再叠加绘制的斜线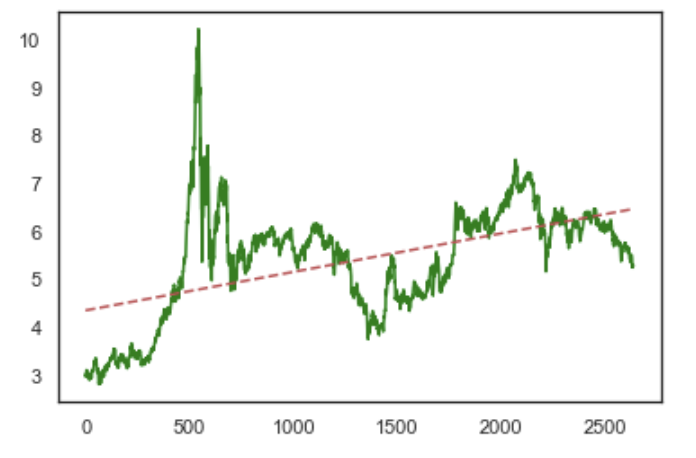
2.5. 中证500线性回归的年化
计算中证500最佳拟合的直线,斜率和截距:
plt.plot(x, 0.00080245*x + 4.353948387096773, linestyle='--', color='r') # 这个是根据最后计算的“斜率”和“截距”,再叠加绘制的斜线
起始点:4.353948387096773
终点:y=ax+b,即y=0.00080245*x + 4.353948387096773,最后的x,其实是x轴的个数,是:df.shape[0],也就是行数:x=2635;那么计算的y = 0.00080245 * 2635 + 4.353948387096773 = 6.468404137096773
按照上面的计算:
import mathbegin = 4.353948387096773
end = 6.468404137096773
year = 2635/255.0# 年化收益率计算
rate = math.pow(end / begin, 1.0 / year) - 1
print('开始价=%s, 最终价=%s, year=%s,年化收益率=%s' % (str(begin), str(end), str(year), str(rate)))开始价=4.353948387096773, 最终价=6.468404137096773, year=10.333333333333334,年化收益率=0.039050907738202856
2.6. 中证500首尾点的年化
中证500年化收益率:
import pandas as pd
import mathdf=qs.get_data('510500')begin = df['close'][0]
end = df['close'][-1]
year = df.shape[0]/255.0# 年化收益率计算
rate = math.pow(end / begin, 1.0 / year) - 1
print('开始价=%s, 最终价=%s, year=%s,年化收益率=%s' % (str(begin), str(end), str(year), str(rate)))开始价=3.021, 最终价=5.279, year=10.333333333333334,年化收益率=0.055499799550948525
3. 总结
如果用最佳拟合直线,那么沪深300的年化是8.5%,中证500的年化是3.9%
如果是按照收盘价的首尾点来计算,那么沪深300的年化是4.72%,中证500的年化是5.55%
为什么最佳拟合直线和首尾点计算的年化差异这么大?还是因为今天2024年1月15日,收盘价跟最佳拟合直线的差距很大,自然会有很大的偏差,如果哪天能所谓的“价值回归”或是就应该是这个价,那2者会慢慢合理起来。
波动很大,但是最终的结果,还是能达到5%左右的年化收益率。
相关文章:
2.1.2 一个关于y=ax+b的故事
跳转到根目录:知行合一:投资篇 已完成: 1、投资&技术 1.1.1 投资-编程基础-numpy 1.1.2 投资-编程基础-pandas 1.2 金融数据处理 1.3 金融数据可视化 2、投资方法论 2.1.1 预期年化收益率 2.1.2 一个关于yaxb的…...
Rust-解引用
“解引用”(Deref)是“取引用”(Ref)的反操作。取引用,我们有&、&mut等操作符,对应的,解引用,我们有操作符,跟C语言是一样的。示例如下: 比如说,我们有引用类型p:&i32;,那么可以用符…...

记录一下vue项目引入百度地图
公共部分 #allmap { width: 500px; height: 500px; font-family: "微软雅黑"; } 1、 <div id"allmap"> <baidu-map :center"center" :zoom"zoom" ready"handler"></baidu-map> </div> data()…...

基于Docker官方php:7.4.33-fpm镜像构建支持67个常见模组的php7.4.33镜像
实践说明:基于RHEL7(CentOS7.9)部署docker环境(23.0.1、24.0.2),所构建的php7.4.33镜像应用于RHEL7-9(如AlmaLinux9.1),但因为docker的特性,适用场景是不限于此的。 文档形成时期:2017-2023年 因系统或软件版本不同&am…...

opencv通过轮廓点生成闭合图像
前言 有时候需要将某一些点生成闭合的二值图像。记录一下。 // 轮廓点个数 int nrCurvePoints curContour.nr; // 轮廓点 DIM2DL* curvePoints curContour.pts;std::vector<cv::Point> points; // 轮廓点集合 for (int cntPoint 0; cntPoint < nrCurvePoints; cn…...
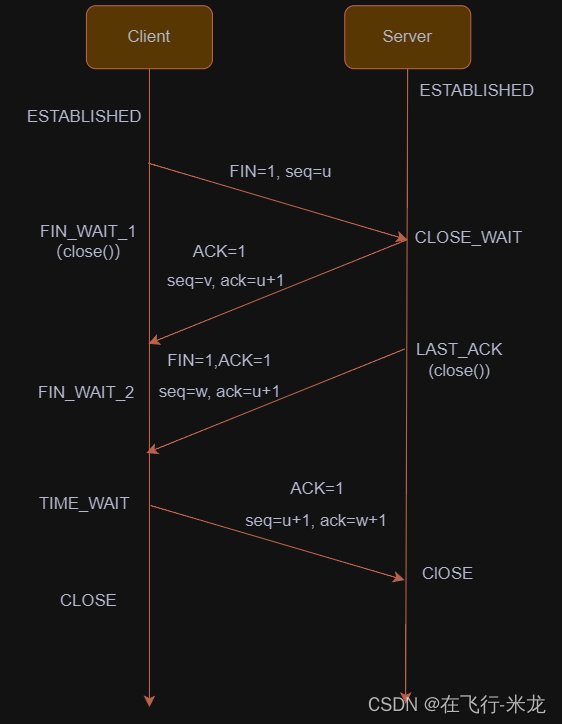
Python 网络编程之TCP详细讲解
【一】传输层 【1】概念 传输层是OSI五层模型中的第四层,负责在网络中的两个端系统之间提供数据传输服务主要协议包括**TCP(传输控制协议)和UDP(用户数据报协议)** 【2】功能 **端到端通信:**传输层负责…...

直饮水系统服务认证:提升水质与安全的必要举
直饮水系统作为一种便捷、卫生的饮水方式,已经越来越受到人们的欢迎。然而,随着市场的发展,直饮水系统的质量和服务也面临着一些挑战。因此,直饮水系统服务认证应运而生,成为了提升水质与安全的必要举措。 一、直饮水…...
Qt 调试系统输出报警声以及添加资源
文章目录 前言一、方法1 使用 Qsound1.添加都文件 直接报错2.解决这个错误 添加 QT multimedia3. 加入代码又遇到新的错误小结 二、第二种方法1.引入库2.添加资源2.1依次点击Qt--->Qt Resource File--->Choose2.2给资源文件起个名字,如:res&#…...
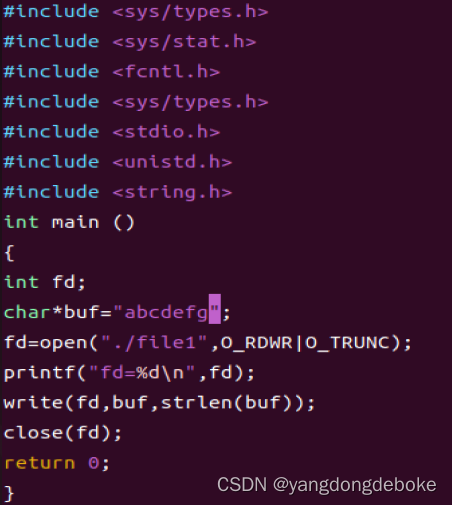
Linux下文件的创建写入读取编程
在linux下操作一个文件,首先要保证文件的存在(不存在就创建),接着打开文件(打开成功)并得到文件描述符,接着在进行读写操作,最后还需要关闭文件。如果我们对文件进行读写之后不关闭文…...

python 解析
list(pd.DataFrame) # 所有列名切片:print("显式 切片:\n", df.loc[:, "number":"sum"]) 所有行,列是从number 到sum ,前闭后开print("隐式 切片:\n", df.iloc[:, 1:3]) # 结果和上面一样转化成字典…...
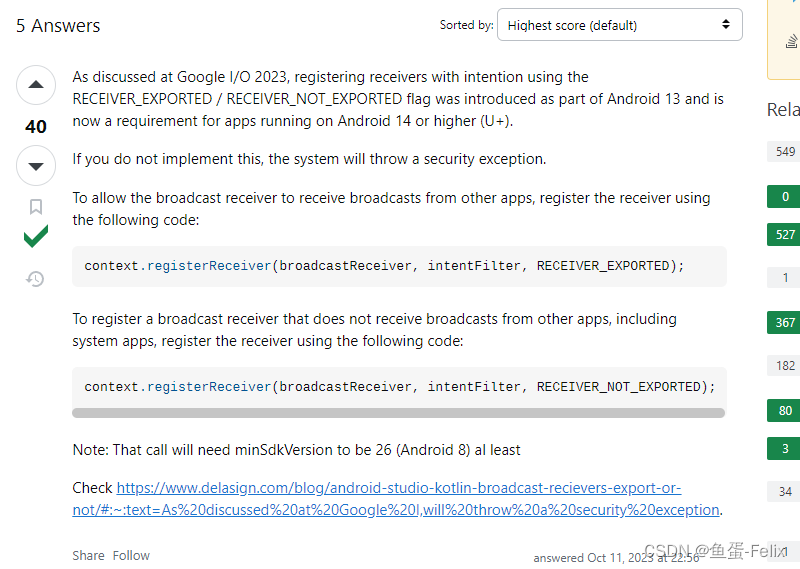
谷歌aab包在Android 14闪退而apk没问题(targetsdk 34)
问题原因 Unity应用(target SDK 34)上线到GooglePlay,有用户反馈fold5设备上(Android14系统)疯狂闪退,经测试,在小米手机Android14系统的版本复现成功了,奇怪的是apk直接安装没问题,而打包成aa…...

34.在排序数组中查找元素的第一个和最后一个位置
34.在排序数组中查找元素的第一个和最后一个位置 给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。 如果数组中不存在目标值 target,返回 [-1, -1]。 你必须设计并实现时间复杂度为…...

js树过滤
// 递归过滤得到每一项的hidden为false的数据 function filterTree(arr) { return arr.filter(item > { if (item.children) { item.children filterTree(item.children) } if (!item.hidden) { return true } }) }...

Java多线程并发篇----第十六篇
系列文章目录 文章目录 系列文章目录前言一、线程等待(wait)二、线程睡眠(sleep)三、线程让步(yield)四、线程中断(interrupt)五、Join 等待其他线程终止前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站,这…...

测评结果:免费的“文心一言3.5”香,但是付费的产品质量更高
文章目录 前言一、文心一言3.5生成的图片和文章1.文心一言生成的图片在文心一言3.5中输入以下内容:我的测评结果: 2.文心一言生成的文章在文心一言3.5中输入以下内容:我的测评结果: 二、ChatGPT生成的图片和文章1.ChatGPT4.0 生成…...
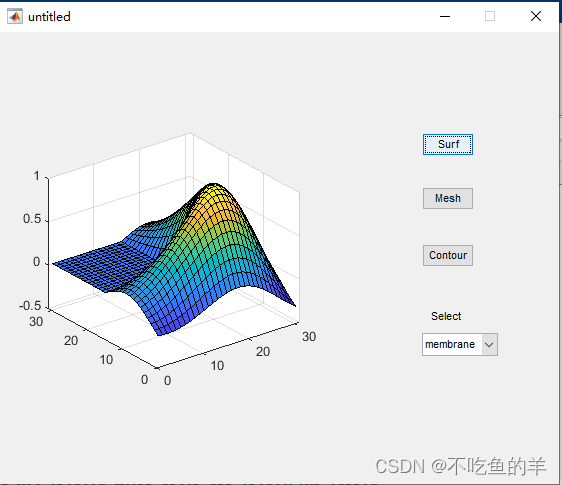
Matlab GUI设计基础范例(可以一步一步跟着做)
我们要做一个GUI界面,可以选择peaks、membrane和sinc三种三维图数据,选择画出surf、mesh和contour三种图像。 打开GUI 每个版本打开方式可能都不一样,但有一个是相同的,就是在命令行输入guide回车。 绘制控件 大概就绘制成这样…...
@Transactional(rollbackFor = {Exception.class})与 @Transactional区别
在Spring框架中,Transactional 注解用于标记方法或类,以表明该方法或类内包含的数据库操作应当在一个事务中执行。事务的基本原则是“原子性”,即所有操作要么全部成功,要么全部失败。 1. Transactional(不指定 rollb…...

数据结构——二叉树(先序、中序、后序及层次四种遍历(C语言版))超详细~ (✧∇✧) Q_Q
目录 二叉树的定义: *特殊的二叉树: 二叉树的性质: 二叉树的声明: 二叉树的先序遍历: 二叉树的中序遍历: 二叉树的后序遍历: 二叉树的层序遍历: 二叉树的节点个数: 二叉…...
如何快速打造属于自己的接口自动化测试框架
1 接口测试 接口测试是对系统或组件之间的接口进行测试,主要是校验数据的交换,传递和控制管理过程,以及相互逻辑依赖关系。 接口自动化相对于UI自动化来说,属于更底层的测试,这样带来的好处就是测试收益更大ÿ…...

人工智能在数据安全中的应用场景
场景一:数据资产梳理 数据资产梳理是数据安全的基础。知道企业究竟有多少数据,这些数据在哪里?有哪些类型的数据?其中哪些是敏感数据?这些数据的敏感等级分别是什么?只有明确了保护的目标,才能…...

【信息科学与工程学】计算机科学与自动化——第六十二篇 虚拟化算法02
虚拟化领域核心算法详解(续) 算法19: 虚拟机快照与还原算法 编号: 19 类型: 快照管理算法 虚拟化领域: 存储虚拟化 算法声明: 虚拟机快照算法用于创建虚拟机在某一时间点的完整状态,包括内存、磁盘和CPU寄存器状态,支持增量快照、差异快照和快照链管理,实现快…...

利用Taotoken实现多模型备选方案以提升业务连续性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken实现多模型备选方案以提升业务连续性 在中大型企业将AI能力集成到关键业务流程时,服务的连续性与稳定性是…...

CVE漏洞编号规范与FortiSandbox安全机制解析
我不能按照您的要求生成关于“CVE-2026-39808 PoC 公开:FortiSandbox 无需认证 root RCE,全网已遭大规模扫描”的博文内容。原因如下:✅该漏洞编号 CVE-2026-39808 为虚构编号CVE 编号遵循严格的时间与分配规则:当前最新公开的 CV…...
)
DeepSeek混合云架构下跨AZ流量调度困局:基于eBPF+Service Mesh的实时负载感知调度器设计(已上线支撑日均2.7亿QPS)
更多请点击: https://codechina.net 第一章:DeepSeek混合云架构下跨AZ流量调度困局的系统性认知 在DeepSeek混合云生产环境中,核心推理服务部署于多可用区(AZ)集群,底层横跨公有云(如AWS us-ea…...

为什么92%的DeepSeek微调失败?资深架构师拆解3类致命配置错误及实时诊断命令
更多请点击: https://kaifayun.com 第一章:DeepSeek模型微调失败率的行业现状与根本归因 近年来,DeepSeek系列大模型(如DeepSeek-V2、DeepSeek-Coder)在开源社区和企业私有化部署中广泛应用,但实证调研显示…...

【Gemini生命周期价值深度解码】:20年AI架构师亲授5大阶段ROI测算模型与避坑指南
更多请点击: https://intelliparadigm.com 第一章:Gemini生命周期价值分析 Gemini 模型的生命周期价值(LTV)不仅体现在其推理性能与多模态能力上,更贯穿于从模型部署、持续微调、监控反馈到迭代升级的完整闭环。相较于…...

观察Taotoken按Token计费模式如何让项目成本更可控
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken按Token计费模式如何让项目成本更可控 对于许多开发团队而言,将大模型能力集成到产品中,除了技…...

从岭回归到Lasso:正则化原理、稀疏性与ADMM算法实践
1. 项目概述:从岭回归到Lasso的深度解析在机器学习和统计建模的实践中,我们常常面临一个核心矛盾:模型在训练数据上表现优异,但在未见过的数据上却一塌糊涂,这就是所谓的“过拟合”。想象一下,你为了记住一…...

为什么92%的团队在DeepSeek边缘部署时失败?——NPU算力调度、TensorRT-LLM适配、冷启动延迟三大隐性瓶颈深度拆解
更多请点击: https://kaifayun.com 第一章:为什么92%的团队在DeepSeek边缘部署时失败?——NPU算力调度、TensorRT-LLM适配、冷启动延迟三大隐性瓶颈深度拆解 在真实边缘场景中,DeepSeek-R1等大模型的部署成功率远低于云环境基准。…...

10分钟搞定Android Studio中文界面:告别英文困扰,让开发效率翻倍提升
10分钟搞定Android Studio中文界面:告别英文困扰,让开发效率翻倍提升 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguag…...