用 Rust 过程宏魔法简化 SQL 函数实现
#[function("length(varchar) -> int4")]
pub fn char_length(s: &str) -> i32 {s.chars().count() as i32
}
这是 RisingWave 中一个 SQL 函数的实现。只需短短几行代码,通过在 Rust 函数上加一行过程宏,我们就把它包装成了一个 SQL 函数。
dev=> select length('Rising Wave');length <br/>--------11
(1 row)
类似的,除了标量函数(Scalar Function),表函数(Table Function)和聚合函数(Aggregate Function)也可以用这样的方法定义。我们甚至可以利用泛型来同时定义多种类型的重载函数:
#[function("generate_series(int4, int4) -> setof int4")]
#[function("generate_series(int8, int8) -> setof int8")]
fn generate_series<T: Step>(start: T, stop: T) -> impl Iterator<Item = T> {start..=stop
}#[aggregate("max(int2) -> int2", state = "ref")]
#[aggregate("max(int4) -> int4", state = "ref")]
#[aggregate("max(int8) -> int8", state = "ref")]
fn max<T: Ord>(state: T, input: T) -> T {state.max(input)
}dev=> select generate_series(1, 3);generate_series
-----------------123
(3 rows)dev=> select max(x) from generate_series(1, 3) t(x);max
-----3
(1 row)
利用 Rust 过程宏,我们将函数实现背后的琐碎细节隐藏起来,向开发者暴露一个干净简洁的接口。这样我们便能够专注于函数本身逻辑的实现,从而大幅提高开发和维护的效率。
而当一个接口足够简单,简单到连 ChatGPT 都可以理解时,让 AI 帮我们写代码就不再是天方夜谭了。(警告:AI 会自信地写出 Bug,使用前需要人工 review)


向 GPT 展示一个 SQL 函数实现的例子,然后给出一个新函数的文档,让他生成完整的 Rust 实现代码。
在本文中,我们将深度解析 RisingWave 中 #[function] 过程宏的设计目标和工作原理。通过回答以下几个问题揭开过程宏的魔法面纱:
- 函数执行的过程是怎样的?
- 为什么选择使用过程宏实现?
- 这个宏是如何展开的?生成了怎样的代码?
- 利用过程宏还能实现哪些高级需求?
1. 向量化计算模型
RisingWave 是一个支持 SQL 语言的流处理引擎。在内部处理数据时,它使用基于列式内存存储的向量化计算模型。在这种模型下,一个表(Table)的数据按列分割,每一列的数据连续存储在一个数组(Array)中。为了便于理解,本文中我们采用列式内存的行业标准 Apache Arrow 格式作为示例。下图是其中一批数据(RecordBatch)的内存结构,RisingWave 的列存结构与之大同小异。

列式内存存储的数据结构
在函数求值时,我们首先把每个输入参数对应的数据列合并成一个 RecordBatch,然后依次读取每一行的数据,作为参数调用函数,最后将函数返回值压缩成一个数组,作为最终返回结果。这种一次处理一批数据的方式就是向量化计算。

函数的向量化求值
之所以要这么折腾一圈做列式存储、向量化求值,本质上还是因为批处理能够均摊掉控制逻辑的开销,并充分利用现代 CPU 中的缓存局部性和 SIMD 指令等特性,实现更高的访存和计算性能。
我们将上述函数求值过程抽象成一个 Rust trait,大概长这样:
pub trait ScalarFunction {/// Call the function on each row and return results as an array.fn eval(&self, input: &RecordBatch) -> Result<ArrayRef>;
}
在实际查询中,多个函数嵌套组合成一个表达式。例如表达式 a + b - c等价于 sub(add(a, b), c)。对表达式求值就相当于递归地对多个函数进行求值。这个表达式本身也可以看作一个函数,同样适用上面的 trait。因此本文中我们不区分表达式和标量函数。
2. 表达式执行的黑白魔法:类型体操 vs 代码生成
接下来我们讨论在 Rust 语言中如何具体实现表达式向量化求值。
2.1 我们要实现什么
回顾上一节中提到的求值过程,写成代码的整体结构是这样的:
// 首先定义好对每行数据的求值函数
fn add(a: i32, b: i32) -> i32 {a + b
}// 对于每一种函数,我们需要定义一个 struct
struct Add;// 并为之实现 ScalarFunction trait
impl ScalarFunction for Add {// 在此方法中实现向量化批处理fn eval(&self, input: &RecordBatch) -> Result<ArrayRef> {// 我们拿到一个 RecordBatch,里面包含了若干列,每一列对应一个输入参数// 此时我们拿到的列是 Arc<dyn Array>,也就是一个**类型擦除**的数组let a0: Arc<dyn Array> = input.columns(0);let a1: Arc<dyn Array> = input.columns(1);// 我们可以获取每一列的数据类型,并验证它符合函数的要求ensure!(a0.data_type() == DataType::Int32);ensure!(a1.data_type() == DataType::Int32);// 然后将它们 downcast 到具体的数组类型let a0: &Int32Array = a0.as_any().downcast_ref().context("type mismatch")?;let a1: &Int32Array = a1.as_any().downcast_ref().context("type mismatch")?;// 在求值前,我们还需要准备好一个 array builder 存储返回值let mut builder = Int32Builder::with_capacity(input.num_rows());// 此时我们就可以通过 .iter() 来遍历具体的元素了for (v0, v1) in a0.iter().zip(a1.iter()) {// 这里我们拿到的 v0 和 v1 是 Option<i32> 类型// 对于 add 函数来说let res = match (v0, v1) {// 只有当所有输入都非空时,函数才会被计算(Some(v0), Some(v1)) => Some(add(v0, v1)),// 而任何一个输入为空会导致输出也为空_ => None,};// 最后将结果存入 array builderbuilder.append_option(res);}// 返回结果 arrayOk(Arc::new(builder.finish()))}
}
我们发现,这个函数本体的逻辑只需要短短一个 fn 就可以描述:
fn add(a: i32, b: i32) -> i32 {a + b
}
然而,为了支持在列存上进行向量化计算,还需要实现后面这一大段样板代码来处理琐碎逻辑。有什么办法能自动生成这坨代码呢?
2.2 类型体操
著名数据库专家迟先生曾在博文「数据库表达式执行的黑魔法:用 Rust 做类型体操」中讨论了各种可能的解决方法,包括:
- 基于 trait 的泛型
- 声明宏
- 过程宏
- 外部代码生成器
并且系统性地阐述了它们的关系和工程实现中的利弊:

从方法论的角度来讲,一旦开发者在某个需要使用泛型的地方使用了宏展开,调用它的代码就不可能再通过 trait-based generics 使用这段代码。从这个角度来说,越是“大道至简”的生成代码,越难维护。但反过来说,如果要完全实现 trait-based generics,往往要和编译器斗智斗勇,就算是通过编译也需要花掉大量的时间。
我们首先来看基于 trait 泛型的解决方案。在 arrow-rs 中有一个名为 binary 的 kernel 就是做这个的:给定一个二元标量函数,将其应用于两个 array 进行向量化计算,并生成一个新的 array。它的函数签名如下:
pub fn binary<A, B, F, O>(a: &PrimitiveArray<A>,b: &PrimitiveArray<B>,op: F
) -> Result<PrimitiveArray<O>, ArrowError>
whereA: ArrowPrimitiveType,B: ArrowPrimitiveType,O: ArrowPrimitiveType,F: Fn(<A as ArrowPrimitiveType>::Native, <B as ArrowPrimitiveType>::Native) -> <O as ArrowPrimitiveType>::Native,
相信你已经开始感受到「类型体操」的味道了。尽管如此,它依然有以下这些局限:
- 支持的类型仅限于
PrimitiveArray,也就是 int, float, decimal 等基础类型。对于复杂类型,如 bytes, string, list, struct,因为没有统一到一个 trait 下,所以每种都需要一个新的函数。 - 仅适用于两个参数的函数。对于一个或更多参数,每一种都需要这样一个函数。arrow-rs 中也只内置了
unary和binary两种 kernel。 - 仅适用于一种标量函数签名,即不出错的、不接受空值的函数。考虑其它各种可能的情况下,需要有不同的
F定义:
fn add(i32, i32) -> i32;
fn checked_add(i32, i32) -> Result<i32>;
fn optional_add(i32, Option<i32>) -> Option<i32>;如果考虑以上三种因素的结合,那么可能的组合无穷尽也,不可能覆盖所有的函数类型。
2.3 类型体操 + 声明宏
在文章《类型体操》及 RisingWave 的初版实现中,作者使用 泛型 + 声明宏 的方法部分解决了以上问题:

- 首先设计一套精妙的类型系统,将全部类型统一到一个 trait 下,解决了第一个问题。
- 然后,使用声明宏来生成多种类型的 kernel 函数。覆盖常见的 1、2、3 个参数,以及
T和Option的输入输出组合。生成了常用的unarybinaryternaryunary_nullableunary_bytes等 kernel,部分解决了第二三个问题。(具体实现参见 RisingWave 早期代码) 当然,这里理论上也可以继续使用类型体操。例如,引入 trait 统一(A,) (A, B) (A, B, C),用Into, AsReftrait 统一T, Option<T>, Result<T>等。只不过,大概率迎接我们的是 rustc 带来的一点小小的类型震撼:) - 最后,这些 kernel 没有解决类型动态 downcast 的问题。为此,作者又利用声明宏设计了一套精妙的宏套宏机制来实现动态派发。
macro_rules! for_all_cmp_combinations {($macro:tt $(, $x:tt)*) => {$macro! {[$($x),*],// comparison across integer types{ int16, int32, int32 },{ int32, int16, int32 },{ int16, int64, int64 },// ...尽管解决了一些问题,但这套方案依然有它的痛点:
- 基于 trait 做类型体操使我们不可避免地陷入到与 Rust 编译器斗智斗勇之中。
- 依然没有全面覆盖所有可能情况。有相当一部分函数仍然需要开发者手写向量化实现。
- 性能。当我们需要引入 SIMD 对部分函数进行优化时,需要重新实现一套 kernel 函数。
- 没有对开发者隐藏全部细节。函数开发者依然需要先熟悉类型体操和声明宏的工作原理,才能比较流畅地添加函数。
究其原因,我认为是函数的变体形式过于复杂,而 Rust 的 trait 和声明宏系统的灵活性不足导致的。本质上是一种元编程能力不够强大的表现。
2.4 元编程?
让我们来看看其他语言和框架是怎么解决这个问题的。
首先是 Python,一种灵活的动态类型语言。这是 Flink 中的 Python UDF 接口,其它大数据系统的接口也大同小异:
@udf(result_type='BIGINT')
def add(i, j):return i + j
我们发现它是用 @udf 这个装饰器标记了函数的签名信息,然后在运行时对不同类型进行相应的处理。当然,由于它本身是动态类型,因此 Rust 中的很多问题在 Python 中根本不存在,代价则是性能损失。
接下来是 Java,它是一种静态类型语言,但通过虚拟机 JIT 运行。这是 Flink 中的 Java UDF 接口:
public static class SubstringFunction extends ScalarFunction {public String eval(String s, Integer begin, Integer end) {return s.substring(begin, end);}
}
可以看到同样也很短。这次甚至不需要额外标记类型了,因为静态类型系统本身就包含了类型信息。我们可以通过运行时反射拿到类型信息,并通过 JIT 机制在运行时生成高效的强类型代码,兼具灵活与性能。
最后是 Zig,一种新时代的 C 语言。它最大的特色是任何代码都可以加上 comptime 关键字在编译时运行,因此具备非常强的元编程能力。tygg 在博文「Zig lang 初体验 -- 『大道至简』的 comptime」中演示了用 Zig 实现迟先生类型体操的方法:通过 编译期反射 和 过程式的代码生成 来代替开发者完成类型体操。
用一张表总结一下:
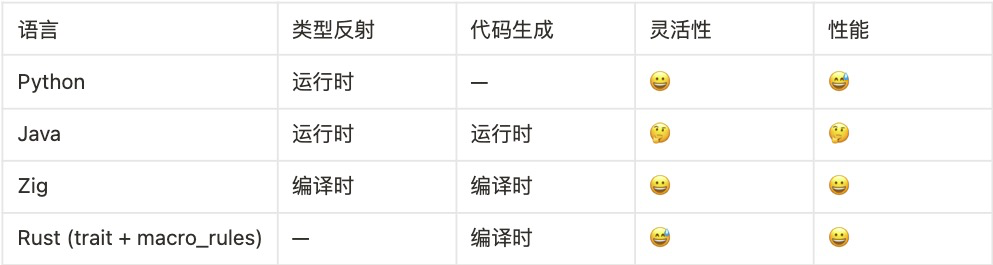
可以发现,Zig 语言强大的元编程能力提供了相对最好的解决方案。
2.5 过程宏
那么 Rust 里面有没有类似 Zig 的特性呢。其实是有的,那就是过程宏(Procedural Macros)。它可以在编译期动态执行任何 Rust 代码来修改 Rust 程序本身。只不过,它的编译时和运行时代码是物理分开的,相比 Zig 的体验没有那么统一,但是效果几乎一样。
参考 Python UDF 的接口设计,我们便得到了 ”大道至简“ 的 Rust 函数接口:
#[function("add(int, int) -> int")]
fn add(a: i32, b: i32) -> i32 {a + b
}
从用户的角度看,他只需要在自己熟悉的 Rust 函数上面标一个函数签名。其它的类型体操和代码生成操作都被隐藏在过程宏之后,完全无需关心。
此时我们已经拿到了一个函数所必须的全部信息,接下来我们将看到过程宏如何生成向量化执行所需的样板代码。
3. 展开 #[function]
3.1 解析函数签名
首先我们要实现类型反射,也就是分别解析 SQL 函数和 Rust 函数的签名,以此决定后面如何生成代码。在过程宏入口处我们会拿到两个 TokenStream,分别包含了标注信息和函数本体:
#[proc_macro_attribute]
pub fn function(attr: TokenStream, item: TokenStream) -> TokenStream {// attr: "add(int, int) -> int"// item: fn add(a: i32, b: i32) -> i32 { a + b }...
}
我们使用 syn 库将 TokenStream 转为 AST,然后:
- 解析 SQL 函数签名字符串,获取函数名、输入输出类型等信息。
- 解析 Rust 函数签名,获取函数名、每个参数和返回值的类型模式、是否 async 等信息。
具体地:
- 对于参数类型,我们确定它是
T或者Option<T>。 - 对于返回值类型,我们将其识别为:
T,Option<T>,Result<T>,Result<Option<T>>四种类型之一。
这将决定我们后面如何调用函数以及处理错误。
3.2 定义类型表
作为 trait 类型体操的代替方案,我们在过程宏中定义了这样一张类型表,来描述类型系统之间的对应关系,并且提供了相应的查询函数。
// name primitive array prefix data type
const TYPE_MATRIX: &str = "void _ Null Nullboolean _ Boolean Booleansmallint y Int16 Int16int y Int32 Int32bigint y Int64 Int64real y Float32 Float32float y Float64 Float64...varchar _ String Utf8bytea _ Binary Binaryarray _ List Liststruct _ Struct Struct
";
比如当我们拿到用户的函数签名后,
#[function("length(varchar) -> int")]
查表即可得知:
- 第一个参数
varchar对应的 array 类型为StringArray - 返回值
int对应的数据类型为DataType::Int32,对应的 Builder 类型为Int32Builder - 并非所有输入输出均为 primitive 类型,因此无法进行 SIMD 优化
在下面的代码生成中,这些类型将被填入到对应的位置。
3.3 生成求值代码
在代码生成阶段,我们主要使用 quote 库来生成并组合代码片段。最终生成的代码整体结构如下:
quote! {struct #struct_name;impl ScalarFunction for #struct_name {fn eval(&self, input: &RecordBatch) -> Result<ArrayRef> {#downcast_arrayslet mut builder = #builder;#evalOk(Arc::new(builder.finish()))}}
}
下面我们来逐个填写代码片段,首先是 downcast 输入 array:
let children_indices = (0..self.args.len());
let arrays = children_indices.map(|i| format_ident!("a{i}"));
let arg_arrays = children_indices.map(|i| format_ident!("{}", types::array_type(&self.args[*i])));let downcast_arrays = quote! {#(let #arrays: &#arg_arrays = input.column(#children_indices).as_any().downcast_ref().ok_or_else(|| ArrowError::CastError(...))?;)*
};
builder:
let builder_type = format_ident!("{}", types::array_builder_type(ty));
let builder = quote! { #builder_type::with_capacity(input.num_rows()) };
接下来是最关键的执行部分,我们先写出函数调用的那一行:
let inputs = children_indices.map(|i| format_ident!("i{i}"));
let output = quote! { #user_fn_name(#(#inputs,)*) };
// example: add(i0, i1)
然后考虑:这个表达式返回了什么类型呢?这需要根据 Rust 函数签名决定,它可能包含 Option,也可能包含 Result。我们进行错误处理,然后将其归一化到 Option<T> 类型:
let output = match user_fn.return_type_kind {T => quote! { Some(#output) },Option => quote! { #output },Result => quote! { Some(#output?) },ResultOption => quote! { #output? },
};
// example: Some(add(i0, i1))
下面考虑:这个函数接收什么样的类型作为输入?这同样需要根据 Rust 函数签名决定,每个参数可能是或不是 Option。如果函数不接受 Option 输入,但实际输入的却是 null,那么我们默认它的返回值就是 null,此时无需调用函数。因此,我们使用 match 语句来对输入参数做预处理:
let some_inputs = inputs.iter().zip(user_fn.arg_is_option.iter()).map(|(input, opt)| {if *opt {quote! { #input }} else {quote! { Some(#input) }}});
let output = quote! {// 这里的 inputs 是从 array 中拿出来的 Option<T>match (#(#inputs,)*) {// 我们将部分参数 unwrap 后再喂给函数(#(#some_inputs,)*) => #output,// 如有 unwrap 失败则直接返回 null_ => None,}
};
// example:
// match (i0, i1) {
// (Some(i0), Some(i1)) => Some(add(i0, i1)),
// _ => None,
// }
此时我们已经拿到了一行的返回值,可以将它 append 到 builder 中:
let append_output = quote! { builder.append_option(#output); };
最后在外面套一层循环,对输入逐行操作:
let eval = quote! {for (i, (#(#inputs,)*)) in multizip((#(#arrays.iter(),)*)).enumerate() {#append_output}
};
如果一切顺利的话,过程宏展开生成的代码将如 2.1 节中所示的那样。
3.4 函数注册
到此为止我们已经完成了最核心、最困难的部分,即生成向量化求值代码。但是,用户该怎么使用生成的代码呢?
注意到一开始我们生成了一个 struct。因此,我们可以允许用户指定这个 struct 的名称,或者定义一套规范自动生成唯一的名称。这样用户就能在这个 struct 上调用函数了。
// 指定生成名为 Add 的 struct
#[function("add(int, int) -> int", output = "Add")]
fn add(a: i32, b: i32) -> i32 {a + b
}// 调用生成的向量化求值函数
let input: RecordBatch = ...;
let output: RecordBatch = Add.eval(&input).unwrap();
不过在实际场景中,很少有这种使用特定函数的需求。更多是在项目中定义很多函数,然后在解析 SQL 查询时,动态地查找匹配的函数。为此我们需要一种全局的函数注册和查找机制。
问题来了:Rust 本身没有反射机制,如何在运行时获取所有由 #[function] 静态定义的函数呢?
答案是:利用程序的链接时(link time)特性,将函数指针等元信息放入特定的 section 中。程序链接时,链接器(linker)会自动收集分布在各处的符号(symbol)集中在一起。程序运行时即可扫描这个 section 获取全部函数了。
Rust 社区的 dtolnay 大佬为此需求做了两个开箱即用的库:linkme 和 inventory。其中前者是直接利用上述机制,后者是利用 C 标准的 constructor 初始化函数,但背后的原理没有本质区别。下面我们以 linkme 为例来演示如何实现注册机制。
首先我们需要在公共库(而不是 proc-macro)中定义函数签名的结构:
pub struct FunctionSignature {pub name: String,pub arg_types: Vec<DataType>,pub return_type: DataType,pub function: Box<dyn ScalarFunction>,
}
然后定义一个全局变量 REGISTRY 作为注册中心。它会在第一次被访问时利用 linkme 将所有 #[function] 定义的函数收集到一个 HashMap 中:
/// A collection of distributed `#[function]` signatures.
#[linkme::distributed_slice]
pub static SIGNATURES: [fn() -> FunctionSignature];lazy_static::lazy_static! {/// Global function registry.pub static ref REGISTRY: FunctionRegistry = {let mut signatures = HashMap::<String, Vec<FunctionSignature>>::new();for sig in SIGNATURES {let sig = sig();signatures.entry(sig.name.clone()).or_default().push(sig);}FunctionRegistry { signatures }};
}
最后在 #[function] 过程宏中,我们为每个函数生成如下代码:
#[linkme::distributed_slice(SIGNATURES)]
fn #sig_name() -> FunctionSignature {FunctionSignature {name: #name.into(),arg_types: vec![#(#args),*],return_type: #ret,// 这里 #struct_name 就是我们之前生成的函数结构体function: Box::new(#struct_name),}
}
如此一来,用户就可以通过 FunctionRegistry 提供的方法动态查找函数并进行求值了:
let gcd = REGISTRY.get("gcd", &[Int32, Int32], &Int32);
let output: RecordBatch = gcd.function.eval(&input).unwrap();
3.5 小结
以上我们完整阐述了 #[function] 过程宏的工作原理和实现过程:
- 使用
syn库解析函数签名 - 使用
quote库生成定制化的向量化求值代码 - 使用
linkme库实现函数的全局注册和动态查找
其中:
- SQL 签名决定了如何从 input array 中读取数据,如何生成 output array
- Rust 签名决定了如何调用用户的 Rust 函数,如何处理空值和错误
- 类型查找表决定了 SQL 类型和 Rust 类型的映射关系
相比 trait + 声明宏的解决方案,过程宏中的 “过程式” 风格为我们提供了极大的灵活性,一揽子解决了之前提到的全部问题。在下一章中,我们将会在这个框架的基础上继续扩展,解决更多实际场景下的复杂需求。
44. 高级功能
抽象的问题是简单的,但现实的需求是复杂的。上面的原型看似解决了所有问题,但在 RisingWave 的实际工程开发中,我们遇到了各种稀奇古怪的需求,都无法用最原始的 #[function] 宏实现。下面我们来逐一介绍这些问题,并利用过程宏的灵活性见招拆招。
4.1 支持多类型重载
有些函数支持大量不同类型的重载,例如 + 运算对几乎支持所有数字类型。此时我们一般会复用同一个泛型函数,然后用不同的类型去实例化它。
#[function("add(*int, *int) -> auto")]
#[function("add(*float, *float) -> auto")]
#[function("add(decimal, decimal) -> decimal")]
#[function("add(interval, interval) -> interval")]
fn add<T1, T2, T3>(l: T1, r: T2) -> Result<T3>
whereT1: Into<T3> + Debug,T2: Into<T3> + Debug,T3: CheckedAdd<Output = T3>,
{a.into().checked_add(b.into()).ok_or(ExprError::NumericOutOfRange)
}
因此我们支持在同一个函数上同时标记多个#[function] 宏。此外,我们还支持使用类型通配符将一个#[function] 自动展开成多个,并使用 auto 自动推断返回类型。例如 *int 通配符表示全部整数类型 int2, int4, int8,那么 add(*int, *int) 将展开为 3 x 3 = 9 种整数的组合,返回值自动推断为两种类型中最大的一个:
#[function("add(int2, int2) -> int2")]
#[function("add(int2, int4) -> int4")]
#[function("add(int2, int8) -> int8")]
#[function("add(int4, int4) -> int4")]
...
而如果泛型不能满足一些特殊类型的要求,你也完全可以定义新函数进行特化(specialization):
#[function("add(interval, timestamp) -> timestamp")]
fn interval_timestamp_add(l: Interval, r: Timestamp) -> Result<Timestamp> {r.checked_add(l).ok_or(ExprError::NumericOutOfRange)
}
这一特性帮助我们快速实现函数重载,同时避免了冗余代码。
4.2 自动 SIMD 优化
作为零开销抽象语言,Rust 从不向性能妥协,#[function] 宏也是如此。对于很多简单函数,理论上可以利用 CPU 内置的 SIMD 指令实现上百倍的性能提升。然而,编译器往往只能对简单的循环结构实现自动 SIMD 向量化。一旦循环中出现分支跳转等复杂结构,自动向量化就会失效。
// 简单循环支持自动向量化
assert_eq!(a.len(), n);
assert_eq!(b.len(), n);
assert_eq!(c.len(), n);
for i in 0..n {c[i] = a[i] + b[i];
}// 一旦出现分支结构,如错误处理、越界检查等,自动向量化就会失效
for i in 0..n {c.push(a[i].checked_add(b[i])?);
}
不幸的是,我们前文中生成的代码结构并不利于编译器进行自动向量化,因为循环中的 builder.append_option() 操作本身就自带条件分支。
为了支持自动向量化,我们需要对代码生成逻辑进一步特化:
- 首先根据函数签名判断这个函数能否实现 SIMD 优化。这需要满足以下两个主要条件:
- 所有输入输出类型均为基础类型,即 boolean, int, float, decimal
- Rust 函数的输入类型均不含
Option,输出不含Option和Result
#[function("equal(int, int) -> boolean")]
fn equal(a: i32, b: i32) -> bool {a == b
}
- 一旦上述条件满足,我们会对
#eval代码段进行特化,将其替换为这样的代码,调用 arrow-rs 内置的unary和binarykernel 实现自动向量化:
// SIMD optimization for primitive types
match self.args.len() {0 => quote! {let c = #ret_array_type::from_iter_values(std::iter::repeat_with(|| #user_fn_name()).take(input.num_rows()));let array = Arc::new(c);},1 => quote! {let c: #ret_array_type = arrow_arith::arity::unary(a0, #user_fn_name);let array = Arc::new(c);},2 => quote! {let c: #ret_array_type = arrow_arith::arity::binary(a0, a1, #user_fn_name)?;let array = Arc::new(c);},n => todo!("SIMD optimization for {n} arguments"),
}需要注意,如果用户函数本身包含分支结构,那么自动向量化也是无效的。我们只是尽力为编译器创造了实现优化的条件。另一方面,这一优化也不是完全安全的,它会使得原本为 null 的输入强制执行。例如整数除法 a / b,如果 b 为 null,原本不会执行,现在却会执行 a / 0,导致除零异常而崩溃。这种情况下我们只能修改函数签名,避免生成特化代码。
整体而言,实现这一功能后,用户编写代码不需要有任何变化,但是部分函数的性能得到了大幅提高。这对于高性能数据处理系统而言是必须的。
4.3 返回字符串直接写入 buffer
很多函数会返回字符串。但是朴素地返回 String 会导致大量动态内存分配,降低性能。
#[function("concat(varchar, varchar) -> varchar")]
fn concat(left: &str, right: &str) -> String {format!("{left}{right}")
}
注意到列式内存存储中,StringArray 实际上是把多个字符串存放在一段连续的内存上,构建这个数组的 StringBuilder 实际上也只是将字符串追加写入同一个 buffer 里。因此函数返回 String 是没有必要的,它可以直接将字符串写入 StringBuilder 的 buffer 中。
于是我们支持对返回字符串的函数添加一个 &mut Write 类型的 writer 参数。内部可以直接用 write! 方法向 writer 写入返回值。
#[function("concat(varchar, varchar) -> varchar")]
fn concat(left: &str, right: &str, writer: &mut impl std::fmt::Write) {writer.write_str(left).unwrap();writer.write_str(right).unwrap();
}
在过程宏的实现中,我们主要修改了函数调用部分:
let writer = user_fn.write.then(|| quote! { &mut builder, });
let output = quote! { #user_fn_name(#(#inputs,)* #writer) };
以及特化 append_output 的逻辑:
let append_output = if user_fn.write {quote! {{if #output.is_some() { // 返回值直接在这行写入 builderbuilder.append_value("");} else {builder.append_null();}}}
} else {quote! { builder.append_option(#output); }
};
经过测试,这一功能也可以大幅提升字符串处理函数的性能。
4.4 常量预处理优化
有些函数的某个参数往往是一个常量,并且这个常量需要经过一个开销较大的预处理过程。这类函数的典型代表是正则表达式匹配:
// regexp_like(source, pattern)
#[function("regexp_like(varchar, varchar) -> boolean")]
fn regexp_like(text: &str, pattern: &str) -> Result<bool> {let regex = regex::Regex::new(pattern)?; // 预处理:编译正则表达式Ok(regex.is_match(text))
}
对于一次向量化求值来说,如果输入的 pattern 是常数(very likely),那么其实只需要编译一次,然后用编译后的数据结构对每一行文本进行匹配即可。但如果不是常数(unlikely,但是合法行为),则需要对每一行 pattern 编译一次再执行。
为了支持这一需求,我们修改用户接口,将特定参数的预处理过程提取到过程宏中,然后把预处理后的类型作为参数:
#[function("regexp_like(varchar, varchar) -> boolean",prebuild = "Regex::new($1)?" // $1 表示第一个参数(下标从0开始)
)]
fn regexp_like(text: &str, regex: &Regex) -> bool {regex.is_match(text)
}
这样,过程宏可以对这个函数生成两个版本的代码:
- 如果指定参数为常量,那么在构造函数中执行
prebuild代码,并将生成的Regex中间值存放在 struct 当中,在求值阶段直接传入函数。 - 如果不是常量,那么在求值阶段将
prebuild代码嵌入到函数参数的位置上。
至于具体的代码生成逻辑,由于细节相当复杂,这里就不再展开介绍了。
总之,这一优化保证了此类函数各种输入下都具有最优性能,并且极大简化了手工实现的复杂性。
4.5 表函数
最后,我们来看表函数(Table Function,Postgres 中也称 Set-returning Funcion,返回集合的函数)。这类函数的返回值不再是一行,而是多行。如果同时返回多列,那么就相当于返回一个表。
select * from generate_series(1, 3);generate_series
-----------------123
对应到常见的编程语言中,实际是一个生成器函数(Generator)。以 Python 为例,可以写成这样:
def generate_series(start, end):for i in range(start, end + 1):yield i
Rust 语言目前在 nightly 版本支持生成器,但这一特性尚未 stable。不过如果不用 yield 语法的话,我们可以利用 RPIT 特性实现返回迭代器的函数,以达到同样的效果:
#[function("generate_series(int, int) -> setof int")]
fn generate_series(start: i32, stop: i32) -> impl Iterator<Item = i32> {start..=stop
}
我们支持在 #[function] 签名中使用 -> setof 以声明一个表函数。它修饰的 Rust 函数必须返回一个 impl Iterator,其中的 Item 需要匹配返回类型。当然,Iterator 的内外都可以包含 Option 或 Result。
在对表函数进行向量化求值时,我们会对每一行输入调用生成器函数,然后将每一行返回的多行结果串联起来,最后按照固定的 chunk size 进行切割,依次返回多个 RecordBatch。因此表函数的向量化接口长这个样子:
pub trait TableFunction {fn eval(&self, input: &RecordBatch, chunk_size: usize) -> Result<Box<dyn Iterator<Item = Result<RecordBatch>>>>;
}
我们给出一组 generate_series 的输入输出样例(假设 chunk size = 2):
input output
+-------+------+ +-----+-----------------+
| start | stop | | row | generate_series |
+-------+------+ +-----+-----------------+
| 0 | 0 |---->| 0 | 0 |
| | | +->| 2 | 0 |
| 0 | 2 |--+ +-----+-----------------+
+-------+------+ | 2 | 1 || 2 | 2 |+-----+-----------------+
由于表函数的输入输出不再具有一对一的关系,我们在 output 中会额外生成一列 row 来表示每一行输出对应 input 中的哪一行输入。这一关系信息会在某些 SQL 查询中被使用到。
回到 #[function] 宏的实现,它为表函数生成的代码实际上也是一个生成器。我们在内部使用了 futures_async_stream 提供的 #[try_stream] 宏实现 async generator(它依赖 nightly 的 generator 特性),在 stable 版本中则使用 genawaiter 代替。之所以要使用生成器,则是因为一个表函数可能会生成非常长的结果(例如 generate_series(0, 1000000000)),中途必须把控制权交还调用者,才能保证系统不被卡死。感兴趣的读者可以思考一下:如果没有 generator 机制,高效的向量化表函数求值能否实现?如何实现?
说到这里,多扯两句。genawaiter 也是个很有意思的库,它使用 async-await 机制来在 stable Rust 中实现 generator。我们知道 async-await 本质上也是一种 generator,它们都依赖编译器的 CPS 变换实现状态机。不过出于对异步编程的强烈需求,async-await 很早就被稳定化,而 generator 却迟迟没有稳定。由于背后的原理相通,它们可以互相实现。 此外,目前 Rust 社区正在积极推动 async generator 的进展,原生的[async gen](https://github.com/rust-lang/rust/pull/118420)和[for await](https://github.com/rust-lang/rust/pull/118847)语法刚刚在上个月进入 nightly。不过由于没有和 futures 生态对接,整体依然处于不可用状态。RisingWave 的流处理引擎就深度依赖 async generator 机制实现流算子,以简化异步 IO 下的流状态管理。不过这又是一个庞大的话题,之后有机会再来介绍这方面的应用吧。
5. 总结
由于篇幅所限,我们只能展开这么多了。如你所见,一个简单的函数求值背后,隐藏着非常多的设计和实现细节:
- 为了高性能,我们选择列式内存存储和向量化求值。
- 存储数据的容器通常是类型擦除的结构。但 Rust 是一门静态类型语言,用户定义的函数是强类型的签名。这意味着我们需要在编译期确定每一个容器的具体类型,做类型体操来处理不同类型之间的转换,准确地把数据从容器中取出来喂给函数,最后高效地将函数吐出来的结果打包回数据容器中。
- 为了将上述过程隐藏起来,我们设计了
#[function]过程宏在编译期做类型反射和代码生成,最终暴露给用户一个尽可能简单直观的接口。 - 但是实际工程中存在各种复杂需求以及对性能的要求,我们必须持续在接口上打洞,并对代码生成逻辑进行特化。幸好,过程宏具有非常强的灵活性,使得我们可以敏捷地应对变化的需求。
#[function] 宏最初是为 RisingWave 内部函数实现的一套框架。最近,我们将它从 RisingWave 项目中独立出来,基于 Apache Arrow 标准化成一套通用的用户定义函数接口 arrow-udf。如果你的项目也在使用 arrow-rs 进行数据处理,现在可以直接使用这套 #[function] 宏定义自己的函数。如果你在使用 RisingWave,那么从这个月底发布的 1.7 版本起,你可以使用这个库来定义 Rust UDF。它可以编译成 WebAssembly 模块插入到 RisingWave 中运行。感兴趣的读者也可以阅读这个项目的源码了解更多实现细节。
事实上,RisingWave 基于 Apache Arrow 构建了一整套用户定义函数接口。此前,我们已经实现了服务器模式的 Python 和 Java UDF。最近,我们又基于 WebAssembly 实现了 Rust UDF,基于 QuickJS 实现了 JavaScript UDF。它们都可以嵌入到 RisingWave 中运行,以实现更好的性能和用户体验。在下一篇文章中,我们将系统介绍 RisingWave UDF 的设计与实现。敬请期待!
RisingWave 是一款基于 Apache 2.0 协议开源的分布式流数据库,致力于为用户提供极致简单、高效的流数据处理与管理能力。RisingWave 采用存算分离架构,实现了高效的复杂查询、瞬时动态扩缩容以及快速故障恢复,并助力用户极大地简化流计算架构,轻松搭建稳定且高效的流计算应用。RisingWave 始终聆听来自社区的声音,并积极回应用户的反馈。目前,RisingWave 已汇聚了近 150 名开源贡献者和近 3000 名社区成员。全球范围内,已有上百个 RisingWave 集群在生产环境中部署。
了解更多:
官网: risingwave.com
教程:risingwavetutorial.com
GitHub:risingwave.com/github
微信公众号:RisingWave中文开源社区
社区用户交流群:risingwave_assistant
相关文章:
用 Rust 过程宏魔法简化 SQL 函数实现
#[function("length(varchar) -> int4")] pub fn char_length(s: &str) -> i32 {s.chars().count() as i32 }这是 RisingWave 中一个 SQL 函数的实现。只需短短几行代码,通过在 Rust 函数上加一行过程宏,我们就把它包装成了一个 SQL…...

OpenSource - 基于 DFA 算法实现的高性能 java 敏感词过滤工具框架
文章目录 sensitive-word创作目的特性变更日志更多资料敏感词控台敏感词标签文件 快速开始准备Maven 引入核心方法判断是否包含敏感词返回第一个敏感词返回所有敏感词默认的替换策略指定替换的内容自定义替换策略 IWordResultHandler 结果处理类使用实例 更多特性样式处理忽略大…...

端杂七杂八系列篇四-Java8篇
后端杂七杂八系列篇四-Java8篇 ① Lombok插件① RequiredArgsConstructor② SneakyThrows③ UtilityClass④ Cleanup ② Lambda 4个常用的内置函数① Function<T, R> - 接受一个输入参数并返回一个结果② Consumer - 接受一个输入参数,并执行某种操作…...

操作系统一些面试
你这个请求队列是属于一写多读对吧,怎么解决冲突的? 可以采用双buffer或者说双缓冲区,一个缓冲区用来写,一个缓冲区用来读,采用交换指针的方法来进行缓存区的交换,这样交换效率是O(1)的,但是交…...
大语言模型
概念 大语言模型(Large Language Model,简称LLM)是一种基于人工智能技术的自然语言处理模型,是指在大量数据上训练的高级人工智能算法,以自上文推理词语概率为核心任务。它通过在海量文本数据上进行训练,学…...
php反序列化之pop链构造(基于重庆橙子科技靶场)
常见魔术方法的触发 __construct() //创建类对象时调用 __destruct() //对象被销毁时触发 __call() //在对象中调用不可访问的方法时触发 __callStatic() //在静态方式中调用不可访问的方法时触发 __get() //调用类中不存在变量时触发(找有连续箭头的…...
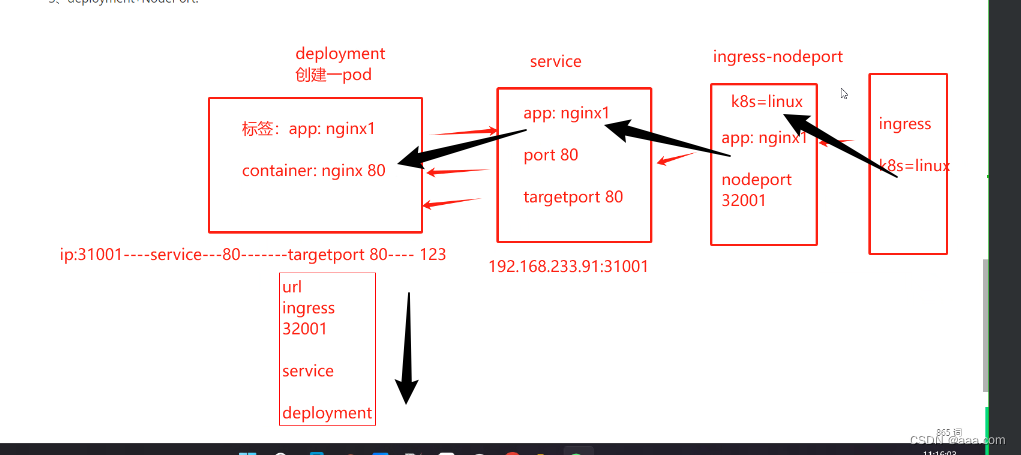
k8s---对外服务 ingress
目录 目录 目录 ingress与service ingress的组成 ingress-controller: ingress暴露服务的方式 2.方式二:DaemonSethostnetworknodeSelector DaemonSethostnetworknodeSelector如何实现 3.deploymentNodePort: 虚拟主机的方式实现http代…...
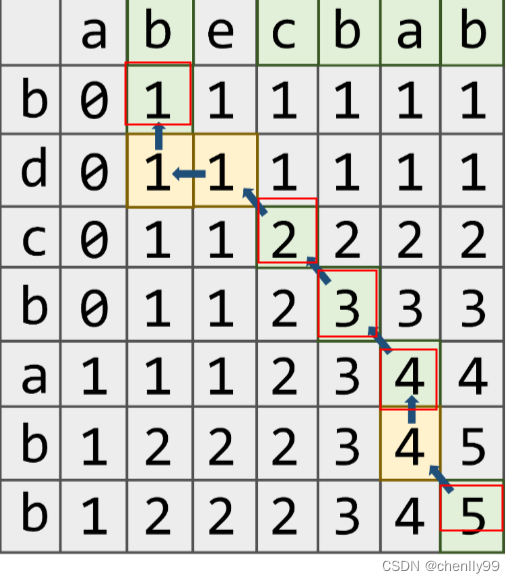
最优解-最长公共子序列
问题描述 最长公共子序列(Longest Common Subsequence,LCS)即求两个序列最长的公共子序列(可以不连续)。比如3 2 1 4 5和1 2 3 4 5两个序列,最长公共子序列为2 4 5 长度为3。解决这个问题必然要使用动态规划。既然要用到动态规划,就要知道状…...
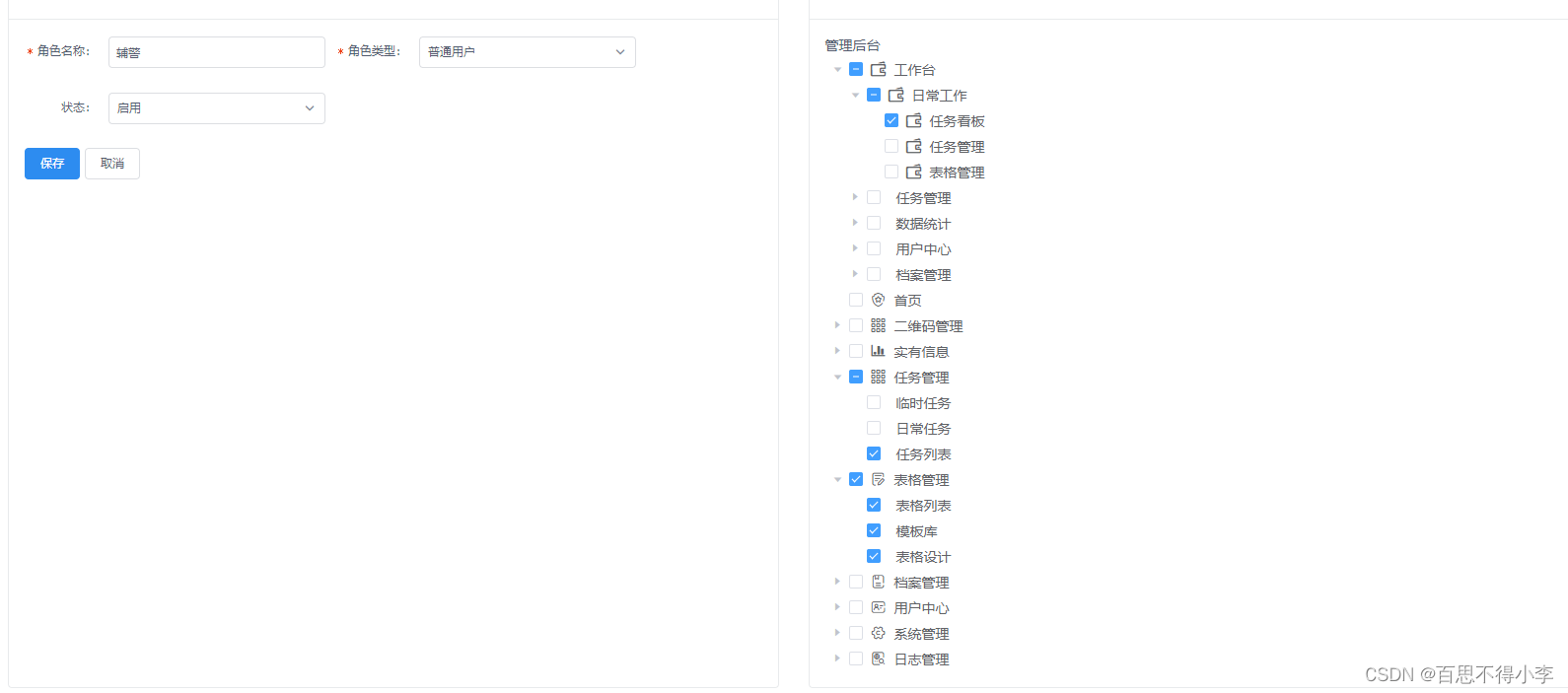
el-tree获取当前选中节点及其所有父节点的id(包含半选中父节点的id)
如下图,我们现在全勾中的有表格管理及其下的子级,而半勾中的有工作台和任务管理及其子级 现在点击保存按钮后,需要将勾中的节点id及该节点对应的父节点,祖先节点的id(包含半选中父节点的id)也都一并传给后端,那这个例子里就应该共传入9个id,我们可以直接将getCheckedK…...

新上线一个IT公司微信小程序
项目介绍 项目背景: 一家IT公司,业务包含以下六大块: 1、IT设备回收 2、IT设备租赁 3、IT设备销售 4、IT设备维修 5、IT外包 6、IT软件开发 通过小程序,提供在线下单,在线制单,在线销售,业务介绍,推广,会员 项目目的: 业务介绍: 包含企业业务介绍 客户需…...

MCAL配置-PWM(EB23.0)
PWM配置项的介绍 一、General 1、PwmDeInitApi 从代码中添加/删除Pwm_17_GtmCcu6_Delnit() API。 TRUE:Pwm_17_GtmCcu6_Delnit() API可供用户使用。 FALSE:Pwm_17_GtmCcu6_Delnit() API对用户不可用。 注意:默认情况下禁用Pwm_17_GtmCcu6_Delnit() …...
v-if和v-for哪个优先级更高?
v-if和v-for哪个优先级更高? 结论: vue2输出的渲染函数是先执行循环,在看条件判断,如果将v-if和v-for写在一个标签内,哪怕只渲染列表中的一小部分,也要重新遍历整个列表,无形造成资源浪费。vu…...
.)
Mapstruct 常用案例(持续更新.).
将A转换为B Mapper(componentModel "spring") public interface DemoConvert {B A2B(A a); }将List转换为List 注意:以下两个都不可缺少,需要先声明单个和集合的同时生命才可 Mapper(componentModel "spring") public interface …...
QT5网络与通信)
QT基础篇(10)QT5网络与通信
QT5网络与通信是指在QT5开发环境中使用网络进行数据传输和通信的相关功能和技术。 QT5提供了一套完善的网络模块,包括了TCP、UDP、HTTP等协议的支持,可以方便地在QT应用程序中进行网络通信。通过QT5的网络模块,开发者可以实现客户端和服务器…...
)
【Leetcode】269.火星词典(Hard)
一、题目 1、题目描述 现有一种使用英语字母的火星语言,这门语言的字母顺序与英语顺序不同。 给你一个字符串列表 words ,作为这门语言的词典,words 中的字符串已经 按这门新语言的字母顺序进行了排序 。 请你根据该词典还原出此语言中已知的字母顺序,并 按字母递增顺序…...

opencv_模型训练
文件夹 opencv训练文件 xml negdataposdata 说明 negdata目录: 放负样本的目录 posdata目录: 放正样本的目录 xml目录: 新建的一个目录,为之后存放分类器文件使用 neg.txt: 负样本路径列表 pos.txt: 正样本路径列表 pos.vec: 后续自动生成…...
python PyQt5的学习
一、安装与配置 1、环境: python3.7 2、相关模块 pip install pyqt5 pyqt5-tools pyqt5designer 可以加个镜像 -i https://pypi.tuna.tsinghua.edu.cn/simple3、配置设计器 python的pyqt5提供了一个设计器,便于ui的设计 界面是这样的:…...

3.goLand基础语法
目录 概述语法for常量与变量数组切片 slice切片问题问题1问题2 Make 和 New结构体和指针结构体标签 结束 概述 从 java 转来学 go ,在此记录,方便以后翻阅。 语法 for package mainimport "fmt"func main() {for i : 0; i < 3; i {fmt.…...
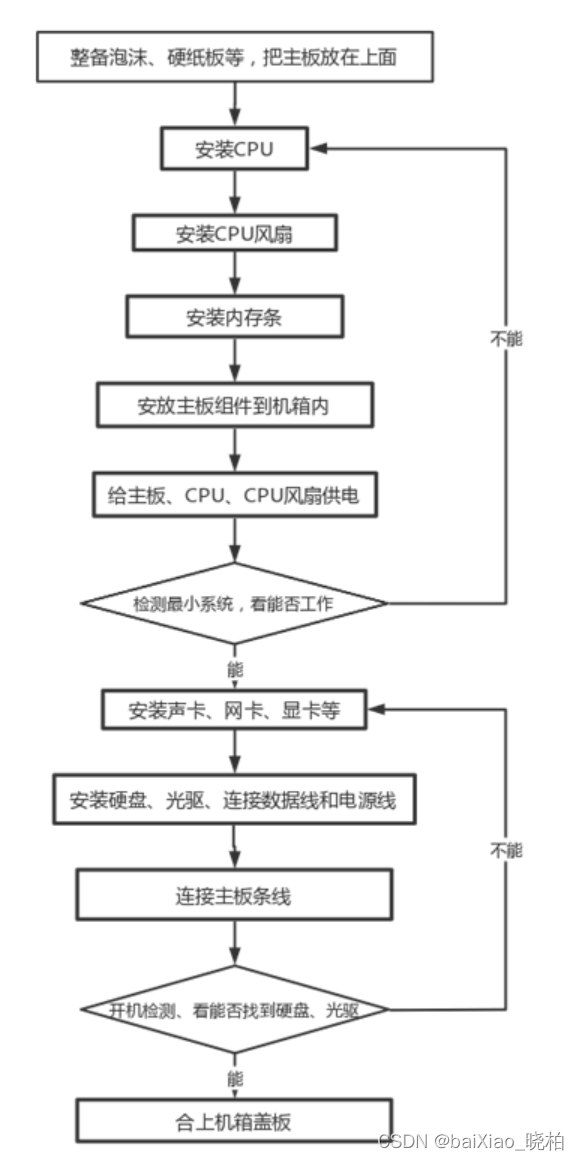
计算机硬件 5.2组装整机
第二节 组装整机 一、准备工作 1.常用工具:中号十字螺丝刀、尖嘴钳、软毛刷、防静电手环等。 2.组装原则: ①按“先小后大”“从里到外”的顺序进行,不遗漏每一环节,不“带病”进行下一环节。 ②合理使用工具器材,…...
Docker搭建MySQL主从数据库-亲测有效
1、测试环境概述 1、使用MySQL5.7.35版本 2、使用Centos7操作系统 3、使用Docker20版本 案例中描述了整个测试的详细过程 2、安装Docker 2.1、如果已经安装docker,可以先卸载 yum remove -y docker \ docker-client \ docker-client-latest \ docker-common \ docker-l…...

2026届学术党必备的十大AI学术方案实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek AI工具运用越来越广泛,然而随之出现的信息过多无法承受以及决策变得复杂的状况&…...

【MySQL百日打怪升级第8天】SELECT执行流程
【第8天】每天一个MySQL知识点,百日打怪升级 SQL基础:SELECT执行流程 大家好,我是一名拥有10年以上经验的DBA老兵。 做这个系列,源于一个朴素的愿望:把踩过的坑、总结的经验系统化输出,希望能帮到刚入行或…...

告别手动提交!用Bash脚本批量处理VASP+ShengBTE热输运计算的700+任务
计算材料学自动化革命:Bash脚本驱动的高通量热输运计算实践 在计算材料学领域,研究者常常需要处理数百甚至上千个相似的计算任务。以硅材料热输运性质计算为例,当使用VASP结合ShengBTE进行三阶力常数计算时,可能产生700多个独立的…...
)
【数字对调】信息学奥赛一本通C语言解法(题号2070)
自留or欢迎大佬纠错【题目描述】输入一个三位数,要求把这个数的百位数与个位数对调,输出对调后的数。【输入】三位数。【输出】如题述结果。【输入样例】123【输出样例】321#include<stdio.h> int main(){int a;scanf("%d",&a);int …...
)
Steam账号被盗,手机邮箱都失效?别慌!我用支付宝账单截图成功找回(附详细客服案件创建流程)
Steam账号终极找回指南:当手机邮箱全失效时的支付宝账单申诉法 凌晨三点,盯着屏幕上"未找到关联账户"的红色提示,手指在键盘上悬停了十分钟——这是许多Steam玩家遭遇账号全维度被盗时的真实噩梦。当盗号者不仅修改了密码…...

创业公司如何设计有效的OKR
创业公司如何设计有效的OKR 前言 创业第一年,我们没有明确的目标,大家都很忙,但不知道忙什么。每个人都在做事,但好像没有形成合力。 后来我开始研究 OKR(Objectives and Key Results),发现这不…...

ncmdumpGUI:专业音频解密工具实现网易云音乐跨平台播放自由
ncmdumpGUI:专业音频解密工具实现网易云音乐跨平台播放自由 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 在数字音乐时代,平台间的格…...

unrpa:当Ren‘Py游戏资源被锁定时,你的万能钥匙是什么?
unrpa:当RenPy游戏资源被锁定时,你的万能钥匙是什么? 【免费下载链接】unrpa A program to extract files from the RPA archive format. 项目地址: https://gitcode.com/gh_mirrors/un/unrpa 你是否曾面对一个RenPy游戏的RPA档案文件…...

微积分入门书籍之高考篇
导数的秘密(第二版)-2021.01 高考导数满分精讲(2021) 高考导数探秘:解题技巧与策略 董晟渤(2024.10) 微积分与高考数学(第2版)-2024 高考导数解题全攻略(2024…...

标签系统的底层同步拓扑:大批量客户标签异步更新的一致性方案
标签(Tag)是私域精细化运营的灵魂。在进行大规模广告投放、或者老客清洗时,企业系统经常需要同时为上万个外部客户批量追加或清空标签。 1. 标签同步的复杂性在哪里? 原生设计中,企业微信的标签是以“企业标签组&#…...