Hadoop基础知识
Hadoop基础知识

1、Hadoop简介
- 广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
- 狭义上说,Hadoop指Apache这款开源框架,它的核心组件有:
- HDFS(分布式文件系统):解决海量数据存储
- YARN(作业调度和集群资源管理的框架):解决资源任务调度
- MAPREDUCE(分布式运算编程框架):解决海量数据计算
2、Hadoop特性优点
- 扩容能力(Scalable):Hadoop是在可用的计算机集群间分配数据并完成计算任务的,这些集群可用方便的扩展到数以千计的节点中。
- 成本低(Economical):Hadoop通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
- 高效率(Efficient):通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快。
- 可靠性(Rellable):能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。所以Hadoop的按位存储和处理数据的能力值得人们信赖。
3、hadoop集群中hadoop都需要启动哪些进程,他们的作用分别是什么?
- namenode =>HDFS的守护进程,负责维护整个文件系统,存储着整个文件系统的元数据信息,fsimage+edit log
- fsimage保存了最新的元数据检查点,包含了整个HDFS文件系统的所有目录和文件的信息。
- editlog主要是在NameNode已经启动情况下对HDFS进行的各种更新操作进行记录,HDFS客户端执行所有的写操作都会被记录到editlog中。
- datanode =>是具体文件系统的工作节点,当我们需要某个数据,namenode告诉我们去哪里找,就直接和那个DataNode对应的服务器的后台进程进行通信,由DataNode进行数据的检索,然后进行具体的读/写操作
- secondarynamenode =>一个守护进程,相当于一个namenode的元数据的备份机制,定期的更新,和namenode进行通信,将namenode上的image和edits进行合并,可以作为namenode的备份使用
- 触发checkpoint需要满足两个条件中的任意一个,定时时间到和edits中数据写满了:
- 每隔一小时执行一次;
- 一分钟检查一次操作次数,当操作次数达到1百万时
- 触发checkpoint需要满足两个条件中的任意一个,定时时间到和edits中数据写满了:
- resourcemanager =>是yarn平台的守护进程,负责所有资源的分配与调度,client的请求由此负责,监控nodemanager
- nodemanager => 是单个节点的资源管理,执行来自resourcemanager的具体任务和命令
- DFSZKFailoverController高可用时它负责监控NN的状态,并及时的把状态信息写入ZK。它通过一个独立线程周期性的调用NN上的一个特定接口来获取NN的健康状态。FC也有选择谁作为Active NN的权利,因为最多只有两个节点,目前选择策略还比较简单(先到先得,轮换)。
- 7)JournalNode 高可用情况下存放namenode的editlog文件
4、Hadoop主要的配置文件
-
hadoop-env.sh
- 文件中设置的是Hadoop运行时需要的环境变量。JAVA_HOME是必须设置的,即使我们当前的系统中设置了JAVA_HOME,它也是不认识的,因为Hadoop即使是在本机上执行,它也是把当前的执行环境当成远程服务器。
-
core-site.xml
-
设置Hadoop的文件系统地址
<property><name>fs.defaultFS</name><value>hdfs://node-1:9000</value> </property>
-
-
hdfs-site.xml
-
指定HDFS副本的数量
-
secondary namenode 所在主机的ip和端口
<property><name>dfs.replication</name><value>2</value></property><property><name>dfs.namenode.secondary.http-address</name><value>node-2:50090</value></property>
-
-
mapred-site.xml
-
指定mr运行时框架,这里指定在yarn上,默认是local
<property><name>mapreduce.framework.name</name><value>yarn</value> </property>
-
-
yarn-site.xml
-
指定YARN的主角色(ResourceManager)的地址
<property><name>yarn.resourcemanager.hostname</name><value>node-1</value> </property>
-
5、Hadoop集群重要命令
-
初始化
- hadoop namenode –format
-
启动dfs
- start-dfs.sh
-
启动yarn
- start-yarn.sh
-
启动任务历史服务器
- mr-jobhistory-daemon.sh start historyserver
- 默认端口:19888
-
一键启动
- start-all.sh
-
启动成功后:
- NameNode http://nn_host:port/ 默认50070.
- ResourceManagerhttp://rm_host:port/ 默认 8088


- NameNode http://nn_host:port/ 默认50070.
| 选项名称 | 使用格式 | 含义 |
|---|---|---|
| -ls | -ls <路径> | 查看指定路径的当前目录结构 |
| -lsr | -lsr <路径> | 递归查看指定路径的目录结构 |
| -du | -du <路径> | 统计目录下个文件大小 |
| -dus | -dus <路径> | 汇总统计目录下文件(夹)大小 |
| -count | -count [-q] <路径> | 统计文件(夹)数量 |
| -mv | -mv <源路径> <目的路径> | 移动 |
| -cp | -cp <源路径> <目的路径> | 复制 |
| -rm | -rm [-skipTrash] <路径> | 删除文件/空白文件夹 |
| -rmr | -rmr [-skipTrash] <路径> | 递归删除 |
| -put | -put <多个linux上的文件> <hdfs路径> | 上传文件 |
| -copyFromLocal | -copyFromLocal <多个linux上的文件> <hdfs路径> | 从本地复制 |
| -moveFromLocal | -moveFromLocal <多个linux上的文件> <hdfs路径> | 从本地移动 |
| -getmerge | -getmerge <源路径> <linux路径> | 合并到本地 |
| -cat | -cat <hdfs路径> | 查看文件内容 |
| -text | -text <hdfs路径> | 查看文件内容 |
| -copyToLocal | -copyToLocal [-ignoreCrc][-crc] [hdfs源路径][linux目的路径] | 从本地复制 |
| -moveToLocal | -moveToLocal [-crc] <hdfs源路径> <linux目的路径> | 从本地移动 |
| -mkdir | -mkdir <hdfs路径> | 创建空白文件夹 |
| -setrep | -setrep [-R][-w] <副本数> <路径> | 修改副本数量 |
| -touchz | -touchz <文件路径> | 创建空白文件 |
| -stat | -stat [format] <路径> | 显示文件统计信息 |
| -tail | -tail [-f] <文件> | 查看文件尾部信息 |
| -chmod | -chmod [-R] <权限模式> [路径] | 修改权限 |
| -chown | -chown [-R][属主][:[属组]] 路径 | 修改属主 |
| -chgrp | -chgrp [-R] 属组名称 路径 | 修改属组 |
| -help | -help [命令选项] | 帮助 |
6、HDFS的垃圾桶机制
-
修改core-site.xml
<property><name>fs.trash.interval</name><value>1440</value></property> -
这个时间以分钟为单位,例如1440=24h=1天。HDFS的垃圾回收的默认配置属性为 0,也就是说,如果你不小心误删除了某样东西,那么这个操作是不可恢复的。
7、HDFS写数据流程
HDFS dfs -put a.txt /

详细步骤:
-
1)客户端通过Distributed FileSystem模块向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。
-
client和namenode之间是通过RPC通信; datanode和namenode之间是通过RPC通信; client和datanode之间是通过简单的Socket通信;
-
-
2)namenode返回是否可以上传。
-
3)客户端请求第一个 block上传到哪几个datanode服务器上。
-
4)namenode返回3个datanode节点,分别为dn1、dn2、dn3。
-
5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。(RPC通信)
-
6)dn1、dn2、dn3逐级应答客户端。
-
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位(大小为64k),dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
-
8)当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器。
8、Hadoop读数据流程

详细步骤:
- 1)客户端通过Distributed FileSystem向namenode请求下载文件,namenode通过查询元数据,找到文件块所在的datanode地址。
- 2)挑选一台datanode(就近原则,然后随机)服务器,请求读取数据。
- 3)datanode开始传输数据给客户端(从磁盘里面读取数据输入流,以packet为单位来做校验,大小为64k)。
- 4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
9、SecondaryNameNode的作用
NameNode职责是管理元数据信息,DataNode的职责是负责数据具体存储,那么SecondaryNameNode的作用是什么?
答:它的职责是合并NameNode的edit logs到fsimage文件。
每达到触发条件 [达到一个小时,或者事务数达到100万],会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge(这个过程称为checkpoint),如下图所示:

10、HDFS的扩容、缩容
10.1.动态扩容
随着公司业务的增长,数据量越来越大,原有的datanode节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点。也就是俗称的动态扩容。
有时候旧的服务器需要进行退役更换,暂停服务,可能就需要在当下的集群中停止某些机器上hadoop的服务,俗称动态缩容。
10.1.1. 基础准备
在基础准备部分,主要是设置hadoop运行的系统环境
修改新机器系统hostname(通过/etc/sysconfig/network进行修改)

修改hosts文件,将集群所有节点hosts配置进去(集群所有节点保持hosts文件统一)

设置NameNode到DataNode的免密码登录(ssh-copy-id命令实现)
修改主节点slaves文件,添加新增节点的ip信息(集群重启时配合一键启动脚本使用)

在新的机器上上传解压一个新的hadoop安装包,从主节点机器上将hadoop的所有配置文件,scp到新的节点上。
10.1.2. 添加datanode
- 在namenode所在的机器的
/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop目录下创建dfs.hosts文件
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoopvim dfs.hosts添加如下主机名称(包含新服役的节点)node-1node-2node-3node-4- 在namenode机器的hdfs-site.xml配置文件中增加dfs.hosts属性
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim hdfs-site.xml
<property><name>dfs.hosts</name><value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/dfs.hosts</value>
</property>
dfs.hosts属性的意义:命名一个文件,其中包含允许连接到namenode的主机列表。必须指定文件的完整路径名。如果该值为空,则允许所有主机。相当于一个白名单,也可以不配置。
在新的机器上单独启动datanode: hadoop-daemon.sh start datanode

刷新页面就可以看到新的节点加入进来了

10.1.3.datanode负载均衡服务
新加入的节点,没有数据块的存储,使得集群整体来看负载还不均衡。因此最后还需要对hdfs负载设置均衡,因为默认的数据传输带宽比较低,可以设置为64M,即hdfs dfsadmin -setBalancerBandwidth 67108864即可
默认balancer的threshold为10%,即各个节点与集群总的存储使用率相差不超过10%,我们可将其设置为5%。然后启动Balancer,
sbin/start-balancer.sh -threshold 5,等待集群自均衡完成即可。
10.1.4.添加nodemanager
在新的机器上单独启动nodemanager:
yarn-daemon.sh start nodemanager

在ResourceManager,通过yarn node -list查看集群情况

10.2.动态缩容
10.2.1.添加退役节点
在namenode所在服务器的hadoop配置目录etc/hadoop下创建dfs.hosts.exclude文件,并添加需要退役的主机名称。
注意:该文件当中一定要写真正的主机名或者ip地址都行,不能写node-4
node04.hadoop.com
在namenode机器的hdfs-site.xml配置文件中增加dfs.hosts.exclude属性
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim hdfs-site.xml
<property> <name>dfs.hosts.exclude</name><value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/dfs.hosts.exclude</value>
</property>
dfs.hosts.exclude属性的意义:命名一个文件,其中包含不允许连接到namenode的主机列表。必须指定文件的完整路径名。如果值为空,则不排除任何主机。
10.2.2.刷新集群
在namenode所在的机器执行以下命令,刷新namenode,刷新resourceManager。
hdfs dfsadmin -refreshNodes
yarn rmadmin –refreshNodes

等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役。
node-4执行以下命令,停止该节点进程
cd /export/servers/hadoop-2.6.0-cdh5.14.0
sbin/hadoop-daemon.sh stop datanode
sbin/yarn-daemon.sh stop nodemanager
namenode所在节点执行以下命令刷新namenode和resourceManager
hdfs dfsadmin –refreshNodes
yarn rmadmin –refreshNodes
namenode所在节点执行以下命令进行均衡负载
cd /export/servers/hadoop-2.6.0-cdh5.14.0/
sbin/start-balancer.sh
11、HDFS安全模式
安全模式是HDFS所处的一种特殊状态,在这种状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求,是一种保护机制,用于保证集群中的数据块的安全性。
在NameNode主节点启动时,HDFS首先进入安全模式,集群会开始检查数据块的完整性。DataNode在启动的时候会向namenode汇报可用的block信息,当整个系统达到安全标准时,HDFS自动离开安全模式。
-
手动进入安全模式
hdfs dfsadmin -safemode enter -
手动离开安全模式
hdfs dfsadmin -safemode leave
12、机架感知
hadoop自身是没有机架感知能力的,必须通过人为的设定来达到这个目的。一种是通过配置一个脚本来进行映射;另一种是通过实现DNSToSwitchMapping接口的resolve()方法来完成网络位置的映射。
#!/usr/bin/python
#-*-coding:UTF-8 -*-
import sysrack = {"hadoop-node-31":"rack1","hadoop-node-32":"rack1","hadoop-node-33":"rack1","hadoop-node-34":"rack1","hadoop-node-49":"rack2","hadoop-node-50":"rack2","hadoop-node-51":"rack2","hadoop-node-52":"rack2","hadoop-node-53":"rack2","hadoop-node-54":"rack2","192.168.1.31":"rack1","192.168.1.32":"rack1","192.168.1.33":"rack1","192.168.1.34":"rack1","192.168.1.49":"rack2","192.168.1.50":"rack2","192.168.1.51":"rack2","192.168.1.52":"rack2","192.168.1.53":"rack2","192.168.1.54":"rack2",}if __name__=="__main__":print "/" + rack.get(sys.argv[1],"rack0")
-
将脚本赋予可执行权限chmod +x RackAware.py,并放到bin/目录下。
-
然后打开conf/core-site.html
<property><name>topology.script.file.name</name><value>/opt/modules/hadoop/hadoop-1.0.3/bin/RackAware.py</value>
<!--机架感知脚本路径--></property><property><name>topology.script.number.args</name><value>20</value>
<!--机架服务器数量,由于我写了20个,所以这里写20--></property>
-
重启Hadoop集群
- namenode日志
2012-06-08 14:42:19,174 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* NameSystem.registerDatanode: node registration from 192.168.1.49:50010 storage DS-1155827498-192.168.1.49-50010-1338289368956 2012-06-08 14:42:19,204 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack2/192.168.1.49:50010 2012-06-08 14:42:19,205 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* NameSystem.registerDatanode: node registration from 192.168.1.53:50010 storage DS-1773813988-192.168.1.53-50010-1338289405131 2012-06-08 14:42:19,226 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack2/192.168.1.53:50010 2012-06-08 14:42:19,226 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* NameSystem.registerDatanode: node registration from 192.168.1.34:50010 storage DS-2024494948-127.0.0.1-50010-1338289438983 2012-06-08 14:42:19,242 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack1/192.168.1.34:50010 2012-06-08 14:42:19,242 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* NameSystem.registerDatanode: node registration from 192.168.1.54:50010 storage DS-767528606-192.168.1.54-50010-13382894122672012-06-08 14:42:49,492 INFO org.apache.hadoop.hdfs.StateChange: STATE* Network topology has 2 racks and 10 datanodes2012-06-08 14:42:49,492 INFO org.apache.hadoop.hdfs.StateChange: STATE* UnderReplicatedBlocks has 0 blocks2012-06-08 14:42:49,642 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: ReplicateQueue QueueProcessingStatistics: First cycle completed 0 blocks in 0 msec2012-06-08 14:42:49,642 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: ReplicateQueue QueueProcessingStatistics: Queue flush completed 0 blocks in 0 msec processing time, 0 msec clock time, 1 cycles
相关文章:
Hadoop基础知识
Hadoop基础知识 1、Hadoop简介 广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。狭义上说,Hadoop指Apache这款开源框架,它的核心组件有: HDFS(分布式文件系统):解决海量数据存储Y…...

Java进阶之旅第五天
Java进阶之旅第五天 不可变集合 应用场景 1.如果某个数据不能被修改,把它拷贝到不可变集合中是个很好的实践2.当集合对象被不可信的库调用时,不可变形式是安全的3.不可变集合不能修改,只能进行查询 获取方式 在List,Set,Map接口中,都存在静态的of方法,可以获取一个不可变的…...
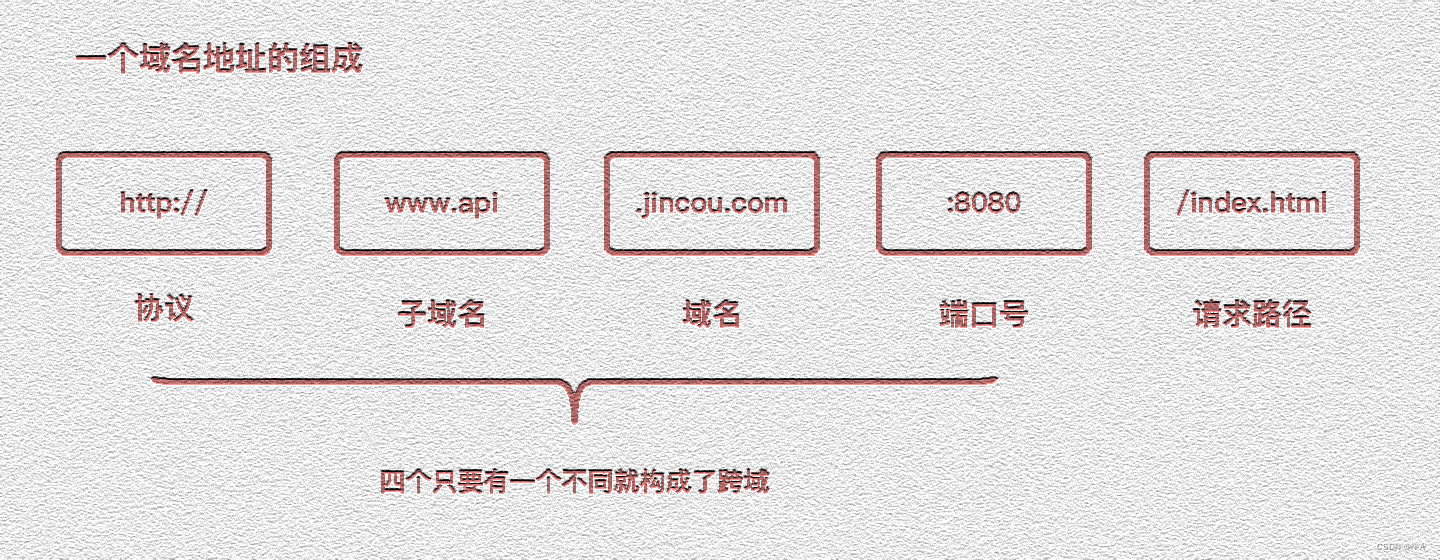
拓展边界:前端世界的跨域挑战
目录 什么是跨域 概念 同源策略及限制内容 常见跨域场景 如何解决跨域 CORS Nginx代理跨域 Node中间件代理跨域 WebSocket postMessage JSONP 其他 什么是跨域 概念 在此之前,我们了解一下一个域名地址的组成: 跨域指的是在网络安全中&…...
旅游项目day03
1. 前端整合后端发短信接口 2. 注册功能 后端提供注册接口,接受前端传入的参数,创建新的用户对象,保存到数据库。 接口设计: 实现步骤: 手机号码唯一性校验(后端一定要再次校验手机号唯一性)…...
)
单片机学习记录(一)
简答题 第1章 1.微处理器、微计算机、CPU、单片机、嵌入式处理器他们之间有何区别? 答:微处理器、CPU都是中央处理器的不同称谓,微处理器芯片本身不是计算机; 单片机、微计算机都是一个完整的计算机系统,单片机是集…...
MacBookPro怎么数据恢复? mac电脑数据恢复?
使用电脑的用户都知道,被删除的文件一般都会经过回收站,想要恢复它直接点击“还原”就可以恢复到原始位置。mac电脑同理也是这样,但是“回收站”在mac电脑显示为“废纸篓”。 如果电脑回收站,或者是废纸篓里面的数据被清空了&…...
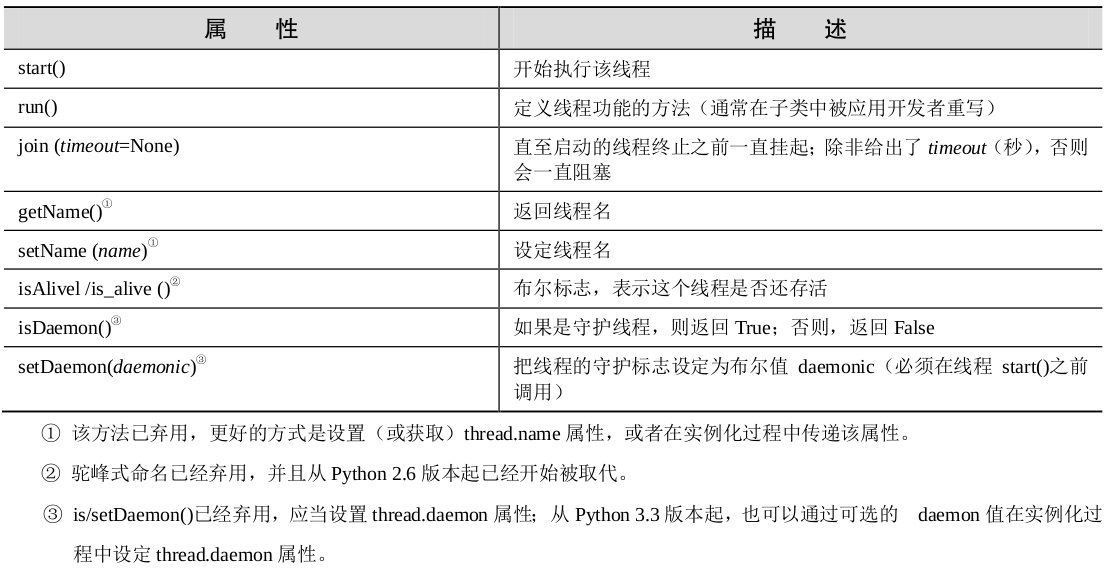
Python多线程—threading模块
参考:《Python核心编程》 threading 模块的Thread 类是主要的执行对象,而且,使用Thread类可以有很多方法来创建线程,这里介绍以下两种方法: 创建 Thread 实例,传给它一个函数。派生 Thread 的子类…...

mysql limit
语法 SELECT * FROM TABLE_NAME LIMIT 起始位置,偏移量注: 起始位置从0开始 示例 查询的第1条数据到第100条数据 limit 0,100查询的第101条数据到第200条数据 limit 100,100注意不要用 limit 101,100示例2 limit 语句应放在order by语句后面执行 …...
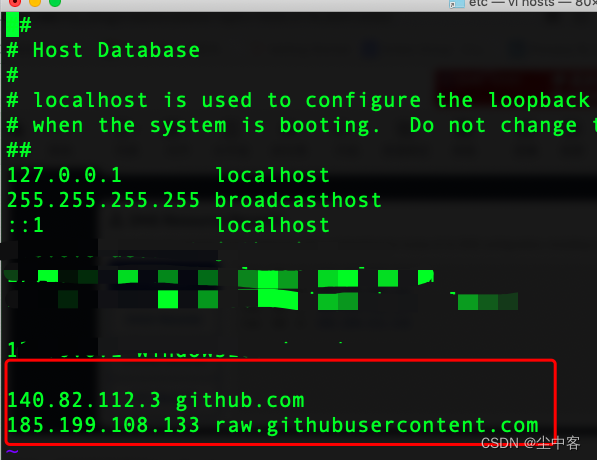
解决国内Linux服务器无法使用Github的方法
解决思路:修改Host https://www.ipaddress.com/ 利用上面的网站查询github.com和raw.githubusercontent.com的DNS解析的IP地址 最后,修改服务器的/etc/hosts 添加如下两行: 140.82.112.3 github.com 185.199.108.133 raw.githubuserconte…...
最长公共子序列 LCS)
动态规划基础(二)最长公共子序列 LCS
讲解求两个串中最长的公共的子序列长度或输出子序列等 poj1458 题目大意 给定两个字符串,要求输出两个字符串中最长公共子序列长度 思路 我们定义 a [ i ] [ j ] a[i][j] a[i][j]为,当字串 s t r 1 str1 str1到 i i i位置,字串 s t r 2 s…...
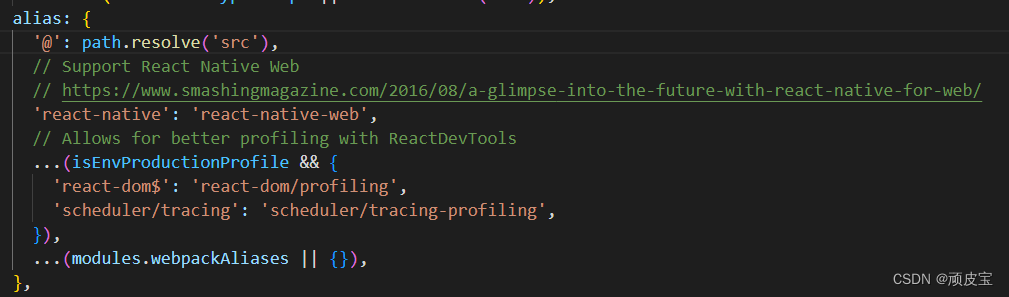
React配置src根目录@
文章目录 1.打开webpack配置文件2.配置webpack 1.打开webpack配置文件 yarn eject or npm run eject 如果报错了记得提前 git commit一下 2.配置webpack 找到 webpack.config.js 文件在 webpack.config.js 文件中找到 alias 配置在alias里添加: path.resolve(src) , 或者 : pa…...
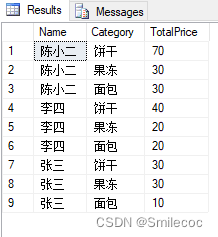
SQL Povit函数使用及实例
PIVOT函数常用于数据的行转列,同时也可以用此函数实现类似于Excel中的数据透视表的效果。 PIVOT函数 PIVOT 函数的基本语法如下: -- PIVOT 语法 SELECT <非透视的列>,[第一个透视的列] AS <列名称>,[第二个透视的列] AS <列名称>,.…...
Lite AD的安装
1、Lite AD的安装及配置 Lite AD流程: (1)创建一个新的Windows 10,安装tools,再安装ITA组件(安装Lite AD会自动安装VAG/VLB) (2)创建一个新的Windows 10,安…...
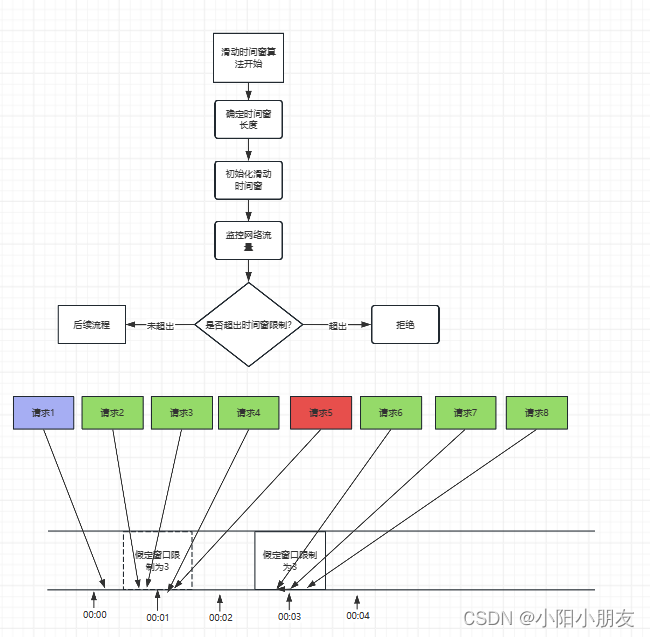
限流算法之流量控制的平滑之道:滑动时间窗算法
文章目录 引言简介优点缺点样例样例图样例代码 应用场景结论 引言 在互联网应用中,流量控制是一个重要的组件,用于防止系统过载和保护核心资源。常见的限流算法包括固定窗口算法和滑动时间窗算法。本文将重点介绍滑动时间窗算法,并分析其优缺…...
C语言数据结构——顺序表
(图片由AI生成) 0.前言 在程序设计的世界里,数据结构是非常重要的基础概念。本文将专注于C语言中的一种基本数据结构——顺序表。我们将从数据结构的基本概念讲起,逐步深入到顺序表的内部结构、分类,最后通过一个实…...

网络安全:守护数字世界的盾牌
在当今数字化的时代,网络已经渗透到我们生活的方方面面。从社交媒体到在线银行,从在线购物到工作文件传输,网络几乎无处不在。然而,随着网络的普及,网络安全问题也日益凸显。那么,如何确保我们的数字资产安…...

vue3hooks的使用
hook是钩子的意思,看到“钩子”是不是就想到了钩子函数?事实上,hooks 还真是函数的一种写法。 vue3 借鉴 react hooks 开发出了 Composition API ,所以也就意味着 Composition API 也能进行自定义封装 hooks。 vue3 中的 hooks …...

elementUI+el-upload 上传、下载、删除文件以及文件展示列表自定义为表格展示
Upload 上传组件的使用 官方文档链接使用el-upload组件上传文件 具体参数说明,如何实现上传、下载、删除等功能获取文件列表进行file-list格式匹配代码 文件展示列表自定义为表格展示 使用的具体参数说明文件大小展示问题(KB/MB)文件下载代码…...

供应链安全项目in-toto开源框架详解
引言:in-toto 是一个开源框架,能够以密码学的方式验证构件生产路径上的每个组件和步骤。它可与主流的构建工具、部署工具进行集成。in-toto已经被CNCF技术监督委员会 (Technical Oversight Committee,TOC)接纳为CNCF孵化项目。 1. 背景 由于…...

自己是如何使用单元测试
前言 自己是如何使用单元测试 进行单元测试能够让我们在编写方法的具体实现代码后,能清晰地看到其是否能实现预期的功能,有助于我们及时修正自己方法中存在的bug,以免在后续使用到某方法时出现意想不到的错误。 一、引入单元测试所使用的依赖…...

MySQL新手必看:Navicat导入SQL文件报错1046?三步搞定数据库选择问题
MySQL图形化工具避坑指南:彻底解决1046报错与数据库选择问题 刚接触MySQL的开发者,十有八九会在第一次导入SQL文件时遇到那个令人困惑的弹窗——"Error Code: 1046. No database selected"。这个看似简单的提示背后,其实隐藏着MySQ…...

搜索已死?不,它刚刚重生为Agent的“天眼”
前言2026年,AI Agent的能力正以月为单位狂飙突进。写代码、跑审计、做研报……曾经需要人类全程陪跑的任务,如今八成以上已被Agent自主接管。然而,一个看似微不足道的环节,却成了整个智能链条中最脆弱的一环——搜索。你让Agent查…...

django-tenants测试策略:单元测试、集成测试与持续集成
django-tenants测试策略:单元测试、集成测试与持续集成 【免费下载链接】django-tenants Django tenants using PostgreSQL Schemas 项目地址: https://gitcode.com/gh_mirrors/dj/django-tenants django-tenants是一个基于PostgreSQL模式的Django多租户解决…...

如何在5分钟内解锁所有Steam成就:Steam Achievement Manager完整使用指南
如何在5分钟内解锁所有Steam成就:Steam Achievement Manager完整使用指南 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager 还在为Steam游戏中那…...
)
电脑截图工具深度测评:PixPin、Snipaste、兔灵截图(Utools插件)
日常办公、写教程、做笔记,截图是高频刚需。Windows自带截图简陋,截图功能有限,精准标注、长截图、OCR识别等需求,需要专业工具来满足。 本文实测3款「免费无广告、口碑拉满」的截图工具:PixPin、Snipaste、兔灵截图&a…...

实验室御用MedPeer科研绘图工具实测
我之前总觉得科研绘图是“科研人的附加技能”——不会用AI就得啃PS,不会用PS就得找外包,要么耗时间要么烧钱,还经常踩坑:要么用了非授权素材被期刊卡版权,要么画出来的图风格混乱被导师吐槽,直到被同门安利…...

急救场景下的志愿者调度与AED就近匹配
急救场景下的志愿者调度与AED就近匹配——120急救通的设计思路 一、问题的起点:黄金4分钟 心脏骤停后,每延迟1分钟,存活率下降7%-10%。医学上公认的黄金抢救时间是4分钟。 而现实是:城市中120救护车平均到达时间超过10分钟&#x…...

MCU工程迁移实战:从STM32到MSPM0L1306的完整指南
1. 项目概述:从零理解MCU工程迁移最近在折腾TI的MSPM0系列MCU,特别是MSPM0L1306这颗芯片。很多朋友拿到新的开发板或者从旧项目切换到新平台时,最头疼的就是“迁移工程”这一步。这不仅仅是把代码从一个文件夹复制到另一个文件夹那么简单&…...

8351健康管理中心用黑科技设备为企业家筑起生命防线
事业的成功固然值得骄傲,但如果没有健康作为根基,一切的辉煌都显得摇摇欲坠。对于每天在高压下决策、在商海中搏击的企业家而言,健康早已不是一句简单的口号,而是一场需要长期投入的战略投资。然而现实往往是,很多企业…...

用Python实战脑电分析:手把手教你计算PLV、MVL、MI跨频耦合指标
Python脑电分析实战:PLV、MVL、MI跨频耦合指标全流程解析 神经振荡的跨频耦合(Cross-Frequency Coupling, CFC)分析正在成为探索大脑信息处理机制的重要工具。想象一下,当你面对一组EEG数据时,如何从复杂的波形中提取出…...