SpringBoot ES 聚合后多字段加减乘除
SpringBoot ES 聚合后多字段加减乘除
在SpringData Elasticsearch中,聚合统计的原理主要依赖于Elasticsearch本身的聚合框架。Elasticsearch提供了强大的聚合功能,使得你可以对文档进行各种计算和统计,从而得到有关数据集的有用信息。
Elasticsearch的聚合(Aggregation)是一种强大的数据分析和统计工具,它允许你对文档集合进行多层次、多维度的计算和分析。聚合的原理可以分为以下几个方面:
| 关键词 | 原理 |
|---|---|
| 桶(Buckets) | 桶是聚合的基本单元,它将文档分组到不同的集合中,这些集合称为桶。桶可以按照不同的标准进行分组,比如词条、范围、日期等。 |
| 度量(Metrics) | 除了桶,聚合还可以返回一些度量结果,如总和、平均值、最大值、最小值等。度量通常与桶结合使用,以提供更详细的统计信息。 |
| Pipeline Aggregations | Elasticsearch支持通过管道(pipeline)对聚合结果进行再处理。管道聚合(Pipeline Aggregations)允许你在已经聚合的结果上进行进一步的计算,例如计算平均值、求和等。 |
| 分布式计算 | Elasticsearch是一个分布式的搜索引擎,聚合的计算也是分布式的。当执行聚合查询时,Elasticsearch会将聚合任务分发到不同的分片上,然后将结果合并到一个全局结果中。 |
| 优化和缓存 | 为了提高性能,Elasticsearch会对聚合进行优化和缓存。在多次执行相同聚合查询时,Elasticsearch可能会缓存中间结果,以减少重复计算的开销。 |
| 脚本 | Elasticsearch支持使用脚本来进行聚合计算。脚本可以在聚合过程中对文档的字段进行定制的计算,从而实现更灵活的聚合操作。 |
import org.elasticsearch.script.Script;
import org.elasticsearch.script.ScriptType;
import org.elasticsearch.search.aggregations.Aggregation;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.bucket.terms.ParsedStringTerms;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder;
import org.elasticsearch.search.aggregations.metrics.AvgAggregationBuilder;
import org.elasticsearch.search.aggregations.metrics.MaxAggregationBuilder;
import org.elasticsearch.search.aggregations.metrics.MinAggregationBuilder;
import org.elasticsearch.search.aggregations.metrics.SumAggregationBuilder;
import org.jeecg.modules.mark.common.es.entity.AudioMarkInfo;
import org.junit.jupiter.api.Test;import java.util.Collections;
import java.util.List;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.mapping.IndexCoordinates;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;@SpringBootTest
public class ElasticSearchTest {@Autowiredprivate ElasticsearchRestTemplate restTemplate;@Testpublic void count() {String indexName = "app_student_1";NativeSearchQueryBuilder query = new NativeSearchQueryBuilder();TermsAggregationBuilder group = AggregationBuilders.terms("group").field("id");// 多字段积 聚合求 和Script script1 = new Script(ScriptType.INLINE, "painless","doc['age'].value * doc['score'].value", Collections.emptyMap());SumAggregationBuilder sum = AggregationBuilders.sum("sum").script(script1);// 多字段差 聚合求 平均数Script script2 = new Script(ScriptType.INLINE, "painless","doc['age'].value / doc['score'].value", Collections.emptyMap());AvgAggregationBuilder avg = AggregationBuilders.avg("avg").script(script2);// 多字段和 聚合求 最大值Script script3 = new Script(ScriptType.INLINE, "painless","doc['age'].value + doc['score'].value", Collections.emptyMap());MaxAggregationBuilder max = AggregationBuilders.max("max").script(script3);// 多字段商 聚合求 最小值Script script4 = new Script(ScriptType.INLINE, "painless","doc['age'].value + doc['score'].value + doc['mathScore'].value", Collections.emptyMap());MinAggregationBuilder min = AggregationBuilders.min("min").script(script4);group.subAggregation(sum);group.subAggregation(avg);group.subAggregation(max);group.subAggregation(min);SearchHits<AudioMarkInfo> search = restTemplate.search(query.build(), AudioMarkInfo.class,IndexCoordinates.of(indexName));Aggregations aggregations = search.getAggregations();ParsedStringTerms terms = aggregations.get("group");List<? extends Terms.Bucket> buckets = terms.getBuckets();for (Terms.Bucket bucket : buckets) {String id = bucket.getKeyAsString();long count = bucket.getDocCount();for (Aggregation list : bucket.getAggregations().asList()) {// TODO:}}}}相关文章:

SpringBoot ES 聚合后多字段加减乘除
SpringBoot ES 聚合后多字段加减乘除 在SpringData Elasticsearch中,聚合统计的原理主要依赖于Elasticsearch本身的聚合框架。Elasticsearch提供了强大的聚合功能,使得你可以对文档进行各种计算和统计,从而得到有关数据集的有用信息。 Elast…...

React16源码: React中requestCurrentTime和expirationTime的源码实现补充
requestCurrentTime 1 )概述 关于 currentTime,在计算 expirationTime 和其他的一些地方都会用到 从它的名义上来讲,应等于performance.now() 或者 Date.now() 就是指定的当前时间在react整体设计当中,它是有一些特定的用处和一些…...

【论文阅读】Deep Graph Contrastive Representation Learning
目录 0、基本信息1、研究动机2、创新点3、方法论3.1、整体框架及算法流程3.2、Corruption函数的具体实现3.2.1、删除边(RE)3.2.2、特征掩盖(MF) 3.3、[编码器](https://blog.csdn.net/qq_44426403/article/details/135443921)的设…...
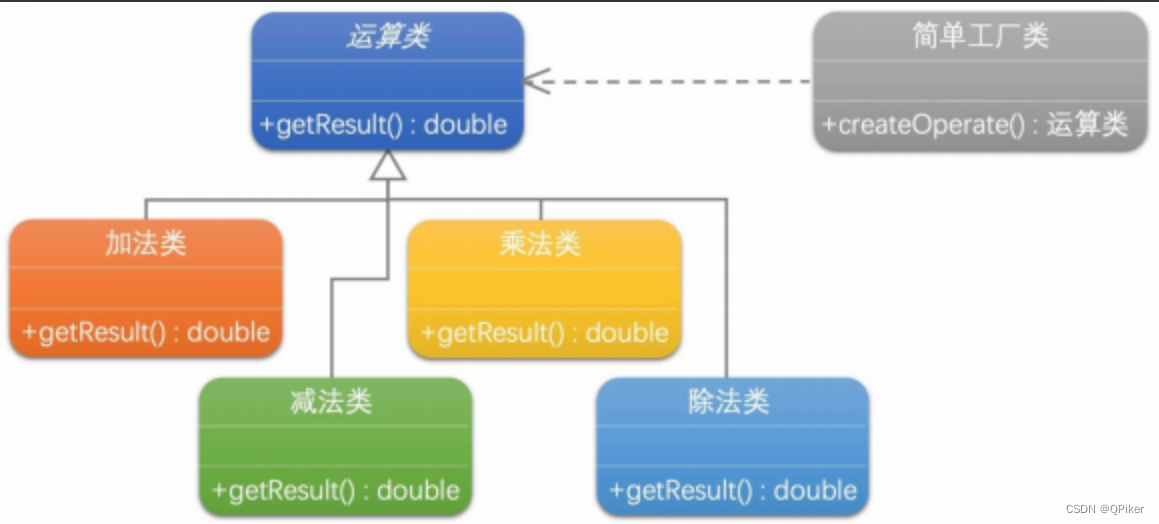
设计模式-简单工厂
设计模式-简单工厂 简单工厂模式是一个集中管理对象创建,并根据条件生成所需类型对象的设计模式,有助于提高代码的复用性和维护性,但可能会导致工厂类过于复杂且违反开闭原则。 抽象提取理论: 封装对象创建过程解耦客户端与产品…...
)
Django ORM 中的单表查询 API(1)
在 Django 中,对象关系映射(ORM)提供了一种功能强大、表现力丰富的数据库交互方式。ORM 允许开发人员使用高级 Python 代码执行数据库查询,从而更轻松地处理数据库实体。 下面,我们将探讨 Django ORM 中单表查询 API …...
电子雨html代码
废话不多说下面是代码: <!DOCTYPE html><html lang"en"><head><meta charset"UTF-8"><title>Code</title><style>body{margin: 0;overflow: hidden;}</style></head><body><c…...

xadmin基于Django的后台管理系统安装与使用
xadmin是基于Django的后台管理系统 官网:http://sshwsfc.github.io/xadmin/ github地址:https://github.com/sshwsfc/xadmin 安装方式 pip安装 pip install xadmin在setting配置中添加: INSTALLED_APPS [xadmin,crispy_forms, ]在urls.py…...

[go语言]输入输出
目录 知识结构 输入 1.Scan 编辑 2.Scanf 3.Scanln 4.os.Stdin --标准输入,从键盘输入 输出 1.Print 2.Printf 3.Println 知识结构 输入 为了展示集中输入的区别,将直接进行代码演示。 三者区别的结论:Scanf格式化输入&#x…...

【SpringBoot系列】AOP详解
🤵♂️ 个人主页:@香菜的个人主页,加 ischongxin ,备注csdn ✍🏻作者简介:csdn 认证博客专家,游戏开发领域优质创作者,华为云享专家,2021年度华为云年度十佳博主 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞👍🏻 收…...

openssl3.2 - 官方demo学习 - signature - rsa_pss_hash.c
文章目录 openssl3.2 - 官方demo学习 - signature - rsa_pss_hash.c概述笔记END openssl3.2 - 官方demo学习 - signature - rsa_pss_hash.c 概述 对私钥对明文做签名(摘要算法为SHA256) 用公钥对密文做验签(摘要算法为SHA256) 笔记 /*! \file rsa_pss_hash.c \note openss…...

Redis相关知识点
1.什么是Redis Redis (REmote DIctionary Server) 是用 C 语言开发的一个开源的高性能键值对(key-value)数据库,它支持网络,可基于内存亦可持久化,并提供多种语言的API。Redis具有高效性、原子性、支持多种数据结构、…...
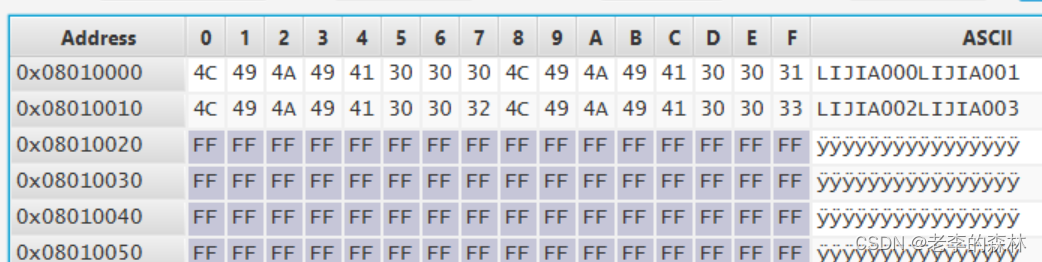
嵌入式开发--STM32G4系列片上FLASH的读写
这个玩意吧,说起来很简单,就是几行代码的事,但楞是折腾了我大半天时间才搞定。原因后面说,先看代码吧: 读操作 读操作很简单,以32位方式读取的时候是这样的: data *(__IO uint32_t *)(0x080…...
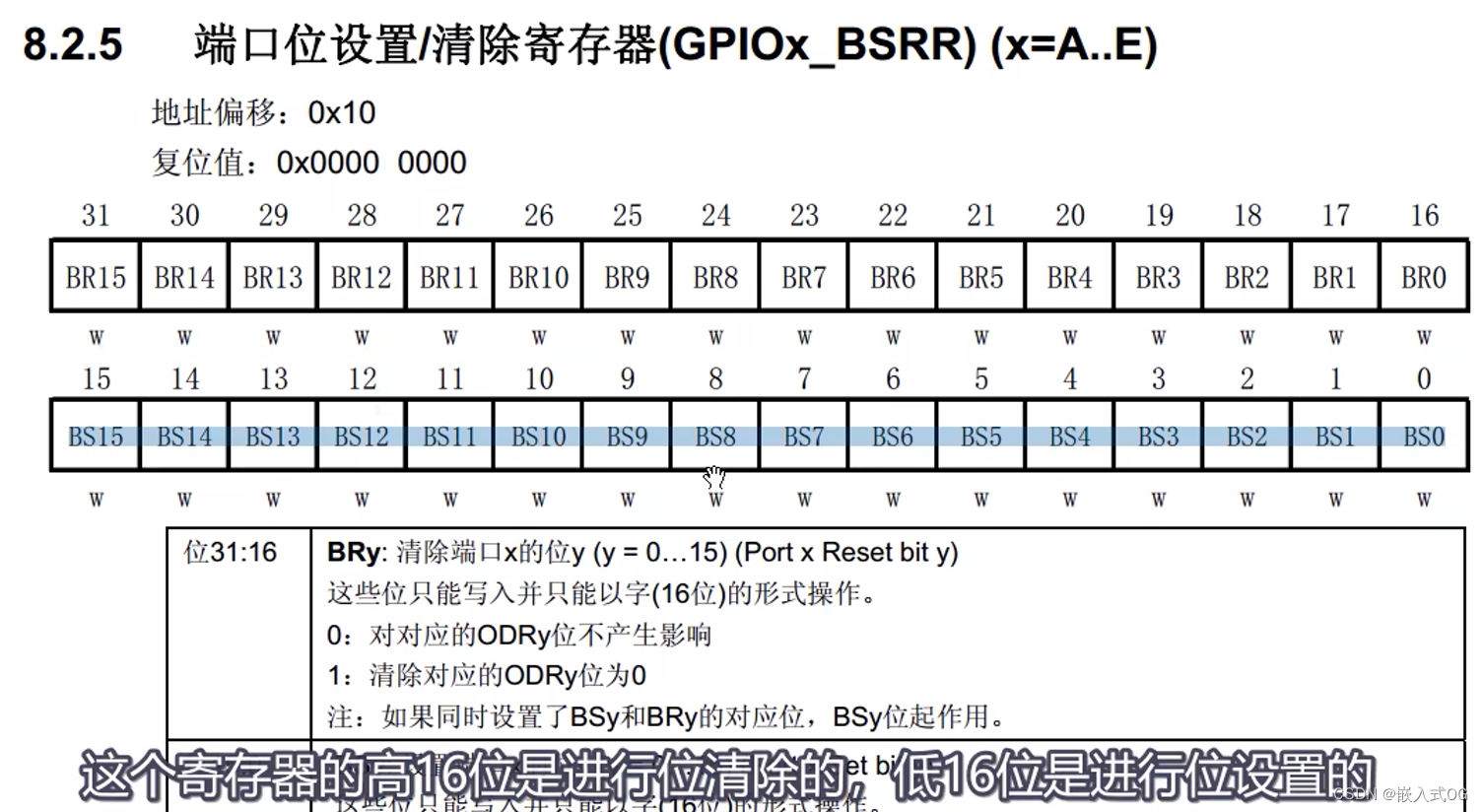
嵌入式-Stm32-江科大基于标准库的GPIO的八种模式
文章目录 一:GPIO输入输出原理二:GPIO基本结构三:GPIO位结构四:GPIO的八种模式道友:相信别人,更要一百倍地相信自己。 (推荐先看文章:《 嵌入式-32单片机-GPIO推挽输出和开漏输出》…...

2024年1月17日Arxiv热门NLP大模型论文:THE FAISS LIBRARY
Meta革新搜索技术!提出Faiss库引领向量数据库性能飞跃 引言:向量数据库的兴起与发展 随着人工智能应用的迅速增长,需要存储和索引的嵌入向量(embeddings)数量也在急剧增加。嵌入向量是由神经网络生成的向量表示&…...
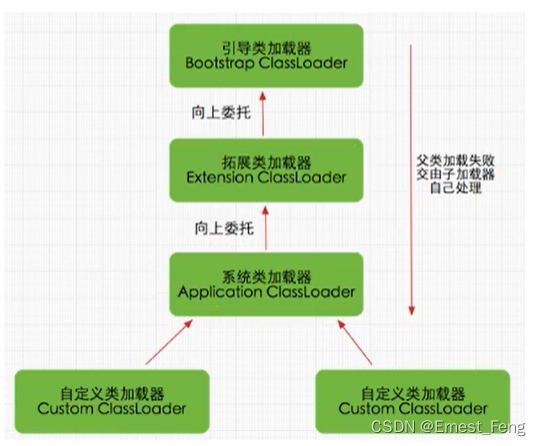
深度解析JVM类加载器与双亲委派模型
概述 Java虚拟机(JVM)是Java程序运行的核心,其中类加载器和双亲委派模型是JVM的重要组成部分。本文将深入讨论这两个概念,并解释它们在实际开发中的应用。 1. 什么是类加载器? 类加载器是JVM的一部分,负…...
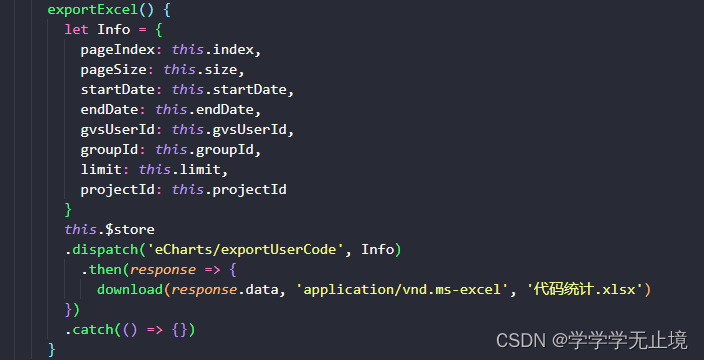
前端下载文件流,设置返回值类型responseType:‘blob‘无效的问题
前言: 本是一个非常简单的请求,即是下载文件。通常的做法如下: 1.前端通过Vue Axios向后端请求,同时在请求中设置响应体为Blob格式。 2.后端相应前端的请求,同时返回Blob格式的文件给到前端(如果没有步骤…...
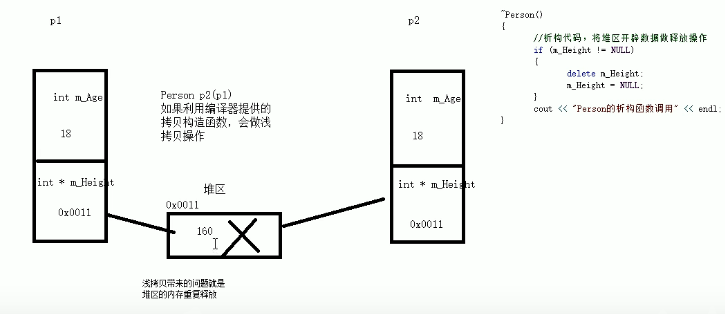
C++核心编程——类和对象(一)
本专栏记录C学习过程包括C基础以及数据结构和算法,其中第一部分计划时间一个月,主要跟着黑马视频教程,学习路线如下,不定时更新,欢迎关注。 当前章节处于: ---------第1阶段-C基础入门 ---------第2阶段实战…...

脱模斜度是什么意思,为什么要有脱模斜度,没有斜度不行吗?
问题描述:脱模斜度是什么意思,为什么要有脱模斜度,没有斜度不行吗? 问题解答: 脱模斜度是指在模具中的零件在脱模(从模具中取出)过程中相对于模具开合方向的倾斜程度。在模具设计和制造中&…...

【现代密码学】笔记9-10.3-- 公钥(非对称加密)、混合加密理论《introduction to modern cryphtography》
【现代密码学】笔记9-10.3-- 公钥(非对称加密)、混合加密理论《introduction to modern cryphtography》 写在最前面8.1 公钥加密理论随机预言机模型(Random Oracle Model,ROM) 写在最前面 主要在 哈工大密码学课程 张…...
牛客-寻找第K大、LeetCode215. 数组中的第K个最大元素【中等】
文章目录 前言牛客-寻找第K大、LeetCode215. 数组中的第K个最大元素【中等】题目及类型思路思路1:大顶堆思路2:快排二分随机基准点 前言 博主所有博客文件目录索引:博客目录索引(持续更新) 牛客-寻找第K大、LeetCode215. 数组中的第K个最大元…...

从CDP“3A”到千亿美元目标:联想集团的创新路径与AI原生转型
在全球产业链加速重构、人工智能技术范式快速迭代的背景下,中国企业的创新能力正成为各界关注的焦点。当被问及“哪些中国企业创新做得不错”时,有一家科技企业凭借其在绿色低碳、供应链协同以及混合式人工智能领域的系统性突破,给出了具有说…...

如何做好费用率数据分析?巧用费用率研判企业盈利现状
企业经营发展过程中,盈利水平高低直接决定长远发展实力,而费用率数据是看透企业真实盈利水平最直观、最核心的指标。很多经营者在日常管理中,往往只看重账面营收的增长,却忽略了费用率数据的深层分析与解读,最终出现营…...

用RT-Thread Studio玩转STM32 PWM:从电机控制到呼吸灯,一个框架搞定
用RT-Thread Studio玩转STM32 PWM:从电机控制到呼吸灯,一个框架搞定 在嵌入式开发领域,PWM(脉冲宽度调制)技术堪称"瑞士军刀"般的存在。无论是调节电机转速、控制舵机角度,还是实现LED呼吸灯效果…...

Captain AI:Ozon俄文内容本地化,打破语言壁垒,贴合本土需求
俄文内容本地化是Ozon商家立足俄罗斯市场的核心前提,Ozon平台95%以上的用户为俄语母语者,纯中文或机翻的内容不仅会导致搜索曝光降低,还可能因语言错误引发合规风险、影响买家信任。然而,国内商家普遍面临“俄语专业人才短缺、机翻…...

PS 图片模糊修复教程:4 种方法,一键变高清
在日常设计、摄影后期、电商运营等场景中,模糊图片往往会严重影响观感与使用效果——无论是拍摄时的对焦失误、低分辨率素材的压缩失真,还是老照片的模糊褪色,都需要快速恢复清晰度。本文整理4种超实用的图片清晰化方法,涵盖PS原生…...

CANN算子生成器Agent配置
【免费下载链接】cannbot-skills CANNBot 是面向 CANN 开发的用于提升开发效率的系列智能体,本仓库为其提供可复用的 Skills 模块。 项目地址: https://gitcode.com/cann/cannbot-skills name: triton-op-generator description: Triton-Ascend 算子代码生成…...
)
探灵直播2026最新官方正版免费下载 一键转存 永久更新 (看到速转存 资源随时走丢)
下载链接 本文将为您客观介绍《探灵直播》的幕后作者、核心玩法机制,并将其与同类型竞品进行简单的横向对比,带您全面了解这款作品的独特之处。 一、 幕后作者:专注于美少女题材的 qureate 《探灵直播》的开发商 qureate 是一家在日本游戏界…...

如何轻松地将数据从Android传输到 iPhone ?
从Android切换到 iPhone可能会让人不知所措,尤其是当你想在不重置新设备的情况下保持数据完整时。许多指南都侧重于恢复出厂设置,但在本文中,我们将探讨一些方法,让你能够无缝转移宝贵的数据,而无需清除 iPhone 上的所…...

5步打造你的英雄联盟智能游戏助手:从零到效率革命的完整指南
5步打造你的英雄联盟智能游戏助手:从零到效率革命的完整指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联盟中繁琐…...

AI for Science:从数据驱动到科学发现,构建科研新范式
1. 从AlphaFold到GPT-3:AI如何成为科学家的“新感官”如果你是一位从事物理、化学、生物或材料科学的研究者,最近几年可能时常被一种复杂的情绪所包围:一方面是兴奋,看到像AlphaFold2这样的人工智能工具,几乎一夜间解决…...