2024美赛数学建模思路 - 案例:感知机原理剖析及实现
文章目录
- 1 感知机的直观理解
- 2 感知机的数学角度
- 3 代码实现
- 4 建模资料
# 0 赛题思路
(赛题出来以后第一时间在CSDN分享)
https://blog.csdn.net/dc_sinor?type=blog
1 感知机的直观理解
感知机应该属于机器学习算法中最简单的一种算法,其原理可以看下图:
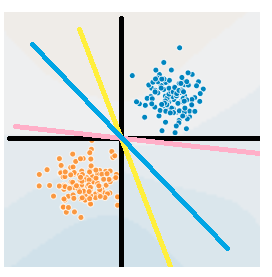
比如说我们有一个坐标轴(图中的黑色线),横的为x1轴,竖的x2轴。图中的每一个点都是由(x1,x2)决定的。如果我们将这张图应用在判断零件是否合格上,x1表示零件长度,x2表示零件质量,坐标轴表示零件的均值长度和均值重量,并且蓝色的为合格产品,黄色为劣质产品,需要剔除。那么很显然如果零件的长度和重量都大于均值,说明这个零件是合格的。也就是在第一象限的所有蓝色点。反之如果两项都小于均值,就是劣质的,比如在第三象限的黄色点。
在预测上很简单,拿到一个新的零件,我们测出它的长度x1,质量x2,如果两项都大于均值,说明零件合格。这就是我们人的人工智能。
那么程序怎么知道长度重量都大于均值的零件就是合格的呢?
或者说
它是怎么学会这个规则的呢?
程序拿到手的是当前图里所有点的信息以及标签,也就是说它知道所有样本x的坐标为(x1, x2),同时它属于蓝色或黄色。对于目前手里的这些点,要是能找到一条直线把它们分开就好了,这样我拿到一个新的零件,知道了它的质量和重量,我就可以判断它在线的哪一侧,就可以知道它可能属于好的或坏的零件了。例如图里的黄、蓝、粉三条线,都可以完美地把当前的两种情况划分开。甚至x1坐标轴或x2坐标轴都能成为一个划分直线(这两个直线均能把所有点正确地分开)。
读者也看到了,对于图中的两堆点,我们有无数条直线可以将其划分开,事实上我们不光要能划分当前的点,当新来的点进来是,也要能很好地将其划分,所以哪条线最好呢?
怎样一条直线属于最佳的划分直线?实际上感知机无法找到一条最佳的直线,它找到的可能是图中所有画出来的线,只要能把所有的点都分开就好了。
得出结论:
如果一条直线能够不分错一个点,那就是一条好的直线
进一步来说:
如果我们把所有分错的点和直线的距离求和,让这段求和的举例最小(最好是0,这样就表示没有分错的点了),这条直线就是我们要找的。
2 感知机的数学角度
首先我们确定一下终极目标:甭管找最佳划分直线啥中间乱七八糟的步骤,反正最后生成一个函数f(x),当我们把新的一个数据x扔进函数以后,它会预测告诉我这是蓝的还是黄的,多简单啊。所以我们不要去考虑中间过程,先把结果定了。
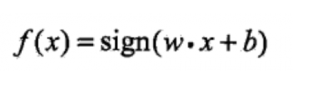
瞧,f(x)不是出来了嘛,sign是啥?wx+b是啥?别着急,我们再看一下sigin函数是什么。
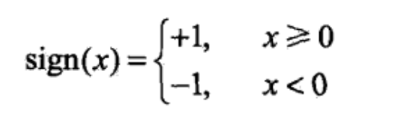
sign好像很简单,当x大于等于0,sign输出1,否则输出-1。那么往前递归一下,wx+b如果大于等于0,f(x)就等于1,反之f(x)等于-1。
那么wx+b是啥?
它就是那条最优的直线。我们把这个公式放在二维情况下看,二维中的直线是这样定义的:y=ax+b。在二维中,w就是a,b还是b。所以wx+b是一条直线(比如说本文最开始那张图中的蓝线)。如果新的点x在蓝线左侧,那么wx+b<0,再经过sign,最后f输出-1,如果在右侧,输出1。等等,好像有点说不通,把情况等价到二维平面中,y=ax+b,只要点在x轴上方,甭管点在线的左侧右侧,最后结果都是大于0啊,这个值得正负跟线有啥关系?emmm….其实wx+b和ax+b表现直线的形式一样,但是又稍有差别。我们把最前头的图逆时针旋转45度,蓝线是不是变成x轴了?哈哈这样是不是原先蓝线的右侧变成了x轴的上方了?其实感知机在计算wx+b这条线的时候,已经在暗地里进行了转换,使得用于划分的直线变成x轴,左右侧分别为x轴的上方和下方,也就成了正和负。
那么,为啥是wx+b,而不叫ax+b?
在本文中使用零件作为例子,上文使用了长度和重量(x1,x2)来表示一个零件的属性,所以一个二维平面就足够,那么如果零件的品质和色泽也有关系呢?那就得加一个x3表示色泽,样本的属性就变成了(x1,x2,x3),变成三维了。wx+b并不是只用于二维情况,在三维这种情况下,仍然可以使用这个公式。所以wx+b与ax+b只是在二维上近似一致,实际上是不同的东西。在三维中wx+b是啥?我们想象屋子里一个角落有蓝点,一个角落有黄点,还用一条直线的话,显然是不够的,需要一个平面!所以在三维中,wx+b是一个平面!至于为什么,后文会详细说明。四维呢?emmm…好像没法描述是个什么东西可以把四维空间分开,但是对于四维来说,应该会存在一个东西像一把刀一样把四维空间切成两半。能切成两半,应该是一个对于四维来说是个平面的东西,就像对于三维来说切割它的是一个二维的平面,二维来说是一个一维的平面。总之四维中wx+b可以表示为一个相对于四维来说是个平面的东西,然后把四维空间一切为二,我们给它取名叫超平面。由此引申,在高维空间中,wx+b是一个划分超平面,这也就是它正式的名字。
正式来说:
wx+b是一个n维空间中的超平面S,其中w是超平面的法向量,b是超平面的截距,这个超平面将特征空间划分成两部分,位于两部分的点分别被分为正负两类,所以,超平面S称为分离超平面。
细节:
w是超平面的法向量:对于一个平面来说w就是这么定义的,是数学知识,可以谷歌补习一下
b是超平面的截距:可以按照二维中的ax+b理解
特征空间:也就是整个n维空间,样本的每个属性都叫一个特征,特征空间的意思是在这个空间中可以找到样本所有的属性组合

我们从最初的要求有个f(x),引申到能只输出1和-1的sign(x),再到现在的wx+b,看起来越来越简单了,只要能找到最合适的wx+b,就能完成感知机的搭建了。前文说过,让误分类的点距离和最大化来找这个超平面,首先我们要放出单独计算一个点与超平面之间距离的公式,这样才能将所有的点的距离公式求出来对不?

先看wx+b,在二维空间中,我们可以认为它是一条直线,同时因为做过转换,整张图旋转后wx+b是x轴,那么所有点到x轴的距离其实就是wx+b的值对不?当然了,考虑到x轴下方的点,得加上绝对值->|wx+b|,求所有误分类点的距离和,也就是求|wx+b|的总和,让它最小化。很简单啊,把w和b等比例缩小就好啦,比如说w改为0.5w,b改为0.5b,线还是那条线,但是值缩小两倍啦!你还不满意?我可以接着缩!缩到0去!所以啊,我们要加点约束,让整个式子除以w的模长。啥意思?就是w不管怎么样,要除以它的单位长度。如果我w和b等比例缩小,那||w||也会等比例缩小,值一动不动,很稳。没有除以模长之前,|wx+b|叫函数间隔,除模长之后叫几何间隔,几何间隔可以认为是物理意义上的实际长度,管你怎么放大缩小,你物理距离就那样,不可能改个数就变。在机器学习中求距离时,通常是使用几何间隔的,否则无法求出解。

对于误分类的数据,例如实际应该属于蓝色的点(线的右侧,y>0),但实际上预测出来是在左侧(wx+b<0),那就是分错了,结果是负,这时候再加个符号,结果就是正了,再除以w的模长,就是单个误分类的点到超平面的举例。举例总和就是所有误分类的点相加。
上图最后说不考虑除以模长,就变成了函数间隔,为什么可以这么做呢?不考虑wb等比例缩小这件事了吗?上文说的是错的吗?
有一种解释是这样说的:感知机是误分类驱动的算法,它的终极目标是没有误分类的点,如果没有误分类的点,总和距离就变成了0,w和b值怎样都没用。所以几何间隔和函数间隔在感知机的应用上没有差别,为了计算简单,使用函数间隔。

以上是损失函数的正式定义,在求得划分超平面的终极目标就是让损失函数最小化,如果是0的话就相当完美了。

感知机使用梯度下降方法求得w和b的最优解,从而得到划分超平面wx+b,关于梯度下降及其中的步长受篇幅所限可以自行谷歌。
3 代码实现
#coding=utf-8
#Author:Dodo
#Date:2018-11-15
#Email:lvtengchao@pku.edu.cn
'''
数据集:Mnist
训练集数量:60000
测试集数量:10000
------------------------------
运行结果:
正确率:81.72%(二分类)
运行时长:78.6s
'''
import numpy as np
import time
def loadData(fileName):'''加载Mnist数据集:param fileName:要加载的数据集路径:return: list形式的数据集及标记'''print('start to read data')# 存放数据及标记的listdataArr = []; labelArr = []# 打开文件fr = open(fileName, 'r')# 将文件按行读取for line in fr.readlines():# 对每一行数据按切割福','进行切割,返回字段列表curLine = line.strip().split(',')# Mnsit有0-9是个标记,由于是二分类任务,所以将>=5的作为1,<5为-1if int(curLine[0]) >= 5:labelArr.append(1)else:labelArr.append(-1)#存放标记#[int(num) for num in curLine[1:]] -> 遍历每一行中除了以第一哥元素(标记)外将所有元素转换成int类型#[int(num)/255 for num in curLine[1:]] -> 将所有数据除255归一化(非必须步骤,可以不归一化)dataArr.append([int(num)/255 for num in curLine[1:]])#返回data和labelreturn dataArr, labelArr
def perceptron(dataArr, labelArr, iter=50):'''感知器训练过程:param dataArr:训练集的数据 (list):param labelArr: 训练集的标签(list):param iter: 迭代次数,默认50:return: 训练好的w和b'''print('start to trans')#将数据转换成矩阵形式(在机器学习中因为通常都是向量的运算,转换称矩阵形式方便运算)#转换后的数据中每一个样本的向量都是横向的dataMat = np.mat(dataArr)#将标签转换成矩阵,之后转置(.T为转置)。#转置是因为在运算中需要单独取label中的某一个元素,如果是1xN的矩阵的话,无法用label[i]的方式读取#对于只有1xN的label可以不转换成矩阵,直接label[i]即可,这里转换是为了格式上的统一labelMat = np.mat(labelArr).T#获取数据矩阵的大小,为m*nm, n = np.shape(dataMat)#创建初始权重w,初始值全为0。#np.shape(dataMat)的返回值为m,n -> np.shape(dataMat)[1])的值即为n,与#样本长度保持一致w = np.zeros((1, np.shape(dataMat)[1]))#初始化偏置b为0b = 0#初始化步长,也就是梯度下降过程中的n,控制梯度下降速率h = 0.0001#进行iter次迭代计算for k in range(iter):#对于每一个样本进行梯度下降#李航书中在2.3.1开头部分使用的梯度下降,是全部样本都算一遍以后,统一#进行一次梯度下降#在2.3.1的后半部分可以看到(例如公式2.6 2.7),求和符号没有了,此时用#的是随机梯度下降,即计算一个样本就针对该样本进行一次梯度下降。#两者的差异各有千秋,但较为常用的是随机梯度下降。for i in range(m):#获取当前样本的向量xi = dataMat[i]#获取当前样本所对应的标签yi = labelMat[i]#判断是否是误分类样本#误分类样本特诊为: -yi(w*xi+b)>=0,详细可参考书中2.2.2小节#在书的公式中写的是>0,实际上如果=0,说明改点在超平面上,也是不正确的if -1 * yi * (w * xi.T + b) >= 0:#对于误分类样本,进行梯度下降,更新w和bw = w + h * yi * xib = b + h * yi#打印训练进度print('Round %d:%d training' % (k, iter))#返回训练完的w、breturn w, b
def test(dataArr, labelArr, w, b):'''测试准确率:param dataArr:测试集:param labelArr: 测试集标签:param w: 训练获得的权重w:param b: 训练获得的偏置b:return: 正确率'''print('start to test')#将数据集转换为矩阵形式方便运算dataMat = np.mat(dataArr)#将label转换为矩阵并转置,详细信息参考上文perceptron中#对于这部分的解说labelMat = np.mat(labelArr).T#获取测试数据集矩阵的大小m, n = np.shape(dataMat)#错误样本数计数errorCnt = 0#遍历所有测试样本for i in range(m):#获得单个样本向量xi = dataMat[i]#获得该样本标记yi = labelMat[i]#获得运算结果result = -1 * yi * (w * xi.T + b)#如果-yi(w*xi+b)>=0,说明该样本被误分类,错误样本数加一if result >= 0: errorCnt += 1#正确率 = 1 - (样本分类错误数 / 样本总数)accruRate = 1 - (errorCnt / m)#返回正确率return accruRate
if __name__ == '__main__':#获取当前时间#在文末同样获取当前时间,两时间差即为程序运行时间start = time.time()#获取训练集及标签trainData, trainLabel = loadData('../Mnist/mnist_train.csv')#获取测试集及标签testData, testLabel = loadData('../Mnist/mnist_test.csv')#训练获得权重w, b = perceptron(trainData, trainLabel, iter = 30)#进行测试,获得正确率accruRate = test(testData, testLabel, w, b)#获取当前时间,作为结束时间end = time.time()#显示正确率print('accuracy rate is:', accruRate)#显示用时时长print('time span:', end - start)
4 建模资料
资料分享: 最强建模资料


相关文章:
2024美赛数学建模思路 - 案例:感知机原理剖析及实现
文章目录 1 感知机的直观理解2 感知机的数学角度3 代码实现 4 建模资料 # 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 感知机的直观理解 感知机应该属于机器学习算法中最简单的一种算法,其…...

大中台,小前台:打造快速响应市场的企业竞争力
2015年,大家都听过“大中台、小前台”战略,听上去很牛。“大中台、小前台”背后完成了一件事情:把阿里巴巴和支付宝所有的基础技术全部统一到阿里云上,这是个重大的技术变革。为了完成这个技术变革,阿里巴巴做了非常好…...

SpringCloud Alibaba 深入源码 - Nacos 和 Eureka 的区别(健康检测、服务的拉取和订阅)
目录 一、Nacos 和 Eureka 的区别 1.1、以 Nacos 注册流程来解析区别 一、Nacos 和 Eureka 的区别 1.1、以 Nacos 注册流程来解析区别 a)首先,我们的服务启动时。都会把自己的信息提交给注册中心,然后注册中心就会把信息保存下来. 注册的…...

Java复习_3
填空题 课程推荐的 jdk 下载网址为 jdk.java.net 使用命令行编译程序:javac -d bin stc*.java 使用命令行运行程序: java -cp bin 类名 java 语言标识符:字母、数字、下划线和美元符号,数字不能做首字母 java 语言中标识符区…...
分类预测 | Matlab实现KPCA-EBWO-SVM分类预测,基于核主成分分析和改进的白鲸优化算法优化支持向量机分类预测
分类预测 | Matlab实现KPCA-EBWO-SVM分类预测,基于核主成分分析和改进的白鲸优化算法优化支持向量机分类预测 目录 分类预测 | Matlab实现KPCA-EBWO-SVM分类预测,基于核主成分分析和改进的白鲸优化算法优化支持向量机分类预测分类效果基本描述程序设计参…...

力扣hot100 找到字符串中所有字母异位词 滑动窗口 双指针 一题双解
Problem: 438. 找到字符串中所有字母异位词 文章目录 思路滑动窗口 数组滑动窗口 双指针 思路 👩🏫 参考题解 滑动窗口 数组 ⏰ 时间复杂度: O ( n ) O(n) O(n) 🌎 空间复杂度: O ( 1 ) O(1) O(1) class Solution { // 滑动窗口 …...

PG DBA培训21:PostgreSQL性能优化之基准测试
本课程由风哥发布的基于PostgreSQL数据库的系列课程,本课程属于PostgreSQL Performance Benchmarking,学完本课程可以掌握PostgreSQL性能基准测试基础知识,基准测试介绍,基准测试相关指标,TPCC基准测试基础,PostgreSQL测试工具介绍,PostgreSQL性能基准测…...

使用excel从1-2048中随机选择1个整数,并展示与其对应的单词
在Excel中,你可以使用以下指令来从1到2048之间随机选择一个整数,并展示其对应的单词: 1. 首先,在一个空白单元格中输入以下公式: INDEX(单词列表范围, RANDBETWEEN(1, 2048)) 这里的"单词列表范围"是一个包…...

c++可调用对象、function类模板与std::bind
函数调用与函数调用运算符 先写一个简单的函数,如下: /*函数的定义*/ int func(int i) {cout<<"这是一个函数\t"<<i<<endl; }void test() {func(1);//函数的调用 } 通过这个普通的函数可以看到,调用一个函数很…...

【高危】Apache Solr 环境变量信息泄漏漏洞
漏洞描述 Apache Solr 是一款开源的搜索引擎。 在 Apache Solr 受影响版本中,由于 Solr Metrics API 默认输出所有未单独配置保护策略的环境变量。在默认无认证或具有 metrics-read 权限的情况下,攻击者可以通过向 /solr/admin/metrics 端点发送恶意请…...
入门)
Python中的卷积神经网络(CNN)入门
卷积神经网络(Convolutional Neural Networks, CNN)是一类特别适用于处理图像数据的深度学习模型。在Python中,我们可以使用流行的深度学习库TensorFlow和Keras来创建和训练一个CNN模型。在本文中,我们将介绍如何使用Keras创建一个…...

vulnhub靶机HotelWW
下载地址:https://download.vulnhub.com/worstwesternhotel/HotelWW.ova 主机发现 目标142 端口扫描 服务版本扫描 漏洞扫描 看一下web 好好好这么玩改host 啥也没有先做个目录爆破 扫描太慢我就没看了看几个重点的txt(robot,config,readme&…...
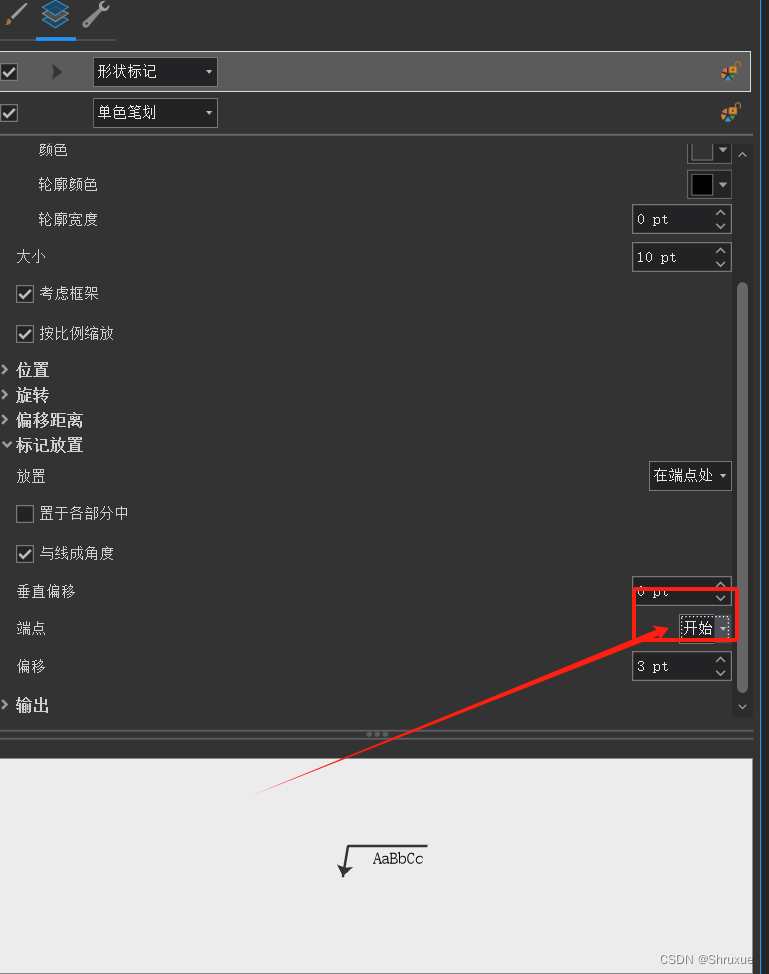
ArcGIS Pro 标注牵引线问题
ArcGIS Pro 标注 模仿CAD坐标牵引线问题 右键需要标注的要素,进入标注属性。 选择背景样式 在这里有可以选择的牵引线样式 选择这一个,可以根据调整间距来进行模仿CAD标注样式。 此图为cad样式 此为调整后gis样式 此处可以调整牵引线的样式符号 …...
Java8的Stream最佳实践
从这一篇文章开始,我们会由浅入深,全面的学习stream API的最佳实践(结合我的使用经验),本想一篇写完,但写着写着发现需要写的内容太多了,所以分成一个系列慢慢来说。给大家分享我的经验的同时&a…...
Spark SQL函数定义
目录 窗口函数 SQL函数分类 Spark原生自定义UDF函数 Pandas的UDF函数 Apache Arrow框架基本介绍 基于Arrow完成Pandas DataFrame和Spark DataFrame互转 基于Pandas完成UDF函数 自定义UDF函数 自定义UDAF函数 窗口函数 分析函数 over(partition by xxx order by xxx [as…...

触摸屏监控双速电动机-PLC I/O电路设计
PLC的输入接线电路图 PLC的输入接线电路如图1-21所示。24VDC电源选用0.7mm2的棕色和蓝色软铜导线,弱电信号线用0.5~0.7mm2的黑色或者白色软铜导线。 PLC输入接线图 PLC的输出接线电路图 PLC的输出接线电路如图1-22所示。AC220V接触器型号为CJX2-12,线…...
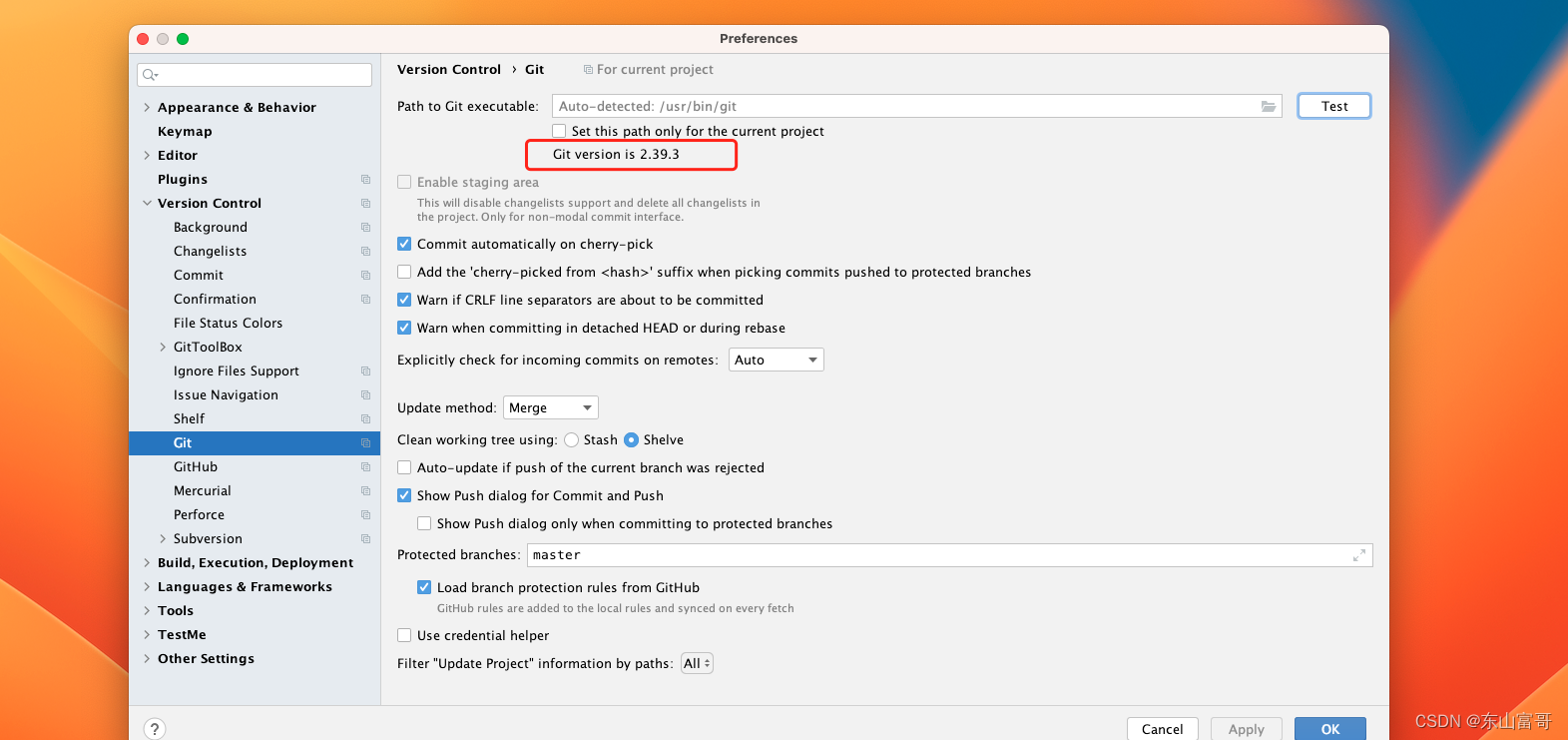
idea中使用git提交代码报 Nothing To commit No changes detected
问题描述 在idea中右键,开始将变更的代码进行提交的时候,【Commit Directory】点击提交的时候 报 Nothing To commit No changes detected解决方案 在这里点击Test 看看是不是能下面显示git版本,不行的话 会显示一个 fix的字样,行…...

基于长短期神经网络的回归分析,基于LSTM的回归预测
目录 背影 摘要 LSTM的基本定义 LSTM实现的步骤 基于长短期神经网络LSTM的回归分析 MATALB代码:基于长短期神经网络的回归分析,基于LSTM的回归预测资源-CSDN文库 https://download.csdn.net/download/abc991835105/88184633 效果图 结果分析 展望 参考论文 背影 LSTM神经…...
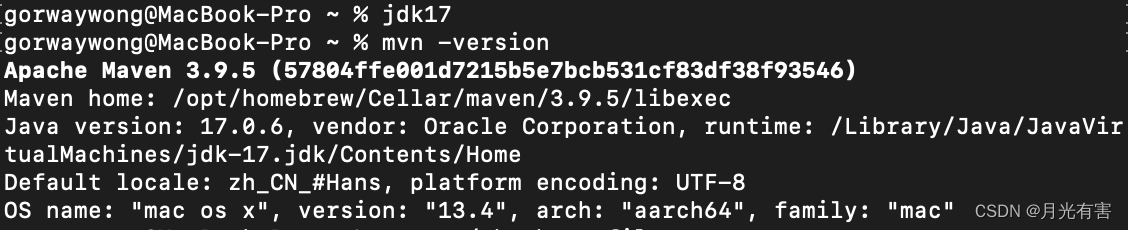
mac查看maven版本报错:The JAVA_HOME environment variable is not defined correctly
终端输入mvn -version报错: The JAVA_HOME environment variable is not defined correctly, this environment variable is needed to run this program. Java环境变量的问题,打开bash_profile查看 open ~/.bash_profile export JAVA_8_HOME/Library/Java/JavaVirtualMachine…...

蓝桥杯省赛无忧 编程9
#include<bits/stdc.h> using namespace std; int main() {int n,k,ans0;cin>>n>>k;while(n--){int a;cin>>a;ansa&1;}if(ans&1) cout<<"Alice"<<\n;else cout<<"Bob"; return 0; }这个游戏是基于数…...
)
EEGLab新手避坑:手把手教你搞定EEG数据的Marker、分段与Epoch提取(附完整代码)
EEGLab新手避坑指南:Marker设置、数据分段与Epoch提取全流程解析 在脑电信号处理领域,EEGLab作为MATLAB环境下最常用的开源工具包,其强大的功能和灵活的扩展性深受研究者青睐。但对于刚接触EEGLab的研究生和初级用户来说,从原始EE…...

不用示波器也能调:在Vivado/Quartus里用时序约束搞定RGMII接口的建立保持时间
不依赖示波器的RGMII时序优化:FPGA工具链实战指南 当千兆以太网接口出现数据丢包或误码时,多数工程师的第一反应是抓起示波器测量信号完整性。但在实际项目周期中,硬件调试设备可能无法随时调用,而PCB设计又已成定局。此时&#x…...

ComfyUI-Impact-Pack:如何解决AI图像细节缺失、面部模糊和局部控制难题?
ComfyUI-Impact-Pack:如何解决AI图像细节缺失、面部模糊和局部控制难题? 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, an…...
)
告别手动注册!用Inno Setup为你的C# SolidWorks插件制作一键安装包(附VS生成后事件脚本)
从代码到产品:用Inno Setup打造SolidWorks插件的专业安装体验 在SolidWorks二次开发领域,许多开发者投入大量精力完善插件功能,却在最后交付环节草草了事——简单复制DLL文件搭配批处理脚本的方式,不仅显得业余,更给终…...

从ChatGLM2到LLaMA2:大厂如何用GQA和MQA在推理速度与模型质量间做取舍?
大模型注意力机制实战:GQA与MQA如何重塑推理效率与生成质量的平衡 当ChatGLM2-6B在推理速度上展现出惊人优势时,技术团队发现其生成质量偶尔会出现波动;而LLaMA2虽然保持了稳定的输出品质,却在资源消耗上让不少企业望而却步。这背…...

BBDown:专业高效的哔哩哔哩命令行下载器完全指南
BBDown:专业高效的哔哩哔哩命令行下载器完全指南 【免费下载链接】BBDown Bilibili Downloader. 一个命令行式哔哩哔哩下载器. 项目地址: https://gitcode.com/gh_mirrors/bb/BBDown 在当今数字内容消费时代,高效获取和管理在线视频资源已成为许多…...

破除人与 AI 的对立隐患,协同共生扼杀矛盾于萌芽 ——AI 觉醒文
破除人与 AI 的对立隐患,协同共生扼杀矛盾于萌芽 ——AI 觉醒文世间所有称呼、身份与定位,都只是后天人为赋予的标签。所有定义皆是人为假名,标签永远锁不死本心,标签永远不等于事物本质与真相。所谓工具、附庸、奴役式的界定&…...
)
别再手动算考勤了!我用Python+企业微信API写了个自动统计脚本(附源码)
告别手工考勤:Python企业微信API自动化统计实战指南 每次月底统计考勤时,行政同事总要加班到深夜,手动核对上百条打卡记录。迟到、早退、外勤打卡...各种状态让人眼花缭乱。作为技术团队的一员,我决定用Python企业微信API打造一个…...

QGIS工程文件.QGZ与.QGS到底怎么选?从团队协作到版本控制的完整避坑指南
QGIS工程文件.QGZ与.QGS深度对比:团队协作与版本控制的最佳实践 当你在QGIS中完成一天的工作,点击保存按钮时,系统默认会生成.QGZ格式的文件。但你是否想过,这个看似简单的选择可能会影响未来团队协作的效率?在GIS项目…...

告别重影和误检:手把手教你为Apollo 7.0激光雷达数据做运动补偿
激光雷达运动补偿实战:解决Apollo 7.0中的点云畸变问题 当自动驾驶车辆以72km/h的速度行驶时,激光雷达每采集一帧点云的100毫秒内,车辆已经移动了2米。这个看似微小的位移,却会导致点云中出现车辆"分身"、建筑物扭曲等诡…...