Spark算子(RDD)超细致讲解
SPARK算子(RDD)超细致讲解
map,flatmap,sortBykey, reduceBykey,groupBykey,Mapvalues,filter,distinct,sortBy,groupBy共10个转换算子
(一)转换算子
1、map
from pyspark import SparkContext# 创建SparkContext对象
sc = SparkContext()# 生成rdd
data = [1, 2, 3, 4]
rdd = sc.parallelize(data)# 对rdd进行计算
# 转化算子map使用
# 将处理数据函数当成参数传递给map
# 定义函数只需要一个接受参数
def func(x):return x + 1def func2(x):return str(x)
# 转化算子执行后会返回新的rdd
rdd_map = rdd.map(func)
rdd_map2 = rdd.map(func2)
rdd_map3 = rdd_map2.map(lambda x: [x])# 对rdd数据结果展示
# 使用rdd的触发算子,collect获取是所有的rdd元素数据
res = rdd_map.collect()
print(res)res2 = rdd_map2.collect()
print(res2)res3 = rdd_map3.collect()
print(res3)
2、flatmap
from pyspark import SparkContext# 创建SparkContext对象
sc = SparkContext()# 生成rdd
data = [[1, 2], [3, 4]]
data2 = ['a,b,c','d,f,g'] # 将数据转为['a','b','c','d','f','g']
rdd = sc.parallelize(data)
rdd2 = sc.parallelize(data2)# rdd计算
# flatMap算子使用 将rdd元素中的列表数依次遍历取出对应的值放入新的rdd [1,2,3,4]
# 传递一个函数,函数接受一个参数
rdd_flatMap = rdd.flatMap(lambda x: x)rdd_map = rdd2.map(lambda x:x.split(','))
rdd_flatMap2 = rdd_map.flatMap(lambda x:x)# 输出展示数据
# 使用执行算子
res = rdd_flatMap.collect()
print(res)res2 = rdd_map.collect()
print(res2)res3 = rdd_flatMap2.collect()
print(res3)
3、kv数据结构(sortBykey, reduceBykey,groupBykey,Mapvalues)
# 对kv数据进行处理
from pyspark import SparkContext# 创建SparkContext对象
sc = SparkContext()
# RDD中的kv结构数据 (k,v)
data = [('a', 1), ('b', 2), ('c', 3), ('a', 1), ('b', 2)]
# 将python数据转化为RDD数据类型
rdd = sc.parallelize(data)# 排序 根据key排序
# ascending 指定升序还是降序 默认为true是升序 从小到大
rdd_sortByKey = rdd.sortByKey(ascending=False) # todo 无需传递处理方法# 根据key聚合计算 将相同key的数据放在一起,然后根据指定的计算方法对分组内的数据进行聚合计算
rdd_reduceByKey = rdd.reduceByKey(lambda x, y: x + y) # todo 需要传递处理方法# 分组 只按照key分组 而且无法直接获取到值内容,需要mapValues
rdd_groupByKey = rdd.groupByKey() # todo 无需传递处理方法# 获取kv数据中v值
# x接受value值
rdd_mapValues = rdd_groupByKey.mapValues(lambda x: list(x)) # todo 需要传递处理方法# 展示数据
res = rdd_sortByKey.collect()
print(res)res2 = rdd_reduceByKey.collect()
print(res2)res3 = rdd_groupByKey.collect()
print(res3)res4 = rdd_mapValues.collect()
print(res4)
4、复习()
data =[hadoop,flink,spark,hive,hive,spark,python,java,python,itcast,itheima] #自己转一下字符串
# rdd计算
# 对读取到的rdd中的每行数据,先进行切割获取每个单词的数据
# rdd_map = rdd.map(lambda x: x.split(','))
# todo 这段代码给我的感觉就是先进行数据处理再执行flatmap函数。
rdd_flatMap= rdd.flatMap(lambda x: x.split(','))# 将单词数据转化为k-v结构数据 [(k,v),(k1,v1)] 给每个单词的value一个初始值1
rdd_map_kv = rdd_flatMap.map(lambda x:(x,1))# 对kv数据进行聚合计算 hive:[1,1] 求和 求平均数 求最大值 求最小值
rdd_reduceByKey = rdd_map_kv.reduceByKey(lambda x,y:x+y) # 现将相同key值的数据放在一起,然后对相同key值内的进行累加# 展示数据
res = rdd.collect()
print(res)# res2 = rdd_map.collect()
# print(res2)res3 = rdd_flatMap.collect()
print(res3)res4 = rdd_map_kv.collect()
print(res4)res5 = rdd_reduceByKey.collect()
print(res5)
5、过滤算子(filter)
# 数据条件过滤 类似 sql中的where
# 导入sparkcontext
from pyspark import SparkContext# 创建SparkContext对象
sc = SparkContext()# 生成rdd数据
data = [1, 2, 3, 4, 5, 6]
rdd = sc.parallelize(data)# 对rdd数据进行过滤
# filter 接受函数,要求一个函数参数
# lambda x: x > 3 x接受rdd中的每个元素数据 x>3 是过滤条件 过滤条件的数据内容和Python的 if书写内容一样
# 符合条件的数据会放入一个新的rdd
rdd_filter1 = rdd.filter(lambda x: x > 3)
rdd_filter2 = rdd.filter(lambda x: x in [2, 3, 5])
rdd_filter3 = rdd.filter(lambda x: x % 2 == 0)# 展示数据
res = rdd_filter1.collect()
print(res)res = rdd_filter2.collect()
print(res)res = rdd_filter3.collect()
print(res)
6、去重和排序算子(distinct,sortby注意和sortBYkey的区别)
# rdd数据去重
# 导入sparkcontext
from pyspark import SparkContext# 创建SparkContext对象
sc = SparkContext()# 生成rdd数据
data = [1, 1, 3, 3, 5, 6]
rdd = sc.parallelize(data)# 去重
rdd_distinct = rdd.distinct()# 获取数据
res = rdd_distinct.collect()
print(res)
# todo 其它都是传递计算函数,但是这个传递的不是排序函数,而是指定根据谁来排序
# rdd数据排序
# 导入sparkcontext
from pyspark import SparkContext# 创建SparkContext对象
sc = SparkContext()# 生成rdd数据
data = [6, 1, 5, 3]
data_kv = [('a',2),('b',3),('c',1)]
rdd = sc.parallelize(data)
rdd_kv = sc.parallelize(data_kv)# 数据排序
# 传递函数 需要定义一个接收参数
# lambda x:x 第一个参数x 接收rdd中的元素, 第二计算x 指定后会按照该x值排序
# ascending 指定排序规则 默认是True 升序
rdd_sortBy = rdd.sortBy(lambda x:x,ascending=False)
# 对于kv结构数据 可以通过下标指定按照哪个数据排序
rdd_sortBy2 = rdd_kv.sortBy(lambda x:x[1],ascending=False)# 查看结果
res = rdd_sortBy.collect()
print(res)res2 = rdd_sortBy2.collect()
print(res2)
7、分组算子(groupBy注意和groupBYkey的区别,同时都需要MapValues)
# rdd分组
# 导入sparkcontext
from pyspark import SparkContext# 创建SparkContext对象
sc = SparkContext()# 生成rdd数据
data = [6, 1, 5, 3, 10, 22, 35, 17]
rdd = sc.parallelize(data)# 分组
# 传递函数 函数需要一个接收参数
# lambda x: x % 3 x接收rdd中的每个元素 x%3 对x进行计算,余数相同的数据会放在一起
rdd_groupBy = rdd.groupBy(lambda x: x % 3)
# mapValues 会获取kv中的value数据
# lambda x:list(x) x接收value值数据
rdd_mapValues = rdd_groupBy.mapValues(lambda x: list(x))def func(x):if len(str(x)) ==1:return '1'elif len(str(x)) ==2:return 'two' # 返回分组的key值 指定分组名rdd_groupBy2 = rdd.groupBy(func)
rdd_mapValues2 = rdd_groupBy2.mapValues(lambda x: list(x))# 查看结果
res = rdd_groupBy.collect()
print(res)res2 = rdd_mapValues.collect()
print(res2)res3 = rdd_groupBy2.collect()
print(res3)res4 = rdd_mapValues2.collect()
print(res4)
相关文章:
超细致讲解)
Spark算子(RDD)超细致讲解
SPARK算子(RDD)超细致讲解 map,flatmap,sortBykey, reduceBykey,groupBykey,Mapvalues,filter,distinct,sortBy,groupBy共10个转换算子 (一)转换算子 1、map from pyspark import SparkContext# 创建SparkContext对象 sc Spark…...
C卷 (JavaPythonC++Node.jsC语言))
转盘寿司(100%用例)C卷 (JavaPythonC++Node.jsC语言)
寿司店周年庆,正在举办优惠活动回馈新老客户。 寿司转盘上总共有n盘寿司,prices[i]是第i盘寿司的价格,如果客户选择了第i盘寿司,寿司店免费赠送客户距离,第i盘寿司最近的下一盘寿司i,前提是prices[j]< prices[i],如果没有满足条件的j,则不赠送寿司。 每个价格的寿司都…...

【python】搭配Miniconda使用VSCode
现在的spyder总是运行出错,启动不了,尝试使用VSCode。 一、在VSCode中使用Miniconda管理的Python环境,可以按照以下步骤进行: a. 确保Miniconda环境已经安装并且正确配置。 b. 打开VSCode,安装Python扩展。 打开VS…...
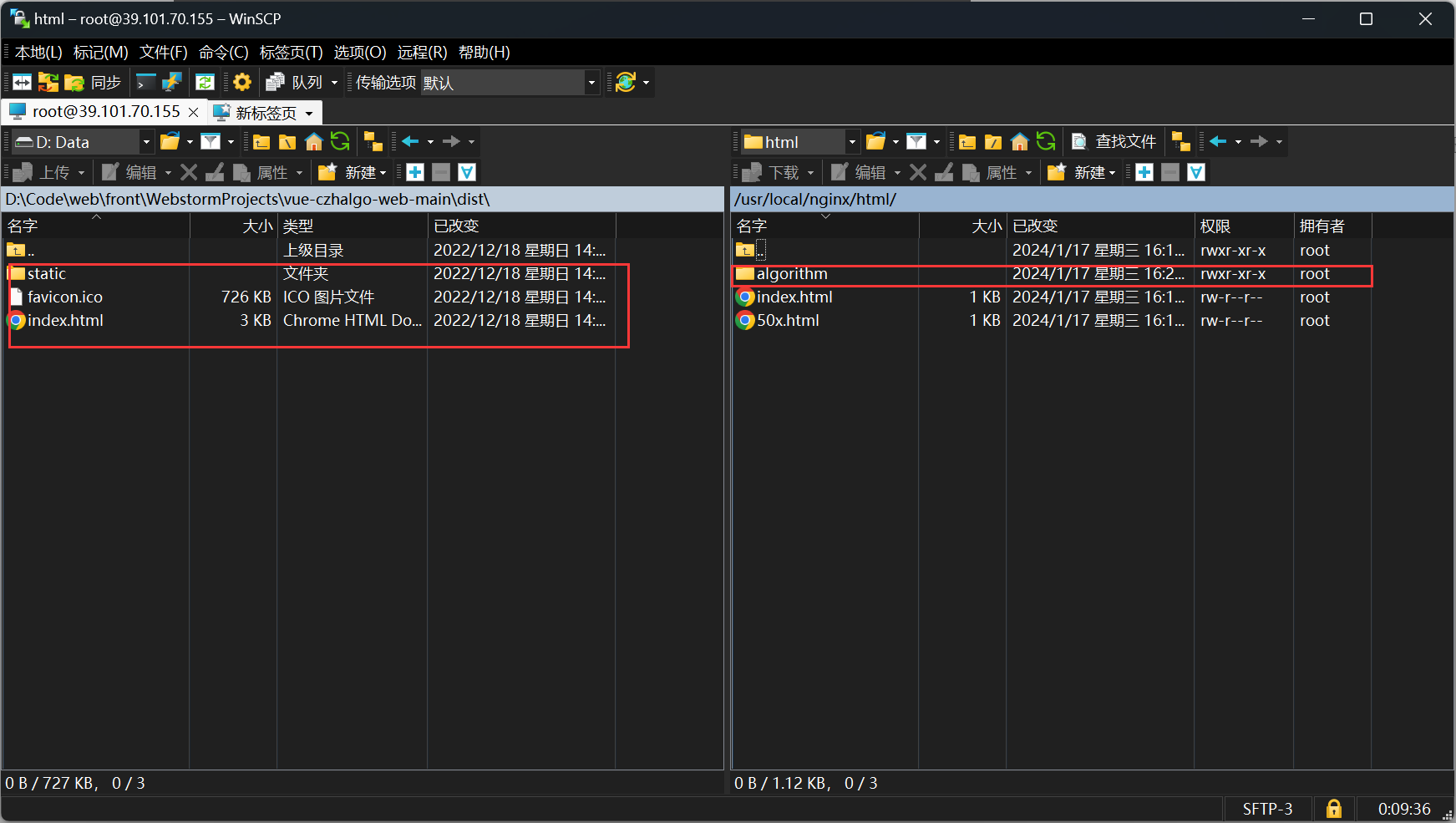
从购买服务器到部署前端VUE项目
购买 选择阿里云服务器,地址:https://ecs.console.aliyun.com/home。学生会送一个300的满减券,我买了一个400多一年的,用券之后100多点。 使用SSH连接服务器 我选择的是vscode 中SSH工具。 安装一个插件 找到配置文件配置一下…...

python中print函数的用法
在 Python 中,print() 函数是用于输出信息到控制台的内置函数。它可以将文本、变量、表达式等内容打印出来,方便程序员进行调试和查看结果。print() 函数的基本语法如下: ``` print(*objects, sep= , end=\n, file=sys.stdout, flush=False) ``` 其中,objects 是要打印…...

SpringBoot整合MyBatis项目进行CRUD操作项目示例
文章目录 SpringBoot整合MyBatis项目进行CRUD操作项目示例1.1.需求分析1.2.创建工程1.3.pom.xml1.4.application.properties1.5.启动类 2.添加用户2.1.数据表设计2.2.pojo2.3.mapper2.4.service2.5.junit2.6.controller2.7.thymeleaf2.8.测试 3.查询用户3.1.mapper3.2.service3…...
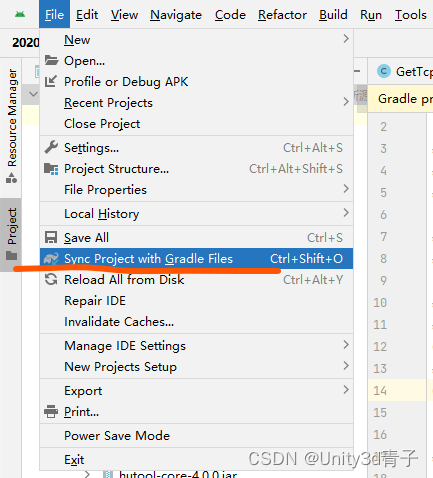
Android Studio下载gradle反复失败
我的版本:gradle-5.1.1 首先检查设置路径是否正确,参考我的修改! 解决方案 1.手动下载Gradle.bin Gradle Distributions 下载地址 注意根据编译器提示下载,我这要求下载的是bin 而不是all 2.把下载好的整个压缩包放在C:\Users\…...
【HTML5】 canvas 绘制图形
文章目录 一、基本用法二、用法详见2.0、方法属性2.1、绘制线条2.2、绘制矩形2.3、绘制圆形2.4、绘制文本2.5、填充图像 一、基本用法 canvas 标签:可用于在网页上绘制图形(使用 JavaScript 在网页上绘制图像)画布是一个矩形区域,…...
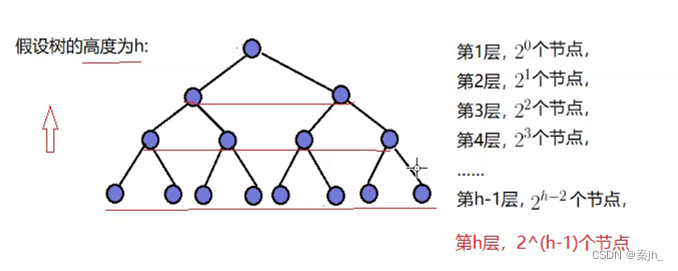
【数据结构】二叉树-堆(top-k问题,堆排序,时间复杂度)
🌈个人主页:秦jh__https://blog.csdn.net/qinjh_?spm1010.2135.3001.5343🔥 系列专栏:《数据结构》https://blog.csdn.net/qinjh_/category_12536791.html?spm1001.2014.3001.5482 目录 堆排序 第一种 编辑 第二种 …...

通过浏览器判断是否安装APP
场景 求在分享出来的h5页面中,有一个立即打开的按钮,如果本地安装了我们的app,那么点击就直接唤本地app,如果没有安装,则跳转到下载。 移动端 判断本地是否安装了app 首先我们可以确认的是,在浏览器中无…...

vivado Revision Control
2020.2 只需要git 管理 prj.xpr 和 prj.srcs/ https://china.xilinx.com/video/hardware/ip-revision-control.html Using Vivado Design Suite with Revision Control https://www.xilinx.com/video/hardware/vivado-design-suite-revision-control.html http://www.xi…...

【AI视野·今日Robot 机器人论文速览 第七十三期】Tue, 9 Jan 2024
AI视野今日CS.Robotics 机器人学论文速览 Tue, 9 Jan 2024 Totally 40 papers 👉上期速览✈更多精彩请移步主页 Daily Robotics Papers Digital Twin for Autonomous Surface Vessels for Safe Maritime Navigation Authors Daniel Menges, Andreas Von Brandis, A…...

java解析json复杂数据的第四种思路
文章目录 一、概述二、数据预览1. 接口json数据 三、代码实现1. 核心代码2. 字符串替换结果3. 运行结果 一、概述 接前两篇 java解析json复杂数据的两种思路 java解析json复杂数据的第三种思路 我们已经有了解析json数据的几种思路,下面介绍的方法是最少依赖情况下…...
【不用找素材】ECS 游戏Demo制作教程(1) 1.15
一、项目设置 版本:2022.2.0f1 (版本太低的话会安装不了ECS插件) 模板选择3D URP 进来后移除URP(因为并不是真的需要,但也不是完全不需要) Name: com.unity.entities.graphics Version: 1.0.0-exp.8 点击…...

Mysql的in与exits
Mysql的in与exits IN和EXISTS是MySQL中用于子查询的两种不同的条件操作符。它们在使用和实现上有一些区别。 IN 操作符: IN操作符用于判断一个值是否在一个集合内。它可以用于子查询中,检查主查询的某一列是否在子查询返回的结果集中。 SELECT colum…...
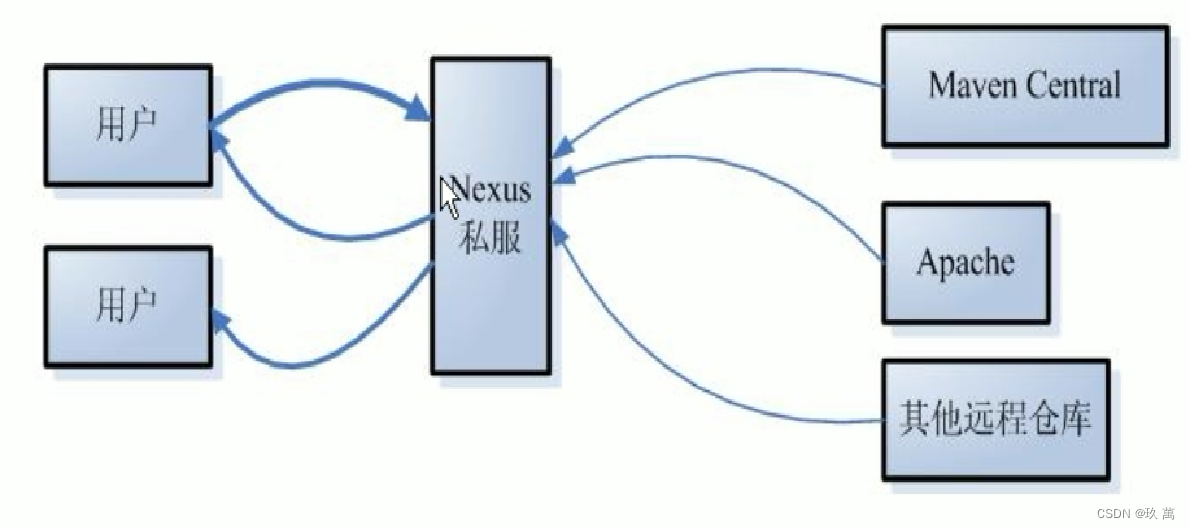
浅谈对Maven的理解
一、什么是Maven Maven——是Java社区事实标准的项目管理工具,能帮你从琐碎的手工劳动中解脱出来,帮你规范整个组织的构建系统。不仅如此,它还有依赖管理、自动生成项目站点等特性,已经有无数的开源项目使用它来构建项目并促进团队…...

【算法实验】实验2
实验2-1 二分搜索 【问题描述】给定一个包含 n 个元素有序的(升序)整型数组 nums 和一个目标值 target,要求实现搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。题目保证nums中的所有元素都不重复。 【…...

杂记:使用 mac 和 windows 以及编辑器的总结
Chrome 扩展 Grammarly 语法检查 DM Integration Module idm 下载扩展 JSON Formatter json 格式化查看 uBlock Origin Ad block 油猴 任意网站都可以使用的脚本管理工具 Mac 快捷键整理 截图到剪贴板 shift command control 4 (不按 shift 存储为文件) 切换输入法…...

vue2使用qiankun微前端(跟着步骤走可实现)
需求:做一个vue2的微前端,以vue2为主应用,其他技术栈为子应用,比如vue3,本文章只是做vue2一套的微前端应用实现,之后解决的一些问题。vue3子应用可以看我另一篇vue3vitets实现qiankun微前端子应用-CSDN博客…...

1.C语言基础知识
这里写目录标题 1.第一个C语言程序2.注释3.标识符4.关键字5.数据类型6.变量7.常量8.运算符9.输入输出输入输出 1.第一个C语言程序 C语言的编程框架 #include <stdio.h> int main() {/* 我的第一个 C 程序 */printf("Hello, World! \n");return 0; }2.注释 单行…...

终极ANI-RSS界面定制指南:打造专业级追番体验
终极ANI-RSS界面定制指南:打造专业级追番体验 【免费下载链接】ani-rss 基于RSS自动追番、订阅、下载、刮削、洗版 项目地址: https://gitcode.com/gh_mirrors/an/ani-rss ANI-RSS作为一款基于RSS的自动追番、订阅、下载工具,为动漫爱好者提供了强…...

抖音内容保存技术方案:开源下载工具深度解析与应用实践
抖音内容保存技术方案:开源下载工具深度解析与应用实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback supp…...

显卡驱动清理终极指南:为什么你的系统需要Display Driver Uninstaller深度清理?
显卡驱动清理终极指南:为什么你的系统需要Display Driver Uninstaller深度清理? 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirr…...

如何在10分钟内搭建个人游戏串流服务器:Sunshine跨平台游戏流媒体完全指南
如何在10分钟内搭建个人游戏串流服务器:Sunshine跨平台游戏流媒体完全指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否梦想过在任何设备上畅玩PC游戏&#x…...

Windows环境OpenCore引导盘制作:7步搞定Hackintosh安装
Windows环境OpenCore引导盘制作:7步搞定Hackintosh安装 【免费下载链接】OpenCore-Install-Guide Repo for the OpenCore Install Guide 项目地址: https://gitcode.com/gh_mirrors/op/OpenCore-Install-Guide 想在Windows电脑上安装macOS吗?别担…...

5大核心功能深度解析:Akebi-GC游戏辅助工具完整使用指南
5大核心功能深度解析:Akebi-GC游戏辅助工具完整使用指南 【免费下载链接】Akebi-GC (Fork) The great software for some game that exploiting anime girls (and boys). 项目地址: https://gitcode.com/gh_mirrors/ak/Akebi-GC Akebi-GC是一款功能强大的游戏…...

KMS_VL_ALL_AIO:智能激活脚本的完整使用指南
KMS_VL_ALL_AIO:智能激活脚本的完整使用指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO KMS_VL_ALL_AIO是一款基于微软官方KMS协议开发的智能激活脚本,为Windows系统…...

魔兽争霸3兼容性修复终极指南:告别闪退卡顿的智能解决方案
魔兽争霸3兼容性修复终极指南:告别闪退卡顿的智能解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3这款经典游戏在…...

如何在OneNote 2016中实现专业级代码高亮?NoteHighlight2016完整使用指南
如何在OneNote 2016中实现专业级代码高亮?NoteHighlight2016完整使用指南 【免费下载链接】NoteHighlight2016 Source code syntax highlighting for OneNote 2016 and OneNote for O365 . NoteHighlight 2013 port for OneNote 2016 (32-bit and 64-bit) 项目地址…...

企业级应用如何通过Taotoken聚合API管理多个大模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用如何通过Taotoken聚合API管理多个大模型调用 在构建企业级AI应用时,一个常见的需求是同时接入多个不同厂商的…...