MySQL作业 (3)多表查询
多表查询
- 1.创建student和score表
- 2.为student表和score表增加记录
- 3.查询student表的所有记录
- 4.查询student表的第2条到4条记录
- 5.从student表查询所有学生的学号(id)、姓名(name)和院系(department)的信息
- 6.从student表中查询计算机系和英语系的学生的信息
- 7.从student表中查询年龄18~22岁的学生信息
- 8.从student表中查询每个院系有多少人
- 9.从score表中查询每个科目的最高分
- 10.查询李四的考试科目(c_name)和考试成绩(grade)
- 11.用连接的方式查询所有学生的信息和考试信息
- 12.计算每个学生的总成绩
- 13.计算每个考试科目的平均成绩
- 14.查询计算机成绩低于95的学生信息
- 15.查询同时参加计算机和英语考试的学生的信息
- 16.将计算机考试成绩按从高到低进行排序
- 17.从student表和score表中查询出学生的学号,然后合并查询结果
- 18.查询姓张或者姓王的同学的姓名、院系和考试科目及成绩
- 19.查询都是湖南的学生的姓名、年龄、院系和考试科目及成绩
1.创建student和score表
CREATE TABLE student (
id INT(10) NOT NULL UNIQUE PRIMARY KEY ,
name VARCHAR(20) NOT NULL ,
sex VARCHAR(4) ,
birth YEAR,
department VARCHAR(20) ,
address VARCHAR(50)
);
创建score表。SQL代码如下:
CREATE TABLE score (
id INT(10) NOT NULL UNIQUE PRIMARY KEY AUTO_INCREMENT ,
stu_id INT(10) NOT NULL ,
c_name VARCHAR(20) ,
grade INT(10)
);
mysql> create table student (-> id int(10) not null unique primary key,-> name varchar(20) not null,-> sex varchar(4),-> birth year,-> department varchar(20),-> address varchar(50)-> );
Query OK, 0 rows affected, 1 warning (0.01 sec)mysql> create table score (-> id int(10) not null unique primary key auto_increment,-> stu_id int(10) not null,-> c_name varchar(20),-> grade int(10)-> );
Query OK, 0 rows affected, 3 warnings (0.00 sec)mysql> show tables;
+---------------+
| Tables_in_cla |
+---------------+
| score |
| student |
+---------------+
2 rows in set (0.00 sec)2.为student表和score表增加记录
向student表插入记录的INSERT语句如下:
INSERT INTO student VALUES( 901,'张老大', '男',1985,'计算机系', '北京市海淀区');
INSERT INTO student VALUES( 902,'张老二', '男',1986,'中文系', '北京市昌平区');
INSERT INTO student VALUES( 903,'张三', '女',1990,'中文系', '湖南省永州市');
INSERT INTO student VALUES( 904,'李四', '男',1990,'英语系', '辽宁省阜新市');
INSERT INTO student VALUES( 905,'王五', '女',1991,'英语系', '福建省厦门市');
INSERT INTO student VALUES( 906,'王六', '男',1988,'计算机系', '湖南省衡阳市');
向score表插入记录的INSERT语句如下:
INSERT INTO score VALUES(NULL,901, '计算机',98);
INSERT INTO score VALUES(NULL,901, '英语', 80);
INSERT INTO score VALUES(NULL,902, '计算机',65);
INSERT INTO score VALUES(NULL,902, '中文',88);
INSERT INTO score VALUES(NULL,903, '中文',95);
INSERT INTO score VALUES(NULL,904, '计算机',70);
INSERT INTO score VALUES(NULL,904, '英语',92);
INSERT INTO score VALUES(NULL,905, '英语',94);
INSERT INTO score VALUES(NULL,906, '计算机',90);
INSERT INTO score VALUES(NULL,906, '英语',85);
mysql> INSERT INTO student VALUES( 902,'张老二', '男',1986,'中文系', '北京市昌平区');
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO student VALUES( 903,'张三', '女',1990,'中文系', '湖南省永州市');
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO student VALUES( 904,'李四', '男',1990,'英语系', '辽宁省阜新市');
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO student VALUES( 905,'王五', '女',1991,'英语系', '福建省厦门市');
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO student VALUES( 906,'王六', '男',1988,'计算机系', '湖南省衡阳市');
Query OK, 1 row affected (0.00 sec)mysql> select * from student;
+-----+-----------+------+-------+--------------+--------------------+
| id | name | sex | birth | department | address |
+-----+-----------+------+-------+--------------+--------------------+
| 901 | 张老大 | 男 | 1985 | 计算机系 | 北京市海淀区 |
| 902 | 张老二 | 男 | 1986 | 中文系 | 北京市昌平区 |
| 903 | 张三 | 女 | 1990 | 中文系 | 湖南省永州市 |
| 904 | 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 |
| 905 | 王五 | 女 | 1991 | 英语系 | 福建省厦门市 |
| 906 | 王六 | 男 | 1988 | 计算机系 | 湖南省衡阳市 |
+-----+-----------+------+-------+--------------+--------------------+
6 rows in set (0.00 sec)mysql> INSERT INTO score VALUES(NULL,901, '英语', 80);
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO score VALUES(NULL,902, '计算机',65);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO score VALUES(NULL,902, '中文',88);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO score VALUES(NULL,903, '中文',95);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO score VALUES(NULL,904, '计算机',70);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO score VALUES(NULL,904, '英语',92);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO score VALUES(NULL,905, '英语',94);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO score VALUES(NULL,906, '计算机',90);
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO score VALUES(NULL,906, '英语',85);
Query OK, 1 row affected (0.01 sec)mysql> select * from score;
+----+--------+-----------+-------+
| id | stu_id | c_name | grade |
+----+--------+-----------+-------+
| 1 | 901 | 计算机 | 98 |
| 2 | 901 | 英语 | 80 |
| 3 | 902 | 计算机 | 65 |
| 4 | 902 | 中文 | 88 |
| 5 | 903 | 中文 | 95 |
| 6 | 904 | 计算机 | 70 |
| 7 | 904 | 英语 | 92 |
| 8 | 905 | 英语 | 94 |
| 9 | 906 | 计算机 | 90 |
| 10 | 906 | 英语 | 85 |
+----+--------+-----------+-------+
10 rows in set (0.00 sec)3.查询student表的所有记录
mysql> select id, name, department from student;
+-----+-----------+--------------+
| id | name | department |
+-----+-----------+--------------+
| 901 | 张老大 | 计算机系 |
| 902 | 张老二 | 中文系 |
| 903 | 张三 | 中文系 |
| 904 | 李四 | 英语系 |
| 905 | 王五 | 英语系 |
| 906 | 王六 | 计算机系 |
+-----+-----------+--------------+
6 rows in set (0.00 sec)4.查询student表的第2条到4条记录
mysql> select * from student limit 2,4;
+-----+-----------+------+-------+--------------+--------------------+
| id | name | sex | birth | department | address |
+-----+-----------+------+-------+--------------+--------------------+
| 903 | 张三 | 女 | 1990 | 中文系 | 湖南省永州市 |
| 904 | 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 |
| 905 | 王五 | 女 | 1991 | 英语系 | 福建省厦门市 |
| 906 | 王六 | 男 | 1988 | 计算机系 | 湖南省衡阳市 |
+-----+-----------+------+-------+--------------+--------------------+
6 rows in set (0.00 sec)
5.从student表查询所有学生的学号(id)、姓名(name)和院系(department)的信息
mysql> select id, name, department from student;
+-----+-----------+--------------+
| id | name | department |
+-----+-----------+--------------+
| 901 | 张老大 | 计算机系 |
| 902 | 张老二 | 中文系 |
| 903 | 张三 | 中文系 |
| 904 | 李四 | 英语系 |
| 905 | 王五 | 英语系 |
| 906 | 王六 | 计算机系 |
+-----+-----------+--------------+
6 rows in set (0.00 sec)6.从student表中查询计算机系和英语系的学生的信息
mysql> select * from student where department='计算机系' or department='英语系';
+-----+-----------+------+-------+--------------+--------------------+
| id | name | sex | birth | department | address |
+-----+-----------+------+-------+--------------+--------------------+
| 901 | 张老大 | 男 | 1985 | 计算机系 | 北京市海淀区 |
| 904 | 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 |
| 905 | 王五 | 女 | 1991 | 英语系 | 福建省厦门市 |
| 906 | 王六 | 男 | 1988 | 计算机系 | 湖南省衡阳市 |
+-----+-----------+------+-------+--------------+--------------------+
4 rows in set (0.00 sec)7.从student表中查询年龄18~22岁的学生信息
8.从student表中查询每个院系有多少人
mysql> select department, count(*) as count from student group by department;
+--------------+-------+
| department | count |
+--------------+-------+
| 计算机系 | 2 |
| 中文系 | 2 |
| 英语系 | 2 |
+--------------+-------+
3 rows in set (0.01 sec)9.从score表中查询每个科目的最高分
mysql> select c_name, max(grade) as max_grade from score group by c_name;
+-----------+-----------+
| c_name | max_grade |
+-----------+-----------+
| 计算机 | 98 |
| 英语 | 94 |
| 中文 | 95 |
+-----------+-----------+
3 rows in set (0.01 sec)10.查询李四的考试科目(c_name)和考试成绩(grade)
mysql> select c_name, grade-> from score-> where stu_id = 904;
+-----------+-------+
| c_name | grade |
+-----------+-------+
| 计算机 | 70 |
| 英语 | 92 |
+-----------+-------+
2 rows in set (0.00 sec)11.用连接的方式查询所有学生的信息和考试信息
mysql> select s.id, s.name, s.sex, s.birth, s.department, s.address, sc.c_name, sc.grade from student s join score sc on s.id = sc.stu_id;
+-----+-----------+------+-------+--------------+--------------------+-----------+-------+
| id | name | sex | birth | department | address | c_name | grade |
+-----+-----------+------+-------+--------------+--------------------+-----------+-------+
| 901 | 张老大 | 男 | 1985 | 计算机系 | 北京市海淀区 | 计算机 | 98 |
| 901 | 张老大 | 男 | 1985 | 计算机系 | 北京市海淀区 | 英语 | 80 |
| 902 | 张老二 | 男 | 1986 | 中文系 | 北京市昌平区 | 计算机 | 65 |
| 902 | 张老二 | 男 | 1986 | 中文系 | 北京市昌平区 | 中文 | 88 |
| 903 | 张三 | 女 | 1990 | 中文系 | 湖南省永州市 | 中文 | 95 |
| 904 | 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 | 计算机 | 70 |
| 904 | 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 | 英语 | 92 |
| 905 | 王五 | 女 | 1991 | 英语系 | 福建省厦门市 | 英语 | 94 |
| 906 | 王六 | 男 | 1988 | 计算机系 | 湖南省衡阳市 | 计算机 | 90 |
| 906 | 王六 | 男 | 1988 | 计算机系 | 湖南省衡阳市 | 英语 | 85 |
+-----+-----------+------+-------+--------------+--------------------+-----------+-------+
10 rows in set (0.00 sec)12.计算每个学生的总成绩
mysql> select stu_id, sum(grade) as total_score from score group by stu_id;
+--------+-------------+
| stu_id | total_score |
+--------+-------------+
| 901 | 178 |
| 902 | 153 |
| 903 | 95 |
| 904 | 162 |
| 905 | 94 |
| 906 | 175 |
+--------+-------------+
6 rows in set (0.00 sec)13.计算每个考试科目的平均成绩
mysql> select c_name, avg(grade) as average_score from score group by c_name;
+-----------+---------------+
| c_name | average_score |
+-----------+---------------+
| 计算机 | 80.7500 |
| 英语 | 87.7500 |
| 中文 | 91.5000 |
+-----------+---------------+
3 rows in set (0.00 sec)14.查询计算机成绩低于95的学生信息
mysql> select s.id, s.name, s.sex, s.birth, s.department, s.address, sc.grade-> from student s-> join score sc on s.id = sc.stu_id-> where sc.c_name = '计算机' and sc.grade < 95;
+-----+-----------+------+-------+--------------+--------------------+-------+
| id | name | sex | birth | department | address | grade |
+-----+-----------+------+-------+--------------+--------------------+-------+
| 902 | 张老二 | 男 | 1986 | 中文系 | 北京市昌平区 | 65 |
| 904 | 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 | 70 |
| 906 | 王六 | 男 | 1988 | 计算机系 | 湖南省衡阳市 | 90 |
+-----+-----------+------+-------+--------------+--------------------+-------+
3 rows in set (0.01 sec)15.查询同时参加计算机和英语考试的学生的信息
mysql> select s.id, s.name, s.sex, s.birth, s.department, s.address-> from student s-> join score sc1 on s.id = sc1.stu_id-> join score sc2 on s.id = sc2.stu_id-> where sc1.c_name = '计算机' and sc2.c_name = '英语';
+-----+-----------+------+-------+--------------+--------------------+
| id | name | sex | birth | department | address |
+-----+-----------+------+-------+--------------+--------------------+
| 901 | 张老大 | 男 | 1985 | 计算机系 | 北京市海淀区 |
| 904 | 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 |
| 906 | 王六 | 男 | 1988 | 计算机系 | 湖南省衡阳市 |
+-----+-----------+------+-------+--------------+--------------------+
3 rows in set (0.00 sec)16.将计算机考试成绩按从高到低进行排序
mysql> select s.name, s.sex, s.birth, s.department, s.address, sc.grade-> from student s-> join score sc on s.id = sc.stu_id-> where sc.c_name = '计算机'-> order by sc.grade desc;
+-----------+------+-------+--------------+--------------------+-------+
| name | sex | birth | department | address | grade |
+-----------+------+-------+--------------+--------------------+-------+
| 张老大 | 男 | 1985 | 计算机系 | 北京市海淀区 | 98 |
| 王六 | 男 | 1988 | 计算机系 | 湖南省衡阳市 | 90 |
| 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 | 70 |
| 张老二 | 男 | 1986 | 中文系 | 北京市昌平区 | 65 |
+-----------+------+-------+--------------+--------------------+-------+
4 rows in set (0.00 sec)17.从student表和score表中查询出学生的学号,然后合并查询结果
mysql> select id from student-> union-> select stu_id from score;
+-----+
| id |
+-----+
| 901 |
| 902 |
| 903 |
| 904 |
| 905 |
| 906 |
+-----+
6 rows in set (0.00 sec)18.查询姓张或者姓王的同学的姓名、院系和考试科目及成绩
mysql> select s.name, s.department, sc.c_name, sc.grade-> from student s-> join score sc on s.id = sc.stu_id-> where s.name like '张%' or s.name like '王%';
+-----------+--------------+-----------+-------+
| name | department | c_name | grade |
+-----------+--------------+-----------+-------+
| 张老大 | 计算机系 | 计算机 | 98 |
| 张老大 | 计算机系 | 英语 | 80 |
| 张老二 | 中文系 | 计算机 | 65 |
| 张老二 | 中文系 | 中文 | 88 |
| 张三 | 中文系 | 中文 | 95 |
| 王五 | 英语系 | 英语 | 94 |
| 王六 | 计算机系 | 计算机 | 90 |
| 王六 | 计算机系 | 英语 | 85 |
+-----------+--------------+-----------+-------+
8 rows in set (0.01 sec)19.查询都是湖南的学生的姓名、年龄、院系和考试科目及成绩
mysql> select s.name, year(curdate())-s.birth as age, s.department, sc.c_name, sc.grade-> from student s-> join score sc on s.id = sc.stu_id-> where s.address like '%湖南%';
+--------+------+--------------+-----------+-------+
| name | age | department | c_name | grade |
+--------+------+--------------+-----------+-------+
| 张三 | 34 | 中文系 | 中文 | 95 |
| 王六 | 36 | 计算机系 | 计算机 | 90 |
| 王六 | 36 | 计算机系 | 英语 | 85 |
+--------+------+--------------+-----------+-------+
3 rows in set (0.00 sec)相关文章:
多表查询)
MySQL作业 (3)多表查询
多表查询 1.创建student和score表2.为student表和score表增加记录3.查询student表的所有记录4.查询student表的第2条到4条记录5.从student表查询所有学生的学号(id)、姓名(name)和院系(department)的信息6.…...

ConcurrentHashMap和HashMap的区别
什么是HashMap (1)HashMap 是基于 Map 接口的非同步实现,线程不安全,是为了快速存取而设计的;它采用 key-value 键值对的形式存放元素(并封装成 Node 对象),允许使用 null 键和 nul…...

MCM备赛笔记——图论模型
Key Concept 图论是数学的一个分支,专注于研究图的性质和图之间的关系。在图论中,图是由顶点(或节点)以及连接这些顶点的边(或弧)组成的。图论的模型广泛应用于计算机科学、通信网络、社会网络、生物信息学…...

算法笔记(动态规划入门题)
1.找零钱 int coinChange(int* coins, int coinsSize, int amount) {int dp[amount 1];memset(dp,-1,sizeof(dp));dp[0] 0;for (int i 1; i < amount; i)for (int j 0; j < coinsSize; j)if (coins[j] < i && dp[i - coins[j]] ! -1)if (dp[i] -1 || dp[…...

开发实践_阶段三
编写一个告知APP。 需求: 1.登录、注册 2.发布定向讯息:检测是否登录,是则向用户或用户组发布 ”名称 时间“ ;否则提示登录 3.讯息接收:检测是否登录,是则查看收到信息(未读数)…...

codegeex和通义灵码辅助编程——以及通义灵码无法登陆的bug解决
通义的速度更快,延迟低,150ms。 codegeex速度慢些,延迟较高,500ms。 个人评价:延迟低的会很好地改善使用体验,所以通义加分。 但是整体功能上还是codegeex强一些,可以选中代码进行对话…...

Android14之DefaultKeyedVector实现(一百八十二)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...
银河麒麟操作系统 v10 中离线安装 Docker
银河麒麟操作系统 v10 中离线安装 Docker 1. 查看系统版本2. 查看 Linux 内核版本(3.10以上)3. 查看 iptabls 版本(1.4以上)4. 判断处理器架构5. 离线下载 Docker 安装包6. 移动解压出来的二进制文件到 /usr/bin 目录中7. 配置 Do…...

如何系统的学习Python
学习 Python 的时候,可以按照以下步骤进行系统学习: 学习 Python 基础知识:首先了解 Python 的基础语法、数据类型、变量和运算符等基本概念。可以通过阅读《Python编程从入门到实践》等经典教材来建立基础。也可以通过翻阅Python官方文档来进…...

Java并发基础:一文讲清util.concurrent包的作用
java.util.concurrent包是 Java 中用于并发编程的重要工具集,提供了线程池、原子变量、并发集合、同步工具类、阻塞队列等一系列高级并发工具类,使用这些工具类可以极大地简化并发编程的难度,减少出错的可能性,提高程序的效率和可…...

C++PythonC# 三语言OpenCV从零开发(2):教程选择
文章目录 相关专栏前言视频教学和官方文档视频教程OpenCV 官方教程最终选择我的最终选择 相关专栏 C&Python&Csharp in OpenCV 前言 OpenCV 有官方的教程和简单的视频教程: OpenCV 官方教程 B站也有相关的视频教学 OpenCV4 C 快速入门视频30讲 - 系列合集 …...

【嘉立创EDA-PCB设计指南】3.网络表概念解读+板框绘制
前言:本文对网络表概念解读板框绘制(确定PCB板子轮廓) 网络表概念解读 在本专栏的上一篇文章【嘉立创EDA-PCB设计指南】2,将设计的原理图转为了PCB,在PCB界面下出现了所有的封装,以及所有的飞线属性&…...
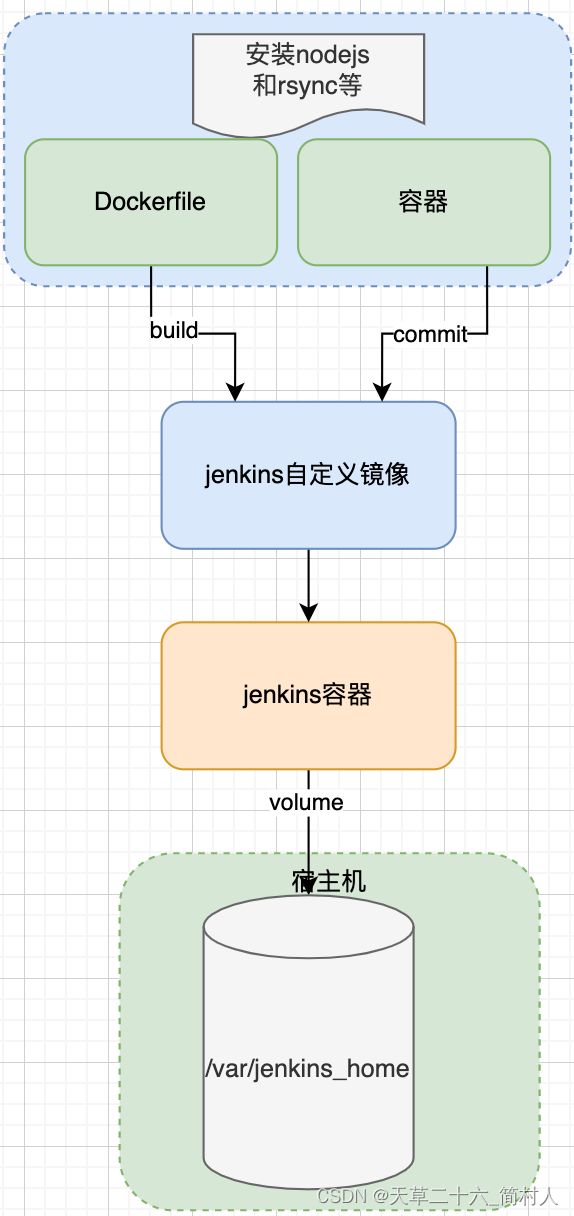
nodejs前端项目的CI/CD实现(二)jenkins的容器化部署
一、背景 docker安装jenkins,可能你会反问,这太简单了,有什么好讲的。 我最近就接手了一个打包项目,它是一个nodejs的前端项目,jenkins已在容器里部署且运行OK。 但是,前端组很追求新技术,不…...

python爬虫案例分享
当然,我可以分享一个基本的Python爬虫示例。这个示例将使用Python的requests库来抓取网页内容,然后使用BeautifulSoup库来解析和提取信息。我们将构建一个简单的爬虫来从一个示例网站抓取标题。 Python爬虫示例 目标 提取某网站的标题。 需要的库 r…...

【CC++】为什么 scanf 函数在读取字符串时不需要用取地址运算符
在C语言中如何使用 scanf 读取字符串 在C语言中,字符串实际上是字符数组,所以我们可以使用scanf函数来读取字符串。但是,需要注意的是,scanf在读取字符串时会在遇到空格、制表符或换行符时停止。因此,它不能用于读取包…...
)
Linux dirs命令教程:dirs命令详解与实例(附实例详解和注意事项)
Linux dirs命令介绍 dirs这是一个内置在shell中的命令,用于显示当前被记忆的目录列表。默认状态下,它会按照stack的方式储存目录,即最后加入的目录会被首先列出来。 Linux dirs命令适用的Linux版本 dirs命令在所有常见的Linux发行版中都适…...
掌握虚拟化:PVE平台安装教程与技术解析
🌟🌌 欢迎来到知识与创意的殿堂 — 远见阁小民的世界!🚀 🌟🧭 在这里,我们一起探索技术的奥秘,一起在知识的海洋中遨游。 🌟🧭 在这里,每个错误都…...

Godot FileDialog无法访问其它盘符的文件
问题描述 使用Godot的FileDialog对象访问Windows系统的文件,例如: func _on_hud_sig_save():var dlg FileDialog.new()dlg.set_access(FileDialog.ACCESS_FILESYSTEM)dlg.set_file_mode(FileDialog.FILE_MODE_SAVE_FILE)add_child(dlg)dlg.popup_cent…...

TestNG注释
目录 TestNG注释列表 BeforeXXX和AfterXXX注释放在超类上时如何工作? 使用BeforeXXX和AfterXXX TestNG注释 TestNG是一个测试框架,旨在简化广泛的测试需求,从单元测试(隔离测试一个类)到集成测试(测试由…...

数据预处理 matlab 数据质量评估
知乎 数据类型转换等 Mathworks 数据预处理 概念辨析 配对是同一批样本的前后比较,独立是两批不同样本的的比较 独立样本是指我们得到的样本是相互独立的。配对样本就是一个样本中的数据与另一个样本中的数据相对应的两个样本。配对样本可以消除由于样本指定的不公…...

LangFuse与LangSmith区别
文章目录🔄 **核心定位对比**🎯 **适用场景差异**💡 **为什么两者并存?**🔄 核心定位对比 LangSmith(LangChain官方): 闭源产品,由LangChain官方提供深度集成ÿ…...

免费在线去水印工具哪个好用?2026好用的去水印软件推荐,无广告干净体验
想要快速去除视频或图片上的水印,又不想下载安装应用,在线工具是最便捷的选择。本文为你精选了2026年最实用的免费在线去水印方案,包括专业小程序和web工具,帮你找到真正好用、无广告、完全免费的去水印解决方案。 快速对比&#…...

chatgpt-web-midjourney-proxy的移动端PWA应用:离线AI工具开发指南
chatgpt-web-midjourney-proxy的移动端PWA应用:离线AI工具开发指南 chatgpt-web-midjourney-proxy项目是一个强大的AI工具集成平台,将ChatGPT、Midjourney绘图和GPTs功能统一在一个界面中。通过PWA技术,这个项目可以轻松转换为移动端离线应用…...

企业盈利密码,商业模式必读经典书籍推荐
很多人一提到“商业模式”,脑子里马上会想到诸如盈利、流量、融资、裂变、风口等一类的关键词。但真正问一句:“商业模式到底是什么?”往往又说不清。有人把商业模式理解成赚钱的方法;有人觉得是营销套路;还有人认为只…...

【紧急预警】ElevenLabs 2024 Q3瑞典文语音许可证变更:3类商业场景已触发合规风险,附欧盟GDPR语音数据处理自查清单
更多请点击: https://codechina.net 第一章:ElevenLabs瑞典文语音许可证变更的合规背景与影响速览 2024年第三季度,ElevenLabs正式更新其语音合成服务的区域许可政策,将瑞典语(sv-SE)语音模型纳入欧盟《人…...

为OpenClaw智能体工作流配置Taotoken作为统一模型服务源
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw智能体工作流配置Taotoken作为统一模型服务源 在构建基于智能体(Agent)的自动化工作流时&#x…...

备考执业兽医考试哪里有免费资料可以领?
备战执业兽医考试,是不是还在四处搜罗备考资料?网上资源杂乱老旧、版本参差不齐,要么内容不全,要么找不到重点,浪费大把时间还没头绪。不用再盲目翻找、费心整理了!给大家推荐一个能免费领执业兽医全科资料…...

告别‘断头路’:聊聊DSCNet中那个神奇的拓扑连续性损失函数
告别‘断头路’:DSCNet中拓扑连续性损失函数的深度解析 在医学影像和遥感图像分析中,管状结构(如血管、道路)的精确分割一直是个棘手问题。传统分割网络常产生断裂、毛刺或不连续的结果,这种现象在业内被称为"断…...

MPV_lazy:Windows用户必备的终极视频播放体验提升指南
MPV_lazy:Windows用户必备的终极视频播放体验提升指南 【免费下载链接】mpv_PlayKit 🔄 mpv player 播放器折腾记录 Windows conf | 中文注释配置 汉化文档 快速帮助入门 | mpv-lazy 懒人包 Win11 x64 config | 着色器 shader 滤镜 filter 整合方案 项…...

3步找回密码:如何用ArchivePasswordTestTool解锁加密压缩包
3步找回密码:如何用ArchivePasswordTestTool解锁加密压缩包 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经面对一个…...