ElasticSearch高阶使用
目录
一、match_all
二、 text和keyword的区别
三、match、term的区别
四、exists query
五、 ids query
六、range query范围查询
七、prefix query前缀查询
八、 wildcard query通配符查询
九、 fuzzy query模糊查询
十、match query匹配查询
十一、multi_match query 多字段查询
十二、match_phrase query短语查询
十三、query_string query
十四、simple_query_string query
十五、bool query布尔查询
一、match_all
#使用match_all,匹配所有文档,默认只会返回10条数据。
#原因:_search查询默认采用的是分页查询,每页记录数size的默认值为10。如果想显示更多数据,指定size
GET /es_db/_search
{"query":{# 使用match_all,匹配所有文档,默认只会返回10条数据。# 原因:_search查询默认采用的是分页查询,每页记录数size的默认值为10。如果想显示更多数据,指定size"match_all":{}}# _source 关键字: 是一个数组,在数组中用来指定展示那些字段"_source": ["name","address"]# 不查看源数据,仅查看元字段# "_source": false,# 只看以obj.开头的字段# "_source": "obj.*",# size 关键字: 指定查询结果中返回指定条数。 默认返回值10条"size": 100# from 关键字用来指定起始返回位置,和size关键字连用可实现分页效果,默认是 0"from": 0,# 指定字段排序sort,会让得分失效"sort": [{"age": "desc"}]
}二、 text和keyword的区别
- text类型字段在存储时会分词建立索引,keywaord不会。也就是说text支持模糊查询。keyword只能用于精准查询
- text类型不支持聚合、排序等操作,因为它是被拆分成单个词项存储的,而keyword可以
三、match、term的区别
- match在查询时会将查询条件先分词,分词列表中的任何一个值匹配到记录都会返回相应结果
- match_phrase是短语查询,如果记录中有字段完全包含这个短语则会有查询结果
- term在查询时不会将查询条件分词,而是直接以源查询条件去匹配,如果匹配到记录则返回相应结果。并且使用相关度算分公式为每个包含该词项的文档进行相关度算分。
可以通过 Constant Score 将查询转换成一个 Filtering,避免算分,并利用缓存,提高性能。term处理多值字段时,term查询是包含,不是等于。
GET /es_db/_search
{"query": {"constant_score": {"filter": {"term": {"address.keyword": "广州白云山公园"}}}}
}注意:最好不要在term查询的字段中使用text字段,因为text字段会被分词,这样做既没有意义,还很有可能什么也查不到。
四、exists query
在Elasticsearch中可以使用exists进行查询,以判断文档中是否存在对应的字段
GET / es_db / _search {"query": {"exists": {"field": "remark"}}
}五、 ids query
ids 关键字 : 值为数组类型,用来根据一组id获取多个对应的文档
GET /es_db/_search
{"query": {"ids": {"values": [1, 2]}}
}六、range query范围查询
range:范围关键字
- gte 大于等于
- lte 小于等于
- gt 大于
- lt 小于
- now 当前时间
POST /es_db/_search
{"query": {"range": {"age": {"gte": 25,"lte": 28}}}
}GET /product/_search
{"query": {"range": {"date": {"gte": "now-2y"}}}
}七、prefix query前缀查询
- 它会对分词后的term进行前缀搜索。
- 它不会分析要搜索字符串,传入的前缀就是想要查找的前缀
- 默认状态下,前缀查询不做相关度分数计算,它只是将所有匹配的文档返回,然后赋予所有相关分数值为1。
- 它的行为更像是一个过滤器而不是查询。两者实际的区别就是过滤器是可以被缓存的,而前缀查询不行。
- prefix的原理:需要遍历所有倒排索引,并比较每个term是否以所指定的前缀开头。
GET /es_db/_search
{"query": {"prefix": {"address": {"value": "广州"}}}
}八、 wildcard query通配符查询
通配符查询:工作原理和prefix相同,只不过它不是只比较开头,它能支持更为复杂的匹配模式。
GET /es_db/_search
{"query": {"wildcard": {"address": {"value": "*白*"}}}
}九、 fuzzy query模糊查询
在实际的搜索中,我们有时候会打错字,从而导致搜索不到。在Elasticsearch中,我们可以使用fuzziness属性来进行模糊查询,从而达到搜索有错别字的情形。
fuzzy 查询会用到两个很重要的参数,fuzziness,prefix_length
fuzziness:表示输入的关键字通过几次操作可以转变成为ES库里面的对应field的字段
操作是指:新增一个字符,删除一个字符,修改一个字符,每次操作可以记做编辑距离为1;如中文集团到中威集团编辑距离就是1,只需要修改一个字符;如果fuzziness值在这里设置成2,会把编辑距离为2的东东集团也查出来。
该参数默认值为0,即不开启模糊查询; fuzzy 模糊查询 最大模糊错误必须在0-2之间
prefix_length:表示限制输入关键字和ES对应查询field的内容开头的第n个字符必须完全匹配,不允许错别字匹配;如这里等于1,则表示开头的字必须匹配,不匹配则不返回;默认值也是0;
加大prefix_length的值可以提高效率和准确率。
GET /es_db /_search
{"query": {"fuzzy": {"address": {"value": "白运山","fuzziness": 1}}}
}十、match query匹配查询
match在匹配时会对所查找的关键词进行分词,然后按分词匹配查找。
match支持以下参数:
- query : 指定匹配的值
- operator : 匹配条件类型
- and : 条件分词后都要匹配
- or : 条件分词后有一个匹配即可(默认)
- minmum_should_match : 最低匹配度,即条件在倒排索引中最低的匹配度
#match 分词后or的效果
GET /es_db/_search
{"query": {"match": {"address": "广州白云山公园"}}
}# 分词后 and的效果
GET /es_db/_search
{"query": {"match": {"address": {"query": "广州白云山公园","operator": "and"}}}
}在match中的应用: 当operator参数设置为or时,minnum_should_match参数用来控制匹配的分词的最少数量。
# 最少匹配广州,公园两个词
GET /es_db/_search
{"query": {"match": {"address": {"query": "广州公园","minimum_should_match": 2}}}
}对于match查询,其底层逻辑的概述:
- 分词:首先,输入的查询文本会被分词器进行分词。分词器会将文本拆分成一个个词项(terms),如单词、短语或特定字符。分词器通常根据特定的语言规则和配置进行操作。
- 倒排索引:ES使用倒排索引来加速搜索过程。倒排索引是一种数据结构,它将词项映射到包含这些词项的文档。每个词项都有一个对应的倒排列表,其中包含了包含该词项的所有文档的引用。
- 匹配计算:一旦查询被分词,ES将根据查询的类型和参数计算文档与查询的匹配度。对于match查询,ES将比较查询的词项与倒排索引中的词项,并计算文档的相关性得分。相关性得分衡量了文档与查询的匹配程度。
- 结果返回:根据相关性得分,ES将返回最匹配的文档作为搜索结果。搜索结果通常按照相关性得分进行排序,以便最相关的文档排在前面。
十一、multi_match query 多字段查询
多字段查询,可以根据字段类型,决定是否使用分词查询,得分最高的在前面
GET /es_db/_search
{"query": {"multi_match": {"query": "长沙张龙","fields": ["address","name"]}}
}注意:字段类型分词,将查询条件分词之后进行查询,如果该字段不分词就会将查询条件作为整体进行查询。
十二、match_phrase query短语查询
短语搜索(match phrase)会对搜索文本进行文本分析,然后到索引中寻找搜索的每个分词并要求分词相邻,你可以通过调整slop参数设置分词出现的最大间隔距离。match_phrase 会将检索关键词分词。可以借助slop参数,slop参数告诉match_phrase查询词条能够相隔多远(位置偏移量,不是隔多少个分词)时仍然将文档视为匹配。
GET /es_db/_search
{"query": {"match_phrase": {"address": {"query": "广州云山","slop": 2}}}
}十三、query_string query
允许我们在单个查询字符串中指定AND | OR | NOT条件,同时也和 multi_match query 一样,支持多字段搜索。和match类似,但是match需要指定字段名,query_string是在所有字段中搜索,范围更广泛。
注意: 查询字段分词就将查询条件分词查询,查询字段不分词将查询条件不分词查询
# 未指定字段查询# AND 要求大写
GET /es_db/_search
{"query": {"query_string": {"query": "赵六 AND 橘子洲"}}
}# 指定单个字段查询
#Query String
GET /es_db/_search
{"query": {"query_string": {"default_field": "address","query": "白云山 OR 橘子洲"}}
}# 指定多个字段查询
GET /es_db/_search
{"query": {"query_string": {"fields": ["name","address"],"query": "张三 OR (广州 AND 王五)"}}
}十四、simple_query_string query
类似Query String,但是会忽略错误的语法,同时只支持部分查询语法,不支持AND OR NOT,会当作字符串处理。支持部分逻辑:
- + 替代AND
- | 替代OR
- - 替代NOT
GET /es_db/_search
{"query": {"simple_query_string": {"fields": ["name", "address"],"query": "广州公园","default_operator": "AND"}}
}GET /es_db/_search
{"query": {"simple_query_string": {"fields": ["name", "address"],"query": "广州 + 公园"}}
}十五、bool query布尔查询
布尔查询可以按照布尔逻辑条件组织多条查询语句,只有符合整个布尔条件的文档才会被搜索出来。
在布尔条件中,可以包含两种不同的上下文。
1. 搜索上下文(query context):使用搜索上下文时,Elasticsearch需要计算每个文档与搜索条件的相关度得分,这个得分的计算需使用一套复杂的计算公式,有一定的性能开销,带文本分析的全文检索的查询语句很适合放在
搜索上下文中。
2. 过滤上下文(filter context):使用过滤上下文时,Elasticsearch只需要判断搜索条件跟文档数据是否匹配,例如使用Term query判断一个值是否跟搜索内容一致,使用Range query判断某数据是否位于某个区间等。过滤上下文的查询不需要进行相关度得分计算,还可以使用缓存加快响应速度,很多术语级查询语句都适合放在过滤上下文中。
布尔查询一共支持4种组合类型:
| 类型 | 说明 |
| filter | 可包含多个过滤条件,每个条件均满足的文档才能被搜索到,每个过滤条件不计算相关度得分,结果在一定条件下会被缓存, 属于过滤上下文 |
| must | 可包含多个查询条件,每个条件均满足的文档才能被搜索到,每次查询需要计算相关度得分,属于搜索上下文 |
| must_not | 可包含多个过滤条件,每个条件均不满足的文档才能被搜索到,每个过滤条件不计算相关度得分,结果在一定条件下会被缓存, 属于过滤上下文 |
| should | 可包含多个查询条件,不存在must和fiter条件时,至少要满足多个查询条件中的一个,文档才能被搜索到,否则需满足的条件数量不受限制,匹配到的查询越多相关度越高,也属于搜索上下文 |
GET /books/_search
{"query ": {"bool": {"must": [{"match": {title ": "java编程"}}, {"match": {"description": "性能优化"}}]}}
}GET /books/_search
{"query": {"bool": {"should": [{"match": {"title": "java编程"}}, {"match": {"description": "性能优化"}}],"minimum_should_match": 1}}
}GET /books/_search
{"query": {"bool": {"filter": [{"term": {"language": "java"}},{"range": {"publish_time": {"gte": "2010-08-01"}}}]}}
}相关文章:

ElasticSearch高阶使用
目录 一、match_all 二、 text和keyword的区别 三、match、term的区别 四、exists query 五、 ids query 六、range query范围查询 七、prefix query前缀查询 八、 wildcard query通配符查询 九、 fuzzy query模糊查询 十、match query匹配查询 十一、multi_match q…...

美易官方:盘前:道指期货跌0.4% “恐怖数据”将发布
盘前:道指期货跌0.4% “恐怖数据”将发布 在今日的盘前交易中,道琼斯工业平均指数期货小幅下跌0.4%,市场正在等待即将发布的“恐怖数据”——美国零售销售数据。这一数据被视为衡量美国经济健康状况的重要指标,因此备受关注。 由于…...
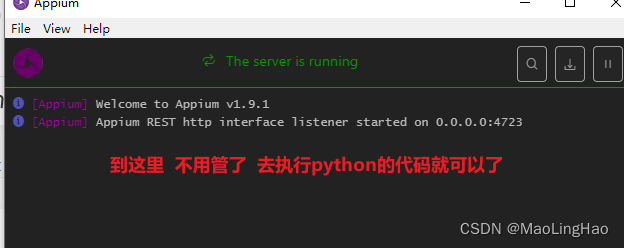
appium之联动pycharm
前置条件: 1.java环境安装好了 2.android-sdk安装好(uiautomatorviewer 也可以把这个启动起来) 3.appium安装好 4.adb devices查看下设备是否连接 pycharm入门代码--固定写法 from appium import webdriver# 定义字典变量 desired_caps …...

Java中泛型的详细介绍
引言: Java语言中的泛型是一种强大的特性,它允许我们在编写代码时指定类、接口和方法的参数类型。通过使用泛型,我们可以提高代码的重用性、可读性和安全性。在本博客中,我们将详细介绍Java中泛型的知识。 一、泛型的基本概念 泛型…...

chrome 307状态码
问题:不知道什么原因导致http请求chrome始终307跳转到https,这个307的跳转非常恶心的地方是客户端缓存行为,并且非普通的f12下面清除缓存可以去掉 解决办法:使用chrome的清除浏览数据,通过这个方式清除,才能解决。 问…...
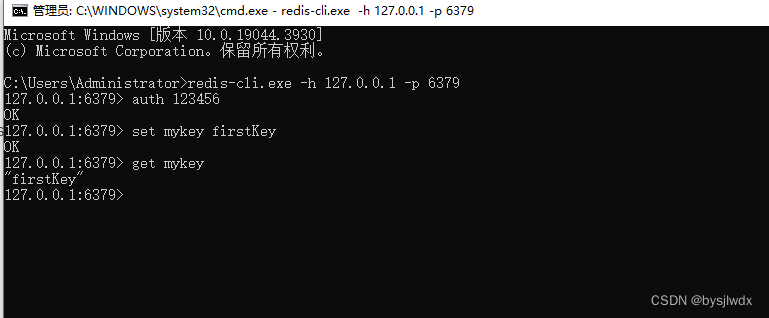
Redis在Windows10中安装和配置
1.首先去下载Redis 这里不给出下载地址,自己可以用去搜索一下地址 下载 下载完成后解压到D盘redis下,本人用的是3.2.100 D:\Redis\Redis-x64-3.2.100 2.解压完成后需要设置环境变量,这里新建一个系统环境变量中path 中添加一个文件所…...
)
华为OD机试 - 特殊的加密算法(Java JS Python C)
题目描述 有一种特殊的加密算法,明文为一段数字串,经过密码本查找转换,生成另一段密文数字串。 规则如下: 明文为一段数字串由 0~9 组成密码本为数字 0~9 组成的二维数组需要按明文串的数字顺序在密码本里找到同样的数字串,密码本里的数字串是由相邻的单元格数字组成,上…...
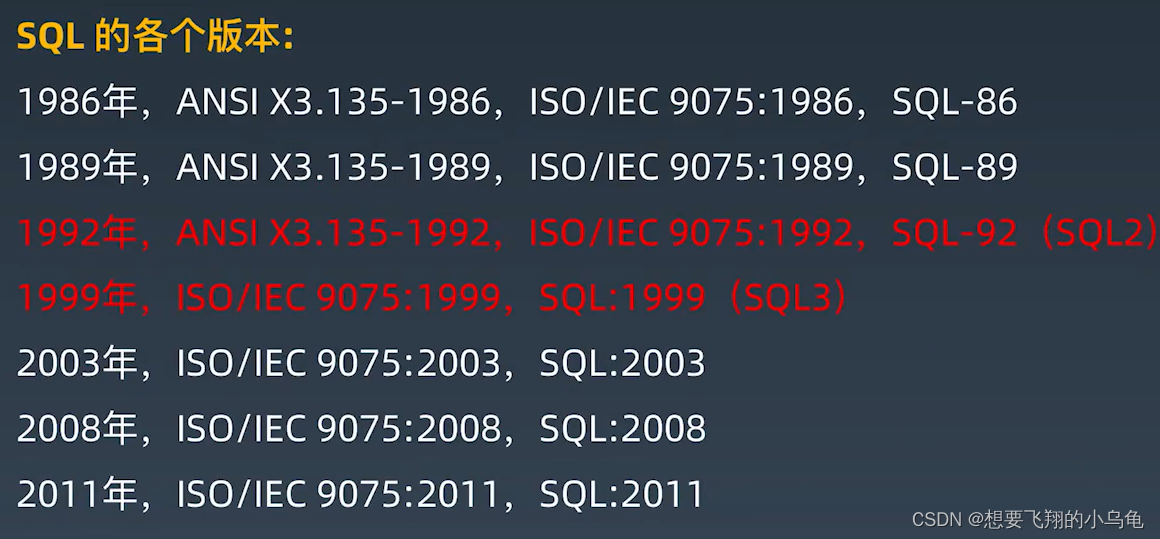
MySQL——性能优化与关系型数据库
文章目录 什么是性能?什么是关系型数据库?数据库设计范式 常见的数据库SQL语言结构化查询语言的六个部分版本 MySQL数据库故事历史版本5.6/5.7差异5.7/8.0差异 什么是性能? 吞吐与延迟:有些结论是反直觉的,指导我们关…...
【机器学习300问】12、为什么要进行特征归一化?
当线性回归模型的特征量变多之后,会出现不同的特征量,然而对于那些同是数值型的特征量为什么要做归一化处理呢? 一、为了消除数据特征之间的量纲影响 使得不同指标之间具有可比性。例如,分析一个人的身高和体重对健康的影响&…...
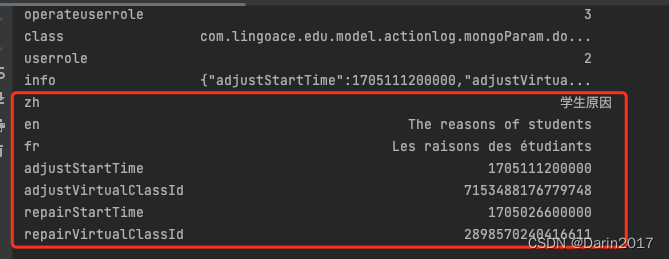
CSV文件中json列的处理2
如上所示,csv文件中包含以中括号{}包含的json字段,可用如下方法提取: import pandas as pd from datetime import date todaystr(date.today()) import jsonfilepath/Users/kangyongqing/Documents/kangyq/202401/调课功能使用统计/ file104…...
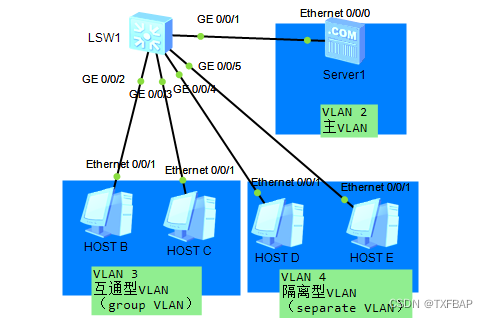
eNSP学习——部分VLAN间互通、部分VLAN间隔离、VLAN内用户隔离(MUX-VLAN)
MUX VLAN(Multiplex VLAN)提供了一种通过VLAN进行网络资源控制 的机制。通过MUX VLAN提供的二层流量隔离的机制可以实现企业内部员 工之间互相通信,而企业外来访客之间的互访是隔离的。 特点: 一、主VLAN端口可以和所有VLAN通信 二…...
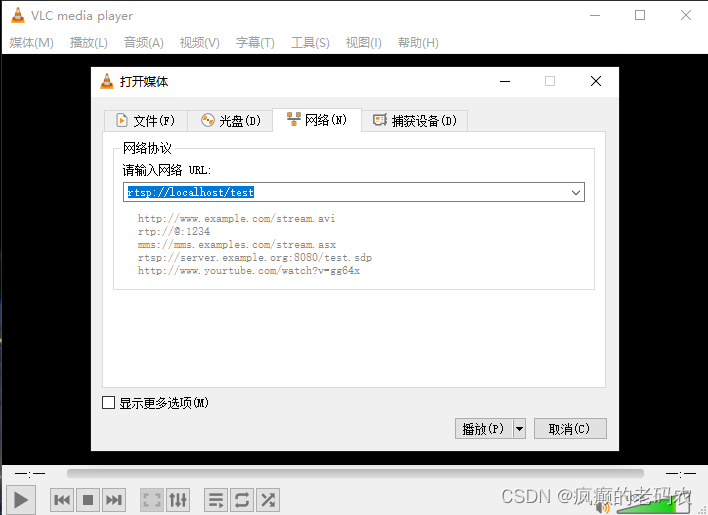
【音视频】如何播放rtsp视频流
背景 现阶段直播越来越流行,直播技术发展也越来越快。Webrtc和rtsp是比较火热的技术,而且应用也比较广泛。本文通过实践来展开介绍关于rtsp、webrtc的使用过程。 概要 本文重点介绍如何播放rtsp视频流,通过ffplay方式以及VLC media player…...

Qt6入门教程 8:信号和槽机制(连接方式)
目录 一.一个信号与槽连接的例子 二.第五个参数 1.Qt::AutoConnection 2.Qt::DirectConnection 3.Qt::QueuedConnection 4.Qt::BlockingQueuedConnection 5.Qt::UniqueConnection 三.信号 四.connect函数原型 五.信号与槽的多种用法 六.槽的属性 一.一个信号与槽连接…...

Python如何操作RabbitMQ实现fanout发布订阅模式?有录播直播私教课视频教程
fanout发布订阅模式 基本用法 生产者 import json import rabbitmq# 建立连接 credentials rabbitmq.PlainCredentials(zhangdapeng,zhangdapeng520, ) # mq用户名和密码 connection_target rabbitmq.ConnectionParameters(host127.0.0.1,port5672,virtual_host/,credent…...

QT 原生布局和QML的区别
一、QML 与 Qt Quick的区别 1.1 从概念上区分 为了更精确地对两者进行说明,先看助手对 QML 的描述: QML is a user interface specification and programming language. QML 是一种用户界面规范和标记语言,允许开发人员和设计师创建高性能、流…...

视频转码实例:把MP4转为MKV视频,一键批量转换的操作方法
在数字媒体时代,视频格式的多样性是不可避免的。经常把MP4格式的视频转换为MKV格式。MKV格式有较高的音频和视频质量,能在其他设备或软件上播放视频。以下是云炫AI智剪如何把MP4视频转为MKV格式的一键批量转换操作方法。 已转码的mkv视频效果缩略图展示…...

异步Merkle Tree
1. 引言 前序博客: 利用多核的Rust快速Merkle tree Anoushk Kharangate 2023年论文《Asynchronous Merkle Trees》,其对Merkle tree数据结构进行修改,使得可跨多线程异步计算。 开源代码实现见: https://github.com/anoushk1…...

7. UE5 RPG修改GAS的Attribute的值
前面几节文章介绍了如何在角色身上添加AbilitySystemComponent和AttributeSet。并且还实现了给AttributeSet添加自定义属性。接下来,实现一下如何去修改角色身上的Attribute的值。 实现拾取药瓶回血功能 首先创建一个继承于Actor的c类,actor是可以放置到…...

Oracle/DM序列基本使用
序列(SEQUENCE)是序列号生成器,可以为表中的行自动生成序列号,产生一组等间隔的数值(类型为数字)。其主要的用途是生成表的主键值,可以在插入语句中引用,也可以通过查询检查当前值,或使序列增至下一个值。序列是一个计…...

校验ChatGPT 4真实性的三个经典问题:提供免费测试网站快速区分 GPT3.5 与 GPT4
现在已经有很多 ChatGPT 的套壳网站,以下分享验明 GPT-4 真身的三个经典问题,帮助你快速区分套壳网站背后到底用的是 GPT-3.5 还是 GPT-4。 大家可以在这个网站测试:https://ai.hxkj.vip,免登录可以问三条,登录之后无限…...

CANN ops-sparse与Ascend C编程:深入理解NPU原生稀疏计算
CANN ops-sparse与Ascend C编程:深入理解NPU原生稀疏计算 【免费下载链接】ops-sparse 本项目是CANN提供的高性能稀疏矩阵计算的算子库,专注于优化稀疏矩阵的计算效率。 项目地址: https://gitcode.com/cann/ops-sparse 在高性能计算领域…...

【大模型12步学习路线 · 第12步 · ①原理篇】多模态 LLM + Multimodal RAG 全景:从 Qwen3-VL 到 ColPali / ColQwen2.5,让 LLM看懂Spec
【大模型12步学习路线 第12步 ①原理篇】多模态 LLM + Multimodal RAG 全景:从 Qwen3-VL 到 ColPali / ColQwen2.5,让 LLM"看懂"Spec 时序图 系列定位:「大模型正确学习顺序」12 步系列 第 12 步 多模态 的 ①原理篇 —— 最后一步,Veri-Copilot v1.0 大结局。 前…...

告别手动下载:用CNKI-download轻松实现知网文献批量获取
告别手动下载:用CNKI-download轻松实现知网文献批量获取 【免费下载链接】CNKI-download :frog: 知网(CNKI)文献下载及文献速览爬虫 (Web Scraper for Extracting Data) 项目地址: https://gitcode.com/gh_mirrors/cn/CNKI-download 还在为毕业论文的文献收…...

多语种语音合成新突破,ElevenLabs维吾尔语TTS上线即受限?3类企业正在紧急迁移替代方案
更多请点击: https://kaifayun.com 第一章:ElevenLabs维吾尔语TTS上线即受限的技术真相 ElevenLabs在2024年3月宣布支持维吾尔语(ug)文本转语音,但实际调用API时立即触发服务端策略拦截——即便请求头携带合法API密钥…...

终极指南:如何用TrafficMonitor股票插件打造桌面投资监控中心
终极指南:如何用TrafficMonitor股票插件打造桌面投资监控中心 【免费下载链接】TrafficMonitorPlugins 用于TrafficMonitor的插件 项目地址: https://gitcode.com/gh_mirrors/tr/TrafficMonitorPlugins 还在为错过重要股票行情而烦恼吗?想在工作时…...

如何在GTA5在线模式中保护自己?YimMenu安全增强菜单完整指南
如何在GTA5在线模式中保护自己?YimMenu安全增强菜单完整指南 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/y…...

vscode使用claude code接入deepseek教程
1 在VSCode拓展商城中搜索Claude Code for VS Code,安装2 快捷键Ctrl“,”,进入设置,选择拓展,选择Claude Code。接着往下拉找到Environment Variables,点击下方的“在settings.json中编辑”,将…...

别再瞎找了!2026年不容错过的专业AI论文软件
2026年AI论文写作工具已从“基础生成”升级为智能协同研究系统,核心评价维度包括文献真实性、格式合规性、长文本逻辑、查重降重、AIGC合规与多语言支持。本次测评覆盖6款主流工具,涵盖中文与英文场景、全流程与专项功能、免费与付费版本,让你…...
:7类发音错误+5个未公开参数修复方案)
ElevenLabs印地文语音质量崩塌真相(印地语TTS失效深度溯源):7类发音错误+5个未公开参数修复方案
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs印地文语音质量崩塌的全局现象与影响评估 近期,ElevenLabs平台在印地语(Hindi)TTS合成任务中出现系统性语音质量退化,表现为音素错读、韵律断裂…...

深拷贝和浅拷贝深入讲解
What? 浅拷贝和深拷贝发生在对象和对象之间,假设你需要将一个对象的值赋予给另一个对象,这个过程就叫做拷贝。那么拷贝的过程中,对象的属性中可能既有普通变量也有对象,能够复制后副本对象的引用指向新地址的就是深拷贝ÿ…...