OpenSource - 基于 DFA 算法实现的高性能 java 敏感词过滤工具框架
文章目录
- sensitive-word
- 创作目的
- 特性
- 变更日志
- 更多资料
- 敏感词控台
- 敏感词标签文件
- 快速开始
- 准备
- Maven 引入
- 核心方法
- 判断是否包含敏感词
- 返回第一个敏感词
- 返回所有敏感词
- 默认的替换策略
- 指定替换的内容
- 自定义替换策略
- IWordResultHandler 结果处理类
- 使用实例
- 更多特性
- 样式处理
- 忽略大小写
- 忽略半角圆角
- 忽略数字的写法
- 忽略繁简体
- 忽略英文的书写格式
- 忽略重复词
- 更多检测策略
- 邮箱检测
- 连续数字检测
- 网址检测
- 引导类特性配置
- 说明
- 配置方法
- 配置说明
- 忽略字符
- 说明
- 例子
- 敏感词标签
- 说明
- 入门例子
- 接口
- 配置文件
- 实现
- 动态加载(用户自定义)
- 情景说明
- 接口说明
- IWordDeny
- IWordAllow
- 配置使用
- 系统的默认配置
- 指定自己的实现
- 同时配置多个
- spring 整合
- 背景
- 自定义数据源
- 动态变更
- Benchmark
- 环境
- 测试效果记录
- 后期 road-map
- 拓展阅读
- NLP 开源矩阵

sensitive-word
sensitive-word 基于 DFA 算法实现的高性能敏感词工具。
The sensitive word tool for java.(敏感词/违禁词/违法词/脏词。基于 DFA 算法实现的高性能 java 敏感词过滤工具框架。请勿发布涉及政治、广告、营销、翻墙、违反国家法律法规等内容。高性能敏感词检测过滤组件,附带繁体简体互换,支持全角半角互换,汉字转拼音,模糊搜索等功能。)

在线体验
创作目的
实现一款好用敏感词工具。
基于 DFA 算法实现,目前敏感词库内容收录 6W+(源文件 18W+,经过一次删减)。
后期将进行持续优化和补充敏感词库,并进一步提升算法的性能。
希望可以细化敏感词的分类,感觉工作量比较大,暂时没有进行。
特性
-
6W+ 词库,且不断优化更新
-
基于 fluent-api 实现,使用优雅简洁
-
基于 DFA 算法,性能为 7W+ QPS,应用无感
-
支持敏感词的判断、返回、脱敏等常见操作
-
支持常见的格式转换
全角半角互换、英文大小写互换、数字常见形式的互换、中文繁简体互换、英文常见形式的互换、忽略重复词等
-
支持敏感词检测、邮箱检测、数字检测、网址检测等
-
支持自定义替换策略
-
支持用户自定义敏感词和白名单
-
支持数据的数据动态更新(用户自定义),实时生效
-
支持敏感词的标签接口
-
支持跳过一些特殊字符,让匹配更灵活
变更日志
CHANGE_LOG.md
更多资料
敏感词控台
有时候敏感词有一个控台,配置起来会更加灵活方便。
java 如何实现开箱即用的敏感词控台服务?
敏感词标签文件
梳理了大量的敏感词标签文件,可以让我们的敏感词更加方便。
这两个资料阅读可在下方文章获取:
v0.11.0-敏感词新特性及对应标签文件
快速开始
准备
-
JDK1.7+
-
Maven 3.x+
Maven 引入
<dependency><groupId>com.github.houbb</groupId><artifactId>sensitive-word</artifactId><version>0.12.0</version>
</dependency>
核心方法
SensitiveWordHelper 作为敏感词的工具类,核心方法如下:
| 方法 | 参数 | 返回值 | 说明 |
|---|---|---|---|
| contains(String) | 待验证的字符串 | 布尔值 | 验证字符串是否包含敏感词 |
| replace(String, ISensitiveWordReplace) | 使用指定的替换策略替换敏感词 | 字符串 | 返回脱敏后的字符串 |
| replace(String, char) | 使用指定的 char 替换敏感词 | 字符串 | 返回脱敏后的字符串 |
| replace(String) | 使用 * 替换敏感词 | 字符串 | 返回脱敏后的字符串 |
| findAll(String) | 待验证的字符串 | 字符串列表 | 返回字符串中所有敏感词 |
| findFirst(String) | 待验证的字符串 | 字符串 | 返回字符串中第一个敏感词 |
| findAll(String, IWordResultHandler) | IWordResultHandler 结果处理类 | 字符串列表 | 返回字符串中所有敏感词 |
| findFirst(String, IWordResultHandler) | IWordResultHandler 结果处理类 | 字符串 | 返回字符串中第一个敏感词 |
| tags(String) | 获取敏感词的标签 | 敏感词字符串 | 返回敏感词的标签列表 |
判断是否包含敏感词
final String text = "五星红旗迎风飘扬,毛主席的画像屹立在天安门前。";Assert.assertTrue(SensitiveWordHelper.contains(text));
返回第一个敏感词
final String text = "五星红旗迎风飘扬,毛主席的画像屹立在天安门前。";String word = SensitiveWordHelper.findFirst(text);
Assert.assertEquals("五星红旗", word);
SensitiveWordHelper.findFirst(text) 等价于:
String word = SensitiveWordHelper.findFirst(text, WordResultHandlers.word());
WordResultHandlers.raw() 可以保留对应的下标信息:
final String text = "五星红旗迎风飘扬,毛主席的画像屹立在天安门前。";IWordResult word = SensitiveWordHelper.findFirst(text, WordResultHandlers.raw());
Assert.assertEquals("WordResult{startIndex=0, endIndex=4}", word.toString());
返回所有敏感词
final String text = "五星红旗迎风飘扬,毛主席的画像屹立在天安门前。";List<String> wordList = SensitiveWordHelper.findAll(text);
Assert.assertEquals("[五星红旗, 毛主席, 天安门]", wordList.toString());
返回所有敏感词用法上类似于 SensitiveWordHelper.findFirst(),同样也支持指定结果处理类。
SensitiveWordHelper.findAll(text) 等价于:
List<String> wordList = SensitiveWordHelper.findAll(text, WordResultHandlers.word());
WordResultHandlers.raw() 可以保留对应的下标信息:
final String text = "五星红旗迎风飘扬,毛主席的画像屹立在天安门前。";List<IWordResult> wordList = SensitiveWordHelper.findAll(text, WordResultHandlers.raw());
Assert.assertEquals("[WordResult{startIndex=0, endIndex=4}, WordResult{startIndex=9, endIndex=12}, WordResult{startIndex=18, endIndex=21}]", wordList.toString());
默认的替换策略
final String text = "五星红旗迎风飘扬,毛主席的画像屹立在天安门前。";
String result = SensitiveWordHelper.replace(text);
Assert.assertEquals("****迎风飘扬,***的画像屹立在***前。", result);
指定替换的内容
final String text = "五星红旗迎风飘扬,毛主席的画像屹立在天安门前。";
String result = SensitiveWordHelper.replace(text, '0');
Assert.assertEquals("0000迎风飘扬,000的画像屹立在000前。", result);
自定义替换策略
V0.2.0 支持该特性。
场景说明:有时候我们希望不同的敏感词有不同的替换结果。比如【游戏】替换为【电子竞技】,【失业】替换为【灵活就业】。
诚然,提前使用字符串的正则替换也可以,不过性能一般。
使用例子:
/*** 自定替换策略* @since 0.2.0*/
@Test
public void defineReplaceTest() {final String text = "五星红旗迎风飘扬,毛主席的画像屹立在天安门前。";ISensitiveWordReplace replace = new MySensitiveWordReplace();String result = SensitiveWordHelper.replace(text, replace);Assert.assertEquals("国家旗帜迎风飘扬,教员的画像屹立在***前。", result);
}
其中 MySensitiveWordReplace 是我们自定义的替换策略,实现如下:
public class MyWordReplace implements IWordReplace {@Overridepublic void replace(StringBuilder stringBuilder, final char[] rawChars, IWordResult wordResult, IWordContext wordContext) {String sensitiveWord = InnerWordCharUtils.getString(rawChars, wordResult);// 自定义不同的敏感词替换策略,可以从数据库等地方读取if("五星红旗".equals(sensitiveWord)) {stringBuilder.append("国家旗帜");} else if("毛主席".equals(sensitiveWord)) {stringBuilder.append("教员");} else {// 其他默认使用 * 代替int wordLength = wordResult.endIndex() - wordResult.startIndex();for(int i = 0; i < wordLength; i++) {stringBuilder.append('*');}}}}
我们针对其中的部分词做固定映射处理,其他的默认转换为 *。
IWordResultHandler 结果处理类
IWordResultHandler 可以对敏感词的结果进行处理,允许用户自定义。
内置实现见 WordResultHandlers 工具类:
- WordResultHandlers.word()
只保留敏感词单词本身。
- WordResultHandlers.raw()
保留敏感词相关信息,包含敏感词的开始和结束下标。
- WordResultHandlers.wordTags()
同时保留单词,和对应的词标签信息。
使用实例
所有测试案例参见 SensitiveWordHelperTest
1)基本例子
final String text = "五星红旗迎风飘扬,毛主席的画像屹立在天安门前。";List<String> wordList = SensitiveWordHelper.findAll(text);
Assert.assertEquals("[五星红旗, 毛主席, 天安门]", wordList.toString());
List<String> wordList2 = SensitiveWordHelper.findAll(text, WordResultHandlers.word());
Assert.assertEquals("[五星红旗, 毛主席, 天安门]", wordList2.toString());List<IWordResult> wordList3 = SensitiveWordHelper.findAll(text, WordResultHandlers.raw());
Assert.assertEquals("[WordResult{startIndex=0, endIndex=4}, WordResult{startIndex=9, endIndex=12}, WordResult{startIndex=18, endIndex=21}]", wordList3.toString());
- wordTags 例子
我们在 dict_tag_test.txt 文件中指定对应词的标签信息。
final String text = "五星红旗迎风飘扬,毛主席的画像屹立在天安门前。";// 默认敏感词标签为空
List<WordTagsDto> wordList1 = SensitiveWordHelper.findAll(text, WordResultHandlers.wordTags());
Assert.assertEquals("[WordTagsDto{word='五星红旗', tags=[]}, WordTagsDto{word='毛主席', tags=[]}, WordTagsDto{word='天安门', tags=[]}]", wordList1.toString());List<WordTagsDto> wordList2 = SensitiveWordBs.newInstance().wordTag(WordTags.file("dict_tag_test.txt")).init().findAll(text, WordResultHandlers.wordTags());
Assert.assertEquals("[WordTagsDto{word='五星红旗', tags=[政治, 国家]}, WordTagsDto{word='毛主席', tags=[政治, 伟人, 国家]}, WordTagsDto{word='天安门', tags=[政治, 国家, 地址]}]", wordList2.toString());
更多特性
后续的诸多特性,主要是针对各种针对各种情况的处理,尽可能的提升敏感词命中率。
这是一场漫长的攻防之战。
样式处理
忽略大小写
final String text = "fuCK the bad words.";String word = SensitiveWordHelper.findFirst(text);
Assert.assertEquals("fuCK", word);
忽略半角圆角
final String text = "fuck the bad words.";String word = SensitiveWordHelper.findFirst(text);
Assert.assertEquals("fuck", word);
忽略数字的写法
这里实现了数字常见形式的转换。
final String text = "这个是我的微信:9⓿二肆⁹₈③⑸⒋➃㈤㊄";List<String> wordList = SensitiveWordHelper.findAll(text);
Assert.assertEquals("[9⓿二肆⁹₈③⑸⒋➃㈤㊄]", wordList.toString());
忽略繁简体
final String text = "我爱我的祖国和五星紅旗。";List<String> wordList = SensitiveWordHelper.findAll(text);
Assert.assertEquals("[五星紅旗]", wordList.toString());
忽略英文的书写格式
final String text = "Ⓕⓤc⒦ the bad words";List<String> wordList = SensitiveWordHelper.findAll(text);
Assert.assertEquals("[Ⓕⓤc⒦]", wordList.toString());
忽略重复词
final String text = "ⒻⒻⒻfⓤuⓤ⒰cⓒ⒦ the bad words";List<String> wordList = SensitiveWordBs.newInstance().ignoreRepeat(true).init().findAll(text);
Assert.assertEquals("[ⒻⒻⒻfⓤuⓤ⒰cⓒ⒦]", wordList.toString());
更多检测策略
邮箱检测
final String text = "楼主好人,邮箱 sensitiveword@xx.com";List<String> wordList = SensitiveWordHelper.findAll(text);
Assert.assertEquals("[sensitiveword@xx.com]", wordList.toString());
连续数字检测
一般用于过滤手机号/QQ等广告信息。
V0.2.1 之后,支持通过 numCheckLen(长度) 自定义检测的长度。
final String text = "你懂得:12345678";// 默认检测 8 位
List<String> wordList = SensitiveWordBs.newInstance().init().findAll(text);
Assert.assertEquals("[12345678]", wordList.toString());// 指定数字的长度,避免误杀
List<String> wordList2 = SensitiveWordBs.newInstance().numCheckLen(9).init().findAll(text);
Assert.assertEquals("[]", wordList2.toString());
网址检测
用于过滤常见的网址信息。
final String text = "点击链接 www.baidu.com查看答案";List<String> wordList = SensitiveWordBs.newInstance().init().findAll(text);
Assert.assertEquals("[链接, www.baidu.com]", wordList.toString());Assert.assertEquals("点击** *************查看答案", SensitiveWordBs.newInstance().init().replace(text));
引导类特性配置
说明
上面的特性默认都是开启的,有时业务需要灵活定义相关的配置特性。
所以 v0.0.14 开放了属性配置。
配置方法
为了让使用更加优雅,统一使用 fluent-api 的方式定义。
用户可以使用 SensitiveWordBs 进行如下定义:
SensitiveWordBs wordBs = SensitiveWordBs.newInstance().ignoreCase(true).ignoreWidth(true).ignoreNumStyle(true).ignoreChineseStyle(true).ignoreEnglishStyle(true).ignoreRepeat(false).enableNumCheck(true).enableEmailCheck(true).enableUrlCheck(true).enableWordCheck(true).numCheckLen(8).wordTag(WordTags.none()).charIgnore(SensitiveWordCharIgnores.defaults()).init();final String text = "五星红旗迎风飘扬,毛主席的画像屹立在天安门前。";
Assert.assertTrue(wordBs.contains(text));
配置说明
其中各项配置的说明如下:
| 序号 | 方法 | 说明 | 默认值 |
|---|---|---|---|
| 1 | ignoreCase | 忽略大小写 | true |
| 2 | ignoreWidth | 忽略半角圆角 | true |
| 3 | ignoreNumStyle | 忽略数字的写法 | true |
| 4 | ignoreChineseStyle | 忽略中文的书写格式 | true |
| 5 | ignoreEnglishStyle | 忽略英文的书写格式 | true |
| 6 | ignoreRepeat | 忽略重复词 | false |
| 7 | enableNumCheck | 是否启用数字检测。 | true |
| 8 | enableEmailCheck | 是有启用邮箱检测 | true |
| 9 | enableUrlCheck | 是否启用链接检测 | true |
| 10 | enableWordCheck | 是否启用敏感单词检测 | true |
| 11 | numCheckLen | 数字检测,自定义指定长度。 | 8 |
| 12 | wordTag | 词对应的标签 | none |
| 13 | charIgnore | 忽略的字符 | none |
忽略字符
说明
我们的敏感词一般都是比较连续的,比如【傻帽】
那就有大聪明发现,可以在中间加一些字符,比如【傻!@#$帽】跳过检测,但是骂人等攻击力不减。
那么,如何应对这些类似的场景呢?
我们可以指定特殊字符的跳过集合,忽略掉这些无意义的字符即可。
v0.11.0 开始支持
例子
其中 charIgnore 对应的字符策略,用户可以自行灵活定义。
final String text = "傻@冒,狗+东西";//默认因为有特殊字符分割,无法识别
List<String> wordList = SensitiveWordBs.newInstance().init().findAll(text);
Assert.assertEquals("[]", wordList.toString());// 指定忽略的字符策略,可自行实现。
List<String> wordList2 = SensitiveWordBs.newInstance().charIgnore(SensitiveWordCharIgnores.specialChars()).init().findAll(text);Assert.assertEquals("[傻@冒, 狗+东西]", wordList2.toString());
敏感词标签
说明
有时候我们希望对敏感词加一个分类标签:比如社情、暴/力等等。
这样后续可以按照标签等进行更多特性操作,比如只处理某一类的标签。
支持版本:v0.10.0
入门例子
接口
这里只是一个抽象的接口,用户可以自行定义实现。比如从数据库查询等。
public interface IWordTag {/*** 查询标签列表* @param word 脏词* @return 结果*/Set<String> getTag(String word);}
配置文件
我们可以自定义 dict 标签文件,通过 WordTags.file() 创建一个 WordTag 实现。
- dict_tag_test.txt
五星红旗 政治,国家
格式如下:
敏感词 tag1,tag2
实现
具体的效果如下,在引导类设置一下即可。
默认的 wordTag 是空的。
String filePath = "dict_tag_test.txt";
IWordTag wordTag = WordTags.file(filePath);SensitiveWordBs sensitiveWordBs = SensitiveWordBs.newInstance().wordTag(wordTag).init();Assert.assertEquals("[政治, 国家]", sensitiveWordBs.tags("五星红旗").toString());;
后续会考虑引入一个内置的标签文件策略。
动态加载(用户自定义)
情景说明
有时候我们希望将敏感词的加载设计成动态的,比如控台修改,然后可以实时生效。
v0.0.13 支持了这种特性。
接口说明
为了实现这个特性,并且兼容以前的功能,我们定义了两个接口。
IWordDeny
接口如下,可以自定义自己的实现。
返回的列表,表示这个词是一个敏感词。
/*** 拒绝出现的数据-返回的内容被当做是敏感词* @author binbin.hou* @since 0.0.13*/
public interface IWordDeny {/*** 获取结果* @return 结果* @since 0.0.13*/List<String> deny();}
比如:
public class MyWordDeny implements IWordDeny {@Overridepublic List<String> deny() {return Arrays.asList("我的自定义敏感词");}}
IWordAllow
接口如下,可以自定义自己的实现。
返回的列表,表示这个词不是一个敏感词。
/*** 允许的内容-返回的内容不被当做敏感词* @author binbin.hou* @since 0.0.13*/
public interface IWordAllow {/*** 获取结果* @return 结果* @since 0.0.13*/List<String> allow();}
如:
public class MyWordAllow implements IWordAllow {@Overridepublic List<String> allow() {return Arrays.asList("五星红旗");}}
配置使用
接口自定义之后,当然需要指定才能生效。
为了让使用更加优雅,我们设计了引导类 SensitiveWordBs。
可以通过 wordDeny() 指定敏感词,wordAllow() 指定非敏感词,通过 init() 初始化敏感词字典。
系统的默认配置
SensitiveWordBs wordBs = SensitiveWordBs.newInstance().wordDeny(WordDenys.system()).wordAllow(WordAllows.system()).init();final String text = "五星红旗迎风飘扬,毛主席的画像屹立在天安门前。";
Assert.assertTrue(wordBs.contains(text));
备注:init() 对于敏感词 DFA 的构建是比较耗时的,一般建议在应用初始化的时候只初始化一次。而不是重复初始化!
指定自己的实现
我们可以测试一下自定义的实现,如下:
String text = "这是一个测试,我的自定义敏感词。";SensitiveWordBs wordBs = SensitiveWordBs.newInstance().wordDeny(new MyWordDeny()).wordAllow(new MyWordAllow()).init();Assert.assertEquals("[我的自定义敏感词]", wordBs.findAll(text).toString());
这里只有 我的自定义敏感词 是敏感词,而 测试 不是敏感词。
当然,这里是全部使用我们自定义的实现,一般建议使用系统的默认配置+自定义配置。
可以使用下面的方式。
同时配置多个
- 多个敏感词
WordDenys.chains() 方法,将多个实现合并为同一个 IWordDeny。
- 多个白名单
WordAllows.chains() 方法,将多个实现合并为同一个 IWordAllow。
例子:
String text = "这是一个测试。我的自定义敏感词。";IWordDeny wordDeny = WordDenys.chains(WordDenys.system(), new MyWordDeny());
IWordAllow wordAllow = WordAllows.chains(WordAllows.system(), new MyWordAllow());SensitiveWordBs wordBs = SensitiveWordBs.newInstance().wordDeny(wordDeny).wordAllow(wordAllow).init();Assert.assertEquals("[我的自定义敏感词]", wordBs.findAll(text).toString());
这里都是同时使用了系统默认配置,和自定义的配置。
注意:我们初始化了新的 wordBs,那么用新的 wordBs 去判断。而不是用以前的 SensitiveWordHelper 工具方法,工具方法配置是默认的!
spring 整合
背景
实际使用中,比如可以在页面配置修改,然后实时生效。
数据存储在数据库中,下面是一个伪代码的例子,可以参考 SpringSensitiveWordConfig.java
要求,版本 v0.0.15 及其以上。
自定义数据源
简化伪代码如下,数据的源头为数据库。
MyDdWordAllow 和 MyDdWordDeny 是基于数据库为源头的自定义实现类。
@Configuration
public class SpringSensitiveWordConfig {@Autowiredprivate MyDdWordAllow myDdWordAllow;@Autowiredprivate MyDdWordDeny myDdWordDeny;/*** 初始化引导类* @return 初始化引导类* @since 1.0.0*/@Beanpublic SensitiveWordBs sensitiveWordBs() {SensitiveWordBs sensitiveWordBs = SensitiveWordBs.newInstance().wordAllow(WordAllows.chains(WordAllows.system(), myDdWordAllow)).wordDeny(myDdWordDeny)// 各种其他配置.init();return sensitiveWordBs;}}
敏感词库的初始化较为耗时,建议程序启动时做一次 init 初始化。
动态变更
为了保证敏感词修改可以实时生效且保证接口的尽可能简化,此处没有新增 add/remove 的方法。
而是在调用 sensitiveWordBs.init() 的时候,根据 IWordDeny+IWordAllow 重新构建敏感词库。
因为初始化可能耗时较长(秒级别),所有优化为 init 未完成时不影响旧的词库功能,完成后以新的为准。
@Component
public class SensitiveWordService {@Autowiredprivate SensitiveWordBs sensitiveWordBs;/*** 更新词库** 每次数据库的信息发生变化之后,首先调用更新数据库敏感词库的方法。* 如果需要生效,则调用这个方法。** 说明:重新初始化不影响旧的方法使用。初始化完成后,会以新的为准。*/public void refresh() {// 每次数据库的信息发生变化之后,首先调用更新数据库敏感词库的方法,然后调用这个方法。sensitiveWordBs.init();}}
如上,你可以在数据库词库发生变更时,需要词库生效,主动触发一次初始化 sensitiveWordBs.init();。
其他使用保持不变,无需重启应用。
Benchmark
V0.6.0 以后,添加对应的 benchmark 测试。
BenchmarkTimesTest
环境
测试环境为普通的笔记本:
处理器 12th Gen Intel(R) Core(TM) i7-1260P 2.10 GHz
机带 RAM 16.0 GB (15.7 GB 可用)
系统类型 64 位操作系统, 基于 x64 的处理器
ps: 不同环境会有差异,但是比例基本稳定。
测试效果记录
测试数据:100+ 字符串,循环 10W 次。
| 序号 | 场景 | 耗时 | 备注 |
|---|---|---|---|
| 1 | 只做敏感词,无任何格式转换 | 1470ms,约 7.2W QPS | 追求极致性能,可以这样配置 |
| 2 | 只做敏感词,支持全部格式转换 | 2744ms,约 3.7W QPS | 满足大部分场景 |
后期 road-map
-
移除单个汉字的敏感词,在中国,要把词组当做一次词,降低误判率。
-
支持单个的敏感词变化?
remove、add、edit?
-
敏感词标签接口支持
-
敏感词处理时标签支持
-
wordData 的内存占用对比 + 优化
-
用户指定自定义的词组,同时允许指定词组的组合获取,更加灵活
FormatCombine/CheckCombine/AllowDenyCombine 组合策略,允许用户自定义。
-
word check 策略的优化,统一遍历+转换
-
添加 ThreadLocal 等性能优化
拓展阅读
敏感词工具实现思路
DFA 算法讲解
敏感词库优化流程
java 如何实现开箱即用的敏感词控台服务?
v0.11.0-敏感词新特性及对应标签文件

NLP 开源矩阵
pinyin 汉字转拼音
pinyin2hanzi 拼音转汉字
segment 高性能中文分词
opencc4j 中文繁简体转换
nlp-hanzi-similar 汉字相似度
word-checker 拼写检测
sensitive-word 敏感词
相关文章:
OpenSource - 基于 DFA 算法实现的高性能 java 敏感词过滤工具框架
文章目录 sensitive-word创作目的特性变更日志更多资料敏感词控台敏感词标签文件 快速开始准备Maven 引入核心方法判断是否包含敏感词返回第一个敏感词返回所有敏感词默认的替换策略指定替换的内容自定义替换策略 IWordResultHandler 结果处理类使用实例 更多特性样式处理忽略大…...

端杂七杂八系列篇四-Java8篇
后端杂七杂八系列篇四-Java8篇 ① Lombok插件① RequiredArgsConstructor② SneakyThrows③ UtilityClass④ Cleanup ② Lambda 4个常用的内置函数① Function<T, R> - 接受一个输入参数并返回一个结果② Consumer - 接受一个输入参数,并执行某种操作…...

操作系统一些面试
你这个请求队列是属于一写多读对吧,怎么解决冲突的? 可以采用双buffer或者说双缓冲区,一个缓冲区用来写,一个缓冲区用来读,采用交换指针的方法来进行缓存区的交换,这样交换效率是O(1)的,但是交…...
大语言模型
概念 大语言模型(Large Language Model,简称LLM)是一种基于人工智能技术的自然语言处理模型,是指在大量数据上训练的高级人工智能算法,以自上文推理词语概率为核心任务。它通过在海量文本数据上进行训练,学…...
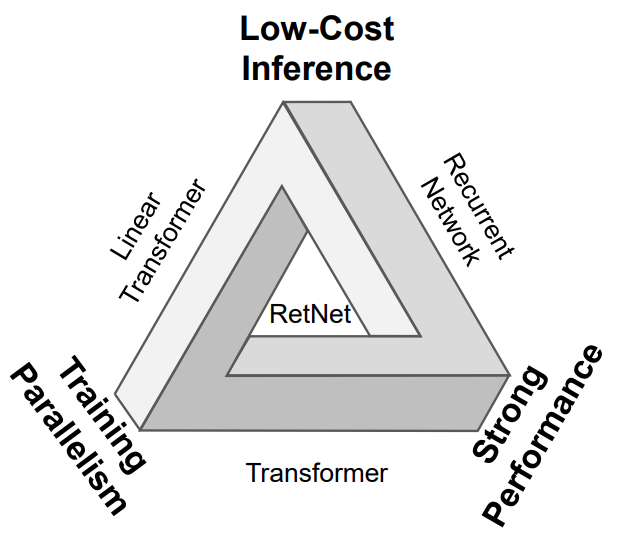
php反序列化之pop链构造(基于重庆橙子科技靶场)
常见魔术方法的触发 __construct() //创建类对象时调用 __destruct() //对象被销毁时触发 __call() //在对象中调用不可访问的方法时触发 __callStatic() //在静态方式中调用不可访问的方法时触发 __get() //调用类中不存在变量时触发(找有连续箭头的…...
k8s---对外服务 ingress
目录 目录 目录 ingress与service ingress的组成 ingress-controller: ingress暴露服务的方式 2.方式二:DaemonSethostnetworknodeSelector DaemonSethostnetworknodeSelector如何实现 3.deploymentNodePort: 虚拟主机的方式实现http代…...
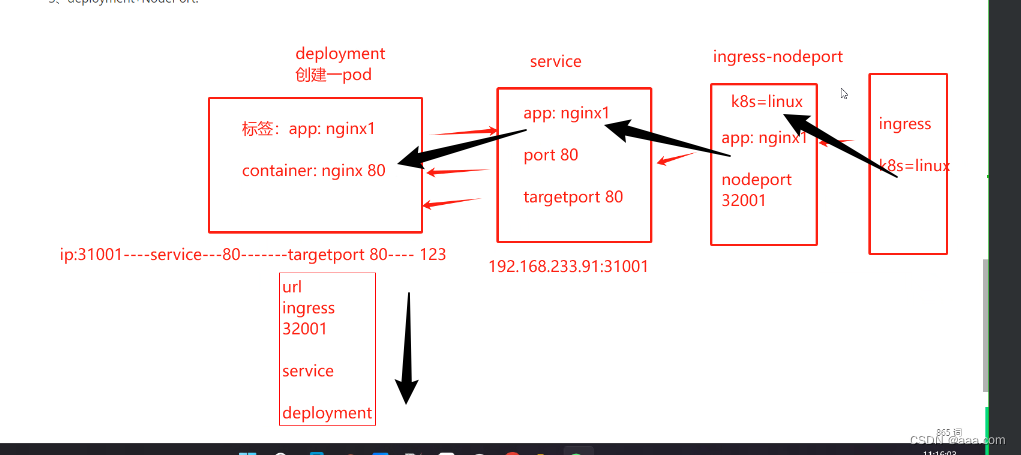
最优解-最长公共子序列
问题描述 最长公共子序列(Longest Common Subsequence,LCS)即求两个序列最长的公共子序列(可以不连续)。比如3 2 1 4 5和1 2 3 4 5两个序列,最长公共子序列为2 4 5 长度为3。解决这个问题必然要使用动态规划。既然要用到动态规划,就要知道状…...
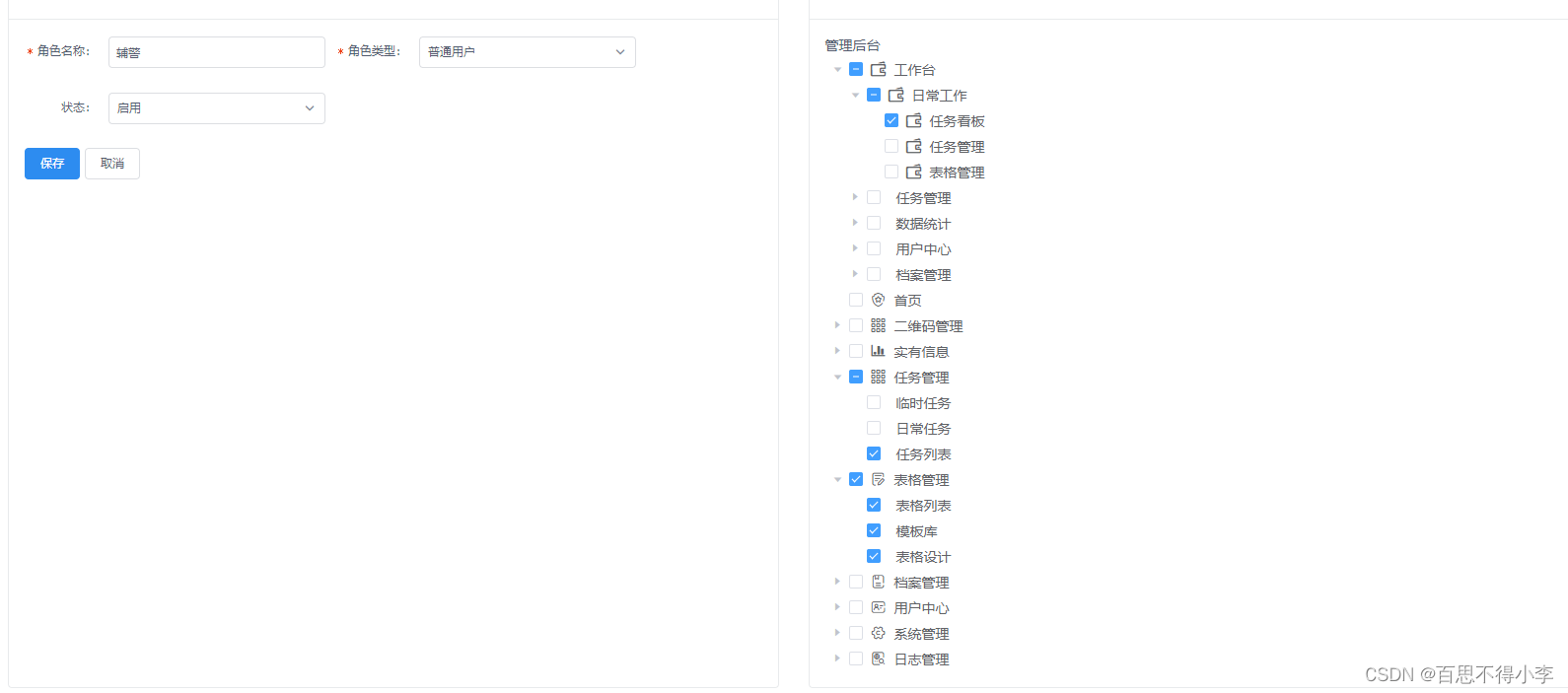
el-tree获取当前选中节点及其所有父节点的id(包含半选中父节点的id)
如下图,我们现在全勾中的有表格管理及其下的子级,而半勾中的有工作台和任务管理及其子级 现在点击保存按钮后,需要将勾中的节点id及该节点对应的父节点,祖先节点的id(包含半选中父节点的id)也都一并传给后端,那这个例子里就应该共传入9个id,我们可以直接将getCheckedK…...

新上线一个IT公司微信小程序
项目介绍 项目背景: 一家IT公司,业务包含以下六大块: 1、IT设备回收 2、IT设备租赁 3、IT设备销售 4、IT设备维修 5、IT外包 6、IT软件开发 通过小程序,提供在线下单,在线制单,在线销售,业务介绍,推广,会员 项目目的: 业务介绍: 包含企业业务介绍 客户需…...

MCAL配置-PWM(EB23.0)
PWM配置项的介绍 一、General 1、PwmDeInitApi 从代码中添加/删除Pwm_17_GtmCcu6_Delnit() API。 TRUE:Pwm_17_GtmCcu6_Delnit() API可供用户使用。 FALSE:Pwm_17_GtmCcu6_Delnit() API对用户不可用。 注意:默认情况下禁用Pwm_17_GtmCcu6_Delnit() …...
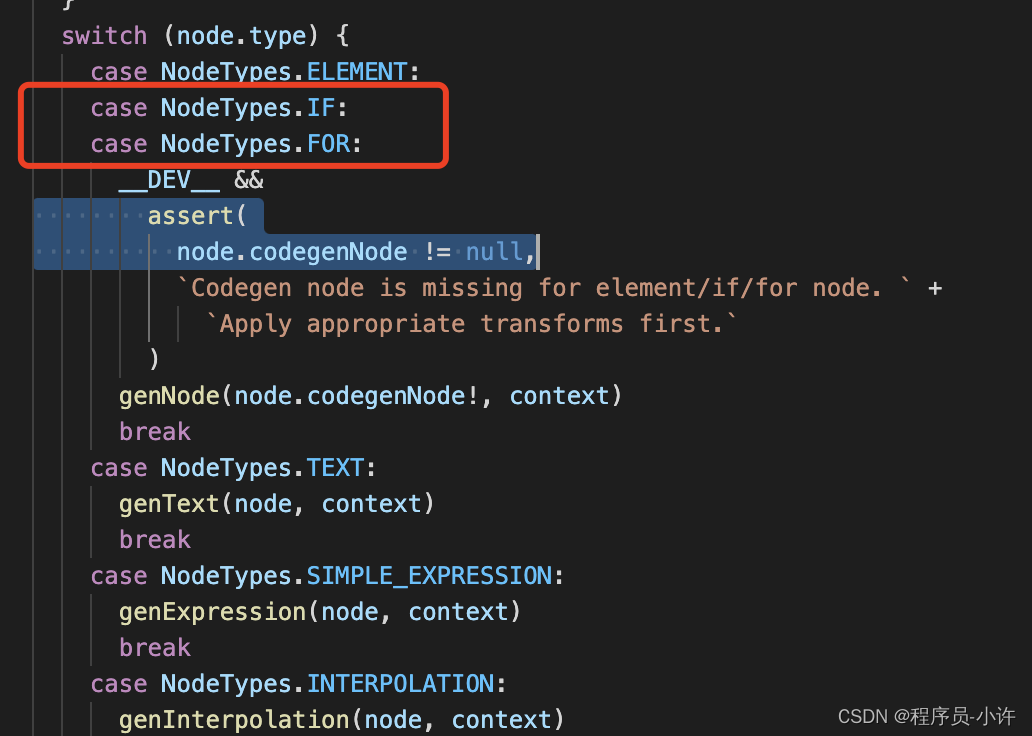
v-if和v-for哪个优先级更高?
v-if和v-for哪个优先级更高? 结论: vue2输出的渲染函数是先执行循环,在看条件判断,如果将v-if和v-for写在一个标签内,哪怕只渲染列表中的一小部分,也要重新遍历整个列表,无形造成资源浪费。vu…...
.)
Mapstruct 常用案例(持续更新.).
将A转换为B Mapper(componentModel "spring") public interface DemoConvert {B A2B(A a); }将List转换为List 注意:以下两个都不可缺少,需要先声明单个和集合的同时生命才可 Mapper(componentModel "spring") public interface …...
QT5网络与通信)
QT基础篇(10)QT5网络与通信
QT5网络与通信是指在QT5开发环境中使用网络进行数据传输和通信的相关功能和技术。 QT5提供了一套完善的网络模块,包括了TCP、UDP、HTTP等协议的支持,可以方便地在QT应用程序中进行网络通信。通过QT5的网络模块,开发者可以实现客户端和服务器…...
)
【Leetcode】269.火星词典(Hard)
一、题目 1、题目描述 现有一种使用英语字母的火星语言,这门语言的字母顺序与英语顺序不同。 给你一个字符串列表 words ,作为这门语言的词典,words 中的字符串已经 按这门新语言的字母顺序进行了排序 。 请你根据该词典还原出此语言中已知的字母顺序,并 按字母递增顺序…...

opencv_模型训练
文件夹 opencv训练文件 xml negdataposdata 说明 negdata目录: 放负样本的目录 posdata目录: 放正样本的目录 xml目录: 新建的一个目录,为之后存放分类器文件使用 neg.txt: 负样本路径列表 pos.txt: 正样本路径列表 pos.vec: 后续自动生成…...
python PyQt5的学习
一、安装与配置 1、环境: python3.7 2、相关模块 pip install pyqt5 pyqt5-tools pyqt5designer 可以加个镜像 -i https://pypi.tuna.tsinghua.edu.cn/simple3、配置设计器 python的pyqt5提供了一个设计器,便于ui的设计 界面是这样的:…...

3.goLand基础语法
目录 概述语法for常量与变量数组切片 slice切片问题问题1问题2 Make 和 New结构体和指针结构体标签 结束 概述 从 java 转来学 go ,在此记录,方便以后翻阅。 语法 for package mainimport "fmt"func main() {for i : 0; i < 3; i {fmt.…...
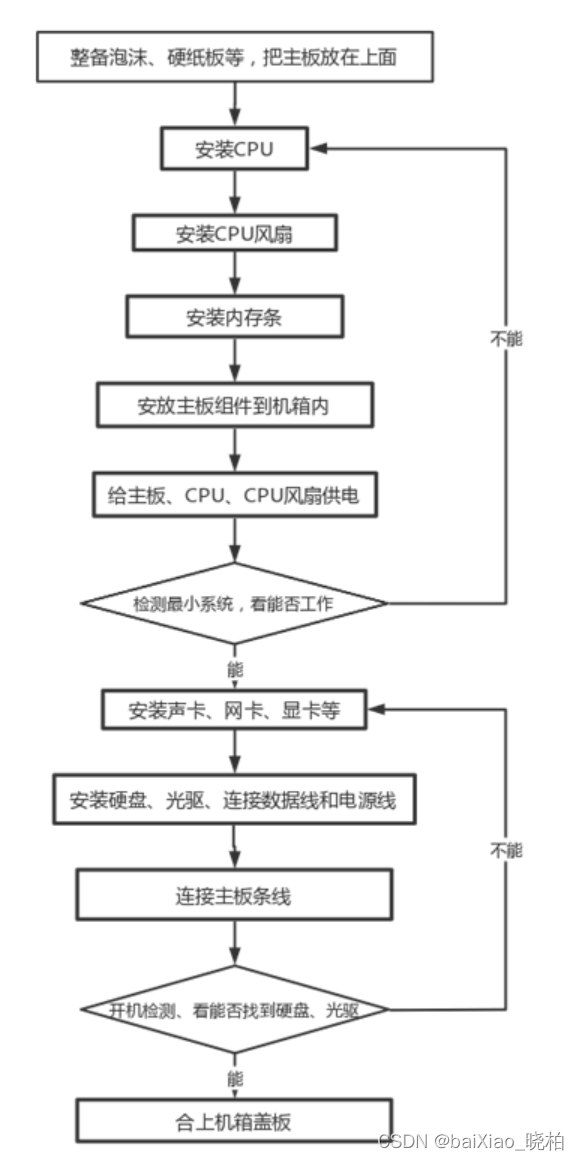
计算机硬件 5.2组装整机
第二节 组装整机 一、准备工作 1.常用工具:中号十字螺丝刀、尖嘴钳、软毛刷、防静电手环等。 2.组装原则: ①按“先小后大”“从里到外”的顺序进行,不遗漏每一环节,不“带病”进行下一环节。 ②合理使用工具器材,…...
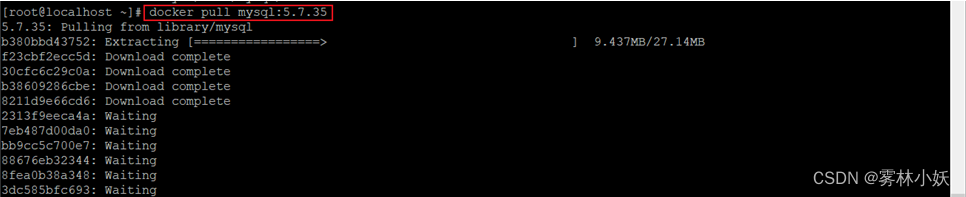
Docker搭建MySQL主从数据库-亲测有效
1、测试环境概述 1、使用MySQL5.7.35版本 2、使用Centos7操作系统 3、使用Docker20版本 案例中描述了整个测试的详细过程 2、安装Docker 2.1、如果已经安装docker,可以先卸载 yum remove -y docker \ docker-client \ docker-client-latest \ docker-common \ docker-l…...
PyTorch 中的距离函数深度解析:掌握向量间的距离和相似度计算
目录 Pytorch中Distance functions详解 pairwise_distance 用途 用法 参数 数学理论公式 示例代码 cosine_similarity 用途 用法 参数 数学理论 示例代码 输出结果 pdist 用途 用法 参数 数学理论 示例代码 总结 Pytorch中Distance functions详解 pair…...

AArch64虚拟内存系统架构与地址转换详解
1. AArch64虚拟内存系统架构概述虚拟内存是现代计算机系统的核心机制,它通过地址转换技术将程序使用的虚拟地址(VA)映射到实际的物理地址(PA)。AArch64作为ARMv8-A和ARMv9-A架构的64位执行状态,其虚拟内存系统在设计上兼顾了灵活性和性能需求。在AArch64…...
)
别再让电机‘刹不住车’:用ADRC的TD模块实现位置精准无超调控制(附STM32代码)
电机控制中的精准停车艺术:ADRC-TD模块实战解析与STM32实现 引言 在机器人关节控制、无人机云台稳定、CNC机床定位等场景中,工程师们经常面临一个看似简单却极具挑战的问题——如何让电机在到达目标位置时完美停下,不产生丝毫超调?…...
)
别再只跑测试了!用KAIR库从零训练你自己的SwinIR超分模型(附DIV2K/Flickr2K数据集处理避坑指南)
从测试到训练:SwinIR超分模型实战进阶指南 当你第一次用SwinIR的预训练模型将模糊照片变得清晰时,那种惊艳感可能让你跃跃欲试想训练自己的模型。但面对几十GB的数据集和复杂的训练配置,很多开发者停在了"只跑测试"的阶段。本文将带…...

从开发板到工业边缘计算平台:UP Board二代的硬件解析与应用实战
1. 项目概述:从“开发板”到“边缘计算平台”的认知跃迁最近在整理手头的嵌入式设备,翻出了这块研扬的UP Board二代。说实话,第一次拿到它的时候,我下意识地还是把它归类为“一块性能不错的x86开发板”,就像树莓派之于…...

不同版本Python安装常见问题与解决方案
1. 如何在特定的版本下安装package (1) 在命令提示符中,打开相应版本python的安装目录; (2) 执行语句python.exe -m pip install XX (3) 更新库 2. 如何在Spyder中设定特定的python解释器 Spyder—Tools—Python Interpreter...

如何快速部署AI视觉瞄准系统:3个版本满足不同需求的终极指南
如何快速部署AI视觉瞄准系统:3个版本满足不同需求的终极指南 【免费下载链接】AI-Aimbot Worlds Best AI Aimbot - CS2, Valorant, Fortnite, APEX, every game 项目地址: https://gitcode.com/gh_mirrors/ai/AI-Aimbot 欢迎来到AI视觉瞄准系统的完整实战教程…...

从黑盒到白盒:Testbench验证机制与FPGA/ASIC开发实践
1. 从“黑盒”到“白盒”:理解Testbench的本质在数字电路设计,尤其是FPGA和ASIC开发领域,我们常常把设计好的硬件描述语言(HDL)模块,比如一个Verilog写的加法器或者一个VHDL写的状态机,称为“待…...

量子同态加密:理论与实践的突破
1. 量子同态加密:理论与实践的桥梁量子同态加密(Quantum Homomorphic Encryption, QHE)是密码学领域的一项突破性技术,它允许在加密的量子数据上直接执行任意量子计算,而无需事先解密。这项技术对于构建真正隐私保护的…...

技术从业者的情绪管理:如何应对工作压力和职业焦虑
一、软件测试从业者的情绪困境:压力源与焦虑画像在敏捷开发与DevOps模式深度普及的今天,软件测试早已不是传统意义上的“事后把关”,而是贯穿需求分析、代码开发、上线运维全流程的质量核心环节。这种角色转变,也让测试从业者面临…...

ScienceDecrypting终极指南:如何永久解锁您的加密学术文献
ScienceDecrypting终极指南:如何永久解锁您的加密学术文献 【免费下载链接】ScienceDecrypting 破解CAJViewer带有效期的文档,支持破解科学文库、标准全文数据库下载的文档。无损破解,保留文字和目录,解除有效期限制。 项目地址…...