LLM:Training Compute-Optimal Large Language Models
论文:https://arxiv.org/pdf/2203.15556.pdf
发表:2022

前文回顾:
OpenAI在2020年提出《Scaling Laws for Neural Language Models》:Scaling Laws(缩放法则)也一直影响了后续大模型的训练。其给出的结论是最佳计算效率训练涉及在相对适中的数据量上训练非常大的模型并在收敛之前early stopping。所以后续的工作都专注于提升参数规模,设计越来越大的模型,而不是在更多的数据上训练较小的模型。每个人都认为模型大小比数据大小重要的多得多!但DeepMind在2022年提出了不同的看法。
摘要

1:目前的LLM大模型训练都不够充分,原因是:大部分精力主要花费在扩大模型尺寸上,训练数据却没有同步增长。(这个主要是受OpenAI论文观点的影响)
2:DeepMind团队发现:最优的训练是模型尺寸和训练的Token数量应该是等比例增长。如果模型尺寸翻倍,token数量也应该翻倍。
简介

DeepMind得到了与OpenAI相同的结论:大模型在训练到loss最低前已经到算力最优了,即在收敛前进行early stopping。尽管得出了同样的结论,但DeepMind认为:大型模型应训练更多的token,远超过OPenAI作者推荐的数量。具体来说,给定计算预算增加10倍,OpenAI建议模型大小应增加5.5倍,而训练token数量只应增加1.8倍。相反,DeepMind认为模型大小和训练令牌数量应该以相同的比例增长。
相关工作

OpenAI首先观测到了scale law法则,DeepMind也采用了相同的技术手段:训练不同尺寸的模型,然后进行观测。但他们存在以下不同点。
1:OpenAI固定了训练的token数目以及学习率方案,这阻止了他们研究这些超参数对损失的影响。相反,DeepMind发现将学习率调度设置为大约匹配训练token数量可以导致最好的最终损失,无论模型大小如何。作者举例:130B token,使用cosine学习率。因为会在收敛前进行早停,所以观测到的都是中间状态(即训练token数量还没有到130B token 时候的loss),使用这些中间损失观测,导致对训练模型在小于130B token的数据上的有效性的低估,并最终导致了一个结论,即模型大小应比训练数据大小增长得更快。DeepMind的观点是同比例缩放。
2:OpenAI使用的模型参数量比较小,DeepMind观测的范围更广。
3 估计最优的参数 / 训练token数目
 首先训练一系列模型:模型大小和训练数据数量两方面都有所不同,然后使用所得到的训练曲线来拟合他们应该满足的经验规律。
首先训练一系列模型:模型大小和训练数据数量两方面都有所不同,然后使用所得到的训练曲线来拟合他们应该满足的经验规律。

训练70M到10B的一系列模型大小,每个模型大小针对四个不同的余弦周期长度进行训练。从这些曲线中,提取了每FLOP最小损失的包络,并用这些点来估计给定计算量条件下最优模型大小以及最优训练token数。(此处的scale law 实践与OpenAI一致)。从上图不难看出:模型越大,需要的算力越大,需要的token也越多。
左图可以看到计算量与模型性能呈现幂律关系(可以认为数据和模型都不受限制),根据中图和右图,可以发现,
,即计算效率最优时,模型的参数与计算量的幂次成线性关系,数据量的大小也与计算量的幂次成线性关系。
根据C=6ND,可以推算出a+b=1,但是a,b分别是多少存在分歧。
OpenAI:认为模型规模更重要,即a=0.73, b=0.27,
DeepMind在Chinchilla工作和Google在PaLM工作中都验证了 a=b=0.5 ,即模型和数据同等重要。
所以假定计算量整体放大10倍,OpenAI认为模型参数更重要,模型应放大 (5.32)倍,数据放大
(1.86)倍;后来DeepMind和Google认为模型参数量与数据同等重要,两者都应该分别放大
(3.16)倍。
3.1 方案1:固定模型,训练不同的token数目

通过方案1,得到N、D与C的幂次关系:模型尺寸和数据量同等重要,缩放比例相同,均为0.5。
3.2 方案2:固定FLOP

选取9种不同的计算量:e18−e21 ,观测不同参数量模型的训练情况:
在每条曲线的最小值的左侧,模型太小——在较少数据上训练的较大模型将是一种改进。
在每条曲线的最小值的右侧,模型太大——在更多数据上训练的较小模型将是一种改进。
最好的模型处于最小值。
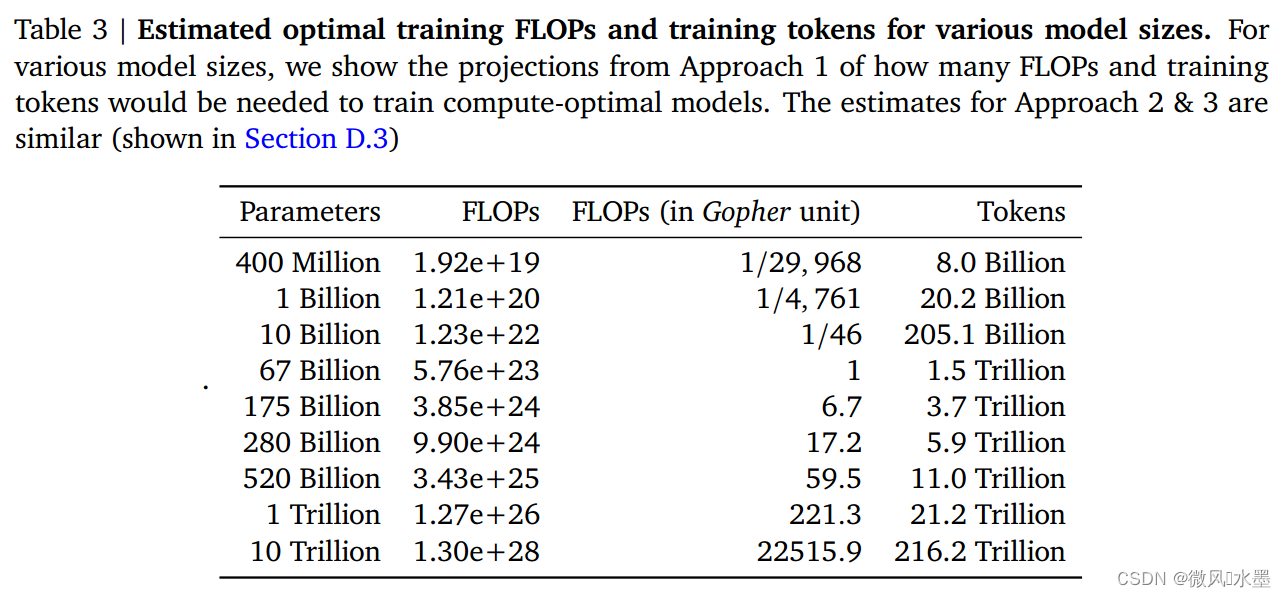
这个是DeepMind推荐的模型参数N、训练数据D、训练算力C的配比。可以发现和OpenAI的推荐是不一样的。也与BaiChuan2中7B/13B训练需要2.6T的数据量对不上。
相关文章:
LLM:Training Compute-Optimal Large Language Models
论文:https://arxiv.org/pdf/2203.15556.pdf 发表:2022 前文回顾: OpenAI在2020年提出《Scaling Laws for Neural Language Models》:Scaling Laws(缩放法则)也一直影响了后续大模型的训练。其给出的结论是最佳计算效…...
http跟https有什么区别?
HTTP(Hypertext Transfer Protocol)和HTTPS(HTTP Secure)是两种不同的通信协议,它们在数据传输的安全性方面有明显的区别: 1. 安全性: - HTTP:是一种明文传输协议,数…...

python flask学生管理系统
预览 前端 jquery css html bootstrap: 4.x 后端 python: 3.6.x flask: 2.0.x 数据库 mysql: 5.7 学生管理模块 登录、退出查看个人信息、修改个人信息成绩查询查看已选课程选课、取消选课搜索课程课程列表分页功能 教师模块 登录、退出查看个人信息、修改个人信息录入…...
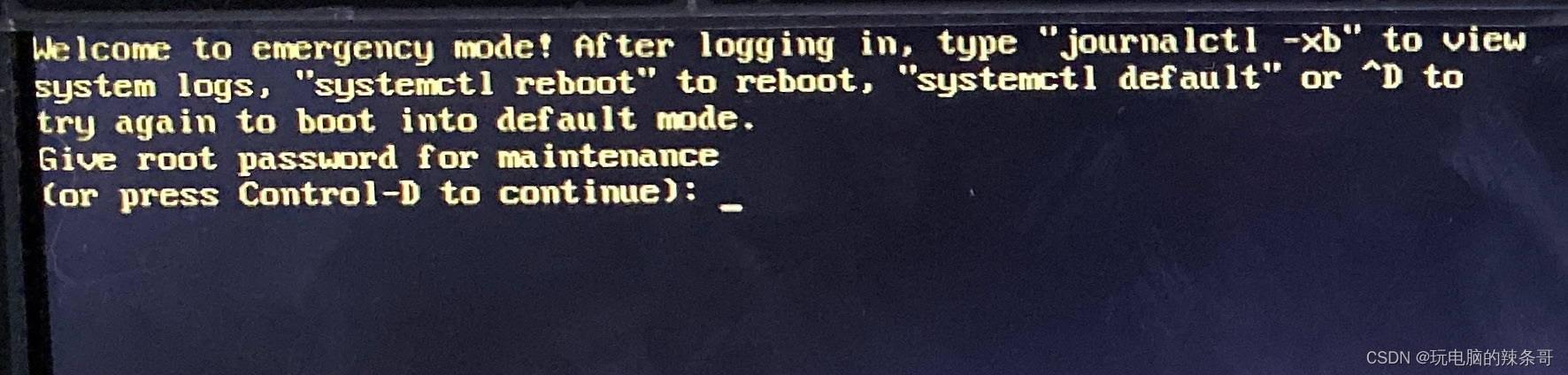
IDC机房服务器搬迁之运行了几年的服务器没关过机,今天关机下架,再上架突然起不来了,怎么快速处理?
环境 戴尔R420 服务器 1U 2台直连存储 4U CentOS 7 问题描述 IDC机房服务器搬迁之运行了几年的服务器没关过机,今天关机下架,再上架突然起不来了,怎么快速处理? 服务器上电开机就出现进入紧急模式 Welcome to emergency mode! After logging in, type “journalctl …...

基于位的权限系统
基于位的权限系统是一种利用二进制位运算进行权限管理的技术。在这种系统中,不同的权限被编码为2的幂次方 (例如1、2、4、8等),每个权限对应一个独立的二进制位(可想而知运算速度是非常快的)。通过将这些权限值组合在一起形成一个…...

[AIGC] Spring Boot Docker 部署指南
Spring Boot Docker 部署指南 引言 近年来,容器化部署成为了越来越流行的部署方式。Docker 是目前最受欢迎的容器化平台之一,它提供了一种将应用程序与其依赖项打包在一起,并以容器的形式运行的方法。Spring Boot 是一种用于快速开发和微服…...

图像处理------亮度
from PIL import Imagedef change_brightness(img: Image, level: float) -> Image:"""按照给定的亮度等级,改变图片的亮度"""def brightness(c: int) -> float:return 128 level (c - 128)if not -255.0 < level < 25…...

LeetCode刷题---基本计算器
解题思路: 根据题意,字符串中包含的运算符只有和- 使用辅助栈的方法来解决该问题 定义结果集res和符号位sign(用于判断对下一数的加减操作),接着对字符串进行遍历。 如果当前字符为数字字符,判断当前字符的下一个字符是否也是数字字符&#x…...
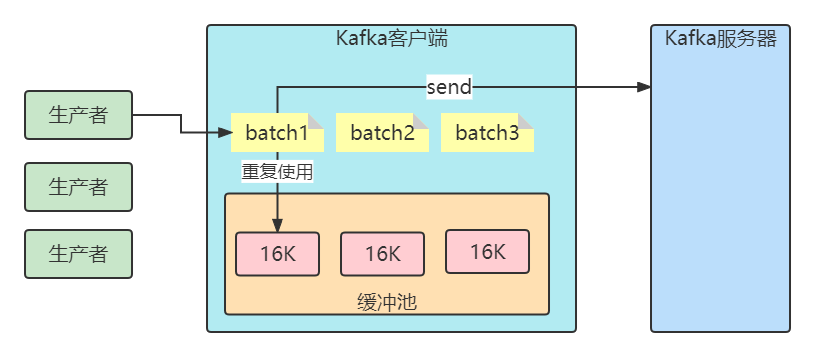
Kafka生产消费流程
Kafka生产消费流程 1.Kafka一条消息发送和消费的流程图(非集群) 2.三种发送方式 准备工作 创建maven工程,引入依赖 <dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.3.1…...

c 小熊猫 c++ IDE编译ffmpeg 设置
菜单-》运行-》运行参数->编译器->编译器配置集->链接时加入下列选项 : -I /usr/local/ffmpeg/include -L /usr/local/ffmpeg/lib -lavformat -lavdevice -lavfilter -lavcodec -lavutil -lswscale -lswresample -lm 本机ffmpeg存储位置:inclu…...

【Java】十年老司机转开发语言,新小白从学习路线图开始
欢迎来到《小5讲堂》 大家好,我是全栈小5。 这是《Java》序列文章,每篇文章将以博主理解的角度展开讲解, 特别是针对知识点的概念进行叙说,大部分文章将会对这些概念进行实际例子验证,以此达到加深对知识点的理解和掌握…...
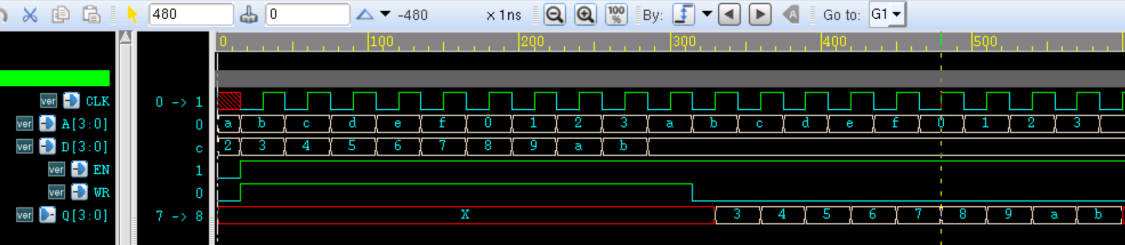
5.3 Verilog 带参数例化
5.3 Verilog 带参数例化 分类 Verilog 教程 关键词: defparam,参数,例化,ram 当一个模块被另一个模块引用例化时,高层模块可以对低层模块的参数值进行改写。这样就允许在编译时将不同的参数传递给多个相同名字的模块…...

边缘计算的挑战和机遇
边缘计算是一种分布式计算框架,它将应用程序、数据和计算服务带离集中式数据中心,靠近用户和数据源的位置。这种方法可以减少延迟,提高服务速度,并可能改善数据安全性和隐私性。然而,边缘计算同时也面临着挑战…...

Mybatis基础---------增删查改
目录结构 增删改 1、新建工具类用来获取会话对象 import org.apache.ibatis.session.SqlSession; import org.apache.ibatis.session.SqlSessionFactory; import org.apache.ibatis.session.SqlSessionFactoryBuilder; import org.apache.ibatis.io.Resources;import java.io…...

CentOS查看修改时间
经常玩docker的朋友应该都知道,有很多的镜像运行起来后,发现容器里的系统时间不对,一般是晚被北京时间8个小时(不一定)。 这里合理怀疑是镜像给的初始时区是世界标准时间(也叫协调世界时间)。 有…...
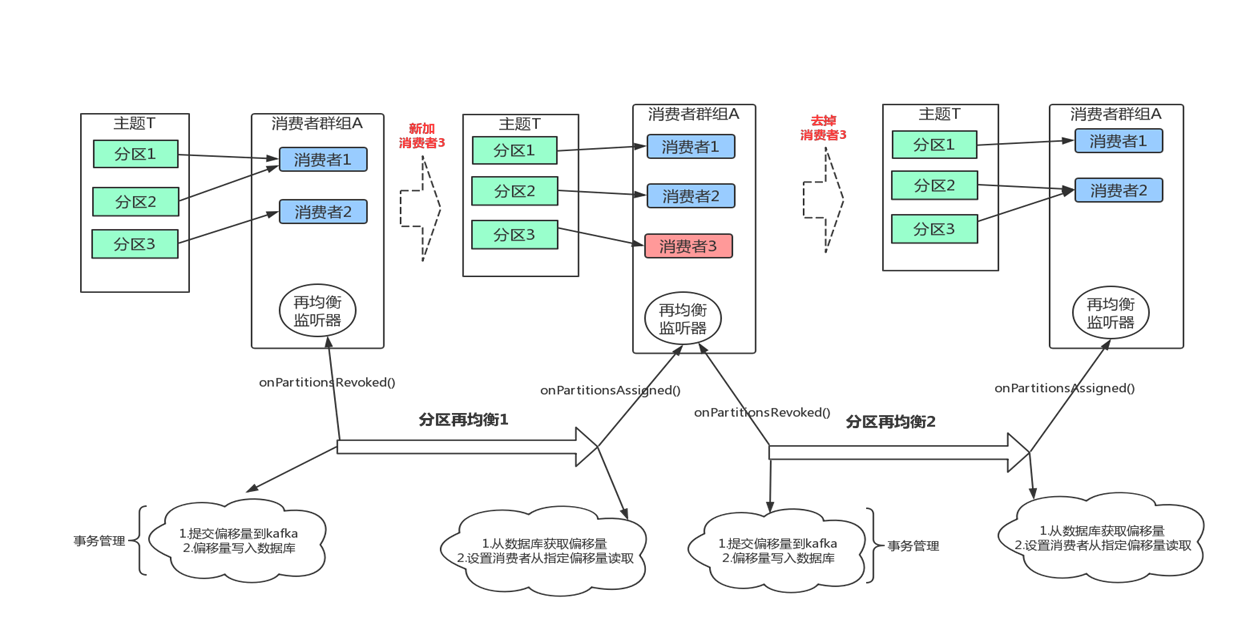
Kafka消费流程
Kafka消费流程 消息是如何被消费者消费掉的。其中最核心的有以下内容。 1、多线程安全问题 2、群组协调 3、分区再均衡 1.多线程安全问题 当多个线程访问某个类时,这个类始终都能表现出正确的行为,那么就称这个类是线程安全的。 对于线程安全&…...
)
RPC原理介绍与使用(@RpcServiceAnnotation)
Java RPC(Remote Procedure Call,远程过程调用)是一种用于实现分布式系统中不同节点之间通信的技术。它允许在不同的计算机或进程之间调用远程方法,就像调用本地方法一样。 ** 一.Java RPC的原理如下: ** 定义接口&…...

力扣labuladong——一刷day94
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言二叉堆(Binary Heap)没什么神秘,性质比二叉搜索树 BST 还简单。其主要操作就两个,sink(下沉…...

Vim 是一款强大的文本编辑器,广泛用于 Linux 和其他 Unix 系统。以下是 Vim 的一些基本用法
Vim 是一款强大的文本编辑器,广泛用于 Linux 和其他 Unix 系统。以下是 Vim 的一些基本用法: 打开文件: vim filename 基本移动: 使用箭头键或 h, j, k, l 分别向左、下、上、右移动。Ctrl f: 向前翻页。Ctrl b: 向后翻页。…...
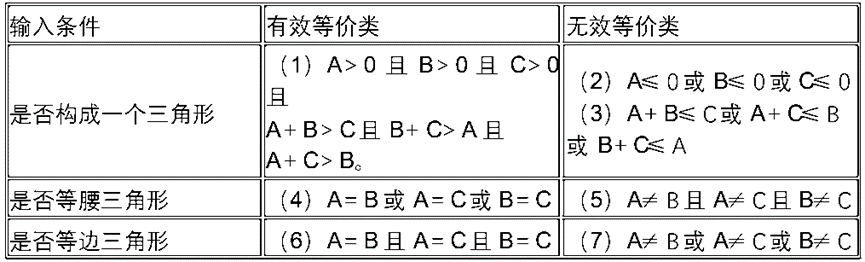
软件工程:黑盒测试等价分类法相关知识和多实例分析
目录 一、黑盒测试和等价分类法 1. 黑盒测试 2. 等价分类法 二、黑盒测试等价分类法实例分析 1. 工厂招工年龄测试 2. 规定电话号码测试 3. 八位微机测试 4. 三角形判断测试 一、黑盒测试和等价分类法 1. 黑盒测试 黑盒测试就是根据被测试程序功能来进行测试…...
)
深入了解指针(3)
文章目录数组名的理解对arr[i]的理解一维数组传参的本质二级指针指针数组指针数组的用处总结这里是think的博客 希望可以一起交流知识,一起think 今天我们来学习指针(3)吧 一起来think吧 数组名的理解 //测试环境:X86 #include <stdio.h> int main() { int a…...

GPT-4稀疏激活真相:2%参数如何实现高效推理
1. 项目概述:参数规模与稀疏激活的真相拆解 “GPT-4 Has 1.8 Trillion Parameters. It Uses 2% of Them Per Token.”——这句话过去两年在技术社区反复刷屏,常被当作“大模型已突破算力瓶颈”的标志性论断。但作为从2017年就开始部署LSTM语音识别系统、…...

【NotebookLM显著性判断实战指南】:20年AI架构师亲授5大误判陷阱与3步精准验证法
更多请点击: https://intelliparadigm.com 第一章:NotebookLM显著性判断的核心概念与本质认知 NotebookLM 是 Google 推出的基于用户上传文档进行语义理解与对话生成的实验性 AI 工具,其“显著性判断”并非传统统计学中的 p 值检验ÿ…...

终极RPG Maker游戏资源解密工具:无需安装的浏览器解决方案
终极RPG Maker游戏资源解密工具:无需安装的浏览器解决方案 【免费下载链接】RPG-Maker-MV-Decrypter You can decrypt RPG-Maker-MV Resource Files with this project ~ If you dont wanna download it, you can use the Script on my HP: 项目地址: https://git…...

基于瑞萨R8C MCU的180度电角度无感FOC BLDC电机控制方案详解
1. 项目概述与核心需求解析大家好,我是老王,一个在电机控制和嵌入式系统开发领域摸爬滚打了十几年的工程师。今天想和大家深入聊聊一个非常具体且有意思的项目:如何基于瑞萨电子的R8C系列MCU,来实现一套180度电角度控制的无刷直流…...

MASA模组汉化包技术解析:构建高效中文游戏体验的技术解决方案
MASA模组汉化包技术解析:构建高效中文游戏体验的技术解决方案 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 在Minecraft模组生态系统中,MASA系列模组以其强大的…...

【ElevenLabs云南话语音落地实战】:20年语音AI专家亲授3步适配方言模型,避开92%开发者踩过的声学对齐陷阱
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs云南话语音落地实战导论 云南话作为西南官话的重要分支,具有声调丰富、语流连贯、地域变体多样等特点,为语音合成技术带来独特挑战。ElevenLabs 提供的多语言、高保真…...

稀疏记忆微调:面向边缘设备的持续学习落地方法
1. 项目概述:这不是又一篇“加个正则就叫持续学习”的水文“Continual Learning via Sparse Memory Finetuning”——光看标题,你可能以为这是某篇顶会里被塞进附录、连作者自己都懒得细讲的补充实验。但实际翻开原文,它像一把薄刃手术刀&…...
迟滞模型及其PSO算法参数辨识【含Matlab源码 15544期】)
【参数辨识】经典Prandtl–Ishlinskii(PI)迟滞模型及其PSO算法参数辨识【含Matlab源码 15544期】
💥💥💥💥💥💥💥💥💞💞💞💞💞💞💞💞💞Matlab领域博客之家💞&…...

明日方舟智能基建管理终极指南:Arknights-Mower 完整使用教程
明日方舟智能基建管理终极指南:Arknights-Mower 完整使用教程 【免费下载链接】arknights-mower 《明日方舟》长草助手 项目地址: https://gitcode.com/gh_mirrors/ar/arknights-mower 还在为《明日方舟》每日繁琐的基建操作而烦恼吗?Arknights-M…...