Go 中 slice 的 In 功能实现探索

文章目录
- 遍历
- 二分查找
- map key
- 性能
- 总结
之前在知乎看到一个问题:为什么 Golang 没有像 Python 中 in 一样的功能?于是,搜了下这个问题,发现还是有不少人有这样的疑问。
补充:本文写于 2019 年。GO 现在已经支持泛型,而且新增了一个 slices 包,已经支持了 Contains 方法。
今天来谈谈这个话题。
in 是一个很常用的功能,有些语言中可能也称为 contains,虽然不同语言的表示不同,但基本都是有的。不过可惜的是,Go 却没有,它即没有提供类似 Python 操作符 in,也没有像其他语言那样提供这样的标准库函数,如 PHP 中 in_array。
Go 的哲学是追求少即是多。我想或许 Go 团队觉得这是一个实现起来不足为道的功能吧。
为何说微不足道?如果要自己实现,又该如何做呢?
我所想到的有三种实现方式,一是遍历,二是 sort 的二分查找,三是 map 的 key 索引。
本文相关源码已经上传在我的 github 上,poloxue/gotin。
遍历
遍历应该是我们最容易想到的最简单的实现方式。
示例如下:
func InIntSlice(haystack []int, needle int) bool {for _, e := range haystack {if e == needle {return true}}return false
}
上面演示了如何在一个 []int 类型变量中查找指定 int 是否存在的例子,是不是非常简单,由此我们也可以感受到我为什么说它实现起来微不足道。
这个例子有个缺陷,它只支持单一类型。如果要支持像解释语言一样的通用 in 功能,则需借助反射实现。
代码如下:
func In(haystack interface{}, needle interface{}) (bool, error) {sVal := reflect.ValueOf(haystack)kind := sVal.Kind()if kind == reflect.Slice || kind == reflect.Array {for i := 0; i < sVal.Len(); i++ {if sVal.Index(i).Interface() == needle {return true, nil}}return false, nil}return false, ErrUnSupportHaystack
}
为了更加通用,In 函数的输入参数 haystack 和 needle 都是 interface{} 类型。
简单说说输入参数都是 interface{} 的好处吧,主要有两点,如下:
其一,haystack 是 interface{} 类型,使 in 支持的类型不止于 slice,还包括 array。我们看到,函数内部通过反射对 haystack 进行了类型检查,支持 slice(切片)与 array(数组)。如果是其他类型则会提示错误,增加新的类型支持,如 map,其实也很简单。但不推荐这种方式,因为通过 _, ok := m[k] 的语法即可达到 in 的效果。
其二,haystack 是 interface{},则 []interface{} 也满足要求,并且 needle 是 interface{}。如此一来,我们就可以实现类似解释型语言一样的效果了。
怎么理解?直接示例说明,如下:
gotin.In([]interface{}{1, "two", 3}, "two")
haystack 是 []interface{}{1, “two”, 3},而且 needle 是 interface{},此时的值是 “two”。如此看起来,是不是实现了解释型语言中,元素可以是任意类型,不必完全相同效果。如此一来,我们就可以肆意妄为的使用了。
但有一点要说明,In 函数的实现中有这样一段代码:
if sVal.Index(i).Interface() == needle {...
}
Go 中并非任何类型都可以使用 == 比较的,如果元素中含有 slice 或 map,则可能会报错。
二分查找
以遍历确认元素是否存在有个缺点,那就是,如果数组或切片中包含了大量数据,比如 1000000 条数据,即一百万,最坏的情况是,我们要遍历 1000000 次才能确认,时间复杂度 On。
有什么办法可以降低遍历次数?
自然而然地想到的方法是二分查找,它的时间复杂度 log2(n) 。但这个算法有前提,需要依赖有序序列。
于是,第一个要我们解决的问题是使序列有序,Go 的标准库已经提供了这个功能,在 sort 包下。
示例代码如下:
fmt.Println(sort.SortInts([]int{4, 2, 5, 1, 6}))
对于 []int,我们使用的函数是 SortInts,如果是其他类型切片,sort 也提供了相关的函数,比如 []string 可通过 SortStrings 排序。
完成排序就可以进行二分查找,幸运的是,这个功能 Go 也提供了,[]int 类型对应函数是 SearchInts。
简单介绍下这个函数,先看定义:
func SearchInts(a []int, x int) int
输入参数容易理解,从切片 a 中搜索 x。重点要说下返回值,这对于我们后面确认元素是否存在至关重要。返回值的含义,返回查找元素在切片中的位置,如果元素不存在,则返回,在保持切片有序情况下,插入该元素应该在什么位置。
比如,序列如下:
1 2 6 8 9 11
假设,x 为 6,查找之后将发现它的位置在索引 2 处;x 如果是 7,发现不存在该元素,如果插入序列,将会放在 6 和 8 之间,索引位置是 3,因而返回值为 3。
代码测试下:
fmt.Println(sort.SearchInts([]int{1, 2, 6, 8, 9, 11}, 6)) // 2
fmt.Println(sort.SearchInts([]int{1, 2, 6, 8, 9, 11}, 7)) // 3
如果判断元素是否在序列中,只要判断返回位置上的值是否和查找的值相同即可。
但还有另外一种情况,如果插入元素位于序列最后,例如元素值为 12,插入位置即为序列的长度 6。如果直接查找 6 位置上的元素就可能发生越界的情况。那怎么办呢?其实判断返回是否小于切片长度即可,小于则说明元素在切片序列中。
完整的实现代码如下:
func SortInIntSlice(haystack []int, needle int) bool {sort.Ints(haystack)index := sort.SearchInts(haystack, needle)return index < len(haystack) && haystack[index] == needle
}
但这还有个问题,对于无序的场景,如果每次查询都要经过一次排序并不划算。最好能实现一次排序,稍微修改下代码。
func InIntSliceSortedFunc(haystack []int) func(int) bool {sort.Ints(haystack)return func(needle int) bool {index := sort.SearchInts(haystack, needle)return index < len(haystack) && haystack[index] == needle}
}
上面的实现,我们通过调用 InIntSliceSortedFunc 对 haystack 切片排序,并返回一个可多次使用的函数。
使用案例如下:
in := gotin.InIntSliceSortedFunc(haystack)for i := 0; i<maxNeedle; i++ {if in(i) {fmt.Printf("%d is in %v", i, haystack)}
}
二分查找的方式有什么不足呢?
我想到的重要一点,要实现二分查找,元素必须是可排序的,如 int,string,float 类型。而对于结构体、切片、数组、映射等类型,使用起来就不是那么方便,当然,如果要用,也是可以的,不过需要我们进行一些适当扩展,按指定标准排序,比如结构的某个成员。
到此,二分查找的 in 实现就介绍完毕了。
map key
本节介绍 map key 方式。它的算法复杂度是 O1,无论数据量多大,查询性能始终不变。它主要依赖的是 Go 中的 map 数据类型,通过 hash map 直接检查 key 是否存在,算法大家应该都比较熟悉,通过 key 可直接映射到索引位置。
我们常会用到这个方法。
_, ok := m[k]
if ok {fmt.Println("Found")
}
那么它和 in 如何结合呢?一个案例就说明白了这个问题。
假设,我们有一个 []int 类型变量,如下:
s := []int{1, 2, 3}
为了使用 map 的能力检查某个元素是否存在,可以将 s 转化 map[int]struct{}。
m := map[interface{}]struct{}{1: struct{}{},2: struct{}{},3: struct{}{},4: struct{}{},
}
如果检查某个元素是否存在,只需要通过如下写法即可确定:
k := 4
if _, ok := m[k]; ok {fmt.Printf("%d is found\n", k)
}
是不是非常简单?
补充一点,关于这里为什么使用 struct{},可以阅读我之前写的一篇关于 Go 中如何使用 set 的文章。
按照这个思路,实现函数如下:
func MapKeyInIntSlice(haystack []int, needle int) bool {set := make(map[int]struct{})for _ , e := range haystack {set[e] = struct{}{}}_, ok := set[needle]return ok
}
实现起来不难,但和二分查找有着同样的问题,开始要做数据处理,将 slice 转化为 map。如果是每次数据相同,稍微修改下它的实现。
func InIntSliceMapKeyFunc(haystack []int) func(int) bool {set := make(map[int]struct{})for _ , e := range haystack {set[e] = struct{}{}}return func(needle int) bool {_, ok := set[needle]return ok}
}
对于相同的数据,它会返回一个可多次使用的 in 函数,一个使用案例如下:
in := gotin.InIntSliceMapKeyFunc(haystack)for i := 0; i<maxNeedle; i++ {if in(i) {fmt.Printf("%d is in %v", i, haystack)}
}
对比前两种算法,这种方式的处理效率最高,非常适合于大数据的处理。接下来的性能测试,我们将会看到效果。
性能
介绍完所有方式,我们来实际对比下每种算法的性能。测试源码位于 gotin_test.go 文件中。
基准测试主要是从数据量大小考察不同算法的性能,本文中选择了三个量级的测试样本数据,分别是 10、1000、1000000。
为便于测试,首先定义了一个用于生成 haystack 和 needle 样本数据的函数。
代码如下:
func randomHaystackAndNeedle(size int) ([]int, int){haystack := make([]int, size)for i := 0; i<size ; i++{haystack[i] = rand.Int()}return haystack, rand.Int()
}
输入参数是 size,通过 rand.Int() 随机生成切片大小为 size 的 haystack 和 1 个 needle。在基准测试用例中,引入这个随机函数生成数据即可。
举个例子,如下:
func BenchmarkIn_10(b *testing.B) {haystack, needle := randomHaystackAndNeedle(10)b.ResetTimer()for i := 0; i < b.N; i++ {_, _ = gotin.In(haystack, needle)}
}
首先,通过 randomHaystackAndNeedle 随机生成了一个含有 10 个元素的切片。因为生成样本数据的时间不应该计入到基准测试中,我们使用 b.ResetTimer() 重置了时间。
其次,压测函数是按照 Test+函数名+样本数据量 规则编写,如案例中 BenchmarkIn_10,表示测试 In 函数,样本数据量为 10。如果我们要用 1000 数据量测试 InIntSlice,压测函数名为 BenchmarkInIntSlice_1000。
测试开始吧!简单说下我的笔记本配置,Mac Pro 15 版,16G 内存,512 SSD,4 核 8 线程的 CPU。
测试所有函数在数据量在 10 的情况下的表现。
$ go test -run=none -bench=10$ -benchmem
匹配所有以 10 结尾的压测函数。
测试结果:
goos: darwin
goarch: amd64
pkg: github.com/poloxue/gotin
BenchmarkIn_10-8 3000000 501 ns/op 112 B/op 11 allocs/op
BenchmarkInIntSlice_10-8 200000000 7.47 ns/op 0 B/op 0 allocs/op
BenchmarkInIntSliceSortedFunc_10-8 100000000 22.3 ns/op 0 B/op 0 allocs/op
BenchmarkSortInIntSlice_10-8 10000000 162 ns/op 32 B/op 1 allocs/op
BenchmarkInIntSliceMapKeyFunc_10-8 100000000 17.7 ns/op 0 B/op 0 allocs/op
BenchmarkMapKeyInIntSlice_10-8 3000000 513 ns/op 163 B/op 1 allocs/op
PASS
ok github.com/poloxue/gotin 13.162s
表现最好的并非 SortedFunc 和 MapKeyFunc,而是最简单的针对单类型的遍历查询,平均耗时 7.47ns/op,当然,另外两种方式表现也不错,分别是 22.3ns/op 和 17.7ns/op。
表现最差的是 In、SortIn(每次重复排序) 和 MapKeyIn(每次重复创建 map)两种方式,平均耗时分别为 501ns/op 和 513ns/op。
测试所有函数在数据量在 1000 的情况下的表现。
$ go test -run=none -bench=1000$ -benchmem
测试结果:
goos: darwin
goarch: amd64
pkg: github.com/poloxue/gotin
BenchmarkIn_1000-8 30000 45074 ns/op 8032 B/op 1001 allocs/op
BenchmarkInIntSlice_1000-8 5000000 313 ns/op 0 B/op 0 allocs/op
BenchmarkInIntSliceSortedFunc_1000-8 30000000 44.0 ns/op 0 B/op 0 allocs/op
BenchmarkSortInIntSlice_1000-8 20000 65401 ns/op 32 B/op 1 allocs/op
BenchmarkInIntSliceMapKeyFunc_1000-8 100000000 17.6 ns/op 0 B/op 0 allocs/op
BenchmarkMapKeyInIntSlice_1000-8 20000 82761 ns/op 47798 B/op 65 allocs/op
PASS
ok github.com/poloxue/gotin 11.312s
表现前三依然是 InIntSlice、InIntSliceSortedFunc 和 InIntSliceMapKeyFunc,但这次顺序发生了变化,MapKeyFunc 表现最好,17.6 ns/op,与数据量 10 的时候相比基本无变化。再次验证了前文的说法。
同样的,数据量 1000000 的时候。
$ go test -run=none -bench=1000000$ -benchmem
测试结果如下:
goos: darwin
goarch: amd64
pkg: github.com/poloxue/gotin
BenchmarkIn_1000000-8 30 46099678 ns/op 8000098 B/op 1000001 allocs/op
BenchmarkInIntSlice_1000000-8 3000 424623 ns/op 0 B/op 0 allocs/op
BenchmarkInIntSliceSortedFunc_1000000-8 20000000 72.8 ns/op 0 B/op 0 allocs/op
BenchmarkSortInIntSlice_1000000-8 10 138873420 ns/op 32 B/op 1 allocs/op
BenchmarkInIntSliceMapKeyFunc_1000000-8 100000000 16.5 ns/op 0 B/op 0 allocs/op
BenchmarkMapKeyInIntSlice_1000000-8 10 156215889 ns/op 49824225 B/op 38313 allocs/op
PASS
ok github.com/poloxue/gotin 15.178s
MapKeyFunc 依然表现最好,每次操作用时 17.2 ns,Sort 次之,而 InIntSlice 呈现线性增加的趋势。一般情况下,如果不是对性能要特殊要求,数据量特别大的场景,针对单类型的遍历已经有非常好的性能了。
从测试结果可以看出,反射实现的通用 In 函数每次执行需要进行大量的内存分配,方便的同时,也是以牺牲性能为代价的。
总结
本文通过一个问题引出主题,为什么 Go 中没有类似 Python 的 In 方法。我认为,一方面是实现非常简单,没有必要。除此以外,另一方面,在不同场景下,我们还需要根据实际情况分析用哪种方式实现,而不是一种固定的方式。
接着,我们介绍了 In 实现的三种方式,并分析了各自的优劣。通过性能分析测试,我们能得出大致的结论,什么方式适合什么场景,但总体还是不能说足够细致,有兴趣的朋友可以继续研究下。
相关文章:
Go 中 slice 的 In 功能实现探索
文章目录 遍历二分查找map key性能总结 之前在知乎看到一个问题:为什么 Golang 没有像 Python 中 in 一样的功能?于是,搜了下这个问题,发现还是有不少人有这样的疑问。 补充:本文写于 2019 年。GO 现在已经支持泛型&am…...
 pyDAL的一些性能优化)
pyDAL一个python的ORM(终) pyDAL的一些性能优化
一、大批量插入数据 对于 大量数据插入时,虽然pyDAL也手册中有个方法:bulk_insert(),但是手册也说了,虽然方法上是一次可以多条数据,如果后端数据库是关系型数据库,他转换为SQL时它是一条一条的插入的&…...

springboot log4j配置xml实例说明
提供样本配置代码 xml <?xml version"1.0" encoding"UTF-8"?> <!--日志级别以及优先级排序: OFF > FATAL > ERROR > WARN > INFO > DEBUG > TRACE > ALL --> <!-- status log4j2内部日志级别 --> <configurat…...
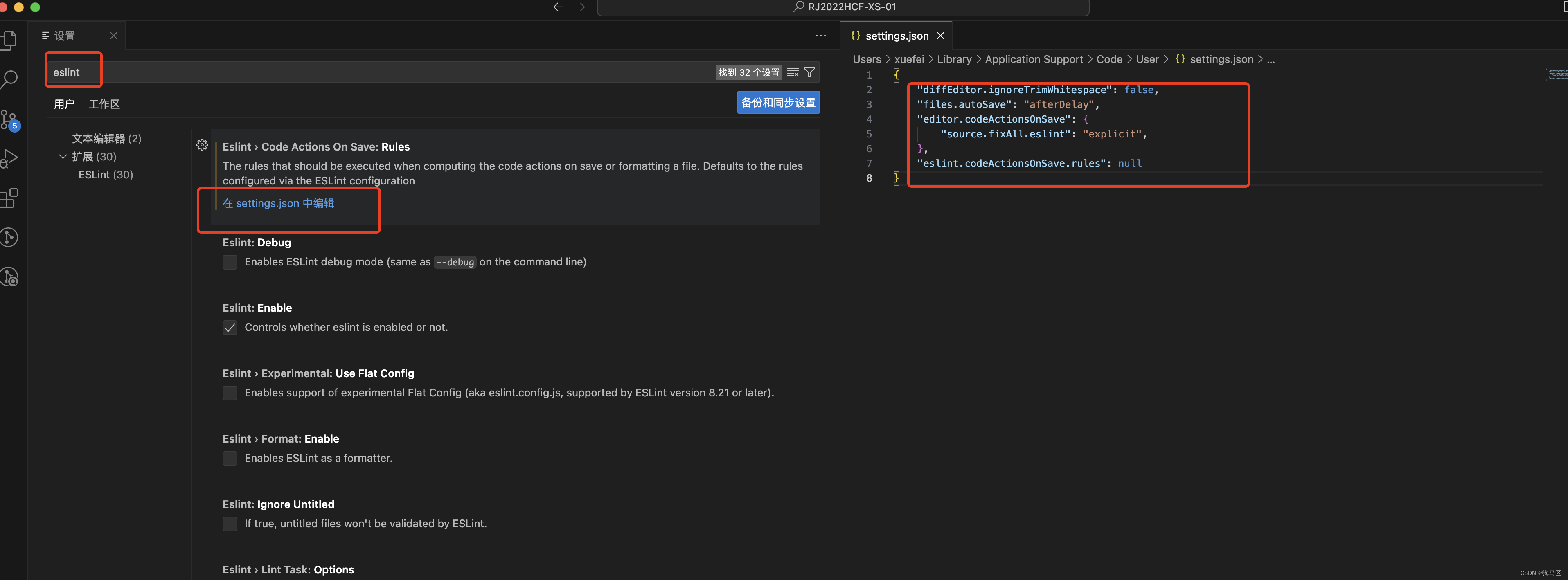
VsCode重新安装需要配机的ESLint和 Prettier - Code formatter 配置
新电脑安装完Vscode后,需要装几个插件,这里记录下: {"diffEditor.ignoreTrimWhitespace": false,"files.autoSave": "afterDelay","editor.codeActionsOnSave": {"source.fixAll.eslint"…...
录屏功能怎么打开?简单操作,一学就会!
录屏功能在当今互联网时代变得越来越重要,无论是游戏录制、在线课程录制还是屏幕操作演示,录屏功能都为我们提供了便捷的解决方案。可是您知道录屏功能怎么打开吗?接下来,让我们一起探索如何在电脑上开启录屏功能,记录…...

小程序显示兼容处理,home键处理
定义: env(safe-area-inset-bottom)和env(safe-area-inset-top)是CSS中的变量,用于获取设备底部和顶部安全区域的大小 示例: padding-bottom: calc(env(safe-area-inset-bottom) 12px); /* 兼容iOS> 11.2 */安全间距类型: …...
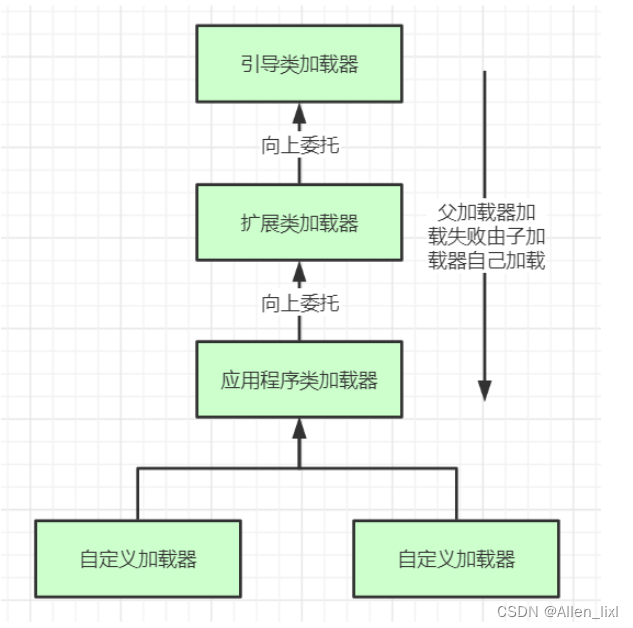
【java八股文】之JVM基础篇
【java八股文】之JVM基础篇-CSDN博客 【java八股文】之MYSQL基础篇-CSDN博客 【java八股文】之Redis基础篇-CSDN博客 【java八股文】之Spring系列篇-CSDN博客 【java八股文】之分布式系列篇-CSDN博客 【java八股文】之多线程篇-CSDN博客 【java八股文】之JVM基础篇-CSDN博…...

2024美赛数学建模思路 - 案例:异常检测
文章目录 赛题思路一、简介 -- 关于异常检测异常检测监督学习 二、异常检测算法2. 箱线图分析3. 基于距离/密度4. 基于划分思想 建模资料 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 一、简介 – 关于异常…...

【EI会议征稿通知】2024年通信技术与软件工程国际学术会议 (CTSE 2024)
2024年通信技术与软件工程国际学术会议 (CTSE 2024) 2024 International Conference on Communication Technology and Software Engineering (CTSE 2024) 2024年通信技术与软件工程国际学术会议 (CTSE 2024)将于2024年03月15-17日在中国长沙举行。会议专注于通信技术与软件工…...

Js面试之作用域与闭包
Js面试之作用域与闭包 作用域词法作用域动态作用域 闭包闭包使用场景封装私有变量模块化开发保持变量状态异步操作 注意事项 最近在整理一些前端面试中经常被问到的问题,分为vue相关、react相关、js相关、react相关等等专题,可持续关注后续内容ÿ…...

Go 爬虫之 colly 从入门到不放弃指南
文章目录 概要介绍如何学习官方文档如何安装快速开始如何配置调试分布式代理层面执行层面存储层面存储多收集器配置优化持久化存储启用异步加快任务执行禁止或限制 KeepAlive 连接扩展总结如果想用 GO 实现爬虫能力,该如何做呢?抽时间研究了 Go 的一款爬虫框架 colly。 概要…...
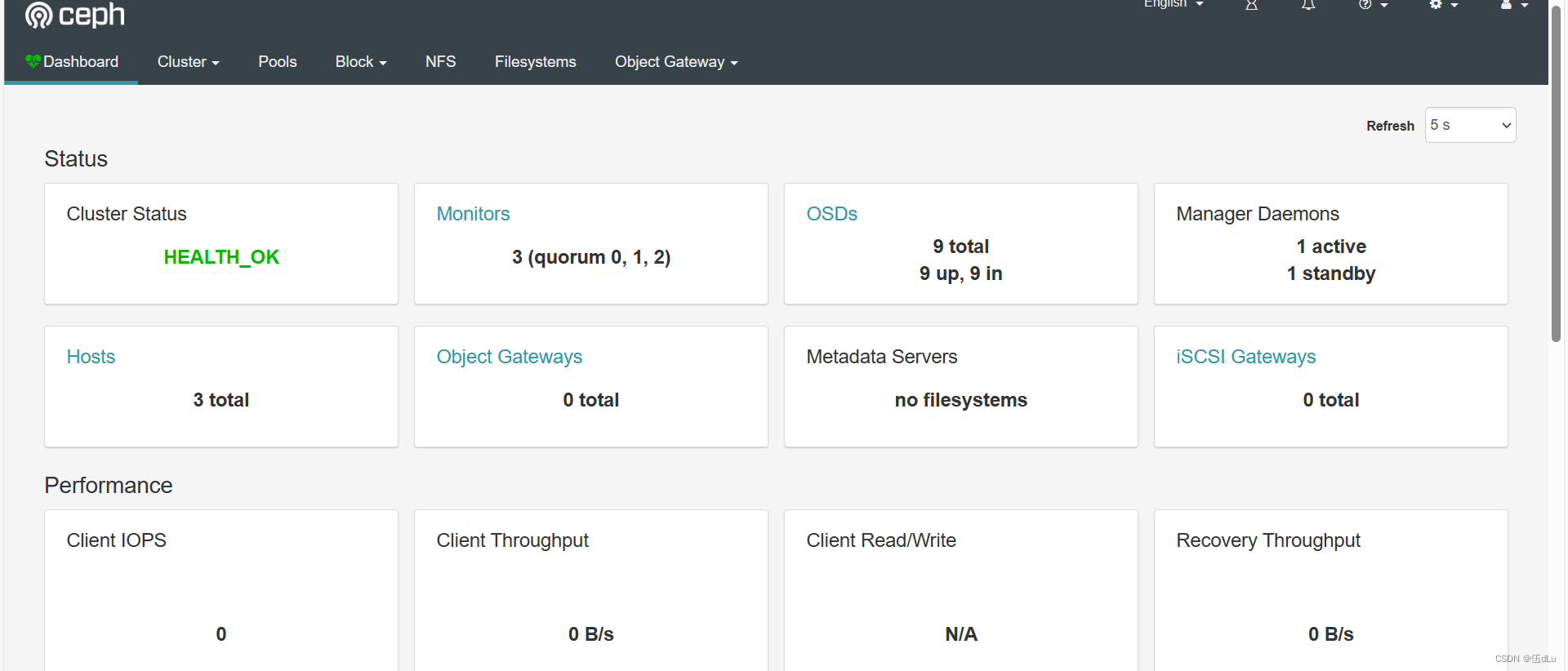
Ceph分布式存储(1)
目录 一.ceph分布式存储 Ceph架构(自上往下) OSD的存储引擎: Ceph的存储过程: 二. 基于 ceph-deploy 部署 Ceph 集群 20-40节点上添加3块硬盘,一个网卡: 10节点为admin,20-40为node&…...

制造业工厂为什么要实施MES系统呢?
MES是生产管理系统,生产管理是通过对生产系统的战略计划、组织、指挥、实施、协调、控制等活动,实现系统的物质变换、产品生产、价值提升的过程。在企业的价值链中,生产经营是企业核心能力的重要组成部分。 实施MES系统的原因 MES系统是中国比…...

Python 一行命令部署http、ftp服务
Python 一行命令部署http服务 文章目录 Python 一行命令部署http服务具体操作命令如下浏览器返回下载Python 一行命令部署FTP服务 具体操作命令如下 这个比nginx相对来说更加简单,可以用于部署特殊场景时如银行等部署时,各种权限控制,内网之间…...

DBA技术栈(三):MySQL 性能影响因素
文章目录 前言一、影响MySQL性能的因素1.1 商业上的需求1.2 应用架构规划1.3 查询语句使用方式1.4 Schema的设计1.5 硬件环境 总结 前言 大部分人都一致认为一个数据库应用系统(这里的数据库应用系统概指所有使用数据库的系统)的性能瓶颈最容易出现在数…...
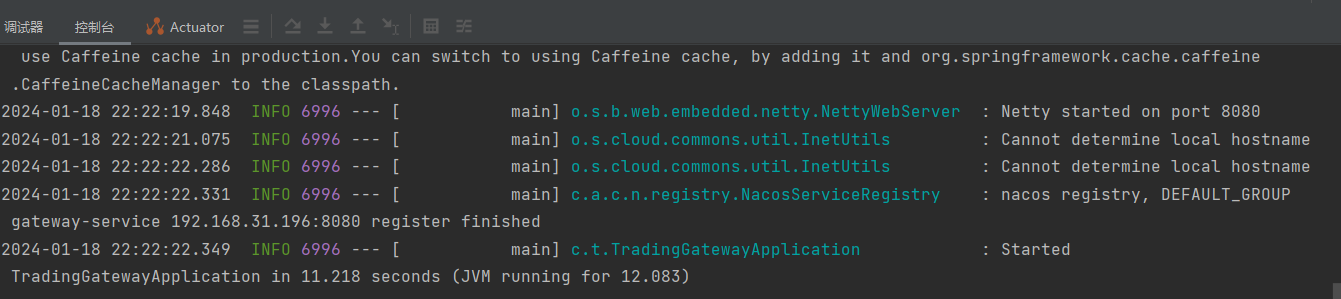
SpringCloud GateWay 在全局过滤器中注入OpenFeign网关后无法启动
目录 一、问题 二、原因 1、修改配置 2、添加Lazy注解在client上面 3、启动成功 一、问题 当在gateway的全局过滤器GlobalFilter中注入OpenFeign接口的时候会一直卡在路由中,但是不会进一步,导致启动未成功也未报错失败 2024-01-18 22:06:59.299 I…...

web前端项目-贪吃蛇小游戏【附源码】
web前端项目-贪吃蛇小游戏 【贪吃蛇】是一款经典的小游戏,采用HTML、CSS和JavaScript技术进行开发,玩家通过控制一条蛇在地图上移动,蛇的目的是吃掉地图上的食物,并且让自己变得更长。游戏的核心玩法是控制蛇的移动方向和长度&am…...
ICCV2023 | PTUnifier+:通过Soft Prompts(软提示)统一医学视觉语言预训练
论文标题:Towards Unifying Medical Vision-and-Language Pre-training via Soft Prompts 代码:https://github.com/zhjohnchan/ptunifier Fusion-encoder type和Dual-encoder type。前者在多模态任务中具有优势,因为模态之间有充分的相互…...

代码随想录 Leetcode459. 重复的子字符串(KMP算法)
题目: 代码(首刷看解析 KMP算法 2024年1月18日): class Solution { public:void getNext(string& s,vector<int>& next) {int j 0;next[0] j;for (int i 1; i < s.size(); i) {while (j > 0 && s…...

Rust之构建命令行程序(三):重构改进模块化和错误处理
开发环境 Windows 10Rust 1.74.1 VS Code 1.85.1 项目工程 这次创建了新的工程minigrep. 重构改进模块化和错误处理 为了改进我们的程序,我们将修复与程序结构及其处理潜在错误的方式有关的四个问题。首先,我们的main函数现在执行两项任务:解析参数和…...

3分钟解决Cursor试用限制:设备标识重置完整指南
3分钟解决Cursor试用限制:设备标识重置完整指南 【免费下载链接】go-cursor-help 解决Cursor在免费订阅期间出现以下提示的问题: Your request has been blocked as our system has detected suspicious activity / Youve reached your trial request limit. / Too …...

Komanda代码嵌入功能详解:Gist、JSFiddle和Twitter无缝集成
Komanda代码嵌入功能详解:Gist、JSFiddle和Twitter无缝集成 【免费下载链接】komanda The IRC Client For Developers 项目地址: https://gitcode.com/gh_mirrors/ko/komanda Komanda作为一款面向开发者的IRC客户端,提供了强大的代码嵌入功能&…...
)
ArcGIS Pro 3.x 批量处理遥感栅格:用Python脚本实现自动化转点、计算与导出(附完整代码)
ArcGIS Pro 3.x 遥感栅格自动化处理实战:从数据清洗到生产级流水线构建 遥感数据分析师常常需要处理TB级的时序栅格数据,比如月度NDVI指数、地表温度或降水分布。传统手动操作不仅效率低下,还容易因人为失误导致数据不一致。本文将分享如何基…...

LabVIEW 32位版如何调用Halcon 17.12的.NET库?手把手教你打通图像处理流程
LabVIEW 32位版与Halcon 17.12 .NET库深度兼容指南:从原理到实战 在工业视觉和自动化测试领域,LabVIEW与Halcon的组合堪称黄金搭档。但当我们试图在32位LabVIEW环境中调用Halcon 17.12的.NET库时,常常会遇到各种"拦路虎"——从神秘…...

四旋翼无人机深度强化学习控制框架与实战优化
1. 四旋翼无人机端到端深度强化学习框架解析四旋翼无人机的自主飞行控制一直是机器人学领域的核心挑战。传统PID控制虽然稳定可靠,但在复杂动态环境中表现受限。深度强化学习(DRL)通过模拟环境交互实现智能决策,为无人机控制带来了…...

基于8ms平台的嵌入式GUI开发实践:智能家居86盒UI设计与实现
1. 项目概述:当智能家居遇上8ms,一个86盒的UI革命 最近在折腾一个智能家居的改造项目,核心是想把家里那些老旧的开关面板,换成能联网、能自定义、还能显示点信息的“智能大脑”。市面上现成的智能开关要么功能固化,要么…...
)
保姆级教程:在VMware上安装BCLinux for Euler 21.10最小化系统(附镜像校验与网络配置)
虚拟化环境实战:BCLinux for Euler 21.10最小化系统部署全指南 在云计算和容器化技术盛行的今天,本地虚拟化环境仍然是开发者进行系统测试、软件验证的重要工具。BCLinux for Euler作为一款针对企业级场景优化的Linux发行版,其21.10版本在性能…...
)
新手村通关攻略:大唐杯‘通信技术导论’仿真模块全流程实操解析(含设备配置清单)
大唐杯通信技术仿真实战指南:从零搭建智能通信系统 第一次参加大唐杯的新手们,面对仿真模块里密密麻麻的设备参数和操作界面,是不是有种"我是谁?我在哪?我要点哪里?"的迷茫感?别担心&…...

紫光展锐虎贲T618核心板硬件设计实战解析:从架构到量产
1. 从一颗芯片到一块核心板:T618的硬件设计哲学在智能硬件开发领域,选型一颗合适的处理器平台,往往是项目成败的起点。紫光展锐的虎贲T618,作为一款定位中高端的移动平台SoC,近年来在平板、智能POS、工业手持终端乃至一…...

深入解析Keil MDK编译流程:从C代码到单片机运行的完整过程
1. 项目概述:从源码到芯片运行的旅程作为一名在嵌入式领域摸爬滚打了十多年的老工程师,我经常被问到这样一个问题:“我写的C代码,点一下MDK的‘Build’按钮,怎么就变成能在单片机里跑的程序了?” 这背后&am…...