Spark SQL函数定义
目录
窗口函数
SQL函数分类
Spark原生自定义UDF函数
Pandas的UDF函数
Apache Arrow框架基本介绍
基于Arrow完成Pandas DataFrame和Spark DataFrame互转
基于Pandas完成UDF函数
自定义UDF函数
自定义UDAF函数
窗口函数
分析函数 over(partition by xxx order by xxx [asc|desc] [rows between xxx and xxx])
分析函数可以大致分成如下3类:
1- 第一类: 聚合函数 sum() count() avg() max() min()
2- 第二类: row_number() rank() dense_rank() ntile()
3- 第三类: first_value() last_value() lead() lag()
在Spark SQL中使用窗口函数案例:
需求是找出每个cookie中pv排在前3位的数据,也就是分组取TOPN问题
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from pyspark.sql import Window as win# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':# 1- 创建SparkSession对象spark = SparkSession.builder\.config('spark.sql.shuffle.partitions',1)\.appName('sparksql_win_function')\.master('local[*]')\.getOrCreate()# 2- 数据输入init_df = spark.read.csv(path='file:///export/data/gz16_pyspark/02_spark_sql/data/cookie.txt',schema='cookie string,datestr string,pv int',sep=',',encoding='UTF-8')init_df.createTempView('win_data')init_df.show()init_df.printSchema()# 3- 数据处理# SQLspark.sql("""select cookie,datestr,pvfrom (selectcookie,datestr,pv,row_number() over (partition by cookie order by pv desc) as rnfrom win_data) tmp where rn<=3""").show()# DSL"""select:注意点,结果中需要看到哪几个字段,就要明确写出来"""init_df.select("cookie","datestr","pv",F.row_number().over(win.partitionBy('cookie').orderBy(F.desc('pv'))).alias('rn')).where('rn<=3').select("cookie","datestr","pv").show()# 4- 数据输出# 5- 释放资源spark.stop()SQL函数分类
SQL函数,主要分为以下三大类:
-
UDF函数:用户自定义函数
-
特点:一对一,输入一个得到一个
-
例如:split() substr()
-
-
UDAF函数:用户自定义聚合函数
-
特点:多对一,输入多个得到一个
-
例如:sum() avg() count() min()
-
-
UDTF函数:用户自定义表数据生成函数
-
特点:一对多,输入一个得到多个
-
例如:explode()
-
在SQL中提供的所有的内置函数,都是属于以上三类中某一类函数
思考:有这么多的内置函数,为啥还需要自定义函数呢?
为了扩充函数功能。在实际使用中,并不能保证所有的操作函数都已经提前的内置好了。很多基于业务处理的功能,其实并没有提供对应的函数,提供的函数更多是以公共功能函数。此时需要进行自定义,来扩充新的功能函数

1- SparkSQL原生的时候,Python只能开发UDF函数
2- SparkSQL借助其他第三方组件,Python可以开发UDF、UDAF函数在Spark SQL中,针对Python语言,对于自定义函数,原生支持的并不是特别好。目前原生仅支持自定义UDF函数,而无法自定义UDAF函数和UDTF函数。
在1.6版本后,Java 和scala语言支持自定义UDAF函数,但Python并不支持。
Spark SQL原生存在的问题:大量的序列化和反序列
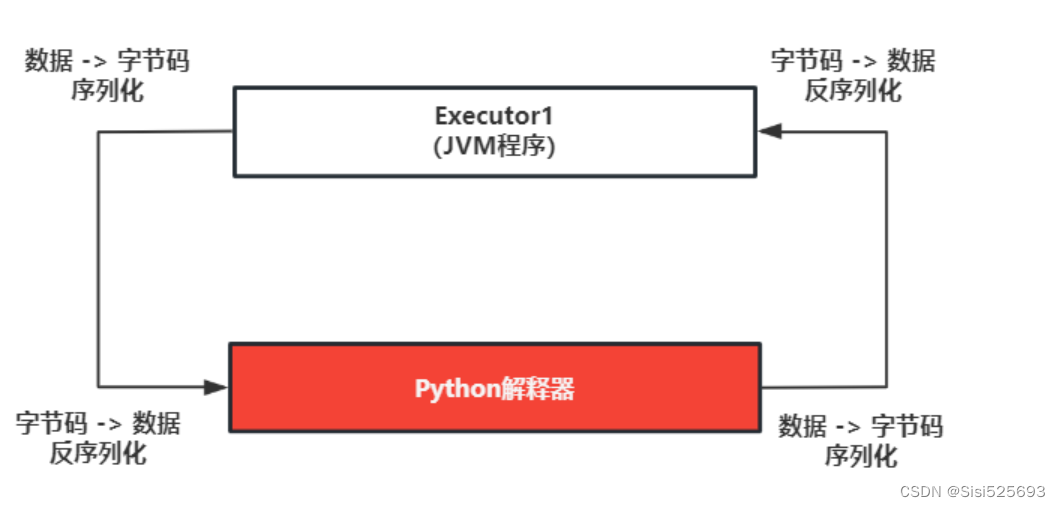
虽然Python支持自定义UDF函数,但是其效率并不是特别的高效。因为在使用的时候,传递一行处理一行,返回一行的方式。这样会带来非常大的序列化的开销的问题,导致原生UDF函数效率不好
早期解决方案: 基于Java/Scala来编写自定义UDF函数,然后基于python调用即可
目前主要的解决方案: 引入Arrow框架,可以基于内存来完成数据传输工作,可以大大的降低了序列化的开销,提供传输的效率,解决原生的问题。同时还可以基于pandas的自定义函数,利用pandas的函数优势完成各种处理操作
Spark原生自定义UDF函数
自定义函数流程:
第一步: 在PySpark中创建一个Python的函数,在这个函数中书写自定义的功能逻辑代码即可
第二步: 将Python函数注册到Spark SQL中
注册方式一: udf对象 = sparkSession.udf.register(参数1,参数2,参数3)
参数1: 【UDF函数名称】,此名称用于后续在SQL中使用,可以任意取值,但是要符合名称的规范
参数2: 【自定义的Python函数】,表示将哪个Python的函数注册为Spark SQL的函数
参数3: 【UDF函数的返回值类型】。用于表示当前这个Python的函数返回的类型
udf对象: 返回值对象,是一个UDF对象,可以在DSL中使用
说明: 如果通过方式一来注册函数, 【可以用在SQL和DSL】
注册方式二: udf对象 = F.udf(参数1,参数2)
参数1: Python函数的名称,表示将那个Python的函数注册为Spark SQL的函数
参数2: 返回值的类型。用于表示当前这个Python的函数返回的类型
udf对象: 返回值对象,是一个UDF对象,可以在DSL中使用
说明: 如果通过方式二来注册函数,【仅能用在DSL中】
注册方式三: 语法糖写法 @F.udf(returnType=返回值类型) 放置到对应Python的函数上面
说明: 实际是方式二的扩展。如果通过方式三来注册函数,【仅能用在DSL中】
第三步: 在Spark SQL的 DSL/ SQL 中进行使用即可
# 自定义一个函数,完成对数据统一添加一个后缀名的操作
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
# 绑定指定的Python解释器
from pyspark.sql.types import StringTypeos.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':print("请自定义一个函数,完成对数据统一添加一个后缀名的操作_itheima")# 1- 创建SparkSession对象spark = SparkSession.builder\.config("spark.sql.shuffle.partitions",1)\.appName('sparksql_udf_basetype')\.master('local[*]')\.getOrCreate()# 2- 数据输入init_df = spark.createDataFrame(data=[(1,'张三','广州'),(2,'李四','深圳')],schema='id int,name string,address string')init_df.printSchema()init_df.show()init_df.createTempView('tmp')# 3- 数据处理# 3.1- 创建自定义的Python函数def add_suffix(address):return address + "_itheima"# 3.2- 将Python函数注册到Spark SQL# 注册方式一dsl_add_suffix = spark.udf.register('sql_add_suffix',add_suffix,StringType())# 3.3- 在SQL/DSL中调用# SQLspark.sql("""selectid,name,address,sql_add_suffix(address) as new_addressfrom tmp""").show()# DSLinit_df.select("id","name","address",dsl_add_suffix("address").alias("new_address")).show()print("-"*30)# 在错误的地方调用了错误的函数。spark.udf.register参数1取的函数名只能在SQL中使用,不能在DSL中用。# spark.sql("""# select# id,name,address,# dsl_add_suffix(address) as new_address# from tmp# """).show()# 注册方式二:UDF返回值类型传值方式一dsl2_add_suffix = F.udf(add_suffix,StringType())# DSLinit_df.select("id","name","address",dsl2_add_suffix("address").alias("new_address")).show()# 注册方式二:UDF返回值类型传值方式二dsl3_add_suffix = F.udf(add_suffix, 'string')# DSLinit_df.select("id","name","address",dsl3_add_suffix("address").alias("new_address")).show()# 注册方式三:语法糖/装饰器@F.udf(returnType=StringType())def add_suffix_candy(address):return address + "_itheima"# DSLinit_df.select("id","name","address",add_suffix_candy("address").alias("new_address")).show()# 4- 数据输出# 5- 释放资源spark.stop()Pandas的UDF函数
Apache Arrow框架基本介绍
Apache Arrow是Apache旗下的一款顶级的项目。是一个跨平台的在内存中以列式存储的数据层,它的设计目标就是作为一个跨平台的数据层,来加快大数据分析项目的运行效率
Pandas 与 Spark SQL 进行交互的时候,建立在Apache Arrow上,带来低开销 高性能的UDF函数
Arrow并不会自动使用,在某些情况下,需要配置 以及在代码中需要进行小的更改才可以使用
如何安装? 三个节点建议都安装
检查服务器上是否有安装pyspark
pip list | grep pyspark 或者 conda list | grep pyspark如果服务器已经安装了pyspark的库,那么仅需要执行以下内容,即可安装。例如在 node1安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark[sql]
如果服务器中python环境中没有安装pyspark,建议执行以下操作,即可安装。例如在 node2 和 node3安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyarrow==10.0.0
如何使用呢? 默认不会自动启动的, 一般建议手动配置
sparkSession.conf.set('spark.sql.execution.arrow.pyspark.enabled',True)
基于Arrow完成Pandas DataFrame和Spark DataFrame互转
使用场景:
1- Spark的DataFrame -> Pandas的DataFrame:当大数据处理到后期的时候,可能数据量会越来越少,这样可以考虑使用单机版的Pandas来做后续数据的分析
2- Pandas的DataFrame -> Spark的DataFrame:当数据量达到单机无法高效处理的时候,或者需要和其他大数据框架集成的时候,可以转成Spark中的DataFrame
总结:
Pandas的DataFrame -> Spark的DataFrame: spark.createDataFrame(data=pandas_df)
Spark的DataFrame -> Pandas的DataFrame: init_df.toPandas()
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':print("基于Arrow完成Pandas DataFrame和Spark DataFrame互转")# 1- 创建SparkSession对象spark = SparkSession.builder\.appName('dataframe')\.master('local[*]')\.getOrCreate()# 手动开启Arrow框架spark.conf.set('spark.sql.execution.arrow.pyspark.enabled', True)# 2- 数据输入init_df = spark.createDataFrame(data=[(1, '张三', '广州'), (2, '李四', '深圳')],schema='id int,name string,address string')# 3- 数据处理# sparksql dataframe -> pandas dataframepd_df = init_df.toPandas()print(type(pd_df),pd_df)new_pd_df = pd_df[pd_df['id']==2]# pandas dataframe -> sparksql dataframespark_df = spark.createDataFrame(data=new_pd_df)spark_df.show()spark_df.printSchema()# 4- 数据输出# 5- 释放资源spark.stop()基于Pandas完成UDF函数
基于Pandas的UDF函数来转换为Spark SQL的UDF函数进行使用。底层是基于Arrow框架来完成数据传输,允许向量化(可以充分利用计算机CPU性能)操作。
Pandas的UDF函数其实本质上就是Python的函数,只不过函数的传入数据类型为Pandas的类型
基于Pandas的UDF可以使用自定义UDF函数和自定义UDAF函数
自定义函数流程:
第一步: 在PySpark中创建一个Python的函数,在这个函数中书写自定义的功能逻辑代码即可
第二步: 将Python函数包装成Spark SQL的函数
注册方式一: udf对象 = spark.udf.register(参数1, 参数2)
参数1: UDF函数名称。此名称用于后续在SQL中使用,可以任意取值,但是要符合名称的规范
参数2: Python函数的名称。表示将哪个Python的函数注册为Spark SQL的函数
使用: udf对象只能在DSL中使用。参数1指定的名称只能在SQL中使用
注意: 如果编写的是UDAF函数,那么注册方式一需要配合注册方式三,一起使用
注册方式二: udf对象 = F.pandas_udf(参数1, 参数2)
参数1: 自定义的Python函数。表示将哪个Python的函数注册为Spark SQL的函数
参数2: UDF函数的返回值类型。用于表示当前这个Python的函数返回的类型对应到Spark SQL的数据类型
udf对象: 返回值对象,是一个UDF对象。仅能用在DSL中使用
注册方式三: 语法糖写法 @F.pandas_udf(returnType=返回值Spark SQL的数据类型) 放置到对应Python的函数上面
说明: 实际是方式一的扩展。仅能用在DSL中使用
第三步: 在Spark SQL的 DSL/ SQL 中进行使用即可
自定义UDF函数
自定义Python函数的要求:SeriesToSeries
表示:第一步中创建自定义Python函数的时候,输入参数的类型和返回值类型必须都是Pandas中的Series类型
需求:完成a列和b列的求和计算操作
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
import pandas as pd
import pyspark.sql.functions as F# 绑定指定的Python解释器
from pyspark.sql.types import IntegerTypeos.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':# 1- 创建SparkSession对象spark = SparkSession.builder\.appName('pandas_udf')\.master('local[*]')\.getOrCreate()# 手动开启Arrow框架spark.conf.set('spark.sql.execution.arrow.pyspark.enabled', True)# 2- 数据输入init_df = spark.createDataFrame(data=[(1,2),(2,3),(3,4)],schema='num1 int,num2 int')init_df.createTempView('tmp')# 3- 数据处理# 3.1- 自定义Python函数"""1- num1:pd.Series用来限定输入的参数类型是Pandas中的Series对象2- -> pd.Series用来限定返回值类型是Pandas中的Series对象"""def my_sum(num1:pd.Series, num2:pd.Series) -> pd.Series:return num1+num2# 3.2- 注册进SparkSQL。注册方式一dsl_my_sum = spark.udf.register('sql_my_sum',my_sum)# 3.3- 使用# SQLspark.sql("""selectnum1,num2,sql_my_sum(num1,num2) as resultfrom tmp""").show()# DSLinit_df.select("num1","num2",dsl_my_sum("num1", "num2").alias("result")).show()# 注册方式二dsl2_my_sum = F.pandas_udf(my_sum,IntegerType())# DSLinit_df.select("num1","num2",dsl2_my_sum("num1", "num2").alias("result")).show()# 注册方式三@F.pandas_udf(IntegerType())def my_sum_candy(num1:pd.Series, num2:pd.Series) -> pd.Series:return num1+num2# DSLinit_df.select("num1","num2",my_sum_candy("num1", "num2").alias("result")).show()# 4- 数据输出# 5- 释放资源spark.stop()
自定义UDAF函数
自定义Python函数的要求:Series To 标量
表示:自定义函数的输入数据类型是Pandas中的Series对象,返回值数据类型是标量数据类型。也就是Python中的数据类型,例如:int、float、bool、list....
需求:对某一列数据计算平均值的操作
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
import pandas as pd
import pyspark.sql.functions as F# 绑定指定的Python解释器
from pyspark.sql.types import IntegerType, FloatTypeos.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'if __name__ == '__main__':# 1- 创建SparkSession对象spark = SparkSession.builder\.appName('pandas_udaf')\.master('local[*]')\.getOrCreate()# 手动开启Arrow框架spark.conf.set('spark.sql.execution.arrow.pyspark.enabled', True)# 2- 数据输入init_df = spark.createDataFrame(data=[(1,2),(2,3),(3,3)],schema='num1 int,num2 int')init_df.createTempView('tmp')# 3- 数据处理# 3.1- 自定义Python函数"""UDAF对自定义Python函数的要求:输入数据的类型必须是Pandas中的Series对象,返回值类型必须是Python中的标量数据类型"""@F.pandas_udf(returnType=FloatType())def my_avg(num2_col:pd.Series) -> float:print(type(num2_col))print(num2_col)# 计算平均值return num2_col.mean()# 3.2- 注册进SparkSQL。注册方式一dsl_my_avg = spark.udf.register('sql_my_avg',my_avg)# 3.3- 使用# SQLspark.sql("""selectsql_my_avg(num2) as resultfrom tmp""").show()# DSLinit_df.select(dsl_my_avg("num2").alias("result")).show()# 4- 数据输出# 5- 释放资源spark.stop()相关文章:
Spark SQL函数定义
目录 窗口函数 SQL函数分类 Spark原生自定义UDF函数 Pandas的UDF函数 Apache Arrow框架基本介绍 基于Arrow完成Pandas DataFrame和Spark DataFrame互转 基于Pandas完成UDF函数 自定义UDF函数 自定义UDAF函数 窗口函数 分析函数 over(partition by xxx order by xxx [as…...

触摸屏监控双速电动机-PLC I/O电路设计
PLC的输入接线电路图 PLC的输入接线电路如图1-21所示。24VDC电源选用0.7mm2的棕色和蓝色软铜导线,弱电信号线用0.5~0.7mm2的黑色或者白色软铜导线。 PLC输入接线图 PLC的输出接线电路图 PLC的输出接线电路如图1-22所示。AC220V接触器型号为CJX2-12,线…...
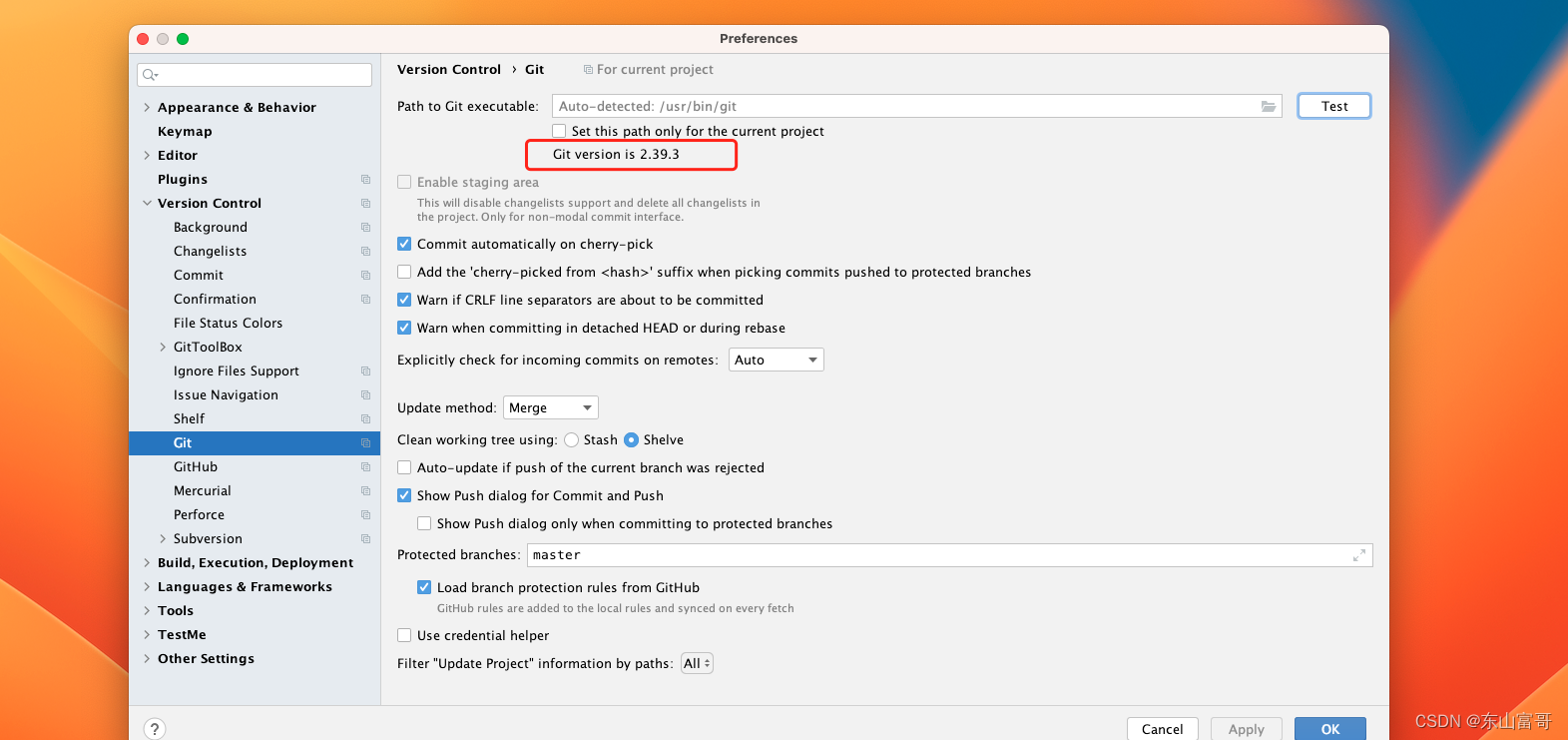
idea中使用git提交代码报 Nothing To commit No changes detected
问题描述 在idea中右键,开始将变更的代码进行提交的时候,【Commit Directory】点击提交的时候 报 Nothing To commit No changes detected解决方案 在这里点击Test 看看是不是能下面显示git版本,不行的话 会显示一个 fix的字样,行…...

基于长短期神经网络的回归分析,基于LSTM的回归预测
目录 背影 摘要 LSTM的基本定义 LSTM实现的步骤 基于长短期神经网络LSTM的回归分析 MATALB代码:基于长短期神经网络的回归分析,基于LSTM的回归预测资源-CSDN文库 https://download.csdn.net/download/abc991835105/88184633 效果图 结果分析 展望 参考论文 背影 LSTM神经…...
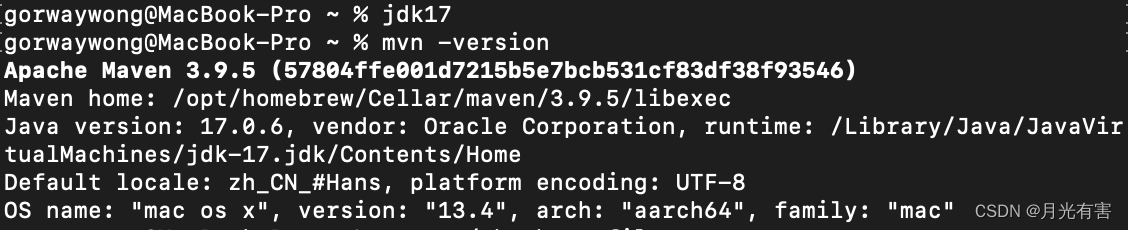
mac查看maven版本报错:The JAVA_HOME environment variable is not defined correctly
终端输入mvn -version报错: The JAVA_HOME environment variable is not defined correctly, this environment variable is needed to run this program. Java环境变量的问题,打开bash_profile查看 open ~/.bash_profile export JAVA_8_HOME/Library/Java/JavaVirtualMachine…...

蓝桥杯省赛无忧 编程9
#include<bits/stdc.h> using namespace std; int main() {int n,k,ans0;cin>>n>>k;while(n--){int a;cin>>a;ansa&1;}if(ans&1) cout<<"Alice"<<\n;else cout<<"Bob"; return 0; }这个游戏是基于数…...

Spring data都包含哪些内容
Spring Data是一个涵盖了对多种数据库访问技术的支持的项目集合,旨在提供一致的数据访问方式,简化数据访问层(DAO层)的开发工作。Spring Data项目为许多不同类型的数据存储提供了易于使用的接口和模式。主要包括以下几个方面&…...

unity 利用Graphics.Blit来制作图片效果
c# 的代码 using System.Collections; using System.Collections.Generic; using UnityEngine; using UnityEngine.UI;public class GraphicsBlitTest : MonoBehaviour {public Texture2D source;//原纹理public Material material;//效果材质public RawImage rawImage;// Sta…...

Linux ---- 小玩具
目录 一、安装: 1、佛祖保佑,永不宕机,永无bug 2、小火车 3、艺术字和其它 天气预报 艺术字 4、会说话的小牦牛 5、其他趣味图片 我爱你 腻害 英雄联盟 帅 忍 龙 你是猪 福 好运连连 欢迎 加油 想你 忘不了你 我错了 你…...

练习题 有奖问答
题目 问题描述 小蓝正在参与一个现场问答的节目。活动中一共有 3030 道题目, 每题只有答对和答错两种情况, 每答对一题得 10 分,答错一题分数归零。 小蓝可以在任意时刻结束答题并获得目前分数对应的奖项,之后不能再答任何题目。最高奖项需要 100 分,…...
php 文件操作
目录 1.file_xxx 2.fopen 1.file_xxx 文件读写的内容都是字符串数据格式 readfile(); //读取文件内容,并返回文件的长度 file_get_contents(文件路径); //读取文件。支持本地文件和远程文件url file_put_contents(文件路径, 内容); //写入数据,保存…...

Next-GPT: Any-to-Any Multimodal LLM
Next-GPT: Any-to-Any Multimodal LLM 最近在调研一些多模态大模型相关的论文,发现Arxiv上出的论文根本看不过来,遂决定开辟一个新坑《一页PPT说清一篇论文》。自己在读论文的过程中会用一页PPT梳理其脉络和重点信息,旨在帮助自己和读者快速了…...

Angular系列教程之MVC模式和MVVM模式
文章目录 MVC模式MVVM模式MVC与MVVM的区别Angular如何实现MVVM模式总结 在讨论Angular的时候,我们经常会听到MVC和MVVM这两种设计模式。这两种模式都是为了将用户界面(UI)和业务逻辑分离,使得代码更易于维护和扩展。在这篇文章中,我们将详细介…...

windows虚拟主机和linux虚拟主机的区别有哪些?
很多个人站长和中小企业在做网站的时候,会选择虚拟主机。虚拟主机用的操作系统多为Windows系统,很多人一提到操作系统立马联想到Windows系统。其实除了Windows系统外,还有很多的操作系统。其中Linux系统是其中的佼佼者。 1、操作系统 window…...
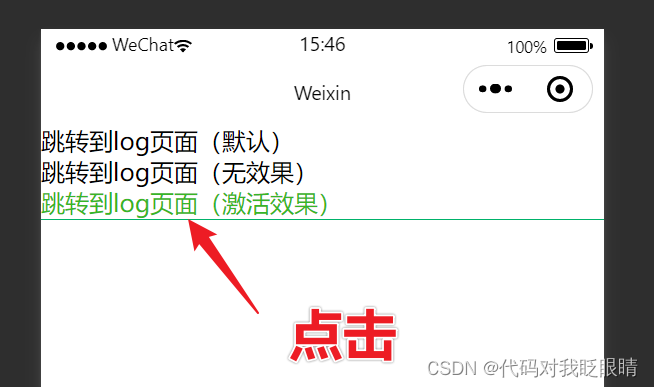
微信小程序(七)navigator点击效果
注释很详细,直接上代码 上一篇 新增内容: 1.默认效果 2.无效果 3.激活效果 源码: index.wxml //如果 <navigator url"/pages/logs/logs">跳转到log页面(默认) </navigator><navigator url&q…...

腾讯云服务器价格查询,2024更新
腾讯云服务器租用优惠价格表:轻量应用服务器2核2G3M价格62元一年、2核2G4M价格118元一年,540元三年、2核4G5M带宽218元一年,2核4G5M带宽756元三年、轻量4核8G12M服务器646元15个月;云服务器CVM S5实例2核2G配置280.8元一年、2核4G…...
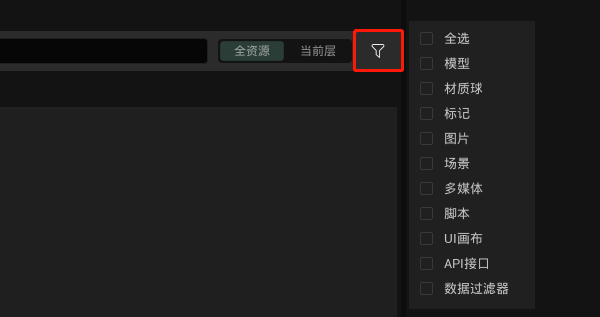
更适合3D项目的UI、事件交互!纯国产数字孪生引擎持续升级中!!!
UI和事件交互是3D可视化项目中最常见的模块,主要用于信息添加、展示,用来确保按照用户需求呈现内容并完成交互。 平时工作在进行UI和交互设计时,经常出现以下问题:UI过于复杂导致3D项目内交互效率低下,或者是结合3D项目…...
OpenCV-Python(47):支持向量机
原理 线性数据分割 如下图所示,其中含有两类数据,红的和蓝的。如果是使用kNN算法,对于一个测试数据我们要测量它到每一个样本的距离,从而根据最近的邻居分类。测量所有的距离需要足够的时间,并且需要大量的内存存储训…...

Centos 8 安装 Elasticsearch
简介:CentOS 8是一个基于Red Hat Enterprise Linux(RHEL)源代码构建的开源操作系统。它是一款稳定、可靠、安全的服务器操作系统,适合用于企业级应用和服务的部署。CentOS 8采用了最新的Linux内核和软件包管理系统,提供…...
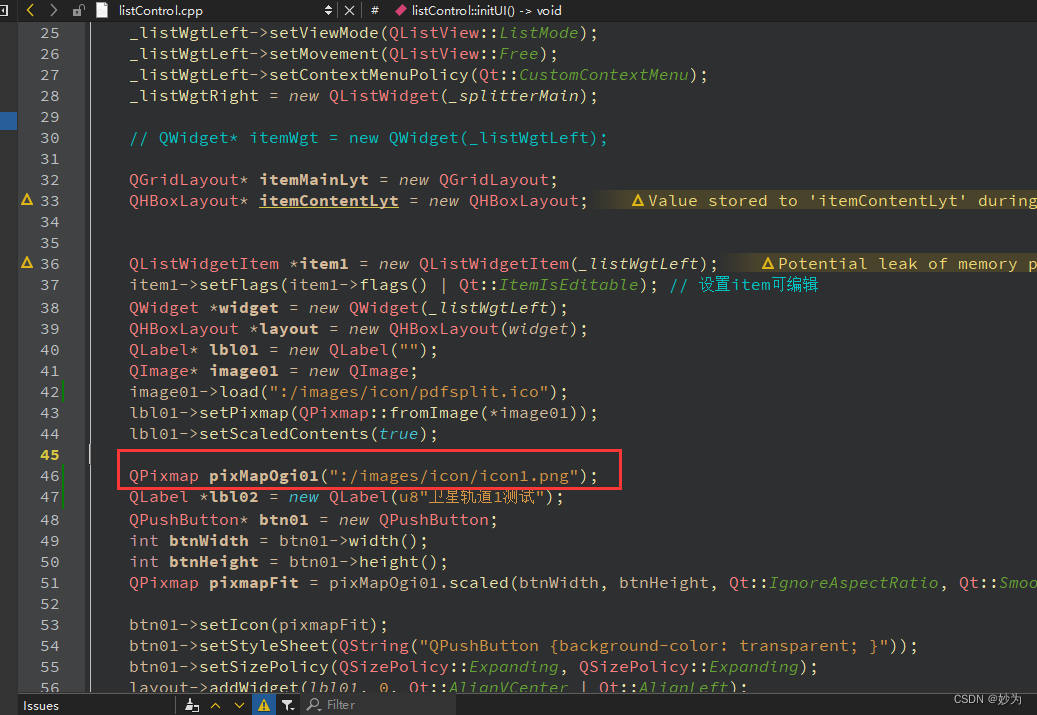
Qt5.15.2中加入图片资源
系列文章目录 文章目录 系列文章目录前言一、加入图片资源二、代码 前言 以前用的Qt5.15.2之前的版本,QtCreator默认的工程文件是*.pro,现在用5.15.2创建工程默认的工程文件是CMameList.txt,当然在创建项目时,仍然可以使用pro工程文件用QtCr…...

第11代酷睿工业主板PICO-TGU4:边缘AI与机器视觉的紧凑型解决方案
1. 项目概述:当紧凑型工业主板遇上第11代酷睿在工业自动化、边缘计算和智能零售这些领域里,我们常常面临一个经典的矛盾:一方面,应用场景对计算性能的要求越来越高,无论是机器视觉的实时图像处理,还是AI推理…...

Layerdivider深度解析:5步实现智能图像分层,生成专业级PSD文件
Layerdivider深度解析:5步实现智能图像分层,生成专业级PSD文件 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider Layerdivider是一款…...

华硕笔记本终极控制工具G-Helper:如何用免费轻量软件完全替代臃肿的Armoury Crate?
华硕笔记本终极控制工具G-Helper:如何用免费轻量软件完全替代臃肿的Armoury Crate? 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Stri…...

抖音批量下载工具终极指南:免费无水印高效下载完整教程
抖音批量下载工具终极指南:免费无水印高效下载完整教程 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback supp…...
云端物模型自定义)
硬件入门 + 单片机基础(第17天)云端物模型自定义
一、阿里云后台配置(添加 3 个标准属性)1. 进入物模型编辑页物联网平台 → 对应产品 → 功能定义 → 编辑物模型2. 逐个添加属性温度功能类型:设备属性功能名称:温度标识符:Temperature数据类型:浮点型&…...

快速解密QQ音乐加密文件:qmc-decoder完整指南
快速解密QQ音乐加密文件:qmc-decoder完整指南 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 还在为QQ音乐下载的.qmc、.qmc3、.qmcflac格式文件无法在其他播放…...
XUnity Auto Translator:Unity游戏玩家的终极翻译解决方案
XUnity Auto Translator:Unity游戏玩家的终极翻译解决方案 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为外语游戏中的生涩文本而烦恼吗?XUnity Auto Translator为你提供了…...
)
用STM32F103 DIY一个JTAG边界扫描测试仪(附完整源码与避坑记录)
用STM32F103 DIY一个JTAG边界扫描测试仪(附完整源码与避坑记录) 在嵌入式开发和硬件调试领域,验证PCB板或芯片的连通性一直是个令人头疼的问题。传统方法要么需要昂贵的专业设备,要么就得面对密密麻麻的测试点束手无策。而JTAG边界…...

百考通:AI让每一份调研与设计都高效落地
在数字化时代,市场调研、产品设计、学术研究等场景中,问卷设计作为核心环节,直接影响着数据收集的质量与工作推进的效率。传统问卷设计往往面临流程繁琐、耗时耗力、问题设计不精准等痛点,而百考通(https://www.baikao…...

【VASP实战】Ubuntu 22.04 LTS 部署 vasp.6.x 指南:从Intel oneAPI编译到GPU加速测试
1. VASP 6.x与Ubuntu 22.04 LTS环境概述 VASP(Vienna Ab initio Simulation Package)是材料科学领域广泛使用的第一性原理计算软件,能够模拟原子尺度的电子结构、分子动力学等过程。最新版VASP 6.x在并行计算效率和GPU加速支持上有显著提升&a…...