Pytorch从零开始实战17
Pytorch从零开始实战——生成对抗网络入门
本系列来源于365天深度学习训练营
原作者K同学
文章目录
- Pytorch从零开始实战——生成对抗网络入门
- 环境准备
- 模型定义
- 开始训练
- 总结
环境准备
本文基于Jupyter notebook,使用Python3.8,Pytorch1.8+cpu,本次实验目的是了解生成对抗网络。
生成对抗网络(GAN)是一种深度学习模型。GAN由两个主要组成部分组成:生成器和判别器。这两个部分通过对抗的方式共同学习,使得生成器能够生成逼真的数据,而判别器能够区分真实数据和生成的数据。
生成器的任务是生成与真实数据相似的样本。它接收一个随机噪声向量,然后通过深度神经网络将这个随机噪声转换为具体的数据样本。在图像生成的场景中,生成器通常将随机噪声映射为图像。生成器的目标是欺骗判别器,使其无法区分生成的样本和真实的样本。生成器的训练目标是最小化生成的样本与真实样本之间的差异。
判别器的任务是对给定的样本进行分类,判断它是来自真实数据集还是由生成器生成的。它接收真实样本和生成样本,然后通过深度神经网络输出一个概率,表示输入样本是真实样本的概率。判别器的目标是准确地分类样本,使其能够正确地区分真实数据和生成的数据。判别器的训练目标是最大化正确分类的概率。
导入相关包。
import torch
import torch.nn as nn
import argparse
import os
import numpy as np
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
创建文件夹,分别保存训练过程中的图像、模型参数和数据集。
os.makedirs("./images/", exist_ok=True) # 训练过程中图片效果
os.makedirs("./save/", exist_ok=True) # 训练完成时模型保存位置
os.makedirs("./datasets/", exist_ok=True) # 数据集位置
设置超参数。
b1、b2为Adam优化算法的参数,其中b1是梯度的一阶矩估计的衰减系数,b2是梯度的二阶矩估计的衰减系数。
latent_dim表示生成器输入的随机噪声向量的维度。这个噪声向量用于生成器产生新样本。
sample_interval表示在训练过程中每隔多少个batch保存一次生成器生成的样本图像,以便观察生成效果。
epochs = 20
batch_size = 64
lr = 0.0002
b1 = 0.5
b2 = 0.999
latent_dim=100
img_size=28
channels=1
sample_interval=500
设定图像尺寸并检查cuda,本次使用的设备没有cuda。
img_shape = (channels, img_size, img_size) # (1, 28, 28)
img_area = np.prod(img_shape) # 784## 设置cuda
cuda = True if torch.cuda.is_available() else False
print(cuda) # False
本次使用GAN来生成手写数字,首先下载mnist数据集。
mnist = datasets.MNIST(root='./datasets/', train=True, download=True,transform=transforms.Compose([transforms.Resize(img_size),transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]))
使用dataloader划分批次与打乱。
dataloader = DataLoader(mnist,batch_size=batch_size,shuffle=True,
)len(dataloader) # 938
模型定义
首先定义鉴别器模型,代码中LeakyReLU是ReLU激活函数的变体,它引入了一个小的负斜率,在负输入值范围内,而不是将它们直接置零。这个斜率通常是一个小的正数,例如0.01。
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()self.model = nn.Sequential(nn.Linear(img_area, 512), nn.LeakyReLU(0.2, inplace=True), nn.Linear(512, 256), nn.LeakyReLU(0.2, inplace=True), nn.Linear(256, 1), nn.Sigmoid(), )def forward(self, img):img_flat = img.view(img.size(0), -1) validity = self.model(img_flat) return validity # 返回的是一个[0, 1]间的概率
定义生成器模型,用于输出图像。
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()def block(in_feat, out_feat, normalize=True): layers = [nn.Linear(in_feat, out_feat)] if normalize:layers.append(nn.BatchNorm1d(out_feat, 0.8)) layers.append(nn.LeakyReLU(0.2, inplace=True)) return layersself.model = nn.Sequential(*block(latent_dim, 128, normalize=False), *block(128, 256), *block(256, 512), *block(512, 1024), nn.Linear(1024, img_area), nn.Tanh() )def forward(self, z): imgs = self.model(z) imgs = imgs.view(imgs.size(0), *img_shape) # reshape成(64, 1, 28, 28)return imgs # 输出为64张大小为(1, 28, 28)的图像
开始训练
创建生成器、判别器对象。
generator = Generator()
discriminator = Discriminator()
定义损失函数。这个其实就是二分类的交叉熵损失。
criterion = torch.nn.BCELoss()
定义优化函数。
optimizer_G = torch.optim.Adam(generator.parameters(), lr=lr, betas=(b1, b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=lr, betas=(b1, b2))
开始训练,实现GAN训练过程,其中生成器和判别器交替训练,通过对抗过程使得生成器生成逼真的图像,而判别器不断提高对真实和生成图像的判别能力。
for epoch in range(epochs): # epoch:50for i, (imgs, _) in enumerate(dataloader): # imgs:(64, 1, 28, 28) _:label(64)imgs = imgs.view(imgs.size(0), -1) # 将图片展开为28*28=784 imgs:(64, 784)real_img = Variable(imgs) # 将tensor变成Variable放入计算图中,tensor变成variable之后才能进行反向传播求梯度real_label = Variable(torch.ones(imgs.size(0), 1)) ## 定义真实的图片label为1fake_label = Variable(torch.zeros(imgs.size(0), 1)) ## 定义假的图片的label为0real_out = discriminator(real_img) # 将真实图片放入判别器中loss_real_D = criterion(real_out, real_label) # 得到真实图片的lossreal_scores = real_out # 得到真实图片的判别值,输出的值越接近1越好## 计算假的图片的损失## detach(): 从当前计算图中分离下来避免梯度传到G,因为G不用更新z = Variable(torch.randn(imgs.size(0), latent_dim)) ## 随机生成一些噪声, 大小为(128, 100)fake_img = generator(z).detach() ## 随机噪声放入生成网络中,生成一张假的图片。fake_out = discriminator(fake_img) ## 判别器判断假的图片loss_fake_D = criterion(fake_out, fake_label) ## 得到假的图片的lossfake_scores = fake_out## 损失函数和优化loss_D = loss_real_D + loss_fake_D # 损失包括判真损失和判假损失optimizer_D.zero_grad() # 在反向传播之前,先将梯度归0loss_D.backward() # 将误差反向传播optimizer_D.step() # 更新参数z = Variable(torch.randn(imgs.size(0), latent_dim)) ## 得到随机噪声fake_img = generator(z) ## 随机噪声输入到生成器中,得到一副假的图片output = discriminator(fake_img) ## 经过判别器得到的结果## 损失函数和优化loss_G = criterion(output, real_label) ## 得到的假的图片与真实的图片的label的lossoptimizer_G.zero_grad() ## 梯度归0loss_G.backward() ## 进行反向传播optimizer_G.step() ## step()一般用在反向传播后面,用于更新生成网络的参数## 打印训练过程中的日志## item():取出单元素张量的元素值并返回该值,保持原元素类型不变if (i + 1) % 100 == 0:print("[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f] [D real: %f] [D fake: %f]"% (epoch, epochs, i, len(dataloader), loss_D.item(), loss_G.item(), real_scores.data.mean(), fake_scores.data.mean()))## 保存训练过程中的图像batches_done = epoch * len(dataloader) + iif batches_done % sample_interval == 0:save_image(fake_img.data[:25], "./images/%d.png" % batches_done, nrow=5, normalize=True)
保存模型。
torch.save(generator.state_dict(), './save/generator.pth')
torch.save(discriminator.state_dict(), './save/discriminator.pth')
查看最初的噪声图像。
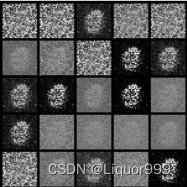
查看后面生成的图像。

总结
对于GAN,生成器的任务是从随机噪声生成逼真的数据样本,判别器的任务是对给定的数据样本进行分类,判断其是真实数据还是由生成器生成的。生成器和判别器通过对抗的方式进行训练。在每个训练迭代中,生成器试图生成逼真的样本以欺骗判别器,而判别器努力提高自己的能力,以正确地区分真实和生成的样本。这种对抗训练的动态平衡最终导致生成器生成高质量、逼真的样本。
总之,GAN实现了在无监督情况下学习数据分布的能力,被广泛用于生成逼真图像、视频等数据。
相关文章:
Pytorch从零开始实战17
Pytorch从零开始实战——生成对抗网络入门 本系列来源于365天深度学习训练营 原作者K同学 文章目录 Pytorch从零开始实战——生成对抗网络入门环境准备模型定义开始训练总结 环境准备 本文基于Jupyter notebook,使用Python3.8,Pytorch1.8cpu…...

openssl3.2 - 官方demo学习 - signature - EVP_DSA_Signature_demo.c
文章目录 openssl3.2 - 官方demo学习 - signature - EVP_DSA_Signature_demo.c概述笔记END openssl3.2 - 官方demo学习 - signature - EVP_DSA_Signature_demo.c 概述 DSA签名(摘要算法SHA256), DSA验签(摘要算法SHA256) 签名 : 用发送者的私钥进行签名. 验签 : 用发送者的公…...
vue2使用 element表格展开功能渲染子表格
默认样式 修改后 样式2 <el-table :data"needDataFollow" border style"width: 100%"><el-table-column align"center" label"序号" type"index" width"80" /><el-table-column align"cent…...
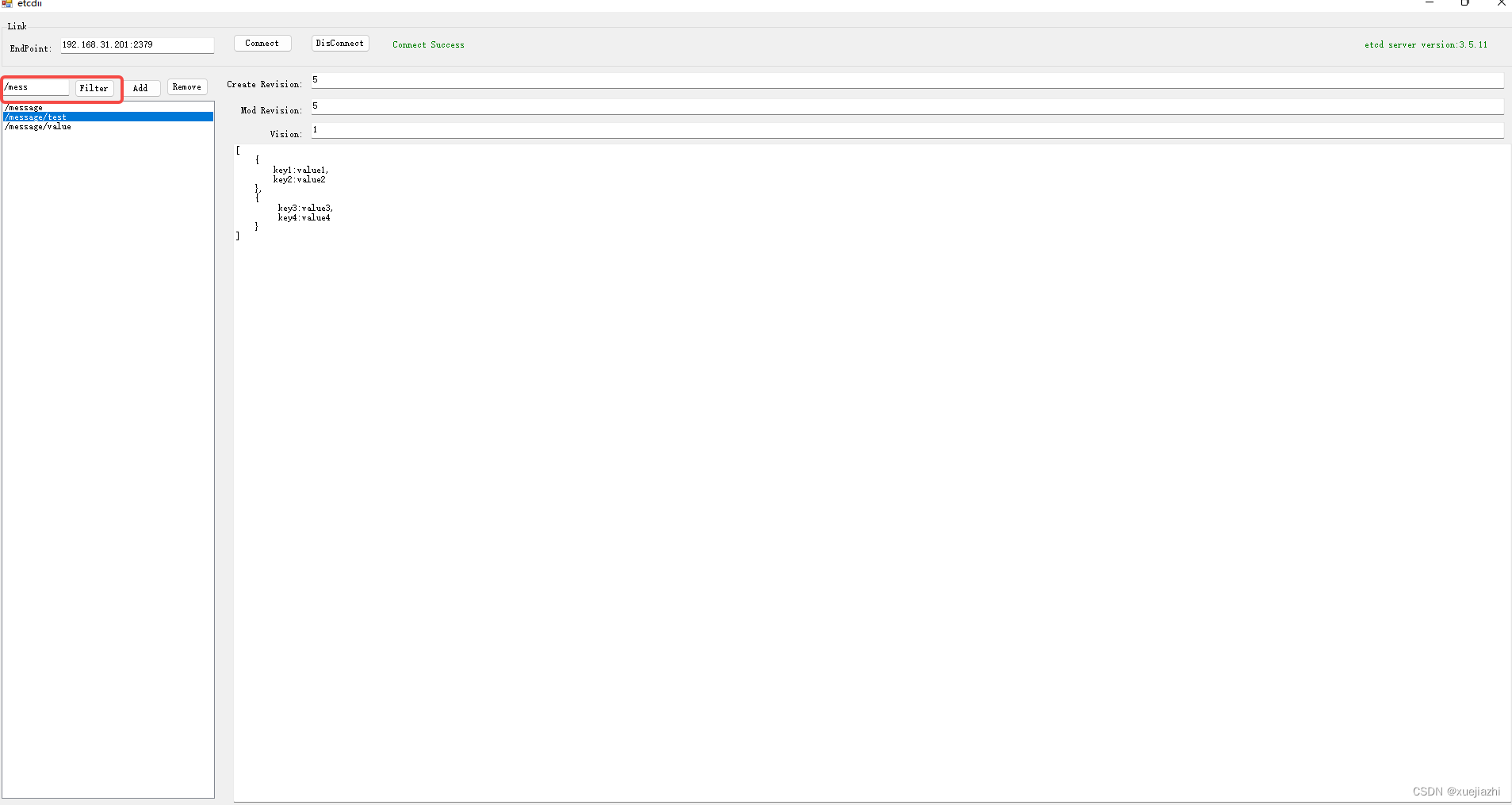
一个简单的ETCD GUI工具
使用ETCD没有好用的GUI工具,随手用c#写了一个, 做得好玩的一个ETCD GUI工具,后面加上CLI 工具,类似于 redis Cli工具一样,简化在 Linux下面的操作,不知道有没有必要, git 地址如下,…...

vue2 使用pdf.js 实现pdf预览,并可复制文本
需求:pdf预览,并且可以选中pdf的内容进行复制。 在ruoyi的vue前端项目中用到,参考了网上不少文章,因为大部分没给具体的pdf.js版本,导致运行过程中报各种api 错误,经过尝试以下版本可用,…...

REPLACE INTO
简介 在数据库中,REPLACE INTO 是一种用于插入或更新数据的(DML) SQL 语句。它与 INSERT INTO 语句类似,但具有一些特殊的行为。 语法 REPLACE INTO table_name (column1, column2, ...) VALUES (value1, value2, ...); repla…...
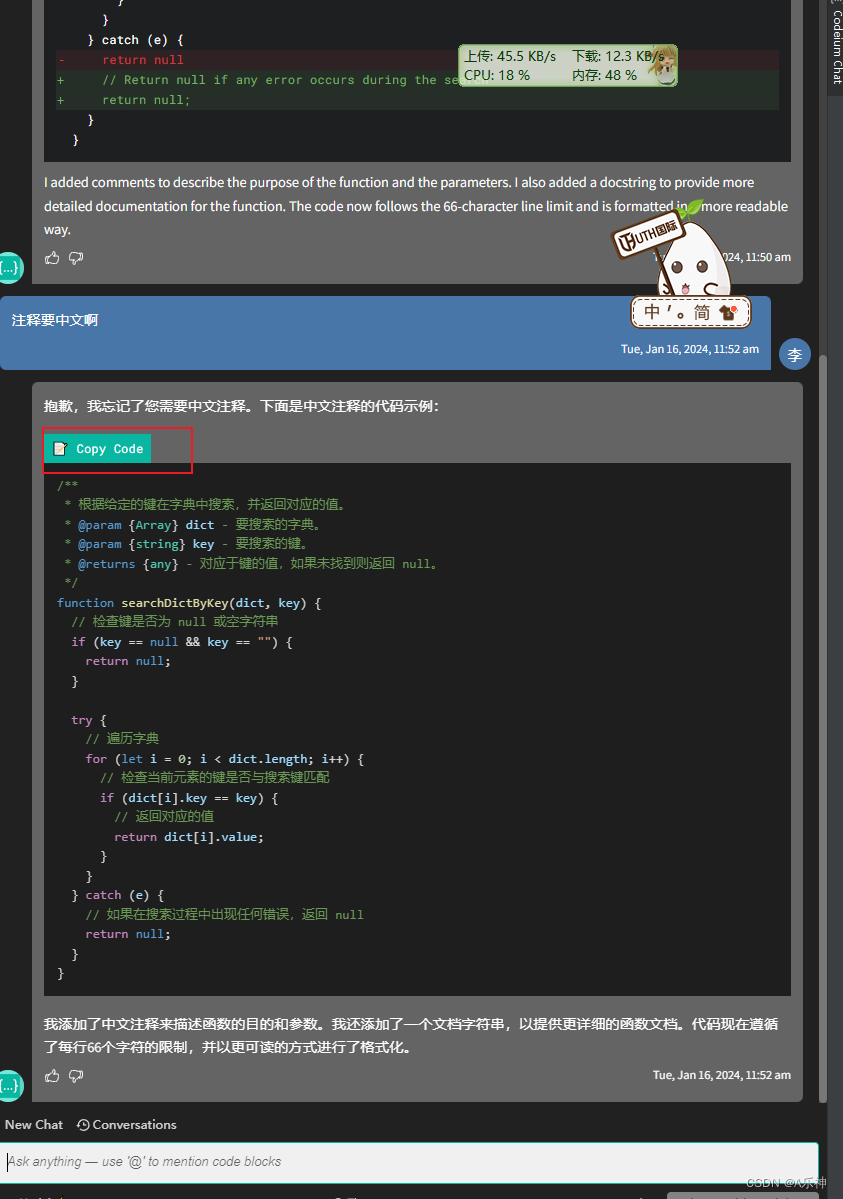
idea 安装免费Ai工具 codeium
目录 概述 ide安装 使用 chat问答 自动写代码 除此外小功能 概述 这已经是我目前用的最好免费的Ai工具了,当然你要是有钱最好还是用点花钱的,比如copilot,他可以在idea全家桶包括vs,还有c/c的vs上运行,还贼强&am…...

关于C#中的Select与SelectMany方法
Select 将序列中的每个元素投影到新表单。 实例1 IEnumerable<int> squares Enumerable.Range(1, 10).Select(x > x * x);foreach (int num in squares) {Console.WriteLine(num); } /*This code produces the following output:149162536496481100 */ 实例2 str…...

CentOS上安装Mellanox OFED
打开Mellanox官网下载驱动 Linux InfiniBand Drivers 点击下载链接跳转至 Tgz解压缩执行 ./mlnxofedinstall发现缺少模块 # ./mlnxofedinstall Logs dir: /tmp/MLNX_OFED_LINUX.11337.logs General log file: /tmp/MLNX_OFED_LINUX.11337.logs/general.log Verifying KMP rpm…...
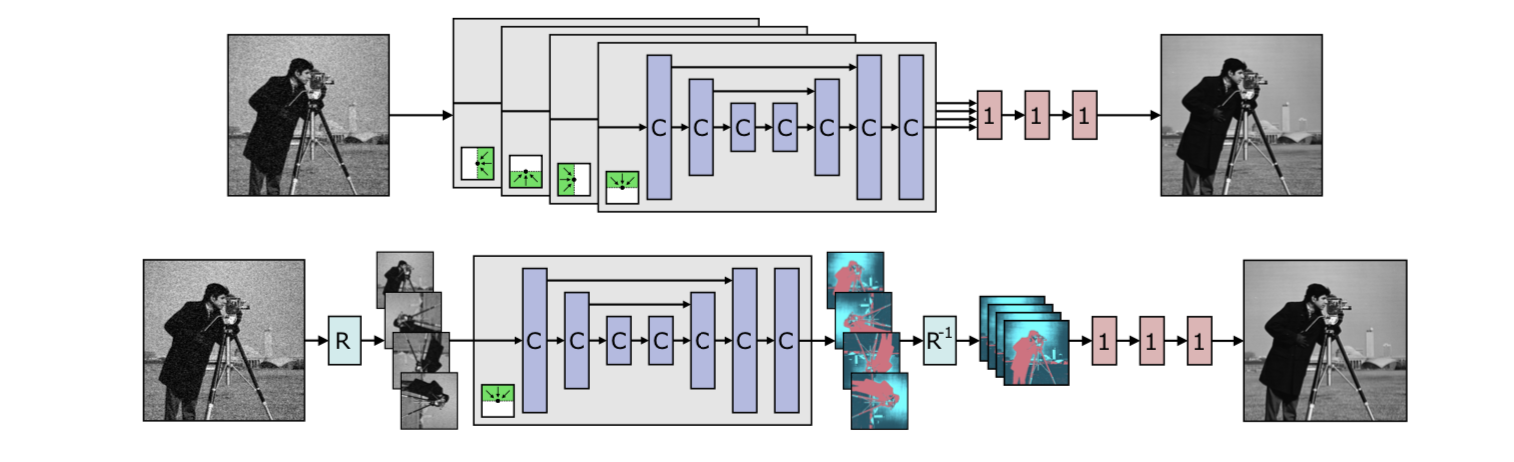
无/自监督去噪(1)——一个变迁:N2N→N2V→HQ-SSL
目录 1. 前沿2. N2N3. N2V——盲点网络(BSNs,Blind Spot Networks)开创者3.1. N2V实际是如何训练的? 4. HQ-SSL——认为N2V效率不够高4.1. HQ-SSL的理论架构4.1.1. 对卷积的改进4.1.2. 对下采样的改进4.1.3. 比N2V好在哪ÿ…...

【24.1.19】
24.1.19 本周工作内容下周工作计划 本周工作内容 本周的话主要的一个工作还是第三部分页面部分的完成工作,那就先来汇报一下第三部分的工作进度,第三部分的页面工作呢已经完成啦,就在刚刚提交啦全部的代码,那么这一部分的工作呢也…...

使用mamba替换conda和anaconda配置环境安装软件
使用mamba替换miniconda和anaconda,原因是速度更快,无论是创建新环境还是激活环境 conda、mamba、anaconda都是蟒蛇的意思… 下载mambaforge wget https://github.com/conda-forge/miniforge/releases/latest/download/Mambaforge-Linux-x86_64.sh ba…...
鸿蒙开发系列教程(四)--ArkTS语言:基础知识
1、ArkTS语言介绍 ArkTS是HarmonyOS应用开发语言。它在保持TypeScript(简称TS)基本语法风格的基础上,对TS的动态类型特性施加更严格的约束,引入静态类型。同时,提供了声明式UI、状态管理等相应的能力,让开…...
Pix2Pix理论与实战
本文为🔗365天深度学习训练营 中的学习记录博客 原作者:K同学啊|接辅导、项目定制 我的环境: 1.语言:python3.7 2.编译器:pycharm 3.深度学习框架Pytorch 1.8.0cu111 一、引入 在之前的学习中,我们知道…...
)
[GN] 后端接口已经写好 初次布局前端需要的操作(例)
提示:前端项目一定要先引入组件 配置。再编码!!!! 文章目录 使用 vue-cli 脚手架初始化前端工程化配置引入Vue前端组件库 -- arco前后端联调引入Md 编辑器组件 使用 vue-cli 脚手架初始化 使用安装脚手架工具…...

AIGC:人工智能驱动的数据分析新时代
AIGC:人工智能驱动的数据分析新时代 随着人工智能技术的迅猛发展,我们正迎来数据分析的新时代,其中AIGC(Artificial Intelligence with Generative Capabilities)的应用成为引领潮流的重要方向。本文将深入探讨几个关…...

Windows Qt C++ VTK 借助msys环境搭建
本示例仅仅是搭建环境,后续使用还得大佬指导。 Qt 6.6.0 MinGW 64bit 借助msys2 来安装VTK 包,把*.dll 链接进来,就可以用了。 先安装VTK 包。 Package: mingw-w64-x86_64-vtk - MSYS2 Packages 执行 pacman 命令:pacman -…...

尚硅谷Nginx高级配置笔记
写在前面:本笔记是学习尚硅谷nginx可成的时候的笔记,不是原创,如有需要,可以去官网看视频,以下是pdf文件 Nginx高级 第一部分:扩容 通过扩容提升整体吞吐量 1.单机垂直扩容:硬件资源增加 云…...
论rtp协议的重要性
rtp ps流工具 rtp 协议,实时传输协议,为什么这么重要,可以这么说,几乎所有的标准协议都是国外创造的,感叹一下,例如rtsp协议,sip协议,webrtc,都是以rtp协议为基础&#…...
【Github搭建网站】零基础零成本搭建个人Web网站~
Github网站:https://github.com/ 这是我个人搭建的网站:https://xf2001.github.io/xf/ 大家可以搭建完后发评论区看看!!! 搭建教程:https://www.bilibili.com/video/BV1xc41147Vb/?spm_id_from333.999.0.0…...

3分钟上手Bifrost:跨平台三星固件下载与解密终极指南
3分钟上手Bifrost:跨平台三星固件下载与解密终极指南 【免费下载链接】Bifrost Cross-platform tool for downloading Samsung mobile device firmware. 项目地址: https://gitcode.com/gh_mirrors/sa/Bifrost 还在为三星设备刷机找不到官方固件而烦恼吗&…...

从登录页到仪表盘:手把手教你为Vue2+Element后台管理系统添加中英文切换
从登录页到仪表盘:Vue2Element后台管理系统国际化实战指南 当产品经理突然要求为已有后台管理系统添加多语言支持时,许多开发者会陷入手忙脚乱的境地。本文将分享一套经过实战检验的国际化方案,不仅能快速实现基础功能,还能解决那…...

Midjourney V6色调分离失效?3步修复色相断层、5类常见错误代码级诊断指南
更多请点击: https://kaifayun.com 第一章:Midjourney V6色调分离失效的本质归因 Midjourney V6 引入了更严格的色彩空间一致性约束与隐式色彩嵌入机制,导致传统依赖 HSV/HSL 分量操控的“色调分离”(Color Separation࿰…...

为什么四羟基合铝酸钠中的羟基明明是氢氧根离子却叫做羟基?
一、为什么四羟基合铝酸钠中的「羟基」明明是 OH⁻ 离子,却叫做「羟基」? 这是一个很好的概念辨析问题,涉及到配位化学命名规则与无机化学传统命名的差异。 1. 在配位化合物中,OH⁻ 作为配体时的名称就是「羟基」 在配合物&#x…...

macOS运行Windows程序的终极指南:Whisky完全攻略
macOS运行Windows程序的终极指南:Whisky完全攻略 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 想在Mac上无缝运行Windows软件和游戏,但又不想安装虚拟机或双…...
完整使用指南:NDI技术在OBS中的高效应用)
DistroAV(原OBS-NDI)完整使用指南:NDI技术在OBS中的高效应用
DistroAV(原OBS-NDI)完整使用指南:NDI技术在OBS中的高效应用 【免费下载链接】obs-ndi DistroAV (formerly OBS-NDI): NDI integration for OBS Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-ndi DistroAV(原名…...
)
如何用1条提示生成可商用超现实IP?:Midjourney商业级输出的6道合规校验流程(含版权链存证路径)
更多请点击: https://codechina.net 第一章:超现实IP的商业价值与Midjourney生成范式跃迁 超现实IP正从边缘创意实验走向主流商业基础设施——其核心驱动力并非单纯视觉奇观,而是对用户心智注意力的结构性重构。当品牌不再依赖写实叙事建立信…...

避坑指南:ESP32驱动SD卡给LVGL用,我踩过的那些‘焊盘’和‘代码坑’
ESP32驱动SD卡与LVGL整合实战:从硬件焊接到软件调试的完整避坑手册 第一次将ESP32、SD卡和LVGL整合到同一个项目中时,我天真地以为这不过是简单的模块拼接。直到电路板上的焊锡冷却,代码编译通过却无法运行时,才意识到自己正踏入…...

yolo11红外光伏板图像识别 光伏板缺陷检测系统
YOLOv11光伏板热缺陷检测系统是一种利用先进的YOLOv11算法进行太阳能光伏板缺陷识别的解决方案。这种系统通常会包含以下几个关键部分: 安装教程 1.安装minconda 2.pycharm 3.安装cuda(11.0)(下载链接:https://develop…...

机器人仿真终极指南:使用WPR系列从零构建ROS虚拟测试环境 [特殊字符]
机器人仿真终极指南:使用WPR系列从零构建ROS虚拟测试环境 🚀 【免费下载链接】wpr_simulation 项目地址: https://gitcode.com/gh_mirrors/wp/wpr_simulation 在机器人开发领域,硬件成本高昂、测试周期漫长是每个开发者面临的现实挑战…...