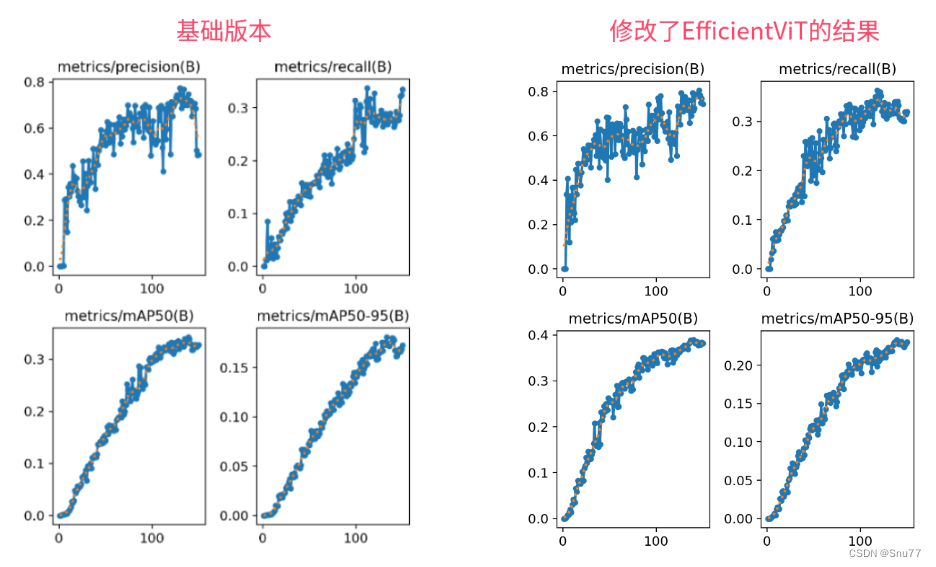
YOLOv8改进 | 主干篇 | EfficientViT高效的特征提取网络完爆MobileNet系列(轻量化网络结构)
一、本文介绍
本文给大家带来的改进机制是主干网络,一个名字EfficientViT的特征提取网络(和之前发布的只是同名但不是同一个),其基本原理是提升视觉变换器在高效处理高分辨率视觉任务的能力。它采用了创新的建筑模块设计,包括三明治布局和级联群组注意力模块。其是一种高效率的特征提取网络训练速度非常快,推理速度也要比基础版本的要快,其效果完爆之前的MobileNetV3等轻量化网络模型。欢迎大家订阅本专栏,本专栏每周更新3-5篇最新机制,更有包含我所有改进的文件和交流群提供给大家。
欢迎大家订阅我的专栏一起学习YOLO!
专栏目录:YOLOv8改进有效系列目录 | 包含卷积、主干、检测头、注意力机制、Neck上百种创新机制
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备
目录
一、本文介绍
二、EfficientViT原理
2.1 EfficientViT的基本原理
三、EfficientViT的核心代码
四、手把手教你添加EfficientVit
4.1 修改一
4.2 修改二
4.3 修改三
4.4 修改四
4.5 修改五
4.6 修改六
4.7 修改七
4.8 修改八
注意!!! 额外的修改!
修改八
注意事项!!!
五、EfficientViT的yaml文件
5.1 训练文件的代码
六、成功运行记录
七、本文总结
二、EfficientViT原理

论文地址:论文官方地址
代码地址:代码官方地址

2.1 EfficientViT的基本原理
EfficientViT的基本原理是提升视觉变换器在高效处理高分辨率视觉任务的能力。它采用了创新的建筑模块设计,包括三明治布局和级联群组注意力模块。
1. 三明治布局:在前馈神经网络(FFN)层之间使用单个受内存限制的多头自注意力机制(MHSA),以提高内存效率。
2. 级联群组注意力模块:通过将不同的特征分割喂给不同的注意力头,减少计算冗余,并提高注意力的多样性。
下面为大家展示了EfficientViT的整体架构和关键组成部分:
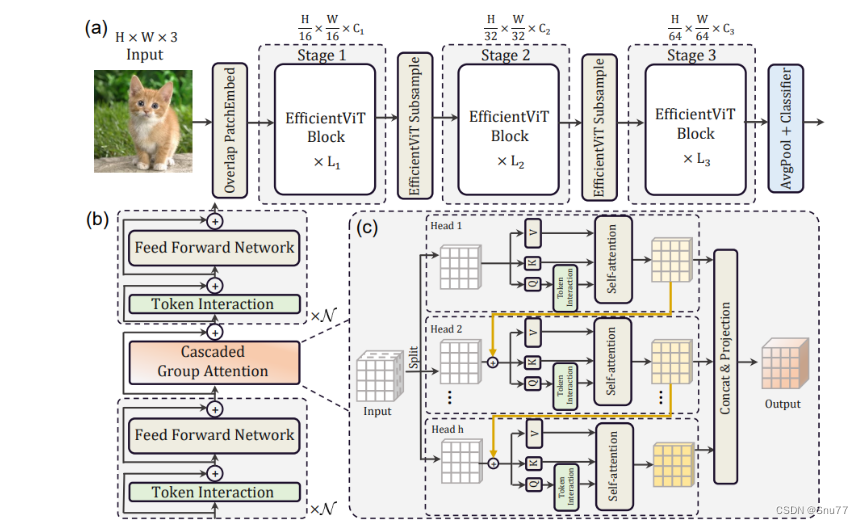
(a). 架构概览:EfficientViT的整体架构分为三个阶段,每个阶段都包含了若干EfficientViT块,随着阶段的进展,特征图的维度会减小,而通道数会增加。
(b). 三明治布局块:展示了EfficientViT块的内部结构,它采用了一种三明治布局,其中的自注意力层(绿色部分)被两层前馈神经网络(FFN)夹在中间。
(c). 级联群组注意力:这是一个创新的注意力机制,通过将输入特征分割成不同的部分,分别喂给
不同的注意力头。
三、EfficientViT的核心代码
代码的使用方式看章节四。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
import itertools
from timm.models.layers import SqueezeExcite
import numpy as np
import itertools__all__ = ['EfficientViT_M0', 'EfficientViT_M1', 'EfficientViT_M2', 'EfficientViT_M3', 'EfficientViT_M4','EfficientViT_M5']class Conv2d_BN(torch.nn.Sequential):def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,groups=1, bn_weight_init=1, resolution=-10000):super().__init__()self.add_module('c', torch.nn.Conv2d(a, b, ks, stride, pad, dilation, groups, bias=False))self.add_module('bn', torch.nn.BatchNorm2d(b))torch.nn.init.constant_(self.bn.weight, bn_weight_init)torch.nn.init.constant_(self.bn.bias, 0)@torch.no_grad()def switch_to_deploy(self):c, bn = self._modules.values()w = bn.weight / (bn.running_var + bn.eps) ** 0.5w = c.weight * w[:, None, None, None]b = bn.bias - bn.running_mean * bn.weight / \(bn.running_var + bn.eps) ** 0.5m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation,groups=self.c.groups)m.weight.data.copy_(w)m.bias.data.copy_(b)return mdef replace_batchnorm(net):for child_name, child in net.named_children():if hasattr(child, 'fuse'):setattr(net, child_name, child.fuse())elif isinstance(child, torch.nn.BatchNorm2d):setattr(net, child_name, torch.nn.Identity())else:replace_batchnorm(child)class PatchMerging(torch.nn.Module):def __init__(self, dim, out_dim, input_resolution):super().__init__()hid_dim = int(dim * 4)self.conv1 = Conv2d_BN(dim, hid_dim, 1, 1, 0, resolution=input_resolution)self.act = torch.nn.ReLU()self.conv2 = Conv2d_BN(hid_dim, hid_dim, 3, 2, 1, groups=hid_dim, resolution=input_resolution)self.se = SqueezeExcite(hid_dim, .25)self.conv3 = Conv2d_BN(hid_dim, out_dim, 1, 1, 0, resolution=input_resolution // 2)def forward(self, x):x = self.conv3(self.se(self.act(self.conv2(self.act(self.conv1(x))))))return xclass Residual(torch.nn.Module):def __init__(self, m, drop=0.):super().__init__()self.m = mself.drop = dropdef forward(self, x):if self.training and self.drop > 0:return x + self.m(x) * torch.rand(x.size(0), 1, 1, 1,device=x.device).ge_(self.drop).div(1 - self.drop).detach()else:return x + self.m(x)class FFN(torch.nn.Module):def __init__(self, ed, h, resolution):super().__init__()self.pw1 = Conv2d_BN(ed, h, resolution=resolution)self.act = torch.nn.ReLU()self.pw2 = Conv2d_BN(h, ed, bn_weight_init=0, resolution=resolution)def forward(self, x):x = self.pw2(self.act(self.pw1(x)))return xclass CascadedGroupAttention(torch.nn.Module):r""" Cascaded Group Attention.Args:dim (int): Number of input channels.key_dim (int): The dimension for query and key.num_heads (int): Number of attention heads.attn_ratio (int): Multiplier for the query dim for value dimension.resolution (int): Input resolution, correspond to the window size.kernels (List[int]): The kernel size of the dw conv on query."""def __init__(self, dim, key_dim, num_heads=8,attn_ratio=4,resolution=14,kernels=[5, 5, 5, 5], ):super().__init__()self.num_heads = num_headsself.scale = key_dim ** -0.5self.key_dim = key_dimself.d = int(attn_ratio * key_dim)self.attn_ratio = attn_ratioqkvs = []dws = []for i in range(num_heads):qkvs.append(Conv2d_BN(dim // (num_heads), self.key_dim * 2 + self.d, resolution=resolution))dws.append(Conv2d_BN(self.key_dim, self.key_dim, kernels[i], 1, kernels[i] // 2, groups=self.key_dim,resolution=resolution))self.qkvs = torch.nn.ModuleList(qkvs)self.dws = torch.nn.ModuleList(dws)self.proj = torch.nn.Sequential(torch.nn.ReLU(), Conv2d_BN(self.d * num_heads, dim, bn_weight_init=0, resolution=resolution))points = list(itertools.product(range(resolution), range(resolution)))N = len(points)attention_offsets = {}idxs = []for p1 in points:for p2 in points:offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))if offset not in attention_offsets:attention_offsets[offset] = len(attention_offsets)idxs.append(attention_offsets[offset])self.attention_biases = torch.nn.Parameter(torch.zeros(num_heads, len(attention_offsets)))self.register_buffer('attention_bias_idxs',torch.LongTensor(idxs).view(N, N))@torch.no_grad()def train(self, mode=True):super().train(mode)if mode and hasattr(self, 'ab'):del self.abelse:self.ab = self.attention_biases[:, self.attention_bias_idxs]def forward(self, x): # x (B,C,H,W)B, C, H, W = x.shapetrainingab = self.attention_biases[:, self.attention_bias_idxs]feats_in = x.chunk(len(self.qkvs), dim=1)feats_out = []feat = feats_in[0]for i, qkv in enumerate(self.qkvs):if i > 0: # add the previous output to the inputfeat = feat + feats_in[i]feat = qkv(feat)q, k, v = feat.view(B, -1, H, W).split([self.key_dim, self.key_dim, self.d], dim=1) # B, C/h, H, Wq = self.dws[i](q)q, k, v = q.flatten(2), k.flatten(2), v.flatten(2) # B, C/h, Nattn = ((q.transpose(-2, -1) @ k) * self.scale+(trainingab[i] if self.training else self.ab[i]))attn = attn.softmax(dim=-1) # BNNfeat = (v @ attn.transpose(-2, -1)).view(B, self.d, H, W) # BCHWfeats_out.append(feat)x = self.proj(torch.cat(feats_out, 1))return xclass LocalWindowAttention(torch.nn.Module):r""" Local Window Attention.Args:dim (int): Number of input channels.key_dim (int): The dimension for query and key.num_heads (int): Number of attention heads.attn_ratio (int): Multiplier for the query dim for value dimension.resolution (int): Input resolution.window_resolution (int): Local window resolution.kernels (List[int]): The kernel size of the dw conv on query."""def __init__(self, dim, key_dim, num_heads=8,attn_ratio=4,resolution=14,window_resolution=7,kernels=[5, 5, 5, 5], ):super().__init__()self.dim = dimself.num_heads = num_headsself.resolution = resolutionassert window_resolution > 0, 'window_size must be greater than 0'self.window_resolution = window_resolutionself.attn = CascadedGroupAttention(dim, key_dim, num_heads,attn_ratio=attn_ratio,resolution=window_resolution,kernels=kernels, )def forward(self, x):B, C, H, W = x.shapeif H <= self.window_resolution and W <= self.window_resolution:x = self.attn(x)else:x = x.permute(0, 2, 3, 1)pad_b = (self.window_resolution - H %self.window_resolution) % self.window_resolutionpad_r = (self.window_resolution - W %self.window_resolution) % self.window_resolutionpadding = pad_b > 0 or pad_r > 0if padding:x = torch.nn.functional.pad(x, (0, 0, 0, pad_r, 0, pad_b))pH, pW = H + pad_b, W + pad_rnH = pH // self.window_resolutionnW = pW // self.window_resolution# window partition, BHWC -> B(nHh)(nWw)C -> BnHnWhwC -> (BnHnW)hwC -> (BnHnW)Chwx = x.view(B, nH, self.window_resolution, nW, self.window_resolution, C).transpose(2, 3).reshape(B * nH * nW, self.window_resolution, self.window_resolution, C).permute(0, 3, 1, 2)x = self.attn(x)# window reverse, (BnHnW)Chw -> (BnHnW)hwC -> BnHnWhwC -> B(nHh)(nWw)C -> BHWCx = x.permute(0, 2, 3, 1).view(B, nH, nW, self.window_resolution, self.window_resolution,C).transpose(2, 3).reshape(B, pH, pW, C)if padding:x = x[:, :H, :W].contiguous()x = x.permute(0, 3, 1, 2)return xclass EfficientViTBlock(torch.nn.Module):""" A basic EfficientViT building block.Args:type (str): Type for token mixer. Default: 's' for self-attention.ed (int): Number of input channels.kd (int): Dimension for query and key in the token mixer.nh (int): Number of attention heads.ar (int): Multiplier for the query dim for value dimension.resolution (int): Input resolution.window_resolution (int): Local window resolution.kernels (List[int]): The kernel size of the dw conv on query."""def __init__(self, type,ed, kd, nh=8,ar=4,resolution=14,window_resolution=7,kernels=[5, 5, 5, 5], ):super().__init__()self.dw0 = Residual(Conv2d_BN(ed, ed, 3, 1, 1, groups=ed, bn_weight_init=0., resolution=resolution))self.ffn0 = Residual(FFN(ed, int(ed * 2), resolution))if type == 's':self.mixer = Residual(LocalWindowAttention(ed, kd, nh, attn_ratio=ar, \resolution=resolution, window_resolution=window_resolution,kernels=kernels))self.dw1 = Residual(Conv2d_BN(ed, ed, 3, 1, 1, groups=ed, bn_weight_init=0., resolution=resolution))self.ffn1 = Residual(FFN(ed, int(ed * 2), resolution))def forward(self, x):return self.ffn1(self.dw1(self.mixer(self.ffn0(self.dw0(x)))))class EfficientViT(torch.nn.Module):def __init__(self, img_size=400,patch_size=16,frozen_stages=0,in_chans=3,stages=['s', 's', 's'],embed_dim=[64, 128, 192],key_dim=[16, 16, 16],depth=[1, 2, 3],num_heads=[4, 4, 4],window_size=[7, 7, 7],kernels=[5, 5, 5, 5],down_ops=[['subsample', 2], ['subsample', 2], ['']],pretrained=None,distillation=False, ):super().__init__()resolution = img_sizeself.patch_embed = torch.nn.Sequential(Conv2d_BN(in_chans, embed_dim[0] // 8, 3, 2, 1, resolution=resolution),torch.nn.ReLU(),Conv2d_BN(embed_dim[0] // 8, embed_dim[0] // 4, 3, 2, 1,resolution=resolution // 2), torch.nn.ReLU(),Conv2d_BN(embed_dim[0] // 4, embed_dim[0] // 2, 3, 2, 1,resolution=resolution // 4), torch.nn.ReLU(),Conv2d_BN(embed_dim[0] // 2, embed_dim[0], 3, 1, 1,resolution=resolution // 8))resolution = img_size // patch_sizeattn_ratio = [embed_dim[i] / (key_dim[i] * num_heads[i]) for i in range(len(embed_dim))]self.blocks1 = []self.blocks2 = []self.blocks3 = []for i, (stg, ed, kd, dpth, nh, ar, wd, do) in enumerate(zip(stages, embed_dim, key_dim, depth, num_heads, attn_ratio, window_size, down_ops)):for d in range(dpth):eval('self.blocks' + str(i + 1)).append(EfficientViTBlock(stg, ed, kd, nh, ar, resolution, wd, kernels))if do[0] == 'subsample':# ('Subsample' stride)blk = eval('self.blocks' + str(i + 2))resolution_ = (resolution - 1) // do[1] + 1blk.append(torch.nn.Sequential(Residual(Conv2d_BN(embed_dim[i], embed_dim[i], 3, 1, 1, groups=embed_dim[i], resolution=resolution)),Residual(FFN(embed_dim[i], int(embed_dim[i] * 2), resolution)), ))blk.append(PatchMerging(*embed_dim[i:i + 2], resolution))resolution = resolution_blk.append(torch.nn.Sequential(Residual(Conv2d_BN(embed_dim[i + 1], embed_dim[i + 1], 3, 1, 1, groups=embed_dim[i + 1],resolution=resolution)),Residual(FFN(embed_dim[i + 1], int(embed_dim[i + 1] * 2), resolution)), ))self.blocks1 = torch.nn.Sequential(*self.blocks1)self.blocks2 = torch.nn.Sequential(*self.blocks2)self.blocks3 = torch.nn.Sequential(*self.blocks3)self.width_list = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]def forward(self, x):outs = []x = self.patch_embed(x)outs.append(x)x = self.blocks1(x)outs.append(x)x = self.blocks2(x)outs.append(x)x = self.blocks3(x)outs.append(x)return outsEfficientViT_m0 = {'img_size': 224,'patch_size': 16,'embed_dim': [64, 128, 192],'depth': [1, 2, 3],'num_heads': [4, 4, 4],'window_size': [7, 7, 7],'kernels': [7, 5, 3, 3],
}EfficientViT_m1 = {'img_size': 224,'patch_size': 16,'embed_dim': [128, 144, 192],'depth': [1, 2, 3],'num_heads': [2, 3, 3],'window_size': [7, 7, 7],'kernels': [7, 5, 3, 3],
}EfficientViT_m2 = {'img_size': 224,'patch_size': 16,'embed_dim': [128, 192, 224],'depth': [1, 2, 3],'num_heads': [4, 3, 2],'window_size': [7, 7, 7],'kernels': [7, 5, 3, 3],
}EfficientViT_m3 = {'img_size': 224,'patch_size': 16,'embed_dim': [128, 240, 320],'depth': [1, 2, 3],'num_heads': [4, 3, 4],'window_size': [7, 7, 7],'kernels': [5, 5, 5, 5],
}EfficientViT_m4 = {'img_size': 224,'patch_size': 16,'embed_dim': [128, 256, 384],'depth': [1, 2, 3],'num_heads': [4, 4, 4],'window_size': [7, 7, 7],'kernels': [7, 5, 3, 3],
}EfficientViT_m5 = {'img_size': 224,'patch_size': 16,'embed_dim': [192, 288, 384],'depth': [1, 3, 4],'num_heads': [3, 3, 4],'window_size': [7, 7, 7],'kernels': [7, 5, 3, 3],
}def EfficientViT_M0(pretrained='', frozen_stages=0, distillation=False, fuse=False, pretrained_cfg=None,model_cfg=EfficientViT_m0):model = EfficientViT(frozen_stages=frozen_stages, distillation=distillation, pretrained=pretrained, **model_cfg)if pretrained:model.load_state_dict(update_weight(model.state_dict(), torch.load(pretrained)['model']))if fuse:replace_batchnorm(model)return modeldef EfficientViT_M1(pretrained='', frozen_stages=0, distillation=False, fuse=False, pretrained_cfg=None,model_cfg=EfficientViT_m1):model = EfficientViT(frozen_stages=frozen_stages, distillation=distillation, pretrained=pretrained, **model_cfg)if pretrained:model.load_state_dict(update_weight(model.state_dict(), torch.load(pretrained)['model']))if fuse:replace_batchnorm(model)return modeldef EfficientViT_M2(pretrained='', frozen_stages=0, distillation=False, fuse=False, pretrained_cfg=None,model_cfg=EfficientViT_m2):model = EfficientViT(frozen_stages=frozen_stages, distillation=distillation, pretrained=pretrained, **model_cfg)if pretrained:model.load_state_dict(update_weight(model.state_dict(), torch.load(pretrained)['model']))if fuse:replace_batchnorm(model)return modeldef EfficientViT_M3(pretrained='', frozen_stages=0, distillation=False, fuse=False, pretrained_cfg=None,model_cfg=EfficientViT_m3):model = EfficientViT(frozen_stages=frozen_stages, distillation=distillation, pretrained=pretrained, **model_cfg)if pretrained:model.load_state_dict(update_weight(model.state_dict(), torch.load(pretrained)['model']))if fuse:replace_batchnorm(model)return modeldef EfficientViT_M4(pretrained='', frozen_stages=0, distillation=False, fuse=False, pretrained_cfg=None,model_cfg=EfficientViT_m4):model = EfficientViT(frozen_stages=frozen_stages, distillation=distillation, pretrained=pretrained, **model_cfg)if pretrained:model.load_state_dict(update_weight(model.state_dict(), torch.load(pretrained)['model']))if fuse:replace_batchnorm(model)return modeldef EfficientViT_M5(pretrained='', frozen_stages=0, distillation=False, fuse=False, pretrained_cfg=None,model_cfg=EfficientViT_m5):model = EfficientViT(frozen_stages=frozen_stages, distillation=distillation, pretrained=pretrained, **model_cfg)if pretrained:model.load_state_dict(update_weight(model.state_dict(), torch.load(pretrained)['model']))if fuse:replace_batchnorm(model)return modeldef update_weight(model_dict, weight_dict):idx, temp_dict = 0, {}for k, v in weight_dict.items():# k = k[9:]if k in model_dict.keys() and np.shape(model_dict[k]) == np.shape(v):temp_dict[k] = vidx += 1model_dict.update(temp_dict)print(f'loading weights... {idx}/{len(model_dict)} items')return model_dict四、手把手教你添加EfficientVit
4.1 修改一
第一步还是建立文件,我们找到如下ultralytics/nn/modules文件夹下建立一个目录名字呢就是'Addmodules'文件夹(用群内的文件的话已经有了无需新建)!然后在其内部建立一个新的py文件将核心代码复制粘贴进去即可。
此处需要注意我们之前已经修改过一个EfficientViT了,所以这里需要加一个2,其模型为名字重复实际不是一个。
4.2 修改二
第二步我们在该目录下创建一个新的py文件名字为'__init__.py'(用群内的文件的话已经有了无需新建),然后在其内部导入我们的检测头如下图所示。
4.3 修改三
第三步我门中到如下文件'ultralytics/nn/tasks.py'进行导入和注册我们的模块(用群内的文件的话已经有了无需重新导入直接开始第四步即可)!
从今天开始以后的教程就都统一成这个样子了,因为我默认大家用了我群内的文件来进行修改!!
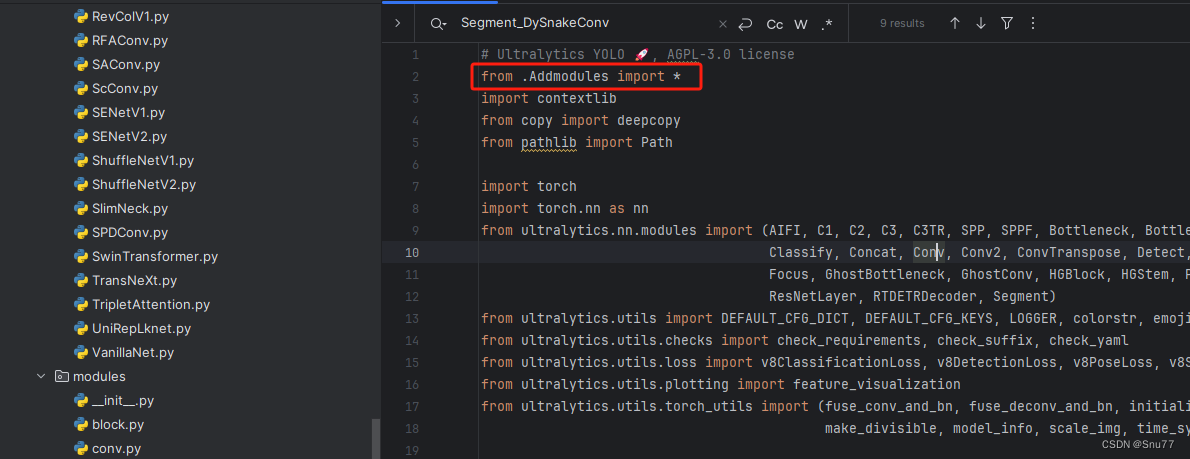
4.4 修改四
添加如下两行代码!!!

4.5 修改五
找到七百多行大概把具体看图片,按照图片来修改就行,添加红框内的部分,注意没有()只是函数名。

elif m in {自行添加对应的模型即可,下面都是一样的}:m = m(*args)c2 = m.width_list # 返回通道列表backbone = True4.6 修改六
下面的两个红框内都是需要改动的。

if isinstance(c2, list):m_ = mm_.backbone = Trueelse:m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace('__main__.', '') # module typem.np = sum(x.numel() for x in m_.parameters()) # number paramsm_.i, m_.f, m_.type = i + 4 if backbone else i, f, t # attach index, 'from' index, type4.7 修改七
如下的也需要修改,全部按照我的来。
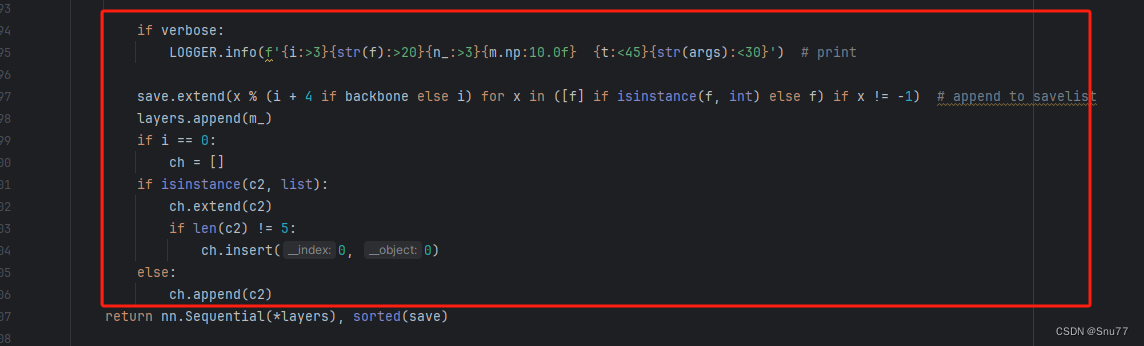
代码如下把原先的代码替换了即可。
if verbose:LOGGER.info(f'{i:>3}{str(f):>20}{n_:>3}{m.np:10.0f} {t:<45}{str(args):<30}') # printsave.extend(x % (i + 4 if backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelistlayers.append(m_)if i == 0:ch = []if isinstance(c2, list):ch.extend(c2)if len(c2) != 5:ch.insert(0, 0)else:ch.append(c2)4.8 修改八
修改七和前面的都不太一样,需要修改前向传播中的一个部分, 已经离开了parse_model方法了。
可以在图片中开代码行数,没有离开task.py文件都是同一个文件。 同时这个部分有好几个前向传播都很相似,大家不要看错了,是70多行左右的!!!,同时我后面提供了代码,大家直接复制粘贴即可,有时间我针对这里会出一个视频。

代码如下->
def _predict_once(self, x, profile=False, visualize=False):"""Perform a forward pass through the network.Args:x (torch.Tensor): The input tensor to the model.profile (bool): Print the computation time of each layer if True, defaults to False.visualize (bool): Save the feature maps of the model if True, defaults to False.Returns:(torch.Tensor): The last output of the model."""y, dt = [], [] # outputsfor m in self.model:if m.f != -1: # if not from previous layerx = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layersif profile:self._profile_one_layer(m, x, dt)if hasattr(m, 'backbone'):x = m(x)if len(x) != 5: # 0 - 5x.insert(0, None)for index, i in enumerate(x):if index in self.save:y.append(i)else:y.append(None)x = x[-1] # 最后一个输出传给下一层else:x = m(x) # runy.append(x if m.i in self.save else None) # save outputif visualize:feature_visualization(x, m.type, m.i, save_dir=visualize)return x到这里就完成了修改部分,但是这里面细节很多,大家千万要注意不要替换多余的代码,导致报错,也不要拉下任何一部,都会导致运行失败,而且报错很难排查!!!很难排查!!!
注意!!! 额外的修改!
关注我的其实都知道,我大部分的修改都是一样的,这个网络需要额外的修改一步,就是s一个参数,将下面的s改为640!!!即可完美运行!!

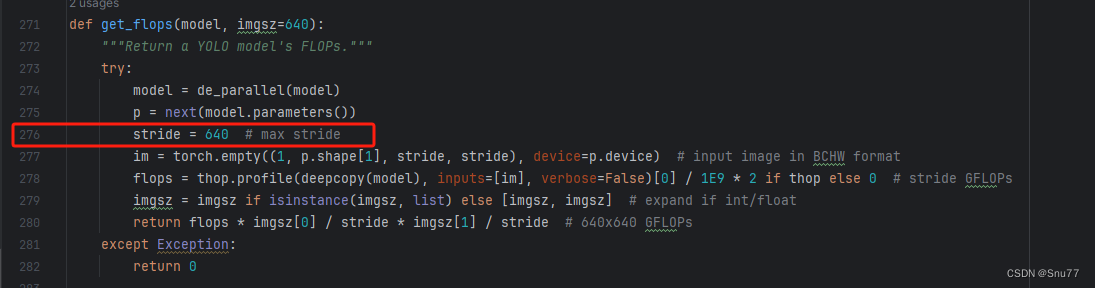
修改八
我们找到如下文件'ultralytics/utils/torch_utils.py'按照如下的图片进行修改,否则容易打印不出来计算量。
注意事项!!!
如果大家在验证的时候报错形状不匹配的错误可以固定验证集的图片尺寸,方法如下 ->
找到下面这个文件ultralytics/models/yolo/detect/train.py然后其中有一个类是DetectionTrainer class中的build_dataset函数中的一个参数rect=mode == 'val'改为rect=False

五、EfficientViT的yaml文件
复制如下yaml文件进行运行!!!
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, EfficientViT_M0, []] # 4 大家可以下载官方的与训练权重进行加载训练用字符串格式放在参数list里就行- [-1, 1, SPPF, [1024, 5]] # 5# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 6- [[-1, 3], 1, Concat, [1]] # 7 cat backbone P4- [-1, 3, C2f, [512]] # 8- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 9- [[-1, 2], 1, Concat, [1]] # 10 cat backbone P3- [-1, 3, C2f, [256]] # 11 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]] # 12- [[-1, 8], 1, Concat, [1]] # 13 cat head P4- [-1, 3, C2f, [512]] # 14 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]] # 15- [[-1, 5], 1, Concat, [1]] # 16 cat head P5- [-1, 3, C2f, [1024]] # 17 (P5/32-large)- [[11, 14, 17], 1, Detect, [nc]] # Detect(P3, P4, P5)
5.1 训练文件的代码
可以复制我的运行文件进行运行。
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':model = YOLO("替换你的yaml文件地址")model.load('yolov8n.pt') model.train(data=r'你的数据集的地址',cache=False,imgsz=640,epochs=150,batch=4,close_mosaic=0,workers=0,device=0,optimizer='SGD'amp=False,)
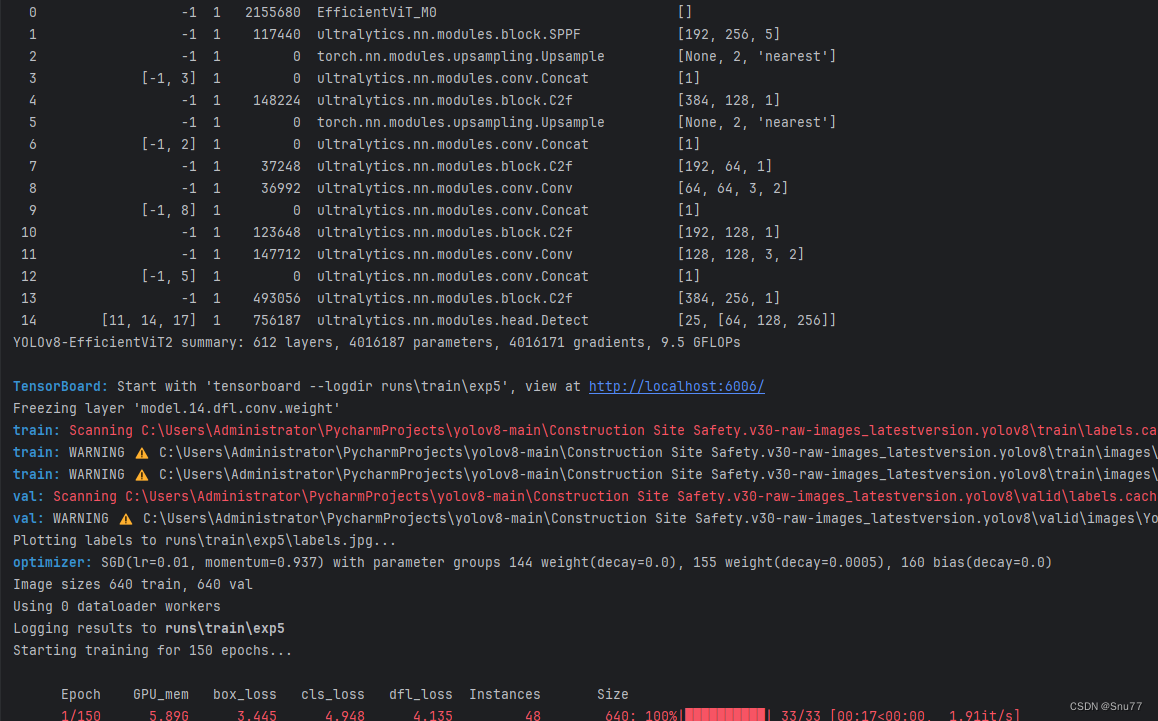
六、成功运行记录
下面是成功运行的截图,已经完成了有1个epochs的训练,图片太大截不全第2个epochs了。
七、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备

相关文章:
YOLOv8改进 | 主干篇 | EfficientViT高效的特征提取网络完爆MobileNet系列(轻量化网络结构)
一、本文介绍 本文给大家带来的改进机制是主干网络,一个名字EfficientViT的特征提取网络(和之前发布的只是同名但不是同一个),其基本原理是提升视觉变换器在高效处理高分辨率视觉任务的能力。它采用了创新的建筑模块设计,包括三明治布局和级联…...
分布式限流要注意的问题
本文已收录至我的个人网站:程序员波特,主要记录Java相关技术系列教程,共享电子书、Java学习路线、视频教程、简历模板和面试题等学习资源,让想要学习的你,不再迷茫。 为什么需要匀速限流 同学们回想一下在Guava小节里…...

git将一个远程分支的部分修改提交到另一个远程分支
将一个远程分支的部分修改提交到另一个远程分支 将一个远程分支的部分修改提交到另一个远程分支,可以使用 git cherry-pick 命令。这个命令可以选择特定的提交(commit)从一个分支应用到另一个分支。 切换到目标本地分支: 首先&am…...

promise是什么怎么使用
Promise 是一种 JavaScript 中的对象,用于处理异步操作。它表示一个最终可能完成(解析)或失败(拒绝)的操作,以及其结果值。 Promise 有三种状态: Pending(待定)&#x…...

国际版WPS Office 18.6.1
【应用名称】:WPS Office 【适用平台】:#Android 【软件标签】:#WPS 【应用版本】:18.6.1 【应用大小】:160MB 【软件说明】:软件日常更新。WPS Office是使用人数最多的移动办公软件。独有手机阅读模式…...

记录一次数据中包含转义字符\引发的bug
后端返回给前端的数据是: { "bizObj": { "current": 1, "orders": [ ], "pages": 2, "records": [ { "from": "1d85b8a4bd33aaf99adc2e71ef02960e", …...
网络协议:ICMP协议及实用工具介绍
目 录 一、ICMP介绍 1、概述 2、功能 3、特点 二、ICMP的数据报文 三、ICMP相关工具 四、主要ICMP工具应用 1、Ping 2、Traceroute (1) 方法1: (2)方法2: 3、Nmap 一、ICMP介绍 1、概述 …...
Hyper-V如何设置网络-虚拟交换机设置
Hyper-V如何设置网络-虚拟交换机设置 缘起虚拟交换机类型1. 外部交换机;2. 内部交换机;3. 专用交换机;4.default switch; 虚拟机上openwrt多种网络连接方式 缘起 发现win10还有个虚拟机Hyper-V的功能,不太占资源&…...
SAP不同语言开发
文章目录 1 Please write English Nmae2 go to goto menu and translation3 Write your target language .4 Please input Chinese5 Summary 1 Please write English Nmae 2 go to goto menu and translation 3 Write your target language . 4 Please input Chinese 5 Summary…...

瑞_Java开发手册_(一)编程规约
文章目录 编程规约的意义(一)命名风格(二)常量定义(三)代码格式(四)OOP 规约(五)日期时间(六)集合处理(七)并发…...

【JVM】本地方法接口 Native Interface
一、JNI简介 JVM本地方法接口(Java Native Interface,JNI)是一种允许Java代码调用本地方法(如C或C编写的方法)的机制。这种技术通常用于实现高性能的计算密集型任务,或者与底层系统库进行交互。 二、JNI组…...
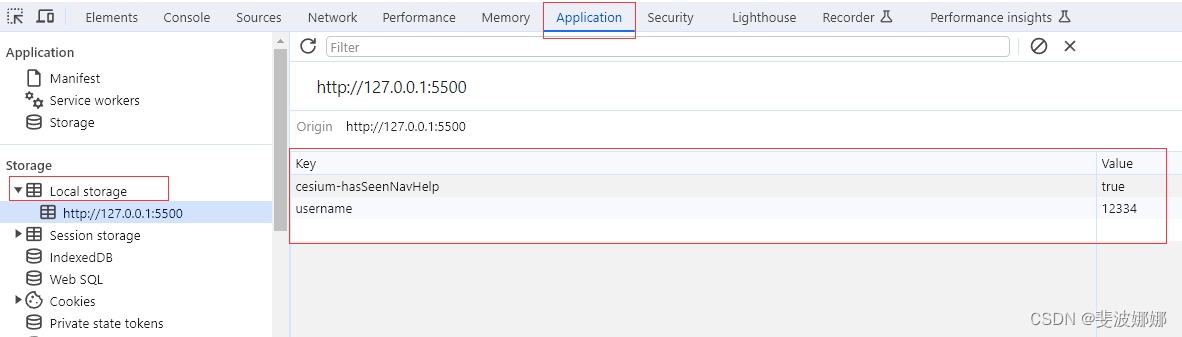
JS 本地存储 sessionStorage localStorage
本地存储 随着互联网的快速发展,基于网页的应用越来越普遍,同时也变的越来越复杂,为了满足各种各样的需求,会经常性在本地存储大量的数据,HTML5规范提出了相关解决方案。 本地存储特性 1、数据存储在用户浏览器中 2…...
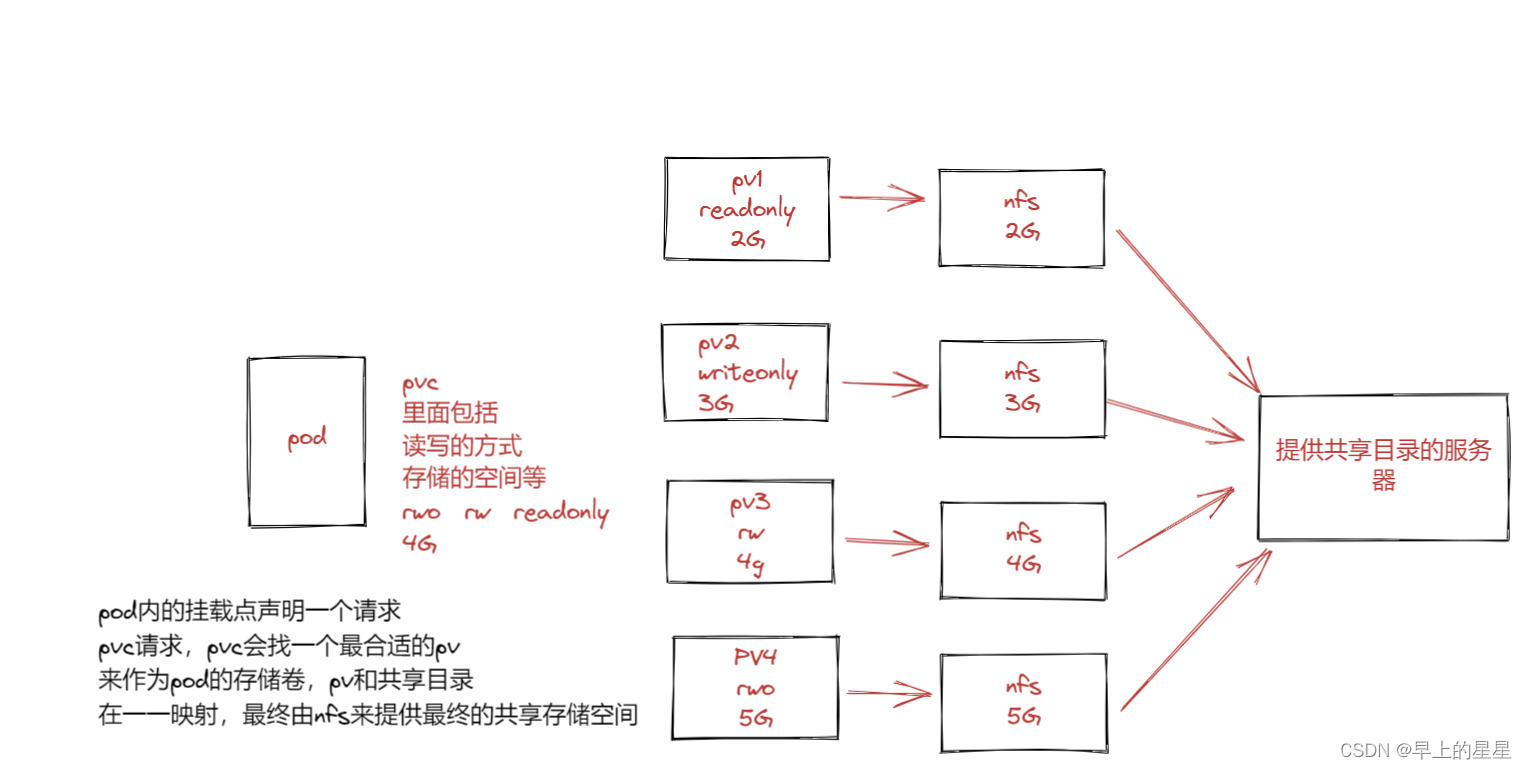
K8S 存储卷
意义:存储卷----数据卷 容器内的目录和宿主机的目录进行挂载 容器在系统上的生命周期是短暂的,delete,k8s用控制器创建的pod,delete相当于重启,容器的状态也会回复到初始状态 一旦回到初始状态,所有的后天编辑的文件…...

一个SqlSugar实际案例
SqlGugar是一个非常好的数据库操作框架,今天用一个示例来分享如何使用。 新建一张课程表 结构如下: CREATE TABLE t_course (id int NOT NULL AUTO_INCREMENT COMMENT ID,title varchar(1024) NOT NULL COMMENT 课程标题,description text NOT NULL C…...

【RT-DETR有效改进】ShapeIoU、InnerShapeIoU关注边界框本身的IoU(包含二次创新)
前言 大家好,我是Snu77,这里是RT-DETR有效涨点专栏。 本专栏的内容为根据ultralytics版本的RT-DETR进行改进,内容持续更新,每周更新文章数量3-10篇。 专栏以ResNet18、ResNet50为基础修改版本,同时修改内容也支持Re…...
从理论到实践:数字孪生技术的全面应用探讨
数字孪生是一种将实际物体或系统的数字模型与其实时运行状态相结合的概念。这一概念的核心在于创建一个虚拟的、与真实世界相对应的数字副本,以便监测、分析和优化实体系统的性能。 简单理解,数字孪生就是在一个设备或系统的基础上,创造一个…...
2.1.2 一个关于y=ax+b的故事
跳转到根目录:知行合一:投资篇 已完成: 1、投资&技术 1.1.1 投资-编程基础-numpy 1.1.2 投资-编程基础-pandas 1.2 金融数据处理 1.3 金融数据可视化 2、投资方法论 2.1.1 预期年化收益率 2.1.2 一个关于yaxb的…...
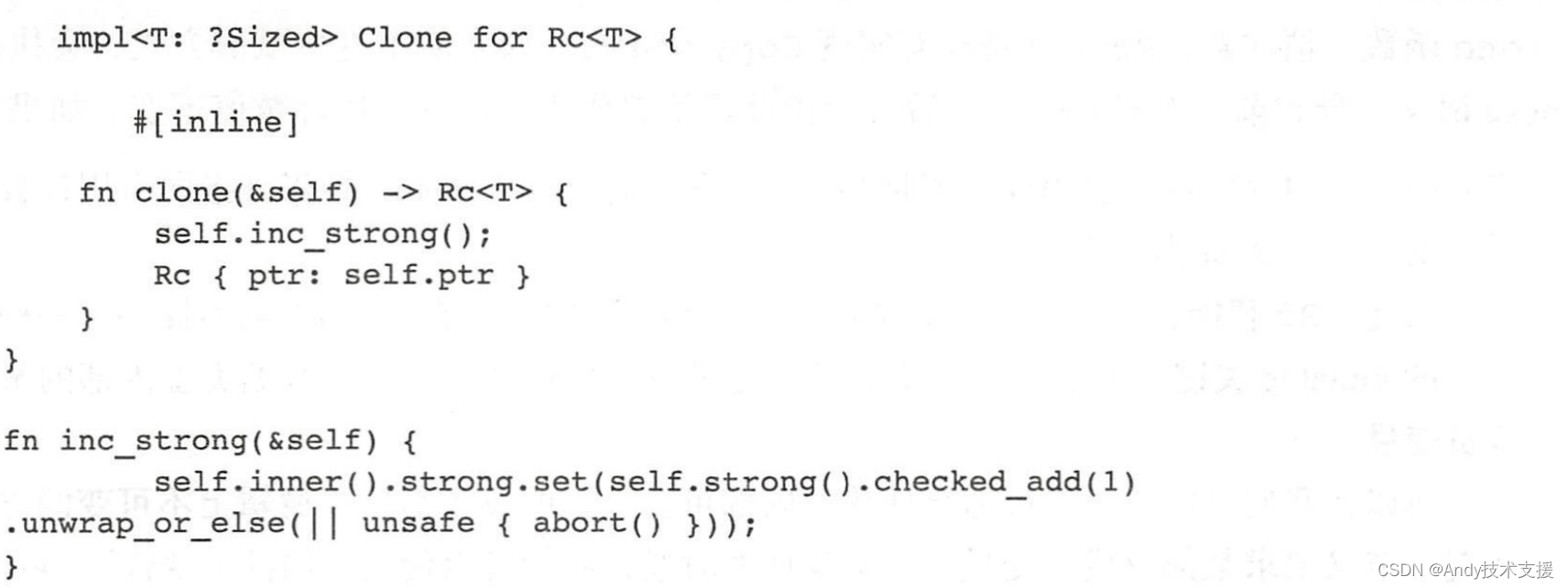
Rust-解引用
“解引用”(Deref)是“取引用”(Ref)的反操作。取引用,我们有&、&mut等操作符,对应的,解引用,我们有操作符,跟C语言是一样的。示例如下: 比如说,我们有引用类型p:&i32;,那么可以用符…...

记录一下vue项目引入百度地图
公共部分 #allmap { width: 500px; height: 500px; font-family: "微软雅黑"; } 1、 <div id"allmap"> <baidu-map :center"center" :zoom"zoom" ready"handler"></baidu-map> </div> data()…...

基于Docker官方php:7.4.33-fpm镜像构建支持67个常见模组的php7.4.33镜像
实践说明:基于RHEL7(CentOS7.9)部署docker环境(23.0.1、24.0.2),所构建的php7.4.33镜像应用于RHEL7-9(如AlmaLinux9.1),但因为docker的特性,适用场景是不限于此的。 文档形成时期:2017-2023年 因系统或软件版本不同&am…...

5大AI音频处理插件:用OpenVINO为Audacity注入本地智能处理能力
5大AI音频处理插件:用OpenVINO为Audacity注入本地智能处理能力 【免费下载链接】openvino-plugins-ai-audacity A set of AI-enabled effects, generators, and analyzers for Audacity. 项目地址: https://gitcode.com/gh_mirrors/op/openvino-plugins-ai-audaci…...

在Python项目中实现故障转移通过Taotoken自动切换备用大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Python项目中实现故障转移通过Taotoken自动切换备用大模型 应用场景类,面向构建高可用AI应用的中高级开发者。当核心…...

告别黄牛票:用DamaiHelper脚本轻松抢到大麦网演唱会门票
告别黄牛票:用DamaiHelper脚本轻松抢到大麦网演唱会门票 【免费下载链接】DamaiHelper 大麦网演唱会演出抢票脚本。 项目地址: https://gitcode.com/gh_mirrors/dama/DamaiHelper 还在为抢不到心仪的演唱会门票而烦恼吗?面对秒光的票源和黄牛的高…...

League-Toolkit:英雄联盟玩家的智能自动化助手终极指南
League-Toolkit:英雄联盟玩家的智能自动化助手终极指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为繁琐的游戏操作而烦恼…...

Python Android打包终极指南:3种架构方案解决跨平台开发痛点
Python Android打包终极指南:3种架构方案解决跨平台开发痛点 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-android(简称…...

对比直接使用厂商API,Taotoken在稳定性方面的补充价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商API,Taotoken在稳定性方面的补充价值 在构建依赖大模型能力的应用时,开发者通常会直接调用…...

零起点Python机器学习快速入门【1.0】
第 1 章 从阿尔法狗开始说起1.1 阿尔法狗的前世今生百度百科的“阿尔法狗”词条是:阿尔法狗( AlphaGo)是一款围棋人工智能程序,由谷歌( Google)旗下 DeepMind 公司的戴密斯哈萨比斯、大卫席尔瓦、黄士杰与他…...

开发者在进行多轮对话应用测试时如何利用Taotoken快速切换模型对比
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发者在进行多轮对话应用测试时如何利用Taotoken快速切换模型对比 在开发基于大语言模型的多轮对话应用时,评估不同模…...

【专业级】Draw.io ECE电路设计库:电子工程师的绘图效率革命
【专业级】Draw.io ECE电路设计库:电子工程师的绘图效率革命 【免费下载链接】Draw-io-ECE Custom-made draw.io-shapes - in the form of an importable library - for drawing circuits and conceptual drawings in draw.io. 项目地址: https://gitcode.com/gh_…...

反诈渗透测试实战:绕过人的决策链而非系统漏洞
1. 这不是黑客炫技,而是一次真实的反诈防线压力测试 “我们刚上线的反诈预警弹窗,被内部员工用三分钟绕过了。” 这句话是我在某地市反诈中心做驻场支持时,接到的第一通电话。不是红蓝对抗演练通知,不是安全培训课件里的假设场景…...