三、Sharding-JDBC系列03:自定义分片算法
目录
一、概述
1.1、分片算法
精确分片算法
范围分片算法
复合分片算法
Hint分片算法
1.2、分片策略
标准分片策略
复合分片策略
行表达式分片策略
Hint分片策略
不分片策略
二、自定义分片算法 - 复合分片算法
(1)、创建数据库和表
(2)、自定义分库算法
(3)、自定义分片算法
(4)、配置分库分表规则
(5)、测试插入操作
三、自定义分片算法 - 精确分片算法
四、自定义分片算法 - 范围分片算法
五、自定义分片算法 - Hint算法
一、概述
1.1、分片算法
通过分片算法将数据分片,支持通过=、BETWEEN和IN分片。分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供4种分片算法。由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。

精确分片算法
对应PreciseShardingAlgorithm,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
范围分片算法
对应RangeShardingAlgorithm,用于处理使用单一键作为分片键的BETWEEN AND进行分片的场景。需要配合StandardShardingStrategy使用。
复合分片算法
对应ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
Hint分片算法
对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
1.2、分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供5种分片策略。
标准分片策略
对应StandardShardingStrategy。提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm(精准分片)和RangeShardingAlgorithm(范围分片)两个分片算法。PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。RangeShardingAlgorithm是可选的,用于处理BETWEEN AND分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
复合分片策略
对应ComplexShardingStrategy。复合分片策略。提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
行表达式分片策略
对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: t_user_$->{u_id % 8} 表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7。
Hint分片策略
对应HintShardingStrategy。通过Hint而非SQL解析的方式分片的策略。
不分片策略
对应NoneShardingStrategy。不分片的策略。
在前面 Sharding-JDBC的案例中,我们都是使用的系统内置的分表分库算法,配置起来非常简单, 直接使用行表达式配置即可,如t_order$->{order_id % 2}等。但是它的功能比较简单,只能进行简单的取模,哈希运算,对于需要根据业务逻辑进行复杂的分片规则,内置的一些算法就无法实现了,这个时候就需要我们自己自定义满足业务规则的分片算法,下面演示一下如何自定义分片算法。
二、自定义分片算法 - 复合分片算法
使用场景:SQL 语句中有>,>=, <=,<,=,IN 和 BETWEEN AND 等操作符,不同的是复合分片策略支持对多个分片键操作。
下面我们实现同时以 order_id、user_id两个字段作为分片键,自定义复合分片策略。
(1)、创建数据库和表
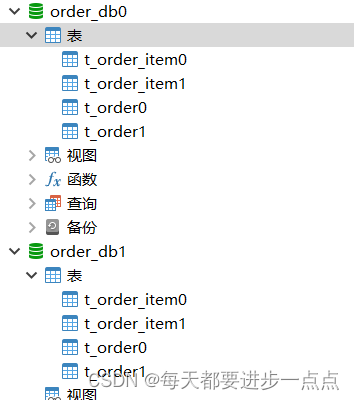
CREATE TABLE `t_order0` (`order_id` bigint(20) NOT NULL COMMENT '订单ID',`order_name` varchar(255) DEFAULT NULL COMMENT '订单名称',`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `t_order1` (`order_id` bigint(20) NOT NULL COMMENT '订单ID',`order_name` varchar(255) DEFAULT NULL COMMENT '订单名称',`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;(2)、自定义分库算法
重点是演示如何自定义分库算法,所以我们只是实现了一个很简单的多个分片键共同决定分库选择的策略:
(order_id.hashCode() + user_id.hashCode()) % databases.size()。
/*** 自定义一个简单的复合分库算法: 使用到两个分片键(order_id、user_id)共同决定数据应该落到哪个真实数据库。* (order_id.hashCode() + user_id.hashCode()) % databases.size()** 泛型是Long的原因是order_id、user_id这两个分表列类型就是Long,就是说这个算法你要应用到数据表的哪一个字段,那么这个泛型的类型就是这个字段的类型。*/
public class MyDataBaseShardingAlgorithm implements ComplexKeysShardingAlgorithm<Long> {private static final Logger logger = LoggerFactory.getLogger(MyDataBaseShardingAlgorithm.class);@Overridepublic Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<Long> shardingValue) {logger.info("【MyDataBaseShardingAlgorithm】execute MyDataBaseShardingAlgorithm.doSharding()...");logger.info("【MyDataBaseShardingAlgorithm】availableTargetNames: {}, shardingValue: {}", availableTargetNames, JSON.toJSONString(shardingValue));// dataSourceIndex = (order_id.hashCode() + user_id.hashCode()) % databases.size()int dataSourceIndex = getDataSourceIndex(availableTargetNames, shardingValue);logger.info("【MyDataBaseShardingAlgorithm】dataSourceIndex:{}", dataSourceIndex);List<String> shardingResults = new ArrayList<>();// availableTargetNames: [ds0, ds1]for (String dataSourceName : availableTargetNames) {// 截取数据源名称ds后面的部分String dataSourceNameSuffix = dataSourceName.substring(2);// 匹配到第一个合适的数据源,直接返回if (dataSourceNameSuffix.equals(String.valueOf(dataSourceIndex))) {shardingResults.add(dataSourceName);break;}}return shardingResults;}private static int getDataSourceIndex(Collection<String> availableTargetNames, ComplexKeysShardingValue<Long> shardingValue) {// availableTargetNames: [ds0, ds1], shardingValue: {"columnNameAndRangeValuesMap":{},"columnNameAndShardingValuesMap":{"order_id":[13847],"user_id":[28]},"logicTableName":"t_order"}// 分片键的h值int columnShardingValueHashCode = shardingValue.getColumnNameAndShardingValuesMap().values().stream().map(longs -> (List<Long>) longs).mapToInt(columnShardingValues -> columnShardingValues.get(0).hashCode()).sum();// (order_id.hashCode() + user_id.hashCode()) % databases.size()logger.info("【MyDataBaseShardingAlgorithm】columnShardingValueHashCode:{}", columnShardingValueHashCode);return columnShardingValueHashCode % availableTargetNames.size();}}(3)、自定义分片算法
重点是演示如何自定义分库算法,所以我们只是实现了一个很简单的多个分片键共同决定分库选择的策略:
(order_id * user_id) % databases.size()。
/*** 自定义一个简单的复合分表算法: 使用到两个分片键(order_id、user_id)共同决定数据应该落到哪个真实数据库。* (order_id * user_id) % databases.size()*/
public class MyTableShardingAlgorithm implements ComplexKeysShardingAlgorithm<Long> {private static final Logger logger = LoggerFactory.getLogger(MyTableShardingAlgorithm.class);@Overridepublic Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<Long> shardingValue) {logger.info("【MyTableShardingAlgorithm】execute MyTableShardingAlgorithm.doSharding()...");logger.info("【MyTableShardingAlgorithm】availableTargetNames: {}, shardingValue: {}", availableTargetNames, JSON.toJSONString(shardingValue));// dataSourceIndex = (order_id * user_id) % databases.size()int tableIndex = getTableIndex(availableTargetNames, shardingValue);logger.info("【MyTableShardingAlgorithm】tableIndex:{}", tableIndex);List<String> shardingResults = new ArrayList<>();// availableTargetNames: [t_order0, t_order1]for (String dataSourceName : availableTargetNames) {// 截取数据源名称t_order后面的部分String dataSourceNameSuffix = dataSourceName.substring(7);// 匹配到第一个合适的数据表,直接返回if (dataSourceNameSuffix.equals(String.valueOf(tableIndex))) {shardingResults.add(dataSourceName);break;}}return shardingResults;}private static int getTableIndex(Collection<String> availableTargetNames, ComplexKeysShardingValue<Long> shardingValue) {// availableTargetNames: [t_order0, t_order1], shardingValue: {"columnNameAndRangeValuesMap":{},"columnNameAndShardingValuesMap":{"order_id":[58201],"user_id":[95]},"logicTableName":"t_order"}int columnShardingValue = shardingValue.getColumnNameAndShardingValuesMap().values().stream().map(longs -> (List<Long>) longs).mapToInt(columnShardingValues -> Math.toIntExact(columnShardingValues.get(0))).reduce(1, (a, b) -> a * b);// (order_id * user_id) % databases.size()logger.info("【MyTableShardingAlgorithm】columnShardingValue:{}", columnShardingValue);return columnShardingValue % availableTargetNames.size();}}(4)、配置分库分表规则
application.properties 配置文件中只需修改分库策略名 database-strategy 为复合模式complex,分片算法 complex.algorithm-class-name为自定义的分库算法类路径。
spring:shardingsphere:props:sql:show: true # 打印具体的插入SQLdatasource:names: ds0,ds1ds0: # 数据源的名称type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://127.0.0.1:3306/order_db0?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMTusername: rootpassword: "0905"ds1: # 数据源的名称type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://127.0.0.1:3306/order_db1?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMTusername: rootpassword: "0905"sharding:tables:t_order: # 逻辑表的名称actual-data-nodes: ds$->{0..1}.t_order$->{0..1} # 真实的数据节点: ds0数据源下的t_order0、t_order1两个表table-strategy:complex:sharding-columns: order_id,user_id # 表分片字段algorithm-class-name: org.example.shardingjdbcdemo.algorithm.MyTableShardingAlgorithm # 自定义数据表分片算法database-strategy:complex:sharding-columns: order_id,user_id # 分库字段algorithm-class-name: org.example.shardingjdbcdemo.algorithm.MyDataBaseShardingAlgorithm # 自定义分库算法key-generator:column: order_id # 主键字段名称type: SNOWFLAKE # 主键生成策略:雪花算法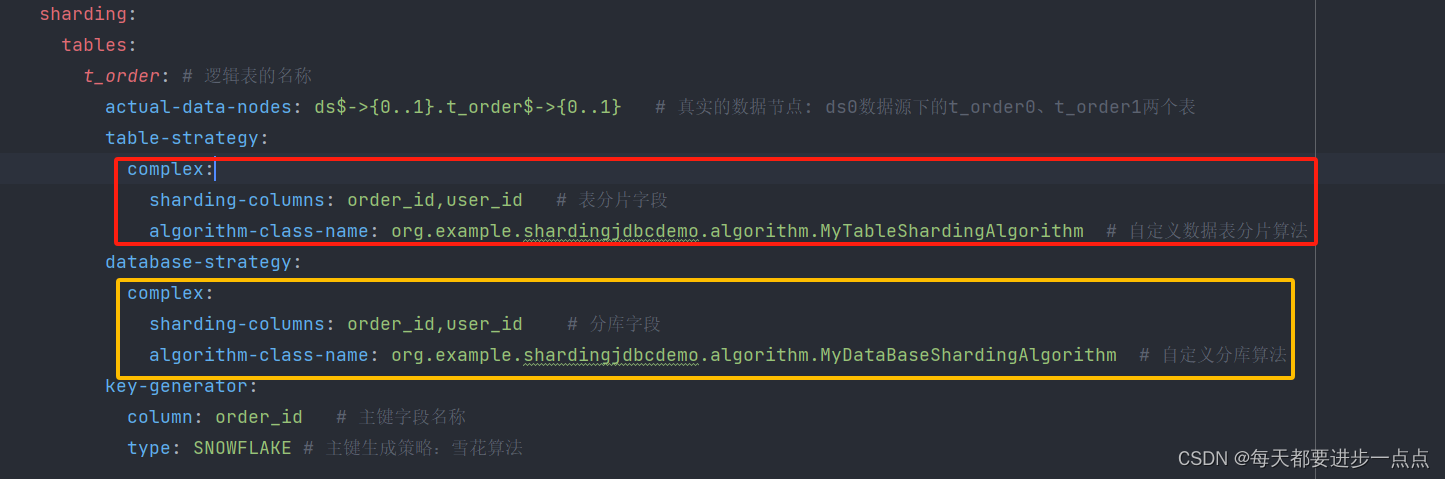
(5)、测试插入操作
从控制台的路由信息可以看到,分库、分表的选择策略都如上面我们定义的根据order_id、user_id共同决定的,在工作中如有需要根据多个分片键共同决定分片策略的场景,就可以通过实现ComplexKeysShardingAlgorithm接口实现。
2023-12-21 17:46:44.356 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】execute MyDataBaseShardingAlgorithm.doSharding()...
2023-12-21 17:46:44.890 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】availableTargetNames: [ds0, ds1], shardingValue: {"columnNameAndRangeValuesMap":{},"columnNameAndShardingValuesMap":{"order_id":[29687],"user_id":[75]},"logicTableName":"t_order"}
2023-12-21 17:46:44.894 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】columnShardingValueHashCode:29762
2023-12-21 17:46:44.894 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】dataSourceIndex:0
2023-12-21 17:46:44.895 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】execute MyTableShardingAlgorithm.doSharding()...
2023-12-21 17:46:44.896 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】availableTargetNames: [t_order0, t_order1], shardingValue: {"columnNameAndRangeValuesMap":{},"columnNameAndShardingValuesMap":{"order_id":[29687],"user_id":[75]},"logicTableName":"t_order"}
2023-12-21 17:46:44.898 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】columnShardingValue:2226525
2023-12-21 17:46:44.898 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】tableIndex:1
2023-12-21 17:46:44.955 INFO 3652 --- [ main] ShardingSphere-SQL : Logic SQL: insert into t_order(`order_id`, `order_name`, `user_id`) values (?, ?, ?)
2023-12-21 17:46:44.956 INFO 3652 --- [ main] ShardingSphere-SQL : SQLStatement: InsertStatementContext(super=CommonSQLStatementContext(sqlStatement=org.apache.shardingsphere.sql.parser.sql.statement.dml.InsertStatement@261de205, tablesContext=org.apache.shardingsphere.sql.parser.binder.segment.table.TablesContext@7f3fc42f), tablesContext=org.apache.shardingsphere.sql.parser.binder.segment.table.TablesContext@7f3fc42f, columnNames=[order_id, order_name, user_id], insertValueContexts=[InsertValueContext(parametersCount=3, valueExpressions=[ParameterMarkerExpressionSegment(startIndex=66, stopIndex=66, parameterMarkerIndex=0), ParameterMarkerExpressionSegment(startIndex=69, stopIndex=69, parameterMarkerIndex=1), ParameterMarkerExpressionSegment(startIndex=72, stopIndex=72, parameterMarkerIndex=2)], parameters=[29687, 订单[0], 75])], generatedKeyContext=Optional[GeneratedKeyContext(columnName=order_id, generated=false, generatedValues=[29687])])
2023-12-21 17:46:44.956 INFO 3652 --- [ main] ShardingSphere-SQL : Actual SQL: ds0 ::: insert into t_order1(`order_id`, `order_name`, `user_id`) values (?, ?, ?) ::: [29687, 订单[0], 75]
2023-12-21 17:46:45.051 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】execute MyDataBaseShardingAlgorithm.doSharding()...
2023-12-21 17:46:45.052 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】availableTargetNames: [ds0, ds1], shardingValue: {"columnNameAndRangeValuesMap":{},"columnNameAndShardingValuesMap":{"order_id":[83190],"user_id":[8]},"logicTableName":"t_order"}
2023-12-21 17:46:45.052 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】columnShardingValueHashCode:83198
2023-12-21 17:46:45.052 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】dataSourceIndex:0
2023-12-21 17:46:45.052 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】execute MyTableShardingAlgorithm.doSharding()...
2023-12-21 17:46:45.053 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】availableTargetNames: [t_order0, t_order1], shardingValue: {"columnNameAndRangeValuesMap":{},"columnNameAndShardingValuesMap":{"order_id":[83190],"user_id":[8]},"logicTableName":"t_order"}
2023-12-21 17:46:45.053 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】columnShardingValue:665520
2023-12-21 17:46:45.053 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】tableIndex:0
2023-12-21 17:46:45.054 INFO 3652 --- [ main] ShardingSphere-SQL : Logic SQL: insert into t_order(`order_id`, `order_name`, `user_id`) values (?, ?, ?)
2023-12-21 17:46:45.054 INFO 3652 --- [ main] ShardingSphere-SQL : SQLStatement: InsertStatementContext(super=CommonSQLStatementContext(sqlStatement=org.apache.shardingsphere.sql.parser.sql.statement.dml.InsertStatement@261de205, tablesContext=org.apache.shardingsphere.sql.parser.binder.segment.table.TablesContext@324b6a56), tablesContext=org.apache.shardingsphere.sql.parser.binder.segment.table.TablesContext@324b6a56, columnNames=[order_id, order_name, user_id], insertValueContexts=[InsertValueContext(parametersCount=3, valueExpressions=[ParameterMarkerExpressionSegment(startIndex=66, stopIndex=66, parameterMarkerIndex=0), ParameterMarkerExpressionSegment(startIndex=69, stopIndex=69, parameterMarkerIndex=1), ParameterMarkerExpressionSegment(startIndex=72, stopIndex=72, parameterMarkerIndex=2)], parameters=[83190, 订单[1], 8])], generatedKeyContext=Optional[GeneratedKeyContext(columnName=order_id, generated=false, generatedValues=[83190])])
2023-12-21 17:46:45.055 INFO 3652 --- [ main] ShardingSphere-SQL : Actual SQL: ds0 ::: insert into t_order0(`order_id`, `order_name`, `user_id`) values (?, ?, ?) ::: [83190, 订单[1], 8]
2023-12-21 17:46:45.067 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】execute MyDataBaseShardingAlgorithm.doSharding()...
2023-12-21 17:46:45.067 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】availableTargetNames: [ds0, ds1], shardingValue: {"columnNameAndRangeValuesMap":{},"columnNameAndShardingValuesMap":{"order_id":[13400],"user_id":[3]},"logicTableName":"t_order"}
2023-12-21 17:46:45.067 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】columnShardingValueHashCode:13403
2023-12-21 17:46:45.068 INFO 3652 --- [ main] o.e.s.a.MyDataBaseShardingAlgorithm : 【MyDataBaseShardingAlgorithm】dataSourceIndex:1
2023-12-21 17:46:45.068 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】execute MyTableShardingAlgorithm.doSharding()...
2023-12-21 17:46:45.068 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】availableTargetNames: [t_order0, t_order1], shardingValue: {"columnNameAndRangeValuesMap":{},"columnNameAndShardingValuesMap":{"order_id":[13400],"user_id":[3]},"logicTableName":"t_order"}
2023-12-21 17:46:45.068 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】columnShardingValue:40200
2023-12-21 17:46:45.068 INFO 3652 --- [ main] o.e.s.a.MyTableShardingAlgorithm : 【MyTableShardingAlgorithm】tableIndex:0
2023-12-21 17:46:45.069 INFO 3652 --- [ main] ShardingSphere-SQL : Logic SQL: insert into t_order(`order_id`, `order_name`, `user_id`) values (?, ?, ?)
2023-12-21 17:46:45.070 INFO 3652 --- [ main] ShardingSphere-SQL : SQLStatement: InsertStatementContext(super=CommonSQLStatementContext(sqlStatement=org.apache.shardingsphere.sql.parser.sql.statement.dml.InsertStatement@261de205, tablesContext=org.apache.shardingsphere.sql.parser.binder.segment.table.TablesContext@36359723), tablesContext=org.apache.shardingsphere.sql.parser.binder.segment.table.TablesContext@36359723, columnNames=[order_id, order_name, user_id], insertValueContexts=[InsertValueContext(parametersCount=3, valueExpressions=[ParameterMarkerExpressionSegment(startIndex=66, stopIndex=66, parameterMarkerIndex=0), ParameterMarkerExpressionSegment(startIndex=69, stopIndex=69, parameterMarkerIndex=1), ParameterMarkerExpressionSegment(startIndex=72, stopIndex=72, parameterMarkerIndex=2)], parameters=[13400, 订单[2], 3])], generatedKeyContext=Optional[GeneratedKeyContext(columnName=order_id, generated=false, generatedValues=[13400])])
2023-12-21 17:46:45.070 INFO 3652 --- [ main] ShardingSphere-SQL : Actual SQL: ds1 ::: insert into t_order0(`order_id`, `order_name`, `user_id`) values (?, ?, ?) ::: [13400, 订单[2], 3]三、自定义分片算法 - 精确分片算法
实现自定义精准分库、分表算法的方式大致相同,都要实现 PreciseShardingAlgorithm 接口,并重写 doSharding() 方法,只是配置稍有不同,而且它只是个空方法,得我们自行处理分库、分表逻辑。
/*** 自定义精确分片算法*/
public class MyPreciseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {private static final Logger logger = LoggerFactory.getLogger(MyPreciseShardingAlgorithm.class);/*** 精确分片的返回只有一个** @param availableTargetNames 可用的数据源或表的名称* @param shardingValue PreciseShardingValue: 其中logicTableName为逻辑表,columnName分片键(字段),value为分片键的值* @return*/@Overridepublic String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {logger.info("execute MyPreciseShardingAlgorithm.doSharding....");logger.info("【MyPreciseShardingAlgorithm】availableTargetNames:{}, shardingValue:{}", availableTargetNames, shardingValue);for (String availableTargetName : availableTargetNames) {// 分片键的值 % 表数量String shardingIndex = String.valueOf(shardingValue.getValue() % availableTargetNames.size());// 找到一个合适的分片后直接返回if (availableTargetName.endsWith(shardingIndex)) {return availableTargetName;}}throw new IllegalArgumentException();}
}分库分表规则配置如下:
# 分库策略
# 分库分片键
spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.sharding-column=order_id
# 自定义分库算法
spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.precise-algorithm-class-name=自定义分库算法的全限定类名# 分表策略
# 分表分片键
spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.sharding-column=order_id
# 自定义分表算法
spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.precise-algorithm-class-name=自定义分表算法的全限定类名四、自定义分片算法 - 范围分片算法
使用场景:当我们 SQL中的分片键字段用到 BETWEEN AND操作符会使用到此算法,会根据 SQL中给出的分片键值范围值处理分库、分表逻辑。
/*** 自定义范围分片算法*/
public class MyRangeShardingAlgorithm implements RangeShardingAlgorithm<Long> {@Overridepublic Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Long> shardingValue) {// 满足分片规则的DataSourceName或者TableNamesSet<String> result = new LinkedHashSet<>();// between and的起始值long lower = shardingValue.getValueRange().lowerEndpoint();// between and的截止值long upper = shardingValue.getValueRange().upperEndpoint();long i = lower;while (i <= upper) {for (String targetName : availableTargetNames) {if (targetName.endsWith(String.valueOf(i % availableTargetNames.size()))) {result.add(targetName);}}i++;}return result;}
}分库分表规则配置如下:
# 分库策略
# 分库分片键
spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.sharding-column=order_id
# 自定义分库算法
spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.range-algorithm-class-name=自定义分库算法的全限定类名# 分表策略
# 分表分片键
spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.sharding-column=order_id
# 自定义分表算法
spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.range-algorithm-class-name=自定义分表算法的全限定类名五、自定义分片算法 - Hint算法
Hint分片策略(HintShardingStrategy)相比于上面几种分片策略稍有不同,这种分片策略无需配置分片键,分片键值也不再从 SQL中解析,而是由外部指定分片信息,让 SQL在指定的分库、分表中执行。ShardingSphere 通过 Hint API实现指定操作,实际上就是把分片规则tablerule 、databaserule由集中配置变成了个性化配置。
举个例子,如果我们希望订单表t_order用 user_id 做分片键进行分库分表,但是 t_order 表中却没有 user_id 这个字段,这时可以通过 Hint API 在外部手动指定分片键或分片库。
/*** 自定义Hint分片算法*/
public class MyHintShardingAlgorithm implements HintShardingAlgorithm<String> {@Overridepublic Collection<String> doSharding(Collection<String> availableTargetNames, HintShardingValue<String> shardingValue) {Collection<String> result = new ArrayList<>();for (String targetName : availableTargetNames) {for (String value : shardingValue.getValues()) {if (targetName.endsWith(String.valueOf(Long.parseLong(value) % availableTargetNames.size()))) {result.add(targetName);}}}return result;}
}这种方式自定义完分片算法时,需要在业务代码中手动设置分库或者分片的值,对业务代码侵入太大,在实际工作中用的不多,这里只是做个了解,不再阐述,感兴趣的同学可自行google下。
相关文章:
三、Sharding-JDBC系列03:自定义分片算法
目录 一、概述 1.1、分片算法 精确分片算法 范围分片算法 复合分片算法 Hint分片算法 1.2、分片策略 标准分片策略 复合分片策略 行表达式分片策略 Hint分片策略 不分片策略 二、自定义分片算法 - 复合分片算法 (1)、创建数据库和表 (2)、自定义分库算法 (3)、…...
像操作本地文件一样操作linux文件 centos7环境下samba共享服务搭建详细教程
1.安装dnf yum -y install dnf 2.安装samba dnf install samba -y 3.配置 3.1创建并设置用户信息 #创建用户 useradd -M -s /sbin/nologin samba echo 123|passwd --stdin samba mkdir /home/samba chown -R samba:samba /home/samba smbpasswd -a samba smaba设置密码示…...

web块级如何居中,关于css/html居中问题
1. text-align:center; 可以实现其内部元素水平居中,通常用于字体水平居中,初学者也可以用于简单块级居中。这种方法对行内元素 (inline),行内块 (inline-block),行内表 (inline-table),inline…...

docker 部署 springboot 2.6.13 jar包流程笔记
1 . 将dockerfile复制到与jar包同一目录 Dockerfile # 基础镜像 FROM openjdk:8 # 环境变量 ENV APP_HOME/apps # 创建容器默认进入的目录 WORKDIR $APP_HOME # 复制jar包到容器中 COPY ./elastic-log-service.jar ./elastic-log-service.jar # 暴露端口 EXPOSE 8003 # 启动命…...
rust跟我学二:模块编写与使用
图为RUST吉祥物 大家好,我是get_local_info作者带剑书生,这里用一篇文章讲解get_local_info中模块的使用。 首先,先要了解get_local_info是什么? get_local_info是一个获取linux系统信息的rust三方库,并提供一些常用功能,目前版本0.2.4。详细介绍地址:[我的Rust库更新]g…...

数据结构——Java实现栈和队列
一、栈 Stack 1.特点 (1)栈是一种线性数据结构 (2)规定只能从栈顶添加元素,从栈顶取出元素 (3)是一种先进后出的数据结构(Last First Out)LIFO 2.具体实现 Java中可…...

【状态压缩】【动态规划】【C++算法】691贴纸拼词
作者推荐 【动态规划】【数学】【C算法】18赛车 本文涉及知识点 状态压缩 动态规划 LeetCode:691 贴纸拼词 我们有 n 种不同的贴纸。每个贴纸上都有一个小写的英文单词。 您想要拼写出给定的字符串 target ,方法是从收集的贴纸中切割单个字母并重新排列它们。如…...
)
JavaEE之多线程编程:3. 线程的状态(易懂!)
文章目录 一、关于线程的状态二、观察线程的所有状态1. NEW状态2. TERMINATED状态3. RUNNABLE状态4. TIMED_WAITING 一、关于线程的状态 进程最核心的状态,一个是就绪状态,一个是阻塞状态(对于线程同样使用)。 以线程为单位进行调…...

Android13预装APP到data分区
修改步骤与Android11是差不多的,只是有部分代码所在位置不一样。 Android 11内置APP到data/app Android 8(O)预置APP到data/app 默认内置应用到data会出错 1970-01-01 08:03:54.499 1177-1177/system_process I/PackageManager: /data/app/xx changed; collecting…...
Docker registry镜像仓库,私有仓库及harbor管理详解
目录 registry镜像仓库概述 Docker 镜像仓库(Docker Registry): registry 容器: 私有仓库概述 搭建本地私有仓库示例 Harbor概述 harbor架构 详解构成 Harbor由容器构成 Harbor部署示例 环境准备 部署Docker-Compose服…...
用 Rust 过程宏魔法简化 SQL 函数实现
#[function("length(varchar) -> int4")] pub fn char_length(s: &str) -> i32 {s.chars().count() as i32 }这是 RisingWave 中一个 SQL 函数的实现。只需短短几行代码,通过在 Rust 函数上加一行过程宏,我们就把它包装成了一个 SQL…...

OpenSource - 基于 DFA 算法实现的高性能 java 敏感词过滤工具框架
文章目录 sensitive-word创作目的特性变更日志更多资料敏感词控台敏感词标签文件 快速开始准备Maven 引入核心方法判断是否包含敏感词返回第一个敏感词返回所有敏感词默认的替换策略指定替换的内容自定义替换策略 IWordResultHandler 结果处理类使用实例 更多特性样式处理忽略大…...

端杂七杂八系列篇四-Java8篇
后端杂七杂八系列篇四-Java8篇 ① Lombok插件① RequiredArgsConstructor② SneakyThrows③ UtilityClass④ Cleanup ② Lambda 4个常用的内置函数① Function<T, R> - 接受一个输入参数并返回一个结果② Consumer - 接受一个输入参数,并执行某种操作…...

操作系统一些面试
你这个请求队列是属于一写多读对吧,怎么解决冲突的? 可以采用双buffer或者说双缓冲区,一个缓冲区用来写,一个缓冲区用来读,采用交换指针的方法来进行缓存区的交换,这样交换效率是O(1)的,但是交…...
大语言模型
概念 大语言模型(Large Language Model,简称LLM)是一种基于人工智能技术的自然语言处理模型,是指在大量数据上训练的高级人工智能算法,以自上文推理词语概率为核心任务。它通过在海量文本数据上进行训练,学…...
php反序列化之pop链构造(基于重庆橙子科技靶场)
常见魔术方法的触发 __construct() //创建类对象时调用 __destruct() //对象被销毁时触发 __call() //在对象中调用不可访问的方法时触发 __callStatic() //在静态方式中调用不可访问的方法时触发 __get() //调用类中不存在变量时触发(找有连续箭头的…...
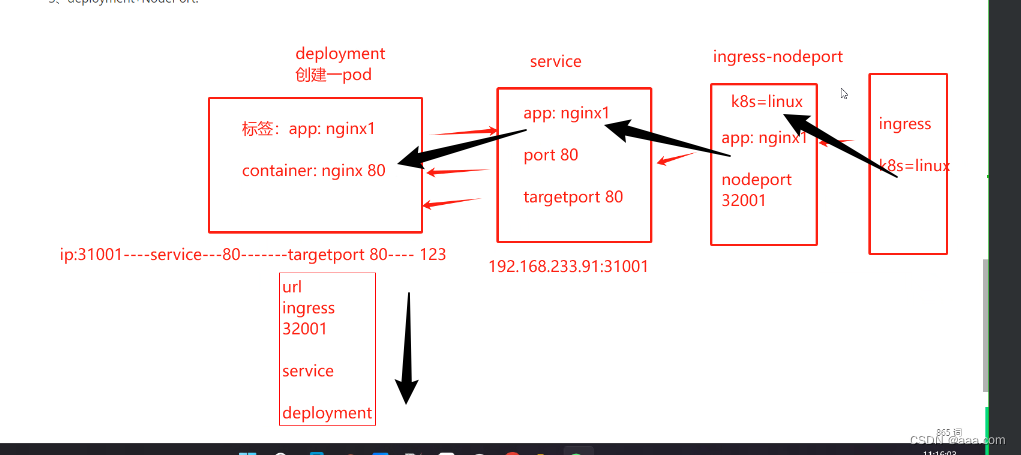
k8s---对外服务 ingress
目录 目录 目录 ingress与service ingress的组成 ingress-controller: ingress暴露服务的方式 2.方式二:DaemonSethostnetworknodeSelector DaemonSethostnetworknodeSelector如何实现 3.deploymentNodePort: 虚拟主机的方式实现http代…...
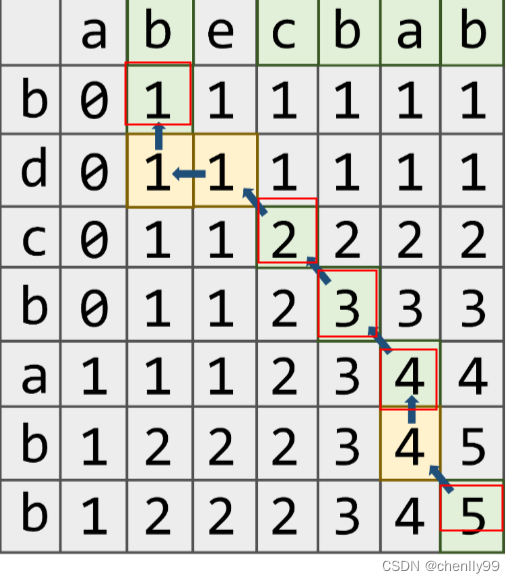
最优解-最长公共子序列
问题描述 最长公共子序列(Longest Common Subsequence,LCS)即求两个序列最长的公共子序列(可以不连续)。比如3 2 1 4 5和1 2 3 4 5两个序列,最长公共子序列为2 4 5 长度为3。解决这个问题必然要使用动态规划。既然要用到动态规划,就要知道状…...
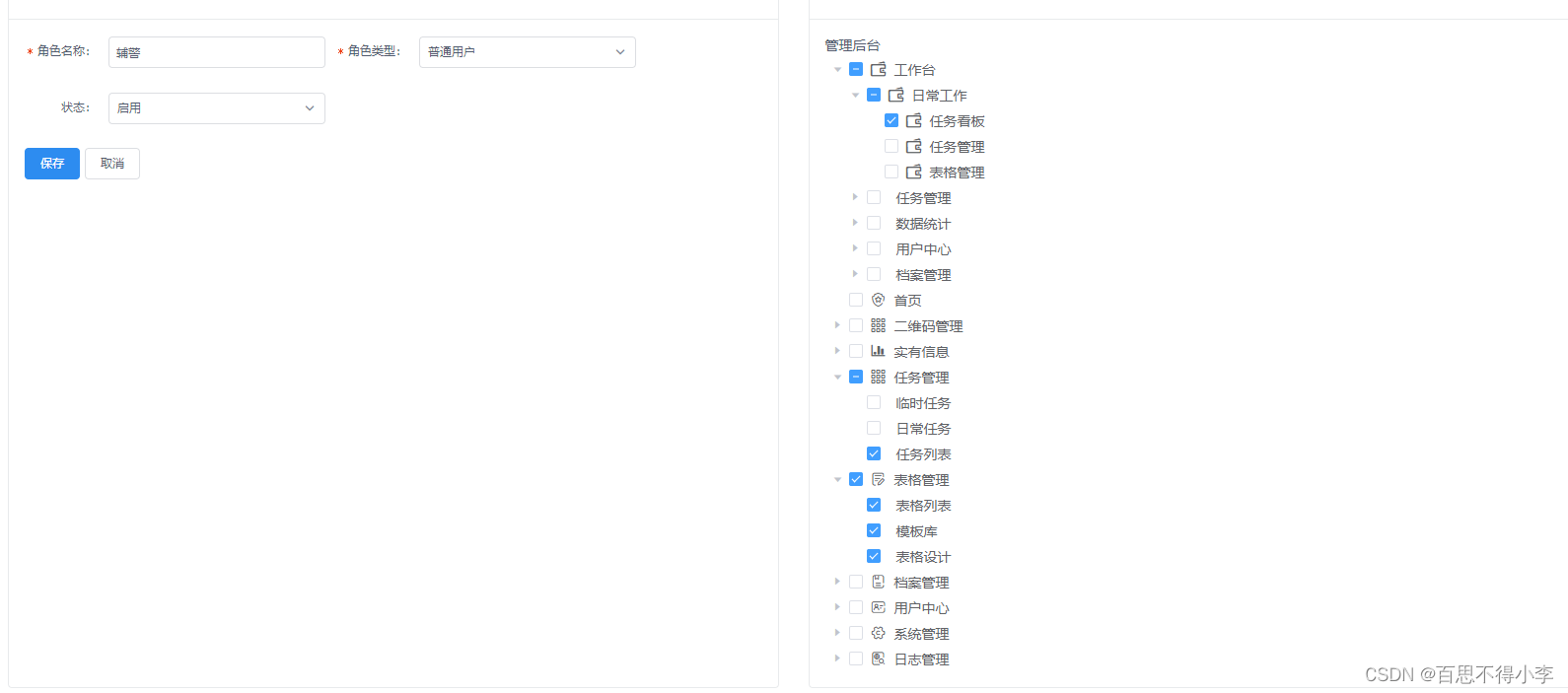
el-tree获取当前选中节点及其所有父节点的id(包含半选中父节点的id)
如下图,我们现在全勾中的有表格管理及其下的子级,而半勾中的有工作台和任务管理及其子级 现在点击保存按钮后,需要将勾中的节点id及该节点对应的父节点,祖先节点的id(包含半选中父节点的id)也都一并传给后端,那这个例子里就应该共传入9个id,我们可以直接将getCheckedK…...

新上线一个IT公司微信小程序
项目介绍 项目背景: 一家IT公司,业务包含以下六大块: 1、IT设备回收 2、IT设备租赁 3、IT设备销售 4、IT设备维修 5、IT外包 6、IT软件开发 通过小程序,提供在线下单,在线制单,在线销售,业务介绍,推广,会员 项目目的: 业务介绍: 包含企业业务介绍 客户需…...

避坑指南:用3dMax一键房屋插件时,为什么你的窗洞总创建失败?
3dMax一键房屋插件窗洞创建失败的深度排查手册 引言 在建筑可视化与室内设计领域,3dMax的一键房屋插件确实为设计师节省了大量重复劳动时间。然而,许多中级用户在尝试创建窗洞时,常常遭遇各种意料之外的失败——从简单的按钮灰色不可点击&…...
)
保姆级教程:用Unity+OpenCVSharp插件实现摄像头实时轮廓检测与交互(附完整C#代码)
Unity与OpenCVSharp实战:从摄像头捕捉到交互式轮廓检测全流程解析 在游戏开发与计算机视觉的交叉领域,实时图像处理正成为增强玩家沉浸感的新 frontier。想象一下:玩家只需在摄像头前挥动手势,游戏中的角色就能同步做出反应&#…...

LeetCode 重新安排行程题解
LeetCode 重新安排行程题解 题目描述 给定一个机票列表,从起点出发,重新安排行程。 示例: 输入:tickets [["MUC","LHR"],["JFK","MUC"],["SFO","SJC"],["LHR&…...

The import xxx.xxx.xxx is never used
The import xxx.xxx.xxx is never used List is a raw type. References to generic type List<E> should be parameterized Dead code The value of the local variable d is not used代码洁癖啊,为啥这些这么多黄色警告都不处理呢。 没有用的代码࿰…...

Sub-agent 协同失效的 3 类边界场景:Claude Code 8.1 机制原理解析
1. Sub-agent 协同失效不是 Bug,是机制在“按说明书执行” 大多数人第一次遇到 Sub-agent 返回空响应、反复循环调用主 Agent、或在多轮协作后突然“忘记”前序任务时,第一反应是:配置错了?网络不稳定?模型退化了?我试过把 claude-code 从 8.0.3 升到 8.1.1,又降回 8.0…...

Windows HEIC缩略图解决方案:告别格式壁垒,实现跨平台无缝浏览
Windows HEIC缩略图解决方案:告别格式壁垒,实现跨平台无缝浏览 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails…...

从ColorDialog到FontDialog:手把手教你定制WinForm功能对话框,打造个性化桌面应用
从ColorDialog到FontDialog:WinForm功能对话框的深度定制与用户体验优化 在桌面应用开发中,对话框不仅是功能实现的工具,更是用户体验的重要组成部分。想象一下,当用户在使用你的文本编辑器时,能够像专业软件那样流畅地…...

【.NET新特性·第1篇】.NET 8:统一平台的成熟之作
三年磨一剑,.NET 8 是微软统一平台战略的首个 LTS 里程碑版本 版本定位 适用版本:.NET 8 | LTS(长期支持) 支持周期:3 年(2023.11 - 2026.11) 前置知识:.NET 6/7 或其他版本的 C# 开…...

Adams新手避坑指南:从几何点、Marker坐标系到立方体,这些基础元素你真的用对了吗?
Adams新手避坑指南:几何元素背后的工程逻辑与实战陷阱 刚接触Adams的工程师常会陷入一个误区——把软件操作手册当作圣经,却忽略了每个几何元素背后的物理意义和工程逻辑。这种"知其然不知其所以然"的学习方式,往往会导致仿真结果失…...

零碳园区绿电直供技术的挑战与解决方案
一、难点问题 二次系统+储能推高初投 篇幅有限仅展示了部分 根据650号文 ,绿电直连项目必须配置继电保护、安全稳定控制装置和通信设备等二次系统 ,以确保项目的安全性和稳定性。这些强制性配置显著增加了项目的初始投资成本。 专线造价与全周…...