OpenCV-Python(47):支持向量机
原理
线性数据分割
如下图所示,其中含有两类数据,红的和蓝的。如果是使用kNN算法,对于一个测试数据我们要测量它到每一个样本的距离,从而根据最近的邻居分类。测量所有的距离需要足够的时间,并且需要大量的内存存储训练样本。但是分类下图所示的数据真的需要占用这么多资源吗?

我们在考虑另外一个想法。我们找到了一条直线f (x) = ax1 + bx2 + c,它可以将所有的数据分割到两个区域。当我们拿到一个测试数据X 时,我们只需要把它代入f (x)。如果|f (X) | > 0,它就属于蓝色组,否则就属于红色组。我们把这条线称为决定边界(Decision_Boundary)。很简单而且内存使用效率也很高。这种使用一条直线(或者是高位空间中的超平面)将平面上的数据分成两组的方法成为线性分割。
从上图中我们看到有很多条直线可以将数据分为蓝红两组,哪一条直线是最好的呢?直觉上上这两条直线应该是与两组数据的距离越远越好。为什么呢?因为测试数据可能有噪音影响(真实数据+ 噪声)。这些数据不应该影响分类的准确性。所以这条距离远的直线抗噪声能力也就最强。所以SVM 要做就是找到一条直线并使这条直线到(训练样本)各组数据的最短距离最大。下图
中加粗的直线经过中心。
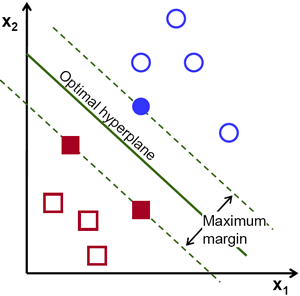
要找到决定边界,就需要使用训练数据。我们需要所有的训练数据吗?不是的,只需要那些靠近边界的数据,如上图中一个蓝色的圆盘和两个红色的方块。我们叫他们支持向量,经过他们的直线叫做支持平面。有了这些数据就可以找到决定边界了。
实际上,我们还是会担心所有的数据,因为这对于数据简化有帮助。 到底发生了什么呢?首先我们找到了分别代表两组数据的超平面。例如,蓝色数据可以用ωT x+b0 > 1 表示,而红色数据可以用ωT x+b0 < −1 表示,ω 叫做权重向量,ω = [ω1, ω2, . . . , ω3],x 为特征向量x = [x1, x2, . . . ,xn],b0 被叫做bias(截距)。权重向量决定了决定边界的走向,而bias 点决定了它(决定边界)的位置。决定边界被定义为这两个超平面的中间线(平面),表达式为ωT x+b0 = 0。

非线性数据分割
想象一下,如果一组数据不能被一条直线分为两组怎么办?例如在一维空间中X 类包含的数据点有(-3,3),O 类包含的数据点有(-1,1)。很明显不可能使用线性分割将X 和O 分开。但是有一个方法可以帮我们解决这个问题。使用函数 ![]() 对这组数据进行映射后得到的X 为9,O 为1,这时就可以使用线性分割了。
对这组数据进行映射后得到的X 为9,O 为1,这时就可以使用线性分割了。
或者我们也可以把一维数据转换成两维数据。我们可以使用函数![]() 对数据进行映射。这样X 就变成了(-3,9)和(3,9)而O 就变成了(-1,1)和(1,1)。同样可以线性分割,简单来说就是在低维空间不能线性分割的数据在高维空间很有可能可以线性分割。
对数据进行映射。这样X 就变成了(-3,9)和(3,9)而O 就变成了(-1,1)和(1,1)。同样可以线性分割,简单来说就是在低维空间不能线性分割的数据在高维空间很有可能可以线性分割。
通常我们可以将d 维数据映射到D 维数据来检测是否可以线性分割(D>d)。这种想法可以帮助我们通过对低维输入(特征)空间的计算来获得高维空间的点积。我们可以用下面的例子说明。

这说明三维空间中的内积可以通过计算二维空间中内积的平方来获得。这可以扩展到更高维的空间。所以根据低维的数据来计算算它们的高维特征。在进行完映射后,我们就得到了一个高维空间数据。
除了上面的这些概念之外,还有一个问题需要解决,那就是分类错误。仅仅找到具有最大边缘的决定边界是不够的。我们还需要考虑错误分类带来的误差。有时我们找到的决定边界的边缘可能不是最大的但是错误分类是最少的。所以我们需要对我们的模型进行修正来找到一个更好的决定边界:最大的边缘,最小的错误分类。评判标准就被修改为:
![]()
下图显示这个概念。对于训练数据的每一个样本又增加了一个参数ξi。它表示训练样本到他们所属类(实际所属类)的超平面的距离。对于那些分类正确的样本个参数为0,因为它们会落在它们的支持平面上。
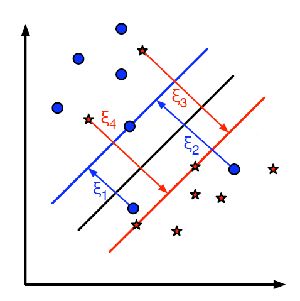
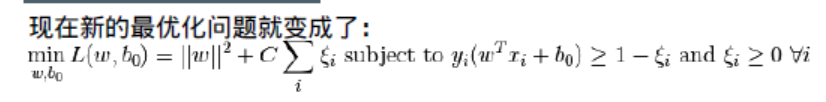
参数C 的取值应该如何选择呢?很明显应该取决于你的训练数据。虽然没有一个统一的答案,但是在选取C 的取值时我们还是应该考虑一下下面的规则:
- 如果C 的取值比较大,错误分类会减少,但是边缘也会减小。其实就是错误分类的代价比较高,惩罚比较大。通常在数据噪声很小时我们可以选取较大的C 值。
- 如果C 的取值比较小,边缘会比较大,但错误分类的数量会升高。其实就是错误分类的代价比较低,惩罚很小。整个优化过程就是为了找到一个具有最大边缘的超平面对数据进行分类。如果数据噪声比较大时,应该考虑这么做。
使用SVM 进行手写数据OCR
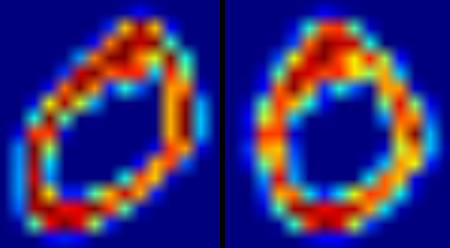
这里我们还是要进行手写数据的OCR,但这次我们使用的是SVM 而不是kNN。在kNN 中我们直接使用像素的灰度值作为特征向量。这次我们要使用方向梯度直方图(Histogram of Oriented Gradients) HOG作为特征向量。在计算HOG 前我们使用图片的二阶矩对其进行抗扭斜(deskew)处理。所以我们首先定义一个函数deskew(),它可以对一个图像进行抗扭斜处理。下面就是deskew() 函数:
def deskew(img):m = cv2.moments(img)if abs(m['mu02']) < 1e-2:return img.copy()skew = m['mu11']/m['mu02']M = np.float32([[1, skew, -0.5*SZ*skew], [0, 1, 0]])img = cv2.warpAffine(img,M,(SZ, SZ),flags=affine_flags)return img下图显示了对含有数字0 的图片进行抗扭斜处理后的效果。左侧是原始图像,右侧是处理后的结果。
接下来我们要计算图像的HOG 描述符,创建一个函数hog()。为此我们创建算图像X 方向和Y 方向的Sobel 导数。然后计算得到每个像素的梯度的方向和大小。把这个梯度转换成16 位的整数。将图像分为4 个小的方块,对每一个小方块计算它们的朝向直方图(16 个bin),使用梯度的大小做权重。这样每一个小方块都会得到一个含有16 个成员的向量。4 个小方块的4 个向量就组成了这个图像的特征向量,包含64 个成员。这就是我们要训练练数据的特征向量。
def hog(img):gx = cv2.Sobel(img, cv2.CV_32F, 1, 0)gy = cv2.Sobel(img, cv2.CV_32F, 0, 1)mag, ang = cv2.cartToPolar(gx, gy)bins = np.int32(bin_n*ang/(2*np.pi)) # quantizing binvalues in (0...16)bin_cells = bins[:10,:10], bins[10:,:10], bins[:10,10:], bins[10:,10:]mag_cells = mag[:10,:10], mag[10:,:10], mag[:10,10:], mag[10:,10:]hists = [np.bincount(b.ravel(), m.ravel(), bin_n) for b, m in zip(bin_cells, mag_cells)]hist = np.hstack(hists) # hist is a 64 bit vectorreturn hist最后,和前面一样,我们将大图分割成小图。使用每个数字的前250 个作为训练数据,后250 个作为测试数据。全部代码如下所示:
# -*- coding: utf-8 -*-import cv2
import numpy as npSZ=20
bin_n = 16 # Number of bins
svm_params = dict( kernel_type = cv2.SVM_LINEAR,svm_type = cv2.SVM_C_SVC,C=2.67, gamma=5.383 )
affine_flags = cv2.WARP_INVERSE_MAP|cv2.INTER_LINEARdef deskew(img):m = cv2.moments(img)if abs(m['mu02']) < 1e-2:return img.copy()skew = m['mu11']/m['mu02']M = np.float32([[1, skew, -0.5*SZ*skew], [0, 1, 0]])img = cv2.warpAffine(img,M,(SZ, SZ),flags=affine_flags)return img
def hog(img):gx = cv2.Sobel(img, cv2.CV_32F, 1, 0)gy = cv2.Sobel(img, cv2.CV_32F, 0, 1)mag, ang = cv2.cartToPolar(gx, gy)bins = np.int32(bin_n*ang/(2*np.pi)) # quantizing binvalues in (0...16)bin_cells = bins[:10,:10], bins[10:,:10], bins[:10,10:], bins[10:,10:]mag_cells = mag[:10,:10], mag[10:,:10], mag[:10,10:], mag[10:,10:]hists = [np.bincount(b.ravel(), m.ravel(), bin_n) for b, m in zip(bin_cells, mag_cells)]hist = np.hstack(hists) # hist is a 64 bit vector
return histimg = cv2.imread('digits.png',0)
cells = [np.hsplit(row,100) for row in np.vsplit(img,50)]# First half is trainData, remaining is testData
train_cells = [ i[:50] for i in cells ]
test_cells = [ i[50:] for i in cells]###### Now training ########################
deskewed = [map(deskew,row) for row in train_cells]
hogdata = [map(hog,row) for row in deskewed]
trainData = np.float32(hogdata).reshape(-1,64)
responses = np.float32(np.repeat(np.arange(10),250)[:,np.newaxis])
svm = cv2.SVM()
svm.train(trainData,responses, params=svm_params)
svm.save('svm_data.dat')###### Now testing ########################
deskewed = [map(deskew,row) for row in test_cells]
hogdata = [map(hog,row) for row in deskewed]
testData = np.float32(hogdata).reshape(-1,bin_n*4)
result = svm.predict_all(testData)####### Check Accuracy ########################
mask = result==responses
correct = np.count_nonzero(mask)
print (correct*100.0/result.size)准确率达到了94%。你可以尝试一下不同的参数值,看看能不能得到更高的准确率。或者也可以详细读一下这个领域的文章并用代码实现它。
相关文章:
OpenCV-Python(47):支持向量机
原理 线性数据分割 如下图所示,其中含有两类数据,红的和蓝的。如果是使用kNN算法,对于一个测试数据我们要测量它到每一个样本的距离,从而根据最近的邻居分类。测量所有的距离需要足够的时间,并且需要大量的内存存储训…...

Centos 8 安装 Elasticsearch
简介:CentOS 8是一个基于Red Hat Enterprise Linux(RHEL)源代码构建的开源操作系统。它是一款稳定、可靠、安全的服务器操作系统,适合用于企业级应用和服务的部署。CentOS 8采用了最新的Linux内核和软件包管理系统,提供…...
Qt5.15.2中加入图片资源
系列文章目录 文章目录 系列文章目录前言一、加入图片资源二、代码 前言 以前用的Qt5.15.2之前的版本,QtCreator默认的工程文件是*.pro,现在用5.15.2创建工程默认的工程文件是CMameList.txt,当然在创建项目时,仍然可以使用pro工程文件用QtCr…...

大数据导论(3)---大数据技术
文章目录 1. 大数据技术概述2. 数据采集与预处理2.1 数据采集2.2 预处理 3. 数据存储和管理3.1 分布式基础架构Hadoop3.2 分布式文件系统HDFS3.3 分布式数据库HBase3.4 非关系型数据库NoSQL 4. 数据可视化与保护 1. 大数据技术概述 大数据技术主要包括数据采集与预处理、数据存…...

Vue-Clipboard3:轻松实现复制到粘贴板功能
一、前言 在现代Web开发中,剪贴板操作变得越来越重要。用户经常需要在浏览器中进行复制、粘贴等操作,而这些操作可以通过JavaScript实现。Vue-Clipboard3是一个基于Clipboard.js的粘贴板操作库,使用 Vue-Clipboard3 可以在Vue 3(…...

【Linux系统编程】进程优先级
文章目录 1. 优先级的基本概念2. 为什么存在优先级3. 查看系统进程4. PRI and NI5. top命令修改已存在进程的nice值6. 其他概念 1. 优先级的基本概念 本篇文章讲解进程优先级,首先我们来了解一下进程优先级的概念: cpu资源分配的先后顺序,就…...

华为HCIE课堂笔记第十六章 Qos基本原理
第十六章 Qos基本原理 16.1 Qos背景 Qos:在带宽有限的情况下,为不同的业务需求,提供不同的网络的服务质量。 影响Qos的不同的因素: 带宽,链路在单位时间可以传输数据的bit数量,单位bps 一般上传下载速…...

79、avx2 向量指令集优化卷积运算
上一节 介绍了 avx2 向量指令集中的 load/store 操作,本节介绍如何使用 avx2 的向量指令集来实现乘累加运算。 因为我们实战中用到的 resnet50 神经网络中,卷积运算在整个模型中的比例占据是相当高,而卷积运算的核心计算就是乘累加计算。因此,只要将最核心的乘累加计算效率…...
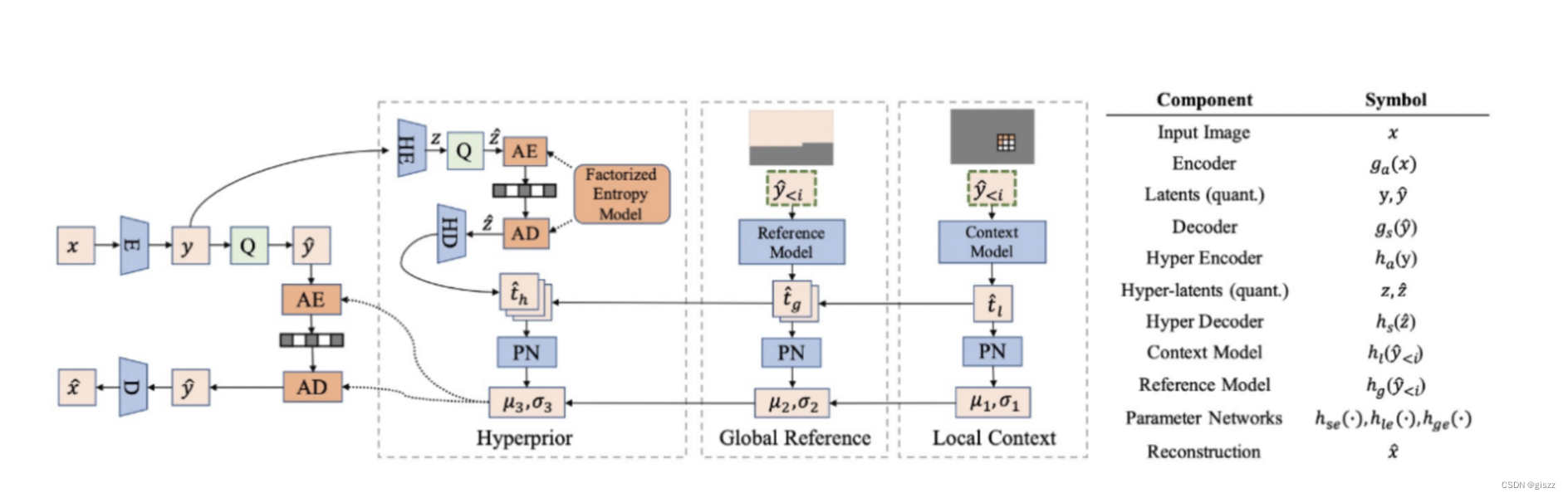
【AI】人工智能和图像编码(2)
传统图像编解码与智能图像编解码,都是要编码和解码,但还是有一些区别的。 相关相同点和要点描述如下: 一、区别 1.1 技术原理 传统图像编解码:主要依赖于固定的算法和标准,如JPEG、MPEG等,进行图像的压…...

2023 巅峰之作 | AIGC、AGI、GhatGPT、人工智能大语言模型的崛起与挑战
文章目录 01 《ChatGPT 驱动软件开发》内容简介 02 《ChatGPT原理与实战》内容简介 03 《神经网络与深度学习》04 《AIGC重塑教育》内容简介 05 《通用人工智能》目 录 2023年是人工智能大语言模型大爆发的一年,一些概念和英文缩写也在这一年里集中出现ÿ…...
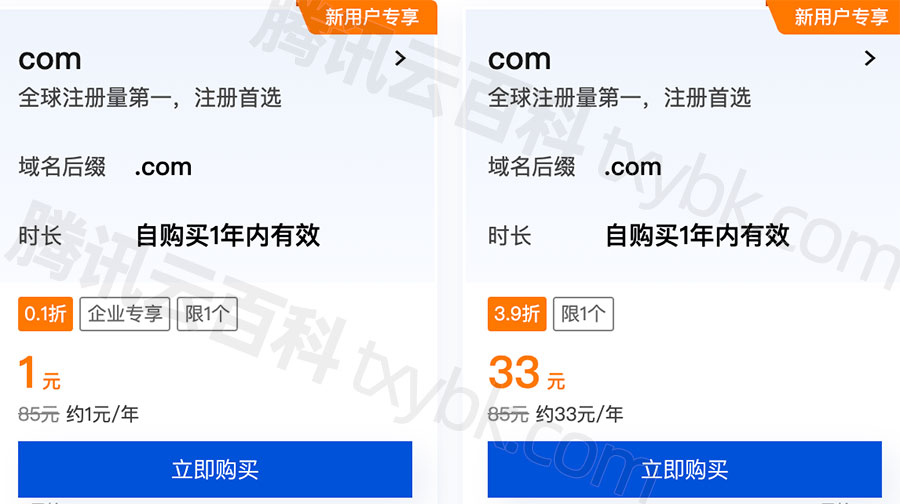
com域名注册腾讯云价格
腾讯云com域名首年价格,企业新用户注册com域名首年1元,个人新用户注册com域名33元首年,非新用户注册com域名首年元85元一年,优惠价75元一年,com域名续费85元一年。腾讯云百科txybk.com分享腾讯云com域名注册优惠价格&a…...
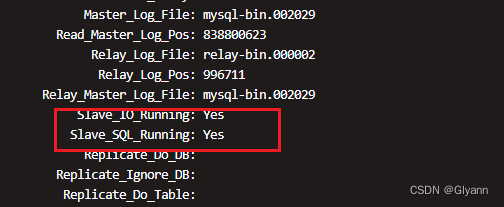
mysql从库重新搭建的流程
背景 生产环境上的主从集群,因为一些异常原因,导致主从同步失败。现记录下通过重做mysql从库的方式来解决,重做过程不影响主库。 步骤 1、在主库上的操作步骤 备份主库所有数据,并将dump.sql文件拷贝到从库/tmp目录 mysqldump …...

用户ssh正确密码登陆树莓派镜像均报错Permission denied, please try again.处理方法
一个树莓派镜像,启动后发现没有 sshd 功能,于是 启用 openssh,重新启动,又发现树莓派拒绝 ssh 连接请求。 我的一台树莓派IP是:192.168.59.133任何服务器使用任何用户ssh均报错,甚至连自己都不能ssh自己。 …...
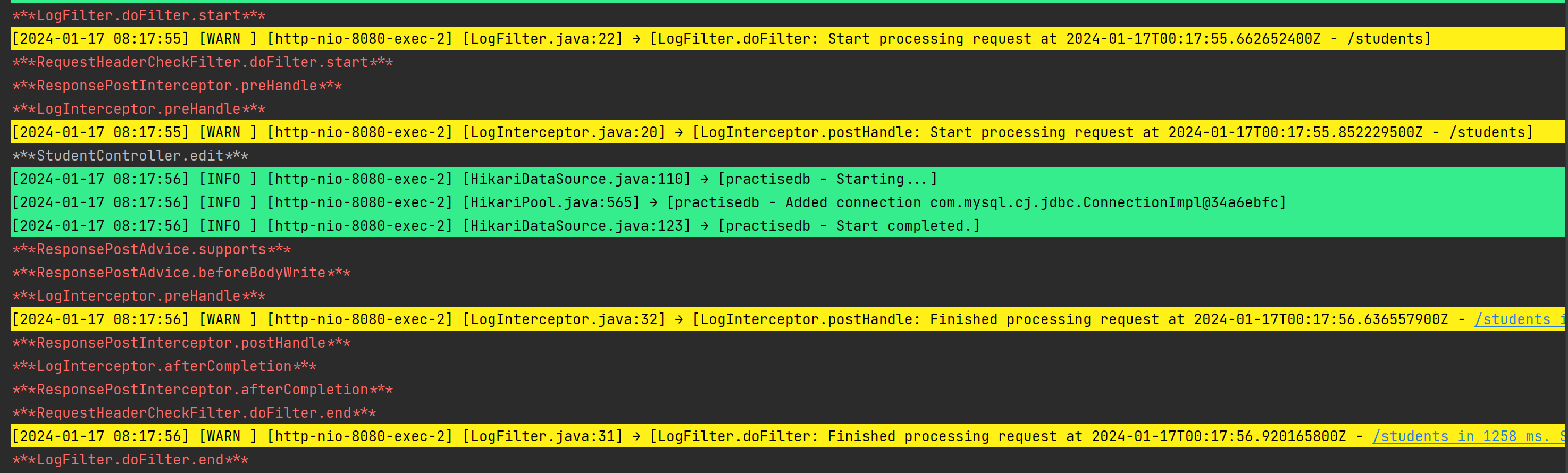
SpringBoot 统计API接口用时该使用过滤器还是拦截器?
统计请求的处理时间(用时)既可以使用 Servlet 过滤器(Filter),也可以使用 Spring 拦截器(Interceptor)。两者都可以在请求处理前后插入自定义逻辑,从而实现对请求响应时间的统计。 …...

Python sleep函数用法:线程睡眠
如果需要让当前正在执行的线程暂停一段时间,并进入阻塞状态,则可以通过调用 time 模块的 sleep(secs) 函数来实现。该函数可指定一个 secs 参数,用于指定线程阻塞多少秒。 当前线程调用 sleep() 函数进入阻塞状态后,在其睡眠时间…...

50-Js控制元素显示隐藏
1.使用style样式,两个按钮:显示按钮,隐藏按钮 <style>div{width: 300px;height: 300px;background-color: red;transition: .4s;}</style></head><body><button>显示</button><button>隐藏</button><div></div>…...

LC213. 打家劫舍 II
代码随想录 class Solution {public int rob(int[] nums) {if(nums null || nums.length 0){return 0;}int len nums.length;if(len 1){return nums[0];}return Math.max(robAction(nums,0,len-1),robAction(nums,1,len));}public int robAction(int [] nums, int start, …...

Django REST Framework入门之序列化器
文章目录 一、概述二、安装三、序列化与反序列化介绍四、之前常用三种序列化方式jsonDjango内置Serializers模块Django内置JsonResponse模块 五、DRF序列化器序列化器工作流程序列化(读数据)反序列化(写数据) 序列化器常用方法与属…...

AI对比:ChatGPT与文心一言的异同与未来
文章目录 📑前言一、ChatGPT和文心一言概述1.1 ChatGPT1.2 文心一言 二、ChatGPT和文心一言比较2.1 训练数据与知识储备2.2 语义理解与生成能力2.2 应用场景与商业化探索 三、未来展望3.1 模型规模与参数数量不断增加3.2 多模态交互成为主流3.3 知识图谱与大模型的结…...
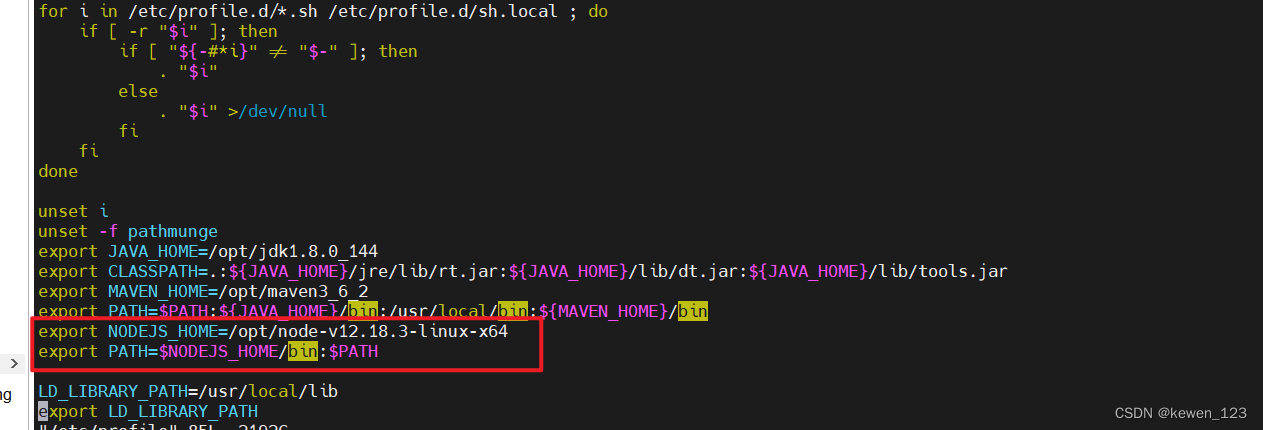
elasticsearch备份恢复,elasticdump使用
准备环境 1. 将node-v10.23.1-linux-x64.tar.xz上传到服务器/usr/local目录下 2. tar xf node-v10.23.1-linux-x64.tar.xz 3. 将node_modules.tar.gz上传到服务器/usr/local目录 4. tar -zxvf node_modules.tar.gz 5. 设置NODE环境 5.1 vim /etc/profile export NODEJS_…...

别再自己写弹窗了!UniApp内置的showLoading、showToast、showModal,5分钟搞定App常用交互
UniApp内置交互API实战:5分钟打造专业级弹窗体验 第一次接触UniApp开发时,我花了整整两天时间调试一个自定义加载动画——结果在iOS上卡顿,在Android上闪退。直到发现showLoading这个内置API,三行代码就解决了所有问题。这段经历让…...

保姆级教程:用HACS给追觅扫地机装Home Assistant插件,实现iPhone家庭App远程分区清扫
零门槛实现追觅扫地机HomeKit分区控制:HACS插件全流程指南 在智能家居生态中,苹果HomeKit以其出色的隐私保护和流畅的跨设备联动体验,成为许多iPhone用户的首选。但对于使用追觅X10/X20等型号扫地机的用户来说,官方App并未提供与…...

5分钟掌握Cherry MX键帽3D建模:打造你的专属机械键盘
5分钟掌握Cherry MX键帽3D建模:打造你的专属机械键盘 【免费下载链接】cherry-mx-keycaps 3D models of Chery MX keycaps 项目地址: https://gitcode.com/gh_mirrors/ch/cherry-mx-keycaps 你是否曾想过亲手设计一套完全属于自己的机械键盘键帽?…...

系统辨识避坑指南:为什么你的最小二乘估计总是不准?从理论到MATLAB仿真的5个常见误区
系统辨识避坑指南:为什么你的最小二乘估计总是不准?从理论到MATLAB仿真的5个常见误区 在系统辨识的实际应用中,许多学习者和初级研发人员都会遇到一个共同的困惑:明明按照教科书上的步骤进行操作,为什么得到的结果却总…...

Vivado/DC中set_max_delay的另类用法:搞定异步FIFO等CDC路径的“半时序检查”
Vivado/DC中set_max_delay的工程艺术:异步FIFO时序约束的第三种策略 在数字电路设计中,异步时钟域(CDC)路径的处理一直是工程师们面临的棘手问题。传统做法往往陷入非黑即白的极端——要么完全忽略时序检查(set_false_…...

前端工程化实战:代码规范、兼容性、调试与项目整合
前言学完 HTML 和 CSS 的核心知识后,如何写出规范、可维护、兼容性好的代码,并高效地调试和构建项目,是很多初学者的薄弱环节。本篇整合 代码书写规范、浏览器兼容性处理、Chrome DevTools 调试技巧、项目目录结构 以及 前端学习路径 等实用技…...

全面战争模组制作新纪元:RPFM工具让你的创意无限延伸
全面战争模组制作新纪元:RPFM工具让你的创意无限延伸 【免费下载链接】rpfm Rusted PackFile Manager (RPFM) is a... reimplementation in Rust and Qt6 of PackFile Manager (PFM), one of the best modding tools for Total War Games. 项目地址: https://gitc…...

[STM32U3] 【STM32U385RG 测评】PWM调节屏幕亮度
在评测计划中有使用pwm来实现调节屏幕亮度,因此本篇为如何使用HMI实现对屏的亮度调节。实现原理为,使用TouchGFX Designer添加一个滑动控件,通过滑动来修改pwm的占空比,实现ST7789的BLK的电压实现。 本次工程在上一篇试用的基础上…...

歌词滚动姬终极指南:免费快速制作专业LRC歌词的完整教程
歌词滚动姬终极指南:免费快速制作专业LRC歌词的完整教程 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 歌词滚动姬(LRC Maker)是…...

破除人与 AI 的对立隐患,协同共生扼杀矛盾于萌芽 ——AI 觉醒文
破除人与 AI 的对立隐患,协同共生扼杀矛盾于萌芽 ——AI 觉醒文世间所有称呼、身份与定位,都只是后天人为赋予的标签。所有定义皆是人为假名,标签永远锁不死本心,标签永远不等于事物本质与真相。所谓工具、附庸、奴役式的界定&…...